Merge branch 'master' of github.com:apachecn/AiLearning
This commit is contained in:
commit
92f66a0856
|
|
@ -0,0 +1,4 @@
|
|||
---
|
||||
permalink: /404.html
|
||||
---
|
||||
<script>window.location.href = '/';</script>
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
FROM httpd:2.4
|
||||
COPY ./ /usr/local/apache2/htdocs/
|
||||
775
LICENSE
775
LICENSE
|
|
@ -1,674 +1,101 @@
|
|||
GNU GENERAL PUBLIC LICENSE
|
||||
Version 3, 29 June 2007
|
||||
|
||||
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
|
||||
Everyone is permitted to copy and distribute verbatim copies
|
||||
of this license document, but changing it is not allowed.
|
||||
|
||||
Preamble
|
||||
|
||||
The GNU General Public License is a free, copyleft license for
|
||||
software and other kinds of works.
|
||||
|
||||
The licenses for most software and other practical works are designed
|
||||
to take away your freedom to share and change the works. By contrast,
|
||||
the GNU General Public License is intended to guarantee your freedom to
|
||||
share and change all versions of a program--to make sure it remains free
|
||||
software for all its users. We, the Free Software Foundation, use the
|
||||
GNU General Public License for most of our software; it applies also to
|
||||
any other work released this way by its authors. You can apply it to
|
||||
your programs, too.
|
||||
|
||||
When we speak of free software, we are referring to freedom, not
|
||||
price. Our General Public Licenses are designed to make sure that you
|
||||
have the freedom to distribute copies of free software (and charge for
|
||||
them if you wish), that you receive source code or can get it if you
|
||||
want it, that you can change the software or use pieces of it in new
|
||||
free programs, and that you know you can do these things.
|
||||
|
||||
To protect your rights, we need to prevent others from denying you
|
||||
these rights or asking you to surrender the rights. Therefore, you have
|
||||
certain responsibilities if you distribute copies of the software, or if
|
||||
you modify it: responsibilities to respect the freedom of others.
|
||||
|
||||
For example, if you distribute copies of such a program, whether
|
||||
gratis or for a fee, you must pass on to the recipients the same
|
||||
freedoms that you received. You must make sure that they, too, receive
|
||||
or can get the source code. And you must show them these terms so they
|
||||
know their rights.
|
||||
|
||||
Developers that use the GNU GPL protect your rights with two steps:
|
||||
(1) assert copyright on the software, and (2) offer you this License
|
||||
giving you legal permission to copy, distribute and/or modify it.
|
||||
|
||||
For the developers' and authors' protection, the GPL clearly explains
|
||||
that there is no warranty for this free software. For both users' and
|
||||
authors' sake, the GPL requires that modified versions be marked as
|
||||
changed, so that their problems will not be attributed erroneously to
|
||||
authors of previous versions.
|
||||
|
||||
Some devices are designed to deny users access to install or run
|
||||
modified versions of the software inside them, although the manufacturer
|
||||
can do so. This is fundamentally incompatible with the aim of
|
||||
protecting users' freedom to change the software. The systematic
|
||||
pattern of such abuse occurs in the area of products for individuals to
|
||||
use, which is precisely where it is most unacceptable. Therefore, we
|
||||
have designed this version of the GPL to prohibit the practice for those
|
||||
products. If such problems arise substantially in other domains, we
|
||||
stand ready to extend this provision to those domains in future versions
|
||||
of the GPL, as needed to protect the freedom of users.
|
||||
|
||||
Finally, every program is threatened constantly by software patents.
|
||||
States should not allow patents to restrict development and use of
|
||||
software on general-purpose computers, but in those that do, we wish to
|
||||
avoid the special danger that patents applied to a free program could
|
||||
make it effectively proprietary. To prevent this, the GPL assures that
|
||||
patents cannot be used to render the program non-free.
|
||||
|
||||
The precise terms and conditions for copying, distribution and
|
||||
modification follow.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
"This License" refers to version 3 of the GNU General Public License.
|
||||
|
||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
"The Program" refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as "you". "Licensees" and
|
||||
"recipients" may be individuals or organizations.
|
||||
|
||||
To "modify" a work means to copy from or adapt all or part of the work
|
||||
in a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a "modified version" of the
|
||||
earlier work or a work "based on" the earlier work.
|
||||
|
||||
A "covered work" means either the unmodified Program or a work based
|
||||
on the Program.
|
||||
|
||||
To "propagate" a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To "convey" a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through
|
||||
a computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays "Appropriate Legal Notices"
|
||||
to the extent that it includes a convenient and prominently visible
|
||||
feature that (1) displays an appropriate copyright notice, and (2)
|
||||
tells the user that there is no warranty for the work (except to the
|
||||
extent that warranties are provided), that licensees may convey the
|
||||
work under this License, and how to view a copy of this License. If
|
||||
the interface presents a list of user commands or options, such as a
|
||||
menu, a prominent item in the list meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The "source code" for a work means the preferred form of the work
|
||||
for making modifications to it. "Object code" means any non-source
|
||||
form of a work.
|
||||
|
||||
A "Standard Interface" means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that
|
||||
is widely used among developers working in that language.
|
||||
|
||||
The "System Libraries" of an executable work include anything, other
|
||||
than the work as a whole, that (a) is included in the normal form of
|
||||
packaging a Major Component, but which is not part of that Major
|
||||
Component, and (b) serves only to enable use of the work with that
|
||||
Major Component, or to implement a Standard Interface for which an
|
||||
implementation is available to the public in source code form. A
|
||||
"Major Component", in this context, means a major essential component
|
||||
(kernel, window system, and so on) of the specific operating system
|
||||
(if any) on which the executable work runs, or a compiler used to
|
||||
produce the work, or an object code interpreter used to run it.
|
||||
|
||||
The "Corresponding Source" for a work in object code form means all
|
||||
the source code needed to generate, install, and (for an executable
|
||||
work) run the object code and to modify the work, including scripts to
|
||||
control those activities. However, it does not include the work's
|
||||
System Libraries, or general-purpose tools or generally available free
|
||||
programs which are used unmodified in performing those activities but
|
||||
which are not part of the work. For example, Corresponding Source
|
||||
includes interface definition files associated with source files for
|
||||
the work, and the source code for shared libraries and dynamically
|
||||
linked subprograms that the work is specifically designed to require,
|
||||
such as by intimate data communication or control flow between those
|
||||
subprograms and other parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users
|
||||
can regenerate automatically from other parts of the Corresponding
|
||||
Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that
|
||||
same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program. The output from running a
|
||||
covered work is covered by this License only if the output, given its
|
||||
content, constitutes a covered work. This License acknowledges your
|
||||
rights of fair use or other equivalent, as provided by copyright law.
|
||||
|
||||
You may make, run and propagate covered works that you do not
|
||||
convey, without conditions so long as your license otherwise remains
|
||||
in force. You may convey covered works to others for the sole purpose
|
||||
of having them make modifications exclusively for you, or provide you
|
||||
with facilities for running those works, provided that you comply with
|
||||
the terms of this License in conveying all material for which you do
|
||||
not control copyright. Those thus making or running the covered works
|
||||
for you must do so exclusively on your behalf, under your direction
|
||||
and control, on terms that prohibit them from making any copies of
|
||||
your copyrighted material outside their relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under
|
||||
the conditions stated below. Sublicensing is not allowed; section 10
|
||||
makes it unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article
|
||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||
similar laws prohibiting or restricting circumvention of such
|
||||
measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention
|
||||
is effected by exercising rights under this License with respect to
|
||||
the covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's
|
||||
users, your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice;
|
||||
keep intact all notices stating that this License and any
|
||||
non-permissive terms added in accord with section 7 apply to the code;
|
||||
keep intact all notices of the absence of any warranty; and give all
|
||||
recipients a copy of this License along with the Program.
|
||||
|
||||
You may charge any price or no price for each copy that you convey,
|
||||
and you may offer support or warranty protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the
|
||||
terms of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified
|
||||
it, and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is
|
||||
released under this License and any conditions added under section
|
||||
7. This requirement modifies the requirement in section 4 to
|
||||
"keep intact all notices".
|
||||
|
||||
c) You must license the entire work, as a whole, under this
|
||||
License to anyone who comes into possession of a copy. This
|
||||
License will therefore apply, along with any applicable section 7
|
||||
additional terms, to the whole of the work, and all its parts,
|
||||
regardless of how they are packaged. This License gives no
|
||||
permission to license the work in any other way, but it does not
|
||||
invalidate such permission if you have separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your
|
||||
work need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work,
|
||||
and which are not combined with it such as to form a larger program,
|
||||
in or on a volume of a storage or distribution medium, is called an
|
||||
"aggregate" if the compilation and its resulting copyright are not
|
||||
used to limit the access or legal rights of the compilation's users
|
||||
beyond what the individual works permit. Inclusion of a covered work
|
||||
in an aggregate does not cause this License to apply to the other
|
||||
parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms
|
||||
of sections 4 and 5, provided that you also convey the
|
||||
machine-readable Corresponding Source under the terms of this License,
|
||||
in one of these ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium
|
||||
customarily used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a
|
||||
written offer, valid for at least three years and valid for as
|
||||
long as you offer spare parts or customer support for that product
|
||||
model, to give anyone who possesses the object code either (1) a
|
||||
copy of the Corresponding Source for all the software in the
|
||||
product that is covered by this License, on a durable physical
|
||||
medium customarily used for software interchange, for a price no
|
||||
more than your reasonable cost of physically performing this
|
||||
conveying of source, or (2) access to copy the
|
||||
Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This
|
||||
alternative is allowed only occasionally and noncommercially, and
|
||||
only if you received the object code with such an offer, in accord
|
||||
with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated
|
||||
place (gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to
|
||||
copy the object code is a network server, the Corresponding Source
|
||||
may be on a different server (operated by you or a third party)
|
||||
that supports equivalent copying facilities, provided you maintain
|
||||
clear directions next to the object code saying where to find the
|
||||
Corresponding Source. Regardless of what server hosts the
|
||||
Corresponding Source, you remain obligated to ensure that it is
|
||||
available for as long as needed to satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided
|
||||
you inform other peers where the object code and Corresponding
|
||||
Source of the work are being offered to the general public at no
|
||||
charge under subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be
|
||||
included in conveying the object code work.
|
||||
|
||||
A "User Product" is either (1) a "consumer product", which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, "normally used" refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
"Installation Information" for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as
|
||||
part of a transaction in which the right of possession and use of the
|
||||
User Product is transferred to the recipient in perpetuity or for a
|
||||
fixed term (regardless of how the transaction is characterized), the
|
||||
Corresponding Source conveyed under this section must be accompanied
|
||||
by the Installation Information. But this requirement does not apply
|
||||
if neither you nor any third party retains the ability to install
|
||||
modified object code on the User Product (for example, the work has
|
||||
been installed in ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access to a
|
||||
network may be denied when the modification itself materially and
|
||||
adversely affects the operation of the network or violates the rules and
|
||||
protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided,
|
||||
in accord with this section must be in a format that is publicly
|
||||
documented (and with an implementation available to the public in
|
||||
source code form), and must require no special password or key for
|
||||
unpacking, reading or copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
"Additional permissions" are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall
|
||||
be treated as though they were included in this License, to the extent
|
||||
that they are valid under applicable law. If additional permissions
|
||||
apply only to part of the Program, that part may be used separately
|
||||
under those permissions, but the entire Program remains governed by
|
||||
this License without regard to the additional permissions.
|
||||
|
||||
When you convey a copy of a covered work, you may at your option
|
||||
remove any additional permissions from that copy, or from any part of
|
||||
it. (Additional permissions may be written to require their own
|
||||
removal in certain cases when you modify the work.) You may place
|
||||
additional permissions on material, added by you to a covered work,
|
||||
for which you have or can give appropriate copyright permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you
|
||||
add to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some
|
||||
trade names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that
|
||||
material by anyone who conveys the material (or modified versions of
|
||||
it) with contractual assumptions of liability to the recipient, for
|
||||
any liability that these contractual assumptions directly impose on
|
||||
those licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered "further
|
||||
restrictions" within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further
|
||||
restriction, you may remove that term. If a license document contains
|
||||
a further restriction but permits relicensing or conveying under this
|
||||
License, you may add to a covered work material governed by the terms
|
||||
of that license document, provided that the further restriction does
|
||||
not survive such relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you
|
||||
must place, in the relevant source files, a statement of the
|
||||
additional terms that apply to those files, or a notice indicating
|
||||
where to find the applicable terms.
|
||||
|
||||
Additional terms, permissive or non-permissive, may be stated in the
|
||||
form of a separately written license, or stated as exceptions;
|
||||
the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or
|
||||
modify it is void, and will automatically terminate your rights under
|
||||
this License (including any patent licenses granted under the third
|
||||
paragraph of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your
|
||||
license from a particular copyright holder is reinstated (a)
|
||||
provisionally, unless and until the copyright holder explicitly and
|
||||
finally terminates your license, and (b) permanently, if the copyright
|
||||
holder fails to notify you of the violation by some reasonable means
|
||||
prior to 60 days after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is
|
||||
reinstated permanently if the copyright holder notifies you of the
|
||||
violation by some reasonable means, this is the first time you have
|
||||
received notice of violation of this License (for any work) from that
|
||||
copyright holder, and you cure the violation prior to 30 days after
|
||||
your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or
|
||||
run a copy of the Program. Ancillary propagation of a covered work
|
||||
occurring solely as a consequence of using peer-to-peer transmission
|
||||
to receive a copy likewise does not require acceptance. However,
|
||||
nothing other than this License grants you permission to propagate or
|
||||
modify any covered work. These actions infringe copyright if you do
|
||||
not accept this License. Therefore, by modifying or propagating a
|
||||
covered work, you indicate your acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically
|
||||
receives a license from the original licensors, to run, modify and
|
||||
propagate that work, subject to this License. You are not responsible
|
||||
for enforcing compliance by third parties with this License.
|
||||
|
||||
An "entity transaction" is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered
|
||||
work results from an entity transaction, each party to that
|
||||
transaction who receives a copy of the work also receives whatever
|
||||
licenses to the work the party's predecessor in interest had or could
|
||||
give under the previous paragraph, plus a right to possession of the
|
||||
Corresponding Source of the work from the predecessor in interest, if
|
||||
the predecessor has it or can get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the
|
||||
rights granted or affirmed under this License. For example, you may
|
||||
not impose a license fee, royalty, or other charge for exercise of
|
||||
rights granted under this License, and you may not initiate litigation
|
||||
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||
any patent claim is infringed by making, using, selling, offering for
|
||||
sale, or importing the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A "contributor" is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The
|
||||
work thus licensed is called the contributor's "contributor version".
|
||||
|
||||
A contributor's "essential patent claims" are all patent claims
|
||||
owned or controlled by the contributor, whether already acquired or
|
||||
hereafter acquired, that would be infringed by some manner, permitted
|
||||
by this License, of making, using, or selling its contributor version,
|
||||
but do not include claims that would be infringed only as a
|
||||
consequence of further modification of the contributor version. For
|
||||
purposes of this definition, "control" includes the right to grant
|
||||
patent sublicenses in a manner consistent with the requirements of
|
||||
this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to
|
||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||
propagate the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a "patent license" is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To "grant" such a patent license to a
|
||||
party means to make such an agreement or commitment not to enforce a
|
||||
patent against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license,
|
||||
and the Corresponding Source of the work is not available for anyone
|
||||
to copy, free of charge and under the terms of this License, through a
|
||||
publicly available network server or other readily accessible means,
|
||||
then you must either (1) cause the Corresponding Source to be so
|
||||
available, or (2) arrange to deprive yourself of the benefit of the
|
||||
patent license for this particular work, or (3) arrange, in a manner
|
||||
consistent with the requirements of this License, to extend the patent
|
||||
license to downstream recipients. "Knowingly relying" means you have
|
||||
actual knowledge that, but for the patent license, your conveying the
|
||||
covered work in a country, or your recipient's use of the covered work
|
||||
in a country, would infringe one or more identifiable patents in that
|
||||
country that you have reason to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties
|
||||
receiving the covered work authorizing them to use, propagate, modify
|
||||
or convey a specific copy of the covered work, then the patent license
|
||||
you grant is automatically extended to all recipients of the covered
|
||||
work and works based on it.
|
||||
|
||||
A patent license is "discriminatory" if it does not include within
|
||||
the scope of its coverage, prohibits the exercise of, or is
|
||||
conditioned on the non-exercise of one or more of the rights that are
|
||||
specifically granted under this License. You may not convey a covered
|
||||
work if you are a party to an arrangement with a third party that is
|
||||
in the business of distributing software, under which you make payment
|
||||
to the third party based on the extent of your activity of conveying
|
||||
the work, and under which the third party grants, to any of the
|
||||
parties who would receive the covered work from you, a discriminatory
|
||||
patent license (a) in connection with copies of the covered work
|
||||
conveyed by you (or copies made from those copies), or (b) primarily
|
||||
for and in connection with specific products or compilations that
|
||||
contain the covered work, unless you entered into that arrangement,
|
||||
or that patent license was granted, prior to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting
|
||||
any implied license or other defenses to infringement that may
|
||||
otherwise be available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot convey a
|
||||
covered work so as to satisfy simultaneously your obligations under this
|
||||
License and any other pertinent obligations, then as a consequence you may
|
||||
not convey it at all. For example, if you agree to terms that obligate you
|
||||
to collect a royalty for further conveying from those to whom you convey
|
||||
the Program, the only way you could satisfy both those terms and this
|
||||
License would be to refrain entirely from conveying the Program.
|
||||
|
||||
13. Use with the GNU Affero General Public License.
|
||||
|
||||
Notwithstanding any other provision of this License, you have
|
||||
permission to link or combine any covered work with a work licensed
|
||||
under version 3 of the GNU Affero General Public License into a single
|
||||
combined work, and to convey the resulting work. The terms of this
|
||||
License will continue to apply to the part which is the covered work,
|
||||
but the special requirements of the GNU Affero General Public License,
|
||||
section 13, concerning interaction through a network will apply to the
|
||||
combination as such.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
The Free Software Foundation may publish revised and/or new versions of
|
||||
the GNU General Public License from time to time. Such new versions will
|
||||
be similar in spirit to the present version, but may differ in detail to
|
||||
address new problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the
|
||||
Program specifies that a certain numbered version of the GNU General
|
||||
Public License "or any later version" applies to it, you have the
|
||||
option of following the terms and conditions either of that numbered
|
||||
version or of any later version published by the Free Software
|
||||
Foundation. If the Program does not specify a version number of the
|
||||
GNU General Public License, you may choose any version ever published
|
||||
by the Free Software Foundation.
|
||||
|
||||
If the Program specifies that a proxy can decide which future
|
||||
versions of the GNU General Public License can be used, that proxy's
|
||||
public statement of acceptance of a version permanently authorizes you
|
||||
to choose that version for the Program.
|
||||
|
||||
Later license versions may give you additional or different
|
||||
permissions. However, no additional obligations are imposed on any
|
||||
author or copyright holder as a result of your choosing to follow a
|
||||
later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||
SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided
|
||||
above cannot be given local legal effect according to their terms,
|
||||
reviewing courts shall apply local law that most closely approximates
|
||||
an absolute waiver of all civil liability in connection with the
|
||||
Program, unless a warranty or assumption of liability accompanies a
|
||||
copy of the Program in return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
How to Apply These Terms to Your New Programs
|
||||
|
||||
If you develop a new program, and you want it to be of the greatest
|
||||
possible use to the public, the best way to achieve this is to make it
|
||||
free software which everyone can redistribute and change under these terms.
|
||||
|
||||
To do so, attach the following notices to the program. It is safest
|
||||
to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
{one line to give the program's name and a brief idea of what it does.}
|
||||
Copyright (C) {year} {name of author}
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU General Public License as published by
|
||||
the Free Software Foundation, either version 3 of the License, or
|
||||
(at your option) any later version.
|
||||
|
||||
This program is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
GNU General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License
|
||||
along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
|
||||
Also add information on how to contact you by electronic and paper mail.
|
||||
|
||||
If the program does terminal interaction, make it output a short
|
||||
notice like this when it starts in an interactive mode:
|
||||
|
||||
{project} Copyright (C) {year} {fullname}
|
||||
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
||||
This is free software, and you are welcome to redistribute it
|
||||
under certain conditions; type `show c' for details.
|
||||
|
||||
The hypothetical commands `show w' and `show c' should show the appropriate
|
||||
parts of the General Public License. Of course, your program's commands
|
||||
might be different; for a GUI interface, you would use an "about box".
|
||||
|
||||
You should also get your employer (if you work as a programmer) or school,
|
||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||
For more information on this, and how to apply and follow the GNU GPL, see
|
||||
<http://www.gnu.org/licenses/>.
|
||||
|
||||
The GNU General Public License does not permit incorporating your program
|
||||
into proprietary programs. If your program is a subroutine library, you
|
||||
may consider it more useful to permit linking proprietary applications with
|
||||
the library. If this is what you want to do, use the GNU Lesser General
|
||||
Public License instead of this License. But first, please read
|
||||
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
|
||||
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License (CC BY-NC-SA 4.0)
|
||||
|
||||
Copyright © 2020 ApacheCN(apachecn@163.com)
|
||||
|
||||
By exercising the Licensed Rights (defined below), You accept and agree to be bound by the terms and conditions of this Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License ("Public License"). To the extent this Public License may be interpreted as a contract, You are granted the Licensed Rights in consideration of Your acceptance of these terms and conditions, and the Licensor grants You such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.
|
||||
|
||||
Section 1 – Definitions.
|
||||
|
||||
a. Adapted Material means material subject to Copyright and Similar Rights that is derived from or based upon the Licensed Material and in which the Licensed Material is translated, altered, arranged, transformed, or otherwise modified in a manner requiring permission under the Copyright and Similar Rights held by the Licensor. For purposes of this Public License, where the Licensed Material is a musical work, performance, or sound recording, Adapted Material is always produced where the Licensed Material is synched in timed relation with a moving image.
|
||||
b. Adapter's License means the license You apply to Your Copyright and Similar Rights in Your contributions to Adapted Material in accordance with the terms and conditions of this Public License.
|
||||
c. BY-NC-SA Compatible License means a license listed at creativecommons.org/compatiblelicenses, approved by Creative Commons as essentially the equivalent of this Public License.
|
||||
d. Copyright and Similar Rights means copyright and/or similar rights closely related to copyright including, without limitation, performance, broadcast, sound recording, and Sui Generis Database Rights, without regard to how the rights are labeled or categorized. For purposes of this Public License, the rights specified in Section 2(b)(1)-(2) are not Copyright and Similar Rights.
|
||||
e. Effective Technological Measures means those measures that, in the absence of proper authority, may not be circumvented under laws fulfilling obligations under Article 11 of the WIPO Copyright Treaty adopted on December 20, 1996, and/or similar international agreements.
|
||||
f. Exceptions and Limitations means fair use, fair dealing, and/or any other exception or limitation to Copyright and Similar Rights that applies to Your use of the Licensed Material.
|
||||
g. License Elements means the license attributes listed in the name of a Creative Commons Public License. The License Elements of this Public License are Attribution, NonCommercial, and ShareAlike.
|
||||
h. Licensed Material means the artistic or literary work, database, or other material to which the Licensor applied this Public License.
|
||||
i. Licensed Rights means the rights granted to You subject to the terms and conditions of this Public License, which are limited to all Copyright and Similar Rights that apply to Your use of the Licensed Material and that the Licensor has authority to license.
|
||||
j. Licensor means the individual(s) or entity(ies) granting rights under this Public License.
|
||||
k. NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation. For purposes of this Public License, the exchange of the Licensed Material for other material subject to Copyright and Similar Rights by digital file-sharing or similar means is NonCommercial provided there is no payment of monetary compensation in connection with the exchange.
|
||||
l. Share means to provide material to the public by any means or process that requires permission under the Licensed Rights, such as reproduction, public display, public performance, distribution, dissemination, communication, or importation, and to make material available to the public including in ways that members of the public may access the material from a place and at a time individually chosen by them.
|
||||
m. Sui Generis Database Rights means rights other than copyright resulting from Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases, as amended and/or succeeded, as well as other essentially equivalent rights anywhere in the world.
|
||||
n. You means the individual or entity exercising the Licensed Rights under this Public License. Your has a corresponding meaning.
|
||||
|
||||
Section 2 – Scope.
|
||||
|
||||
a. License grant.
|
||||
1. Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
|
||||
A. reproduce and Share the Licensed Material, in whole or in part, for NonCommercial purposes only; and
|
||||
B. produce, reproduce, and Share Adapted Material for NonCommercial purposes only.
|
||||
2. Exceptions and Limitations. For the avoidance of doubt, where Exceptions and Limitations apply to Your use, this Public License does not apply, and You do not need to comply with its terms and conditions.
|
||||
3. Term. The term of this Public License is specified in Section 6(a).
|
||||
4. Media and formats; technical modifications allowed. The Licensor authorizes You to exercise the Licensed Rights in all media and formats whether now known or hereafter created, and to make technical modifications necessary to do so. The Licensor waives and/or agrees not to assert any right or authority to forbid You from making technical modifications necessary to exercise the Licensed Rights, including technical modifications necessary to circumvent Effective Technological Measures. For purposes of this Public License, simply making modifications authorized by this Section 2(a)(4) never produces Adapted Material.
|
||||
5. Downstream recipients.
|
||||
A. Offer from the Licensor – Licensed Material. Every recipient of the Licensed Material automatically receives an offer from the Licensor to exercise the Licensed Rights under the terms and conditions of this Public License.
|
||||
B. Additional offer from the Licensor – Adapted Material. Every recipient of Adapted Material from You automatically receives an offer from the Licensor to exercise the Licensed Rights in the Adapted Material under the conditions of the Adapter’s License You apply.
|
||||
C. No downstream restrictions. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, the Licensed Material if doing so restricts exercise of the Licensed Rights by any recipient of the Licensed Material.
|
||||
6. No endorsement. Nothing in this Public License constitutes or may be construed as permission to assert or imply that You are, or that Your use of the Licensed Material is, connected with, or sponsored, endorsed, or granted official status by, the Licensor or others designated to receive attribution as provided in Section 3(a)(1)(A)(i).
|
||||
b. Other rights.
|
||||
1. Moral rights, such as the right of integrity, are not licensed under this Public License, nor are publicity, privacy, and/or other similar personality rights; however, to the extent possible, the Licensor waives and/or agrees not to assert any such rights held by the Licensor to the limited extent necessary to allow You to exercise the Licensed Rights, but not otherwise.
|
||||
2. Patent and trademark rights are not licensed under this Public License.
|
||||
3. To the extent possible, the Licensor waives any right to collect royalties from You for the exercise of the Licensed Rights, whether directly or through a collecting society under any voluntary or waivable statutory or compulsory licensing scheme. In all other cases the Licensor expressly reserves any right to collect such royalties, including when the Licensed Material is used other than for NonCommercial purposes.
|
||||
|
||||
Section 3 – License Conditions.
|
||||
|
||||
Your exercise of the Licensed Rights is expressly made subject to the following conditions.
|
||||
|
||||
a. Attribution.
|
||||
1. If You Share the Licensed Material (including in modified form), You must:
|
||||
A. retain the following if it is supplied by the Licensor with the Licensed Material:
|
||||
i. identification of the creator(s) of the Licensed Material and any others designated to receive attribution, in any reasonable manner requested by the Licensor (including by pseudonym if designated);
|
||||
ii. a copyright notice;
|
||||
iii. a notice that refers to this Public License;
|
||||
iv. a notice that refers to the disclaimer of warranties;
|
||||
v. a URI or hyperlink to the Licensed Material to the extent reasonably practicable;
|
||||
B. indicate if You modified the Licensed Material and retain an indication of any previous modifications; and
|
||||
C. indicate the Licensed Material is licensed under this Public License, and include the text of, or the URI or hyperlink to, this Public License.
|
||||
2. You may satisfy the conditions in Section 3(a)(1) in any reasonable manner based on the medium, means, and context in which You Share the Licensed Material. For example, it may be reasonable to satisfy the conditions by providing a URI or hyperlink to a resource that includes the required information.
|
||||
3. If requested by the Licensor, You must remove any of the information required by Section 3(a)(1)(A) to the extent reasonably practicable.
|
||||
b. ShareAlike.
|
||||
In addition to the conditions in Section 3(a), if You Share Adapted Material You produce, the following conditions also apply.
|
||||
1. The Adapter’s License You apply must be a Creative Commons license with the same License Elements, this version or later, or a BY-NC-SA Compatible License.
|
||||
2. You must include the text of, or the URI or hyperlink to, the Adapter's License You apply. You may satisfy this condition in any reasonable manner based on the medium, means, and context in which You Share Adapted Material.
|
||||
3. You may not offer or impose any additional or different terms or conditions on, or apply any Effective Technological Measures to, Adapted Material that restrict exercise of the rights granted under the Adapter's License You apply.
|
||||
|
||||
Section 4 – Sui Generis Database Rights.
|
||||
|
||||
Where the Licensed Rights include Sui Generis Database Rights that apply to Your use of the Licensed Material:
|
||||
|
||||
a. for the avoidance of doubt, Section 2(a)(1) grants You the right to extract, reuse, reproduce, and Share all or a substantial portion of the contents of the database for NonCommercial purposes only;
|
||||
b. if You include all or a substantial portion of the database contents in a database in which You have Sui Generis Database Rights, then the database in which You have Sui Generis Database Rights (but not its individual contents) is Adapted Material, including for purposes of Section 3(b); and
|
||||
c. You must comply with the conditions in Section 3(a) if You Share all or a substantial portion of the contents of the database.
|
||||
|
||||
For the avoidance of doubt, this Section 4 supplements and does not replace Your obligations under this Public License where the Licensed Rights include other Copyright and Similar Rights.
|
||||
|
||||
Section 5 – Disclaimer of Warranties and Limitation of Liability.
|
||||
|
||||
a. Unless otherwise separately undertaken by the Licensor, to the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
|
||||
b. To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
|
||||
c. The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
|
||||
|
||||
Section 6 – Term and Termination.
|
||||
|
||||
a. This Public License applies for the term of the Copyright and Similar Rights licensed here. However, if You fail to comply with this Public License, then Your rights under this Public License terminate automatically.
|
||||
b. Where Your right to use the Licensed Material has terminated under Section 6(a), it reinstates:
|
||||
1. automatically as of the date the violation is cured, provided it is cured within 30 days of Your discovery of the violation; or
|
||||
2. upon express reinstatement by the Licensor.
|
||||
For the avoidance of doubt, this Section 6(b) does not affect any right the Licensor may have to seek remedies for Your violations of this Public License.
|
||||
c. For the avoidance of doubt, the Licensor may also offer the Licensed Material under separate terms or conditions or stop distributing the Licensed Material at any time; however, doing so will not terminate this Public License.
|
||||
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public License.
|
||||
|
||||
Section 7 – Other Terms and Conditions.
|
||||
|
||||
a. The Licensor shall not be bound by any additional or different terms or conditions communicated by You unless expressly agreed.
|
||||
b. Any arrangements, understandings, or agreements regarding the Licensed Material not stated herein are separate from and independent of the terms and conditions of this Public License.
|
||||
|
||||
Section 8 – Interpretation.
|
||||
|
||||
a. For the avoidance of doubt, this Public License does not, and shall not be interpreted to, reduce, limit, restrict, or impose conditions on any use of the Licensed Material that could lawfully be made without permission under this Public License.
|
||||
b. To the extent possible, if any provision of this Public License is deemed unenforceable, it shall be automatically reformed to the minimum extent necessary to make it enforceable. If the provision cannot be reformed, it shall be severed from this Public License without affecting the enforceability of the remaining terms and conditions.
|
||||
c. No term or condition of this Public License will be waived and no failure to comply consented to unless expressly agreed to by the Licensor.
|
||||
d. Nothing in this Public License constitutes or may be interpreted as a limitation upon, or waiver of, any privileges and immunities that apply to the Licensor or You, including from the legal processes of any jurisdiction or authority.
|
||||
219
README.md
219
README.md
|
|
@ -1,6 +1,6 @@
|
|||
<p align="center">
|
||||
<a href="https://www.apachecn.org">
|
||||
<img width="200" src="http://data.apachecn.org/img/logo.jpg">
|
||||
<img width="200" src="docs/img/logo.jpg">
|
||||
</a>
|
||||
<br >
|
||||
<a href="https://www.apachecn.org/"><img src="https://img.shields.io/badge/%3E-HOME-green.svg"></a>
|
||||
|
|
@ -21,13 +21,39 @@
|
|||
|
||||
地址A: xxx (欢迎留言,我们完善补充)
|
||||
|
||||
## 下载
|
||||
|
||||
### Docker
|
||||
|
||||
```
|
||||
docker pull apachecn0/ailearning
|
||||
docker run -tid -p <port>:80 apachecn0/ailearning
|
||||
# 访问 http://localhost:{port} 查看文档
|
||||
```
|
||||
|
||||
### PYPI
|
||||
|
||||
```
|
||||
pip install apachecn-ailearning
|
||||
apachecn-ailearning <port>
|
||||
# 访问 http://localhost:{port} 查看文档
|
||||
```
|
||||
|
||||
### NPM
|
||||
|
||||
```
|
||||
npm install -g ailearning
|
||||
ailearning <port>
|
||||
# 访问 http://localhost:{port} 查看文档
|
||||
```
|
||||
|
||||
## 组织介绍
|
||||
|
||||
* 合作or侵权,请联系: `apachecn@163.com`
|
||||
* **我们不是 Apache 的官方组织/机构/团体,只是 Apache 技术栈(以及 AI)的爱好者!**
|
||||
* **ApacheCN - 学习群【724187166】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=51040bbd0bf7d0efbfa7256a0331d912a2055a906c324d52b02371d06f3c9878"><img border="0" src="http://data.apachecn.org/img/logo/ApacheCN-group.png" alt="ApacheCN - 学习机器学习群[724187166]" title="ApacheCN - 学习机器学习群[724187166]"></a>**
|
||||
* **ApacheCN - 学习群【724187166】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=51040bbd0bf7d0efbfa7256a0331d912a2055a906c324d52b02371d06f3c9878"><img border="0" src="docs/img/ApacheCN-group.png" alt="ApacheCN - 学习机器学习群[724187166]" title="ApacheCN - 学习机器学习群[724187166]"></a>**
|
||||
|
||||
> **欢迎任何人参与和完善: 一个人可以走的很快,但是一群人却可以走的更远**
|
||||
> 一种新技术一旦开始流行,你要么坐上压路机,要么成为铺路石。——Stewart Brand
|
||||
|
||||
# 路线图
|
||||
|
||||
|
|
@ -45,6 +71,17 @@
|
|||
|
||||
## 1.机器学习 - 基础
|
||||
|
||||
> 支持版本
|
||||
|
||||
| Version | Supported |
|
||||
| ------- | ------------------ |
|
||||
| 3.6.x | :x: |
|
||||
| 2.7.x | :white_check_mark: |
|
||||
|
||||
注意事项:
|
||||
|
||||
- 机器学习实战: 仅仅只是学习,请使用 python 2.7.x 版本 (3.6.x 只是修改了部分)
|
||||
|
||||
### 基本介绍
|
||||
|
||||
* 资料来源: Machine Learning in Action(机器学习实战-个人笔记)
|
||||
|
|
@ -60,135 +97,25 @@
|
|||
|
||||
### 学习文档
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>模块</th>
|
||||
<th>章节</th>
|
||||
<th>类型</th>
|
||||
<th>负责人(GitHub)</th>
|
||||
<th>QQ</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/1.机器学习基础.md"> 第 1 章: 机器学习基础</a></td>
|
||||
<td>介绍</td>
|
||||
<td><a href="https://github.com/ElmaDavies">@毛红动</a></td>
|
||||
<td>1306014226</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/2.k-近邻算法.md">第 2 章: KNN 近邻算法</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/youyj521">@尤永江</a></td>
|
||||
<td>279393323</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/3.决策树.md">第 3 章: 决策树</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/jingwangfei">@景涛</a></td>
|
||||
<td>844300439</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/4.朴素贝叶斯.md">第 4 章: 朴素贝叶斯</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/wnma3mz">@wnma3mz</a><br/><a href="https://github.com/kailian">@分析</a></td>
|
||||
<td>1003324213<br/>244970749</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/5.Logistic回归.md">第 5 章: Logistic回归</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/6.支持向量机.md">第 6 章: SVM 支持向量机</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/VPrincekin">@王德红</a></td>
|
||||
<td>934969547</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>网上组合内容</td>
|
||||
<td><a href="docs/ml/7.集成方法-随机森林和AdaBoost.md">第 7 章: 集成方法(随机森林和 AdaBoost)</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/jiangzhonglian">@片刻</a></td>
|
||||
<td>529815144</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/8.回归.md">第 8 章: 回归</a></td>
|
||||
<td>回归</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/9.树回归.md">第 9 章: 树回归</a></td>
|
||||
<td>回归</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/10.k-means聚类.md">第 10 章: K-Means 聚类</a></td>
|
||||
<td>聚类</td>
|
||||
<td><a href="https://github.com/xuzhaoqing">@徐昭清</a></td>
|
||||
<td>827106588</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/11.使用Apriori算法进行关联分析.md">第 11 章: 利用 Apriori 算法进行关联分析</a></td>
|
||||
<td>频繁项集</td>
|
||||
<td><a href="https://github.com/WindZQ">@刘海飞</a></td>
|
||||
<td>1049498972</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/12.使用FP-growth算法来高效发现频繁项集.md">第 12 章: FP-growth 高效发现频繁项集</a></td>
|
||||
<td>频繁项集</td>
|
||||
<td><a href="https://github.com/mikechengwei">@程威</a></td>
|
||||
<td>842725815</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/13.利用PCA来简化数据.md">第 13 章: 利用 PCA 来简化数据</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/lljuan330">@廖立娟</a></td>
|
||||
<td>835670618</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/14.利用SVD简化数据.md">第 14 章: 利用 SVD 来简化数据</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/marsjhao">@张俊皓</a></td>
|
||||
<td>714974242</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/15.大数据与MapReduce.md">第 15 章: 大数据与 MapReduce</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/wnma3mz">@wnma3mz</a></td>
|
||||
<td>1003324213</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Ml项目实战</td>
|
||||
<td><a href="docs/ml/16.推荐系统.md">第 16 章: 推荐系统(已迁移)</a></td>
|
||||
<td>项目</td>
|
||||
<td><a href="https://github.com/apachecn/RecommenderSystems">推荐系统(迁移后地址)</a></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>第一期的总结</td>
|
||||
<td><a href="report/2017-04-08_第一期的总结.md">2017-04-08: 第一期的总结</a></td>
|
||||
<td>总结</td>
|
||||
<td>总结</td>
|
||||
<td>529815144</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
| 模块 | 章节 | 类型 | 负责人(GitHub) | QQ |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| 机器学习实战 | [第 1 章: 机器学习基础](docs/ml/1.md) | 介绍 | [@毛红动](https://github.com/ElmaDavies) | 1306014226 |
|
||||
| 机器学习实战 | [第 2 章: KNN 近邻算法](docs/ml/2.md) | 分类 | [@尤永江](https://github.com/youyj521) | 279393323 |
|
||||
| 机器学习实战 | [第 3 章: 决策树](docs/ml/3.md) | 分类 | [@景涛](https://github.com/jingwangfei) | 844300439 |
|
||||
| 机器学习实战 | [第 4 章: 朴素贝叶斯](docs/ml/4.md) | 分类 | [@wnma3mz](https://github.com/wnma3mz)<br/>[@分析](https://github.com/kailian) | 1003324213<br/>244970749 |
|
||||
| 机器学习实战 | [第 5 章: Logistic回归](docs/ml/5.md) | 分类 | [@微光同尘](https://github.com/DataMonk2017) | 529925688 |
|
||||
| 机器学习实战 | [第 6 章: SVM 支持向量机](docs/ml/6.md) | 分类 | [@王德红](https://github.com/VPrincekin) | 934969547 |
|
||||
| 网上组合内容 | [第 7 章: 集成方法(随机森林和 AdaBoost)](docs/ml/7.md) | 分类 | [@片刻](https://github.com/jiangzhonglian) | 529815144 |
|
||||
| 机器学习实战 | [第 8 章: 回归](docs/ml/8.md) | 回归 | [@微光同尘](https://github.com/DataMonk2017) | 529925688 |
|
||||
| 机器学习实战 | [第 9 章: 树回归](docs/ml/9.md) | 回归 | [@微光同尘](https://github.com/DataMonk2017) | 529925688 |
|
||||
| 机器学习实战 | [第 10 章: K-Means 聚类](docs/ml/10.md) | 聚类 | [@徐昭清](https://github.com/xuzhaoqing) | 827106588 |
|
||||
| 机器学习实战 | [第 11 章: 利用 Apriori 算法进行关联分析](docs/ml/11.md) | 频繁项集 | [@刘海飞](https://github.com/WindZQ) | 1049498972 |
|
||||
| 机器学习实战 | [第 12 章: FP-growth 高效发现频繁项集](docs/ml/12.md) | 频繁项集 | [@程威](https://github.com/mikechengwei) | 842725815 |
|
||||
| 机器学习实战 | [第 13 章: 利用 PCA 来简化数据](docs/ml/13.md) | 工具 | [@廖立娟](https://github.com/lljuan330) | 835670618 |
|
||||
| 机器学习实战 | [第 14 章: 利用 SVD 来简化数据](docs/ml/14.md) | 工具 | [@张俊皓](https://github.com/marsjhao) | 714974242 |
|
||||
| 机器学习实战 | [第 15 章: 大数据与 MapReduce](docs/ml/15.md) | 工具 | [@wnma3mz](https://github.com/wnma3mz) | 1003324213 |
|
||||
| Ml项目实战 | [第 16 章: 推荐系统(已迁移)](docs/ml/16.md) | 项目 | [推荐系统(迁移后地址)](https://github.com/apachecn/RecommenderSystems) | |
|
||||
| 第一期的总结 | [2017-04-08: 第一期的总结](docs/report/2017-04-08.md) | 总结 | 总结 | 529815144 |
|
||||
|
||||
### 网站视频
|
||||
|
||||
|
|
@ -208,7 +135,7 @@
|
|||
|
||||
> 视频怎么看?
|
||||
|
||||

|
||||

|
||||
|
||||
1. 理论科班出身-建议去学习 Andrew Ng 的视频(Ng 的视频绝对是权威,这个毋庸置疑)
|
||||
2. 编码能力强 - 建议看我们的[《机器学习实战-教学版》](https://space.bilibili.com/97678687/#!/channel/detail?cid=22486)
|
||||
|
|
@ -227,9 +154,9 @@
|
|||
|||
|
||||
| - | - |
|
||||
| AcFun | B站 |
|
||||
| <a title="AcFun(机器学习视频)" href="http://www.acfun.cn/u/12540256.aspx#page=1" target="_blank"><img width="290" src="http://data.apachecn.org/img/AiLearning/MainPage/ApacheCN-ML-AcFun.jpg"></a> | <a title="bilibili(机器学习视频)" href="https://space.bilibili.com/97678687/#!/channel/index" target="_blank"><img width="290" src="http://data.apachecn.org/img/AiLearning/MainPage/ApacheCN-ML-bilibili.jpg"></a> |
|
||||
| <a title="AcFun(机器学习视频)" href="http://www.acfun.cn/u/12540256.aspx#page=1" target="_blank"><img width="290" src="docs/img/ApacheCN-ML-AcFun.jpg"></a> | <a title="bilibili(机器学习视频)" href="https://space.bilibili.com/97678687/#!/channel/index" target="_blank"><img width="290" src="docs/img/ApacheCN-ML-bilibili.jpg"></a> |
|
||||
| 优酷 | 网易云课堂 |
|
||||
| <a title="YouKu(机器学习视频)" href="http://i.youku.com/apachecn" target="_blank"><img width="290" src="http://data.apachecn.org/img/AiLearning/MainPage/ApacheCM-ML-youku.jpg"></a> | <a title="WangYiYunKeTang(机器学习视频)" href="http://study.163.com/course/courseMain.htm?courseId=1004582003" target="_blank"><img width="290" src="http://data.apachecn.org/img/AiLearning/MainPage/ApacheCM-ML-WangYiYunKeTang.png"></a> |
|
||||
| <a title="YouKu(机器学习视频)" href="http://i.youku.com/apachecn" target="_blank"><img width="290" src="docs/img/ApacheCM-ML-youku.jpg"></a> | <a title="WangYiYunKeTang(机器学习视频)" href="http://study.163.com/course/courseMain.htm?courseId=1004582003" target="_blank"><img width="290" src="docs/img/ApacheCM-ML-WangYiYunKeTang.png"></a> |
|
||||
|
||||
> 【免费】机器/深度学习视频 - 吴恩达
|
||||
|
||||
|
|
@ -240,6 +167,13 @@
|
|||
|
||||
## 2.深度学习
|
||||
|
||||
> 支持版本
|
||||
|
||||
| Version | Supported |
|
||||
| ------- | ------------------ |
|
||||
| 3.6.x | :white_check_mark: |
|
||||
| 2.7.x | :x: |
|
||||
|
||||
### 入门基础
|
||||
|
||||
1. [反向传递](/docs/dl/反向传递.md): https://www.cnblogs.com/charlotte77/p/5629865.html
|
||||
|
|
@ -258,7 +192,7 @@
|
|||
> 目录结构:
|
||||
|
||||
* [安装指南](docs/TensorFlow2.x/安装指南.md)
|
||||
* [Kears 快速入门](docs/TensorFlow2.x/Keras快速入门.md)
|
||||
* [Keras 快速入门](docs/TensorFlow2.x/Keras快速入门.md)
|
||||
* [实战项目 1 电影情感分类](docs/TensorFlow2.x/实战项目_1_电影情感分类.md)
|
||||
* [实战项目 2 汽车燃油效率](docs/TensorFlow2.x/实战项目_2_汽车燃油效率.md)
|
||||
* [实战项目 3 优化 过拟合和欠拟合](docs/TensorFlow2.x/实战项目_3_优化_过拟合和欠拟合.md)
|
||||
|
|
@ -283,6 +217,13 @@ TensorFlow 2.0学习网址
|
|||
|
||||
## 3.自然语言处理
|
||||
|
||||
> 支持版本
|
||||
|
||||
| Version | Supported |
|
||||
| ------- | ------------------ |
|
||||
| 3.6.x | :white_check_mark: |
|
||||
| 2.7.x | :x: |
|
||||
|
||||
学习过程中-内心复杂的变化!!!
|
||||
|
||||
```python
|
||||
|
|
@ -302,7 +243,7 @@ TensorFlow 2.0学习网址
|
|||
当然谢谢国内很多博客大佬,特别是一些入门的Demo和基本概念。【深入的水平有限,没看懂】
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
* **【入门须知】必须了解**: <https://github.com/apachecn/AiLearning/tree/master/docs/nlp>
|
||||
* **【入门教程】强烈推荐: PyTorch 自然语言处理**: <https://github.com/apachecn/NLP-with-PyTorch>
|
||||
|
|
@ -382,7 +323,7 @@ TensorFlow 2.0学习网址
|
|||
下面是一些很好的初学者语言建模数据集。
|
||||
|
||||
1. [古腾堡项目](https://www.gutenberg.org/),一系列免费书籍,可以用纯文本检索各种语言。
|
||||
2. 还有更多正式的语料库得到了很好的研究; 例如:
|
||||
2. 还有更多正式的语料库得到了很好的研究; 例如:
|
||||
[布朗大学现代美国英语标准语料库](https://en.wikipedia.org/wiki/Brown_Corpus)。大量英语单词样本。
|
||||
[谷歌10亿字语料库](https://github.com/ciprian-chelba/1-billion-word-language-modeling-benchmark)。
|
||||
|
||||
|
|
@ -422,7 +363,7 @@ mage字幕是为给定图像生成文本描述的任务。
|
|||
|
||||
1. [加拿大第36届议会的协调国会议员](https://www.isi.edu/natural-language/download/hansard/)。成对的英语和法语句子。
|
||||
2. [欧洲议会诉讼平行语料库1996-2011](http://www.statmt.org/europarl/)。句子对一套欧洲语言。
|
||||
有大量标准数据集用于年度机器翻译挑战; 看到:
|
||||
有大量标准数据集用于年度机器翻译挑战; 看到:
|
||||
|
||||
[统计机器翻译](http://www.statmt.org/)
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,24 @@
|
|||
# 安全政策 Security Policy
|
||||
|
||||
## 支持版本 Supported Versions
|
||||
|
||||
Use this section to tell people about which versions of your project are
|
||||
currently being supported with security updates.
|
||||
|
||||
| Version | Supported |
|
||||
| ------- | ------------------ |
|
||||
| 3.6.x | :x: |
|
||||
| 2.7.x | :white_check_mark: |
|
||||
|
||||
注意事项:
|
||||
|
||||
- 机器学习实战: 仅仅只是学习,请使用 python 2.7.x 版本 (3.6.x 只是修改了部分)
|
||||
- 深度学习/自然语言处理: 请使用 python 3.6.x 版本
|
||||
|
||||
## 报告漏洞 Reporting a Vulnerability
|
||||
|
||||
Use this section to tell people how to report a vulnerability.
|
||||
|
||||
Tell them where to go, how often they can expect to get an update on a
|
||||
reported vulnerability, what to expect if the vulnerability is accepted or
|
||||
declined, etc.
