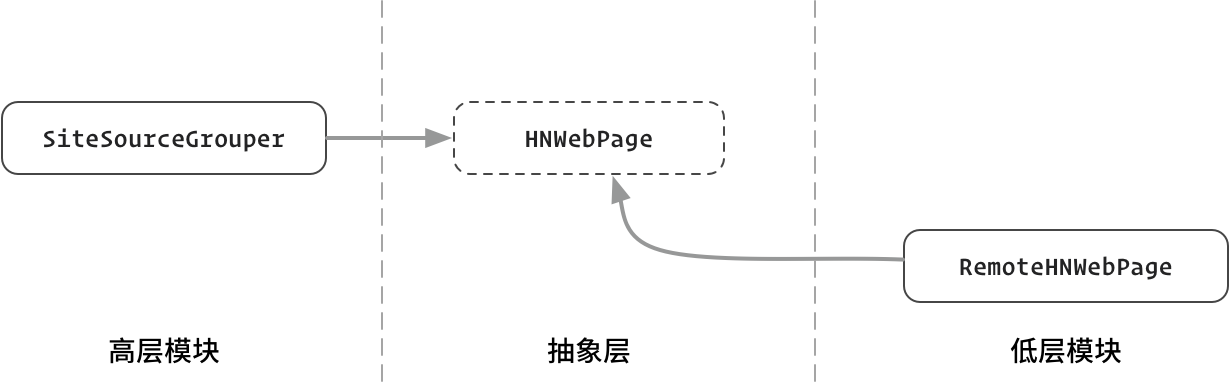
图:SiteSourceGrouper 和 RemoteHNWebPage 都依赖抽象层 HNWebPage
在图中,高层模块不再依赖低层模块,二者同时依赖于抽象概念 `HNWebPage`,低层模块的依赖箭头和之前相比倒过来了。所以我们称其为 **依赖倒置**。
### 依赖倒置后的单元测试
再回到之前的单元测试上来。通过引入了新的抽象层 `HNWebPage`,我们可以实现一个不依赖外部网络的新类型 `LocalHNWebPage`。
```python
class LocalHNWebPage(HNWebPage):
"""本地页面,根据本地文件返回页面内容"""
def __init__(self, path: str):
self.path = path
def get_text(self) -> str:
with open(self.path, 'r') as fp:
return fp.read()
```
所以,单元测试也可以改为使用 `LocalHNWebPage`:
```python
def test_grouper_from_local():
page = LocalHNWebPage(path="./static_hn.html")
grouper = SiteSourceGrouper(page)
result = grouper.get_groups()
assert isinstance(result, Counter), "groups should be Counter instance"
```
这样就可以在没有外网的服务器上测试 `SiteSourceGrouper` 类的核心逻辑了。
> Hint:其实上面的测试函数 `test_grouper_from_local` 远远算不上一个合格的测试用例。
>
> 如果真要测试 `SiteSourceGrouper` 的核心逻辑。我们应该准备一个虚构的 Hacker News 页面 *(比如刚好包含 5 个 来源自 github.com 的条目)*,然后判断结果是否包含 `assert result['github.com] == 5`
### 问题:一定要使用抽象类 abc 吗?
为了实现依赖倒置,我们在上面定义了抽象类:`HNWebPage`。那是不是只有定义了抽象类才能实现依赖倒置?只有用了抽象类才算是依赖倒置呢?
**答案是否定的。** 如果你愿意,你可以把代码里的抽象类 `HNWebPage` 以及所有的相关引用都删掉,你会发现没有它们代码仍然可以正常运行。
这是因为 Python 是一门“鸭子类型”语言。这意味着只要 `RemoteHNWebPage` 和 `LocalHNWebPage` 类型保持着统一的接口协议*(提供 .get_text() 公开方法)*,并且它们的 **协议符合我们定义的抽象**。那么那个中间层就存在,依赖倒置就是成立的。至于这份 **协议** 是通过抽象类还是普通父类(甚至可以是普通函数)定义的,就没那么重要了。
所以,虽然在某些编程语言中,实现依赖倒置必须得定义新的接口类型,但在 Python 里,依赖倒置并不是抽象类 abc 的特权。
### 问题:抽象一定是好东西吗?
前面的所有内容,都是在说新增一个抽象层,然后让依赖关系倒过来的种种好处。所以,多抽象的代码一定就是好的吗?缺少抽象的代码就一定不够灵活?
和所有这类问题的标准回答一样,答案是:**视情况而定。**
当你习惯了依赖倒置原则以后,你会发现 *抽象(Abstract)* 其实是一种思维方式,而不仅仅是一种编程手法。如果你愿意,你可以在代码里的所有地方都 **硬挤** 一层额外抽象出来:
- 比如代码依赖了 lxml 模块的 xpath 具体实现,我是不是得定义一层 *“HNTitleDigester”* 把它抽象进去?