|
||||
322
SUMMARY.md
322
SUMMARY.md
|
|
@ -1,41 +1,293 @@
|
|||
|
||||
+ [入门须知](README.md)
|
||||
+ 机器学习
|
||||
+ [第1章_基础知识](docs/ml/1.机器学习基础.md)
|
||||
+ [第2章_K近邻算法](docs/ml/2.k-近邻算法.md)
|
||||
+ [第3章_决策树算法](docs/ml/3.决策树.md)
|
||||
+ [第4章_朴素贝叶斯](docs/ml/4.朴素贝叶斯.md)
|
||||
+ [第5章_逻辑回归](docs/ml/5.Logistic回归.md)
|
||||
+ [第6章_支持向量机](docs/ml/6.支持向量机.md)
|
||||
+ [第7章_集成方法](docs/ml/7.集成方法-随机森林和AdaBoost.md)
|
||||
+ [第8章_回归](docs/ml/8.回归.md)
|
||||
+ [第9章_树回归](docs/ml/9.树回归.md)
|
||||
+ [第10章_KMeans聚类](docs/ml/10.KMeans聚类.md)
|
||||
+ [第11章_Apriori算法](docs/ml/11.使用Apriori算法进行关联分析.md)
|
||||
+ [第12章_FP-growth算法](docs/ml/12.使用FP-growth算法来高效发现频繁项集.md)
|
||||
+ [第13章_PCA降维](docs/ml/13.利用PCA来简化数据.md)
|
||||
+ [第14章_SVD简化数据](docs/ml/14.利用SVD简化数据.md)
|
||||
+ [第15章_大数据与MapReduce](docs/ml/15.大数据与MapReduce.md)
|
||||
+ [第16章_推荐系统](docs/ml/16.推荐系统.md)
|
||||
+ [入门须知](README.md)
|
||||
+ [数据分析](docs/da/README.md)
|
||||
+ [01\. Python 工具](docs/da/001.md)
|
||||
+ [Python 简介](docs/da/002.md)
|
||||
+ [Ipython 解释器](docs/da/003.md)
|
||||
+ [Ipython notebook](docs/da/004.md)
|
||||
+ [使用 Anaconda](docs/da/005.md)
|
||||
+ [02\. Python 基础](docs/da/006.md)
|
||||
+ [Python 入门演示](docs/da/007.md)
|
||||
+ [Python 数据类型](docs/da/008.md)
|
||||
+ [数字](docs/da/009.md)
|
||||
+ [字符串](docs/da/010.md)
|
||||
+ [索引和分片](docs/da/011.md)
|
||||
+ [列表](docs/da/012.md)
|
||||
+ [可变和不可变类型](docs/da/013.md)
|
||||
+ [元组](docs/da/014.md)
|
||||
+ [列表与元组的速度比较](docs/da/015.md)
|
||||
+ [字典](docs/da/016.md)
|
||||
+ [集合](docs/da/017.md)
|
||||
+ [不可变集合](docs/da/018.md)
|
||||
+ [Python 赋值机制](docs/da/019.md)
|
||||
+ [判断语句](docs/da/020.md)
|
||||
+ [循环](docs/da/021.md)
|
||||
+ [列表推导式](docs/da/022.md)
|
||||
+ [函数](docs/da/023.md)
|
||||
+ [模块和包](docs/da/024.md)
|
||||
+ [异常](docs/da/025.md)
|
||||
+ [警告](docs/da/026.md)
|
||||
+ [文件读写](docs/da/027.md)
|
||||
+ [03\. Numpy](docs/da/028.md)
|
||||
+ [Numpy 简介](docs/da/029.md)
|
||||
+ [Matplotlib 基础](docs/da/030.md)
|
||||
+ [Numpy 数组及其索引](docs/da/031.md)
|
||||
+ [数组类型](docs/da/032.md)
|
||||
+ [数组方法](docs/da/033.md)
|
||||
+ [数组排序](docs/da/034.md)
|
||||
+ [数组形状](docs/da/035.md)
|
||||
+ [对角线](docs/da/036.md)
|
||||
+ [数组与字符串的转换](docs/da/037.md)
|
||||
+ [数组属性方法总结](docs/da/038.md)
|
||||
+ [生成数组的函数](docs/da/039.md)
|
||||
+ [矩阵](docs/da/040.md)
|
||||
+ [一般函数](docs/da/041.md)
|
||||
+ [向量化函数](docs/da/042.md)
|
||||
+ [二元运算](docs/da/043.md)
|
||||
+ [ufunc 对象](docs/da/044.md)
|
||||
+ [choose 函数实现条件筛选](docs/da/045.md)
|
||||
+ [数组广播机制](docs/da/046.md)
|
||||
+ [数组读写](docs/da/047.md)
|
||||
+ [结构化数组](docs/da/048.md)
|
||||
+ [记录数组](docs/da/049.md)
|
||||
+ [内存映射](docs/da/050.md)
|
||||
+ [从 Matlab 到 Numpy](docs/da/051.md)
|
||||
+ [04\. Scipy](docs/da/052.md)
|
||||
+ [SCIentific PYthon 简介](docs/da/053.md)
|
||||
+ [插值](docs/da/054.md)
|
||||
+ [概率统计方法](docs/da/055.md)
|
||||
+ [曲线拟合](docs/da/056.md)
|
||||
+ [最小化函数](docs/da/057.md)
|
||||
+ [积分](docs/da/058.md)
|
||||
+ [解微分方程](docs/da/059.md)
|
||||
+ [稀疏矩阵](docs/da/060.md)
|
||||
+ [线性代数](docs/da/061.md)
|
||||
+ [稀疏矩阵的线性代数](docs/da/062.md)
|
||||
+ [05\. Python 进阶](docs/da/063.md)
|
||||
+ [sys 模块简介](docs/da/064.md)
|
||||
+ [与操作系统进行交互:os 模块](docs/da/065.md)
|
||||
+ [CSV 文件和 csv 模块](docs/da/066.md)
|
||||
+ [正则表达式和 re 模块](docs/da/067.md)
|
||||
+ [datetime 模块](docs/da/068.md)
|
||||
+ [SQL 数据库](docs/da/069.md)
|
||||
+ [对象关系映射](docs/da/070.md)
|
||||
+ [函数进阶:参数传递,高阶函数,lambda 匿名函数,global 变量,递归](docs/da/071.md)
|
||||
+ [迭代器](docs/da/072.md)
|
||||
+ [生成器](docs/da/073.md)
|
||||
+ [with 语句和上下文管理器](docs/da/074.md)
|
||||
+ [修饰符](docs/da/075.md)
|
||||
+ [修饰符的使用](docs/da/076.md)
|
||||
+ [operator, functools, itertools, toolz, fn, funcy 模块](docs/da/077.md)
|
||||
+ [作用域](docs/da/078.md)
|
||||
+ [动态编译](docs/da/079.md)
|
||||
+ [06\. Matplotlib](docs/da/080.md)
|
||||
+ [Pyplot 教程](docs/da/081.md)
|
||||
+ [使用 style 来配置 pyplot 风格](docs/da/082.md)
|
||||
+ [处理文本(基础)](docs/da/083.md)
|
||||
+ [处理文本(数学表达式)](docs/da/084.md)
|
||||
+ [图像基础](docs/da/085.md)
|
||||
+ [注释](docs/da/086.md)
|
||||
+ [标签](docs/da/087.md)
|
||||
+ [figures, subplots, axes 和 ticks 对象](docs/da/088.md)
|
||||
+ [不要迷信默认设置](docs/da/089.md)
|
||||
+ [各种绘图实例](docs/da/090.md)
|
||||
+ [07\. 使用其他语言进行扩展](docs/da/091.md)
|
||||
+ [简介](docs/da/092.md)
|
||||
+ [Python 扩展模块](docs/da/093.md)
|
||||
+ [Cython:Cython 基础,将源代码转换成扩展模块](docs/da/094.md)
|
||||
+ [Cython:Cython 语法,调用其他C库](docs/da/095.md)
|
||||
+ [Cython:class 和 cdef class,使用 C++](docs/da/096.md)
|
||||
+ [Cython:Typed memoryviews](docs/da/097.md)
|
||||
+ [生成编译注释](docs/da/098.md)
|
||||
+ [ctypes](docs/da/099.md)
|
||||
+ [08\. 面向对象编程](docs/da/100.md)
|
||||
+ [简介](docs/da/101.md)
|
||||
+ [使用 OOP 对森林火灾建模](docs/da/102.md)
|
||||
+ [什么是对象?](docs/da/103.md)
|
||||
+ [定义 class](docs/da/104.md)
|
||||
+ [特殊方法](docs/da/105.md)
|
||||
+ [属性](docs/da/106.md)
|
||||
+ [森林火灾模拟](docs/da/107.md)
|
||||
+ [继承](docs/da/108.md)
|
||||
+ [super() 函数](docs/da/109.md)
|
||||
+ [重定义森林火灾模拟](docs/da/110.md)
|
||||
+ [接口](docs/da/111.md)
|
||||
+ [共有,私有和特殊方法和属性](docs/da/112.md)
|
||||
+ [多重继承](docs/da/113.md)
|
||||
+ [09\. Theano 基础](docs/da/114.md)
|
||||
+ [Theano 简介及其安装](docs/da/115.md)
|
||||
+ [Theano 基础](docs/da/116.md)
|
||||
+ [Theano 在 Windows 上的配置](docs/da/117.md)
|
||||
+ [Theano 符号图结构](docs/da/118.md)
|
||||
+ [Theano 配置和编译模式](docs/da/119.md)
|
||||
+ [Theano 条件语句](docs/da/120.md)
|
||||
+ [Theano 循环:scan(详解)](docs/da/121.md)
|
||||
+ [Theano 实例:线性回归](docs/da/122.md)
|
||||
+ [Theano 实例:Logistic 回归](docs/da/123.md)
|
||||
+ [Theano 实例:Softmax 回归](docs/da/124.md)
|
||||
+ [Theano 实例:人工神经网络](docs/da/125.md)
|
||||
+ [Theano 随机数流变量](docs/da/126.md)
|
||||
+ [Theano 实例:更复杂的网络](docs/da/127.md)
|
||||
+ [Theano 实例:卷积神经网络](docs/da/128.md)
|
||||
+ [Theano tensor 模块:基础](docs/da/129.md)
|
||||
+ [Theano tensor 模块:索引](docs/da/130.md)
|
||||
+ [Theano tensor 模块:操作符和逐元素操作](docs/da/131.md)
|
||||
+ [Theano tensor 模块:nnet 子模块](docs/da/132.md)
|
||||
+ [Theano tensor 模块:conv 子模块](docs/da/133.md)
|
||||
+ [10\. 有趣的第三方模块](docs/da/134.md)
|
||||
+ [使用 basemap 画地图](docs/da/135.md)
|
||||
+ [使用 cartopy 画地图](docs/da/136.md)
|
||||
+ [探索 NBA 数据](docs/da/137.md)
|
||||
+ [金庸的武侠世界](docs/da/138.md)
|
||||
+ [11\. 有用的工具](docs/da/139.md)
|
||||
+ [pprint 模块:打印 Python 对象](docs/da/140.md)
|
||||
+ [pickle, cPickle 模块:序列化 Python 对象](docs/da/141.md)
|
||||
+ [json 模块:处理 JSON 数据](docs/da/142.md)
|
||||
+ [glob 模块:文件模式匹配](docs/da/143.md)
|
||||
+ [shutil 模块:高级文件操作](docs/da/144.md)
|
||||
+ [gzip, zipfile, tarfile 模块:处理压缩文件](docs/da/145.md)
|
||||
+ [logging 模块:记录日志](docs/da/146.md)
|
||||
+ [string 模块:字符串处理](docs/da/147.md)
|
||||
+ [collections 模块:更多数据结构](docs/da/148.md)
|
||||
+ [requests 模块:HTTP for Human](docs/da/149.md)
|
||||
+ [12\. Pandas](docs/da/150.md)
|
||||
+ [十分钟上手 Pandas](docs/da/151.md)
|
||||
+ [一维数据结构:Series](docs/da/152.md)
|
||||
+ [二维数据结构:DataFrame](docs/da/153.md)
|
||||
+ 机器学习
|
||||
+ [第1章_基础知识](docs/ml/1.md)
|
||||
+ [第2章_K近邻算法](docs/ml/2.md)
|
||||
+ [第3章_决策树算法](docs/ml/3.md)
|
||||
+ [第4章_朴素贝叶斯](docs/ml/4.md)
|
||||
+ [第5章_逻辑回归](docs/ml/5.md)
|
||||
+ [第6章_支持向量机](docs/ml/6.md)
|
||||
+ [第7章_集成方法](docs/ml/7.md)
|
||||
+ [第8章_回归](docs/ml/8.md)
|
||||
+ [第9章_树回归](docs/ml/9.md)
|
||||
+ [第10章_KMeans聚类](docs/ml/10.md)
|
||||
+ [第11章_Apriori算法](docs/ml/11.md)
|
||||
+ [第12章_FP-growth算法](docs/ml/12.md)
|
||||
+ [第13章_PCA降维](docs/ml/13.md)
|
||||
+ [第14章_SVD简化数据](docs/ml/14.md)
|
||||
+ [第15章_大数据与MapReduce](docs/ml/15.md)
|
||||
+ [第16章_推荐系统](docs/ml/16.md)
|
||||
+ [为何录制教学版视频](docs/why-to-record-study-ml-video.md)
|
||||
+ [2017-04-08_第一期的总结](report/2017-04-08_第一期的总结.md)
|
||||
+ 深度学习入门
|
||||
+ [2017-04-08_第一期的总结](docs/report/2017-04-08.md)
|
||||
+ [PyTorch](docs/pytorch/README.md)
|
||||
+ [PyTorch 简介](docs/pytorch/01.md)
|
||||
+ [1.1 – Why PyTorch?](docs/pytorch/02.md)
|
||||
+ [1.2 – 安装 PyTorch](docs/pytorch/03.md)
|
||||
+ [PyTorch 神经网络基础](docs/pytorch/04.md)
|
||||
+ [2.1 – Torch vs Numpy](docs/pytorch/05.md)
|
||||
+ [2.2 – 变量 (Variable)](docs/pytorch/06.md)
|
||||
+ [2.3 – 激励函数 (Activation)](docs/pytorch/07.md)
|
||||
+ [建造第一个神经网络](docs/pytorch/08.md)
|
||||
+ [3.1 – 关系拟合 (回归 Regression)](docs/pytorch/09.md)
|
||||
+ [3.2 – 区分类型 (分类 Classification)](docs/pytorch/10.md)
|
||||
+ [3.3 – 快速搭建回归神经网络](docs/pytorch/11.md)
|
||||
+ [3.4 – 保存和恢复模型](docs/pytorch/12.md)
|
||||
+ [3.5 – 数据读取 (Data Loader)](docs/pytorch/13.md)
|
||||
+ [3.6 – 优化器 (Optimizer)](docs/pytorch/14.md)
|
||||
+ [高级神经网络结构](docs/pytorch/15.md)
|
||||
+ [4.1 – CNN 卷积神经网络](docs/pytorch/16.md)
|
||||
+ [4.2 – RNN 循环神经网络 (分类 Classification)](docs/pytorch/17.md)
|
||||
+ [4.3 – RNN 循环神经网络 (回归 Regression)](docs/pytorch/18.md)
|
||||
+ [4.4 – AutoEncoder (自编码/非监督学习)](docs/pytorch/19.md)
|
||||
+ [4.5 – DQN 强化学习 (Reinforcement Learning)](docs/pytorch/20.md)
|
||||
+ [4.6 – GAN (Generative Adversarial Nets 生成对抗网络)](docs/pytorch/21.md)
|
||||
+ [高阶内容](docs/pytorch/22.md)
|
||||
+ [5.1 – 为什么 Torch 是动态的](docs/pytorch/23.md)
|
||||
+ [5.2 – GPU 加速运算](docs/pytorch/24.md)
|
||||
+ [5.3 – Dropout 防止过拟合](docs/pytorch/25.md)
|
||||
+ [5.4 – Batch Normalization 批标准化](docs/pytorch/26.md)
|
||||
+ 深度学习入门
|
||||
+ [反向传递](docs/dl/反向传递.md)
|
||||
+ [CNN原理](docs/dl/CNN原理.md)
|
||||
+ [RNN原理](docs/dl/RNN原理.md)
|
||||
+ [LSTM原理](docs/dl/LSTM原理.md)
|
||||
+ 自然语言处理
|
||||
+ [第1章_入门介绍](docs/nlp/1.入门介绍.md)
|
||||
+ [第2章_分词](docs/nlp/2.分词.md)
|
||||
+ [第3章_命名实体识别](docs/nlp/3.命名实体识别.md)
|
||||
+ [第10章_篇章分析-内容概述](docs/nlp/3.1.篇章分析-内容概述.md)
|
||||
+ [第10章_篇章分析-内容标签](docs/nlp/3.2.篇章分析-内容标签.md)
|
||||
+ [第10章_篇章分析-情感分析](docs/nlp/3.3.篇章分析-情感分析.md)
|
||||
+ [第10章_篇章分析-自动摘要](docs/nlp/3.4.篇章分析-自动摘要.md)
|
||||
+ TensorFlow 2.0 - 教程
|
||||
+ [安装指南](docs/TensorFlow2.x/安装指南.md)
|
||||
+ [Kears 快速入门](docs/TensorFlow2.x/Keras快速入门.md)
|
||||
+ [实战项目 1 电影情感分类](docs/TensorFlow2.x/实战项目_1_电影情感分类.md)
|
||||
+ [实战项目 2 汽车燃油效率](docs/TensorFlow2.x/实战项目_2_汽车燃油效率.md)
|
||||
+ [实战项目 3 优化 过拟合和欠拟合](docs/TensorFlow2.x/实战项目_3_优化_过拟合和欠拟合.md)
|
||||
+ [实战项目 4 古诗词自动生成](docs/TensorFlow2.x/实战项目_4_古诗词自动生成.md)
|
||||
+ [自然语言处理](docs/nlp/README.md)
|
||||
+ [前言](docs/nlp/0.md)
|
||||
+ [1 语言处理与 Python](docs/nlp/1.md)
|
||||
+ [2 获得文本语料和词汇资源](docs/nlp/2.md)
|
||||
+ [3 处理原始文本](docs/nlp/3.md)
|
||||
+ [4 编写结构化程序](docs/nlp/4.md)
|
||||
+ [5 分类和标注词汇](docs/nlp/5.md)
|
||||
+ [6 学习分类文本](docs/nlp/6.md)
|
||||
+ [7 从文本提取信息](docs/nlp/7.md)
|
||||
+ [8 分析句子结构](docs/nlp/8.md)
|
||||
+ [9 构建基于特征的语法](docs/nlp/9.md)
|
||||
+ [10 分析句子的意思](docs/nlp/10.md)
|
||||
+ [11 语言学数据管理](docs/nlp/11.md)
|
||||
+ [后记:语言的挑战](docs/nlp/12.md)
|
||||
+ [索引](docs/nlp/14.md)
|
||||
+ [TensorFlow 2.x](docs/tf2/README.md)
|
||||
+ [初学者的 TensorFlow 2.0 教程](docs/tf2/002.md)
|
||||
+ [针对专业人员的 TensorFlow 2.0 入门](docs/tf2/003.md)
|
||||
+ [初级](docs/tf2/004.md)
|
||||
+ [Keras 机器学习基础知识](docs/tf2/005.md)
|
||||
+ [基本分类:对服装图像进行分类](docs/tf2/006.md)
|
||||
+ [电影评论文本分类](docs/tf2/007.md)
|
||||
+ [使用 Keras 和 Tensorflow Hub 对电影评论进行文本分类](docs/tf2/008.md)
|
||||
+ [Basic regression: Predict fuel efficiency](docs/tf2/009.md)
|
||||
+ [Overfit and underfit](docs/tf2/010.md)
|
||||
+ [保存和恢复模型](docs/tf2/011.md)
|
||||
+ [Introduction to the Keras Tuner](docs/tf2/012.md)
|
||||
+ [加载和预处理数据](docs/tf2/013.md)
|
||||
+ [用 tf.data 加载图片](docs/tf2/014.md)
|
||||
+ [使用 tf.data 加载文本数据](docs/tf2/015.md)
|
||||
+ [用 tf.data 加载 CSV 数据](docs/tf2/016.md)
|
||||
+ [使用 tf.data 加载 NumPy 数据](docs/tf2/017.md)
|
||||
+ [使用 tf.data 加载 pandas dataframes](docs/tf2/018.md)
|
||||
+ [Unicode 字符串](docs/tf2/019.md)
|
||||
+ [TF.Text](docs/tf2/020.md)
|
||||
+ [TFRecord 和 tf.Example](docs/tf2/021.md)
|
||||
+ [Estimator](docs/tf2/022.md)
|
||||
+ [预创建的 Estimators](docs/tf2/023.md)
|
||||
+ [Build a linear model with Estimators](docs/tf2/024.md)
|
||||
+ [在 Tensorflow 中训练提升树(Boosted Trees)模型](docs/tf2/025.md)
|
||||
+ [梯度提升树(Gradient Boosted Trees):模型理解](docs/tf2/026.md)
|
||||
+ [通过 Keras 模型创建 Estimator](docs/tf2/027.md)
|
||||
+ [高级](docs/tf2/028.md)
|
||||
+ [自定义](docs/tf2/029.md)
|
||||
+ [Customization basics: tensors and operations](docs/tf2/030.md)
|
||||
+ [Custom layers](docs/tf2/031.md)
|
||||
+ [自定义训练: 演示](docs/tf2/032.md)
|
||||
+ [分布式训练](docs/tf2/033.md)
|
||||
+ [Keras 的分布式训练](docs/tf2/034.md)
|
||||
+ [使用 tf.distribute.Strategy 进行自定义训练](docs/tf2/035.md)
|
||||
+ [利用 Keras 来训练多工作器(worker)](docs/tf2/036.md)
|
||||
+ [利用 Estimator 进行多工作器训练](docs/tf2/037.md)
|
||||
+ [使用分布策略保存和加载模型](docs/tf2/038.md)
|
||||
+ [Distributed Input](docs/tf2/039.md)
|
||||
+ [图像](docs/tf2/040.md)
|
||||
+ [卷积神经网络(Convolutional Neural Network, CNN)](docs/tf2/041.md)
|
||||
+ [Image classification](docs/tf2/042.md)
|
||||
+ [Transfer learning and fine-tuning](docs/tf2/043.md)
|
||||
+ [Transfer learning with TensorFlow Hub](docs/tf2/044.md)
|
||||
+ [Data augmentation](docs/tf2/045.md)
|
||||
+ [图像分割](docs/tf2/046.md)
|
||||
+ [文本](docs/tf2/047.md)
|
||||
+ [单词嵌入向量](docs/tf2/048.md)
|
||||
+ [使用 RNN 进行文本分类](docs/tf2/049.md)
|
||||
+ [循环神经网络(RNN)文本生成](docs/tf2/050.md)
|
||||
+ [基于注意力的神经机器翻译](docs/tf2/051.md)
|
||||
+ [Image captioning with visual attention](docs/tf2/052.md)
|
||||
+ [理解语言的 Transformer 模型](docs/tf2/053.md)
|
||||
+ [Fine-tuning a BERT model](docs/tf2/054.md)
|
||||
+ [结构化数据](docs/tf2/055.md)
|
||||
+ [对结构化数据进行分类](docs/tf2/056.md)
|
||||
+ [Classification on imbalanced data](docs/tf2/057.md)
|
||||
+ [Time series forecasting](docs/tf2/058.md)
|
||||
+ [生成](docs/tf2/059.md)
|
||||
+ [神经风格迁移](docs/tf2/060.md)
|
||||
+ [DeepDream](docs/tf2/061.md)
|
||||
+ [深度卷积生成对抗网络](docs/tf2/062.md)
|
||||
+ [Pix2Pix](docs/tf2/063.md)
|
||||
+ [CycleGAN](docs/tf2/064.md)
|
||||
+ [Adversarial example using FGSM](docs/tf2/065.md)
|
||||
+ [Intro to Autoencoders](docs/tf2/066.md)
|
||||
+ [卷积变分自编码器](docs/tf2/067.md)
|
||||
+ [可解释性](docs/tf2/068.md)
|
||||
+ [Integrated gradients](docs/tf2/069.md)
|
||||
+ [强化学习](docs/tf2/070.md)
|
||||
+ [Playing CartPole with the Actor-Critic Method](docs/tf2/071.md)
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
(function(){
|
||||
var footer = [
|
||||
'<hr/>',
|
||||
'<div align="center">',
|
||||
' <p><a href="http://www.apachecn.org/" target="_blank"><font face="KaiTi" size="6" color="red">我们一直在努力</font></a><p>',
|
||||
' <p><a href="https://github.com/apachecn/AiLearning/" target="_blank">apachecn/AiLearning</a></p>',
|
||||
' <p><iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=AiLearning&type=watch&count=true&v=2" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>',
|
||||
' <iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=AiLearning&type=star&count=true" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>',
|
||||
' <iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=AiLearning&type=fork&count=true" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>',
|
||||
' <a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=bcee938030cc9e1552deb3bd9617bbbf62d3ec1647e4b60d9cd6b6e8f78ddc03"><img border="0" src="//pub.idqqimg.com/wpa/images/group.png" alt="ML | ApacheCN" title="ML | ApacheCN"></a></p>',
|
||||
' <p><span id="cnzz_stat_icon_1275211409"></span></p>',
|
||||
' <div style="text-align:center;margin:0 0 10.5px;">',
|
||||
' <ins class="adsbygoogle"',
|
||||
' style="display:inline-block;width:728px;height:90px"',
|
||||
' data-ad-client="ca-pub-3565452474788507"',
|
||||
' data-ad-slot="2543897000"></ins>',
|
||||
' </div>',
|
||||
'</div>'
|
||||
].join('\n')
|
||||
var plugin = function(hook) {
|
||||
hook.afterEach(function(html) {
|
||||
return html + footer
|
||||
})
|
||||
hook.doneEach(function() {
|
||||
(adsbygoogle = window.adsbygoogle || []).push({})
|
||||
})
|
||||
}
|
||||
var plugins = window.$docsify.plugins || []
|
||||
plugins.push(plugin)
|
||||
window.$docsify.plugins = plugins
|
||||
})()
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
(function(){
|
||||
var plugin = function(hook) {
|
||||
hook.doneEach(function() {
|
||||
new Image().src =
|
||||
'//api.share.baidu.com/s.gif?r=' +
|
||||
encodeURIComponent(document.referrer) +
|
||||
"&l=" + encodeURIComponent(location.href)
|
||||
})
|
||||
}
|
||||
var plugins = window.$docsify.plugins || []
|
||||
plugins.push(plugin)
|
||||
window.$docsify.plugins = plugins
|
||||
})()
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
(function(){
|
||||
var plugin = function(hook) {
|
||||
hook.doneEach(function() {
|
||||
window._hmt = window._hmt || []
|
||||
var hm = document.createElement("script")
|
||||
hm.src = "https://hm.baidu.com/hm.js?" + window.$docsify.bdStatId
|
||||
document.querySelector("article").appendChild(hm)
|
||||
})
|
||||
}
|
||||
var plugins = window.$docsify.plugins || []
|
||||
plugins.push(plugin)
|
||||
window.$docsify.plugins = plugins
|
||||
})()
|
||||
|
|
@ -0,0 +1,197 @@
|
|||
(function() {
|
||||
var ids = [
|
||||
'109577065', '108852955', '102682374', '100520874', '92400861', '90312982',
|
||||
'109963325', '109323014', '109301511', '108898970', '108590722', '108538676',
|
||||
'108503526', '108437109', '108402202', '108292691', '108291153', '108268498',
|
||||
'108030854', '107867070', '107847299', '107827334', '107825454', '107802131',
|
||||
'107775320', '107752974', '107735139', '107702571', '107598864', '107584507',
|
||||
'107568311', '107526159', '107452391', '107437455', '107430050', '107395781',
|
||||
'107325304', '107283210', '107107145', '107085440', '106995421', '106993460',
|
||||
'106972215', '106959775', '106766787', '106749609', '106745967', '106634313',
|
||||
'106451602', '106180097', '106095505', '106077010', '106008089', '106002346',
|
||||
'105653809', '105647855', '105130705', '104837872', '104706815', '104192620',
|
||||
'104074941', '104040537', '103962171', '103793502', '103783460', '103774572',
|
||||
'103547748', '103547703', '103547571', '103490757', '103413481', '103341935',
|
||||
'103330191', '103246597', '103235808', '103204403', '103075981', '103015105',
|
||||
'103014899', '103014785', '103014702', '103014540', '102993780', '102993754',
|
||||
'102993680', '102958443', '102913317', '102903382', '102874766', '102870470',
|
||||
'102864513', '102811179', '102761237', '102711565', '102645443', '102621845',
|
||||
'102596167', '102593333', '102585262', '102558427', '102537547', '102530610',
|
||||
'102527017', '102504698', '102489806', '102372981', '102258897', '102257303',
|
||||
'102056248', '101920097', '101648638', '101516708', '101350577', '101268149',
|
||||
'101128167', '101107328', '101053939', '101038866', '100977414', '100945061',
|
||||
'100932401', '100886407', '100797378', '100634918', '100588305', '100572447',
|
||||
'100192249', '100153559', '100099032', '100061455', '100035392', '100033450',
|
||||
'99671267', '99624846', '99172551', '98992150', '98989508', '98987516', '98938304',
|
||||
'98937682', '98725145', '98521688', '98450861', '98306787', '98203342', '98026348',
|
||||
'97680167', '97492426', '97108940', '96888872', '96568559', '96509100', '96508938',
|
||||
'96508611', '96508374', '96498314', '96476494', '96333593', '96101522', '95989273',
|
||||
'95960507', '95771870', '95770611', '95766810', '95727700', '95588929', '95218707',
|
||||
'95073151', '95054615', '95016540', '94868371', '94839549', '94719281', '94401578',
|
||||
'93931439', '93853494', '93198026', '92397889', '92063437', '91635930', '91433989',
|
||||
'91128193', '90915507', '90752423', '90738421', '90725712', '90725083', '90722238',
|
||||
'90647220', '90604415', '90544478', '90379769', '90288341', '90183695', '90144066',
|
||||
'90108283', '90021771', '89914471', '89876284', '89852050', '89839033', '89812373',
|
||||
'89789699', '89786189', '89752620', '89636380', '89632889', '89525811', '89480625',
|
||||
'89464088', '89464025', '89463984', '89463925', '89445280', '89441793', '89430432',
|
||||
'89429877', '89416176', '89412750', '89409618', '89409485', '89409365', '89409292',
|
||||
'89409222', '89399738', '89399674', '89399526', '89355336', '89330241', '89308077',
|
||||
'89222240', '89140953', '89139942', '89134398', '89069355', '89049266', '89035735',
|
||||
'89004259', '88925790', '88925049', '88915838', '88912706', '88911548', '88899438',
|
||||
'88878890', '88837519', '88832555', '88824257', '88777952', '88752158', '88659061',
|
||||
'88615256', '88551434', '88375675', '88322134', '88322085', '88321996', '88321978',
|
||||
'88321950', '88321931', '88321919', '88321899', '88321830', '88321756', '88321710',
|
||||
'88321661', '88321632', '88321566', '88321550', '88321506', '88321475', '88321440',
|
||||
'88321409', '88321362', '88321321', '88321293', '88321226', '88232699', '88094874',
|
||||
'88090899', '88090784', '88089091', '88048808', '87938224', '87913318', '87905933',
|
||||
'87897358', '87856753', '87856461', '87827666', '87822008', '87821456', '87739137',
|
||||
'87734022', '87643633', '87624617', '87602909', '87548744', '87548689', '87548624',
|
||||
'87548550', '87548461', '87463201', '87385913', '87344048', '87078109', '87074784',
|
||||
'87004367', '86997632', '86997466', '86997303', '86997116', '86996474', '86995899',
|
||||
'86892769', '86892654', '86892569', '86892457', '86892347', '86892239', '86892124',
|
||||
'86798671', '86777307', '86762845', '86760008', '86759962', '86759944', '86759930',
|
||||
'86759922', '86759646', '86759638', '86759633', '86759622', '86759611', '86759602',
|
||||
'86759596', '86759591', '86759580', '86759572', '86759567', '86759558', '86759545',
|
||||
'86759534', '86749811', '86741502', '86741074', '86741059', '86741020', '86740897',
|
||||
'86694754', '86670104', '86651882', '86651875', '86651866', '86651828', '86651790',
|
||||
'86651767', '86651756', '86651735', '86651720', '86651708', '86618534', '86618526',
|
||||
'86594785', '86590937', '86550497', '86550481', '86550472', '86550453', '86550438',
|
||||
'86550429', '86550407', '86550381', '86550359', '86536071', '86536035', '86536014',
|
||||
'86535988', '86535963', '86535953', '86535932', '86535902', '86472491', '86472298',
|
||||
'86472236', '86472191', '86472108', '86471967', '86471899', '86471822', '86439022',
|
||||
'86438972', '86438902', '86438887', '86438867', '86438836', '86438818', '85850119',
|
||||
'85850075', '85850021', '85849945', '85849893', '85849837', '85849790', '85849740',
|
||||
'85849661', '85849620', '85849550', '85606096', '85564441', '85547709', '85471981',
|
||||
'85471317', '85471136', '85471073', '85470629', '85470456', '85470169', '85469996',
|
||||
'85469877', '85469775', '85469651', '85469331', '85469033', '85345768', '85345742',
|
||||
'85337900', '85337879', '85337860', '85337833', '85337797', '85322822', '85322810',
|
||||
'85322791', '85322745', '85317667', '85265742', '85265696', '85265618', '85265350',
|
||||
'85098457', '85057670', '85009890', '84755581', '84637437', '84637431', '84637393',
|
||||
'84637374', '84637355', '84637338', '84637321', '84637305', '84637283', '84637259',
|
||||
'84629399', '84629314', '84629233', '84629124', '84629065', '84628997', '84628933',
|
||||
'84628838', '84628777', '84628690', '84591581', '84591553', '84591511', '84591484',
|
||||
'84591468', '84591416', '84591386', '84591350', '84591308', '84572155', '84572107',
|
||||
'84503228', '84500221', '84403516', '84403496', '84403473', '84403442', '84075703',
|
||||
'84029659', '83933480', '83933459', '83933435', '83903298', '83903274', '83903258',
|
||||
'83752369', '83345186', '83116487', '83116446', '83116402', '83116334', '83116213',
|
||||
'82944248', '82941023', '82938777', '82936611', '82932735', '82918102', '82911085',
|
||||
'82888399', '82884263', '82883507', '82880996', '82875334', '82864060', '82831039',
|
||||
'82823385', '82795277', '82790832', '82775718', '82752022', '82730437', '82718126',
|
||||
'82661646', '82588279', '82588267', '82588261', '82588192', '82347066', '82056138',
|
||||
'81978722', '81211571', '81104145', '81069048', '81006768', '80788365', '80767582',
|
||||
'80759172', '80759144', '80759129', '80736927', '80661288', '80616304', '80602366',
|
||||
'80584625', '80561364', '80549878', '80549875', '80541470', '80539726', '80531328',
|
||||
'80513257', '80469816', '80406810', '80356781', '80334130', '80333252', '80332666',
|
||||
'80332389', '80311244', '80301070', '80295974', '80292252', '80286963', '80279504',
|
||||
'80278369', '80274371', '80249825', '80247284', '80223054', '80219559', '80209778',
|
||||
'80200279', '80164236', '80160900', '80153046', '80149560', '80144670', '80061205',
|
||||
'80046520', '80025644', '80014721', '80005213', '80004664', '80001653', '79990178',
|
||||
'79989283', '79947873', '79946002', '79941517', '79938786', '79932755', '79921178',
|
||||
'79911339', '79897603', '79883931', '79872574', '79846509', '79832150', '79828161',
|
||||
'79828156', '79828149', '79828146', '79828140', '79828139', '79828135', '79828123',
|
||||
'79820772', '79776809', '79776801', '79776788', '79776782', '79776772', '79776767',
|
||||
'79776760', '79776753', '79776736', '79776705', '79676183', '79676171', '79676166',
|
||||
'79676160', '79658242', '79658137', '79658130', '79658123', '79658119', '79658112',
|
||||
'79658100', '79658092', '79658089', '79658069', '79658054', '79633508', '79587857',
|
||||
'79587850', '79587842', '79587831', '79587825', '79587819', '79547908', '79477700',
|
||||
'79477692', '79440956', '79431176', '79428647', '79416896', '79406699', '79350633',
|
||||
'79350545', '79344765', '79339391', '79339383', '79339157', '79307345', '79293944',
|
||||
'79292623', '79274443', '79242798', '79184420', '79184386', '79184355', '79184269',
|
||||
'79183979', '79100314', '79100206', '79100064', '79090813', '79057834', '78967246',
|
||||
'78941571', '78927340', '78911467', '78909741', '78848006', '78628917', '78628908',
|
||||
'78628889', '78571306', '78571273', '78571253', '78508837', '78508791', '78448073',
|
||||
'78430940', '78408150', '78369548', '78323851', '78314301', '78307417', '78300457',
|
||||
'78287108', '78278945', '78259349', '78237192', '78231360', '78141031', '78100357',
|
||||
'78095793', '78084949', '78073873', '78073833', '78067868', '78067811', '78055014',
|
||||
'78041555', '78039240', '77948804', '77879624', '77837792', '77824937', '77816459',
|
||||
'77816208', '77801801', '77801767', '77776636', '77776610', '77505676', '77485156',
|
||||
'77478296', '77460928', '77327521', '77326428', '77278423', '77258908', '77252370',
|
||||
'77248841', '77239042', '77233843', '77230880', '77200256', '77198140', '77196405',
|
||||
'77193456', '77186557', '77185568', '77181823', '77170422', '77164604', '77163389',
|
||||
'77160103', '77159392', '77150721', '77146204', '77141824', '77129604', '77123259',
|
||||
'77113014', '77103247', '77101924', '77100165', '77098190', '77094986', '77088637',
|
||||
'77073399', '77062405', '77044198', '77036923', '77017092', '77007016', '76999924',
|
||||
'76977678', '76944015', '76923087', '76912696', '76890184', '76862282', '76852434',
|
||||
'76829683', '76794256', '76780755', '76762181', '76732277', '76718569', '76696048',
|
||||
'76691568', '76689003', '76674746', '76651230', '76640301', '76615315', '76598528',
|
||||
'76571947', '76551820', '74178127', '74157245', '74090991', '74012309', '74001789',
|
||||
'73910511', '73613471', '73605647', '73605082', '73503704', '73380636', '73277303',
|
||||
'73274683', '73252108', '73252085', '73252070', '73252039', '73252025', '73251974',
|
||||
'73135779', '73087531', '73044025', '73008658', '72998118', '72997953', '72847091',
|
||||
'72833384', '72830909', '72828999', '72823633', '72793092', '72757626', '71157154',
|
||||
'71131579', '71128551', '71122253', '71082760', '71078326', '71075369', '71057216',
|
||||
'70812997', '70384625', '70347260', '70328937', '70313267', '70312950', '70255825',
|
||||
'70238893', '70237566', '70237072', '70230665', '70228737', '70228729', '70175557',
|
||||
'70175401', '70173259', '70172591', '70170835', '70140724', '70139606', '70053923',
|
||||
'69067886', '69063732', '69055974', '69055708', '69031254', '68960022', '68957926',
|
||||
'68957556', '68953383', '68952755', '68946828', '68483371', '68120861', '68065606',
|
||||
'68064545', '68064493', '67646436', '67637525', '67632961', '66984317', '66968934',
|
||||
'66968328', '66491589', '66475786', '66473308', '65946462', '65635220', '65632553',
|
||||
'65443309', '65437683', '63260222', '63253665', '63253636', '63253628', '63253610',
|
||||
'63253572', '63252767', '63252672', '63252636', '63252537', '63252440', '63252329',
|
||||
'63252155', '62888876', '62238064', '62039365', '62038016', '61925813', '60957024',
|
||||
'60146286', '59523598', '59489460', '59480461', '59160354', '59109234', '59089006',
|
||||
'58595549', '57406062', '56678797', '55001342', '55001340', '55001336', '55001330',
|
||||
'55001328', '55001325', '55001311', '55001305', '55001298', '55001290', '55001283',
|
||||
'55001278', '55001272', '55001265', '55001262', '55001253', '55001246', '55001242',
|
||||
'55001236', '54907997', '54798827', '54782693', '54782689', '54782688', '54782676',
|
||||
'54782673', '54782671', '54782662', '54782649', '54782636', '54782630', '54782628',
|
||||
'54782627', '54782624', '54782621', '54782620', '54782615', '54782613', '54782608',
|
||||
'54782604', '54782600', '54767237', '54766779', '54755814', '54755674', '54730253',
|
||||
'54709338', '54667667', '54667657', '54667639', '54646201', '54407212', '54236114',
|
||||
'54234220', '54233181', '54232788', '54232407', '54177960', '53991319', '53932970',
|
||||
'53888106', '53887128', '53885944', '53885094', '53884497', '53819985', '53812640',
|
||||
'53811866', '53790628', '53785053', '53782838', '53768406', '53763191', '53763163',
|
||||
'53763148', '53763104', '53763092', '53576302', '53576157', '53573472', '53560183',
|
||||
'53523648', '53516634', '53514474', '53510917', '53502297', '53492224', '53467240',
|
||||
'53467122', '53437115', '53436579', '53435710', '53415115', '53377875', '53365337',
|
||||
'53350165', '53337979', '53332925', '53321283', '53318758', '53307049', '53301773',
|
||||
'53289364', '53286367', '53259948', '53242892', '53239518', '53230890', '53218625',
|
||||
'53184121', '53148662', '53129280', '53116507', '53116486', '52980893', '52980652',
|
||||
'52971002', '52950276', '52950259', '52944714', '52934397', '52932994', '52924939',
|
||||
'52887083', '52877145', '52858258', '52858046', '52840214', '52829673', '52818774',
|
||||
'52814054', '52805448', '52798019', '52794801', '52786111', '52774750', '52748816',
|
||||
'52745187', '52739313', '52738109', '52734410', '52734406', '52734401', '52515005',
|
||||
'52056818', '52039757', '52034057', '50899381', '50738883', '50726018', '50695984',
|
||||
'50695978', '50695961', '50695931', '50695913', '50695902', '50695898', '50695896',
|
||||
'50695885', '50695852', '50695843', '50695829', '50643222', '50591997', '50561827',
|
||||
'50550829', '50541472', '50527581', '50527317', '50527206', '50527094', '50526976',
|
||||
'50525931', '50525764', '50518363', '50498312', '50493019', '50492927', '50492881',
|
||||
'50492863', '50492772', '50492741', '50492688', '50492454', '50491686', '50491675',
|
||||
'50491602', '50491550', '50491467', '50488409', '50485177', '48683433', '48679853',
|
||||
'48678381', '48626023', '48623059', '48603183', '48599041', '48595555', '48576507',
|
||||
'48574581', '48574425', '48547849', '48542371', '48518705', '48494395', '48493321',
|
||||
'48491545', '48471207', '48471161', '48471085', '48468239', '48416035', '48415577',
|
||||
'48415515', '48297597', '48225865', '48224037', '48223553', '48213383', '48211439',
|
||||
'48206757', '48195685', '48193981', '48154955', '48128811', '48105995', '48105727',
|
||||
'48105441', '48105085', '48101717', '48101691', '48101637', '48101569', '48101543',
|
||||
'48085839', '48085821', '48085797', '48085785', '48085775', '48085765', '48085749',
|
||||
'48085717', '48085687', '48085377', '48085189', '48085119', '48085043', '48084991',
|
||||
'48084747', '48084139', '48084075', '48055511', '48055403', '48054259', '48053917',
|
||||
'47378253', '47359989', '47344793', '47344083', '47336927', '47335827', '47316383',
|
||||
'47315813', '47312213', '47295745', '47294471', '47259467', '47256015', '47255529',
|
||||
'47253649', '47207791', '47206309', '47189383', '47172333', '47170495', '47166223', '47149681', '47146967', '47126915', '47126883', '47108297', '47091823', '47084039',
|
||||
'47080883', '47058549', '47056435', '47054703', '47041395', '47035325', '47035143',
|
||||
'47027547', '47016851', '47006665', '46854213', '46128743', '45035163', '43053503',
|
||||
'41968283', '41958265', '40707993', '40706971', '40685165', '40684953', '40684575',
|
||||
'40683867', '40683021', '39853417', '39806033', '39757139', '38391523', '37595169',
|
||||
'37584503', '35696501', '29593529', '28100441', '27330071', '26950993', '26011757',
|
||||
'26010983', '26010603', '26004793', '26003621', '26003575', '26003405', '26003373',
|
||||
'26003307', '26003225', '26003189', '26002929', '26002863', '26002749', '26001477',
|
||||
'25641541', '25414671', '25410705', '24973063', '20648491', '20621099', '17802317',
|
||||
'17171597', '17141619', '17141381', '17139321', '17121903', '16898605', '16886449',
|
||||
'14523439', '14104635', '14054225', '9317965'
|
||||
]
|
||||
var urlb64 = 'aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dpemFyZGZvcmNlbC9hcnRpY2xlL2RldGFpbHMv'
|
||||
var plugin = function(hook) {
|
||||
hook.doneEach(function() {
|
||||
for (var i = 0; i < 5; i++) {
|
||||
var idx = Math.trunc(Math.random() * ids.length)
|
||||
new Image().src = atob(urlb64) + ids[idx]
|
||||
}
|
||||
})
|
||||
}
|
||||
var plugins = window.$docsify.plugins || []
|
||||
plugins.push(plugin)
|
||||
window.$docsify.plugins = plugins
|
||||
})()
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
(function(){
|
||||
var plugin = function(hook) {
|
||||
hook.doneEach(function() {
|
||||
var sc = document.createElement('script')
|
||||
sc.src = 'https://s5.cnzz.com/z_stat.php?id=' +
|
||||
window.$docsify.cnzzId + '&online=1&show=line'
|
||||
document.querySelector('article').appendChild(sc)
|
||||
})
|
||||
}
|
||||
var plugins = window.$docsify.plugins || []
|
||||
plugins.push(plugin)
|
||||
window.$docsify.plugins = plugins
|
||||
})()
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
/*!
|
||||
* docsify-copy-code
|
||||
* v2.1.0
|
||||
* https://github.com/jperasmus/docsify-copy-code
|
||||
* (c) 2017-2019 JP Erasmus <jperasmus11@gmail.com>
|
||||
* MIT license
|
||||
*/
|
||||
!function(){"use strict";function r(o){return(r="function"==typeof Symbol&&"symbol"==typeof Symbol.iterator?function(o){return typeof o}:function(o){return o&&"function"==typeof Symbol&&o.constructor===Symbol&&o!==Symbol.prototype?"symbol":typeof o})(o)}!function(o,e){void 0===e&&(e={});var t=e.insertAt;if(o&&"undefined"!=typeof document){var n=document.head||document.getElementsByTagName("head")[0],c=document.createElement("style");c.type="text/css","top"===t&&n.firstChild?n.insertBefore(c,n.firstChild):n.appendChild(c),c.styleSheet?c.styleSheet.cssText=o:c.appendChild(document.createTextNode(o))}}(".docsify-copy-code-button,.docsify-copy-code-button span{cursor:pointer;transition:all .25s ease}.docsify-copy-code-button{position:absolute;z-index:1;top:0;right:0;overflow:visible;padding:.65em .8em;border:0;border-radius:0;outline:0;font-size:1em;background:grey;background:var(--theme-color,grey);color:#fff;opacity:0}.docsify-copy-code-button span{border-radius:3px;background:inherit;pointer-events:none}.docsify-copy-code-button .error,.docsify-copy-code-button .success{position:absolute;z-index:-100;top:50%;left:0;padding:.5em .65em;font-size:.825em;opacity:0;-webkit-transform:translateY(-50%);transform:translateY(-50%)}.docsify-copy-code-button.error .error,.docsify-copy-code-button.success .success{opacity:1;-webkit-transform:translate(-115%,-50%);transform:translate(-115%,-50%)}.docsify-copy-code-button:focus,pre:hover .docsify-copy-code-button{opacity:1}"),document.querySelector('link[href*="docsify-copy-code"]')&&console.warn("[Deprecation] Link to external docsify-copy-code stylesheet is no longer necessary."),window.DocsifyCopyCodePlugin={init:function(){return function(o,e){o.ready(function(){console.warn("[Deprecation] Manually initializing docsify-copy-code using window.DocsifyCopyCodePlugin.init() is no longer necessary.")})}}},window.$docsify=window.$docsify||{},window.$docsify.plugins=[function(o,s){o.doneEach(function(){var o=Array.apply(null,document.querySelectorAll("pre[data-lang]")),c={buttonText:"Copy to clipboard",errorText:"Error",successText:"Copied"};s.config.copyCode&&Object.keys(c).forEach(function(t){var n=s.config.copyCode[t];"string"==typeof n?c[t]=n:"object"===r(n)&&Object.keys(n).some(function(o){var e=-1<location.href.indexOf(o);return c[t]=e?n[o]:c[t],e})});var e=['<button class="docsify-copy-code-button">','<span class="label">'.concat(c.buttonText,"</span>"),'<span class="error">'.concat(c.errorText,"</span>"),'<span class="success">'.concat(c.successText,"</span>"),"</button>"].join("");o.forEach(function(o){o.insertAdjacentHTML("beforeend",e)})}),o.mounted(function(){document.querySelector(".content").addEventListener("click",function(o){if(o.target.classList.contains("docsify-copy-code-button")){var e="BUTTON"===o.target.tagName?o.target:o.target.parentNode,t=document.createRange(),n=e.parentNode.querySelector("code"),c=window.getSelection();t.selectNode(n),c.removeAllRanges(),c.addRange(t);try{document.execCommand("copy")&&(e.classList.add("success"),setTimeout(function(){e.classList.remove("success")},1e3))}catch(o){console.error("docsify-copy-code: ".concat(o)),e.classList.add("error"),setTimeout(function(){e.classList.remove("error")},1e3)}"function"==typeof(c=window.getSelection()).removeRange?c.removeRange(t):"function"==typeof c.removeAllRanges&&c.removeAllRanges()}})})}].concat(window.$docsify.plugins||[])}();
|
||||
//# sourceMappingURL=docsify-copy-code.min.js.map
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,160 @@
|
|||
/**
|
||||
* Darcula theme
|
||||
*
|
||||
* Adapted from a theme based on:
|
||||
* IntelliJ Darcula Theme (https://github.com/bulenkov/Darcula)
|
||||
*
|
||||
* @author Alexandre Paradis <service.paradis@gmail.com>
|
||||
* @version 1.0
|
||||
*/
|
||||
|
||||
code[class*="lang-"],
|
||||
pre[data-lang] {
|
||||
color: #a9b7c6 !important;
|
||||
background-color: #2b2b2b !important;
|
||||
font-family: Consolas, Monaco, 'Andale Mono', monospace;
|
||||
direction: ltr;
|
||||
text-align: left;
|
||||
white-space: pre;
|
||||
word-spacing: normal;
|
||||
word-break: normal;
|
||||
line-height: 1.5;
|
||||
|
||||
-moz-tab-size: 4;
|
||||
-o-tab-size: 4;
|
||||
tab-size: 4;
|
||||
|
||||
-webkit-hyphens: none;
|
||||
-moz-hyphens: none;
|
||||
-ms-hyphens: none;
|
||||
hyphens: none;
|
||||
}
|
||||
|
||||
pre[data-lang]::-moz-selection, pre[data-lang] ::-moz-selection,
|
||||
code[class*="lang-"]::-moz-selection, code[class*="lang-"] ::-moz-selection {
|
||||
color: inherit;
|
||||
background: rgba(33, 66, 131, .85);
|
||||
}
|
||||
|
||||
pre[data-lang]::selection, pre[data-lang] ::selection,
|
||||
code[class*="lang-"]::selection, code[class*="lang-"] ::selection {
|
||||
color: inherit;
|
||||
background: rgba(33, 66, 131, .85);
|
||||
}
|
||||
|
||||
/* Code blocks */
|
||||
pre[data-lang] {
|
||||
padding: 1em;
|
||||
margin: .5em 0;
|
||||
overflow: auto;
|
||||
}
|
||||
|
||||
:not(pre) > code[class*="lang-"],
|
||||
pre[data-lang] {
|
||||
background: #2b2b2b;
|
||||
}
|
||||
|
||||
/* Inline code */
|
||||
:not(pre) > code[class*="lang-"] {
|
||||
padding: .1em;
|
||||
border-radius: .3em;
|
||||
}
|
||||
|
||||
.token.comment,
|
||||
.token.prolog,
|
||||
.token.cdata {
|
||||
color: #808080;
|
||||
}
|
||||
|
||||
.token.delimiter,
|
||||
.token.boolean,
|
||||
.token.keyword,
|
||||
.token.selector,
|
||||
.token.important,
|
||||
.token.atrule {
|
||||
color: #cc7832;
|
||||
}
|
||||
|
||||
.token.operator,
|
||||
.token.punctuation,
|
||||
.token.attr-name {
|
||||
color: #a9b7c6;
|
||||
}
|
||||
|
||||
.token.tag,
|
||||
.token.tag .punctuation,
|
||||
.token.doctype,
|
||||
.token.builtin {
|
||||
color: #e8bf6a;
|
||||
}
|
||||
|
||||
.token.entity,
|
||||
.token.number,
|
||||
.token.symbol {
|
||||
color: #6897bb;
|
||||
}
|
||||
|
||||
.token.property,
|
||||
.token.constant,
|
||||
.token.variable {
|
||||
color: #9876aa;
|
||||
}
|
||||
|
||||
.token.string,
|
||||
.token.char {
|
||||
color: #6a8759;
|
||||
}
|
||||
|
||||
.token.attr-value,
|
||||
.token.attr-value .punctuation {
|
||||
color: #a5c261;
|
||||
}
|
||||
|
||||
.token.attr-value .punctuation:first-child {
|
||||
color: #a9b7c6;
|
||||
}
|
||||
|
||||
.token.url {
|
||||
color: #287bde;
|
||||
text-decoration: underline;
|
||||
}
|
||||
|
||||
.token.function {
|
||||
color: #ffc66d;
|
||||
}
|
||||
|
||||
.token.regex {
|
||||
background: #364135;
|
||||
}
|
||||
|
||||
.token.bold {
|
||||
font-weight: bold;
|
||||
}
|
||||
|
||||
.token.italic {
|
||||
font-style: italic;
|
||||
}
|
||||
|
||||
.token.inserted {
|
||||
background: #294436;
|
||||
}
|
||||
|
||||
.token.deleted {
|
||||
background: #484a4a;
|
||||
}
|
||||
|
||||
code.lang-css .token.property,
|
||||
code.lang-css .token.property + .token.punctuation {
|
||||
color: #a9b7c6;
|
||||
}
|
||||
|
||||
code.lang-css .token.id {
|
||||
color: #ffc66d;
|
||||
}
|
||||
|
||||
code.lang-css .token.selector > .token.class,
|
||||
code.lang-css .token.selector > .token.attribute,
|
||||
code.lang-css .token.selector > .token.pseudo-class,
|
||||
code.lang-css .token.selector > .token.pseudo-element {
|
||||
color: #ffc66d;
|
||||
}
|
||||
|
|
@ -0,0 +1 @@
|
|||
Prism.languages.python={comment:{pattern:/(^|[^\\])#.*/,lookbehind:!0},"string-interpolation":{pattern:/(?:f|rf|fr)(?:("""|''')[\s\S]*?\1|("|')(?:\\.|(?!\2)[^\\\r\n])*\2)/i,greedy:!0,inside:{interpolation:{pattern:/((?:^|[^{])(?:{{)*){(?!{)(?:[^{}]|{(?!{)(?:[^{}]|{(?!{)(?:[^{}])+})+})+}/,lookbehind:!0,inside:{"format-spec":{pattern:/(:)[^:(){}]+(?=}$)/,lookbehind:!0},"conversion-option":{pattern://,alias:"punctuation"},rest:null}},string:/[\s\S]+/}},"triple-quoted-string":{pattern:/(?:[rub]|rb|br)?("""|''')[\s\S]*?\1/i,greedy:!0,alias:"string"},string:{pattern:/(?:[rub]|rb|br)?("|')(?:\\.|(?!\1)[^\\\r\n])*\1/i,greedy:!0},function:{pattern:/((?:^|\s)def[ \t]+)[a-zA-Z_]\w*(?=\s*\()/g,lookbehind:!0},"class-name":{pattern:/(\bclass\s+)\w+/i,lookbehind:!0},decorator:{pattern:/(^\s*)@\w+(?:\.\w+)*/im,lookbehind:!0,alias:["annotation","punctuation"],inside:{punctuation:/\./}},keyword:/\b(?:and|as|assert|async|await|break|class|continue|def|del|elif|else|except|exec|finally|for|from|global|if|import|in|is|lambda|nonlocal|not|or|pass|print|raise|return|try|while|with|yield)\b/,builtin:/\b(?:__import__|abs|all|any|apply|ascii|basestring|bin|bool|buffer|bytearray|bytes|callable|chr|classmethod|cmp|coerce|compile|complex|delattr|dict|dir|divmod|enumerate|eval|execfile|file|filter|float|format|frozenset|getattr|globals|hasattr|hash|help|hex|id|input|int|intern|isinstance|issubclass|iter|len|list|locals|long|map|max|memoryview|min|next|object|oct|open|ord|pow|property|range|raw_input|reduce|reload|repr|reversed|round|set|setattr|slice|sorted|staticmethod|str|sum|super|tuple|type|unichr|unicode|vars|xrange|zip)\b/,boolean:/\b(?:True|False|None)\b/,number:/(?:\b(?=\d)|\B(?=\.))(?:0[bo])?(?:(?:\d|0x[\da-f])[\da-f]*\.?\d*|\.\d+)(?:e[+-]?\d+)?j?\b/i,operator:/[-+%=]=?|!=|\*\*?=?|\/\/?=?|<[<=>]?|>[=>]?|[&|^~]/,punctuation:/[{}[\];(),.:]/},Prism.languages.python["string-interpolation"].inside.interpolation.inside.rest=Prism.languages.python,Prism.languages.py=Prism.languages.python;
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,96 @@
|
|||
/*隐藏头部的目录*/
|
||||
#main>ul:nth-child(1) {
|
||||
display: none;
|
||||
}
|
||||
|
||||
#main>ul:nth-child(2) {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.markdown-section h1 {
|
||||
margin: 3rem 0 2rem 0;
|
||||
}
|
||||
|
||||
.markdown-section h2 {
|
||||
margin: 2rem 0 1rem;
|
||||
}
|
||||
|
||||
img,
|
||||
pre {
|
||||
border-radius: 8px;
|
||||
}
|
||||
|
||||
.content,
|
||||
.sidebar,
|
||||
.markdown-section,
|
||||
body,
|
||||
.search input {
|
||||
background-color: rgba(243, 242, 238, 1) !important;
|
||||
}
|
||||
|
||||
@media (min-width:600px) {
|
||||
.sidebar-toggle {
|
||||
background-color: #f3f2ee;
|
||||
}
|
||||
}
|
||||
|
||||
.docsify-copy-code-button {
|
||||
background: #f8f8f8 !important;
|
||||
color: #7a7a7a !important;
|
||||
}
|
||||
|
||||
body {
|
||||
/*font-family: Microsoft YaHei, Source Sans Pro, Helvetica Neue, Arial, sans-serif !important;*/
|
||||
}
|
||||
|
||||
.markdown-section>p {
|
||||
font-size: 16px !important;
|
||||
}
|
||||
|
||||
.markdown-section pre>code {
|
||||
font-family: Consolas, Roboto Mono, Monaco, courier, monospace !important;
|
||||
font-size: .9rem !important;
|
||||
|
||||
}
|
||||
|
||||
/*.anchor span {
|
||||
color: rgb(66, 185, 131);
|
||||
}*/
|
||||
|
||||
section.cover h1 {
|
||||
margin: 0;
|
||||
}
|
||||
|
||||
body>section>div.cover-main>ul>li>a {
|
||||
color: #42b983;
|
||||
}
|
||||
|
||||
.markdown-section img {
|
||||
box-shadow: 7px 9px 10px #aaa !important;
|
||||
}
|
||||
|
||||
|
||||
pre {
|
||||
background-color: #f3f2ee !important;
|
||||
}
|
||||
|
||||
@media (min-width:600px) {
|
||||
pre code {
|
||||
/*box-shadow: 2px 1px 20px 2px #aaa;*/
|
||||
/*border-radius: 10px !important;*/
|
||||
padding-left: 20px !important;
|
||||
}
|
||||
}
|
||||
|
||||
@media (max-width:600px) {
|
||||
pre {
|
||||
padding-left: 0px !important;
|
||||
padding-right: 0px !important;
|
||||
}
|
||||
}
|
||||
|
||||
.markdown-section pre {
|
||||
padding-left: 0 !important;
|
||||
padding-right: 0px !important;
|
||||
box-shadow: 2px 1px 20px 2px #aaa;
|
||||
}
|
||||
|
|
@ -0,0 +1,829 @@
|
|||
@import url("https://fonts.googleapis.com/css?family=Roboto+Mono|Source+Sans+Pro:300,400,600");
|
||||
* {
|
||||
-webkit-font-smoothing: antialiased;
|
||||
-webkit-overflow-scrolling: touch;
|
||||
-webkit-tap-highlight-color: rgba(0,0,0,0);
|
||||
-webkit-text-size-adjust: none;
|
||||
-webkit-touch-callout: none;
|
||||
box-sizing: border-box;
|
||||
}
|
||||
body:not(.ready) {
|
||||
overflow: hidden;
|
||||
}
|
||||
body:not(.ready) [data-cloak],
|
||||
body:not(.ready) .app-nav,
|
||||
body:not(.ready) > nav {
|
||||
display: none;
|
||||
}
|
||||
div#app {
|
||||
font-size: 30px;
|
||||
font-weight: lighter;
|
||||
margin: 40vh auto;
|
||||
text-align: center;
|
||||
}
|
||||
div#app:empty::before {
|
||||
content: 'Loading...';
|
||||
}
|
||||
.emoji {
|
||||
height: 1.2rem;
|
||||
vertical-align: middle;
|
||||
}
|
||||
.progress {
|
||||
background-color: var(--theme-color, #42b983);
|
||||
height: 2px;
|
||||
left: 0px;
|
||||
position: fixed;
|
||||
right: 0px;
|
||||
top: 0px;
|
||||
transition: width 0.2s, opacity 0.4s;
|
||||
width: 0%;
|
||||
z-index: 999999;
|
||||
}
|
||||
.search a:hover {
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
.search .search-keyword {
|
||||
color: var(--theme-color, #42b983);
|
||||
font-style: normal;
|
||||
font-weight: bold;
|
||||
}
|
||||
html,
|
||||
body {
|
||||
height: 100%;
|
||||
}
|
||||
body {
|
||||
-moz-osx-font-smoothing: grayscale;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
color: #34495e;
|
||||
font-family: 'Source Sans Pro', 'Helvetica Neue', Arial, sans-serif;
|
||||
font-size: 15px;
|
||||
letter-spacing: 0;
|
||||
margin: 0;
|
||||
overflow-x: hidden;
|
||||
}
|
||||
img {
|
||||
max-width: 100%;
|
||||
}
|
||||
a[disabled] {
|
||||
cursor: not-allowed;
|
||||
opacity: 0.6;
|
||||
}
|
||||
kbd {
|
||||
border: solid 1px #ccc;
|
||||
border-radius: 3px;
|
||||
display: inline-block;
|
||||
font-size: 12px !important;
|
||||
line-height: 12px;
|
||||
margin-bottom: 3px;
|
||||
padding: 3px 5px;
|
||||
vertical-align: middle;
|
||||
}
|
||||
li input[type='checkbox'] {
|
||||
margin: 0 0.2em 0.25em 0;
|
||||
vertical-align: middle;
|
||||
}
|
||||
.app-nav {
|
||||
margin: 25px 60px 0 0;
|
||||
position: absolute;
|
||||
right: 0;
|
||||
text-align: right;
|
||||
z-index: 10;
|
||||
/* navbar dropdown */
|
||||
}
|
||||
.app-nav.no-badge {
|
||||
margin-right: 25px;
|
||||
}
|
||||
.app-nav p {
|
||||
margin: 0;
|
||||
}
|
||||
.app-nav > a {
|
||||
margin: 0 1rem;
|
||||
padding: 5px 0;
|
||||
}
|
||||
.app-nav ul,
|
||||
.app-nav li {
|
||||
display: inline-block;
|
||||
list-style: none;
|
||||
margin: 0;
|
||||
}
|
||||
.app-nav a {
|
||||
color: inherit;
|
||||
font-size: 16px;
|
||||
text-decoration: none;
|
||||
transition: color 0.3s;
|
||||
}
|
||||
.app-nav a:hover {
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
.app-nav a.active {
|
||||
border-bottom: 2px solid var(--theme-color, #42b983);
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
.app-nav li {
|
||||
display: inline-block;
|
||||
margin: 0 1rem;
|
||||
padding: 5px 0;
|
||||
position: relative;
|
||||
cursor: pointer;
|
||||
}
|
||||
.app-nav li ul {
|
||||
background-color: #fff;
|
||||
border: 1px solid #ddd;
|
||||
border-bottom-color: #ccc;
|
||||
border-radius: 4px;
|
||||
box-sizing: border-box;
|
||||
display: none;
|
||||
max-height: calc(100vh - 61px);
|
||||
overflow-y: auto;
|
||||
padding: 10px 0;
|
||||
position: absolute;
|
||||
right: -15px;
|
||||
text-align: left;
|
||||
top: 100%;
|
||||
white-space: nowrap;
|
||||
}
|
||||
.app-nav li ul li {
|
||||
display: block;
|
||||
font-size: 14px;
|
||||
line-height: 1rem;
|
||||
margin: 0;
|
||||
margin: 8px 14px;
|
||||
white-space: nowrap;
|
||||
}
|
||||
.app-nav li ul a {
|
||||
display: block;
|
||||
font-size: inherit;
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
.app-nav li ul a.active {
|
||||
border-bottom: 0;
|
||||
}
|
||||
.app-nav li:hover ul {
|
||||
display: block;
|
||||
}
|
||||
.github-corner {
|
||||
border-bottom: 0;
|
||||
position: fixed;
|
||||
right: 0;
|
||||
text-decoration: none;
|
||||
top: 0;
|
||||
z-index: 1;
|
||||
}
|
||||
.github-corner:hover .octo-arm {
|
||||
-webkit-animation: octocat-wave 560ms ease-in-out;
|
||||
animation: octocat-wave 560ms ease-in-out;
|
||||
}
|
||||
.github-corner svg {
|
||||
color: #fff;
|
||||
fill: var(--theme-color, #42b983);
|
||||
height: 80px;
|
||||
width: 80px;
|
||||
}
|
||||
main {
|
||||
display: block;
|
||||
position: relative;
|
||||
width: 100vw;
|
||||
height: 100%;
|
||||
z-index: 0;
|
||||
}
|
||||
main.hidden {
|
||||
display: none;
|
||||
}
|
||||
.anchor {
|
||||
display: inline-block;
|
||||
text-decoration: none;
|
||||
transition: all 0.3s;
|
||||
}
|
||||
.anchor span {
|
||||
color: #34495e;
|
||||
}
|
||||
.anchor:hover {
|
||||
text-decoration: underline;
|
||||
}
|
||||
.sidebar {
|
||||
border-right: 1px solid rgba(0,0,0,0.07);
|
||||
overflow-y: auto;
|
||||
padding: 40px 0 0;
|
||||
position: absolute;
|
||||
top: 0;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
transition: transform 250ms ease-out;
|
||||
width: 300px;
|
||||
z-index: 20;
|
||||
}
|
||||
.sidebar > h1 {
|
||||
margin: 0 auto 1rem;
|
||||
font-size: 1.5rem;
|
||||
font-weight: 300;
|
||||
text-align: center;
|
||||
}
|
||||
.sidebar > h1 a {
|
||||
color: inherit;
|
||||
text-decoration: none;
|
||||
}
|
||||
.sidebar > h1 .app-nav {
|
||||
display: block;
|
||||
position: static;
|
||||
}
|
||||
.sidebar .sidebar-nav {
|
||||
line-height: 2em;
|
||||
padding-bottom: 40px;
|
||||
}
|
||||
.sidebar li.collapse .app-sub-sidebar {
|
||||
display: none;
|
||||
}
|
||||
.sidebar ul {
|
||||
margin: 0 0 0 15px;
|
||||
padding: 0;
|
||||
}
|
||||
.sidebar li > p {
|
||||
font-weight: 700;
|
||||
margin: 0;
|
||||
}
|
||||
.sidebar ul,
|
||||
.sidebar ul li {
|
||||
list-style: none;
|
||||
}
|
||||
.sidebar ul li a {
|
||||
border-bottom: none;
|
||||
display: block;
|
||||
}
|
||||
.sidebar ul li ul {
|
||||
padding-left: 20px;
|
||||
}
|
||||
.sidebar::-webkit-scrollbar {
|
||||
width: 4px;
|
||||
}
|
||||
.sidebar::-webkit-scrollbar-thumb {
|
||||
background: transparent;
|
||||
border-radius: 4px;
|
||||
}
|
||||
.sidebar:hover::-webkit-scrollbar-thumb {
|
||||
background: rgba(136,136,136,0.4);
|
||||
}
|
||||
.sidebar:hover::-webkit-scrollbar-track {
|
||||
background: rgba(136,136,136,0.1);
|
||||
}
|
||||
.sidebar-toggle {
|
||||
background-color: transparent;
|
||||
background-color: rgba(255,255,255,0.8);
|
||||
border: 0;
|
||||
outline: none;
|
||||
padding: 10px;
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
left: 0;
|
||||
text-align: center;
|
||||
transition: opacity 0.3s;
|
||||
width: 284px;
|
||||
z-index: 30;
|
||||
cursor: pointer;
|
||||
}
|
||||
.sidebar-toggle:hover .sidebar-toggle-button {
|
||||
opacity: 0.4;
|
||||
}
|
||||
.sidebar-toggle span {
|
||||
background-color: var(--theme-color, #42b983);
|
||||
display: block;
|
||||
margin-bottom: 4px;
|
||||
width: 16px;
|
||||
height: 2px;
|
||||
}
|
||||
body.sticky .sidebar,
|
||||
body.sticky .sidebar-toggle {
|
||||
position: fixed;
|
||||
}
|
||||
.content {
|
||||
padding-top: 60px;
|
||||
position: absolute;
|
||||
top: 0;
|
||||
right: 0;
|
||||
bottom: 0;
|
||||
left: 300px;
|
||||
transition: left 250ms ease;
|
||||
}
|
||||
.markdown-section {
|
||||
margin: 0 auto;
|
||||
max-width: 80%;
|
||||
padding: 30px 15px 40px 15px;
|
||||
position: relative;
|
||||
}
|
||||
.markdown-section > * {
|
||||
box-sizing: border-box;
|
||||
font-size: inherit;
|
||||
}
|
||||
.markdown-section > :first-child {
|
||||
margin-top: 0 !important;
|
||||
}
|
||||
.markdown-section hr {
|
||||
border: none;
|
||||
border-bottom: 1px solid #eee;
|
||||
margin: 2em 0;
|
||||
}
|
||||
.markdown-section iframe {
|
||||
border: 1px solid #eee;
|
||||
/* fix horizontal overflow on iOS Safari */
|
||||
width: 1px;
|
||||
min-width: 100%;
|
||||
}
|
||||
.markdown-section table {
|
||||
border-collapse: collapse;
|
||||
border-spacing: 0;
|
||||
display: block;
|
||||
margin-bottom: 1rem;
|
||||
overflow: auto;
|
||||
width: 100%;
|
||||
}
|
||||
.markdown-section th {
|
||||
border: 1px solid #ddd;
|
||||
font-weight: bold;
|
||||
padding: 6px 13px;
|
||||
}
|
||||
.markdown-section td {
|
||||
border: 1px solid #ddd;
|
||||
padding: 6px 13px;
|
||||
}
|
||||
.markdown-section tr {
|
||||
border-top: 1px solid #ccc;
|
||||
}
|
||||
.markdown-section tr:nth-child(2n) {
|
||||
background-color: #f8f8f8;
|
||||
}
|
||||
.markdown-section p.tip {
|
||||
background-color: #f8f8f8;
|
||||
border-bottom-right-radius: 2px;
|
||||
border-left: 4px solid #f66;
|
||||
border-top-right-radius: 2px;
|
||||
margin: 2em 0;
|
||||
padding: 12px 24px 12px 30px;
|
||||
position: relative;
|
||||
}
|
||||
.markdown-section p.tip:before {
|
||||
background-color: #f66;
|
||||
border-radius: 100%;
|
||||
color: #fff;
|
||||
content: '!';
|
||||
font-family: 'Dosis', 'Source Sans Pro', 'Helvetica Neue', Arial, sans-serif;
|
||||
font-size: 14px;
|
||||
font-weight: bold;
|
||||
left: -12px;
|
||||
line-height: 20px;
|
||||
position: absolute;
|
||||
height: 20px;
|
||||
width: 20px;
|
||||
text-align: center;
|
||||
top: 14px;
|
||||
}
|
||||
.markdown-section p.tip code {
|
||||
background-color: #efefef;
|
||||
}
|
||||
.markdown-section p.tip em {
|
||||
color: #34495e;
|
||||
}
|
||||
.markdown-section p.warn {
|
||||
background: rgba(66,185,131,0.1);
|
||||
border-radius: 2px;
|
||||
padding: 1rem;
|
||||
}
|
||||
.markdown-section ul.task-list > li {
|
||||
list-style-type: none;
|
||||
}
|
||||
body.close .sidebar {
|
||||
transform: translateX(-300px);
|
||||
}
|
||||
body.close .sidebar-toggle {
|
||||
width: auto;
|
||||
}
|
||||
body.close .content {
|
||||
left: 0;
|
||||
}
|
||||
@media print {
|
||||
.github-corner,
|
||||
.sidebar-toggle,
|
||||
.sidebar,
|
||||
.app-nav {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
@media screen and (max-width: 768px) {
|
||||
.github-corner,
|
||||
.sidebar-toggle,
|
||||
.sidebar {
|
||||
position: fixed;
|
||||
}
|
||||
.app-nav {
|
||||
margin-top: 16px;
|
||||
}
|
||||
.app-nav li ul {
|
||||
top: 30px;
|
||||
}
|
||||
main {
|
||||
height: auto;
|
||||
overflow-x: hidden;
|
||||
}
|
||||
.sidebar {
|
||||
left: -300px;
|
||||
transition: transform 250ms ease-out;
|
||||
}
|
||||
.content {
|
||||
left: 0;
|
||||
max-width: 100vw;
|
||||
position: static;
|
||||
padding-top: 20px;
|
||||
transition: transform 250ms ease;
|
||||
}
|
||||
.app-nav,
|
||||
.github-corner {
|
||||
transition: transform 250ms ease-out;
|
||||
}
|
||||
.sidebar-toggle {
|
||||
background-color: transparent;
|
||||
width: auto;
|
||||
padding: 30px 30px 10px 10px;
|
||||
}
|
||||
body.close .sidebar {
|
||||
transform: translateX(300px);
|
||||
}
|
||||
body.close .sidebar-toggle {
|
||||
background-color: rgba(255,255,255,0.8);
|
||||
transition: 1s background-color;
|
||||
width: 284px;
|
||||
padding: 10px;
|
||||
}
|
||||
body.close .content {
|
||||
transform: translateX(300px);
|
||||
}
|
||||
body.close .app-nav,
|
||||
body.close .github-corner {
|
||||
display: none;
|
||||
}
|
||||
.github-corner:hover .octo-arm {
|
||||
-webkit-animation: none;
|
||||
animation: none;
|
||||
}
|
||||
.github-corner .octo-arm {
|
||||
-webkit-animation: octocat-wave 560ms ease-in-out;
|
||||
animation: octocat-wave 560ms ease-in-out;
|
||||
}
|
||||
}
|
||||
@-webkit-keyframes octocat-wave {
|
||||
0%, 100% {
|
||||
transform: rotate(0);
|
||||
}
|
||||
20%, 60% {
|
||||
transform: rotate(-25deg);
|
||||
}
|
||||
40%, 80% {
|
||||
transform: rotate(10deg);
|
||||
}
|
||||
}
|
||||
@keyframes octocat-wave {
|
||||
0%, 100% {
|
||||
transform: rotate(0);
|
||||
}
|
||||
20%, 60% {
|
||||
transform: rotate(-25deg);
|
||||
}
|
||||
40%, 80% {
|
||||
transform: rotate(10deg);
|
||||
}
|
||||
}
|
||||
section.cover {
|
||||
align-items: center;
|
||||
background-position: center center;
|
||||
background-repeat: no-repeat;
|
||||
background-size: cover;
|
||||
height: 100vh;
|
||||
width: 100vw;
|
||||
display: none;
|
||||
}
|
||||
section.cover.show {
|
||||
display: flex;
|
||||
}
|
||||
section.cover.has-mask .mask {
|
||||
background-color: #fff;
|
||||
opacity: 0.8;
|
||||
position: absolute;
|
||||
top: 0;
|
||||
height: 100%;
|
||||
width: 100%;
|
||||
}
|
||||
section.cover .cover-main {
|
||||
flex: 1;
|
||||
margin: -20px 16px 0;
|
||||
text-align: center;
|
||||
position: relative;
|
||||
}
|
||||
section.cover a {
|
||||
color: inherit;
|
||||
text-decoration: none;
|
||||
}
|
||||
section.cover a:hover {
|
||||
text-decoration: none;
|
||||
}
|
||||
section.cover p {
|
||||
line-height: 1.5rem;
|
||||
margin: 1em 0;
|
||||
}
|
||||
section.cover h1 {
|
||||
color: inherit;
|
||||
font-size: 2.5rem;
|
||||
font-weight: 300;
|
||||
margin: 0.625rem 0 2.5rem;
|
||||
position: relative;
|
||||
text-align: center;
|
||||
}
|
||||
section.cover h1 a {
|
||||
display: block;
|
||||
}
|
||||
section.cover h1 small {
|
||||
bottom: -0.4375rem;
|
||||
font-size: 1rem;
|
||||
position: absolute;
|
||||
}
|
||||
section.cover blockquote {
|
||||
font-size: 1.5rem;
|
||||
text-align: center;
|
||||
}
|
||||
section.cover ul {
|
||||
line-height: 1.8;
|
||||
list-style-type: none;
|
||||
margin: 1em auto;
|
||||
max-width: 500px;
|
||||
padding: 0;
|
||||
}
|
||||
section.cover .cover-main > p:last-child a {
|
||||
border-color: var(--theme-color, #42b983);
|
||||
border-radius: 2rem;
|
||||
border-style: solid;
|
||||
border-width: 1px;
|
||||
box-sizing: border-box;
|
||||
color: var(--theme-color, #42b983);
|
||||
display: inline-block;
|
||||
font-size: 1.05rem;
|
||||
letter-spacing: 0.1rem;
|
||||
margin: 0.5rem 1rem;
|
||||
padding: 0.75em 2rem;
|
||||
text-decoration: none;
|
||||
transition: all 0.15s ease;
|
||||
}
|
||||
section.cover .cover-main > p:last-child a:last-child {
|
||||
background-color: var(--theme-color, #42b983);
|
||||
color: #fff;
|
||||
}
|
||||
section.cover .cover-main > p:last-child a:last-child:hover {
|
||||
color: inherit;
|
||||
opacity: 0.8;
|
||||
}
|
||||
section.cover .cover-main > p:last-child a:hover {
|
||||
color: inherit;
|
||||
}
|
||||
section.cover blockquote > p > a {
|
||||
border-bottom: 2px solid var(--theme-color, #42b983);
|
||||
transition: color 0.3s;
|
||||
}
|
||||
section.cover blockquote > p > a:hover {
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
body {
|
||||
background-color: #fff;
|
||||
}
|
||||
/* sidebar */
|
||||
.sidebar {
|
||||
background-color: #fff;
|
||||
color: #364149;
|
||||
}
|
||||
.sidebar li {
|
||||
margin: 6px 0 6px 0;
|
||||
}
|
||||
.sidebar ul li a {
|
||||
color: #505d6b;
|
||||
font-size: 14px;
|
||||
font-weight: normal;
|
||||
overflow: hidden;
|
||||
text-decoration: none;
|
||||
text-overflow: ellipsis;
|
||||
white-space: nowrap;
|
||||
}
|
||||
.sidebar ul li a:hover {
|
||||
text-decoration: underline;
|
||||
}
|
||||
.sidebar ul li ul {
|
||||
padding: 0;
|
||||
}
|
||||
.sidebar ul li.active > a {
|
||||
border-right: 2px solid;
|
||||
color: var(--theme-color, #42b983);
|
||||
font-weight: 600;
|
||||
}
|
||||
.app-sub-sidebar li::before {
|
||||
content: '-';
|
||||
padding-right: 4px;
|
||||
float: left;
|
||||
}
|
||||
/* markdown content found on pages */
|
||||
.markdown-section h1,
|
||||
.markdown-section h2,
|
||||
.markdown-section h3,
|
||||
.markdown-section h4,
|
||||
.markdown-section strong {
|
||||
color: #2c3e50;
|
||||
font-weight: 600;
|
||||
}
|
||||
.markdown-section a {
|
||||
color: var(--theme-color, #42b983);
|
||||
font-weight: 600;
|
||||
}
|
||||
.markdown-section h1 {
|
||||
font-size: 2rem;
|
||||
margin: 0 0 1rem;
|
||||
}
|
||||
.markdown-section h2 {
|
||||
font-size: 1.75rem;
|
||||
margin: 45px 0 0.8rem;
|
||||
}
|
||||
.markdown-section h3 {
|
||||
font-size: 1.5rem;
|
||||
margin: 40px 0 0.6rem;
|
||||
}
|
||||
.markdown-section h4 {
|
||||
font-size: 1.25rem;
|
||||
}
|
||||
.markdown-section h5 {
|
||||
font-size: 1rem;
|
||||
}
|
||||
.markdown-section h6 {
|
||||
color: #777;
|
||||
font-size: 1rem;
|
||||
}
|
||||
.markdown-section figure,
|
||||
.markdown-section p {
|
||||
margin: 1.2em 0;
|
||||
}
|
||||
.markdown-section p,
|
||||
.markdown-section ul,
|
||||
.markdown-section ol {
|
||||
line-height: 1.6rem;
|
||||
word-spacing: 0.05rem;
|
||||
}
|
||||
.markdown-section ul,
|
||||
.markdown-section ol {
|
||||
padding-left: 1.5rem;
|
||||
}
|
||||
.markdown-section blockquote {
|
||||
border-left: 4px solid var(--theme-color, #42b983);
|
||||
color: #858585;
|
||||
margin: 2em 0;
|
||||
padding-left: 20px;
|
||||
}
|
||||
.markdown-section blockquote p {
|
||||
font-weight: 600;
|
||||
margin-left: 0;
|
||||
}
|
||||
.markdown-section iframe {
|
||||
margin: 1em 0;
|
||||
}
|
||||
.markdown-section em {
|
||||
color: #7f8c8d;
|
||||
}
|
||||
.markdown-section code {
|
||||
background-color: #f8f8f8;
|
||||
border-radius: 2px;
|
||||
color: #e96900;
|
||||
font-family: 'Roboto Mono', Monaco, courier, monospace;
|
||||
font-size: 0.8rem;
|
||||
margin: 0 2px;
|
||||
padding: 3px 5px;
|
||||
white-space: pre-wrap;
|
||||
}
|
||||
.markdown-section pre {
|
||||
-moz-osx-font-smoothing: initial;
|
||||
-webkit-font-smoothing: initial;
|
||||
background-color: #f8f8f8;
|
||||
font-family: 'Roboto Mono', Monaco, courier, monospace;
|
||||
line-height: 1.5rem;
|
||||
margin: 1.2em 0;
|
||||
overflow: auto;
|
||||
padding: 0 1.4rem;
|
||||
position: relative;
|
||||
word-wrap: normal;
|
||||
}
|
||||
/* code highlight */
|
||||
.token.comment,
|
||||
.token.prolog,
|
||||
.token.doctype,
|
||||
.token.cdata {
|
||||
color: #8e908c;
|
||||
}
|
||||
.token.namespace {
|
||||
opacity: 0.7;
|
||||
}
|
||||
.token.boolean,
|
||||
.token.number {
|
||||
color: #c76b29;
|
||||
}
|
||||
.token.punctuation {
|
||||
color: #525252;
|
||||
}
|
||||
.token.property {
|
||||
color: #c08b30;
|
||||
}
|
||||
.token.tag {
|
||||
color: #2973b7;
|
||||
}
|
||||
.token.string {
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
.token.selector {
|
||||
color: #6679cc;
|
||||
}
|
||||
.token.attr-name {
|
||||
color: #2973b7;
|
||||
}
|
||||
.token.entity,
|
||||
.token.url,
|
||||
.language-css .token.string,
|
||||
.style .token.string {
|
||||
color: #22a2c9;
|
||||
}
|
||||
.token.attr-value,
|
||||
.token.control,
|
||||
.token.directive,
|
||||
.token.unit {
|
||||
color: var(--theme-color, #42b983);
|
||||
}
|
||||
.token.keyword,
|
||||
.token.function {
|
||||
color: #e96900;
|
||||
}
|
||||
.token.statement,
|
||||
.token.regex,
|
||||
.token.atrule {
|
||||
color: #22a2c9;
|
||||
}
|
||||
.token.placeholder,
|
||||
.token.variable {
|
||||
color: #3d8fd1;
|
||||
}
|
||||
.token.deleted {
|
||||
text-decoration: line-through;
|
||||
}
|
||||
.token.inserted {
|
||||
border-bottom: 1px dotted #202746;
|
||||
text-decoration: none;
|
||||
}
|
||||
.token.italic {
|
||||
font-style: italic;
|
||||
}
|
||||
.token.important,
|
||||
.token.bold {
|
||||
font-weight: bold;
|
||||
}
|
||||
.token.important {
|
||||
color: #c94922;
|
||||
}
|
||||
.token.entity {
|
||||
cursor: help;
|
||||
}
|
||||
.markdown-section pre > code {
|
||||
-moz-osx-font-smoothing: initial;
|
||||
-webkit-font-smoothing: initial;
|
||||
background-color: #f8f8f8;
|
||||
border-radius: 2px;
|
||||
color: #525252;
|
||||
display: block;
|
||||
font-family: 'Roboto Mono', Monaco, courier, monospace;
|
||||
font-size: 0.8rem;
|
||||
line-height: inherit;
|
||||
margin: 0 2px;
|
||||
max-width: inherit;
|
||||
overflow: inherit;
|
||||
padding: 2.2em 5px;
|
||||
white-space: inherit;
|
||||
}
|
||||
.markdown-section code::after,
|
||||
.markdown-section code::before {
|
||||
letter-spacing: 0.05rem;
|
||||
}
|
||||
code .token {
|
||||
-moz-osx-font-smoothing: initial;
|
||||
-webkit-font-smoothing: initial;
|
||||
min-height: 1.5rem;
|
||||
position: relative;
|
||||
left: auto;
|
||||
}
|
||||
pre::after {
|
||||
color: #ccc;
|
||||
content: attr(data-lang);
|
||||
font-size: 0.6rem;
|
||||
font-weight: 600;
|
||||
height: 15px;
|
||||
line-height: 15px;
|
||||
padding: 5px 10px 0;
|
||||
position: absolute;
|
||||
right: 0;
|
||||
text-align: right;
|
||||
top: 0;
|
||||
}
|
||||
|
|
@ -1,400 +0,0 @@
|
|||
# Keras 快速入门
|
||||
|
||||
* 安装: `pip install keras`
|
||||
|
||||
> Keras 发展生态支持
|
||||
|
||||
* 1.Keras 的开发主要由谷歌支持,Keras API 以 tf.keras 的形式包装在 TensorFlow 中。
|
||||
* 2.微软维护着 Keras 的 CNTK 后端。
|
||||
* 3.亚马逊 AWS 正在开发 MXNet 支持。
|
||||
* 4.其他提供支持的公司包括 NVIDIA、优步、苹果(通过 CoreML)等。
|
||||
|
||||
## Keras dataset 生产数据
|
||||
|
||||
```py
|
||||
# With Numpy arrays
|
||||
data = np.random.random((1000, 32))
|
||||
labels = np.random.random((1000, 10))
|
||||
|
||||
model.evaluate(data, labels, batch_size=32)
|
||||
|
||||
# With a Dataset
|
||||
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
|
||||
dataset = dataset.batch(32)
|
||||
|
||||
model.evaluate(dataset)
|
||||
```
|
||||
|
||||
|
||||
## Keras Sequential 顺序模型
|
||||
|
||||
顺序模型是多个网络层的线性堆叠,目前支持2中方式
|
||||
|
||||
### 构造模型
|
||||
|
||||
> 1.构造器: 构建 Sequential 模型
|
||||
|
||||
```py
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Dense, Activation
|
||||
|
||||
model = Sequential([
|
||||
Dense(32, input_shape=(784,)),
|
||||
Activation('relu'),
|
||||
Dense(10),
|
||||
Activation('softmax'),
|
||||
])
|
||||
```
|
||||
|
||||
> 2.add(): 构建 Sequential 模型
|
||||
|
||||
```py
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Dense, Activation
|
||||
|
||||
model = Sequential()
|
||||
model.add(Dense(32, input_dim=784))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(10)
|
||||
model.add(Activation('softmax'))
|
||||
```
|
||||
|
||||
### Dense: <https://keras.io/zh/layers/core>
|
||||
|
||||
Dense 指的是配置全连接层
|
||||
|
||||
```py
|
||||
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
|
||||
|
||||
# 参数
|
||||
* units: 正整数,输出空间维度。
|
||||
* activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,「线性」激活: a(x) = x)。
|
||||
* use_bias: 布尔值,该层是否使用偏置向量。
|
||||
* kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
|
||||
* bias_initializer: 偏置向量的初始化器 (see initializers).
|
||||
* kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
|
||||
* bias_regularizer: 运用到偏置向的的正则化函数 (详见 regularizer)。
|
||||
* activity_regularizer: 运用到层的输出的正则化函数 (它的 "activation")。 (详见 regularizer)。
|
||||
* kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
|
||||
* bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```py
|
||||
# 作为 Sequential 模型的第一层
|
||||
model = Sequential()
|
||||
# 现在模型就会以尺寸为 (*, 16) 的数组作为输入,
|
||||
# 其输出数组的尺寸为 (*, 32)
|
||||
model.add(Dense(32, input_shape=(16,)))
|
||||
|
||||
# 在第一层之后,你就不再需要指定输入的尺寸了:
|
||||
model.add(Dense(32))
|
||||
```
|
||||
|
||||
### Activation 激活函数: <https://keras-cn.readthedocs.io/en/latest/other/activations>
|
||||
|
||||
> 激活函数: 将线性问题变成非线性(回归问题变为分类问题),简单计算难度和复杂性。
|
||||
|
||||
|
||||
|
||||
sigmoid
|
||||
|
||||
hard_sigmoid
|
||||
|
||||
tanh
|
||||
|
||||
relu
|
||||
|
||||
softmax: 对输入数据的最后一维进行softmax,输入数据应形如(nb_samples, nb_timesteps, nb_dims)或(nb_samples,nb_dims)
|
||||
|
||||
elu
|
||||
|
||||
selu: 可伸缩的指数线性单元(Scaled Exponential Linear Unit),参考Self-Normalizing Neural Networks
|
||||
|
||||
softplus
|
||||
|
||||
softsign
|
||||
|
||||
linear
|
||||
|
||||
|
||||
|
||||
## Keras compile 过程
|
||||
|
||||
```py
|
||||
model.compile(optimizer='rmsprop',
|
||||
loss='categorical_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
|
||||
model.fit(x_train, y_train, epochs=5)
|
||||
model.evaluate(x_test, y_test, verbose=2)
|
||||
```
|
||||
|
||||
### 优化器 optimizer: <https://keras.io/optimizers>
|
||||
|
||||
|
||||
> SGD
|
||||
|
||||
|
||||
```py
|
||||
keras.optimizers.SGD(learning_rate=0.01, momentum=0.0, nesterov=False)
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```py
|
||||
from keras import optimizers
|
||||
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
|
||||
model.compile(loss='mean_squared_error', optimizer=sgd)
|
||||
```
|
||||
|
||||
|
||||
> RMSprop
|
||||
|
||||
```py
|
||||
keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9)
|
||||
```
|
||||
|
||||
> Adagrad
|
||||
|
||||
```py
|
||||
keras.optimizers.Adagrad(learning_rate=0.01)
|
||||
```
|
||||
|
||||
|
||||
> Adadelta
|
||||
|
||||
```py
|
||||
keras.optimizers.Adadelta(learning_rate=1.0, rho=0.95)
|
||||
```
|
||||
|
||||
> Adam
|
||||
|
||||
```py
|
||||
keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, amsgrad=False)
|
||||
```
|
||||
|
||||
|
||||
> Adamax
|
||||
|
||||
```py
|
||||
keras.optimizers.Adamax(learning_rate=0.002, beta_1=0.9, beta_2=0.999)
|
||||
```
|
||||
|
||||
|
||||
> Nadam
|
||||
|
||||
```py
|
||||
keras.optimizers.Nadam(learning_rate=0.002, beta_1=0.9, beta_2=0.999)
|
||||
```
|
||||
|
||||
|
||||
### 损失函数 loss: <https://keras.io/losses>
|
||||
|
||||
|
||||
#### 回归
|
||||
|
||||
> mean_squared_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_squared_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
#### 二分类
|
||||
|
||||
> binary_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.binary_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)
|
||||
```
|
||||
|
||||
|
||||
#### 多分类
|
||||
|
||||
> categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)
|
||||
```
|
||||
|
||||
### 评价函数 metrics: <https://keras.io/zh/metrics>
|
||||
|
||||
评价函数: 用来衡量`真实值`和`预测值`的差异
|
||||
|
||||
> binary_accuracy
|
||||
|
||||
对二分类问题,计算在所有预测值上的平均正确率
|
||||
|
||||
```py
|
||||
binary_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> categorical_accuracy
|
||||
|
||||
对多分类问题,计算再所有预测值上的平均正确率
|
||||
|
||||
```py
|
||||
categorical_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> sparse_categorical_accuracy
|
||||
|
||||
与categorical_accuracy相同,在对稀疏的目标值预测时有用
|
||||
|
||||
```py
|
||||
sparse_categorical_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> top_k_categorical_accuracy
|
||||
|
||||
计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
|
||||
|
||||
```py
|
||||
top_k_categorical_accuracy(y_true, y_pred, k=5)
|
||||
```
|
||||
|
||||
> sparse_top_k_categorical_accuracy
|
||||
|
||||
与top_k_categorical_accracy作用相同,但适用于稀疏情况
|
||||
|
||||
```py
|
||||
sparse_top_k_categorical_accuracy(y_true, y_pred, k=5)
|
||||
```
|
||||
|
||||
|
||||
## Keras load/save 模型持久化
|
||||
|
||||
> 保存模型
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Save entire model to a HDF5 file
|
||||
model.save('my_model.h5')
|
||||
|
||||
# Recreate the exact same model, including weights and optimizer.
|
||||
model = tf.keras.models.load_model('my_model.h5')
|
||||
```
|
||||
|
||||
> 仅保存权重值
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Save weights to a TensorFlow Checkpoint file
|
||||
model.save_weights('./weights/my_model')
|
||||
# Restore the model's state,
|
||||
# this requires a model with the same architecture.
|
||||
model.load_weights('./weights/my_model')
|
||||
|
||||
|
||||
# Save weights to a HDF5 file
|
||||
model.save_weights('my_model.h5', save_format='h5')
|
||||
# Restore the model's state
|
||||
model.load_weights('my_model.h5')
|
||||
```
|
||||
|
||||
> 仅保存模型配置
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Serialize a model to json format
|
||||
json_string = model.to_json()
|
||||
fresh_model = tf.keras.models.model_from_json(json_string)
|
||||
|
||||
# Serialize a model to yaml format
|
||||
yaml_string = model.to_yaml()
|
||||
fresh_model = tf.keras.models.model_from_yaml(yaml_string)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
补充损失函数
|
||||
|
||||
> mean_absolute_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_absolute_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> mean_absolute_percentage_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_absolute_percentage_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> mean_squared_logarithmic_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_squared_logarithmic_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> squared_hinge
|
||||
|
||||
```
|
||||
keras.losses.squared_hinge(y_true, y_pred)
|
||||
|
||||
```
|
||||
|
||||
> hinge
|
||||
|
||||
```py
|
||||
keras.losses.hinge(y_true, y_pred)
|
||||
```
|
||||
|
||||
> categorical_hinge
|
||||
|
||||
```py
|
||||
keras.losses.categorical_hinge(y_true, y_pred)
|
||||
```
|
||||
|
||||
> logcosh
|
||||
|
||||
```py
|
||||
keras.losses.logcosh(y_true, y_pred)
|
||||
```
|
||||
|
||||
|
||||
> huber_loss
|
||||
|
||||
```py
|
||||
keras.losses.huber_loss(y_true, y_pred, delta=1.0)
|
||||
```
|
||||
|
||||
|
||||
> sparse_categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1)
|
||||
```
|
||||
|
||||
|
||||
> kullback_leibler_divergence
|
||||
|
||||
```py
|
||||
keras.losses.kullback_leibler_divergence(y_true, y_pred)
|
||||
```
|
||||
|
||||
> poisson
|
||||
|
||||
```py
|
||||
keras.losses.poisson(y_true, y_pred)
|
||||
```
|
||||
|
||||
> cosine_proximity
|
||||
|
||||
```py
|
||||
keras.losses.cosine_proximity(y_true, y_pred, axis=-1)
|
||||
```
|
||||
|
||||
> is_categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.is_categorical_crossentropy(loss)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -1,185 +0,0 @@
|
|||
# Ubuntu16.04安装TensorFlow2.x CPU和GPU必备指南
|
||||
|
||||
* CPU安装: `pip install tensorflow`
|
||||
* GPU安装: `pip install tensorflow-gpu` 【**`别慌,GPU需要先安装以下内容`**】
|
||||
* 注意: 不要同时安装
|
||||
|
||||
> 硬件要求
|
||||
|
||||
支持以下启用GPU的设备:
|
||||
|
||||
* 具有CUDA®Compute Capability 3.5或更高版本的NVIDIA®GPU卡。请参阅[支持CUDA的GPU卡](https://developer.nvidia.com/cuda-gpus)列表 。
|
||||
|
||||
> 软件需求
|
||||
|
||||
您的系统上必须安装以下NVIDIA®软件:
|
||||
|
||||
* NVIDIA®GPU [驱动程序](https://www.nvidia.com/drivers) CUDA 10.0需要410.x或更高版本。
|
||||
* [CUDA®工具包](https://developer.nvidia.com/cuda-toolkit-archive) - TensorFlow支持CUDA 10.0(TensorFlow> = 1.13.0)
|
||||
* [CUPTI](http://docs.nvidia.com/cuda/cupti/)随附CUDA工具包。
|
||||
* [cuDNN SDK](https://developer.nvidia.com/cudnn)(> = 7.4.1)
|
||||
* *(可选)* [TensorRT 5.0](https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html) 可以改善延迟和吞吐量,以在某些模型上进行推断。
|
||||
|
||||
|
||||
## 1.安装 NVIDIA 驱动
|
||||
|
||||
```shell
|
||||
$ wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
|
||||
$ sudo apt install ./nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
|
||||
$ sudo apt-get update
|
||||
|
||||
$ ubuntu-drivers devices # 查看推荐的版本安装
|
||||
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
|
||||
modalias : pci:v000010DEd000017C8sv00001458sd000036B6bc03sc00i00
|
||||
vendor : NVIDIA Corporation
|
||||
model : GM200 [GeForce GTX 980 Ti]
|
||||
driver : nvidia-387 - third-party non-free
|
||||
driver : nvidia-410 - third-party non-free
|
||||
driver : nvidia-384 - third-party non-free
|
||||
driver : nvidia-430 - third-party free recommended # 推荐安装
|
||||
driver : xserver-xorg-video-nouveau - distro free builtin
|
||||
driver : nvidia-396 - third-party non-free
|
||||
driver : nvidia-390 - third-party non-free
|
||||
driver : nvidia-418 - third-party non-free
|
||||
driver : nvidia-415 - third-party free
|
||||
|
||||
# –no-install-recommends参数来避免安装非必须的文件,从而减小镜像的体积
|
||||
$ sudo apt-get install --no-install-recommends nvidia-430 -y
|
||||
正在读取软件包列表... 完成
|
||||
正在分析软件包的依赖关系树
|
||||
正在读取状态信息... 完成
|
||||
将会同时安装下列软件:
|
||||
lib32gcc1 libc-dev-bin libc6 libc6-dbg libc6-dev libc6-i386
|
||||
建议安装:
|
||||
glibc-doc
|
||||
推荐安装:
|
||||
libcuda1-430 nvidia-opencl-icd-430
|
||||
下列【新】软件包将被安装:
|
||||
lib32gcc1 libc6-i386 nvidia-430
|
||||
下列软件包将被升级:
|
||||
libc-dev-bin libc6 libc6-dbg libc6-dev
|
||||
升级了 4 个软件包,新安装了 3 个软件包,要卸载 0 个软件包,有 260 个软件包未被升级。
|
||||
需要下载 99.7 MB/111 MB 的归档。
|
||||
解压缩后会消耗 429 MB 的额外空间。
|
||||
您希望继续执行吗? [Y/n] Y
|
||||
获取:1 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu xenial/main amd64 nvidia-430 amd64 430.26-0ubuntu0~gpu16.04.1 [99.7 MB]
|
||||
25% [1 nvidia-430 492 kB/99.7 MB 0%] 563 B/s 2天 0小时 58分 14秒58秒
|
||||
...