- 比如代码里的字符串字面量也是具体实现,我是不是得定义一个 *"StringLike"* 类型把它抽象进去?
- ... ...
事实上,抽象的好处显而易见:**它解耦了高层模块和低层模块间的依赖关系,让代码变得更灵活。** 但抽象同时也带来了额外的编码与理解成本。所以,了解何时 **不** 抽象与何时抽象同样重要。**只有对代码中那些现在或未来会发生变化的东西进行抽象,才能获得最大的收益。**
## I:接口隔离原则
接口隔离原则*(后简称 I 原则)*全称为 *“Interface Segregation Principles”*。顾名思义,它是一条和“接口(Interface)”有关的原则。
我在前面解释过何为“接口(Interface)”。**接口是模块间相互交流的抽象协议**,它在不同的编程语言里有着不同的表现形态。比如在 Go 里它是 `type ... interface`,而在 Python 中它可以是抽象类、普通类或者函数,甚至某个只在你大脑里存在的一套协议。
I 原则认为:**“客户(client)应该不依赖于它不使用的方法”**
> The interface-segregation principle (ISP) states that no client should be forced to depend on methods it does not use.
这里说的“客户(Client)”指的是接口的使用方 *(客户程序)*,也就是调用接口方法的高层模块。拿上一个统计 HN 页面条目的例子来说:
- `使用方(客户程序)`:SiteSourceGrouper
- `接口(其实是抽象类)`:HNWebPage
- `依赖关系`:调用接口方法:`get_text()` 获取页面文本
在 I 原则看来,**一个接口所提供的方法,应该就是使用方所需要的方法,不多不少刚刚好。** 所以,在上个例子里,我们设计的接口 `HNWebPage` 是符合接口隔离原则的。因为它没有向使用方提供任何后者不需要的方法 。
> 你需要 get_text()!我提供 get_text()!刚刚好!
所以,这条原则看上去似乎很容易遵守。既然如此,让我们试试来违反它吧!
### 例子:开发页面归档功能
让我们接着上一个例子开始。在实现了上个需求后,我现在有一个代表 Hacker News 站点页面的抽象类 `HNWebPage`,它只提供了一种行为,就是获取当前页面的文本内容。
```python
class HNWebPage(metaclass=ABCMeta):
@abstractmethod