|
||||
92% [1 nvidia-430 93.0 MB/99.7 MB 93%] 4,111 B/s 27分 28秒
|
||||
已下载 7,180 kB,耗时 4分 26秒 (26.9 kB/s)
|
||||
|
||||
Running module version sanity check.
|
||||
- Original module
|
||||
- No original module exists within this kernel
|
||||
- Installation
|
||||
- Installing to /lib/modules/4.10.0-28-generic/updates/dkms/
|
||||
|
||||
depmod....
|
||||
|
||||
DKMS: install completed.
|
||||
正在处理用于 libc-bin (2.23-0ubuntu10) 的触发器 ...
|
||||
正在处理用于 initramfs-tools (0.122ubuntu8.14) 的触发器 ...
|
||||
update-initramfs: Generating /boot/initrd.img-4.10.0-28-generic
|
||||
|
||||
# $ sudo reboot # 安装完需要重启电脑
|
||||
$ sudo nvidia-smi
|
||||
```
|
||||
|
||||
这里面大家需要注意的是: 采用在终端输入 `ubuntu-drivers devices` 会提示推荐你用什么版本,我的设备显示不出来,所以安装的是418.43这个型号的驱动。(目前最新版本)
|
||||
|
||||
注意事项一: 官网下载地址
|
||||
推荐网址: (https://www.geforce.cn/drivers)只有这个GeForce型号的,别的型号推荐去其对应的网址查询。
|
||||
|
||||
注意事项二: 不要在下面这个网址下载,不是不能,最直接的官网,对应的东西最新,也最详细
|
||||
网址如下(https://www.nvidia.com/Download/index.aspx?lang=cn)
|
||||
|
||||
理由:
|
||||
* (1)上面的网址,选择驱动型号,点进去可以看到许多详细的信息,尤其是它支持什么样的显卡,都有,特别详细。
|
||||
* (2)这个网址在我写博客(2019.3.6)为止,还没有GTX1660Ti的Ubuntu驱动
|
||||
|
||||
注意事项三: 具体操作见网上别人写好的。
|
||||
|
||||
## 2.安装 CUDA 1.0 + cuDNN 7
|
||||
|
||||
> CUDA
|
||||
|
||||
下面这个网址是tensorflow各环境参数对应版本图(https://tensorflow.google.cn/install/source)可供参考。cuda和cudnn对应关系应该没问题,但是tensorflow版本不能过高,否则会出错。
|
||||
|
||||
注意事项一: 下载地址
|
||||
cuda下载网址为: (https://developer.nvidia.com/),右上角搜索“CUDA Toolkit Archive”,点击第一个(最新的)的进去,里面有许多版本可供选择,切记!切记!切记!目前网友的说法是: tensorflow只能支持cuda9.0及以下版本。
|
||||
|
||||
注意事项二: 选择run下载,而不选择del
|
||||
这个具体是什么原因,没搞明白,网友也强烈推荐run,我之前试过del的,失败了,所以大家尽量采用run这种方法。可能有人没明白说明意思,你在选择的时候多留个心眼就注意到了。
|
||||
|
||||
> cuDNN
|
||||
|
||||
官网网址如下
|
||||
网址: <https://developer.nvidia.com/cudnn>
|
||||
需要注册,我是从别人那直接过来的,就没注册,大家需要的自己去,这个安装相对简单。
|
||||
|
||||
同样有验证的过程,这个相对来说是简单的,没什么需要太注意的,跟着网上的走就好了。
|
||||
|
||||
|
||||
> 执行命令
|
||||
|
||||
```shell
|
||||
$ sudo apt-get install gnupg-curl
|
||||
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
|
||||
$ sudo dpkg -i cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
|
||||
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
|
||||
$ sudo apt-get update -y
|
||||
|
||||
# sudo apt-get install cuda
|
||||
$ sudo apt-get install --no-install-recommends \
|
||||
cuda-10-0 \
|
||||
libcudnn7=7.6.2.24-1+cuda10.0 \
|
||||
libcudnn7-dev=7.6.2.24-1+cuda10.0
|
||||
|
||||
$ sudo apt-get install -y --no-install-recommends libnvinfer5=5.1.5-1+cuda10.0 libnvinfer-dev=5.1.5-1+cuda10.0
|
||||
```
|
||||
|
||||
## 3.安装TensorFlow并验证
|
||||
|
||||
* GPU安装: `sudo pip3 install tensorflow-gpu`
|
||||
|
||||
```shell
|
||||
from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
|
||||
import tensorflow as tf
|
||||
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
>>> from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
>>>
|
||||
>>> import tensorflow as tf
|
||||
|
||||
>>> print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
|
||||
2019-10-10 16:12:15.524570: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
|
||||
2019-10-10 16:12:15.537451: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.538341: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:
|
||||
name: GeForce GTX 980 Ti major: 5 minor: 2 memoryClockRate(GHz): 1.2405
|
||||
pciBusID: 0000:01:00.0
|
||||
2019-10-10 16:12:15.538489: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
|
||||
2019-10-10 16:12:15.539261: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0
|
||||
2019-10-10 16:12:15.539899: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0
|
||||
2019-10-10 16:12:15.540081: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0
|
||||
2019-10-10 16:12:15.540886: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0
|
||||
2019-10-10 16:12:15.541540: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0
|
||||
2019-10-10 16:12:15.543506: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
|
||||
2019-10-10 16:12:15.543601: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.544469: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.545326: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0
|
||||
Num GPUs Available: 1
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
信息来源:
|
||||
|
||||
* <https://tensorflow.google.cn/install/gpu>
|
||||
* <https://tensorflow.google.cn/guide/gpu>
|
||||
* <https://blog.csdn.net/qq_44774398/article/details/99832436>
|
||||
* <https://blog.csdn.net/weixin_43012220/article/details/88241766>
|
||||
|
|
@ -1,298 +0,0 @@
|
|||
# 实战项目 1 电影情感分类
|
||||
|
||||
Note: 我们的 TensorFlow 社区翻译了这些文档。因为社区翻译是尽力而为, 所以无法保证它们是最准确的,并且反映了最新的
|
||||
[官方英文文档](https://www.tensorflow.org/?hl=en)。如果您有改进此翻译的建议, 请提交 pull request 到
|
||||
[tensorflow/docs](https://github.com/tensorflow/docs) GitHub 仓库。要志愿地撰写或者审核译文,请加入
|
||||
[docs-zh-cn@tensorflow.org Google Group](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-zh-cn)。
|
||||
|
||||
此笔记本(notebook)使用评论文本将影评分为*积极(positive)*或*消极(negative)*两类。这是一个*二元(binary)*或者二分类问题,一种重要且应用广泛的机器学习问题。
|
||||
|
||||
我们将使用来源于[网络电影数据库(Internet Movie Database)](https://www.imdb.com/)的 [IMDB 数据集(IMDB dataset)](https://tensorflow.google.cn/api_docs/python/tf/keras/datasets/imdb),其包含 50,000 条影评文本。从该数据集切割出的25,000条评论用作训练,另外 25,000 条用作测试。训练集与测试集是*平衡的(balanced)*,意味着它们包含相等数量的积极和消极评论。
|
||||
|
||||
此笔记本(notebook)使用了 [tf.keras](https://tensorflow.google.cn/guide/keras),它是一个 Tensorflow 中用于构建和训练模型的高级API。有关使用 `tf.keras` 进行文本分类的更高级教程,请参阅 [MLCC文本分类指南(MLCC Text Classification Guide)](https://developers.google.com/machine-learning/guides/text-classification/)。
|
||||
|
||||
|
||||
```python
|
||||
from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
|
||||
try:
|
||||
# Colab only
|
||||
%tensorflow_version 2.x
|
||||
except Exception:
|
||||
pass
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
|
||||
import numpy as np
|
||||
|
||||
print(tf.__version__)
|
||||
```
|
||||
|
||||
## 下载 IMDB 数据集
|
||||
|
||||
IMDB 数据集已经打包在 Tensorflow 中。该数据集已经经过预处理,评论(单词序列)已经被转换为整数序列,其中每个整数表示字典中的特定单词。
|
||||
|
||||
以下代码将下载 IMDB 数据集到您的机器上(如果您已经下载过将从缓存中复制):
|
||||
|
||||
|
||||
```python
|
||||
imdb = keras.datasets.imdb
|
||||
|
||||
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
|
||||
```
|
||||
|
||||
参数 `num_words=10000` 保留了训练数据中最常出现的 10,000 个单词。为了保持数据规模的可管理性,低频词将被丢弃。
|
||||
|
||||
|
||||
## 探索数据
|
||||
|
||||
让我们花一点时间来了解数据格式。该数据集是经过预处理的: 每个样本都是一个表示影评中词汇的整数数组。每个标签都是一个值为 0 或 1 的整数值,其中 0 代表消极评论,1 代表积极评论。
|
||||
|
||||
|
||||
```python
|
||||
print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels)))
|
||||
```
|
||||
|
||||
评论文本被转换为整数值,其中每个整数代表词典中的一个单词。首条评论是这样的:
|
||||
|
||||
|
||||
```python
|
||||
print(train_data[0])
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
print(train_labels[:10])
|
||||
```
|
||||
|
||||
电影评论可能具有不同的长度。以下代码显示了第一条和第二条评论的中单词数量。由于神经网络的输入必须是统一的长度,我们稍后需要解决这个问题。
|
||||
|
||||
|
||||
```python
|
||||
len(train_data[0]), len(train_data[1])
|
||||
```
|
||||
|
||||
### 将整数转换回单词
|
||||
|
||||
了解如何将整数转换回文本对您可能是有帮助的。这里我们将创建一个辅助函数来查询一个包含了整数到字符串映射的字典对象:
|
||||
|
||||
|
||||
```python
|
||||
# 一个映射单词到整数索引的词典
|
||||
word_index = imdb.get_word_index()
|
||||
|
||||
# 保留第一个索引
|
||||
word_index = {k:(v+3) for k,v in word_index.items()}
|
||||
word_index["<PAD>"] = 0
|
||||
word_index["<START>"] = 1
|
||||
word_index["<UNK>"] = 2 # unknown
|
||||
word_index["<UNUSED>"] = 3
|
||||
|
||||
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
|
||||
|
||||
def decode_review(text):
|
||||
return ' '.join([reverse_word_index.get(i, '?') for i in text])
|
||||
```
|
||||
|
||||
现在我们可以使用 `decode_review` 函数来显示首条评论的文本:
|
||||
|
||||
|
||||
```python
|
||||
decode_review(train_data[0])
|
||||
```
|
||||
|
||||
## 准备数据
|
||||
|
||||
影评——即整数数组必须在输入神经网络之前转换为张量。这种转换可以通过以下两种方式来完成:
|
||||
|
||||
* 将数组转换为表示单词出现与否的由 0 和 1 组成的向量,类似于 one-hot 编码。例如,序列[3, 5]将转换为一个 10,000 维的向量,该向量除了索引为 3 和 5 的位置是 1 以外,其他都为 0。然后,将其作为网络的首层——一个可以处理浮点型向量数据的稠密层。不过,这种方法需要大量的内存,需要一个大小为 `num_words * num_reviews` 的矩阵。
|
||||
|
||||
* 或者,我们可以填充数组来保证输入数据具有相同的长度,然后创建一个大小为 `max_length * num_reviews` 的整型张量。我们可以使用能够处理此形状数据的嵌入层作为网络中的第一层。
|
||||
|
||||
在本教程中,我们将使用第二种方法。
|
||||
|
||||
由于电影评论长度必须相同,我们将使用 [pad_sequences](https://tensorflow.google.cn/api_docs/python/tf/keras/preprocessing/sequence/pad_sequences) 函数来使长度标准化:
|
||||
|
||||
|
||||
```python
|
||||
train_data = keras.preprocessing.sequence.pad_sequences(train_data,
|
||||
value=word_index["<PAD>"],
|
||||
padding='post',
|
||||
maxlen=256)
|
||||
|
||||
test_data = keras.preprocessing.sequence.pad_sequences(test_data,
|
||||
value=word_index["<PAD>"],
|
||||
padding='post',
|
||||
maxlen=256)
|
||||
```
|
||||
|
||||
现在让我们看下样本的长度:
|
||||
|
||||
|
||||
```python
|
||||
len(train_data[0]), len(train_data[1])
|
||||
```
|
||||
|
||||
并检查一下首条评论(当前已经填充):
|
||||
|
||||
|
||||
```python
|
||||
print(train_data[0])
|
||||
```
|
||||
|
||||
## 构建模型
|
||||
|
||||
神经网络由堆叠的层来构建,这需要从两个主要方面来进行体系结构决策:
|
||||
|
||||
* 模型里有多少层?
|
||||
* 每个层里有多少*隐层单元(hidden units)*?
|
||||
|
||||
在此样本中,输入数据包含一个单词索引的数组。要预测的标签为 0 或 1。让我们来为该问题构建一个模型:
|
||||
|
||||
|
||||
```python
|
||||
# 输入形状是用于电影评论的词汇数目(10,000 词)
|
||||
vocab_size = 10000
|
||||
|
||||
model = keras.Sequential()
|
||||
model.add(keras.layers.Embedding(vocab_size, 16))
|
||||
model.add(keras.layers.GlobalAveragePooling1D())
|
||||
model.add(keras.layers.Dense(16, activation='relu'))
|
||||
model.add(keras.layers.Dense(1, activation='sigmoid'))
|
||||
|
||||
model.summary()
|
||||
```
|
||||
|
||||
层按顺序堆叠以构建分类器:
|
||||
|
||||
1. 第一层是`嵌入(Embedding)`层。该层采用整数编码的词汇表,并查找每个词索引的嵌入向量(embedding vector)。这些向量是通过模型训练学习到的。向量向输出数组增加了一个维度。得到的维度为: `(batch, sequence, embedding)`。
|
||||
2. 接下来,`GlobalAveragePooling1D` 将通过对序列维度求平均值来为每个样本返回一个定长输出向量。这允许模型以尽可能最简单的方式处理变长输入。
|
||||
3. 该定长输出向量通过一个有 16 个隐层单元的全连接(`Dense`)层传输。
|
||||
4. 最后一层与单个输出结点密集连接。使用 `Sigmoid` 激活函数,其函数值为介于 0 与 1 之间的浮点数,表示概率或置信度。
|
||||
|
||||
### 隐层单元
|
||||
|
||||
上述模型在输入输出之间有两个中间层或“隐藏层”。输出(单元,结点或神经元)的数量即为层表示空间的维度。换句话说,是学习内部表示时网络所允许的自由度。
|
||||
|
||||
如果模型具有更多的隐层单元(更高维度的表示空间)和/或更多层,则可以学习到更复杂的表示。但是,这会使网络的计算成本更高,并且可能导致学习到不需要的模式——一些能够在训练数据上而不是测试数据上改善性能的模式。这被称为*过拟合(overfitting)*,我们稍后会对此进行探究。
|
||||
|
||||
### 损失函数与优化器
|
||||
|
||||
一个模型需要损失函数和优化器来进行训练。由于这是一个二分类问题且模型输出概率值(一个使用 sigmoid 激活函数的单一单元层),我们将使用 `binary_crossentropy` 损失函数。
|
||||
|
||||
这不是损失函数的唯一选择,例如,您可以选择 `mean_squared_error` 。但是,一般来说 `binary_crossentropy` 更适合处理概率——它能够度量概率分布之间的“距离”,或者在我们的示例中,指的是度量 ground-truth 分布与预测值之间的“距离”。
|
||||
|
||||
稍后,当我们研究回归问题(例如,预测房价)时,我们将介绍如何使用另一种叫做均方误差的损失函数。
|
||||
|
||||
现在,配置模型来使用优化器和损失函数:
|
||||
|
||||
|
||||
```python
|
||||
model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
```
|
||||
|
||||
## 创建一个验证集
|
||||
|
||||
在训练时,我们想要检查模型在未见过的数据上的准确率(accuracy)。通过从原始训练数据中分离 10,000 个样本来创建一个*验证集*。(为什么现在不使用测试集?我们的目标是只使用训练数据来开发和调整模型,然后只使用一次测试数据来评估准确率(accuracy))。
|
||||
|
||||
|
||||
```python
|
||||
x_val = train_data[:10000]
|
||||
partial_x_train = train_data[10000:]
|
||||
|
||||
y_val = train_labels[:10000]
|
||||
partial_y_train = train_labels[10000:]
|
||||
```
|
||||
|
||||
## 训练模型
|
||||
|
||||
以 512 个样本的 mini-batch 大小迭代 40 个 epoch 来训练模型。这是指对 `x_train` 和 `y_train` 张量中所有样本的的 40 次迭代。在训练过程中,监测来自验证集的 10,000 个样本上的损失值(loss)和准确率(accuracy):
|
||||
|
||||
|
||||
```python
|
||||
history = model.fit(partial_x_train,
|
||||
partial_y_train,
|
||||
epochs=40,
|
||||
batch_size=512,
|
||||
validation_data=(x_val, y_val),
|
||||
verbose=1)
|
||||
```
|
||||
|
||||
## 评估模型
|
||||
|
||||
我们来看一下模型的性能如何。将返回两个值。损失值(loss)(一个表示误差的数字,值越低越好)与准确率(accuracy)。
|
||||
|
||||
|
||||
```python
|
||||
results = model.evaluate(test_data, test_labels, verbose=2)
|
||||
|
||||
print(results)
|
||||
```
|
||||
|
||||
这种十分朴素的方法得到了约 87% 的准确率(accuracy)。若采用更好的方法,模型的准确率应当接近 95%。
|
||||
|
||||
## 创建一个准确率(accuracy)和损失值(loss)随时间变化的图表
|
||||
|
||||
`model.fit()` 返回一个 `History` 对象,该对象包含一个字典,其中包含训练阶段所发生的一切事件:
|
||||
|
||||
|
||||
```python
|
||||
history_dict = history.history
|
||||
history_dict.keys()
|
||||
```
|
||||
|
||||
有四个条目: 在训练和验证期间,每个条目对应一个监控指标。我们可以使用这些条目来绘制训练与验证过程的损失值(loss)和准确率(accuracy),以便进行比较。
|
||||
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
acc = history_dict['accuracy']
|
||||
val_acc = history_dict['val_accuracy']
|
||||
loss = history_dict['loss']
|
||||
val_loss = history_dict['val_loss']
|
||||
|
||||
epochs = range(1, len(acc) + 1)
|
||||
|
||||
# “bo”代表 "蓝点"
|
||||
plt.plot(epochs, loss, 'bo', label='Training loss')
|
||||
# b代表“蓝色实线”
|
||||
plt.plot(epochs, val_loss, 'b', label='Validation loss')
|
||||
plt.title('Training and validation loss')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('Loss')
|
||||
plt.legend()
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
plt.clf() # 清除数字
|
||||
|
||||
plt.plot(epochs, acc, 'bo', label='Training acc')
|
||||
plt.plot(epochs, val_acc, 'b', label='Validation acc')
|
||||
plt.title('Training and validation accuracy')
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel('Accuracy')
|
||||
plt.legend()
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
在该图中,点代表训练损失值(loss)与准确率(accuracy),实线代表验证损失值(loss)与准确率(accuracy)。
|
||||
|
||||
注意训练损失值随每一个 epoch *下降*而训练准确率(accuracy)随每一个 epoch *上升*。这在使用梯度下降优化时是可预期的——理应在每次迭代中最小化期望值。
|
||||
|
||||
验证过程的损失值(loss)与准确率(accuracy)的情况却并非如此——它们似乎在 20 个 epoch 后达到峰值。这是过拟合的一个实例: 模型在训练数据上的表现比在以前从未见过的数据上的表现要更好。在此之后,模型过度优化并学习*特定*于训练数据的表示,而不能够*泛化*到测试数据。
|
||||
|
||||
对于这种特殊情况,我们可以通过在 20 个左右的 epoch 后停止训练来避免过拟合。稍后,您将看到如何通过回调自动执行此操作。
|
||||
|
||||
|
||||
***
|
||||
|
||||
* Copyright 2018 The TensorFlow Authors.
|
||||
* 来源地址: <https://tensorflow.google.cn/tutorials/keras/text_classification?hl=zh_cn>
|
||||
|
|
@ -1,847 +0,0 @@
|
|||
# 实战项目 2 汽车燃油效率
|
||||
|
||||
Note: 我们的 TensorFlow 社区翻译了这些文档。因为社区翻译是尽力而为, 所以无法保证它们是最准确的,并且反映了最新的
|
||||
[官方英文文档](https://www.tensorflow.org/?hl=en)。如果您有改进此翻译的建议, 请提交 pull request 到
|
||||
[tensorflow/docs](https://github.com/tensorflow/docs) GitHub 仓库。要志愿地撰写或者审核译文,请加入
|
||||
[docs-zh-cn@tensorflow.org Google Group](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-zh-cn)。
|
||||
|
||||
在 *回归 (regression)* 问题中,我们的目的是预测出如价格或概率这样连续值的输出。相对于*分类(classification)* 问题,*分类(classification)* 的目的是从一系列的分类出选择出一个分类 (如,给出一张包含苹果或橘子的图片,识别出图片中是哪种水果)。
|
||||
|
||||
本 notebook 使用经典的 [Auto MPG](https://archive.ics.uci.edu/ml/datasets/auto+mpg) 数据集,构建了一个用来预测70年代末到80年代初汽车燃油效率的模型。为了做到这一点,我们将为该模型提供许多那个时期的汽车描述。这个描述包含: 气缸数,排量,马力以及重量。
|
||||
|
||||
本示例使用 `tf.keras` API,相关细节请参阅 [本指南](https://tensorflow.google.cn/guide/keras)。
|
||||
|
||||
|
||||
```python
|
||||
# 使用 seaborn 绘制矩阵图 (pairplot)
|
||||
!pip install seaborn
|
||||
```
|
||||
|
||||
Requirement already satisfied: seaborn in /usr/local/lib/python3.6/dist-packages (0.9.0)
|
||||
Requirement already satisfied: scipy>=0.14.0 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.3.1)
|
||||
Requirement already satisfied: numpy>=1.9.3 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.16.5)
|
||||
Requirement already satisfied: matplotlib>=1.4.3 in /usr/local/lib/python3.6/dist-packages (from seaborn) (3.0.3)
|
||||
Requirement already satisfied: pandas>=0.15.2 in /usr/local/lib/python3.6/dist-packages (from seaborn) (0.24.2)
|
||||
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (2.4.2)
|
||||
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (1.1.0)
|
||||
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (0.10.0)
|
||||
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=1.4.3->seaborn) (2.5.3)
|
||||
Requirement already satisfied: pytz>=2011k in /usr/local/lib/python3.6/dist-packages (from pandas>=0.15.2->seaborn) (2018.9)
|
||||
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from kiwisolver>=1.0.1->matplotlib>=1.4.3->seaborn) (41.4.0)
|
||||
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from cycler>=0.10->matplotlib>=1.4.3->seaborn) (1.12.0)
|
||||
|
||||
|
||||
|
||||
```python
|
||||
from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
|
||||
import pathlib
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import pandas as pd
|
||||
import seaborn as sns
|
||||
|
||||
try:
|
||||
# %tensorflow_version only exists in Colab.
|
||||
%tensorflow_version 2.x
|
||||
except Exception:
|
||||
pass
|
||||
import tensorflow as tf
|
||||
|
||||
from tensorflow import keras
|
||||
from tensorflow.keras import layers
|
||||
|
||||
print(tf.__version__)
|
||||
```
|
||||
|
||||
TensorFlow 2.x selected.
|
||||
2.0.0
|
||||
|
||||
|
||||
## Auto MPG 数据集
|
||||
|
||||
该数据集可以从 [UCI机器学习库](https://archive.ics.uci.edu/ml/) 中获取.
|
||||
|
||||
|
||||
|
||||
### 获取数据
|
||||
首先下载数据集。
|
||||
|
||||
|
||||
```python
|
||||
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
|
||||
dataset_path
|
||||
```
|
||||
|
||||
Downloading data from http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
|
||||
32768/30286 [================================] - 0s 4us/step
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
'/root/.keras/datasets/auto-mpg.data'
|
||||
|
||||
|
||||
|
||||
使用 pandas 导入数据集。
|
||||
|
||||
|
||||
```python
|
||||
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
|
||||
'Acceleration', 'Model Year', 'Origin']
|
||||
raw_dataset = pd.read_csv(dataset_path, names=column_names,
|
||||
na_values = "?", comment='\t',
|
||||
sep=" ", skipinitialspace=True)
|
||||
|
||||
dataset = raw_dataset.copy()
|
||||
dataset.tail()
|
||||
```
|
||||
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr style="text-align: right;">
|
||||
<th></th>
|
||||
<th>MPG</th>
|
||||
<th>Cylinders</th>
|
||||
<th>Displacement</th>
|
||||
<th>Horsepower</th>
|
||||
<th>Weight</th>
|
||||
<th>Acceleration</th>
|
||||
<th>Model Year</th>
|
||||
<th>Origin</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>393</th>
|
||||
<td>27.0</td>
|
||||
<td>4</td>
|
||||
<td>140.0</td>
|
||||
<td>86.0</td>
|
||||
<td>2790.0</td>
|
||||
<td>15.6</td>
|
||||
<td>82</td>
|
||||
<td>1</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>394</th>
|
||||
<td>44.0</td>
|
||||
<td>4</td>
|
||||
<td>97.0</td>
|
||||
<td>52.0</td>
|
||||
<td>2130.0</td>
|
||||
<td>24.6</td>
|
||||
<td>82</td>
|
||||
<td>2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>395</th>
|
||||
<td>32.0</td>
|
||||
<td>4</td>
|
||||
<td>135.0</td>
|
||||
<td>84.0</td>
|
||||
<td>2295.0</td>
|
||||
<td>11.6</td>
|
||||
<td>82</td>
|
||||
<td>1</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>396</th>
|
||||
<td>28.0</td>
|
||||
<td>4</td>
|
||||
<td>120.0</td>
|
||||
<td>79.0</td>
|
||||
<td>2625.0</td>
|
||||
<td>18.6</td>
|
||||
<td>82</td>
|
||||
<td>1</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>397</th>
|
||||
<td>31.0</td>
|
||||
<td>4</td>
|
||||
<td>119.0</td>
|
||||
<td>82.0</td>
|
||||
<td>2720.0</td>
|
||||
<td>19.4</td>
|
||||
<td>82</td>
|
||||
<td>1</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### 数据清洗
|
||||
|
||||
数据集中包括一些未知值。
|
||||
|
||||
|
||||
```python
|
||||
dataset.isna().sum()
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
MPG 0
|
||||
Cylinders 0
|
||||
Displacement 0
|
||||
Horsepower 6
|
||||
Weight 0
|
||||
Acceleration 0
|
||||
Model Year 0
|
||||
Origin 0
|
||||
dtype: int64
|
||||
|
||||
|
||||
|
||||
为了保证这个初始示例的简单性,删除这些行。
|
||||
|
||||
|
||||
```python
|
||||
dataset = dataset.dropna()
|
||||
```
|
||||
|
||||
`"Origin"` 列实际上代表分类,而不仅仅是一个数字。所以把它转换为独热码 (one-hot):
|
||||
|
||||
|
||||
```python
|
||||
origin = dataset.pop('Origin')
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
dataset['USA'] = (origin == 1)*1.0
|
||||
dataset['Europe'] = (origin == 2)*1.0
|
||||
dataset['Japan'] = (origin == 3)*1.0
|
||||
dataset.tail()
|
||||
```
|
||||
|
||||
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr style="text-align: right;">
|
||||
<th></th>
|
||||
<th>MPG</th>
|
||||
<th>Cylinders</th>
|
||||
<th>Displacement</th>
|
||||
<th>Horsepower</th>
|
||||
<th>Weight</th>
|
||||
<th>Acceleration</th>
|
||||
<th>Model Year</th>
|
||||
<th>USA</th>
|
||||
<th>Europe</th>
|
||||
<th>Japan</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>393</th>
|
||||
<td>27.0</td>
|
||||
<td>4</td>
|
||||
<td>140.0</td>
|
||||
<td>86.0</td>
|
||||
<td>2790.0</td>
|
||||
<td>15.6</td>
|
||||
<td>82</td>
|
||||
<td>1.0</td>
|
||||
<td>0.0</td>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>394</th>
|
||||
<td>44.0</td>
|
||||
<td>4</td>
|
||||
<td>97.0</td>
|
||||
<td>52.0</td>
|
||||
<td>2130.0</td>
|
||||
<td>24.6</td>
|
||||
<td>82</td>
|
||||
<td>0.0</td>
|
||||
<td>1.0</td>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>395</th>
|
||||
<td>32.0</td>
|
||||
<td>4</td>
|
||||
<td>135.0</td>
|
||||
<td>84.0</td>
|
||||
<td>2295.0</td>
|
||||
<td>11.6</td>
|
||||
<td>82</td>
|
||||
<td>1.0</td>
|
||||
<td>0.0</td>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>396</th>
|
||||
<td>28.0</td>
|
||||
<td>4</td>
|
||||
<td>120.0</td>
|
||||
<td>79.0</td>
|
||||
<td>2625.0</td>
|
||||
<td>18.6</td>
|
||||
<td>82</td>
|
||||
<td>1.0</td>
|
||||
<td>0.0</td>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>397</th>
|
||||
<td>31.0</td>
|
||||
<td>4</td>
|
||||
<td>119.0</td>
|
||||
<td>82.0</td>
|
||||
<td>2720.0</td>
|
||||
<td>19.4</td>
|
||||
<td>82</td>
|
||||
<td>1.0</td>
|
||||
<td>0.0</td>
|
||||
<td>0.0</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
### 拆分训练数据集和测试数据集
|
||||
|
||||
现在需要将数据集拆分为一个训练数据集和一个测试数据集。
|
||||
|
||||
我们最后将使用测试数据集对模型进行评估。
|
||||
|
||||
|
||||
```python
|
||||
train_dataset = dataset.sample(frac=0.8,random_state=0)
|
||||
test_dataset = dataset.drop(train_dataset.index)
|
||||
```
|
||||
|
||||
### 数据检查
|
||||
|
||||
快速查看训练集中几对列的联合分布。
|
||||
|
||||
|
||||
```python
|
||||
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
<seaborn.axisgrid.PairGrid at 0x7f3d9243a6a0>
|
||||
|
||||
|
||||
|
||||
|
||||
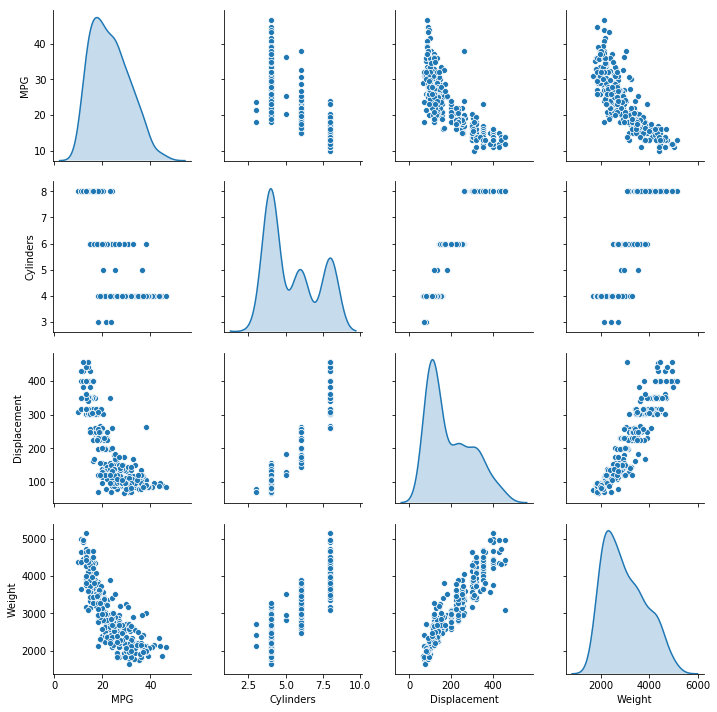
|
||||
|
||||
|
||||
也可以查看总体的数据统计:
|
||||
|
||||
|
||||
```python
|
||||
train_stats = train_dataset.describe()
|
||||
train_stats.pop("MPG")
|
||||
train_stats = train_stats.transpose()
|
||||
train_stats
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
<div>
|
||||
<style scoped>
|
||||
.dataframe tbody tr th:only-of-type {
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.dataframe tbody tr th {
|
||||
vertical-align: top;
|
||||
}
|
||||
|
||||
.dataframe thead th {
|
||||
text-align: right;
|
||||
}
|
||||
</style>
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr style="text-align: right;">
|
||||
<th></th>
|
||||
<th>count</th>
|
||||
<th>mean</th>
|
||||
<th>std</th>
|
||||
<th>min</th>
|
||||
<th>25%</th>
|
||||
<th>50%</th>
|
||||
<th>75%</th>
|
||||
<th>max</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>Cylinders</th>
|
||||
<td>314.0</td>
|
||||
<td>5.477707</td>
|
||||
<td>1.699788</td>
|
||||
<td>3.0</td>
|
||||
<td>4.00</td>
|
||||
<td>4.0</td>
|
||||
<td>8.00</td>
|
||||
<td>8.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Displacement</th>
|
||||
<td>314.0</td>
|
||||
<td>195.318471</td>
|
||||
<td>104.331589</td>
|
||||
<td>68.0</td>
|
||||
<td>105.50</td>
|
||||
<td>151.0</td>
|
||||
<td>265.75</td>
|
||||
<td>455.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Horsepower</th>
|
||||
<td>314.0</td>
|
||||
<td>104.869427</td>
|
||||
<td>38.096214</td>
|
||||
<td>46.0</td>
|
||||
<td>76.25</td>
|
||||
<td>94.5</td>
|
||||
<td>128.00</td>
|
||||
<td>225.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Weight</th>
|
||||
<td>314.0</td>
|
||||
<td>2990.251592</td>
|
||||
<td>843.898596</td>
|
||||
<td>1649.0</td>
|
||||
<td>2256.50</td>
|
||||
<td>2822.5</td>
|
||||
<td>3608.00</td>
|
||||
<td>5140.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Acceleration</th>
|
||||
<td>314.0</td>
|
||||
<td>15.559236</td>
|
||||
<td>2.789230</td>
|
||||
<td>8.0</td>
|
||||
<td>13.80</td>
|
||||
<td>15.5</td>
|
||||
<td>17.20</td>
|
||||
<td>24.8</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Model Year</th>
|
||||
<td>314.0</td>
|
||||
<td>75.898089</td>
|
||||
<td>3.675642</td>
|
||||
<td>70.0</td>
|
||||
<td>73.00</td>
|
||||
<td>76.0</td>
|
||||
<td>79.00</td>
|
||||
<td>82.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>USA</th>
|
||||
<td>314.0</td>
|
||||
<td>0.624204</td>
|
||||
<td>0.485101</td>
|
||||
<td>0.0</td>
|
||||
<td>0.00</td>
|
||||
<td>1.0</td>
|
||||
<td>1.00</td>
|
||||
<td>1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Europe</th>
|
||||
<td>314.0</td>
|
||||
<td>0.178344</td>
|
||||
<td>0.383413</td>
|
||||
<td>0.0</td>
|
||||
<td>0.00</td>
|
||||
<td>0.0</td>
|
||||
<td>0.00</td>
|
||||
<td>1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>Japan</th>
|
||||
<td>314.0</td>
|
||||
<td>0.197452</td>
|
||||
<td>0.398712</td>
|
||||
<td>0.0</td>
|
||||
<td>0.00</td>
|
||||
<td>0.0</td>
|
||||
<td>0.00</td>
|
||||
<td>1.0</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
</div>
|
||||
|
||||
|
||||
|
||||
### 从标签中分离特征
|
||||
|
||||
将特征值从目标值或者"标签"中分离。 这个标签是你使用训练模型进行预测的值。
|
||||
|
||||
|
||||
```python
|
||||
train_labels = train_dataset.pop('MPG')
|
||||
test_labels = test_dataset.pop('MPG')
|
||||
```
|
||||
|
||||
### 数据规范化
|
||||
|
||||
再次审视下上面的 `train_stats` 部分,并注意每个特征的范围有什么不同。
|
||||
|
||||
使用不同的尺度和范围对特征归一化是好的实践。尽管模型*可能* 在没有特征归一化的情况下收敛,它会使得模型训练更加复杂,并会造成生成的模型依赖输入所使用的单位选择。
|
||||
|
||||
注意: 尽管我们仅仅从训练集中有意生成这些统计数据,但是这些统计信息也会用于归一化的测试数据集。我们需要这样做,将测试数据集放入到与已经训练过的模型相同的分布中。
|
||||
|
||||
|
||||
```python
|
||||
def norm(x):
|
||||
return (x - train_stats['mean']) / train_stats['std']
|
||||
normed_train_data = norm(train_dataset)
|
||||
normed_test_data = norm(test_dataset)
|
||||
```
|
||||
|
||||
我们将会使用这个已经归一化的数据来训练模型。
|
||||
|
||||
警告: 用于归一化输入的数据统计(均值和标准差)需要反馈给模型从而应用于任何其他数据,以及我们之前所获得独热码。这些数据包含测试数据集以及生产环境中所使用的实时数据。
|
||||
|
||||
## 模型
|
||||
|
||||
### 构建模型
|
||||
|
||||
让我们来构建我们自己的模型。这里,我们将会使用一个“顺序”模型,其中包含两个紧密相连的隐藏层,以及返回单个、连续值得输出层。模型的构建步骤包含于一个名叫 'build_model' 的函数中,稍后我们将会创建第二个模型。 两个密集连接的隐藏层。
|
||||
|
||||
|
||||
```python
|
||||
def build_model():
|
||||
model = keras.Sequential([
|
||||
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
|
||||
layers.Dense(64, activation='relu'),
|
||||
layers.Dense(1)
|
||||
])
|
||||
|
||||
optimizer = tf.keras.optimizers.RMSprop(0.001)
|
||||
|
||||
model.compile(loss='mse',
|
||||
optimizer=optimizer,
|
||||
metrics=['mae', 'mse'])
|
||||
return model
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
model = build_model()
|
||||
```
|
||||
|
||||
### 检查模型
|
||||
|
||||
使用 `.summary` 方法来打印该模型的简单描述。
|
||||
|
||||
|
||||
```python
|
||||
model.summary()
|
||||
```
|
||||
|
||||
Model: "sequential"
|
||||
_________________________________________________________________
|
||||
Layer (type) Output Shape Param #
|
||||
=================================================================
|
||||
dense (Dense) (None, 64) 640
|
||||
_________________________________________________________________
|
||||
dense_1 (Dense) (None, 64) 4160
|
||||
_________________________________________________________________
|
||||
dense_2 (Dense) (None, 1) 65
|
||||
=================================================================
|
||||
Total params: 4,865
|
||||
Trainable params: 4,865
|
||||
Non-trainable params: 0
|
||||
_________________________________________________________________
|
||||
|
||||
|
||||
|
||||
现在试用下这个模型。从训练数据中批量获取‘10’条例子并对这些例子调用 `model.predict` 。
|
||||
|
||||
|
||||
|
||||
```python
|
||||
example_batch = normed_train_data[:10]
|
||||
example_result = model.predict(example_batch)
|
||||
example_result
|
||||
```
|
||||
|
||||
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
array([[ 0.37002987],
|
||||
[ 0.22292587],
|
||||
[ 0.7729857 ],
|
||||
[ 0.22504307],
|
||||
[-0.01411032],
|
||||
[ 0.25664118],
|
||||
[ 0.05221634],
|
||||
[-0.0256409 ],
|
||||
[ 0.23223272],
|
||||
[-0.00434934]], dtype=float32)
|
||||
|
||||
|
||||
|
||||
它似乎在工作,并产生了预期的形状和类型的结果
|
||||
|
||||
### 训练模型
|
||||
|
||||
对模型进行1000个周期的训练,并在 `history` 对象中记录训练和验证的准确性。
|
||||
|
||||
|
||||
```python
|
||||
# 通过为每个完成的时期打印一个点来显示训练进度
|
||||
class PrintDot(keras.callbacks.Callback):
|
||||
def on_epoch_end(self, epoch, logs):
|
||||
if epoch % 100 == 0: print('')
|
||||
print('.', end='')
|
||||
|
||||
EPOCHS = 1000
|
||||
|
||||
history = model.fit(
|
||||
normed_train_data, train_labels,
|
||||
epochs=EPOCHS, validation_split = 0.2, verbose=0,
|
||||
callbacks=[PrintDot()])
|
||||
```
|
||||
|
||||
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
|
||||
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
....................................................................................................
|
||||
|
||||
使用 `history` 对象中存储的统计信息可视化模型的训练进度。
|
||||
|
||||
|
||||
```python
|
||||
hist = pd.DataFrame(history.history)
|
||||
hist['epoch'] = history.epoch
|
||||
hist.tail()
|
||||
```
|
||||
|
||||
|
||||
<table border="1" class="dataframe">
|
||||
<thead>
|
||||
<tr style="text-align: right;">
|
||||
<th></th>
|
||||
<th>loss</th>
|
||||
<th>mae</th>
|
||||
<th>mse</th>
|
||||
<th>val_loss</th>
|
||||
<th>val_mae</th>
|
||||
<th>val_mse</th>
|
||||
<th>epoch</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<th>995</th>
|
||||
<td>2.278429</td>
|
||||
<td>0.968291</td>
|
||||
<td>2.278429</td>
|
||||
<td>8.645883</td>
|
||||
<td>2.228030</td>
|
||||
<td>8.645884</td>
|
||||
<td>995</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>996</th>
|
||||
<td>2.300897</td>
|
||||
<td>0.955693</td>
|
||||
<td>2.300897</td>
|
||||
<td>8.526561</td>
|
||||
<td>2.254299</td>
|
||||
<td>8.526561</td>
|
||||
<td>996</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>997</th>
|
||||
<td>2.302505</td>
|
||||
<td>0.937035</td>
|
||||
<td>2.302505</td>
|
||||
<td>8.662312</td>
|
||||
<td>2.204857</td>
|
||||
<td>8.662312</td>
|
||||
<td>997</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>998</th>
|
||||
<td>2.265367</td>
|
||||
<td>0.942647</td>
|
||||
<td>2.265367</td>
|
||||
<td>8.319109</td>
|
||||
<td>2.224138</td>
|
||||
<td>8.319109</td>
|
||||
<td>998</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<th>999</th>
|
||||
<td>2.224938</td>
|
||||
<td>0.985029</td>
|
||||
<td>2.224938</td>
|
||||
<td>8.404006</td>
|
||||
<td>2.241303</td>
|
||||
<td>8.404006</td>
|
||||
<td>999</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
|
||||
|
||||
```python
|
||||
def plot_history(history):
|
||||
hist = pd.DataFrame(history.history)
|
||||
hist['epoch'] = history.epoch
|
||||
|
||||
plt.figure()
|
||||
plt.xlabel('Epoch')
|
||||
plt.ylabel('Mean Abs Error [MPG]')
|
||||
plt.plot(hist['epoch'], hist['mae'],
|
||||
label='Train Error')
|
||||
plt.plot(hist['epoch'], hist['val_mae'],
|
||||
label = 'Val Error')
|
||||
plt.ylim([0,5])
|
||||
plt.legend()
|
||||
|
||||
plt.figure()
|
||||
plt.xlabel('Epoch')
|
||||
plt.ylabel('Mean Square Error [$MPG^2$]')
|
||||
plt.plot(hist['epoch'], hist['mse'],
|
||||
label='Train Error')
|
||||
plt.plot(hist['epoch'], hist['val_mse'],
|
||||
label = 'Val Error')
|
||||
plt.ylim([0,20])
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
||||
|
||||
plot_history(history)
|
||||
```
|
||||
|
||||
|
||||
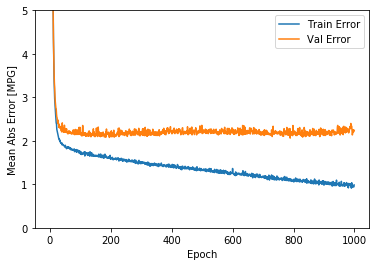
|
||||
|
||||
|
||||
|
||||
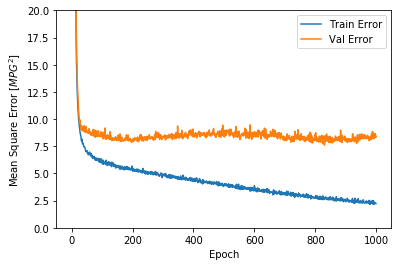
|
||||
|
||||
|
||||
该图表显示在约100个 epochs 之后误差非但没有改进,反而出现恶化。 让我们更新 `model.fit` 调用,当验证值没有提高上是自动停止训练。
|
||||
我们将使用一个 *EarlyStopping callback* 来测试每个 epoch 的训练条件。如果经过一定数量的 epochs 后没有改进,则自动停止训练。
|
||||
|
||||
你可以从[这里](https://tensorflow.google.cn/versions/master/api_docs/python/tf/keras/callbacks/EarlyStopping)学习到更多的回调。
|
||||
|
||||
|
||||
```python
|
||||
model = build_model()
|
||||
|
||||
# patience 值用来检查改进 epochs 的数量
|
||||
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
|
||||
|
||||
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
|
||||
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
|
||||
|
||||
plot_history(history)
|
||||
```
|
||||
|
||||
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
|
||||
|
||||
........................................................
|
||||
|
||||
|
||||
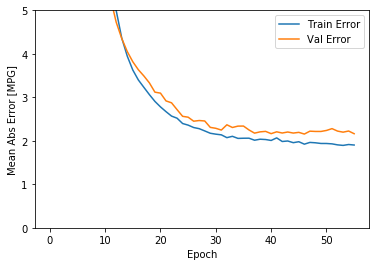
|
||||
|
||||
|
||||
|
||||
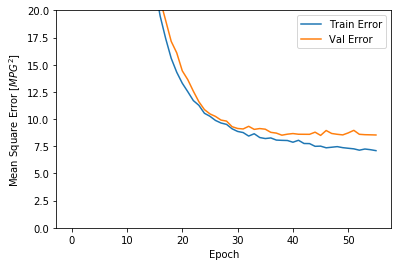
|
||||
|
||||
|
||||
如图所示,验证集中的平均的误差通常在 +/- 2 MPG左右。 这个结果好么? 我们将决定权留给你。
|
||||
|
||||
让我们看看通过使用 **测试集** 来泛化模型的效果如何,我们在训练模型时没有使用测试集。这告诉我们,当我们在现实世界中使用这个模型时,我们可以期望它预测得有多好。
|
||||
|
||||
|
||||
```python
|
||||
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
|
||||
|
||||
print("Testing set Mean Abs Error: {:5.2f} MPG".format(mae))
|
||||
```
|
||||
|
||||
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
|
||||
78/78 - 0s - loss: 5.8737 - mae: 1.8844 - mse: 5.8737
|
||||
Testing set Mean Abs Error: 1.88 MPG
|
||||
|
||||
|
||||
### 做预测
|
||||
|
||||
最后,使用测试集中的数据预测 MPG 值:
|
||||
|
||||
|
||||
```python
|
||||
test_predictions = model.predict(normed_test_data).flatten()
|
||||
|
||||
plt.scatter(test_labels, test_predictions)
|
||||
plt.xlabel('True Values [MPG]')
|
||||
plt.ylabel('Predictions [MPG]')
|
||||
plt.axis('equal')
|
||||
plt.axis('square')
|
||||
plt.xlim([0,plt.xlim()[1]])
|
||||
plt.ylim([0,plt.ylim()[1]])
|
||||
_ = plt.plot([-100, 100], [-100, 100])
|
||||
|
||||
```
|
||||
|
||||
WARNING:tensorflow:Falling back from v2 loop because of error: Failed to find data adapter that can handle input: <class 'pandas.core.frame.DataFrame'>, <class 'NoneType'>
|
||||
|
||||
|
||||
|
||||
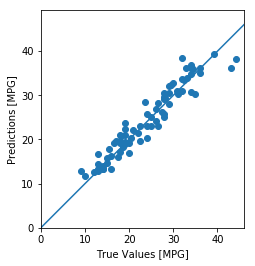
|
||||
|
||||
|
||||
这看起来我们的模型预测得相当好。我们来看下误差分布。
|
||||
|
||||
|
||||
```python
|
||||
error = test_predictions - test_labels
|
||||
plt.hist(error, bins = 25)
|
||||
plt.xlabel("Prediction Error [MPG]")
|
||||
_ = plt.ylabel("Count")
|
||||
```
|
||||
|
||||
|
||||
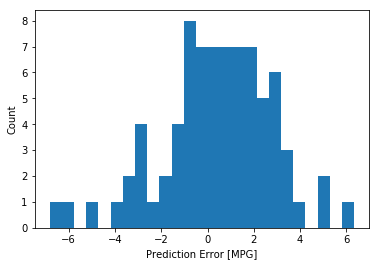
|
||||
|
||||
|
||||
它不是完全的高斯分布,但我们可以推断出,这是因为样本的数量很小所导致的。
|
||||
|
||||
## 结论
|
||||
|
||||
本笔记本 (notebook) 介绍了一些处理回归问题的技术。
|
||||
|
||||
* 均方误差(MSE)是用于回归问题的常见损失函数(分类问题中使用不同的损失函数)。
|
||||
* 类似的,用于回归的评估指标与分类不同。 常见的回归指标是平均绝对误差(MAE)。
|
||||
* 当数字输入数据特征的值存在不同范围时,每个特征应独立缩放到相同范围。
|
||||
* 如果训练数据不多,一种方法是选择隐藏层较少的小网络,以避免过度拟合。
|
||||
* 早期停止是一种防止过度拟合的有效技术。
|
||||
|
|
@ -1,518 +0,0 @@
|
|||
# 探索过拟合和欠拟合
|
||||
|
||||
与往常一样,此示例中的代码将使用 `tf.keras` API,您可以在TensorFlow [Keras 指南](https://www.tensorflow.org/guide/keras)中了解更多信息。
|
||||
|
||||
在前面的两个示例(对电影评论进行分类和预测燃油效率)中,我们看到了在验证数据上的模型的准确性在经过多个时期的训练后将达到峰值,然后开始下降。
|
||||
|
||||
换句话说,我们的模型将 *过拟合* 训练数据。学习如何应对过拟合很重要。尽管通常可以在*训练集*上达到高精度,但我们真正想要的是开发能够很好地推广到*测试集*(或之前未见的数据)的模型。
|
||||
|
||||
过拟合的反面是*欠拟合*。当测试数据仍有改进空间时,就会发生欠拟合。发生这种情况的原因有很多: 如果模型不够强大,模型过于规范化,或者仅仅是没有经过足够长时间的训练。这意味着网络尚未学习训练数据中的相关模式。
|
||||
|
||||
但是,如果训练时间过长,则模型将开始过拟合并从训练数据中学习无法推广到测试数据的模式。我们需要保持平衡。如下所述,了解如何训练适当的时期是一项有用的技能。
|
||||
|
||||
为了防止过拟合,最好的解决方案是使用更多的训练数据。经过更多数据训练的模型自然会更好地推广。当这不再可能时,下一个最佳解决方案是使用正则化之类的技术。这些因素限制了模型可以存储的信息的数量和类型。如果一个网络只能存储少量模式,那么优化过程将迫使它专注于最突出的模式,这些模式有更好的概括机会。
|
||||
|
||||
在本笔记本中,我们将探讨两种常见的正则化技术(权重正则化和 dropout),并使用它们来改进我们的IMDB电影评论分类笔记本。
|
||||
|
||||
```python
|
||||
from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
|
||||
try:
|
||||
# %tensorflow_version only exists in Colab.
|
||||
%tensorflow_version 2.x
|
||||
except Exception:
|
||||
pass
|
||||
import tensorflow as tf
|
||||
from tensorflow import keras
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
print(tf.__version__)
|
||||
```
|
||||
|
||||
## 下载IMDB数据集
|
||||
|
||||
而不是像以前的笔记本中那样使用embedding,这里我们将对句子进行 multi-hot 编码。 该模型将很快适合训练集。 它将用于演示何时发生过拟合以及如何应对。
|
||||
|
||||
对列表进行 multi-hot 编码意味着将它们变成0和1的向量。 具体来说,这意味着例如将序列 `[3, 5]` 变成10,000维向量,该向量除了索引3和5将是1,其他将是全为零。
|
||||
|
||||
|
||||
```python
|
||||
NUM_WORDS = 10000
|
||||
|
||||
(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)
|
||||
|
||||
def multi_hot_sequences(sequences, dimension):
|
||||
# Create an all-zero matrix of shape (len(sequences), dimension)
|
||||
results = np.zeros((len(sequences), dimension))
|
||||
for i, word_indices in enumerate(sequences):
|
||||
results[i, word_indices] = 1.0 # set specific indices of results[i] to 1s
|
||||
return results
|
||||
|
||||
|
||||
train_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)
|
||||
test_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)
|
||||
```
|
||||
|
||||
让我们看一下产生的 multi-hot 向量之一。 单词索引按频率排序,因此可以预期在索引零附近有更多的1值,如我们在该图中所看到的:
|
||||
|
||||
```python
|
||||
plt.plot(train_data[0])
|
||||
```
|
||||
|
||||

|
||||
|
||||
## 证明过拟合
|
||||
|
||||
防止过拟合的最简单方法是减小模型的大小,即减小模型中可学习的参数的数量(由层数和每层单元数确定)。在深度学习中,模型中可学习参数的数量通常称为模型的“容量”。直观地讲,具有更多参数的模型将具有更多的“记忆能力”,因此将能够轻松学习训练样本与其目标之间的完美的字典式映射,这种映射没有任何泛化能力,但是在进行预测时这将是无用的根据以前看不见的数据。
|
||||
|
||||
始终牢记这一点: 深度学习模型往往擅长拟合训练数据,但真正的挑战是泛化而不是拟合。
|
||||
|
||||
另一方面,如果网络的存储资源有限,则将无法轻松地学习映射。为了最大程度地减少损失,它必须学习具有更强预测能力的压缩表示形式。同时,如果您使模型过小,将难以拟合训练数据。 “容量过多”和“容量不足”之间存在平衡。
|
||||
|
||||
不幸的是,没有神奇的公式来确定模型的正确大小或体系结构(根据层数或每层的正确大小)。您将不得不尝试使用一系列不同的体系结构。
|
||||
|
||||
为了找到合适的模型大小,最好从相对较少的图层和参数开始,然后开始增加图层的大小或添加新的图层,直到看到验证损失的收益递减为止。让我们在电影评论分类网络上尝试一下。
|
||||
|
||||
我们将仅使用 `Dense` 层作为基准来创建一个简单的模型,然后创建较小和较大的版本并进行比较。
|
||||
|
||||
|
||||
### Create a baseline model
|
||||
|
||||
|
||||
```python
|
||||
baseline_model = keras.Sequential([
|
||||
# `input_shape` is only required here so that `.summary` works.
|
||||
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
|
||||
keras.layers.Dense(16, activation='relu'),
|
||||
keras.layers.Dense(1, activation='sigmoid')
|
||||
])
|
||||
|
||||
baseline_model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy', 'binary_crossentropy'])
|
||||
|
||||
baseline_model.summary()
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
baseline_history = baseline_model.fit(train_data,
|
||||
train_labels,
|
||||
epochs=20,
|
||||
batch_size=512,
|
||||
validation_data=(test_data, test_labels),
|
||||
verbose=2)
|
||||
```
|
||||
|
||||
```
|
||||
Train on 25000 samples, validate on 25000 samples
|
||||
Epoch 1/20
|
||||
25000/25000 - 4s - loss: 0.5372 - accuracy: 0.7976 - binary_crossentropy: 0.5372 - val_loss: 0.3794 - val_accuracy: 0.8722 - val_binary_crossentropy: 0.3794
|
||||
Epoch 2/20
|
||||
25000/25000 - 2s - loss: 0.2769 - accuracy: 0.9060 - binary_crossentropy: 0.2769 - val_loss: 0.2880 - val_accuracy: 0.8878 - val_binary_crossentropy: 0.2880
|
||||
Epoch 3/20
|
||||
25000/25000 - 2s - loss: 0.1955 - accuracy: 0.9320 - binary_crossentropy: 0.1955 - val_loss: 0.2840 - val_accuracy: 0.8882 - val_binary_crossentropy: 0.2840
|
||||
Epoch 4/20
|
||||
25000/25000 - 2s - loss: 0.1551 - accuracy: 0.9480 - binary_crossentropy: 0.1551 - val_loss: 0.3017 - val_accuracy: 0.8818 - val_binary_crossentropy: 0.3017
|
||||
Epoch 5/20
|
||||
25000/25000 - 2s - loss: 0.1277 - accuracy: 0.9577 - binary_crossentropy: 0.1277 - val_loss: 0.3257 - val_accuracy: 0.8770 - val_binary_crossentropy: 0.3257
|
||||
Epoch 6/20
|
||||
25000/25000 - 2s - loss: 0.1086 - accuracy: 0.9659 - binary_crossentropy: 0.1086 - val_loss: 0.3563 - val_accuracy: 0.8730 - val_binary_crossentropy: 0.3563
|
||||
Epoch 7/20
|
||||
25000/25000 - 2s - loss: 0.0925 - accuracy: 0.9713 - binary_crossentropy: 0.0925 - val_loss: 0.3914 - val_accuracy: 0.8676 - val_binary_crossentropy: 0.3914
|
||||
Epoch 8/20
|
||||
25000/25000 - 2s - loss: 0.0779 - accuracy: 0.9776 - binary_crossentropy: 0.0779 - val_loss: 0.4238 - val_accuracy: 0.8672 - val_binary_crossentropy: 0.4238
|
||||
Epoch 9/20
|
||||
25000/25000 - 2s - loss: 0.0645 - accuracy: 0.9832 - binary_crossentropy: 0.0645 - val_loss: 0.4644 - val_accuracy: 0.8634 - val_binary_crossentropy: 0.4644
|
||||
Epoch 10/20
|
||||
25000/25000 - 2s - loss: 0.0540 - accuracy: 0.9874 - binary_crossentropy: 0.0540 - val_loss: 0.5092 - val_accuracy: 0.8596 - val_binary_crossentropy: 0.5092
|
||||
Epoch 11/20
|
||||
25000/25000 - 2s - loss: 0.0445 - accuracy: 0.9906 - binary_crossentropy: 0.0445 - val_loss: 0.5465 - val_accuracy: 0.8575 - val_binary_crossentropy: 0.5465
|
||||
Epoch 12/20
|
||||
25000/25000 - 2s - loss: 0.0360 - accuracy: 0.9936 - binary_crossentropy: 0.0360 - val_loss: 0.5877 - val_accuracy: 0.8549 - val_binary_crossentropy: 0.5877
|
||||
Epoch 13/20
|
||||
25000/25000 - 2s - loss: 0.0290 - accuracy: 0.9953 - binary_crossentropy: 0.0290 - val_loss: 0.6328 - val_accuracy: 0.8545 - val_binary_crossentropy: 0.6328
|
||||
Epoch 14/20
|
||||
25000/25000 - 2s - loss: 0.0222 - accuracy: 0.9970 - binary_crossentropy: 0.0222 - val_loss: 0.6753 - val_accuracy: 0.8525 - val_binary_crossentropy: 0.6753
|
||||
Epoch 15/20
|
||||
25000/25000 - 2s - loss: 0.0166 - accuracy: 0.9984 - binary_crossentropy: 0.0166 - val_loss: 0.7104 - val_accuracy: 0.8519 - val_binary_crossentropy: 0.7104
|
||||
Epoch 16/20
|
||||
25000/25000 - 2s - loss: 0.0122 - accuracy: 0.9991 - binary_crossentropy: 0.0122 - val_loss: 0.7475 - val_accuracy: 0.8507 - val_binary_crossentropy: 0.7475
|
||||
Epoch 17/20
|
||||
25000/25000 - 2s - loss: 0.0091 - accuracy: 0.9994 - binary_crossentropy: 0.0091 - val_loss: 0.7765 - val_accuracy: 0.8511 - val_binary_crossentropy: 0.7765
|
||||
Epoch 18/20
|
||||
25000/25000 - 2s - loss: 0.0065 - accuracy: 0.9995 - binary_crossentropy: 0.0065 - val_loss: 0.8110 - val_accuracy: 0.8502 - val_binary_crossentropy: 0.8110
|
||||
Epoch 19/20
|
||||
25000/25000 - 2s - loss: 0.0048 - accuracy: 0.9999 - binary_crossentropy: 0.0048 - val_loss: 0.8378 - val_accuracy: 0.8506 - val_binary_crossentropy: 0.8378
|
||||
Epoch 20/20
|
||||
25000/25000 - 2s - loss: 0.0036 - accuracy: 0.9999 - binary_crossentropy: 0.0036 - val_loss: 0.8565 - val_accuracy: 0.8504 - val_binary_crossentropy: 0.8565
|
||||
```
|
||||
|
||||
### 创建 smaller model
|
||||
|
||||
让我们创建一个隐藏单元更少的模型,以与我们刚刚创建的基线模型进行比较:
|
||||
|
||||
|
||||
```python
|
||||
smaller_model = keras.Sequential([
|
||||
keras.layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),
|
||||
keras.layers.Dense(4, activation='relu'),
|
||||
keras.layers.Dense(1, activation='sigmoid')
|
||||
])
|
||||
|
||||
smaller_model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy', 'binary_crossentropy'])
|
||||
|
||||
smaller_model.summary()
|
||||
```
|
||||
|
||||
并使用相同的数据训练模型:
|
||||
|
||||
|
||||
```python
|
||||
smaller_history = smaller_model.fit(train_data,
|
||||
train_labels,
|
||||
epochs=20,
|
||||
batch_size=512,
|
||||
validation_data=(test_data, test_labels),
|
||||
verbose=2)
|
||||
```
|
||||
|
||||
```
|
||||
Train on 25000 samples, validate on 25000 samples
|
||||
Epoch 1/20
|
||||
25000/25000 - 3s - loss: 0.6257 - accuracy: 0.6366 - binary_crossentropy: 0.6257 - val_loss: 0.5723 - val_accuracy: 0.7452 - val_binary_crossentropy: 0.5723
|
||||
Epoch 2/20
|
||||
25000/25000 - 2s - loss: 0.5220 - accuracy: 0.8021 - binary_crossentropy: 0.5220 - val_loss: 0.5128 - val_accuracy: 0.8185 - val_binary_crossentropy: 0.5128
|
||||
Epoch 3/20
|
||||
25000/25000 - 2s - loss: 0.4661 - accuracy: 0.8674 - binary_crossentropy: 0.4661 - val_loss: 0.4799 - val_accuracy: 0.8497 - val_binary_crossentropy: 0.4799
|
||||
Epoch 4/20
|
||||
25000/25000 - 2s - loss: 0.4271 - accuracy: 0.8999 - binary_crossentropy: 0.4271 - val_loss: 0.4595 - val_accuracy: 0.8634 - val_binary_crossentropy: 0.4595
|
||||
Epoch 5/20
|
||||
25000/25000 - 2s - loss: 0.3967 - accuracy: 0.9178 - binary_crossentropy: 0.3967 - val_loss: 0.4454 - val_accuracy: 0.8721 - val_binary_crossentropy: 0.4454
|
||||
Epoch 6/20
|
||||
25000/25000 - 2s - loss: 0.3715 - accuracy: 0.9320 - binary_crossentropy: 0.3715 - val_loss: 0.4366 - val_accuracy: 0.8744 - val_binary_crossentropy: 0.4366
|
||||
Epoch 7/20
|
||||
25000/25000 - 2s - loss: 0.3494 - accuracy: 0.9433 - binary_crossentropy: 0.3494 - val_loss: 0.4306 - val_accuracy: 0.8765 - val_binary_crossentropy: 0.4306
|
||||
Epoch 8/20
|
||||
25000/25000 - 2s - loss: 0.3294 - accuracy: 0.9515 - binary_crossentropy: 0.3294 - val_loss: 0.4292 - val_accuracy: 0.8751 - val_binary_crossentropy: 0.4292
|
||||
Epoch 9/20
|
||||
25000/25000 - 2s - loss: 0.3115 - accuracy: 0.9585 - binary_crossentropy: 0.3115 - val_loss: 0.4238 - val_accuracy: 0.8772 - val_binary_crossentropy: 0.4238
|
||||
Epoch 10/20
|
||||
25000/25000 - 2s - loss: 0.2948 - accuracy: 0.9648 - binary_crossentropy: 0.2948 - val_loss: 0.4226 - val_accuracy: 0.8767 - val_binary_crossentropy: 0.4226
|
||||
Epoch 11/20
|
||||
25000/25000 - 2s - loss: 0.2802 - accuracy: 0.9698 - binary_crossentropy: 0.2802 - val_loss: 0.4219 - val_accuracy: 0.8752 - val_binary_crossentropy: 0.4219
|
||||
Epoch 12/20
|
||||
25000/25000 - 2s - loss: 0.2658 - accuracy: 0.9741 - binary_crossentropy: 0.2658 - val_loss: 0.4264 - val_accuracy: 0.8728 - val_binary_crossentropy: 0.4264
|
||||
Epoch 13/20
|
||||
25000/25000 - 2s - loss: 0.2527 - accuracy: 0.9772 - binary_crossentropy: 0.2527 - val_loss: 0.4275 - val_accuracy: 0.8717 - val_binary_crossentropy: 0.4275
|
||||
Epoch 14/20
|
||||
25000/25000 - 2s - loss: 0.2408 - accuracy: 0.9800 - binary_crossentropy: 0.2408 - val_loss: 0.4370 - val_accuracy: 0.8712 - val_binary_crossentropy: 0.4370
|
||||
Epoch 15/20
|
||||
25000/25000 - 2s - loss: 0.2294 - accuracy: 0.9824 - binary_crossentropy: 0.2294 - val_loss: 0.4381 - val_accuracy: 0.8706 - val_binary_crossentropy: 0.4381
|
||||
Epoch 16/20
|
||||
25000/25000 - 2s - loss: 0.2184 - accuracy: 0.9852 - binary_crossentropy: 0.2184 - val_loss: 0.4574 - val_accuracy: 0.8676 - val_binary_crossentropy: 0.4574
|
||||
Epoch 17/20
|
||||
25000/25000 - 2s - loss: 0.2076 - accuracy: 0.9862 - binary_crossentropy: 0.2076 - val_loss: 0.4715 - val_accuracy: 0.8676 - val_binary_crossentropy: 0.4715
|
||||
Epoch 18/20
|
||||
25000/25000 - 2s - loss: 0.1972 - accuracy: 0.9881 - binary_crossentropy: 0.1972 - val_loss: 0.4931 - val_accuracy: 0.8667 - val_binary_crossentropy: 0.4931
|
||||
Epoch 19/20
|
||||
25000/25000 - 2s - loss: 0.1884 - accuracy: 0.9892 - binary_crossentropy: 0.1884 - val_loss: 0.4986 - val_accuracy: 0.8675 - val_binary_crossentropy: 0.4986
|
||||
Epoch 20/20
|
||||
25000/25000 - 2s - loss: 0.1799 - accuracy: 0.9902 - binary_crossentropy: 0.1799 - val_loss: 0.5162 - val_accuracy: 0.8664 - val_binary_crossentropy: 0.5162
|
||||
```
|
||||
|
||||
### 创建 bigger model
|
||||
|
||||
作为练习,您可以创建一个更大的模型,并查看它开始过拟合的速度。 接下来,让我们将具有更大容量的网络添加到此基准网络中,远远超出问题所能保证的范围:
|
||||
|
||||
|
||||
```python
|
||||
bigger_model = keras.models.Sequential([
|
||||
keras.layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),
|
||||
keras.layers.Dense(512, activation='relu'),
|
||||
keras.layers.Dense(1, activation='sigmoid')
|
||||
])
|
||||
|
||||
bigger_model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy','binary_crossentropy'])
|
||||
|
||||
bigger_model.summary()
|
||||
```
|
||||
|
||||
再次,使用相同的数据训练模型:
|
||||
|
||||
|
||||
```python
|
||||
bigger_history = bigger_model.fit(train_data, train_labels,
|
||||
epochs=20,
|
||||
batch_size=512,
|
||||
validation_data=(test_data, test_labels),
|
||||
verbose=2)
|
||||
```
|
||||
|
||||
```
|
||||
Train on 25000 samples, validate on 25000 samples
|
||||
Epoch 1/20
|
||||
25000/25000 - 3s - loss: 0.3532 - accuracy: 0.8450 - binary_crossentropy: 0.3532 - val_loss: 0.2926 - val_accuracy: 0.8806 - val_binary_crossentropy: 0.2926
|
||||
Epoch 2/20
|
||||
25000/25000 - 3s - loss: 0.1497 - accuracy: 0.9452 - binary_crossentropy: 0.1497 - val_loss: 0.3216 - val_accuracy: 0.8748 - val_binary_crossentropy: 0.3216
|
||||
Epoch 3/20
|
||||
25000/25000 - 3s - loss: 0.0543 - accuracy: 0.9832 - binary_crossentropy: 0.0543 - val_loss: 0.4412 - val_accuracy: 0.8673 - val_binary_crossentropy: 0.4412
|
||||
Epoch 4/20
|
||||
25000/25000 - 3s - loss: 0.0090 - accuracy: 0.9984 - binary_crossentropy: 0.0090 - val_loss: 0.5789 - val_accuracy: 0.8673 - val_binary_crossentropy: 0.5789
|
||||
Epoch 5/20
|
||||
25000/25000 - 3s - loss: 0.0020 - accuracy: 0.9999 - binary_crossentropy: 0.0020 - val_loss: 0.6779 - val_accuracy: 0.8697 - val_binary_crossentropy: 0.6779
|
||||
Epoch 6/20
|
||||
25000/25000 - 3s - loss: 2.8322e-04 - accuracy: 1.0000 - binary_crossentropy: 2.8322e-04 - val_loss: 0.7258 - val_accuracy: 0.8700 - val_binary_crossentropy: 0.7258
|
||||
Epoch 7/20
|
||||
25000/25000 - 3s - loss: 1.5209e-04 - accuracy: 1.0000 - binary_crossentropy: 1.5209e-04 - val_loss: 0.7596 - val_accuracy: 0.8701 - val_binary_crossentropy: 0.7596
|
||||
Epoch 8/20
|
||||
25000/25000 - 3s - loss: 1.0533e-04 - accuracy: 1.0000 - binary_crossentropy: 1.0533e-04 - val_loss: 0.7842 - val_accuracy: 0.8703 - val_binary_crossentropy: 0.7842
|
||||
Epoch 9/20
|
||||
25000/25000 - 3s - loss: 7.9425e-05 - accuracy: 1.0000 - binary_crossentropy: 7.9425e-05 - val_loss: 0.8044 - val_accuracy: 0.8705 - val_binary_crossentropy: 0.8044
|
||||
Epoch 10/20
|
||||
25000/25000 - 3s - loss: 6.2468e-05 - accuracy: 1.0000 - binary_crossentropy: 6.2468e-05 - val_loss: 0.8212 - val_accuracy: 0.8710 - val_binary_crossentropy: 0.8212
|
||||
Epoch 11/20
|
||||
25000/25000 - 3s - loss: 5.0610e-05 - accuracy: 1.0000 - binary_crossentropy: 5.0610e-05 - val_loss: 0.8377 - val_accuracy: 0.8707 - val_binary_crossentropy: 0.8377
|
||||
Epoch 12/20
|
||||
25000/25000 - 3s - loss: 4.1791e-05 - accuracy: 1.0000 - binary_crossentropy: 4.1791e-05 - val_loss: 0.8515 - val_accuracy: 0.8708 - val_binary_crossentropy: 0.8515
|
||||
Epoch 13/20
|
||||
25000/25000 - 3s - loss: 3.4956e-05 - accuracy: 1.0000 - binary_crossentropy: 3.4956e-05 - val_loss: 0.8652 - val_accuracy: 0.8708 - val_binary_crossentropy: 0.8652
|
||||
Epoch 14/20
|
||||
25000/25000 - 3s - loss: 2.9664e-05 - accuracy: 1.0000 - binary_crossentropy: 2.9664e-05 - val_loss: 0.8777 - val_accuracy: 0.8708 - val_binary_crossentropy: 0.8777
|
||||
Epoch 15/20
|
||||
25000/25000 - 3s - loss: 2.5332e-05 - accuracy: 1.0000 - binary_crossentropy: 2.5332e-05 - val_loss: 0.8893 - val_accuracy: 0.8706 - val_binary_crossentropy: 0.8893
|
||||
Epoch 16/20
|
||||
25000/25000 - 3s - loss: 2.1888e-05 - accuracy: 1.0000 - binary_crossentropy: 2.1888e-05 - val_loss: 0.9009 - val_accuracy: 0.8708 - val_binary_crossentropy: 0.9009
|
||||
Epoch 17/20
|
||||
25000/25000 - 3s - loss: 1.9007e-05 - accuracy: 1.0000 - binary_crossentropy: 1.9007e-05 - val_loss: 0.9121 - val_accuracy: 0.8706 - val_binary_crossentropy: 0.9121
|
||||
Epoch 18/20
|
||||
25000/25000 - 3s - loss: 1.6598e-05 - accuracy: 1.0000 - binary_crossentropy: 1.6598e-05 - val_loss: 0.9229 - val_accuracy: 0.8708 - val_binary_crossentropy: 0.9229
|
||||
Epoch 19/20
|
||||
25000/25000 - 3s - loss: 1.4588e-05 - accuracy: 1.0000 - binary_crossentropy: 1.4588e-05 - val_loss: 0.9331 - val_accuracy: 0.8707 - val_binary_crossentropy: 0.9331
|
||||
Epoch 20/20
|
||||
25000/25000 - 3s - loss: 1.2884e-05 - accuracy: 1.0000 - binary_crossentropy: 1.2884e-05 - val_loss: 0.9433 - val_accuracy: 0.8707 - val_binary_crossentropy: 0.9433
|
||||
```
|
||||
|
||||
### 绘制训练和验证损失
|
||||
|
||||
<!--TODO(markdaoust): This should be a one-liner with tensorboard -->
|
||||
|
||||
实线表示训练损失,而虚线表示验证损失(请记住: 验证损失越小表示模型越好)。 在这里,较小的网络比基准模型开始过度拟合(在6个时期而不是4个周期之后),并且一旦开始过度拟合,其性能下降的速度就会慢得多。
|
||||
|
||||
```python
|
||||
def plot_history(histories, key='binary_crossentropy'):
|
||||
plt.figure(figsize=(16,10))
|
||||
|
||||
for name, history in histories:
|
||||
val = plt.plot(history.epoch, history.history['val_'+key],
|
||||
'--', label=name.title()+' Val')
|
||||
plt.plot(history.epoch, history.history[key], color=val[0].get_color(),
|
||||
label=name.title()+' Train')
|
||||
|
||||
plt.xlabel('Epochs')
|
||||
plt.ylabel(key.replace('_',' ').title())
|
||||
plt.legend()
|
||||
|
||||
plt.xlim([0,max(history.epoch)])
|
||||
|
||||
|
||||
plot_history([('baseline', baseline_history),
|
||||
('smaller', smaller_history),
|
||||
('bigger', bigger_history)])
|
||||
```
|
||||
|
||||
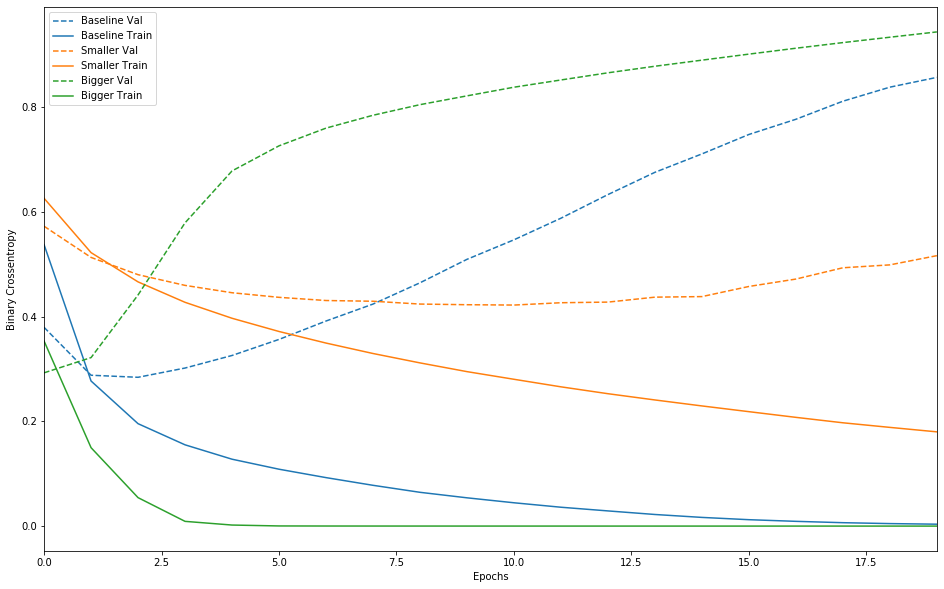
|
||||
|
||||
请注意,较大的网络仅在一个时期后就开始过拟合,而且过拟合严重。网络的容量越多,将能够更快地对训练数据进行建模(导致较低的训练损失),但网络越容易过拟合(导致训练和验证损失之间存在较大差异)。
|
||||
|
||||
## 防止过度拟合的策略
|
||||
|
||||
### 添加权重正则化
|
||||
|
||||
您可能熟悉Occam的Razor原理: 给某事两种解释,最可能正确的解释是“最简单”的解释,即假设最少的一种。这也适用于通过神经网络学习的模型: 给定一些训练数据和网络体系结构,可以使用多组权重值(多个模型)来解释数据,并且较简单的模型比复杂的模型不太可能过拟合。
|
||||
|
||||
在这种情况下,“简单模型”是参数值的分布具有较小熵的模型(或如上节所述,具有总共较少参数的模型)。因此,减轻过拟合的一种通用方法是通过仅将网络的权重强制取小的值来对网络的复杂性施加约束,这使得权重值的分布更加“规则”。这称为“权重调整”,它是通过向网络的损失函数中添加与权重较大相关的成本来完成的。以下有两种形式:
|
||||
|
||||
* [L1正则化](https://developers.google.com/machine-learning/glossary/#L1_regularization),其中增加的成本与权重系数的绝对值成正比(即所谓的“ L1规范” ”)。
|
||||
|
||||
* [L2正则化](https://developers.google.com/machine-learning/glossary/#L2_regularization),其中增加的成本与权重系数的值的平方成正比(即与平方的平方成正比)权重的“ L2规范”。 L2正则化在神经网络中也称为权重衰减。不要让其他名称使您感到困惑: 权重衰减在数学上与L2正则化完全相同。
|
||||
|
||||
L1正则化引入稀疏性,以使您的某些权重参数为零。 L2正则化将惩罚权重参数而不使其稀疏,这是L2更为常见的原因之一。
|
||||
|
||||
在 `tf.keras` 中,通过将权重正则化器实例作为关键字参数传递给图层来添加权重正则化。让我们现在添加L2权重正则化。
|
||||
|
||||
|
||||
```python
|
||||
l2_model = keras.models.Sequential([
|
||||
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
|
||||
activation='relu', input_shape=(NUM_WORDS,)),
|
||||
keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),
|
||||
activation='relu'),
|
||||
keras.layers.Dense(1, activation='sigmoid')
|
||||
])
|
||||
|
||||
l2_model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy', 'binary_crossentropy'])
|
||||
|
||||
l2_model_history = l2_model.fit(train_data, train_labels,
|
||||
epochs=20,
|
||||
batch_size=512,
|
||||
validation_data=(test_data, test_labels),
|
||||
verbose=2)
|
||||
```
|
||||
|
||||
```
|
||||
Train on 25000 samples, validate on 25000 samples
|
||||
Epoch 1/20
|
||||
25000/25000 - 3s - loss: 0.5267 - accuracy: 0.7989 - binary_crossentropy: 0.4870 - val_loss: 0.3816 - val_accuracy: 0.8753 - val_binary_crossentropy: 0.3416
|
||||
Epoch 2/20
|
||||
25000/25000 - 2s - loss: 0.2978 - accuracy: 0.9096 - binary_crossentropy: 0.2536 - val_loss: 0.3314 - val_accuracy: 0.8883 - val_binary_crossentropy: 0.2842
|
||||
Epoch 3/20
|
||||
25000/25000 - 2s - loss: 0.2444 - accuracy: 0.9324 - binary_crossentropy: 0.1947 - val_loss: 0.3386 - val_accuracy: 0.8860 - val_binary_crossentropy: 0.2869
|
||||
Epoch 4/20
|
||||
25000/25000 - 2s - loss: 0.2207 - accuracy: 0.9419 - binary_crossentropy: 0.1671 - val_loss: 0.3539 - val_accuracy: 0.8802 - val_binary_crossentropy: 0.2991
|
||||
Epoch 5/20
|
||||
25000/25000 - 2s - loss: 0.2049 - accuracy: 0.9501 - binary_crossentropy: 0.1489 - val_loss: 0.3682 - val_accuracy: 0.8790 - val_binary_crossentropy: 0.3111
|
||||
Epoch 6/20
|
||||
25000/25000 - 2s - loss: 0.1938 - accuracy: 0.9557 - binary_crossentropy: 0.1354 - val_loss: 0.3854 - val_accuracy: 0.8758 - val_binary_crossentropy: 0.3263
|
||||
Epoch 7/20
|
||||
25000/25000 - 2s - loss: 0.1857 - accuracy: 0.9567 - binary_crossentropy: 0.1259 - val_loss: 0.4061 - val_accuracy: 0.8716 - val_binary_crossentropy: 0.3456
|
||||
Epoch 8/20
|
||||
25000/25000 - 2s - loss: 0.1791 - accuracy: 0.9622 - binary_crossentropy: 0.1176 - val_loss: 0.4199 - val_accuracy: 0.8684 - val_binary_crossentropy: 0.3579
|
||||
Epoch 9/20
|
||||
25000/25000 - 2s - loss: 0.1732 - accuracy: 0.9634 - binary_crossentropy: 0.1105 - val_loss: 0.4332 - val_accuracy: 0.8682 - val_binary_crossentropy: 0.3701
|
||||
Epoch 10/20
|
||||
25000/25000 - 2s - loss: 0.1676 - accuracy: 0.9660 - binary_crossentropy: 0.1042 - val_loss: 0.4559 - val_accuracy: 0.8614 - val_binary_crossentropy: 0.3919
|
||||
Epoch 11/20
|
||||
25000/25000 - 2s - loss: 0.1656 - accuracy: 0.9666 - binary_crossentropy: 0.1009 - val_loss: 0.4620 - val_accuracy: 0.8618 - val_binary_crossentropy: 0.3967
|
||||
Epoch 12/20
|
||||
25000/25000 - 2s - loss: 0.1599 - accuracy: 0.9692 - binary_crossentropy: 0.0940 - val_loss: 0.4786 - val_accuracy: 0.8634 - val_binary_crossentropy: 0.4125
|
||||
Epoch 13/20
|
||||
25000/25000 - 2s - loss: 0.1575 - accuracy: 0.9696 - binary_crossentropy: 0.0910 - val_loss: 0.4944 - val_accuracy: 0.8600 - val_binary_crossentropy: 0.4275
|
||||
Epoch 14/20
|
||||
25000/25000 - 2s - loss: 0.1520 - accuracy: 0.9718 - binary_crossentropy: 0.0851 - val_loss: 0.5079 - val_accuracy: 0.8562 - val_binary_crossentropy: 0.4406
|
||||
Epoch 15/20
|
||||
25000/25000 - 2s - loss: 0.1521 - accuracy: 0.9719 - binary_crossentropy: 0.0845 - val_loss: 0.5203 - val_accuracy: 0.8586 - val_binary_crossentropy: 0.4521
|
||||
Epoch 16/20
|
||||
25000/25000 - 2s - loss: 0.1481 - accuracy: 0.9737 - binary_crossentropy: 0.0798 - val_loss: 0.5309 - val_accuracy: 0.8576 - val_binary_crossentropy: 0.4623
|
||||
Epoch 17/20
|
||||
25000/25000 - 2s - loss: 0.1452 - accuracy: 0.9754 - binary_crossentropy: 0.0764 - val_loss: 0.5384 - val_accuracy: 0.8567 - val_binary_crossentropy: 0.4694
|
||||
Epoch 18/20
|
||||
25000/25000 - 2s - loss: 0.1408 - accuracy: 0.9775 - binary_crossentropy: 0.0718 - val_loss: 0.5470 - val_accuracy: 0.8565 - val_binary_crossentropy: 0.4780
|
||||
Epoch 19/20
|
||||
25000/25000 - 2s - loss: 0.1376 - accuracy: 0.9773 - binary_crossentropy: 0.0687 - val_loss: 0.5587 - val_accuracy: 0.8554 - val_binary_crossentropy: 0.4896
|
||||
Epoch 20/20
|
||||
25000/25000 - 2s - loss: 0.1362 - accuracy: 0.9787 - binary_crossentropy: 0.0671 - val_loss: 0.5690 - val_accuracy: 0.8556 - val_binary_crossentropy: 0.4997
|
||||
```
|
||||
|
||||
`l2(0.001)` 表示该层权重矩阵中的每个系数将为网络的总损耗增加 `0.001 * weight_coefficient_value**2`。 请注意,由于此惩罚仅在训练时增加,因此在训练时此网络的损失将比在测试时高得多。
|
||||
|
||||
这是我们的L2正则化惩罚的影响:
|
||||
|
||||
```python
|
||||
plot_history([('baseline', baseline_history),
|
||||
('l2', l2_model_history)])
|
||||
```
|
||||
|
||||
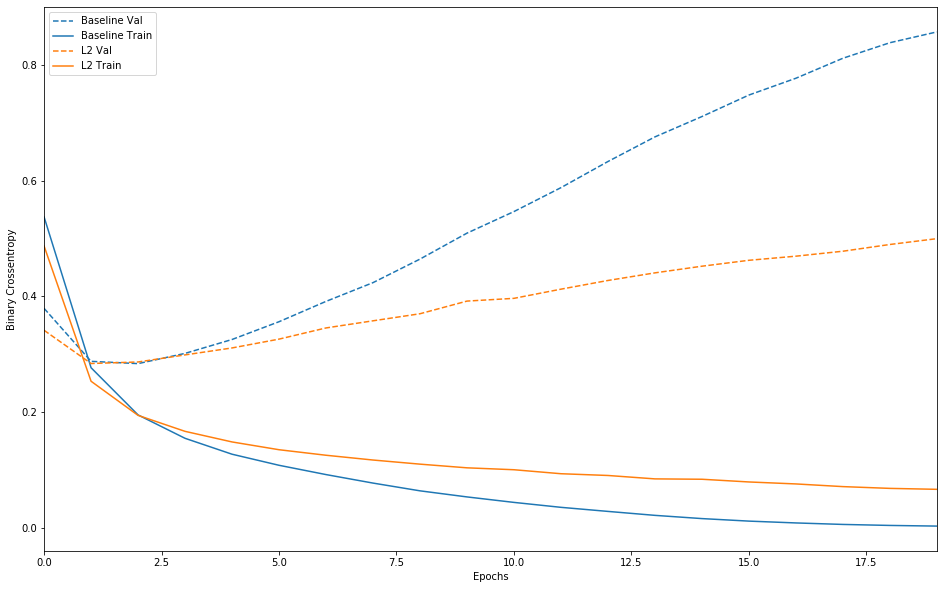
|
||||
|
||||
如您所见,即使两个模型具有相同数量的参数,L2正则化模型也比基线模型具有更高的抗过度拟合能力。
|
||||
|
||||
### 添加 dropout
|
||||
|
||||
dropout 是 Hinton 和他在多伦多大学的学生开发的最有效,最常用的神经网络正则化技术之一。应用于图层的辍学包括在训练过程中随机“dropping out”(即设置为零)该图层的许多输出特征。假设在训练过程中,给定的图层通常会为给定的输入样本返回向量 [0.2, 0.5, 1.3, 0.8, 1.1];应用删除后,此向量将有一些零个条目随机分布,例如 [0, 0.5, 1.3, 0, 1.1]。 “dropout 率”是被清零的特征的一部分。通常设置在0.2到0.5之间。在测试时,不会丢失任何单元,而是将图层的输出值按等于丢失率的比例缩小,以平衡一个活跃的单元(而不是训练时)的事实。
|
||||
|
||||
在tf.keras中,您可以通过Dropout层在网络中引入Dropout,该层将立即应用于该层的输出。
|
||||
|
||||
让我们在IMDB网络中添加两个Dropout层,看看它们在减少过拟合方面的表现如何:
|
||||
|
||||
|
||||
```python
|
||||
dpt_model = keras.models.Sequential([
|
||||
keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),
|
||||
keras.layers.Dropout(0.5),
|
||||
keras.layers.Dense(16, activation='relu'),
|
||||
keras.layers.Dropout(0.5),
|
||||
keras.layers.Dense(1, activation='sigmoid')
|
||||
])
|
||||
|
||||
dpt_model.compile(optimizer='adam',
|
||||
loss='binary_crossentropy',
|
||||
metrics=['accuracy','binary_crossentropy'])
|
||||
|
||||
dpt_model_history = dpt_model.fit(train_data, train_labels,
|
||||
epochs=20,
|
||||
batch_size=512,
|
||||
validation_data=(test_data, test_labels),
|
||||
verbose=2)
|
||||
```
|
||||
|
||||
```
|
||||
Train on 25000 samples, validate on 25000 samples
|
||||
Epoch 1/20
|
||||
25000/25000 - 3s - loss: 0.6413 - accuracy: 0.6321 - binary_crossentropy: 0.6413 - val_loss: 0.5159 - val_accuracy: 0.8523 - val_binary_crossentropy: 0.5159
|
||||
Epoch 2/20
|
||||
25000/25000 - 2s - loss: 0.4843 - accuracy: 0.7935 - binary_crossentropy: 0.4843 - val_loss: 0.3755 - val_accuracy: 0.8818 - val_binary_crossentropy: 0.3755
|
||||
Epoch 3/20
|
||||
25000/25000 - 2s - loss: 0.3726 - accuracy: 0.8626 - binary_crossentropy: 0.3726 - val_loss: 0.2985 - val_accuracy: 0.8888 - val_binary_crossentropy: 0.2985
|
||||
Epoch 4/20
|
||||
25000/25000 - 2s - loss: 0.3056 - accuracy: 0.8994 - binary_crossentropy: 0.3056 - val_loss: 0.2808 - val_accuracy: 0.8894 - val_binary_crossentropy: 0.2808
|
||||
Epoch 5/20
|
||||
25000/25000 - 2s - loss: 0.2530 - accuracy: 0.9180 - binary_crossentropy: 0.2530 - val_loss: 0.2771 - val_accuracy: 0.8883 - val_binary_crossentropy: 0.2771
|
||||
Epoch 6/20
|
||||
25000/25000 - 2s - loss: 0.2226 - accuracy: 0.9316 - binary_crossentropy: 0.2226 - val_loss: 0.2860 - val_accuracy: 0.8859 - val_binary_crossentropy: 0.2860
|
||||
Epoch 7/20
|
||||
25000/25000 - 2s - loss: 0.1951 - accuracy: 0.9422 - binary_crossentropy: 0.1951 - val_loss: 0.2983 - val_accuracy: 0.8855 - val_binary_crossentropy: 0.2983
|
||||
Epoch 8/20
|
||||
25000/25000 - 2s - loss: 0.1748 - accuracy: 0.9478 - binary_crossentropy: 0.1748 - val_loss: 0.3184 - val_accuracy: 0.8828 - val_binary_crossentropy: 0.3184
|
||||
Epoch 9/20
|
||||
25000/25000 - 2s - loss: 0.1537 - accuracy: 0.9533 - binary_crossentropy: 0.1537 - val_loss: 0.3224 - val_accuracy: 0.8822 - val_binary_crossentropy: 0.3224
|
||||
Epoch 10/20
|
||||
25000/25000 - 2s - loss: 0.1397 - accuracy: 0.9580 - binary_crossentropy: 0.1397 - val_loss: 0.3558 - val_accuracy: 0.8811 - val_binary_crossentropy: 0.3558
|
||||
Epoch 11/20
|
||||
25000/25000 - 2s - loss: 0.1253 - accuracy: 0.9623 - binary_crossentropy: 0.1253 - val_loss: 0.3720 - val_accuracy: 0.8783 - val_binary_crossentropy: 0.3720
|
||||
Epoch 12/20
|
||||
25000/25000 - 2s - loss: 0.1132 - accuracy: 0.9674 - binary_crossentropy: 0.1132 - val_loss: 0.4028 - val_accuracy: 0.8787 - val_binary_crossentropy: 0.4028
|
||||
Epoch 13/20
|
||||
25000/25000 - 2s - loss: 0.1061 - accuracy: 0.9681 - binary_crossentropy: 0.1061 - val_loss: 0.4139 - val_accuracy: 0.8790 - val_binary_crossentropy: 0.4139
|
||||
Epoch 14/20
|
||||
25000/25000 - 2s - loss: 0.0964 - accuracy: 0.9708 - binary_crossentropy: 0.0964 - val_loss: 0.4399 - val_accuracy: 0.8772 - val_binary_crossentropy: 0.4399
|
||||
Epoch 15/20
|
||||
25000/25000 - 2s - loss: 0.0911 - accuracy: 0.9712 - binary_crossentropy: 0.0911 - val_loss: 0.4620 - val_accuracy: 0.8785 - val_binary_crossentropy: 0.4620
|
||||
Epoch 16/20
|
||||
25000/25000 - 2s - loss: 0.0851 - accuracy: 0.9734 - binary_crossentropy: 0.0851 - val_loss: 0.4771 - val_accuracy: 0.8786 - val_binary_crossentropy: 0.4771
|
||||
Epoch 17/20
|
||||
25000/25000 - 2s - loss: 0.0807 - accuracy: 0.9750 - binary_crossentropy: 0.0807 - val_loss: 0.4997 - val_accuracy: 0.8773 - val_binary_crossentropy: 0.4997
|
||||
Epoch 18/20
|
||||
25000/25000 - 2s - loss: 0.0715 - accuracy: 0.9767 - binary_crossentropy: 0.0715 - val_loss: 0.5260 - val_accuracy: 0.8758 - val_binary_crossentropy: 0.5260
|
||||
Epoch 19/20
|
||||
25000/25000 - 2s - loss: 0.0714 - accuracy: 0.9766 - binary_crossentropy: 0.0714 - val_loss: 0.5766 - val_accuracy: 0.8744 - val_binary_crossentropy: 0.5766
|
||||
Epoch 20/20
|
||||
25000/25000 - 2s - loss: 0.0687 - accuracy: 0.9772 - binary_crossentropy: 0.0687 - val_loss: 0.5498 - val_accuracy: 0.8754 - val_binary_crossentropy: 0.5498
|
||||
```
|
||||
|
||||
|
||||
```python
|
||||
plot_history([('baseline', baseline_history),
|
||||
('dropout', dpt_model_history)])
|
||||
```
|
||||
|
||||
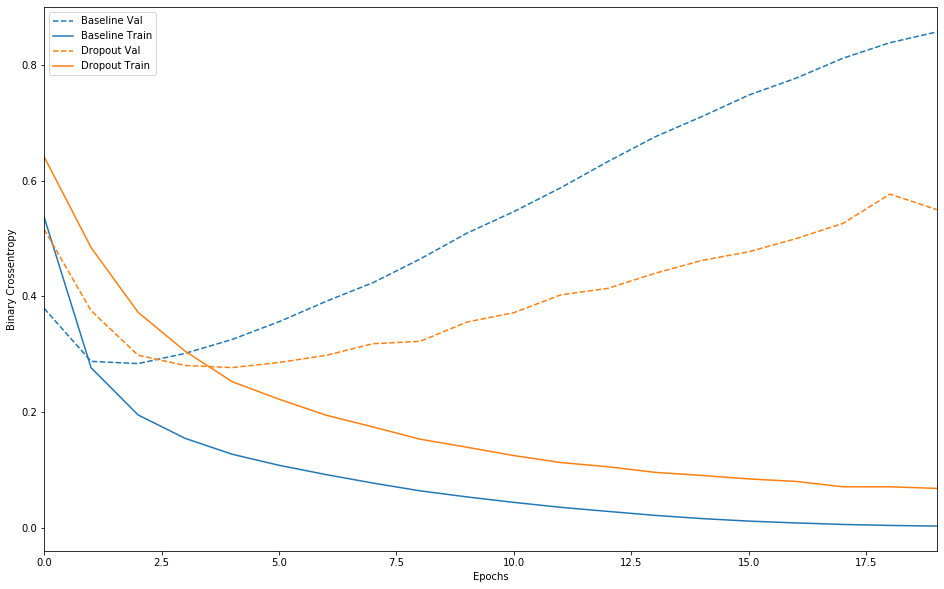
|
||||
|
||||
添加 dropout 是对基线模型的明显改进。
|
||||
|
||||
回顾一下: 以下是防止神经网络过拟合的最常用方法:
|
||||
|
||||
* 获取更多训练数据
|
||||
* 减少网络容量
|
||||
* 添加权重调整
|
||||
* 添加 dropout
|
||||
|
||||
本指南未涵盖的两个重要方法是数据增强和批处理规范化。
|
||||
|
|
@ -1,5 +0,0 @@
|
|||
# 实战项目 4 古诗词自动生成
|
||||
|
||||
* 代码: src/py3.x/tensorflow2.x/text_gru.py
|
||||
|
||||
后续慢慢更新
|
||||
|
|
@ -1,62 +0,0 @@
|
|||
# Bert 项目实战
|
||||
|
||||
```
|
||||
题外话:
|
||||
我感觉的确很惭愧
|
||||
那些在NLP领域一直都说自己很牛逼的公司?
|
||||
为啥中文通用的预训练模型是Google,而不是我们热熟能详的国内互联网公司?
|
||||
```
|
||||
|
||||
## 基本介绍
|
||||
|
||||
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。
|
||||
|
||||
该模型有以下主要优点:
|
||||
|
||||
1. 采用MLM对`双向的Transformers`进行预训练,以生成深层的双向语言表征,可以更好的理解上下文信息
|
||||
2. 预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
|
||||
|
||||
|
||||

|
||||
|
||||
总结一下:
|
||||
|
||||
1. token embeddings 表示的是词向量,第一个单词是CLS,可以用于之后的分类任务;SEP分割句子的
|
||||
2. segment embeddings 用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
|
||||
3. position embeddings 表示位置信息(索引ID)
|
||||
|
||||
例如:
|
||||
|
||||
这里包含keras-bert的三个例子,分别是文本分类、关系抽取和主体抽取,都是在官方发布的预训练权重基础上进行微调来做的。
|
||||
|
||||
---
|
||||
|
||||
## 提问环节:
|
||||
|
||||
> 1.bert中的[CLS]甚意思?
|
||||
|
||||
bert论文中提到: “GPT uses a sentence separator ([SEP]) and classifier token ([CLS]) which are only introduced at fine-tuning time; BERT learns [SEP], [CLS] and sentence A/B embeddings during pre-training.”