def get_text(self) -> str:
"""获取页面文本内容"""
```
现在,假设我要开发一个和 HN 页面有关的新功能: **我想在不同时间点对 HN 首页内容进行归档,观察热点新闻在不同时间点发生的变化。** 所以除了页面文本内容外,我还需要拿到页面的大小、生成时间这些额外信息,然后将它们都保存到数据库中。
为了做到这一点,现在的 `HNWebPage` 类需要被扩展一下:
```python
class HNWebPage(metaclass=ABCMeta):
@abstractmethod
def get_text(self) -> str:
"""获取页面文本内容"""
# 新增 get_size 与 get_generated_at
@abstractmethod
def get_size(self) -> int:
"""获取页面大小"""
@abstractmethod
def get_generated_at(self) -> datetime.datetime:
"""获取页面生成时间"""
```
我在原来的类上增加了两个新的抽象方法:`get_size` 和 `get_generated_at`。这样归档程序就能通过它们拿到页面大小和生成时间了。
改完抽象类后,紧接着的任务就是修改依赖它的实体类。
### 问题:实体类不符合 HNWebPage 接口规范
在修改抽象类前,我们有两个实现了它协议的实体类:`RemoteHNWebPage` 和 `LocalHNWebPage`。如今,`HNWebPage` 增加了两个新方法 `get_size` 和 `get_generated_at`。我们自然需要把这两个实体类也加上这两个方法。
`RemoteHNWebPage` 类的修改很好做,我们只要让 `get_size` 放回页面长度,让 `get_generated_at` 返回当前时间就行了。
```python
# class RemoteHNWebPage:
#
def get_generated_at(self) -> datetime.datetime:
# 页面生成时间等同于通过 requests 请求的时间
return datetime.datetime.now()
```
但是,在给 `LocalHNWebPage` 添加 `get_generated_at` 方法时,我碰到了一个问题。`LocalHNWebPage` 是一个完全基于本地页面文件作为数据来源的类,仅仅通过 “static_hn.html” 这么一个本地文件,我根本就没法知道它的内容是什么时候生成的。