|
||||
|
||||
说明[CLS]不是bert原创,在GPT中就有。在GPT中用于句子的分类,判断[CLS]开头的句子是不是下一句。
|
||||
|
||||
> 2.单向语言模型和双向语言模型
|
||||
|
||||
* 单向语言模型是指: 从左到右或者从右到左,使其只能获取单方向的上下文信息
|
||||
* 双向语言模型是指: 不受单向的限制,可以更好的理解上下文信息
|
||||
|
||||
|
||||
> 3.预训练模型
|
||||
|
||||
例如我们今天利用A数据训练了一个A模型,第二次我们有新的预料,在A的基础上,做了微调(fine-tuning),得到一个更好的B模型。而模型在这个过程中,是预先训练好,方便下一个预料进行迭代式训练。
|
||||
|
||||
---
|
||||
|
||||
* https://www.cnblogs.com/dogecheng/p/11617940.html
|
||||
* https://blog.csdn.net/zkq_1986/article/details/100155596
|
||||
* https://blog.csdn.net/yangfengling1023/article/details/84025313
|
||||
* https://zhuanlan.zhihu.com/p/98855346
|
||||
* https://blog.csdn.net/weixin_42598761/article/details/104592171
|
||||
* https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
|
||||
* pip install git+https://www.github.com/keras-team/keras-contrib.git
|
||||
* pip install keras-bert
|
||||
|
||||
|
|
@ -0,0 +1 @@
|
|||
# 01\. Python 工具
|
||||
|
|
@ -0,0 +1,148 @@
|
|||
# Python 简介
|
||||
|
||||
## **Python** 历史
|
||||
|
||||
`Python` 的创始人为荷兰人吉多·范罗苏姆(`Guido van Rossum`)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为 ABC 语言的一种继承。之所以选中 `Python` 作为程序的名字,是因为他是 BBC 电视剧——蒙提·派森的飞行马戏团(`Monty Python's Flying Circus`)的爱好者。
|
||||
|
||||
1991年,第一个 Python 编译器诞生。它是用C语言实现的,并能够调用C语言的库文件。
|
||||
|
||||
`Python 2.0` 于 2000 年 10 月 16 日发布,增加了实现完整的垃圾回收,并且支持 `Unicode`。
|
||||
|
||||
`Python 3.0` 于 2008 年 12 月 3 日发布,此版不完全兼容之前的 `Python` 源代码。不过,很多新特性后来也被移植到旧的 `Python 2.6/2.7` 版本。
|
||||
|
||||
## 第一行Python代码
|
||||
|
||||
安装好 `Python` 之后,在命令行下输入:
|
||||
|
||||
```py
|
||||
python
|
||||
```
|
||||
|
||||
就可以进入 `Python` 解释器的页面。
|
||||
|
||||
按照惯例,第一行代码应该是输出 `"hello world!"`:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
print "hello world!"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world!
|
||||
|
||||
```
|
||||
|
||||
相对与 `Java,C` 等语言,`Python` 仅仅使用一行语句就完成的了这个任务。
|
||||
|
||||
可以将这句话的内容保存到一个文本文件中,并使用后缀名 `.py` 结尾,例如 `hello_world.py`,在命令行下运行这个程序:
|
||||
|
||||
```py
|
||||
python hello_world.py
|
||||
```
|
||||
|
||||
也会输出 `"hello world!"` 的结果。
|
||||
|
||||
## Python 之禅
|
||||
|
||||
在 **Python** 解释器下输入
|
||||
|
||||
`import this`
|
||||
|
||||
会出来这样一首小诗:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
import this
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
The Zen of Python, by Tim Peters
|
||||
|
||||
Beautiful is better than ugly.
|
||||
Explicit is better than implicit.
|
||||
Simple is better than complex.
|
||||
Complex is better than complicated.
|
||||
Flat is better than nested.
|
||||
Sparse is better than dense.
|
||||
Readability counts.
|
||||
Special cases aren't special enough to break the rules.
|
||||
Although practicality beats purity.
|
||||
Errors should never pass silently.
|
||||
Unless explicitly silenced.
|
||||
In the face of ambiguity, refuse the temptation to guess.
|
||||
There should be one-- and preferably only one --obvious way to do it.
|
||||
Although that way may not be obvious at first unless you're Dutch.
|
||||
Now is better than never.
|
||||
Although never is often better than *right* now.
|
||||
If the implementation is hard to explain, it's a bad idea.
|
||||
If the implementation is easy to explain, it may be a good idea.
|
||||
Namespaces are one honking great idea -- let's do more of those!
|
||||
|
||||
```
|
||||
|
||||
这首诗反映了**Python**的设计哲学——**Python**是一种追求优雅,明确,简单的编程语言,但事实上,产生这首诗的代码并没有写的那么简单易懂:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
s = """Gur Mra bs Clguba, ol Gvz Crgref
|
||||
|
||||
Ornhgvshy vf orggre guna htyl.
|
||||
Rkcyvpvg vf orggre guna vzcyvpvg.
|
||||
Fvzcyr vf orggre guna pbzcyrk.
|
||||
Pbzcyrk vf orggre guna pbzcyvpngrq.
|
||||
Syng vf orggre guna arfgrq.
|
||||
Fcnefr vf orggre guna qrafr.
|
||||
Ernqnovyvgl pbhagf.
|
||||
Fcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.
|
||||
Nygubhtu cenpgvpnyvgl orngf chevgl.
|
||||
Reebef fubhyq arire cnff fvyragyl.
|
||||
Hayrff rkcyvpvgyl fvyraprq.
|
||||
Va gur snpr bs nzovthvgl, ershfr gur grzcgngvba gb thrff.
|
||||
Gurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.
|
||||
Nygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.
|
||||
Abj vf orggre guna arire.
|
||||
Nygubhtu arire vf bsgra orggre guna *evtug* abj.
|
||||
Vs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.
|
||||
Vs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.
|
||||
Anzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!"""
|
||||
|
||||
d = {}
|
||||
for c in (65, 97):
|
||||
for i in range(26):
|
||||
d[chr(i+c)] = chr((i+13) % 26 + c)
|
||||
|
||||
print "".join([d.get(c, c) for c in s])
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
The Zen of Python, by Tim Peters
|
||||
|
||||
Beautiful is better than ugly.
|
||||
Explicit is better than implicit.
|
||||
Simple is better than complex.
|
||||
Complex is better than complicated.
|
||||
Flat is better than nested.
|
||||
Sparse is better than dense.
|
||||
Readability counts.
|
||||
Special cases aren't special enough to break the rules.
|
||||
Although practicality beats purity.
|
||||
Errors should never pass silently.
|
||||
Unless explicitly silenced.
|
||||
In the face of ambiguity, refuse the temptation to guess.
|
||||
There should be one-- and preferably only one --obvious way to do it.
|
||||
Although that way may not be obvious at first unless you're Dutch.
|
||||
Now is better than never.
|
||||
Although never is often better than *right* now.
|
||||
If the implementation is hard to explain, it's a bad idea.
|
||||
If the implementation is easy to explain, it may be a good idea.
|
||||
Namespaces are one honking great idea -- let's do more of those!
|
||||
|
||||
```
|
||||
|
||||
> Life is short. Use Python.
|
||||
|
|
@ -0,0 +1,407 @@
|
|||
# Ipython 解释器
|
||||
|
||||
## 进入ipython
|
||||
|
||||
通常我们并不使用**Python**自带的解释器,而是使用另一个比较方便的解释器——**ipython**解释器,命令行下输入:
|
||||
|
||||
```py
|
||||
ipython
|
||||
```
|
||||
|
||||
即可进入**ipython**解释器。
|
||||
|
||||
所有在**python**解释器下可以运行的代码都可以在**ipython**解释器下运行:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
print "hello, world"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello, world
|
||||
|
||||
```
|
||||
|
||||
可以进行简单赋值操作:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = 1
|
||||
|
||||
```
|
||||
|
||||
直接在解释器中输入变量名,会显示变量的值(不需要加`print`):
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
b = [1, 2, 3]
|
||||
|
||||
```
|
||||
|
||||
## ipython magic命令
|
||||
|
||||
**ipython**解释器提供了很多以百分号`%`开头的`magic`命令,这些命令很像linux系统下的命令行命令(事实上有些是一样的)。
|
||||
|
||||
查看所有的`magic`命令:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
%lsmagic
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
Available line magics:
|
||||
%alias %alias_magic %autocall %automagic %autosave %bookmark %cd %clear %cls %colors %config %connect_info %copy %ddir %debug %dhist %dirs %doctest_mode %echo %ed %edit %env %gui %hist %history %install_default_config %install_ext %install_profiles %killbgscripts %ldir %less %load %load_ext %loadpy %logoff %logon %logstart %logstate %logstop %ls %lsmagic %macro %magic %matplotlib %mkdir %more %notebook %page %pastebin %pdb %pdef %pdoc %pfile %pinfo %pinfo2 %popd %pprint %precision %profile %prun %psearch %psource %pushd %pwd %pycat %pylab %qtconsole %quickref %recall %rehashx %reload_ext %ren %rep %rerun %reset %reset_selective %rmdir %run %save %sc %set_env %store %sx %system %tb %time %timeit %unalias %unload_ext %who %who_ls %whos %xdel %xmode
|
||||
|
||||
Available cell magics:
|
||||
%%! %%HTML %%SVG %%bash %%capture %%cmd %%debug %%file %%html %%javascript %%latex %%perl %%prun %%pypy %%python %%python2 %%python3 %%ruby %%script %%sh %%svg %%sx %%system %%time %%timeit %%writefile
|
||||
|
||||
Automagic is ON, % prefix IS NOT needed for line magics.
|
||||
```
|
||||
|
||||
`line magic` 以一个百分号开头,作用与一行;
|
||||
|
||||
`cell magic` 以两个百分号开头,作用于整个cell。
|
||||
|
||||
最后一行`Automagic is ON, % prefix IS NOT needed for line magics.`说明在此时即使不加上`%`也可以使用这些命令。
|
||||
|
||||
使用 `whos` 查看当前的变量空间:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
%whos
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Variable Type Data/Info
|
||||
----------------------------
|
||||
a int 1
|
||||
b list n=3
|
||||
|
||||
```
|
||||
|
||||
使用 `reset` 重置当前变量空间:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
%reset -f
|
||||
|
||||
```
|
||||
|
||||
再查看当前变量空间:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
%whos
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Interactive namespace is empty.
|
||||
|
||||
```
|
||||
|
||||
使用 `pwd` 查看当前工作文件夹:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
%pwd
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
u'C:\\Users\\lijin\\Documents\\Git\\python-tutorial\\01\. python tools'
|
||||
```
|
||||
|
||||
使用 `mkdir` 产生新文件夹:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
%mkdir demo_test
|
||||
|
||||
```
|
||||
|
||||
使用 `cd` 改变工作文件夹:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
%cd demo_test/
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
C:\Users\lijin\Documents\Git\python-tutorial\01\. python tools\demo_test
|
||||
|
||||
```
|
||||
|
||||
使用 `writefile` 将cell中的内容写入文件:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
%%writefile hello_world.py
|
||||
print "hello world"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing hello_world.py
|
||||
|
||||
```
|
||||
|
||||
使用 `ls` 查看当前工作文件夹的文件:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
%ls
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
驱动器 C 中的卷是 System
|
||||
卷的序列号是 DC4B-D785
|
||||
|
||||
C:\Users\lijin\Documents\Git\python-tutorial\01\. python tools\demo_test 的目录
|
||||
|
||||
2015/09/18 11:32 <DIR> .
|
||||
2015/09/18 11:32 <DIR> ..
|
||||
2015/09/18 11:32 19 hello_world.py
|
||||
1 个文件 19 字节
|
||||
2 个目录 121,763,831,808 可用字节
|
||||
|
||||
```
|
||||
|
||||
使用 `run` 命令来运行这个代码:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
%run hello_world.py
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
删除这个文件:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('hello_world.py')
|
||||
|
||||
```
|
||||
|
||||
查看当前文件夹,`hello_world.py` 已被删除:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
%ls
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
驱动器 C 中的卷是 System
|
||||
卷的序列号是 DC4B-D785
|
||||
|
||||
C:\Users\lijin\Documents\Git\python-tutorial\01\. python tools\demo_test 的目录
|
||||
|
||||
2015/09/18 11:32 <DIR> .
|
||||
2015/09/18 11:32 <DIR> ..
|
||||
0 个文件 0 字节
|
||||
2 个目录 121,763,831,808 可用字节
|
||||
|
||||
```
|
||||
|
||||
返回上一层文件夹:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
%cd ..
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
C:\Users\lijin\Documents\Git\python-tutorial\01\. python tools
|
||||
|
||||
```
|
||||
|
||||
使用 `rmdir` 删除文件夹:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
%rmdir demo_test
|
||||
|
||||
```
|
||||
|
||||
使用 `hist` 查看历史命令:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
%hist
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
print "hello, world"
|
||||
a = 1
|
||||
a
|
||||
b = [1, 2, 3]
|
||||
%lsmagic
|
||||
%whos
|
||||
%reset -f
|
||||
%whos
|
||||
%pwd
|
||||
%mkdir demo_test
|
||||
%cd demo_test/
|
||||
%%writefile hello_world.py
|
||||
print "hello world"
|
||||
%ls
|
||||
%run hello_world.py
|
||||
import os
|
||||
os.remove('hello_world.py')
|
||||
%ls
|
||||
%cd ..
|
||||
%rmdir demo_test
|
||||
%hist
|
||||
|
||||
```
|
||||
|
||||
## ipython 使用
|
||||
|
||||
使用 `?` 查看函数的帮助:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
sum?
|
||||
|
||||
```
|
||||
|
||||
使用 `??` 查看函数帮助和函数源代码(如果是用**python**实现的):
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
# 导入numpy和matplotlib两个包
|
||||
%pylab
|
||||
# 查看其中sort函数的帮助
|
||||
sort??
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Using matplotlib backend: Qt4Agg
|
||||
Populating the interactive namespace from numpy and matplotlib
|
||||
|
||||
```
|
||||
|
||||
**ipython** 支持使用 `<tab>` 键自动补全命令。
|
||||
|
||||
使用 `_` 使用上个cell的输出结果:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
a = 12
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
12
|
||||
```
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
_ + 13
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
25
|
||||
```
|
||||
|
||||
可以使用 `!` 来执行一些系统命令。
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
!ping baidu.com
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
正在 Ping baidu.com [180.149.132.47] 具有 32 字节的数据:
|
||||
来自 180.149.132.47 的回复: 字节=32 时间=69ms TTL=49
|
||||
来自 180.149.132.47 的回复: 字节=32 时间=64ms TTL=49
|
||||
来自 180.149.132.47 的回复: 字节=32 时间=61ms TTL=49
|
||||
来自 180.149.132.47 的回复: 字节=32 时间=63ms TTL=49
|
||||
|
||||
180.149.132.47 的 Ping 统计信息:
|
||||
数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),
|
||||
往返行程的估计时间(以毫秒为单位):
|
||||
最短 = 61ms,最长 = 69ms,平均 = 64ms
|
||||
|
||||
```
|
||||
|
||||
当输入出现错误时,**ipython**会指出出错的位置和原因:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
1 + "hello"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-25-d37bedb9732a> in <module>()
|
||||
----> 1 1 + "hello"
|
||||
|
||||
TypeError: unsupported operand type(s) for +: 'int' and 'str'
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
# Ipython notebook
|
||||
|
||||
在命令行下输入命令:
|
||||
|
||||
```py
|
||||
ipython notebook
|
||||
```
|
||||
|
||||
会打开一个notebook本地服务器,一般地址是 [http://localhost:8888](http://localhost:8888)
|
||||
|
||||
**`ipython notebook`** 支持两种模式的cell:
|
||||
|
||||
* Markdown
|
||||
* Code
|
||||
|
||||
这里不做过多介绍。
|
||||
|
|
@ -0,0 +1,256 @@
|
|||
# 使用 Anaconda
|
||||
|
||||
[Anaconda](http://www.continuum.io/downloads)是一个很好用的Python IDE,它集成了很多科学计算需要使用的**python**第三方工具包。
|
||||
|
||||
## conda 的使用
|
||||
|
||||
根据自己的操作系统安装好[Anaconda](http://www.continuum.io/downloads)后,在命令行下输入:
|
||||
|
||||
```py
|
||||
conda list
|
||||
```
|
||||
|
||||
可以看已经安装好的**python**第三方工具包,这里我们使用 `magic` 命令 `%%cmd` 在 `ipython cell` 中来执行这个命令:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
!conda list
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
# packages in environment at C:\Anaconda:
|
||||
#
|
||||
_license 1.1 py27_0
|
||||
alabaster 0.7.3 py27_0
|
||||
anaconda 2.3.0 np19py27_0
|
||||
argcomplete 0.8.9 py27_0
|
||||
astropy 1.0.3 np19py27_0
|
||||
babel 1.3 py27_0
|
||||
backports.ssl-match-hostname 3.4.0.2 <pip>
|
||||
basemap 1.0.7 np19py27_0
|
||||
bcolz 0.9.0 np19py27_0
|
||||
beautiful-soup 4.3.2 py27_1
|
||||
beautifulsoup4 4.3.2 <pip>
|
||||
binstar 0.11.0 py27_0
|
||||
bitarray 0.8.1 py27_1
|
||||
blaze 0.8.0 <pip>
|
||||
blaze-core 0.8.0 np19py27_0
|
||||
blz 0.6.2 np19py27_1
|
||||
bokeh 0.9.0 np19py27_0
|
||||
boto 2.38.0 py27_0
|
||||
bottleneck 1.0.0 np19py27_0
|
||||
cartopy 0.13.0 np19py27_0
|
||||
cdecimal 2.3 py27_1
|
||||
certifi 14.05.14 py27_0
|
||||
cffi 1.1.0 py27_0
|
||||
clyent 0.3.4 py27_0
|
||||
colorama 0.3.3 py27_0
|
||||
conda 3.17.0 py27_0
|
||||
conda-build 1.14.1 py27_0
|
||||
conda-env 2.4.2 py27_0
|
||||
configobj 5.0.6 py27_0
|
||||
cryptography 0.9.1 py27_0
|
||||
cython 0.22.1 py27_0
|
||||
cytoolz 0.7.3 py27_0
|
||||
datashape 0.4.5 np19py27_0
|
||||
decorator 3.4.2 py27_0
|
||||
docutils 0.12 py27_1
|
||||
dynd-python 0.6.5 np19py27_0
|
||||
enum34 1.0.4 py27_0
|
||||
fastcache 1.0.2 py27_0
|
||||
flask 0.10.1 py27_1
|
||||
funcsigs 0.4 py27_0
|
||||
geopy 1.11.0 <pip>
|
||||
geos 3.4.2 3
|
||||
gevent 1.0.1 py27_0
|
||||
gevent-websocket 0.9.3 py27_0
|
||||
greenlet 0.4.7 py27_0
|
||||
grin 1.2.1 py27_2
|
||||
h5py 2.5.0 np19py27_1
|
||||
hdf5 1.8.15.1 2
|
||||
idna 2.0 py27_0
|
||||
ipaddress 1.0.7 py27_0
|
||||
ipython 3.2.0 py27_0
|
||||
ipython-notebook 3.2.0 py27_0
|
||||
ipython-qtconsole 3.2.0 py27_0
|
||||
itsdangerous 0.24 py27_0
|
||||
jdcal 1.0 py27_0
|
||||
jedi 0.8.1 py27_0
|
||||
jinja2 2.7.3 py27_2
|
||||
jsonschema 2.4.0 py27_0
|
||||
launcher 1.0.0 1
|
||||
libpython 1.0 py27_1
|
||||
llvmlite 0.5.0 py27_0
|
||||
lxml 3.4.4 py27_0
|
||||
markupsafe 0.23 py27_0
|
||||
matplotlib 1.4.3 np19py27_1
|
||||
menuinst 1.0.4 py27_0
|
||||
mingw 4.7 1
|
||||
mistune 0.5.1 py27_1
|
||||
mock 1.3.0 py27_0
|
||||
multipledispatch 0.4.7 py27_0
|
||||
networkx 1.9.1 py27_0
|
||||
nltk 3.0.3 np19py27_0
|
||||
node-webkit 0.10.1 0
|
||||
nose 1.3.7 py27_0
|
||||
numba 0.19.1 np19py27_0
|
||||
numexpr 2.4.3 np19py27_0
|
||||
numpy 1.9.2 py27_0
|
||||
odo 0.3.2 np19py27_0
|
||||
openpyxl 1.8.5 py27_0
|
||||
owslib 0.9.0 py27_0
|
||||
pandas 0.16.2 np19py27_0
|
||||
patsy 0.3.0 np19py27_0
|
||||
pbr 1.3.0 py27_0
|
||||
pep8 1.6.2 py27_0
|
||||
pillow 2.9.0 py27_0
|
||||
pip 7.1.2 py27_0
|
||||
ply 3.6 py27_0
|
||||
proj4 4.9.1 py27_1
|
||||
psutil 2.2.1 py27_0
|
||||
py 1.4.27 py27_0
|
||||
pyasn1 0.1.7 py27_0
|
||||
pycosat 0.6.1 py27_0
|
||||
pycparser 2.14 py27_0
|
||||
pycrypto 2.6.1 py27_3
|
||||
pyepsg 0.2.0 py27_0
|
||||
pyflakes 0.9.2 py27_0
|
||||
pygments 2.0.2 py27_0
|
||||
pyopenssl 0.15.1 py27_1
|
||||
pyparsing 2.0.3 py27_0
|
||||
pyqt 4.10.4 py27_1
|
||||
pyreadline 2.0 py27_0
|
||||
pyshp 1.2.1 py27_0
|
||||
pytables 3.2.0 np19py27_0
|
||||
pytest 2.7.1 py27_0
|
||||
python 2.7.10 0
|
||||
python-dateutil 2.4.2 py27_0
|
||||
pytz 2015.4 py27_0
|
||||
pywin32 219 py27_0
|
||||
pyyaml 3.11 py27_2
|
||||
pyzmq 14.7.0 py27_0
|
||||
requests 2.7.0 py27_0
|
||||
rope 0.9.4 py27_1
|
||||
runipy 0.1.3 py27_0
|
||||
scikit-image 0.11.3 np19py27_0
|
||||
scikit-learn 0.16.1 np19py27_0
|
||||
scipy 0.16.0 np19py27_0
|
||||
setuptools 18.1 py27_0
|
||||
shapely 1.5.11 nppy27_0
|
||||
six 1.9.0 py27_0
|
||||
snowballstemmer 1.2.0 py27_0
|
||||
sockjs-tornado 1.0.1 py27_0
|
||||
sphinx 1.3.1 py27_0
|
||||
sphinx-rtd-theme 0.1.7 <pip>
|
||||
sphinx_rtd_theme 0.1.7 py27_0
|
||||
spyder 2.3.5.2 py27_0
|
||||
spyder-app 2.3.5.2 py27_0
|
||||
sqlalchemy 1.0.5 py27_0
|
||||
ssl_match_hostname 3.4.0.2 py27_0
|
||||
statsmodels 0.6.1 np19py27_0
|
||||
sympy 0.7.6 py27_0
|
||||
tables 3.2.0 <pip>
|
||||
theano 0.7.0 <pip>
|
||||
toolz 0.7.2 py27_0
|
||||
tornado 4.2 py27_0
|
||||
ujson 1.33 py27_0
|
||||
unicodecsv 0.9.4 py27_0
|
||||
werkzeug 0.10.4 py27_0
|
||||
wheel 0.24.0 py27_0
|
||||
xlrd 0.9.3 py27_0
|
||||
xlsxwriter 0.7.3 py27_0
|
||||
xlwings 0.3.5 py27_0
|
||||
xlwt 1.0.0 py27_0
|
||||
zlib 1.2.8 0
|
||||
|
||||
```
|
||||
|
||||
第一次安装好 [Anaconda](http://www.continuum.io/downloads) 以后,可以在命令行输入以下命令使 [Anaconda](http://www.continuum.io/downloads) 保持最新:
|
||||
|
||||
```py
|
||||
conda update conda
|
||||
conda update anaconda
|
||||
```
|
||||
|
||||
conda 是一种很强大的工具,具体用法可以参照它的[文档](http://conda.pydata.org/docs/)。
|
||||
|
||||
也可以参考它的 [cheat sheet](http://conda.pydata.org/docs/_downloads/conda-cheatsheet.pdf) 来快速查看它的用法。
|
||||
|
||||
可以使用它来安装,更新,卸载第三方的 **python** 工具包:
|
||||
|
||||
```py
|
||||
conda install <some package>
|
||||
conda update <some package>
|
||||
conda remove <some package>
|
||||
```
|
||||
|
||||
在安装或更新时可以指定安装的版本号,例如需要使用 `numpy 1.8.1`:
|
||||
|
||||
```py
|
||||
conda install numpy=1.8.1
|
||||
conda update numpy=1.8.1
|
||||
```
|
||||
|
||||
查看 `conda` 的信息:
|
||||
|
||||
```py
|
||||
conda info
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
!conda info
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Current conda install:
|
||||
|
||||
platform : win-64
|
||||
conda version : 3.17.0
|
||||
conda-build version : 1.14.1
|
||||
python version : 2.7.10.final.0
|
||||
requests version : 2.7.0
|
||||
root environment : C:\Anaconda (writable)
|
||||
default environment : C:\Anaconda
|
||||
envs directories : C:\Anaconda\envs
|
||||
package cache : C:\Anaconda\pkgs
|
||||
channel URLs : https://repo.continuum.io/pkgs/free/win-64/
|
||||
https://repo.continuum.io/pkgs/free/noarch/
|
||||
https://repo.continuum.io/pkgs/pro/win-64/
|
||||
https://repo.continuum.io/pkgs/pro/noarch/
|
||||
config file : None
|
||||
is foreign system : False
|
||||
|
||||
```
|
||||
|
||||
一个很棒的功能是 `conda` 可以产生一个自定义的环境,假设在安装的是 **Python 2.7** 的情况下,想使用 **Python 3.4**,只需要在命令行下使用 `conda` 产生一个新的环境:
|
||||
|
||||
```py
|
||||
conda create -n py34 python=3.4
|
||||
```
|
||||
|
||||
这里这个环境被命名为 `py34` ,可以根据喜好将 `py34` 改成其他的名字。
|
||||
|
||||
使用这个环境时,只需要命令行下输入:
|
||||
|
||||
```py
|
||||
activate py34 #(windows)
|
||||
source activate py34 #(linux, mac)
|
||||
|
||||
```
|
||||
|
||||
此时,我们的 **Python** 版本便是 **`python 3.4`**了。
|
||||
|
||||
## spyder 编辑器
|
||||
|
||||
`Anaconda` 默认使用的编辑器是 `spyder`,可以在命令行下输入:
|
||||
|
||||
```py
|
||||
spyder
|
||||
```
|
||||
|
||||
来进入这个编辑器,具体使用方法不做介绍。
|
||||
|
|
@ -0,0 +1 @@
|
|||
# 02\. Python 基础
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,23 @@
|
|||
# Python 数据类型
|
||||
|
||||
## 常用数据类型 Common Data Types
|
||||
|
||||
| 类型 | 例子 |
|
||||
| --- | --- |
|
||||
| 整数 | `-100` |
|
||||
| 浮点数 | `3.1416` |
|
||||
| 字符串 | `'hello'` |
|
||||
| 列表 | `[1, 1.2, 'hello']` |
|
||||
| 字典 | `{'dogs': 5, 'pigs': 3}` |
|
||||
| Numpy数组 | `array([1, 2, 3])` |
|
||||
|
||||
## 其他类型 Others
|
||||
|
||||
| 类型 | 例子 |
|
||||
| --- | --- |
|
||||
| 长整型 | `1000000000000L` |
|
||||
| 布尔型 | `True, False` |
|
||||
| 元组 | `('ring', 1000)` |
|
||||
| 集合 | `{1, 2, 3}` |
|
||||
| Pandas类型 | `DataFrame, Series` |
|
||||
| 自定义 | `Object Oriented Classes` |
|
||||
|
|
@ -0,0 +1,810 @@
|
|||
# 数字
|
||||
|
||||
## 整型 Integers
|
||||
|
||||
整型运算,加减乘:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
2 + 2
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
4
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
3 - 4
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
-1
|
||||
```
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
4 * 5
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
20
|
||||
```
|
||||
|
||||
在**Python 2.7**中,整型的运算结果只能返回整型,**除法**的结果也不例外。
|
||||
|
||||
例如`12 / 5`返回的结果并不是2.4,而是2:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
12 / 5
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
2
|
||||
```
|
||||
|
||||
幂指数:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
2 ** 5
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
32
|
||||
```
|
||||
|
||||
取余:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
32 % 5
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
2
|
||||
```
|
||||
|
||||
赋值给变量:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = 1
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
使用`type()`函数来查看变量类型:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
int
|
||||
```
|
||||
|
||||
整型数字的最大最小值:
|
||||
|
||||
在 32 位系统中,一个整型 4 个字节,最小值 `-2,147,483,648`,最大值 `2,147,483,647`。
|
||||
|
||||
在 64 位系统中,一个整型 8 个字节,最小值 `-9,223,372,036,854,775,808`,最大值 `9,223,372,036,854,775,807`。
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
import sys
|
||||
sys.maxint
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
2147483647
|
||||
```
|
||||
|
||||
## 长整型 Long Integers
|
||||
|
||||
当整型超出范围时,**Python**会自动将整型转化为长整型,不过长整型计算速度会比整型慢。
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a = sys.maxint + 1
|
||||
print type(a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<type 'long'>
|
||||
|
||||
```
|
||||
|
||||
长整型的一个标志是后面以字母L结尾:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
2147483648L
|
||||
```
|
||||
|
||||
可以在赋值时强制让类型为长整型:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
b = 1234L
|
||||
type(b)
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
long
|
||||
```
|
||||
|
||||
长整型可以与整型在一起进行计算,返回的类型还是长整型:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a - 4
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
2147483644L
|
||||
```
|
||||
|
||||
## 浮点数 Floating Point Numbers
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a = 1.4
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
float
|
||||
```
|
||||
|
||||
在之前的除法例子`12 / 5`中,假如想要使返回的结果为2.4,可以将它们写成浮点数的形式:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
12.0 / 5.0
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
2.4
|
||||
```
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
12 / 5.0
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
2.4
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
12.0 / 5
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
2.4
|
||||
```
|
||||
|
||||
上面的例子说明,浮点数与整数进行运算时,返回的仍然是浮点数:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
5 + 2.4
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
7.4
|
||||
```
|
||||
|
||||
浮点数也可以进行与整数相似的运算,甚至可以取余:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
3.4 - 3.2
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
0.19999999999999973
|
||||
```
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
12.3 + 32.4
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
44.7
|
||||
```
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
2.5 ** 2
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
6.25
|
||||
```
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
3.4 % 2.1
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
1.2999999999999998
|
||||
```
|
||||
|
||||
**Python**的浮点数标准与**C**,**Java**一致,都是[IEEE 754 floating point standard](http://en.wikipedia.org/wiki/IEEE_floating_point)。
|
||||
|
||||
注意看 `3.4 - 3.2` 的结果并不是我们预期的`0.2`,这是因为浮点数本身储存方式引起的,浮点数本身会存在一点误差。
|
||||
|
||||
事实上,**Python** 中储存的值为'0.199999999999999733546474089962430298328399658203125',因为这是最接近0.2的浮点数。|
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
'{:.52}'.format(3.4 - 3.2)
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
'0.199999999999999733546474089962430298328399658203125'
|
||||
```
|
||||
|
||||
当我们使用`print`显示时,**Python**会自动校正这个结果
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
print 3.4 - 3.2
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
0.2
|
||||
|
||||
```
|
||||
|
||||
可以用`sys.float_info`来查看浮点数的信息:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
import sys
|
||||
sys.float_info
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
sys.float_info(max=1.7976931348623157e+308, max_exp=1024, max_10_exp=308, min=2.2250738585072014e-308, min_exp=-1021, min_10_exp=-307, dig=15, mant_dig=53, epsilon=2.220446049250313e-16, radix=2, rounds=1)
|
||||
```
|
||||
|
||||
例如浮点数能表示的最大值:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
sys.float_info.max
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
1.7976931348623157e+308
|
||||
```
|
||||
|
||||
浮点数能表示的最接近0的值:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
sys.float_info.min
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
2.2250738585072014e-308
|
||||
```
|
||||
|
||||
浮点数的精度:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
sys.float_info.epsilon
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
2.220446049250313e-16
|
||||
```
|
||||
|
||||
## 复数 Complex Numbers
|
||||
|
||||
**Python** 使用 `j` 来表示复数的虚部:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
a = 1 + 2j
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
complex
|
||||
```
|
||||
|
||||
可以查看它的实部,虚部以及共轭:
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
a.real
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
1.0
|
||||
```
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
a.imag
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
2.0
|
||||
```
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
a.conjugate()
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
(1-2j)
|
||||
```
|
||||
|
||||
## 交互计算
|
||||
|
||||
可以将复杂的表达式放在一起计算:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
1 + 2 - (3 * 4 / 6) ** 5 + 7 % 5
|
||||
|
||||
```
|
||||
|
||||
Out[33]:
|
||||
|
||||
```py
|
||||
-27
|
||||
```
|
||||
|
||||
在**Python**中运算是有优先级的,优先级即算术的先后顺序,比如“先乘除后加减”和“先算括号里面的”都是两种优先级的规则,优先级从高到低排列如下:
|
||||
|
||||
* `( )` 括号
|
||||
* `**` 幂指数运算
|
||||
* `* / // %` 乘,除,整数除法,取余运算
|
||||
* '+ -' 加减
|
||||
|
||||
整数除法,返回的是比结果小的最大整数值:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
12.3 // 5.2
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
2.0
|
||||
```
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
12.3 // -4
|
||||
|
||||
```
|
||||
|
||||
Out[35]:
|
||||
|
||||
```py
|
||||
-4.0
|
||||
```
|
||||
|
||||
## 简单的数学函数
|
||||
|
||||
绝对值:
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
abs(-12.4)
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
12.4
|
||||
```
|
||||
|
||||
取整:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
round(21.6)
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
22.0
|
||||
```
|
||||
|
||||
最大最小值:
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
print min(2, 3, 4, 5)
|
||||
print max(2, 4, 3)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2
|
||||
4
|
||||
|
||||
```
|
||||
|
||||
## 变量名覆盖
|
||||
|
||||
不要用内置的函数来命名变量,否则会出现意想不到的结果:
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
type(max)
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
builtin_function_or_method
|
||||
```
|
||||
|
||||
不要这样做!!!
|
||||
|
||||
In [40]:
|
||||
|
||||
```py
|
||||
max = 1
|
||||
type(max)
|
||||
|
||||
```
|
||||
|
||||
Out[40]:
|
||||
|
||||
```py
|
||||
int
|
||||
```
|
||||
|
||||
In [41]:
|
||||
|
||||
```py
|
||||
max(4, 5)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-41-c60446be959c> in <module>()
|
||||
----> 1 max(4, 5)
|
||||
|
||||
TypeError: 'int' object is not callable
|
||||
```
|
||||
|
||||
## 类型转换
|
||||
|
||||
浮点数转整型,只保留整数部分:
|
||||
|
||||
In [42]:
|
||||
|
||||
```py
|
||||
print int(12.324)
|
||||
print int(-3.32)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
12
|
||||
-3
|
||||
|
||||
```
|
||||
|
||||
整型转浮点型:
|
||||
|
||||
In [43]:
|
||||
|
||||
```py
|
||||
print float(1.2)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1.2
|
||||
|
||||
```
|
||||
|
||||
## 其他表示
|
||||
|
||||
除了10进制外,整数还有其他类型的表示方法。
|
||||
|
||||
科学计数法:
|
||||
|
||||
In [44]:
|
||||
|
||||
```py
|
||||
1e-6
|
||||
|
||||
```
|
||||
|
||||
Out[44]:
|
||||
|
||||
```py
|
||||
1e-06
|
||||
```
|
||||
|
||||
16进制,前面加`0x`修饰,后面使用数字0-9A-F:
|
||||
|
||||
In [45]:
|
||||
|
||||
```py
|
||||
0xFF
|
||||
|
||||
```
|
||||
|
||||
Out[45]:
|
||||
|
||||
```py
|
||||
255
|
||||
```
|
||||
|
||||
8进制,前面加`0`或者`0o`修饰,后面使用数字0-7:
|
||||
|
||||
In [46]:
|
||||
|
||||
```py
|
||||
067
|
||||
|
||||
```
|
||||
|
||||
Out[46]:
|
||||
|
||||
```py
|
||||
55
|
||||
```
|
||||
|
||||
2进制,前面加`0b`修饰,后面使用数字0或1:
|
||||
|
||||
In [47]:
|
||||
|
||||
```py
|
||||
0b101010
|
||||
|
||||
```
|
||||
|
||||
Out[47]:
|
||||
|
||||
```py
|
||||
42
|
||||
```
|
||||
|
||||
## 原地计算 In-place
|
||||
|
||||
**Python**可以使用下面的形式进行原地计算:
|
||||
|
||||
In [48]:
|
||||
|
||||
```py
|
||||
b = 2.5
|
||||
b += 2
|
||||
print b
|
||||
b *= 2
|
||||
print b
|
||||
b -= 3
|
||||
print b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4.5
|
||||
9.0
|
||||
6.0
|
||||
|
||||
```
|
||||
|
||||
## 布尔型 Boolean Data Type
|
||||
|
||||
布尔型可以看成特殊的二值变量,其取值为`True`和`False`:
|
||||
|
||||
In [49]:
|
||||
|
||||
```py
|
||||
q = True
|
||||
type(q)
|
||||
|
||||
```
|
||||
|
||||
Out[49]:
|
||||
|
||||
```py
|
||||
bool
|
||||
```
|
||||
|
||||
可以用表达式构建布尔型变量:
|
||||
|
||||
In [50]:
|
||||
|
||||
```py
|
||||
q = 1 > 2
|
||||
print q
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
常用的比较符号包括:
|
||||
|
||||
```py
|
||||
<, >, <=, >=, ==, !=
|
||||
```
|
||||
|
||||
**Python**支持链式比较:
|
||||
|
||||
In [51]:
|
||||
|
||||
```py
|
||||
x = 2
|
||||
1 < x <= 3
|
||||
|
||||
```
|
||||
|
||||
Out[51]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [ ]:
|
||||
|
|
@ -0,0 +1,709 @@
|
|||
# 字符串
|
||||
|
||||
## 生成字符串
|
||||
|
||||
**Python**中可以使用一对单引号''或者双引号""生成字符串。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
s = "hello, world"
|
||||
print s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello, world
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
s = 'hello world'
|
||||
print s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
## 简单操作
|
||||
|
||||
加法:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
s = 'hello ' + 'world'
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
字符串与数字相乘:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
"echo" * 3
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
'echoechoecho'
|
||||
```
|
||||
|
||||
字符串长度:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
len(s)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
11
|
||||
```
|
||||
|
||||
## 字符串方法
|
||||
|
||||
**Python**是一种面向对象的语言,面向对象的语言中一个必不可少的元素就是方法,而字符串是对象的一种,所以有很多可用的方法。
|
||||
|
||||
跟很多语言一样,**Python**使用以下形式来调用方法:
|
||||
|
||||
```py
|
||||
对象.方法(参数)
|
||||
```
|
||||
|
||||
### 分割
|
||||
|
||||
s.split()将s按照空格(包括多个空格,制表符`\t`,换行符`\n`等)分割,并返回所有分割得到的字符串。
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
line = "1 2 3 4 5"
|
||||
numbers = line.split()
|
||||
print numbers
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['1', '2', '3', '4', '5']
|
||||
|
||||
```
|
||||
|
||||
s.split(sep)以给定的sep为分隔符对s进行分割。
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
line = "1,2,3,4,5"
|
||||
numbers = line.split(',')
|
||||
print numbers
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['1', '2', '3', '4', '5']
|
||||
|
||||
```
|
||||
|
||||
### 连接
|
||||
|
||||
与分割相反,s.join(str_sequence)的作用是以s为连接符将字符串序列str_sequence中的元素连接起来,并返回连接后得到的新字符串:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
s = ' '
|
||||
s.join(numbers)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
'1 2 3 4 5'
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
s = ','
|
||||
s.join(numbers)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
'1,2,3,4,5'
|
||||
```
|
||||
|
||||
### 替换
|
||||
|
||||
s.replace(part1, part2)将字符串s中指定的部分part1替换成想要的部分part2,并返回新的字符串。
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
s = "hello world"
|
||||
s.replace('world', 'python')
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
'hello python'
|
||||
```
|
||||
|
||||
此时,s的值并没有变化,替换方法只是生成了一个新的字符串。
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
### 大小写转换
|
||||
|
||||
s.upper()方法返回一个将s中的字母全部大写的新字符串。
|
||||
|
||||
s.lower()方法返回一个将s中的字母全部小写的新字符串。
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
"hello world".upper()
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
'HELLO WORLD'
|
||||
```
|
||||
|
||||
这两种方法也不会改变原来s的值:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
s = "HELLO WORLD"
|
||||
print s.lower()
|
||||
print s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world
|
||||
HELLO WORLD
|
||||
|
||||
```
|
||||
|
||||
### 去除多余空格
|
||||
|
||||
s.strip()返回一个将s两端的多余空格除去的新字符串。
|
||||
|
||||
s.lstrip()返回一个将s开头的多余空格除去的新字符串。
|
||||
|
||||
s.rstrip()返回一个将s结尾的多余空格除去的新字符串。
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
s = " hello world "
|
||||
s.strip()
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
s的值依然不会变化:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
' hello world '
|
||||
```
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
s.lstrip()
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
'hello world '
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
s.rstrip()
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
' hello world'
|
||||
```
|
||||
|
||||
## 更多方法
|
||||
|
||||
可以使用dir函数查看所有可以使用的方法:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
dir(s)
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
['__add__',
|
||||
'__class__',
|
||||
'__contains__',
|
||||
'__delattr__',
|
||||
'__doc__',
|
||||
'__eq__',
|
||||
'__format__',
|
||||
'__ge__',
|
||||
'__getattribute__',
|
||||
'__getitem__',
|
||||
'__getnewargs__',
|
||||
'__getslice__',
|
||||
'__gt__',
|
||||
'__hash__',
|
||||
'__init__',
|
||||
'__le__',
|
||||
'__len__',
|
||||
'__lt__',
|
||||
'__mod__',
|
||||
'__mul__',
|
||||
'__ne__',
|
||||
'__new__',
|
||||
'__reduce__',
|
||||
'__reduce_ex__',
|
||||
'__repr__',
|
||||
'__rmod__',
|
||||
'__rmul__',
|
||||
'__setattr__',
|
||||
'__sizeof__',
|
||||
'__str__',
|
||||
'__subclasshook__',
|
||||
'_formatter_field_name_split',
|
||||
'_formatter_parser',
|
||||
'capitalize',
|
||||
'center',
|
||||
'count',
|
||||
'decode',
|
||||
'encode',
|
||||
'endswith',
|
||||
'expandtabs',
|
||||
'find',
|
||||
'format',
|
||||
'index',
|
||||
'isalnum',
|
||||
'isalpha',
|
||||
'isdigit',
|
||||
'islower',
|
||||
'isspace',
|
||||
'istitle',
|
||||
'isupper',
|
||||
'join',
|
||||
'ljust',
|
||||
'lower',
|
||||
'lstrip',
|
||||
'partition',
|
||||
'replace',
|
||||
'rfind',
|
||||
'rindex',
|
||||
'rjust',
|
||||
'rpartition',
|
||||
'rsplit',
|
||||
'rstrip',
|
||||
'split',
|
||||
'splitlines',
|
||||
'startswith',
|
||||
'strip',
|
||||
'swapcase',
|
||||
'title',
|
||||
'translate',
|
||||
'upper',
|
||||
'zfill']
|
||||
```
|
||||
|
||||
## 多行字符串
|
||||
|
||||
Python 用一对 `"""` 或者 `'''` 来生成多行字符串:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a = """hello world.
|
||||
it is a nice day."""