这时我只能选择让它的 `get_generated_at` 方法返回一个错误的结果 *(比如文件的修改时间)*,或者直接抛出异常。无论是哪种做法,我都可能违反 [里式替换原则](https://www.piglei.com/articles/write-solid-python-codes-part-2/)。
> Hint:里式替换原则认为子类(派生类)对象应该可以在程序中替代父类(基类)对象使用,而不破坏程序原本的功能。让方法抛出异常显然破坏了这一点。
```python
# class LocalHNWebPage:
#
def get_generated_at(self) -> datetime.datetime:
raise NotImplementedError("local web page can not provide generate_at info")
```
所以,对现有接口的盲目扩展暴露出来一个问题:**更多的接口方法意味着更高的实现成本,给实现方带来麻烦的概率也变高了。**
不过现在让我们暂且把这个问题放到一边,继续写一个 `SiteAchiever` 类完成归档任务:
```python
class SiteAchiever:
"""将不同时间点的 HN 页面归档"""
def save_page(self, page: HNWebPage):
"""将页面保存到后端数据库
"""
data = {
"content": page.get_text(),
"generated_at": page.get_generated_at(),
"size": page.get_size(),
}
# 将 data 保存到数据库中
```
### 成功违反 I 协议
代码写到这,让我们回头看看上个例子里的 *条目来源分组类 `SiteSourceGrouper`* 。

 图:Hacker News 条目来源截图
图:Hacker News 条目来源截图
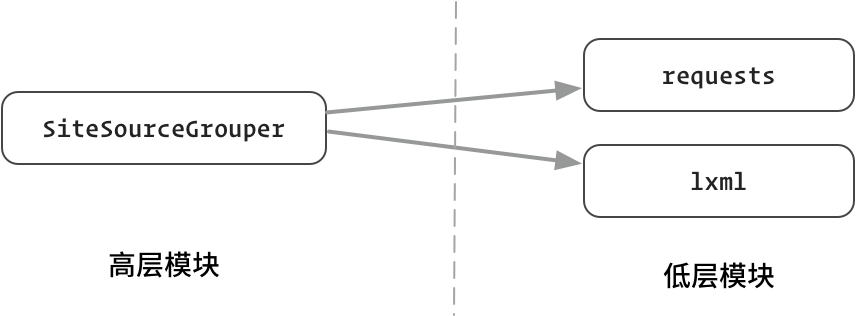 图:SiteSourceGrouper 依赖 requests、lxml
图:SiteSourceGrouper 依赖 requests、lxml
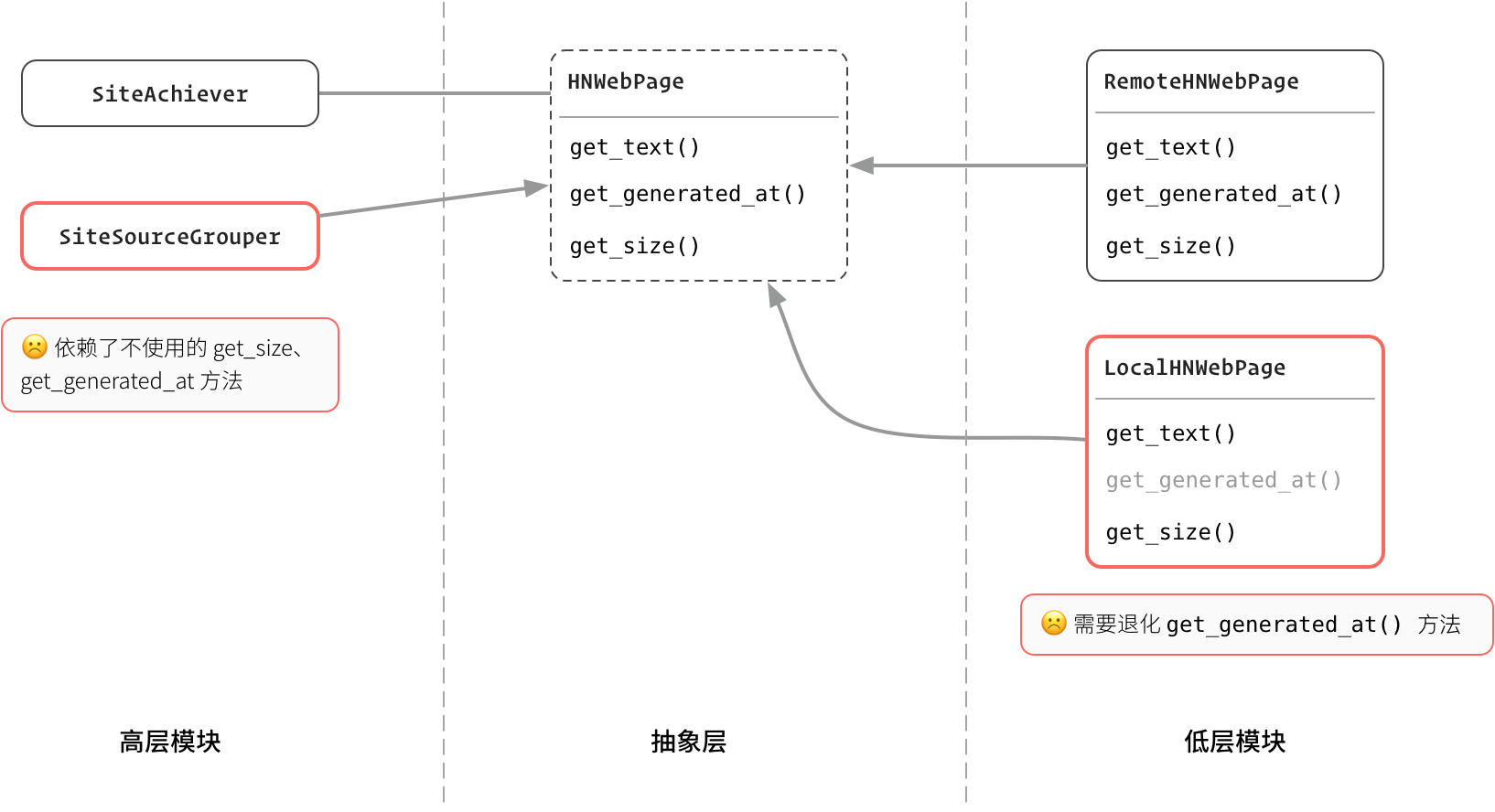 图:成功违反了 I 协议
图:成功违反了 I 协议
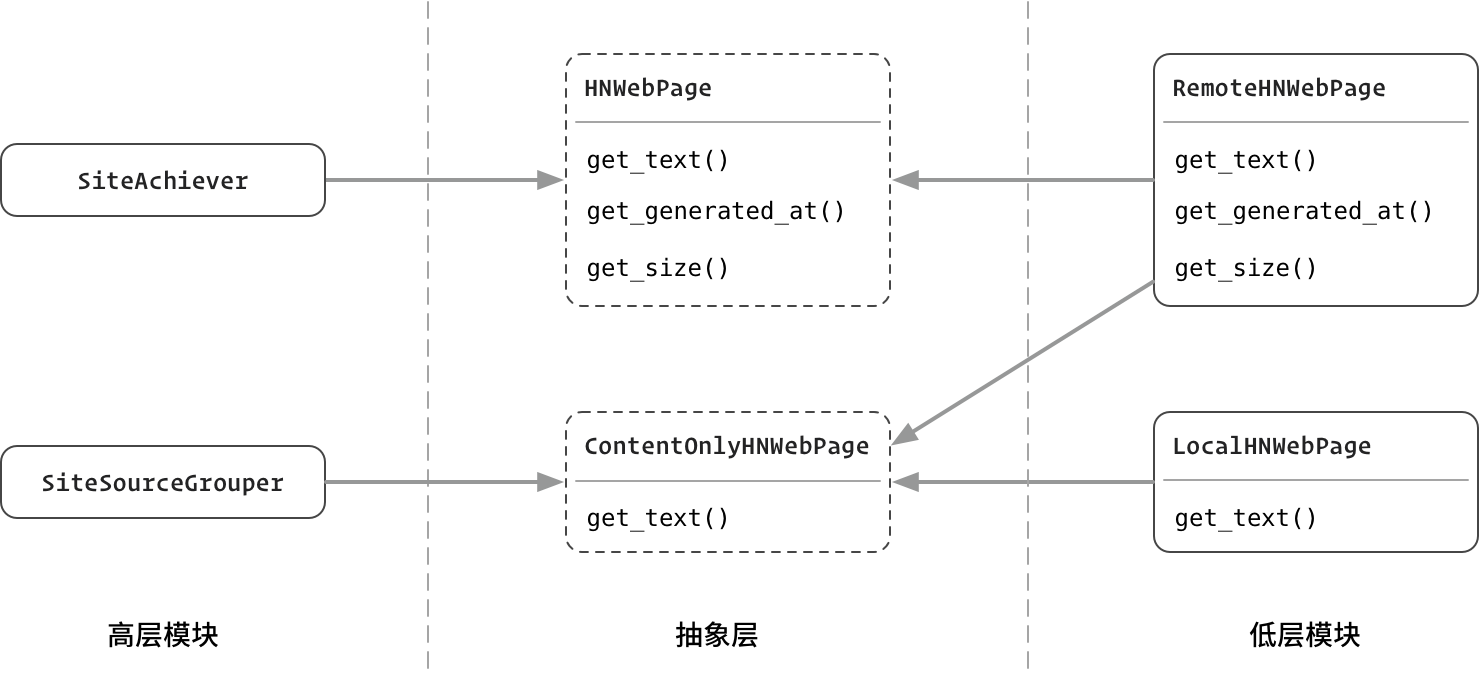 图:实施接口隔离后的结果
图:实施接口隔离后的结果