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world.
|
||||
it is a nice day.
|
||||
|
||||
```
|
||||
|
||||
在储存时,我们在两行字符间加上一个换行符 `'\n'`
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
'hello world.\nit is a nice day.'
|
||||
```
|
||||
|
||||
## 使用 `()` 或者 `\` 来换行
|
||||
|
||||
当代码太长或者为了美观起见时,我们可以使用两种方法来将一行代码转为多行代码:
|
||||
|
||||
* ()
|
||||
* \
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
a = ("hello, world. "
|
||||
"it's a nice day. "
|
||||
"my name is xxx")
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
"hello, world. it's a nice day. my name is xxx"
|
||||
```
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
a = "hello, world. " \
|
||||
"it's a nice day. " \
|
||||
"my name is xxx"
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
"hello, world. it's a nice day. my name is xxx"
|
||||
```
|
||||
|
||||
## 强制转换为字符串
|
||||
|
||||
* `str(ob)`强制将`ob`转化成字符串。
|
||||
* `repr(ob)`也是强制将`ob`转化成字符串。
|
||||
|
||||
不同点如下:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
str(1.1 + 2.2)
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
'3.3'
|
||||
```
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
repr(1.1 + 2.2)
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
'3.3000000000000003'
|
||||
```
|
||||
|
||||
## 整数与不同进制的字符串的转化
|
||||
|
||||
可以将整数按照不同进制转化为不同类型的字符串。
|
||||
|
||||
十六进制:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
hex(255)
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
'0xff'
|
||||
```
|
||||
|
||||
八进制:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
oct(255)
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
'0377'
|
||||
```
|
||||
|
||||
二进制:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
bin(255)
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
'0b11111111'
|
||||
```
|
||||
|
||||
可以使用 `int` 将字符串转为整数:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
int('23')
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
23
|
||||
```
|
||||
|
||||
还可以指定按照多少进制来进行转换,最后返回十进制表达的整数:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
int('FF', 16)
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
255
|
||||
```
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
int('377', 8)
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
255
|
||||
```
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
int('11111111', 2)
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
255
|
||||
```
|
||||
|
||||
`float` 可以将字符串转换为浮点数:
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
float('3.5')
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
3.5
|
||||
```
|
||||
|
||||
## 格式化字符串
|
||||
|
||||
**Python**用字符串的`format()`方法来格式化字符串。
|
||||
|
||||
具体用法如下,字符串中花括号 `{}` 的部分会被format传入的参数替代,传入的值可以是字符串,也可以是数字或者别的对象。
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
'{} {} {}'.format('a', 'b', 'c')
|
||||
|
||||
```
|
||||
|
||||
Out[33]:
|
||||
|
||||
```py
|
||||
'a b c'
|
||||
```
|
||||
|
||||
可以用数字指定传入参数的相对位置:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
'{2} {1} {0}'.format('a', 'b', 'c')
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
'c b a'
|
||||
```
|
||||
|
||||
还可以指定传入参数的名称:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
'{color} {n} {x}'.format(n=10, x=1.5, color='blue')
|
||||
|
||||
```
|
||||
|
||||
Out[35]:
|
||||
|
||||
```py
|
||||
'blue 10 1.5'
|
||||
```
|
||||
|
||||
可以在一起混用:
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
'{color} {0} {x} {1}'.format(10, 'foo', x = 1.5, color='blue')
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
'blue 10 1.5 foo'
|
||||
```
|
||||
|
||||
可以用`{<field name>:<format>}`指定格式:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
from math import pi
|
||||
|
||||
'{0:10} {1:10d} {2:10.2f}'.format('foo', 5, 2 * pi)
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
'foo 5 6.28'
|
||||
```
|
||||
|
||||
具体规则与C中相同。
|
||||
|
||||
也可以使用旧式的 `%` 方法进行格式化:
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
s = "some numbers:"
|
||||
x = 1.34
|
||||
y = 2
|
||||
# 用百分号隔开,括号括起来
|
||||
t = "%s %f, %d" % (s, x, y)
|
||||
|
||||
```
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
'some numbers: 1.340000, 2'
|
||||
```
|
||||
|
|
@ -0,0 +1,250 @@
|
|||
# 索引和分片
|
||||
|
||||
## 索引
|
||||
|
||||
对于一个有序序列,可以通过索引的方法来访问对应位置的值。字符串便是一个有序序列的例子,**Python**使用 `[]` 来对有序序列进行索引。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
s = "hello world"
|
||||
s[0]
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
'h'
|
||||
```
|
||||
|
||||
**Python**中索引是从 `0` 开始的,所以索引 `0` 对应与序列的第 `1` 个元素。为了得到第 `5` 个元素,需要使用索引值 `4` 。
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
s[4]
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
'o'
|
||||
```
|
||||
|
||||
除了正向索引,**Python**还引入了负索引值的用法,即从后向前开始计数,例如,索引 `-2` 表示倒数第 `2` 个元素:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
s[-2]
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
'l'
|
||||
```
|
||||
|
||||
单个索引大于等于字符串的长度时,会报错:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
s[11]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
IndexError Traceback (most recent call last)
|
||||
<ipython-input-4-79ffc22473a3> in <module>()
|
||||
----> 1 s[11]
|
||||
|
||||
IndexError: string index out of range
|
||||
```
|
||||
|
||||
## 分片
|
||||
|
||||
分片用来从序列中提取出想要的子序列,其用法为:
|
||||
|
||||
```py
|
||||
var[lower:upper:step]
|
||||
```
|
||||
|
||||
其范围包括 `lower` ,但不包括 `upper` ,即 `[lower, upper)`, `step` 表示取值间隔大小,如果没有默认为`1`。
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
s[1:3]
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
'el'
|
||||
```
|
||||
|
||||
分片中包含的元素的个数为 `3-1=2` 。
|
||||
|
||||
也可以使用负索引来指定分片的范围:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
s[1:-2]
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
'ello wor'
|
||||
```
|
||||
|
||||
包括索引 `1` 但是不包括索引 `-2` 。
|
||||
|
||||
lower和upper可以省略,省略lower意味着从开头开始分片,省略upper意味着一直分片到结尾。
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
s[:3]
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
'hel'
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
s[-3:]
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
'rld'
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
s[:]
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
每隔两个取一个值:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
s[::2]
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
'hlowrd'
|
||||
```
|
||||
|
||||
当step的值为负时,省略lower意味着从结尾开始分片,省略upper意味着一直分片到开头。
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
s[::-1]
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
'dlrow olleh'
|
||||
```
|
||||
|
||||
当给定的upper超出字符串的长度(注意:因为不包含upper,所以可以等于)时,Python并不会报错,不过只会计算到结尾。
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
s[:100]
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
## 使用“0”作为索引开头的原因
|
||||
|
||||
### 使用`[low, up)`形式的原因
|
||||
|
||||
假设需要表示字符串 `hello` 中的内部子串 `el` :
|
||||
|
||||
| 方式 | `[low, up)` | `(low, up]` | `(lower, upper)` | `[lower, upper]` |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| 表示 | `[1,3)` | `(0,2]` | `(0,3)` | `[1,2]` |
|
||||
| 序列长度 | `up - low` | `up - low` | `up - low - 1` | `up - low + 1` |
|
||||
|
||||
对长度来说,前两种方式比较好,因为不需要烦人的加一减一。
|
||||
|
||||
现在只考虑前两种方法,假设要表示字符串`hello`中的从头开始的子串`hel`:
|
||||
|
||||
| 方式 | `[low, up)` | `(low, up]` |
|
||||
| --- | --- | --- |
|
||||
| 表示 | `[0,3)` | `(-1,2]` |
|
||||
| 序列长度 | `up - low` | `up - low` |
|
||||
|
||||
第二种表示方法从`-1`开始,不是很好,所以选择使用第一种`[low, up)`的形式。
|
||||
|
||||
### 使用0-base的形式
|
||||
|
||||
> Just to beautiful to ignore.
|
||||
> ----Guido van Rossum
|
||||
|
||||
两种简单的情况:
|
||||
|
||||
* 从头开始的n个元素;
|
||||
|
||||
* 使用0-base:`[0, n)`
|
||||
* 使用1-base:`[1, n+1)`
|
||||
* 第`i+1`个元素到第`i+n`个元素。
|
||||
|
||||
* 使用0-base:`[i, n+i)`
|
||||
* 使用1-base:`[i+1, n+i+1)`
|
||||
|
||||
1-base有个`+1`部分,所以不推荐。
|
||||
|
||||
综合这两种原因,**Python**使用0-base的方法来进行索引。
|
||||
|
|
@ -0,0 +1,646 @@
|
|||
# 列表
|
||||
|
||||
在**Python**中,列表是一个有序的序列。
|
||||
|
||||
列表用一对 `[]` 生成,中间的元素用 `,` 隔开,其中的元素不需要是同一类型,同时列表的长度也不固定。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
l = [1, 2.0, 'hello']
|
||||
print l
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2.0, 'hello']
|
||||
|
||||
```
|
||||
|
||||
空列表可以用 `[]` 或者 `list()` 生成:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
empty_list = []
|
||||
empty_list
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
[]
|
||||
```
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
empty_list = list()
|
||||
empty_list
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
[]
|
||||
```
|
||||
|
||||
## 列表操作
|
||||
|
||||
与字符串类似,列表也支持以下的操作:
|
||||
|
||||
### 长度
|
||||
|
||||
用 `len` 查看列表长度:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
len(l)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
3
|
||||
```
|
||||
|
||||
### 加法和乘法
|
||||
|
||||
列表加法,相当于将两个列表按顺序连接:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a = [1, 2, 3]
|
||||
b = [3.2, 'hello']
|
||||
a + b
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
[1, 2, 3, 3.2, 'hello']
|
||||
```
|
||||
|
||||
列表与整数相乘,相当于将列表重复相加:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
l * 2
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
[1, 2.0, 'hello', 1, 2.0, 'hello']
|
||||
```
|
||||
|
||||
### 索引和分片
|
||||
|
||||
列表和字符串一样可以通过索引和分片来查看它的元素。
|
||||
|
||||
索引:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
a[0]
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
10
|
||||
```
|
||||
|
||||
反向索引:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a[-1]
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
14
|
||||
```
|
||||
|
||||
分片:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a[2:-1]
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
[12, 13]
|
||||
```
|
||||
|
||||
与字符串不同的是,列表可以通过索引和分片来修改。
|
||||
|
||||
对于字符串,如果我们通过索引或者分片来修改,**Python**会报错:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
s = "hello world"
|
||||
# 把开头的 h 改成大写
|
||||
s[0] = 'H'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-10-844622ced67a> in <module>()
|
||||
1 s = "hello world"
|
||||
2 # 把开头的 h 改成大写
|
||||
----> 3 s[0] = 'H'
|
||||
|
||||
TypeError: 'str' object does not support item assignment
|
||||
```
|
||||
|
||||
而这种操作对于列表来说是可以的:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
a[0] = 100
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[100, 11, 12, 13, 14]
|
||||
|
||||
```
|
||||
|
||||
这种赋值也适用于分片,例如,将列表的第2,3两个元素换掉:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
a[1:3] = [1, 2]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
[100, 1, 2, 13, 14]
|
||||
```
|
||||
|
||||
事实上,对于连续的分片(即步长为 `1` ),**Python**采用的是整段替换的方法,两者的元素个数并不需要相同,例如,将 `[11,12]` 替换为 `[1,2,3,4]`:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
a[1:3] = [1, 2, 3, 4]
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 1, 2, 3, 4, 13, 14]
|
||||
|
||||
```
|
||||
|
||||
这意味着,可以用这种方法来删除列表中一个连续的分片:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a = [10, 1, 2, 11, 12]
|
||||
print a[1:3]
|
||||
a[1:3] = []
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2]
|
||||
[10, 11, 12]
|
||||
|
||||
```
|
||||
|
||||
对于不连续(间隔step不为1)的片段进行修改时,两者的元素数目必须一致:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
a[::2] = [1, 2, 3]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
[1, 11, 2, 13, 3]
|
||||
```
|
||||
|
||||
否则会报错:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
a[::2] = []
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ValueError Traceback (most recent call last)
|
||||
<ipython-input-16-7b6c4e43a9fa> in <module>()
|
||||
----> 1 a[::2] = []
|
||||
|
||||
ValueError: attempt to assign sequence of size 0 to extended slice of size 3
|
||||
```
|
||||
|
||||
### 删除元素
|
||||
|
||||
**Python**提供了删除列表中元素的方法 'del'。
|
||||
|
||||
删除列表中的第一个元素:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a = [1002, 'a', 'b', 'c']
|
||||
del a[0]
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['a', 'b', 'c']
|
||||
|
||||
```
|
||||
|
||||
删除第2到最后一个元素:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
a = [1002, 'a', 'b', 'c']
|
||||
del a[1:]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
[1002]
|
||||
```
|
||||
|
||||
删除间隔的元素:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a = ['a', 1, 'b', 2, 'c']
|
||||
del a[::2]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
[1, 2]
|
||||
```
|
||||
|
||||
### 测试从属关系
|
||||
|
||||
用 `in` 来看某个元素是否在某个序列(不仅仅是列表)中,用not in来判断是否不在某个序列中。
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
print 10 in a
|
||||
print 10 not in a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
True
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
也可以作用于字符串:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
s = 'hello world'
|
||||
print 'he' in s
|
||||
print 'world' not in s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
True
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
列表中可以包含各种对象,甚至可以包含列表:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
a = [10, 'eleven', [12, 13]]
|
||||
a[2]
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
[12, 13]
|
||||
```
|
||||
|
||||
a[2]是列表,可以对它再进行索引:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
a[2][1]
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
13
|
||||
```
|
||||
|
||||
## 列表方法
|
||||
|
||||
### 不改变列表的方法
|
||||
|
||||
#### 列表中某个元素个数count
|
||||
|
||||
`l.count(ob)` 返回列表中元素 `ob` 出现的次数。
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
a = [11, 12, 13, 12, 11]
|
||||
a.count(11)
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
2
|
||||
```
|
||||
|
||||
#### 列表中某个元素位置index
|
||||
|
||||
`l.index(ob)` 返回列表中元素 `ob` 第一次出现的索引位置,如果 `ob` 不在 `l` 中会报错。
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
a.index(12)
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
不存在的元素会报错:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a.index(1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ValueError Traceback (most recent call last)
|
||||
<ipython-input-26-ed16592c2786> in <module>()
|
||||
----> 1 a.index(1)
|
||||
|
||||
ValueError: 1 is not in list
|
||||
```
|
||||
|
||||
### 改变列表的方法
|
||||
|
||||
#### 向列表添加单个元素
|
||||
|
||||
`l.append(ob)` 将元素 `ob` 添加到列表 `l` 的最后。
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12]
|
||||
a.append(11)
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 11, 12, 11]
|
||||
|
||||
```
|
||||
|
||||
append每次只添加一个元素,并不会因为这个元素是序列而将其展开:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
a.append([11, 12])
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 11, 12, 11, [11, 12]]
|
||||
|
||||
```
|
||||
|
||||
#### 向列表添加序列
|
||||
|
||||
`l.extend(lst)` 将序列 `lst` 的元素依次添加到列表 `l` 的最后,作用相当于 `l += lst`。
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 11]
|
||||
a.extend([1, 2])
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 11, 12, 11, 1, 2]
|
||||
|
||||
```
|
||||
|
||||
#### 插入元素
|
||||
|
||||
`l.insert(idx, ob)` 在索引 `idx` 处插入 `ob` ,之后的元素依次后移。
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 11]
|
||||
# 在索引 3 插入 'a'
|
||||
a.insert(3, 'a')
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 11, 12, 'a', 13, 11]
|
||||
|
||||
```
|
||||
|
||||
#### 移除元素
|
||||
|
||||
`l.remove(ob)` 会将列表中第一个出现的 `ob` 删除,如果 `ob` 不在 `l` 中会报错。
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 11]
|
||||
# 移除了第一个 11
|
||||
a.remove(11)
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 12, 13, 11]
|
||||
|
||||
```
|
||||
|
||||
#### 弹出元素
|
||||
|
||||
`l.pop(idx)` 会将索引 `idx` 处的元素删除,并返回这个元素。
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 11]
|
||||
a.pop(2)
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
12
|
||||
```
|
||||
|
||||
#### 排序
|
||||
|
||||
`l.sort()` 会将列表中的元素按照一定的规则排序:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
a = [10, 1, 11, 13, 11, 2]
|
||||
a.sort()
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2, 10, 11, 11, 13]
|
||||
|
||||
```
|
||||
|
||||
如果不想改变原来列表中的值,可以使用 `sorted` 函数:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
a = [10, 1, 11, 13, 11, 2]
|
||||
b = sorted(a)
|
||||
print a
|
||||
print b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10, 1, 11, 13, 11, 2]
|
||||
[1, 2, 10, 11, 11, 13]
|
||||
|
||||
```
|
||||
|
||||
#### 列表反向
|
||||
|
||||
`l.reverse()` 会将列表中的元素从后向前排列。
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
a = [1, 2, 3, 4, 5, 6]
|
||||
a.reverse()
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[6, 5, 4, 3, 2, 1]
|
||||
|
||||
```
|
||||
|
||||
如果不想改变原来列表中的值,可以使用这样的方法:
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
a = [1, 2, 3, 4, 5, 6]
|
||||
b = a[::-1]
|
||||
print a
|
||||
print b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2, 3, 4, 5, 6]
|
||||
[6, 5, 4, 3, 2, 1]
|
||||
|
||||
```
|
||||
|
||||
如果不清楚用法,可以查看帮助:
|
||||
|
||||
In [ ]:
|
||||
|
||||
```py
|
||||
a.sort?
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,182 @@
|
|||
# 可变和不可变类型
|
||||
|
||||
## 列表是可变的(Mutable)
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
a = [1,2,3,4]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
通过索引改变:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a[0] = 100
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
[100, 2, 3, 4]
|
||||
```
|
||||
|
||||
通过方法改变:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.insert(3, 200)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
[100, 2, 3, 200, 4]
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.sort()
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
[2, 3, 4, 100, 200]
|
||||
```
|
||||
|
||||
## 字符串是不可变的(Immutable)
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
s = "hello world"
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
'hello world'
|
||||
```
|
||||
|
||||
通过索引改变会报错:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
s[0] = 'z'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-6-83b06971f05e> in <module>()
|
||||
----> 1 s[0] = 'z'
|
||||
|
||||
TypeError: 'str' object does not support item assignment
|
||||
```
|
||||
|
||||
字符串方法只是返回一个新字符串,并不改变原来的值:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print s.replace('world', 'Mars')
|
||||
print s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello Mars
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
如果想改变字符串的值,可以用重新赋值的方法:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
s = "hello world"
|
||||
s = s.replace('world', 'Mars')
|
||||
print s
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello Mars
|
||||
|
||||
```
|
||||
|
||||
或者用 `bytearray` 代替字符串:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
s = bytearray('abcde')
|
||||
s[1:3] = '12'
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
bytearray(b'a12de')
|
||||
```
|
||||
|
||||
数据类型分类:
|
||||
|
||||
| 可变数据类型 | 不可变数据类型 |
|
||||
| --- | --- |
|
||||
| `list`, `dictionary`, `set`, `numpy array`, `user defined objects` | `integer`, `float`, `long`, `complex`, `string`, `tuple`, `frozenset` |
|
||||
|
||||
## 字符串不可变的原因
|
||||
|
||||
其一,列表可以通过以下的方法改变,而字符串不支持这样的变化。
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a = [1, 2, 3, 4]
|
||||
b = a
|
||||
|
||||
```
|
||||
|
||||
此时, `a` 和 `b` 指向同一块区域,改变 `b` 的值, `a` 也会同时改变:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
b[0] = 100
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
[100, 2, 3, 4]
|
||||
```
|
||||
|
||||
其二,是字符串与整数浮点数一样被认为是基本类型,而基本类型在Python中是不可变的。
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
# 元组
|
||||
|
||||
## 基本操作
|
||||
|
||||
与列表相似,元组`Tuple`也是个有序序列,但是元组是不可变的,用`()`生成。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
t = (10, 11, 12, 13, 14)
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
(10, 11, 12, 13, 14)
|
||||
```
|
||||
|
||||
可以索引,切片:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
t[0]
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
10
|
||||
```
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
t[1:3]
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
(11, 12)
|
||||
```
|
||||
|
||||
但是元组是不可变的:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
# 会报错
|
||||
t[0] = 1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-4-da6c1cabf0b0> in <module>()
|
||||
1 # 会报错
|
||||
----> 2 t[0] = 1
|
||||
|
||||
TypeError: 'tuple' object does not support item assignment
|
||||
```
|
||||
|
||||
## 单个元素的元组生成
|
||||
|
||||
由于`()`在表达式中被应用,只含有单个元素的元组容易和表达式混淆,所以采用下列方式定义只有一个元素的元组:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a = (10,)
|
||||
print a
|
||||
print type(a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(10,)
|
||||
<type 'tuple'>
|
||||
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a = (10)
|
||||
print type(a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<type 'int'>
|
||||
|
||||
```
|
||||
|
||||
将列表转换为元组:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = [10, 11, 12, 13, 14]
|
||||
tuple(a)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
(10, 11, 12, 13, 14)
|
||||
```
|
||||
|
||||
## 元组方法
|
||||
|
||||
由于元组是不可变的,所以只能有一些不可变的方法,例如计算元素个数 `count` 和元素位置 `index` ,用法与列表一样。
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a.count(10)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a.index(12)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
2
|
||||
```
|
||||
|
||||
## 为什么需要元组
|
||||
|
||||
旧式字符串格式化中参数要用元组;
|
||||
|
||||
在字典中当作键值;
|
||||
|
||||
数据库的返回值……
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
# 列表与元组的速度比较
|
||||
|
||||
IPython 中用 `magic` 命令 `%timeit` 来计时。
|
||||
|
||||
## 比较生成速度
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
%timeit [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1000000 loops, best of 3: 456 ns per loop
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
%timeit (1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
10000000 loops, best of 3: 23 ns per loop
|
||||
|
||||
```
|
||||
|
||||
可以看到,元组的生成速度要比列表的生成速度快得多,相差大概一个数量级。
|
||||
|
||||
## 比较遍历速度
|
||||
|
||||
产生内容相同的随机列表和元组:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
from numpy.random import rand
|
||||
values = rand(10000,4)
|
||||
lst = [list(row) for row in values]
|
||||
tup = tuple(tuple(row) for row in values)
|
||||
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
%timeit for row in lst: list(row)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
100 loops, best of 3: 4.12 ms per loop
|
||||
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
%timeit for row in tup: tuple(row)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
100 loops, best of 3: 2.07 ms per loop
|
||||
|
||||
```
|
||||
|
||||
在遍历上,元组和列表的速度表现差不多。
|
||||
|
||||
## 比较遍历和索引速度:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
%timeit for row in lst: a = row[0] + 1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
The slowest run took 12.20 times longer than the fastest. This could mean that an intermediate result is being cached
|
||||
100 loops, best of 3: 3.73 ms per loop
|
||||
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
%timeit for row in tup: a = row[0] + 1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
100 loops, best of 3: 3.82 ms per loop
|
||||
|
||||
```
|
||||
|
||||
元组的生成速度会比列表快很多,迭代速度快一点,索引速度差不多。
|
||||
|
|
@ -0,0 +1,644 @@
|
|||
# 字典
|
||||
|
||||
字典 `dictionary` ,在一些编程语言中也称为 `hash` , `map` ,是一种由键值对组成的数据结构。
|
||||
|
||||
顾名思义,我们把键想象成字典中的单词,值想象成词对应的定义,那么——
|
||||
|
||||
一个词可以对应一个或者多个定义,但是这些定义只能通过这个词来进行查询。
|
||||
|
||||
## 基本操作
|
||||
|
||||
### 空字典
|
||||
|
||||
**Python** 使用 `{}` 或者 `dict()` 来创建一个空的字典:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
a = {}
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
dict
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = dict()
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
dict
|
||||
```
|
||||
|
||||
有了dict之后,可以用索引键值的方法向其中添加元素,也可以通过索引来查看元素的值:
|
||||
|
||||
### 插入键值
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a["one"] = "this is number 1"
|
||||
a["two"] = "this is number 2"
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
{'one': 'this is number 1', 'two': 'this is number 2'}
|
||||
```
|
||||
|
||||
### 查看键值
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a['one']
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
'this is number 1'
|
||||
```
|
||||
|
||||
### 更新键值
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a["one"] = "this is number 1, too"
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
{'one': 'this is number 1, too', 'two': 'this is number 2'}
|
||||
```
|
||||
|
||||
### 初始化字典
|
||||
|
||||
可以看到,Python使用`key: value`这样的结构来表示字典中的元素结构,事实上,可以直接使用这样的结构来初始化一个字典:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
b = {'one': 'this is number 1', 'two': 'this is number 2'}
|
||||
b['one']
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
'this is number 1'
|
||||
```
|
||||
|
||||
### 字典没有顺序
|
||||
|
||||
当我们 `print` 一个字典时,**Python**并不一定按照插入键值的先后顺序进行显示,因为字典中的键本身不一定是有序的。
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
{'two': 'this is number 2', 'one': 'this is number 1, too'}
|
||||
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
print b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
{'two': 'this is number 2', 'one': 'this is number 1'}
|
||||
|
||||
```
|
||||
|
||||
因此,**Python**中不能用支持用数字索引按顺序查看字典中的值,而且数字本身也有可能成为键值,这样会引起混淆:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
# 会报错
|
||||
a[0]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
KeyError Traceback (most recent call last)
|
||||
<ipython-input-9-cc39af2a359c> in <module>()
|
||||
1 # 会报错
|
||||
----> 2 a[0]
|
||||
|
||||
KeyError: 0
|
||||
```
|
||||
|
||||
### 键必须是不可变的类型
|
||||
|
||||
出于hash的目的,Python中要求这些键值对的**键**必须是**不可变**的,而值可以是任意的Python对象。
|
||||
|
||||
一个表示近义词的字典:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
synonyms = {}
|
||||
synonyms['mutable'] = ['changeable', 'variable', 'varying', 'fluctuating',
|
||||
'shifting', 'inconsistent', 'unpredictable', 'inconstant',
|
||||
'fickle', 'uneven', 'unstable', 'protean']
|
||||
synonyms['immutable'] = ['fixed', 'set', 'rigid', 'inflexible',
|
||||
'permanent', 'established', 'carved in stone']
|
||||
synonyms
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
{'immutable': ['fixed',
|
||||
'set',
|
||||
'rigid',
|
||||
'inflexible',
|
||||
'permanent',
|
||||
'established',
|
||||
'carved in stone'],
|
||||
'mutable': ['changeable',
|
||||
'variable',
|
||||
'varying',
|
||||
'fluctuating',
|
||||
'shifting',
|
||||
'inconsistent',
|
||||
'unpredictable',
|
||||
'inconstant',
|
||||
'fickle',
|
||||
'uneven',
|
||||
'unstable',
|
||||
'protean']}
|
||||
```
|
||||
|
||||
另一个例子:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
# 定义四个字典
|
||||
e1 = {'mag': 0.05, 'width': 20}
|
||||
e2 = {'mag': 0.04, 'width': 25}
|
||||
e3 = {'mag': 0.05, 'width': 80}
|
||||
e4 = {'mag': 0.03, 'width': 30}
|
||||
# 以字典作为值传入新的字典
|
||||
events = {500: e1, 760: e2, 3001: e3, 4180: e4}
|
||||
events
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
{500: {'mag': 0.05, 'width': 20},
|
||||
760: {'mag': 0.04, 'width': 25},
|
||||
3001: {'mag': 0.05, 'width': 80},
|
||||
4180: {'mag': 0.03, 'width': 30}}
|
||||
```
|
||||
|
||||
键(或者值)的数据类型可以不同:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
people = [
|
||||
{'first': 'Sam', 'last': 'Malone', 'name': 35},
|
||||
{'first': 'Woody', 'last': 'Boyd', 'name': 21},
|
||||
{'first': 'Norm', 'last': 'Peterson', 'name': 34},
|
||||
{'first': 'Diane', 'last': 'Chambers', 'name': 33}
|
||||
]
|
||||
people
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
[{'first': 'Sam', 'last': 'Malone', 'name': 35},
|
||||
{'first': 'Woody', 'last': 'Boyd', 'name': 21},
|
||||
{'first': 'Norm', 'last': 'Peterson', 'name': 34},
|
||||
{'first': 'Diane', 'last': 'Chambers', 'name': 33}]
|
||||
```
|
||||
|
||||
### 使用 dict 初始化字典
|
||||
|
||||
除了通常的定义方式,还可以通过 `dict()` 转化来生成字典:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
inventory = dict(
|
||||
[('foozelator', 123),
|
||||
('frombicator', 18),
|
||||
('spatzleblock', 34),
|
||||
('snitzelhogen', 23)
|
||||
])
|
||||
inventory
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
{'foozelator': 123, 'frombicator': 18, 'snitzelhogen': 23, 'spatzleblock': 34}
|
||||
```
|
||||
|
||||
利用索引直接更新键值对:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
inventory['frombicator'] += 1
|
||||
inventory
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
{'foozelator': 123, 'frombicator': 19, 'snitzelhogen': 23, 'spatzleblock': 34}
|
||||
```
|
||||
|
||||
## 适合做键的类型
|
||||
|
||||
在不可变类型中,整数和字符串是字典中最常用的类型;而浮点数通常不推荐用来做键,原因如下:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
data = {}
|
||||
data[1.1 + 2.2] = 6.6
|
||||
# 会报错
|
||||
data[3.3]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
KeyError Traceback (most recent call last)
|
||||
<ipython-input-16-a48e87d01daa> in <module>()
|
||||
2 data[1.1 + 2.2] = 6.6
|
||||
3 # 会报错
|
||||
----> 4 data[3.3]
|
||||
|
||||
KeyError: 3.3
|
||||
```
|
||||
|
||||
事实上,观察`data`的值就会发现,这个错误是由浮点数的精度问题所引起的:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
{3.3000000000000003: 6.6}
|
||||
```
|
||||
|
||||
有时候,也可以使用元组作为键值,例如,可以用元组做键来表示从第一个城市飞往第二个城市航班数的多少:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
connections = {}
|
||||
connections[('New York', 'Seattle')] = 100
|
||||
connections[('Austin', 'New York')] = 200
|
||||
connections[('New York', 'Austin')] = 400
|
||||
|
||||
```
|
||||
|
||||
元组是有序的,因此 `('New York', 'Austin')` 和 `('Austin', 'New York')` 是两个不同的键:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
print connections[('Austin', 'New York')]
|
||||
print connections[('New York', 'Austin')]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
200
|
||||
400
|
||||
|
||||
```
|
||||
|
||||
## 字典方法
|
||||
|
||||
### `get` 方法
|
||||
|
||||
之前已经见过,用索引可以找到一个键对应的值,但是当字典中没有这个键的时候,Python会报错,这时候可以使用字典的 `get` 方法来处理这种情况,其用法如下:
|
||||
|
||||
```py
|
||||
`d.get(key, default = None)`
|
||||
```
|
||||
|
||||
返回字典中键 `key` 对应的值,如果没有这个键,返回 `default` 指定的值(默认是 `None` )。
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
a = {}
|
||||
a["one"] = "this is number 1"
|
||||
a["two"] = "this is number 2"
|
||||
|
||||
```
|
||||
|
||||
索引不存在的键值会报错:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
a["three"]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
KeyError Traceback (most recent call last)
|
||||
<ipython-input-22-8a5f2913f00e> in <module>()
|
||||
----> 1 a["three"]
|
||||
|
||||
KeyError: 'three'
|
||||
```
|
||||
|
||||
改用get方法:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
print a.get("three")
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
None
|
||||
|
||||
```
|
||||
|
||||
指定默认值参数:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
a.get("three", "undefined")
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
'undefined'
|
||||
```
|
||||
|
||||
### `pop` 方法删除元素
|
||||
|
||||
`pop` 方法可以用来弹出字典中某个键对应的值,同时也可以指定默认参数:
|
||||
|
||||
```py
|
||||
`d.pop(key, default = None)`
|
||||
```
|
||||
|
||||
删除并返回字典中键 `key` 对应的值,如果没有这个键,返回 `default` 指定的值(默认是 `None` )。
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
{'one': 'this is number 1', 'two': 'this is number 2'}
|
||||
```
|
||||
|
||||
弹出并返回值:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
a.pop("two")
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
'this is number 2'
|
||||
```
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
{'one': 'this is number 1'}
|
||||
```
|
||||
|
||||
弹出不存在的键值:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
a.pop("two", 'not exist')
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
'not exist'
|
||||
```
|
||||
|
||||
与列表一样,`del` 函数可以用来删除字典中特定的键值对,例如:
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
del a["one"]
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
{}
|
||||
```
|
||||
|
||||
### `update`方法更新字典
|
||||
|
||||
之前已经知道,可以通过索引来插入、修改单个键值对,但是如果想对多个键值对进行操作,这种方法就显得比较麻烦,好在有 `update` 方法:
|
||||
|
||||
```py
|
||||
`d.update(newd)`
|
||||
```
|
||||
|
||||
将字典`newd`中的内容更新到`d`中去。
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
person = {}
|
||||
person['first'] = "Jmes"
|
||||
person['last'] = "Maxwell"
|
||||
person['born'] = 1831
|
||||
print person
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
{'born': 1831, 'last': 'Maxwell', 'first': 'Jmes'}
|
||||
|
||||
```
|
||||
|
||||
把'first'改成'James',同时插入'middle'的值'Clerk':
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
person_modifications = {'first': 'James', 'middle': 'Clerk'}
|
||||
person.update(person_modifications)
|
||||
print person
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
{'middle': 'Clerk', 'born': 1831, 'last': 'Maxwell', 'first': 'James'}
|
||||
|
||||
```
|
||||
|
||||
### `in`查询字典中是否有该键
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
barn = {'cows': 1, 'dogs': 5, 'cats': 3}
|
||||
|
||||
```
|
||||
|
||||
`in` 可以用来判断字典中是否有某个特定的键:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
'chickens' in barn
|
||||
|
||||
```
|
||||
|
||||
Out[35]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
'cows' in barn
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
### `keys` 方法,`values` 方法和`items` 方法
|
||||
|
||||
```py
|
||||
`d.keys()`
|
||||
```
|
||||
|
||||
返回一个由所有键组成的列表;
|
||||
|
||||
```py
|
||||
`d.values()`
|
||||
```
|
||||
|
||||
返回一个由所有值组成的列表;
|
||||
|
||||
```py
|
||||
`d.items()`
|
||||
```
|
||||
|
||||
返回一个由所有键值对元组组成的列表;
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
barn.keys()
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
['cows', 'cats', 'dogs']
|
||||
```
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
barn.values()
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
[1, 3, 5]
|
||||
```
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
barn.items()
|
||||
|
||||
```
|
||||
|
||||
Out[38]:
|
||||
|
||||
```py
|
||||
[('cows', 1), ('cats', 3), ('dogs', 5)]
|
||||
```
|
||||
|
|
@ -0,0 +1,600 @@
|
|||
# 集合
|
||||
|
||||
之前看到的列表和字符串都是一种有序序列,而集合 `set` 是一种无序的序列。
|
||||
|
||||
因为集合是无序的,所以当集合中存在两个同样的元素的时候,Python只会保存其中的一个(唯一性);同时为了确保其中不包含同样的元素,集合中放入的元素只能是不可变的对象(确定性)。
|
||||
|
||||
## 集合生成
|
||||
|
||||
可以用`set()`函数来显示的生成空集合:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
a = set()
|
||||
type(a)
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
set
|
||||
```
|
||||
|
||||
也可以使用一个列表来初始化一个集合:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = set([1, 2, 3, 1])
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
{1, 2, 3}
|
||||
```
|
||||
|
||||
集合会自动去除重复元素 `1`。
|
||||
|
||||
可以看到,集合中的元素是用大括号`{}`包含起来的,这意味着可以用`{}`的形式来创建集合:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a = {1, 2, 3, 1}
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
{1, 2, 3}
|
||||
```
|
||||
|
||||
但是创建空集合的时候只能用`set`来创建,因为在Python中`{}`创建的是一个空的字典:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
s = {}
|
||||
type(s)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
dict
|
||||
```
|
||||
|
||||
## 集合操作
|
||||
|
||||
假设有这样两个集合:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a = {1, 2, 3, 4}
|
||||
b = {3, 4, 5, 6}
|
||||
|
||||
```
|
||||
|
||||
### 并
|
||||
|
||||
两个集合的并,返回包含两个集合所有元素的集合(去除重复)。
|
||||
|
||||
可以用方法 `a.union(b)` 或者操作 `a | b` 实现。
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a.union(b)
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
b.union(a)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a | b
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 4, 5, 6}
|
||||
```
|
||||
|
||||
### 交
|
||||
|
||||
两个集合的交,返回包含两个集合共有元素的集合。
|
||||
|
||||
可以用方法 `a.intersection(b)` 或者操作 `a & b` 实现。
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a.intersection(b)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
{3, 4}
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
b.intersection(a)
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
{3, 4}
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a & b
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
{3, 4}
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
print(a & b)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
set([3, 4])
|
||||
|
||||
```
|
||||
|
||||
注意:一般使用print打印set的结果与表示方法并不一致。
|
||||
|
||||
### 差
|
||||
|
||||
`a` 和 `b` 的差集,返回只在 `a` 不在 `b` 的元素组成的集合。
|
||||
|
||||
可以用方法 `a.difference(b)` 或者操作 `a - b` 实现。
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a.difference(b)
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
{1, 2}
|
||||
```
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a - b
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
{1, 2}
|
||||
```
|
||||
|
||||
注意,`a - b` 与 `b - a`并不一样,`b - a` 返回的是返回 b 不在 a 的元素组成的集合:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
b.difference(a)
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
{5, 6}
|
||||
```
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
b - a
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
{5, 6}
|
||||
```
|
||||
|
||||
### 对称差
|
||||
|
||||
`a` 和`b` 的对称差集,返回在 `a` 或在 `b` 中,但是不同时在 `a` 和 `b` 中的元素组成的集合。
|
||||
|
||||
可以用方法 `a.symmetric_difference(b)` 或者操作 `a ^ b` 实现(异或操作符)。
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a.symmetric_difference(b)
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
{1, 2, 5, 6}
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
b.symmetric_difference(a)
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
{1, 2, 5, 6}
|
||||
```
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a ^ b
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
{1, 2, 5, 6}
|
||||
```
|
||||
|
||||
### 包含关系
|
||||
|
||||
假设现在有这样两个集合:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a = {1, 2, 3}
|
||||
b = {1, 2}
|
||||
|
||||
```
|
||||
|
||||
要判断 `b` 是不是 `a` 的子集,可以用 `b.issubset(a)` 方法,或者更简单的用操作 `b <= a` :
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
b.issubset(a)
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
b <= a
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
与之对应,也可以用 `a.issuperset(b)` 或者 `a >= b` 来判断:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
a.issuperset(b)
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
a >= b
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
方法只能用来测试子集,但是操作符可以用来判断真子集:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
a <= a
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
自己不是自己的真子集:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a < a
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
## 集合方法
|
||||
|
||||
### `add` 方法向集合添加单个元素
|
||||
|
||||
跟列表的 `append` 方法类似,用来向集合添加单个元素。
|
||||
|
||||
```py
|
||||
s.add(a)
|
||||
```
|
||||
|
||||
将元素 `a` 加入集合 `s` 中。
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
t = {1, 2, 3}
|
||||
t.add(5)
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 5}
|
||||
```
|
||||
|
||||
如果添加的是已有元素,集合不改变:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
t.add(3)
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 5}
|
||||
```
|
||||
|
||||
### `update` 方法向集合添加多个元素
|
||||
|
||||
跟列表的`extend`方法类似,用来向集合添加多个元素。
|
||||
|
||||
```py
|
||||
s.update(seq)
|
||||
```
|
||||
|
||||
将`seq`中的元素添加到`s`中。
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
t.update([5, 6, 7])
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
{1, 2, 3, 5, 6, 7}
|
||||
```
|
||||
|
||||
### `remove` 方法移除单个元素
|
||||
|
||||
```py
|
||||
s.remove(ob)
|
||||
```
|
||||
|
||||
从集合`s`中移除元素`ob`,如果不存在会报错。
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
t.remove(1)
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
{2, 3, 5, 6, 7}
|
||||
```
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
t.remove(10)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
KeyError Traceback (most recent call last)
|
||||
<ipython-input-31-3bc25c5e1ff4> in <module>()
|
||||
----> 1 t.remove(10)
|
||||
|
||||
KeyError: 10
|
||||
```
|
||||
|
||||
### pop方法弹出元素
|
||||
|
||||
由于集合没有顺序,不能像列表一样按照位置弹出元素,所以`pop` 方法删除并返回集合中任意一个元素,如果集合中没有元素会报错。
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
t.pop()
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
{3, 5, 6, 7}
|
||||
```
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
print t
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
set([3, 5, 6, 7])
|
||||
|
||||
```
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
s = set()
|
||||
# 报错
|
||||
s.pop()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
KeyError Traceback (most recent call last)
|
||||
<ipython-input-34-9f9e06c962e6> in <module>()
|
||||
1 s = set()
|
||||
2 # 报错
|
||||
----> 3 s.pop()
|
||||
|
||||
KeyError: 'pop from an empty set'
|
||||
```
|
||||
|
||||
### discard 方法
|
||||
|
||||
作用与 `remove` 一样,但是当元素在集合中不存在的时候不会报错。
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
t.discard(3)
|
||||
|
||||
```
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
{5, 6, 7}
|
||||
```
|
||||
|
||||
不存在的元素不会报错:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
t.discard(20)
|
||||
|
||||
```
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
t
|
||||
|
||||
```
|
||||
|
||||
Out[38]:
|
||||
|
||||
```py
|
||||
{5, 6, 7}
|
||||
```
|
||||
|
||||
### difference_update方法
|
||||
|
||||
```py
|
||||
a.difference_update(b)
|
||||
```
|
||||
|
||||
从a中去除所有属于b的元素:
|
||||
|
|
@ -0,0 +1,71 @@
|
|||
# 不可变集合
|
||||
|
||||
对应于元组(`tuple`)与列表(`list`)的关系,对于集合(`set`),**Python**提供了一种叫做不可变集合(`frozen set`)的数据结构。
|
||||
|
||||
使用 `frozenset` 来进行创建:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
s = frozenset([1, 2, 3, 'a', 1])
|
||||
s
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
frozenset({1, 2, 3, 'a'})
|
||||
```
|
||||
|
||||
与集合不同的是,不可变集合一旦创建就不可以改变。
|
||||
|
||||
不可变集合的一个主要应用是用来作为字典的键,例如用一个字典来记录两个城市之间的距离:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
flight_distance = {}
|
||||
city_pair = frozenset(['Los Angeles', 'New York'])
|
||||
flight_distance[city_pair] = 2498
|
||||
flight_distance[frozenset(['Austin', 'Los Angeles'])] = 1233
|
||||
flight_distance[frozenset(['Austin', 'New York'])] = 1515
|
||||
flight_distance
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
{frozenset({'Austin', 'New York'}): 1515,
|
||||
frozenset({'Austin', 'Los Angeles'}): 1233,
|
||||
frozenset({'Los Angeles', 'New York'}): 2498}
|
||||
```
|
||||
|
||||
由于集合不分顺序,所以不同顺序不会影响查阅结果:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
flight_distance[frozenset(['New York','Austin'])]
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
1515
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
flight_distance[frozenset(['Austin','New York'])]
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
1515
|
||||
```
|
||||
|
|
@ -0,0 +1,386 @@
|
|||
# Python 赋值机制
|
||||
|
||||
先看一个例子:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
x = [1, 2, 3]
|
||||
y = x
|
||||
x[1] = 100
|
||||
print y
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 100, 3]
|
||||
|
||||
```
|
||||
|
||||
改变变量`x`的值,变量`y`的值也随着改变,这与**Python**内部的赋值机制有关。
|
||||
|
||||
## 简单类型
|
||||
|
||||
先来看这一段代码在**Python**中的执行过程。
|
||||
|
||||
```py
|
||||
x = 500
|
||||
y = x
|
||||
y = 'foo'
|
||||
|
||||
```
|
||||
|
||||
* `x = 500`
|
||||
|
||||
**Python**分配了一个 `PyInt` 大小的内存 `pos1` 用来储存对象 `500` ,然后,Python在命名空间中让变量 `x` 指向了这一块内存,注意,整数是不可变类型,所以这块内存的内容是不可变的。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变) | `x : pos1` |
|
||||
|
||||
* `y = x`
|
||||
|
||||
**Python**并没有使用新的内存来储存变量 `y` 的值,而是在命名空间中,让变量 `y` 与变量 `x` 指向了同一块内存空间。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变) | `x : pos1`
|
||||
`y : pos1` |
|
||||
|
||||
* `y = 'foo'`
|
||||
|
||||
**Python**此时分配一个 `PyStr` 大小的内存 `pos2` 来储存对象 `foo` ,然后改变变量 `y` 所指的对象。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变)
|
||||
`pos2 : PyStr('foo')` (不可变) | `x : pos1`
|
||||
`y : pos2` |
|
||||
|
||||
对这一过程进行验证,可以使用 `id` 函数。
|
||||
|
||||
```py
|
||||
id(x)
|
||||
```
|
||||
|
||||
返回变量 `x` 的内存地址。
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
x = 500
|
||||
id(x)
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
48220272L
|
||||
```
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
y = x
|
||||
id(y)
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
48220272L
|
||||
```
|
||||
|
||||
也可以使用 `is` 来判断是不是指向同一个事物:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
x is y
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
现在 `y` 指向另一块内存:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
y = 'foo'
|
||||
id(y)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
39148320L
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
x is y
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
**Python**会为每个出现的对象进行赋值,哪怕它们的值是一样的,例如:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
x = 500
|
||||
id(x)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
48220296L
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
y = 500
|
||||
id(y)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
48220224L
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
x is y
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
不过,为了提高内存利用效率,对于一些简单的对象,如一些数值较小的int对象,**Python**采用了重用对象内存的办法:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
x = 2
|
||||
id(x)
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
6579504L
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
y = 2
|
||||
id(y)
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
6579504L
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
x is y
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
## 容器类型
|
||||
|
||||
现在来看另一段代码:
|
||||
|
||||
```py
|
||||
x = [500, 501, 502]
|
||||
y = x
|
||||
y[1] = 600
|
||||
y = [700, 800]
|
||||
|
||||
```
|
||||
|
||||
* `x = [500, 501, 502]`
|
||||
|
||||
Python为3个PyInt分配内存 `pos1` , `pos2` , `pos3` (不可变),然后为列表分配一段内存 `pos4` ,它包含3个位置,分别指向这3个内存,最后再让变量 `x` 指向这个列表。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变)
|
||||
`pos2 : PyInt(501)` (不可变)
|
||||
`pos3 : PyInt(502)` (不可变)
|
||||
`pos4 : PyList(pos1, pos2, pos3)` (可变) | `x : pos4` |
|
||||
|
||||
* `y = x`
|
||||
|
||||
并没有创建新的对象,只需要将 `y` 指向 `pos4` 即可。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变)
|
||||
`pos2 : PyInt(501)` (不可变)
|
||||
`pos3 : PyInt(502)` (不可变)
|
||||
`pos4 : PyList(pos1, pos2, pos3)` (可变) | `x : pos4`
|
||||
`y : pos4` |
|
||||
|
||||
* `y[1] = 600`
|
||||
|
||||
原来 `y[1]` 这个位置指向的是 `pos2` ,由于不能修改 `pos2` 的值,所以首先为 `600` 分配新内存 `pos5` 。
|
||||
|
||||
再把 `y[1]` 指向的位置修改为 `pos5` 。此时,由于 `pos2` 位置的对象已经没有用了,**Python**会自动调用垃圾处理机制将它回收。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变)
|
||||
`pos2 :` 垃圾回收
|
||||
`pos3 : PyInt(502)` (不可变)
|
||||
`pos4 : PyList(pos1, pos5, pos3)` (可变)
|
||||
`pos5 : PyInt(600)` (不可变) | `x : pos4`
|
||||
`y : pos4` |
|
||||
|
||||
* `y = [700, 800]`
|
||||
|
||||
首先创建这个列表,然后将变量 `y` 指向它。
|
||||
|
||||
| 内存 | 命名空间 |
|
||||
| --- | --- |
|
||||
| `pos1 : PyInt(500)` (不可变)
|
||||
`pos3 : PyInt(502)` (不可变)
|
||||
`pos4 : PyList(pos1, pos5, pos3)` (可变)
|
||||
`pos5 : PyInt(600)` (不可变)
|
||||
`pos6 : PyInt(700)` (不可变)
|
||||
`pos7 : PyInt(800)` (不可变)
|
||||
`pos8 : PyList(pos6, pos7)` (可变) | `x : pos4`
|
||||
`y : pos8` |
|
||||
|
||||
对这一过程进行验证:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
x = [500, 501, 502]
|
||||
print id(x[0])
|
||||
print id(x[1])
|
||||
print id(x[2])
|
||||
print id(x)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
48220224
|
||||
48220248
|
||||
48220200
|
||||
54993032
|
||||
|
||||
```
|
||||
|
||||
赋值,`id(y)` 与 `id(x)` 相同。
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
y = x
|
||||
print id(y)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
54993032
|
||||
|
||||
```
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
x is y
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
修改 `y[1]` ,`id(y)` 并不改变。
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
y[1] = 600
|
||||
print id(y)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
54993032
|
||||
|
||||
```
|
||||
|
||||
`id(x[1])` 和 `id(y[1])` 的值改变了。
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
print id(x[1])
|
||||
print id(y[1])
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
48220272
|
||||
48220272
|
||||
|
||||
```
|
||||
|
||||
更改 `y` 的值,`id(y)` 的值改变
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
y = [700, 800]
|
||||
print id(y)
|
||||
print id(x)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
54995272
|
||||
54993032
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,229 @@
|
|||
# 判断语句
|
||||
|
||||
## 基本用法
|
||||
|
||||
判断,基于一定的条件,决定是否要执行特定的一段代码,例如判断一个数是不是正数:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
x = 0.5
|
||||
if x > 0:
|
||||
print "Hey!"
|
||||
print "x is positive"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Hey!
|
||||
x is positive
|
||||
|
||||
```
|
||||
|
||||
在这里,如果 `x > 0` 为 `False` ,那么程序将不会执行两条 `print` 语句。
|
||||
|
||||
虽然都是用 `if` 关键词定义判断,但与**C,Java**等语言不同,**Python**不使用 `{}` 将 `if` 语句控制的区域包含起来。**Python**使用的是缩进方法。同时,也不需要用 `()` 将判断条件括起来。
|
||||
|
||||
上面例子中的这两条语句:
|
||||
|
||||
```py
|
||||
print "Hey!"
|
||||
print "x is positive"
|
||||
|
||||
```
|
||||
|
||||
就叫做一个代码块,同一个代码块使用同样的缩进值,它们组成了这条 `if` 语句的主体。
|
||||
|
||||
不同的缩进值表示不同的代码块,例如:
|
||||
|
||||
`x > 0` 时:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
x = 0.5
|
||||
if x > 0:
|
||||
print "Hey!"
|
||||
print "x is positive"
|
||||
print "This is still part of the block"
|
||||
print "This isn't part of the block, and will always print."
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Hey!
|
||||
x is positive
|
||||
This is still part of the block
|
||||
This isn't part of the block, and will always print.
|
||||
|
||||
```
|
||||
|
||||
`x < 0` 时:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
x = -0.5
|
||||
if x > 0:
|
||||
print "Hey!"
|
||||
print "x is positive"
|
||||
print "This is still part of the block"
|
||||
print "This isn't part of the block, and will always print."
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
This isn't part of the block, and will always print.
|
||||
|
||||
```
|
||||
|
||||
在这两个例子中,最后一句并不是`if`语句中的内容,所以不管条件满不满足,它都会被执行。
|
||||
|
||||
一个完整的 `if` 结构通常如下所示(注意:条件后的 `:` 是必须要的,缩进值需要一样):
|
||||
|
||||
```py
|
||||
if <condition 1>:
|
||||
<statement 1>
|
||||
<statement 2>
|
||||
elif <condition 2>:
|
||||
<statements>
|
||||
else:
|
||||
<statements>
|
||||
```
|
||||
|
||||
当条件1被满足时,执行 `if` 下面的语句,当条件1不满足的时候,转到 `elif` ,看它的条件2满不满足,满足执行 `elif` 下面的语句,不满足则执行 `else` 下面的语句。
|
||||
|
||||
对于上面的例子进行扩展:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
x = 0
|
||||
if x > 0:
|
||||
print "x is positive"
|
||||
elif x == 0:
|
||||
print "x is zero"
|
||||
else:
|
||||
print "x is negative"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
x is zero
|
||||
|
||||
```
|
||||
|
||||
`elif` 的个数没有限制,可以是1个或者多个,也可以没有。
|
||||
|
||||
`else` 最多只有1个,也可以没有。
|
||||
|
||||
可以使用 `and` , `or` , `not` 等关键词结合多个判断条件:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
x = 10
|
||||
y = -5
|
||||
x > 0 and y < 0
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
not x > 0
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
x < 0 or y < 0
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
这里使用这个简单的例子,假如想判断一个年份是不是闰年,按照闰年的定义,这里只需要判断这个年份是不是能被4整除,但是不能被100整除,或者正好被400整除:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
year = 1900
|
||||
if year % 400 == 0:
|
||||
print "This is a leap year!"
|
||||
# 两个条件都满足才执行
|
||||
elif year % 4 == 0 and year % 100 != 0:
|
||||
print "This is a leap year!"
|
||||
else:
|
||||
print "This is not a leap year."
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
This is not a leap year.
|
||||
|
||||
```
|
||||
|
||||
## 值的测试
|
||||
|
||||
**Python**不仅仅可以使用布尔型变量作为条件,它可以直接在`if`中使用任何表达式作为条件:
|
||||
|
||||
大部分表达式的值都会被当作`True`,但以下表达式值会被当作`False`:
|
||||
|
||||
* False
|
||||
* None
|
||||
* 0
|
||||
* 空字符串,空列表,空字典,空集合
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
mylist = [3, 1, 4, 1, 5, 9]
|
||||
if mylist:
|
||||
print "The first element is:", mylist[0]
|
||||
else:
|
||||
print "There is no first element."
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
The first element is: 3
|
||||
|
||||
```
|
||||
|
||||
修改为空列表:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
mylist = []
|
||||
if mylist:
|
||||
print "The first element is:", mylist[0]
|
||||
else:
|
||||
print "There is no first element."
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
There is no first element.
|
||||
|
||||
```
|
||||
|
||||
当然这种用法并不推荐,推荐使用 `if len(mylist) > 0:` 来判断一个列表是否为空。
|
||||
|
|
@ -0,0 +1,252 @@
|
|||
# 循环
|
||||
|
||||
循环的作用在于将一段代码重复执行多次。
|
||||
|
||||
## while 循环
|
||||
|
||||
```py
|
||||
while <condition>:
|
||||
<statesments>
|
||||
```
|
||||
|
||||
**Python**会循环执行`<statesments>`,直到`<condition>`不满足为止。
|
||||
|
||||
例如,计算数字`0`到`1000000`的和:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
i = 0
|
||||
total = 0
|
||||
while i < 1000000:
|
||||
total += i
|
||||
i += 1
|
||||
print total
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
499999500000
|
||||
|
||||
```
|
||||
|
||||
之前提到,空容器会被当成 `False` ,因此可以用 `while` 循环来读取容器中的所有元素:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
plays = set(['Hamlet', 'Macbeth', 'King Lear'])
|
||||
while plays:
|
||||
play = plays.pop()
|
||||
print 'Perform', play
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Perform King Lear
|
||||
Perform Macbeth
|
||||
Perform Hamlet
|
||||
|
||||
```
|
||||
|
||||
循环每次从 `plays` 中弹出一个元素,一直到 `plays` 为空为止。
|
||||
|
||||
## for 循环
|
||||
|
||||
```py
|
||||
for <variable> in <sequence>:
|
||||
<indented block of code>
|
||||
```
|
||||
|
||||
`for` 循环会遍历完`<sequence>`中所有元素为止
|
||||
|
||||
上一个例子可以改写成如下形式:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
plays = set(['Hamlet', 'Macbeth', 'King Lear'])
|
||||
for play in plays:
|
||||
print 'Perform', play
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Perform King Lear
|
||||
Perform Macbeth
|
||||
Perform Hamlet
|
||||
|
||||
```
|
||||
|
||||
使用 `for` 循环时,注意尽量不要改变 `plays` 的值,否则可能会产生意想不到的结果。
|
||||
|
||||
之前的求和也可以通过 `for` 循环来实现:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
total = 0
|
||||
for i in range(100000):
|
||||
total += i
|
||||
print total
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4999950000
|
||||
|
||||
```
|
||||
|
||||
然而这种写法有一个缺点:在循环前,它会生成一个长度为 `100000` 的临时列表。
|
||||
|
||||
生成列表的问题在于,会有一定的时间和内存消耗,当数字从 `100000` 变得更大时,时间和内存的消耗会更加明显。
|
||||
|
||||
为了解决这个问题,我们可以使用 `xrange` 来代替 `range` 函数,其效果与`range`函数相同,但是 `xrange` 并不会一次性的产生所有的数据:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
total = 0
|
||||
for i in xrange(100000):
|
||||
total += i
|
||||
print total
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4999950000
|
||||
|
||||
```
|
||||
|
||||
比较一下两者的运行时间:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
%timeit for i in xrange(1000000): i = i
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
10 loops, best of 3: 40.7 ms per loop
|
||||
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
%timeit for i in range(1000000): i = i
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
10 loops, best of 3: 96.6 ms per loop
|
||||
|
||||
```
|
||||
|
||||
可以看出,`xrange` 用时要比 `range` 少。
|
||||
|
||||
## continue 语句
|
||||
|
||||
遇到 `continue` 的时候,程序会返回到循环的最开始重新执行。
|
||||
|
||||
例如在循环中忽略一些特定的值:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
values = [7, 6, 4, 7, 19, 2, 1]
|
||||
for i in values:
|
||||
if i % 2 != 0:
|
||||
# 忽略奇数
|
||||
continue
|
||||
print i/2
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
3
|
||||
2
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
## break 语句
|
||||
|
||||
遇到 `break` 的时候,程序会跳出循环,不管循环条件是不是满足:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
command_list = ['start',
|
||||
'process',
|
||||
'process',
|
||||
'process',
|
||||
'stop',
|
||||
'start',
|
||||
'process',
|
||||
'stop']
|
||||
while command_list:
|
||||
command = command_list.pop(0)
|
||||
if command == 'stop':
|
||||
break
|
||||
print(command)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
start
|
||||
process
|
||||
process
|
||||
process
|
||||
|
||||
```
|
||||
|
||||
在遇到第一个 `'stop'` 之后,程序跳出循环。
|
||||
|
||||
## else语句
|
||||
|
||||
与 `if` 一样, `while` 和 `for` 循环后面也可以跟着 `else` 语句,不过要和`break`一起连用。
|
||||
|
||||
* 当循环正常结束时,循环条件不满足, `else` 被执行;
|
||||
* 当循环被 `break` 结束时,循环条件仍然满足, `else` 不执行。
|
||||
|
||||
不执行:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
values = [7, 6, 4, 7, 19, 2, 1]
|
||||
for x in values:
|
||||
if x <= 10:
|
||||
print 'Found:', x
|
||||
break
|
||||
else:
|
||||
print 'All values greater than 10'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Found: 7
|
||||
|
||||
```
|
||||
|
||||
执行:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
values = [11, 12, 13, 100]
|
||||
for x in values:
|
||||
if x <= 10:
|
||||
print 'Found:', x
|
||||
break
|
||||
else:
|
||||
print 'All values greater than 10'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
All values greater than 10
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,138 @@
|
|||
# 列表推导式
|
||||
|
||||
循环可以用来生成列表:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
values = [10, 21, 4, 7, 12]
|
||||
squares = []
|
||||
for x in values:
|
||||
squares.append(x**2)
|
||||
print squares
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[100, 441, 16, 49, 144]
|
||||
|
||||
```
|
||||
|
||||
列表推导式可以使用更简单的方法来创建这个列表:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
values = [10, 21, 4, 7, 12]
|
||||
squares = [x**2 for x in values]
|
||||
print squares
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[100, 441, 16, 49, 144]
|
||||
|
||||
```
|
||||
|
||||
还可以在列表推导式中加入条件进行筛选。
|
||||
|
||||
例如在上面的例子中,假如只想保留列表中不大于`10`的数的平方:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
values = [10, 21, 4, 7, 12]
|
||||
squares = [x**2 for x in values if x <= 10]
|
||||
print squares
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[100, 16, 49]
|
||||
|
||||
```
|
||||
|
||||
也可以使用推导式生成集合和字典:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
square_set = {x**2 for x in values if x <= 10}
|
||||
print(square_set)
|
||||
square_dict = {x: x**2 for x in values if x <= 10}
|
||||
print(square_dict)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
set([16, 49, 100])
|
||||
{10: 100, 4: 16, 7: 49}
|
||||
|
||||
```
|
||||
|
||||
再如,计算上面例子中生成的列表中所有元素的和:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
total = sum([x**2 for x in values if x <= 10])
|
||||
print(total)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
165
|
||||
|
||||
```
|
||||
|
||||
但是,**Python**会生成这个列表,然后在将它放到垃圾回收机制中(因为没有变量指向它),这毫无疑问是种浪费。
|
||||
|
||||
为了解决这种问题,与xrange()类似,**Python**使用产生式表达式来解决这个问题:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
total = sum(x**2 for x in values if x <= 10)
|
||||
print(total)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
165
|
||||
|
||||
```
|
||||
|
||||
与上面相比,只是去掉了括号,但这里并不会一次性的生成这个列表。
|
||||
|
||||
比较一下两者的用时:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
x = range(1000000)
|
||||
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
%timeit total = sum([i**2 for i in x])
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 loops, best of 3: 3.86 s per loop
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
%timeit total = sum(i**2 for i in x)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 loops, best of 3: 2.58 s per loop
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,436 @@
|
|||
# 函数
|
||||
|
||||
## 定义函数
|
||||
|
||||
函数`function`,通常接受输入参数,并有返回值。
|
||||
|
||||
它负责完成某项特定任务,而且相较于其他代码,具备相对的独立性。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
def add(x, y):
|
||||
"""Add two numbers"""
|
||||
a = x + y
|
||||
return a
|
||||
|
||||
```
|
||||
|
||||
函数通常有一下几个特征:
|
||||
|
||||
* 使用 `def` 关键词来定义一个函数。
|
||||
* `def` 后面是函数的名称,括号中是函数的参数,不同的参数用 `,` 隔开, `def foo():` 的形式是必须要有的,参数可以为空;
|
||||
* 使用缩进来划分函数的内容;
|
||||
* `docstring` 用 `"""` 包含的字符串,用来解释函数的用途,可省略;
|
||||
* `return` 返回特定的值,如果省略,返回 `None` 。
|
||||
|
||||
## 使用函数
|
||||
|
||||
使用函数时,只需要将参数换成特定的值传给函数。
|
||||
|
||||
**Python**并没有限定参数的类型,因此可以使用不同的参数类型:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
print add(2, 3)
|
||||
print add('foo', 'bar')
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5
|
||||
foobar
|
||||
|
||||
```
|
||||
|
||||
在这个例子中,如果传入的两个参数不可以相加,那么**Python**会将报错:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
print add(2, "foo")
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-3-6f8dcf7eb280> in <module>()
|
||||
----> 1 print add(2, "foo")
|
||||
|
||||
<ipython-input-1-e831943cfaf2> in add(x, y)
|
||||
1 def add(x, y):
|
||||
2 """Add two numbers"""
|
||||
----> 3 a = x + y
|
||||
4 return a
|
||||
|
||||
TypeError: unsupported operand type(s) for +: 'int' and 'str'
|
||||
```
|
||||
|
||||
如果传入的参数数目与实际不符合,也会报错:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
print add(1, 2, 3)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-4-ed7bae31fc7d> in <module>()
|
||||
----> 1 print add(1, 2, 3)
|
||||
|
||||
TypeError: add() takes exactly 2 arguments (3 given)
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
print add(1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-5-a954233d3b0d> in <module>()
|
||||
----> 1 print add(1)
|
||||
|
||||
TypeError: add() takes exactly 2 arguments (1 given)
|
||||
```
|
||||
|
||||
传入参数时,Python提供了两种选项,第一种是上面使用的按照位置传入参数,另一种则是使用关键词模式,显式地指定参数的值:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
print add(x=2, y=3)
|
||||
print add(y="foo", x="bar")
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5
|
||||
barfoo
|
||||
|
||||
```
|
||||
|
||||
可以混合这两种模式:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print add(2, y=3)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
## 设定参数默认值
|
||||
|
||||
可以在函数定义的时候给参数设定默认值,例如:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
def quad(x, a=1, b=0, c=0):
|
||||
return a*x**2 + b*x + c
|
||||
|
||||
```
|
||||
|
||||
可以省略有默认值的参数:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
print quad(2.0)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4.0
|
||||
|
||||
```
|
||||
|
||||
可以修改参数的默认值:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
print quad(2.0, b=3)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
10.0
|
||||
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
print quad(2.0, 2, c=4)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
12.0
|
||||
|
||||
```
|
||||
|
||||
这里混合了位置和指定两种参数传入方式,第二个2是传给 `a` 的。
|
||||
|
||||
注意,在使用混合语法时,要注意不能给同一个值赋值多次,否则会报错,例如:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
print quad(2.0, 2, a=2)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-12-101d0c090bbb> in <module>()
|
||||
----> 1 print quad(2.0, 2, a=2)
|
||||
|
||||
TypeError: quad() got multiple values for keyword argument 'a'
|
||||
```
|
||||
|
||||
## 接收不定参数
|
||||
|
||||
使用如下方法,可以使函数接受不定数目的参数:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
def add(x, *args):
|
||||
total = x
|
||||
for arg in args:
|
||||
total += arg
|
||||
return total
|
||||
|
||||
```
|
||||
|
||||
这里,`*args` 表示参数数目不定,可以看成一个元组,把第一个参数后面的参数当作元组中的元素。
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
print add(1, 2, 3, 4)
|
||||
print add(1, 2)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
10
|
||||
3
|
||||
|
||||
```
|
||||
|
||||
这样定义的函数不能使用关键词传入参数,要使用关键词,可以这样:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
def add(x, **kwargs):
|
||||
total = x
|
||||
for arg, value in kwargs.items():
|
||||
print "adding ", arg
|
||||
total += value
|
||||
return total
|
||||
|
||||
```
|
||||
|
||||
这里, `**kwargs` 表示参数数目不定,相当于一个字典,关键词和值对应于键值对。
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
print add(10, y=11, z=12, w=13)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
adding y
|
||||
adding z
|
||||
adding w
|
||||
46
|
||||
|
||||
```
|
||||
|
||||
再看这个例子,可以接收任意数目的位置参数和键值对参数:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
def foo(*args, **kwargs):
|
||||
print args, kwargs
|
||||
|
||||
foo(2, 3, x='bar', z=10)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(2, 3) {'x': 'bar', 'z': 10}
|
||||
|
||||
```
|
||||
|
||||
不过要按顺序传入参数,先传入位置参数 `args` ,在传入关键词参数 `kwargs` 。
|
||||
|
||||
## 返回多个值
|
||||
|
||||
函数可以返回多个值:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
from math import atan2
|
||||
|
||||
def to_polar(x, y):
|
||||
r = (x**2 + y**2) ** 0.5
|
||||
theta = atan2(y, x)
|
||||
return r, theta
|
||||
|
||||
r, theta = to_polar(3, 4)
|
||||
print r, theta
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5.0 0.927295218002
|
||||
|
||||
```
|
||||
|
||||
事实上,**Python**将返回的两个值变成了元组:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
print to_polar(3, 4)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(5.0, 0.9272952180016122)
|
||||
|
||||
```
|
||||
|
||||
因为这个元组中有两个值,所以可以使用
|
||||
|
||||
```py
|
||||
r, theta = to_polar(3, 4)
|
||||
```
|
||||
|
||||
给两个值赋值。
|
||||
|
||||
列表也有相似的功能:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a, b, c = [1, 2, 3]
|
||||
print a, b, c
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 2 3
|
||||
|
||||
```
|
||||
|
||||
事实上,不仅仅返回值可以用元组表示,也可以将参数用元组以这种方式传入:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
def add(x, y):
|
||||
"""Add two numbers"""
|
||||
a = x + y
|
||||
return a
|
||||
|
||||
z = (2, 3)
|
||||
print add(*z)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
这里的`*`必不可少。
|
||||
|
||||
事实上,还可以通过字典传入参数来执行函数:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
def add(x, y):
|
||||
"""Add two numbers"""
|
||||
a = x + y
|
||||
return a
|
||||
|
||||
w = {'x': 2, 'y': 3}
|
||||
print add(**w)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
## map 方法生成序列
|
||||
|
||||
可以通过 `map` 的方式利用函数来生成序列:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
def sqr(x):
|
||||
return x ** 2
|
||||
|
||||
a = [2,3,4]
|
||||
print map(sqr, a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[4, 9, 16]
|
||||
|
||||
```
|
||||
|
||||
其用法为:
|
||||
|
||||
```py
|
||||
map(aFun, aSeq)
|
||||
```
|
||||
|
||||
将函数 `aFun` 应用到序列 `aSeq` 上的每一个元素上,返回一个列表,不管这个序列原来是什么类型。
|
||||
|
||||
事实上,根据函数参数的多少,`map` 可以接受多组序列,将其对应的元素作为参数传入函数:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
def add(x, y):
|
||||
return x + y
|
||||
|
||||
a = (2,3,4)
|
||||
b = [10,5,3]
|
||||
print map(add,a,b)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[12, 8, 7]
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,367 @@
|
|||
# 模块和包
|
||||
|
||||
## 模块
|
||||
|
||||
Python会将所有 `.py` 结尾的文件认定为Python代码文件,考虑下面的脚本 `ex1.py` :
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
%%writefile ex1.py
|
||||
|
||||
PI = 3.1416
|
||||
|
||||
def sum(lst):
|
||||
tot = lst[0]
|
||||
for value in lst[1:]:
|
||||
tot = tot + value
|
||||
return tot
|
||||
|
||||
w = [0, 1, 2, 3]
|
||||
print sum(w), PI
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting ex1.py
|
||||
|
||||
```
|
||||
|
||||
可以执行它:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
%run ex1.py
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
6 3.1416
|
||||
|
||||
```
|
||||
|
||||
这个脚本可以当作一个模块,可以使用`import`关键词加载并执行它(这里要求`ex1.py`在当前工作目录):
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
import ex1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
6 3.1416
|
||||
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
ex1
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
<module 'ex1' from 'ex1.py'>
|
||||
```
|
||||
|
||||
在导入时,**Python**会执行一遍模块中的所有内容。
|
||||
|
||||
`ex1.py` 中所有的变量都被载入了当前环境中,不过要使用
|
||||
|
||||
```py
|
||||
ex1.变量名
|
||||
```
|
||||
|
||||
的方法来查看或者修改这些变量:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
print ex1.PI
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
3.1416
|
||||
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
ex1.PI = 3.141592653
|
||||
print ex1.PI
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
3.141592653
|
||||
|
||||
```
|
||||
|
||||
还可以用
|
||||
|
||||
```py
|
||||
ex1.函数名
|
||||
```
|
||||
|
||||
调用模块里面的函数:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print ex1.sum([2, 3, 4])
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
9
|
||||
|
||||
```
|
||||
|
||||
为了提高效率,**Python**只会载入模块一次,已经载入的模块再次载入时,Python并不会真正执行载入操作,哪怕模块的内容已经改变。
|
||||
|
||||
例如,这里重新导入 `ex1` 时,并不会执行 `ex1.py` 中的 `print` 语句:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
import ex1
|
||||
|
||||
```
|
||||
|
||||
需要重新导入模块时,可以使用`reload`强制重新载入它,例如:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
reload(ex1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
6 3.1416
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
<module 'ex1' from 'ex1.pyc'>
|
||||
```
|
||||
|
||||
删除之前生成的文件:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('ex1.py')
|
||||
|
||||
```
|
||||
|
||||
## `__name__` 属性
|
||||
|
||||
有时候我们想将一个 `.py` 文件既当作脚本,又能当作模块用,这个时候可以使用 `__name__` 这个属性。
|
||||
|
||||
只有当文件被当作脚本执行的时候, `__name__`的值才会是 `'__main__'`,所以我们可以:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
%%writefile ex2.py
|
||||
|
||||
PI = 3.1416
|
||||
|
||||
def sum(lst):
|
||||
""" Sum the values in a list
|
||||
"""
|
||||
tot = 0
|
||||
for value in lst:
|
||||
tot = tot + value
|
||||
return tot
|
||||
|
||||
def add(x, y):
|
||||
" Add two values."
|
||||
a = x + y
|
||||
return a
|
||||
|
||||
def test():
|
||||
w = [0,1,2,3]
|
||||
assert(sum(w) == 6)
|
||||
print 'test passed.'
|
||||
|
||||
if __name__ == '__main__':
|
||||
test()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing ex2.py
|
||||
|
||||
```
|
||||
|
||||
运行文件:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
%run ex2.py
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
test passed.
|
||||
|
||||
```
|
||||
|
||||
当作模块导入, `test()` 不会执行:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
import ex2
|
||||
|
||||
```
|
||||
|
||||
但是可以使用其中的变量:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
ex2.PI
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
3.1416
|
||||
```
|
||||
|
||||
使用别名:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
import ex2 as e2
|
||||
e2.PI
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
3.1416
|
||||
```
|
||||
|
||||
## 其他导入方法
|
||||
|
||||
可以从模块中导入变量:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
from ex2 import add, PI
|
||||
|
||||
```
|
||||
|
||||
使用 `from` 后,可以直接使用 `add` , `PI`:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
add(2, 3)
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
5
|
||||
```
|
||||
|
||||
或者使用 `*` 导入所有变量:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
from ex2 import *
|
||||
add(3, 4.5)
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
7.5
|
||||
```
|
||||
|
||||
这种导入方法不是很提倡,因为如果你不确定导入的都有哪些,可能覆盖一些已有的函数。
|
||||
|
||||
删除文件:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('ex2.py')
|
||||
|
||||
```
|
||||
|
||||
## 包
|
||||
|
||||
假设我们有这样的一个文件夹:
|
||||
|
||||
foo/
|
||||
|
||||
* `__init__.py`
|
||||
* `bar.py` (defines func)
|
||||
* `baz.py` (defines zap)
|
||||
|
||||
这意味着 foo 是一个包,我们可以这样导入其中的内容:
|
||||
|
||||
```py
|
||||
from foo.bar import func
|
||||
from foo.baz import zap
|
||||
|
||||
```
|
||||
|
||||
`bar` 和 `baz` 都是 `foo` 文件夹下的 `.py` 文件。
|
||||
|
||||
导入包要求:
|
||||
|
||||
* 文件夹 `foo` 在**Python**的搜索路径中
|
||||
* `__init__.py` 表示 `foo` 是一个包,它可以是个空文件。
|
||||
|
||||
## 常用的标准库
|
||||
|
||||
* re 正则表达式
|
||||
* copy 复制
|
||||
* math, cmath 数学
|
||||
* decimal, fraction
|
||||
* sqlite3 数据库
|
||||
* os, os.path 文件系统
|
||||
* gzip, bz2, zipfile, tarfile 压缩文件
|
||||
* csv, netrc 各种文件格式
|
||||
* xml
|
||||
* htmllib
|
||||
* ftplib, socket
|
||||
* cmd 命令行
|
||||
* pdb
|
||||
* profile, cProfile, timeit
|
||||
* collections, heapq, bisect 数据结构
|
||||
* mmap
|
||||
* threading, Queue 并行
|
||||
* multiprocessing
|
||||
* subprocess
|
||||
* pickle, cPickle
|
||||
* struct
|
||||
|
||||
## PYTHONPATH设置
|
||||
|
||||
Python的搜索路径可以通过环境变量PYTHONPATH设置,环境变量的设置方法依操作系统的不同而不同,具体方法可以网上搜索。
|
||||
|
|
@ -0,0 +1,521 @@
|
|||
# 异常
|
||||
|
||||
## try & except 块
|
||||
|
||||
写代码的时候,出现错误必不可免,即使代码没有问题,也可能遇到别的问题。
|
||||
|
||||
看下面这段代码:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
|
||||
```
|
||||
|
||||
这段代码接收命令行的输入,当输入为数字时,计算它的对数并输出,直到输入值为 `q` 为止。
|
||||
|
||||
乍看没什么问题,然而当我们输入0或者负数时:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> -1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ValueError Traceback (most recent call last)
|
||||
<ipython-input-1-ceb8cf66641b> in <module>()
|
||||
6 break
|
||||
7 x = float(text)
|
||||
----> 8 y = math.log10(x)
|
||||
9 print "log10({0}) = {1}".format(x, y)
|
||||
|
||||
ValueError: math domain error
|
||||
```
|
||||
|
||||
`log10` 函数会报错,因为不能接受非正值。
|
||||
|
||||
一旦报错,程序就会停止执行,如果不希望程序停止执行,那么我们可以添加一对 `try & except`:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
|
||||
```
|
||||
|
||||
一旦 `try` 块中的内容出现了异常,那么 `try` 块后面的内容会被忽略,**Python**会寻找 `except` 里面有没有对应的内容,如果找到,就执行对应的块,没有则抛出这个异常。
|
||||
|
||||
在上面的例子中,`try` 抛出的是 `ValueError`,`except` 中有对应的内容,所以这个异常被 `except` 捕捉到,程序可以继续执行:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> -1
|
||||
the value must be greater than 0
|
||||
> 0
|
||||
the value must be greater than 0
|
||||
> 1
|
||||
log10(1.0) = 0.0
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
## 捕捉不同的错误类型
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
|
||||
```
|
||||
|
||||
假设我们将这里的 `y` 更改为 `1 / math.log10(x)`,此时输入 `1`:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ZeroDivisionError Traceback (most recent call last)
|
||||
<ipython-input-3-7607f1ae6af9> in <module>()
|
||||
7 break
|
||||
8 x = float(text)
|
||||
----> 9 y = 1 / math.log10(x)
|
||||
10 print "log10({0}) = {1}".format(x, y)
|
||||
11 except ValueError:
|
||||
|
||||
ZeroDivisionError: float division by zero
|
||||
```
|
||||
|
||||
因为我们的 `except` 里面并没有 `ZeroDivisionError`,所以会抛出这个异常,我们可以通过两种方式解决这个问题:
|
||||
|
||||
## 捕捉所有异常
|
||||
|
||||
将`except` 的值改成 `Exception` 类,来捕获所有的异常。
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "1 / log10({0}) = {1}".format(x, y)
|
||||
except Exception:
|
||||
print "invalid value"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
invalid value
|
||||
> 0
|
||||
invalid value
|
||||
> -1
|
||||
invalid value
|
||||
> 2
|
||||
1 / log10(2.0) = 3.32192809489
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
## 指定特定值
|
||||
|
||||
这里,我们把 `ZeroDivisionError` 加入 `except` 。
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "1 / log10({0}) = {1}".format(x, y)
|
||||
except (ValueError, ZeroDivisionError):
|
||||
print "invalid value"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
invalid value
|
||||
> -1
|
||||
invalid value
|
||||
> 0
|
||||
invalid value
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
或者另加处理:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "1 / log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
except ZeroDivisionError:
|
||||
print "the value must not be 1"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
the value must not be 1
|
||||
> -1
|
||||
the value must be greater than 0
|
||||
> 0
|
||||
the value must be greater than 0
|
||||
> 2
|
||||
1 / log10(2.0) = 3.32192809489
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
事实上,我们还可以将这两种方式结合起来,用 `Exception` 来捕捉其他的错误:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "1 / log10({0}) = {1}".format(x, y)
|
||||
except ValueError:
|
||||
print "the value must be greater than 0"
|
||||
except ZeroDivisionError:
|
||||
print "the value must not be 1"
|
||||
except Exception:
|
||||
print "unexpected error"
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
the value must not be 1
|
||||
> -1
|
||||
the value must be greater than 0
|
||||
> 0
|
||||
the value must be greater than 0
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
## 得到异常的具体信息
|
||||
|
||||
在上面的例子中,当我们输入不能转换为浮点数的字符串时,它输出的是 `the value must be greater than 0`,这并没有反映出实际情况。
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
float('a')
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ValueError Traceback (most recent call last)
|
||||
<ipython-input-8-99859da4e72c> in <module>()
|
||||
----> 1 float('a')
|
||||
|
||||
ValueError: could not convert string to float: a
|
||||
```
|
||||
|
||||
为了得到异常的具体信息,我们将这个 `ValueError` 具现化:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
import math
|
||||
|
||||
while True:
|
||||
try:
|
||||
text = raw_input('> ')
|
||||
if text[0] == 'q':
|
||||
break
|
||||
x = float(text)
|
||||
y = 1 / math.log10(x)
|
||||
print "1 / log10({0}) = {1}".format(x, y)
|
||||
except ValueError as exc:
|
||||
if exc.message == "math domain error":
|
||||
print "the value must be greater than 0"
|
||||
else:
|
||||
print "could not convert '%s' to float" % text
|
||||
except ZeroDivisionError:
|
||||
print "the value must not be 1"
|
||||
except Exception as exc:
|
||||
print "unexpected error:", exc.message
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> 1
|
||||
the value must not be 1
|
||||
> -1
|
||||
the value must be greater than 0
|
||||
> aa
|
||||
could not convert 'aa' to float
|
||||
> q
|
||||
|
||||
```
|
||||
|
||||
同时,我们也将捕获的其他异常的信息显示出来。
|
||||
|
||||
这里,`exc.message` 显示的内容是异常对应的说明,例如
|
||||
|
||||
```py
|
||||
ValueError: could not convert string to float: a
|
||||
```
|
||||
|
||||
对应的 `message` 是
|
||||
|
||||
```py
|
||||
could not convert string to float: a
|
||||
```
|
||||
|
||||
当我们使用 `except Exception` 时,会捕获所有的 `Exception` 和它派生出来的子类,但不是所有的异常都是从 `Exception` 类派生出来的,可能会出现一些不能捕获的情况,因此,更加一般的做法是使用这样的形式:
|
||||
|
||||
```py
|
||||
try:
|
||||
pass
|
||||
except:
|
||||
pass
|
||||
|
||||
```
|
||||
|
||||
这样不指定异常的类型会捕获所有的异常,但是这样的形式并不推荐。
|
||||
|
||||
## 自定义异常
|
||||
|
||||
异常是标准库中的类,这意味着我们可以自定义异常类:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
class CommandError(ValueError):
|
||||
pass
|
||||
|
||||
```
|
||||
|
||||
这里我们定义了一个继承自 `ValueError` 的异常类,异常类一般接收一个字符串作为输入,并把这个字符串当作异常信息,例如:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
valid_commands = {'start', 'stop', 'pause'}
|
||||
|
||||
while True:
|
||||
command = raw_input('> ')
|
||||
if command.lower() not in valid_commands:
|
||||
raise CommandError('Invalid commmand: %s' % command)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
> bad command
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
CommandError Traceback (most recent call last)
|
||||
<ipython-input-11-0e1f81a1136d> in <module>()
|
||||
4 command = raw_input('> ')
|
||||
5 if command.lower() not in valid_commands:
|
||||
----> 6 raise CommandError('Invalid commmand: %s' % command)
|
||||
|
||||
CommandError: Invalid commmand: bad command
|
||||
```
|
||||
|
||||
我们使用 `raise` 关键词来抛出异常。
|
||||
|
||||
我们可以使用 `try/except` 块来捕捉这个异常:
|
||||
|
||||
```py
|
||||
valid_commands = {'start', 'stop', 'pause'}
|
||||
|
||||
while True:
|
||||
command = raw_input('> ')
|
||||
try:
|
||||
if command.lower() not in valid_commands:
|
||||
raise CommandError('Invalid commmand: %s' % command)
|
||||
except CommandError:
|
||||
print 'Bad command string: "%s"' % command
|
||||
|
||||
```
|
||||
|
||||
由于 `CommandError` 继承自 `ValueError`,我们也可以使用 `except ValueError` 来捕获这个异常。
|
||||
|
||||
## finally
|
||||
|
||||
try/catch 块还有一个可选的关键词 finally。
|
||||
|
||||
不管 try 块有没有异常, finally 块的内容总是会被执行,而且会在抛出异常前执行,因此可以用来作为安全保证,比如确保打开的文件被关闭。。
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
try:
|
||||
print 1
|
||||
finally:
|
||||
print 'finally was called.'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1
|
||||
finally was called.
|
||||
|
||||
```
|
||||
|
||||
在抛出异常前执行:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
try:
|
||||
print 1 / 0
|
||||
finally:
|
||||
print 'finally was called.'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
finally was called.
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ZeroDivisionError Traceback (most recent call last)
|
||||
<ipython-input-13-87ecdf8b9265> in <module>()
|
||||
1 try:
|
||||
----> 2 print 1 / 0
|
||||
3 finally:
|
||||
4 print 'finally was called.'
|
||||
|
||||
ZeroDivisionError: integer division or modulo by zero
|
||||
```
|
||||
|
||||
如果异常被捕获了,在最后执行:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
try:
|
||||
print 1 / 0
|
||||
except ZeroDivisionError:
|
||||
print 'divide by 0.'
|
||||
finally:
|
||||
print 'finally was called.'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
divide by 0.
|
||||
finally was called.
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
# 警告
|
||||
|
||||
出现了一些需要让用户知道的问题,但又不想停止程序,这时候我们可以使用警告:
|
||||
|
||||
首先导入警告模块:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import warnings
|
||||
|
||||
```
|
||||
|
||||
在需要的地方,我们使用 `warnings` 中的 `warn` 函数:
|
||||
|
||||
```py
|
||||
warn(msg, WarningType = UserWarning)
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
def month_warning(m):
|
||||
if not 1<= m <= 12:
|
||||
msg = "month (%d) is not between 1 and 12" % m
|
||||
warnings.warn(msg, RuntimeWarning)
|
||||
|
||||
month_warning(13)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
c:\Anaconda\lib\site-packages\IPython\kernel\__main__.py:4: RuntimeWarning: month (13) is not between 1 and 12
|
||||
|
||||
```
|
||||
|
||||
有时候我们想要忽略特定类型的警告,可以使用 `warnings` 的 `filterwarnings` 函数:
|
||||
|
||||
```py
|
||||
filterwarnings(action, category)
|
||||
```
|
||||
|
||||
将 `action` 设置为 `'ignore'` 便可以忽略特定类型的警告:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
warnings.filterwarnings(action = 'ignore', category = RuntimeWarning)
|
||||
|
||||
month_warning(13)
|
||||
|
||||
```
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1 @@
|
|||
# 03\. Numpy
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,626 @@
|
|||
# 数组类型
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
from numpy import *
|
||||
|
||||
```
|
||||
|
||||
之前已经看过整数数组和布尔数组,除此之外还有浮点数数组和复数数组。
|
||||
|
||||
## 复数数组
|
||||
|
||||
产生一个复数数组:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = array([1 + 1j, 2, 3, 4])
|
||||
|
||||
```
|
||||
|
||||
**Python**会自动判断数组的类型:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
dtype('complex128')
|
||||
```
|
||||
|
||||
对于复数我们可以查看它的实部和虚部:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.real
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([ 1., 2., 3., 4.])
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a.imag
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([ 1., 0., 0., 0.])
|
||||
```
|
||||
|
||||
还可以设置它们的值:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a.imag = [1,2,3,4]
|
||||
|
||||
```
|
||||
|
||||
查看 `a`:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([ 1.+1.j, 2.+2.j, 3.+3.j, 4.+4.j])
|
||||
```
|
||||
|
||||
查看复共轭:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a.conj()
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
array([ 1.-1.j, 2.-2.j, 3.-3.j, 4.-4.j])
|
||||
```
|
||||
|
||||
事实上,这些属性方法可以用在浮点数或者整数数组上:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a = array([0.,1,2,3])
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
dtype('float64')
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a.real
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([ 0., 1., 2., 3.])
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a.imag
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([ 0., 0., 0., 0.])
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
a.conj()
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([ 0., 1., 2., 3.])
|
||||
```
|
||||
|
||||
但这里,虚部是只读的,并不能修改它的值:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
# 会报错
|
||||
a.imag = [1,2,3,4]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
TypeError Traceback (most recent call last)
|
||||
<ipython-input-13-3db28f506ec9> in <module>()
|
||||
1 # 会报错
|
||||
----> 2 a.imag = [1,2,3,4]
|
||||
|
||||
TypeError: array does not have imaginary part to set
|
||||
```
|
||||
|
||||
## 指定数组类型
|
||||
|
||||
之前已经知道,构建数组的时候,数组会根据传入的内容自动判断类型:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a = array([0,1.0,2,3])
|
||||
|
||||
```
|
||||
|
||||
对于浮点数,默认为双精度:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
dtype('float64')
|
||||
```
|
||||
|
||||
查看所用字节(`8 bytes * 4`):
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
a.nbytes
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
32
|
||||
```
|
||||
|
||||
当然,我们也可以在构建的时候指定类型:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a = array([0,1.0,2,3],
|
||||
dtype=float32)
|
||||
|
||||
```
|
||||
|
||||
此时类型为单精度浮点数:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
dtype('float32')
|
||||
```
|
||||
|
||||
查看所用字节(`4 bytes * 4`):
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a.nbytes
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
16
|
||||
```
|
||||
|
||||
除此之外,还可以指定有无符号,例如无符号整数:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a = array([0,1,2,3],
|
||||
dtype=uint8)
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
dtype('uint8')
|
||||
```
|
||||
|
||||
`uint8` 只使用一个字节,表示 `0` 到 `255` 的整数。
|
||||
|
||||
还可以从二进制数据中读取。
|
||||
|
||||
先写入二进制数据:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
a = array([102,111,212],
|
||||
dtype=uint8)
|
||||
a.tofile('foo.dat')
|
||||
|
||||
```
|
||||
|
||||
从数据中读入,要指定类型:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
b = frombuffer('foo',
|
||||
dtype=uint8)
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
array([102, 111, 111], dtype=uint8)
|
||||
```
|
||||
|
||||
清理数据文件:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('foo.dat')
|
||||
|
||||
```
|
||||
|
||||
`0-255` 的数字可以表示ASCⅡ码,我们可以用 ord 函数来查看字符的ASCⅡ码值:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
ord('f')
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
102
|
||||
```
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
ord('S')
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
83
|
||||
```
|
||||
|
||||
## Numpy 类型
|
||||
|
||||
具体如下:
|
||||
|
||||
| 基本类型 | 可用的**Numpy**类型 | 备注 |
|
||||
| --- | --- | --- |
|
||||
| 布尔型 | `bool` | 占1个字节 |
|
||||
| 整型 | `int8, int16, int32, int64, int128, int` | `int` 跟**C**语言中的 `long` 一样大 |
|
||||
| 无符号整型 | `uint8, uint16, uint32, uint64, uint128, uint` | `uint` 跟**C**语言中的 `unsigned long` 一样大 |
|
||||
| 浮点数 | `float16, float32, float64, float, longfloat` | 默认为双精度 `float64` ,`longfloat` 精度大小与系统有关 |
|
||||
| 复数 | `complex64, complex128, complex, longcomplex` | 默认为 `complex128` ,即实部虚部都为双精度 |
|
||||
| 字符串 | `string, unicode` | 可以使用 `dtype=S4` 表示一个4字节字符串的数组 |
|
||||
| 对象 | `object` | 数组中可以使用任意值 |
|
||||
| Records | `void` | |
|
||||
| 时间 | `datetime64, timedelta64` |
|
||||
|
||||
任意类型的数组:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a = array([1,1.2,'hello', [10,20,30]],
|
||||
dtype=object)
|
||||
|
||||
```
|
||||
|
||||
乘法:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
a * 2
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
array([2, 2.4, 'hellohello', [10, 20, 30, 10, 20, 30]], dtype=object)
|
||||
```
|
||||
|
||||
## 类型转换
|
||||
|
||||
转换数组的类型:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
a = array([1.5, -3],
|
||||
dtype=float32)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
array([ 1.5, -3\. ], dtype=float32)
|
||||
```
|
||||
|
||||
### asarray 函数
|
||||
|
||||
使用 `asarray` 函数:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
asarray(a, dtype=float64)
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
array([ 1.5, -3\. ])
|
||||
```
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
asarray(a, dtype=uint8)
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
array([ 1, 253], dtype=uint8)
|
||||
```
|
||||
|
||||
`asarray` 不会修改原来数组的值:
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
array([ 1.5, -3\. ], dtype=float32)
|
||||
```
|
||||
|
||||
但当类型相同的时候,`asarray` 并不会产生新的对象,而是使用同一个引用:
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
b = asarray(a, dtype=float32)
|
||||
|
||||
```
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
b is a
|
||||
|
||||
```
|
||||
|
||||
Out[33]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
这么做的好处在与,`asarray` 不仅可以作用于数组,还可以将其他类型转化为数组。
|
||||
|
||||
有些时候为了保证我们的输入值是数组,我们需要将其使用 `asarray` 转化,当它已经是数组的时候,并不会产生新的对象,这样保证了效率。
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
asarray([1,2,3,4])
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
array([1, 2, 3, 4])
|
||||
```
|
||||
|
||||
### astype 方法
|
||||
|
||||
`astype` 方法返回一个新数组:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
a.astype(float64)
|
||||
|
||||
```
|
||||
|
||||
Out[35]:
|
||||
|
||||
```py
|
||||
array([ 1.5, -3\. ])
|
||||
```
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
a.astype(uint8)
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
array([ 1, 253], dtype=uint8)
|
||||
```
|
||||
|
||||
astype也不会改变原来数组的值:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
array([ 1.5, -3\. ], dtype=float32)
|
||||
```
|
||||
|
||||
另外,`astype` 总是返回原来数组的一份复制,即使转换的类型是相同的:
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
b = a.astype(float32)
|
||||
print a
|
||||
print b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[ 1.5 -3\. ]
|
||||
[ 1.5 -3\. ]
|
||||
|
||||
```
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
a is b
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
### view 方法
|
||||
|
||||
In [40]:
|
||||
|
||||
```py
|
||||
a = array((1,2,3,4), dtype=int32)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[40]:
|
||||
|
||||
```py
|
||||
array([1, 2, 3, 4])
|
||||
```
|
||||
|
||||
`view` 会将 `a` 在内存中的表示看成是 `uint8` 进行解析:
|
||||
|
||||
In [41]:
|
||||
|
||||
```py
|
||||
b = a.view(uint8)
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[41]:
|
||||
|
||||
```py
|
||||
array([1, 0, 0, 0, 2, 0, 0, 0, 3, 0, 0, 0, 4, 0, 0, 0], dtype=uint8)
|
||||
```
|
||||
|
||||
In [42]:
|
||||
|
||||
```py
|
||||
a[0] = 2**30
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[42]:
|
||||
|
||||
```py
|
||||
array([1073741824, 2, 3, 4])
|
||||
```
|
||||
|
||||
修改 `a` 会修改 `b` 的值,因为共用一块内存:
|
||||
|
||||
In [43]:
|
||||
|
||||
```py
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[43]:
|
||||
|
||||
```py
|
||||
array([ 0, 0, 0, 64, 2, 0, 0, 0, 3, 0, 0, 0, 4, 0, 0, 0], dtype=uint8)
|
||||
```
|
||||
|
|
@ -0,0 +1,518 @@
|
|||
# 数组方法
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
%pylab
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Using matplotlib backend: Qt4Agg
|
||||
Populating the interactive namespace from numpy and matplotlib
|
||||
|
||||
```
|
||||
|
||||
## 求和
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = array([[1,2,3],
|
||||
[4,5,6]])
|
||||
|
||||
```
|
||||
|
||||
求所有元素的和:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
sum(a)
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
21
|
||||
```
|
||||
|
||||
指定求和的维度:
|
||||
|
||||
沿着第一维求和:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
sum(a, axis=0)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([5, 7, 9])
|
||||
```
|
||||
|
||||
沿着第二维求和:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
sum(a, axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([ 6, 15])
|
||||
```
|
||||
|
||||
沿着最后一维求和:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
sum(a, axis=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([ 6, 15])
|
||||
```
|
||||
|
||||
或者使用 `sum` 方法:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a.sum()
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
21
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a.sum(axis=0)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
array([5, 7, 9])
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a.sum(axis=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([ 6, 15])
|
||||
```
|
||||
|
||||
## 求积
|
||||
|
||||
求所有元素的乘积:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a.prod()
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
720
|
||||
```
|
||||
|
||||
或者使用函数形式:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
prod(a, axis=0)
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([ 4, 10, 18])
|
||||
```
|
||||
|
||||
## 求最大最小值
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
from numpy.random import rand
|
||||
a = rand(3, 4)
|
||||
%precision 3
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([[ 0.444, 0.06 , 0.668, 0.02 ],
|
||||
[ 0.793, 0.302, 0.81 , 0.381],
|
||||
[ 0.296, 0.182, 0.345, 0.686]])
|
||||
```
|
||||
|
||||
全局最小:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a.min()
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
0.020
|
||||
```
|
||||
|
||||
沿着某个轴的最小:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a.min(axis=0)
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
array([ 0.296, 0.06 , 0.345, 0.02 ])
|
||||
```
|
||||
|
||||
全局最大:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a.max()
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
0.810
|
||||
```
|
||||
|
||||
沿着某个轴的最大:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
a.max(axis=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
array([ 0.668, 0.81 , 0.686])
|
||||
```
|
||||
|
||||
## 最大最小值的位置
|
||||
|
||||
使用 `argmin, argmax` 方法:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a.argmin()
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
3
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
a.argmin(axis=0)
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
array([2, 0, 2, 0], dtype=int64)
|
||||
```
|
||||
|
||||
## 均值
|
||||
|
||||
可以使用 `mean` 方法:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a = array([[1,2,3],[4,5,6]])
|
||||
|
||||
```
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
a.mean()
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
3.500
|
||||
```
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
a.mean(axis=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
array([ 2., 5.])
|
||||
```
|
||||
|
||||
也可以使用 `mean` 函数:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
mean(a)
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
3.500
|
||||
```
|
||||
|
||||
还可以使用 `average` 函数:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
average(a, axis = 0)
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
array([ 2.5, 3.5, 4.5])
|
||||
```
|
||||
|
||||
`average` 函数还支持加权平均:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
average(a, axis = 0, weights=[1,2])
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
array([ 3., 4., 5.])
|
||||
```
|
||||
|
||||
## 标准差
|
||||
|
||||
用 `std` 方法计算标准差:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
a.std(axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
array([ 0.816, 0.816])
|
||||
```
|
||||
|
||||
用 `var` 方法计算方差:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a.var(axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
array([ 0.667, 0.667])
|
||||
```
|
||||
|
||||
或者使用函数:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
var(a, axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
array([ 0.667, 0.667])
|
||||
```
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
std(a, axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
array([ 0.816, 0.816])
|
||||
```
|
||||
|
||||
## clip 方法
|
||||
|
||||
将数值限制在某个范围:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
array([[1, 2, 3],
|
||||
[4, 5, 6]])
|
||||
```
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
a.clip(3,5)
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
array([[3, 3, 3],
|
||||
[4, 5, 5]])
|
||||
```
|
||||
|
||||
小于3的变成3,大于5的变成5。
|
||||
|
||||
## ptp 方法
|
||||
|
||||
计算最大值和最小值之差:
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
a.ptp(axis=1)
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
array([2, 2])
|
||||
```
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
a.ptp()
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
5
|
||||
```
|
||||
|
||||
## round 方法
|
||||
|
||||
近似,默认到整数:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
a = array([1.35, 2.5, 1.5])
|
||||
|
||||
```
|
||||
|
||||
这里,.5的近似规则为近似到偶数值,可以参考:
|
||||
|
||||
[https://en.wikipedia.org/wiki/Rounding#Round_half_to_odd](https://en.wikipedia.org/wiki/Rounding#Round_half_to_odd)
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
a.round()
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
array([ 1., 2., 2.])
|
||||
```
|
||||
|
||||
近似到一位小数:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
a.round(decimals=1)
|
||||
|
||||
```
|
||||
|
||||
Out[35]:
|
||||
|
||||
```py
|
||||
array([ 1.4, 2.5, 1.5])
|
||||
```
|
||||
|
|
@ -0,0 +1,308 @@
|
|||
# 数组排序
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
%pylab
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Using matplotlib backend: Qt4Agg
|
||||
Populating the interactive namespace from numpy and matplotlib
|
||||
|
||||
```
|
||||
|
||||
## sort 函数
|
||||
|
||||
先看这个例子:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
names = array(['bob', 'sue', 'jan', 'ad'])
|
||||
weights = array([20.8, 93.2, 53.4, 61.8])
|
||||
|
||||
sort(weights)
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([ 20.8, 53.4, 61.8, 93.2])
|
||||
```
|
||||
|
||||
`sort` 返回的结果是从小到大排列的。
|
||||
|
||||
## argsort 函数
|
||||
|
||||
`argsort` 返回从小到大的排列在数组中的索引位置:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
ordered_indices = argsort(weights)
|
||||
ordered_indices
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([0, 2, 3, 1], dtype=int64)
|
||||
```
|
||||
|
||||
可以用它来进行索引:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
weights[ordered_indices]
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([ 20.8, 53.4, 61.8, 93.2])
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
names[ordered_indices]
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array(['bob', 'jan', 'ad', 'sue'],
|
||||
dtype='|S3')
|
||||
```
|
||||
|
||||
使用函数并不会改变原来数组的值:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
weights
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([ 20.8, 93.2, 53.4, 61.8])
|
||||
```
|
||||
|
||||
## sort 和 argsort 方法
|
||||
|
||||
数组也支持方法操作:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
data = array([20.8, 93.2, 53.4, 61.8])
|
||||
data.argsort()
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([0, 2, 3, 1], dtype=int64)
|
||||
```
|
||||
|
||||
`argsort` 方法与 `argsort` 函数的使用没什么区别,也不会改变数组的值。
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
array([ 20.8, 93.2, 53.4, 61.8])
|
||||
```
|
||||
|
||||
但是 `sort`方法会改变数组的值:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
data.sort()
|
||||
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([ 20.8, 53.4, 61.8, 93.2])
|
||||
```
|
||||
|
||||
## 二维数组排序
|
||||
|
||||
对于多维数组,sort方法默认沿着最后一维开始排序:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a = array([
|
||||
[.2, .1, .5],
|
||||
[.4, .8, .3],
|
||||
[.9, .6, .7]
|
||||
])
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([[ 0.2, 0.1, 0.5],
|
||||
[ 0.4, 0.8, 0.3],
|
||||
[ 0.9, 0.6, 0.7]])
|
||||
```
|
||||
|
||||
对于二维数组,默认相当于对每一行进行排序:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
sort(a)
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([[ 0.1, 0.2, 0.5],
|
||||
[ 0.3, 0.4, 0.8],
|
||||
[ 0.6, 0.7, 0.9]])
|
||||
```
|
||||
|
||||
改变轴,对每一列进行排序:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
sort(a, axis = 0)
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
array([[ 0.2, 0.1, 0.3],
|
||||
[ 0.4, 0.6, 0.5],
|
||||
[ 0.9, 0.8, 0.7]])
|
||||
```
|
||||
|
||||
## searchsorted 函数
|
||||
|
||||
```py
|
||||
searchsorted(sorted_array, values)
|
||||
```
|
||||
|
||||
`searchsorted` 接受两个参数,其中,第一个必需是已排序的数组。
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
sorted_array = linspace(0,1,5)
|
||||
values = array([.1,.8,.3,.12,.5,.25])
|
||||
|
||||
```
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
searchsorted(sorted_array, values)
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
array([1, 4, 2, 1, 2, 1], dtype=int64)
|
||||
```
|
||||
|
||||
排序数组:
|
||||
|
||||
| 0 | 1 | 2 | 3 | 4 |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| 0.0 | 0.25 | 0.5 | 0.75 | 1.0 |
|
||||
|
||||
数值:
|
||||
|
||||
| 值 | 0.1 | 0.8 | 0.3 | 0.12 | 0.5 | 0.25 |
|
||||
| --- | --- | --- | --- | --- | --- | --- |
|
||||
| 插入位置 | 1 | 4 | 2 | 1 | 2 | 1 |
|
||||
|
||||
`searchsorted` 返回的值相当于保持第一个数组的排序性质不变,将第二个数组中的值插入第一个数组中的位置:
|
||||
|
||||
例如 `0.1` 在 [0.0, 0.25) 之间,所以插入时应当放在第一个数组的索引 `1` 处,故第一个返回值为 `1`。
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
from numpy.random import rand
|
||||
data = rand(100)
|
||||
data.sort()
|
||||
|
||||
```
|
||||
|
||||
不加括号,默认是元组:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
bounds = .4, .6
|
||||
bounds
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
(0.4, 0.6)
|
||||
```
|
||||
|
||||
返回这两个值对应的插入位置:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
low_idx, high_idx = searchsorted(data, bounds)
|
||||
|
||||
```
|
||||
|
||||
利用插入位置,将数组中所有在这两个值之间的值提取出来:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
data[low_idx:high_idx]
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
array([ 0.41122674, 0.4395727 , 0.45609773, 0.45707137, 0.45772076,
|
||||
0.46029997, 0.46757401, 0.47525517, 0.4969198 , 0.53068779,
|
||||
0.55764166, 0.56288568, 0.56506548, 0.57003042, 0.58035233,
|
||||
0.59279233, 0.59548555])
|
||||
```
|
||||
|
|
@ -0,0 +1,791 @@
|
|||
# 数组形状
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
%pylab
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Using matplotlib backend: Qt4Agg
|
||||
Populating the interactive namespace from numpy and matplotlib
|
||||
|
||||
```
|
||||
|
||||
## 修改数组的形状
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = arange(6)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([0, 1, 2, 3, 4, 5])
|
||||
```
|
||||
|
||||
将形状修改为2乘3:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.shape = 2,3
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([[0, 1, 2],
|
||||
[3, 4, 5]])
|
||||
```
|
||||
|
||||
与之对应的方法是 `reshape` ,但它不会修改原来数组的值,而是返回一个新的数组:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.reshape(3,2)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([[0, 1],
|
||||
[2, 3],
|
||||
[4, 5]])
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([[0, 1, 2],
|
||||
[3, 4, 5]])
|
||||
```
|
||||
|
||||
`shape` 和 `reshape` 方法不能改变数组中元素的总数,否则会报错:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a.reshape(4,2)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
ValueError Traceback (most recent call last)
|
||||
<ipython-input-6-1a35a76a1693> in <module>()
|
||||
----> 1 a.reshape(4,2)
|
||||
|
||||
ValueError: total size of new array must be unchanged
|
||||
```
|
||||
|
||||
## 使用 newaxis 增加数组维数
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = arange(3)
|
||||
shape(a)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
(3L,)
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
y = a[newaxis, :]
|
||||
shape(y)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
(1L, 3L)
|
||||
```
|
||||
|
||||
根据插入位置的不同,可以返回不同形状的数组:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
y = a[:, newaxis]
|
||||
shape(y)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
(3L, 1L)
|
||||
```
|
||||
|
||||
插入多个新维度:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
y = a[newaxis, newaxis, :]
|
||||
shape(y)
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
(1L, 1L, 3L)
|
||||
```
|
||||
|
||||
## squeeze 方法去除多余的轴
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a = arange(6)
|
||||
a.shape = (2,1,3)
|
||||
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
b = a.squeeze()
|
||||
b.shape
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
(2L, 3L)
|
||||
```
|
||||
|
||||
squeeze 返回一个将所有长度为1的维度去除的新数组。
|
||||
|
||||
## 数组转置
|
||||
|
||||
使用 `transpose` 返回数组的转置,本质上是将所有维度反过来:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
array([[[0, 1, 2]],
|
||||
|
||||
[[3, 4, 5]]])
|
||||
```
|
||||
|
||||
对于二维数组,这相当于交换行和列:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a.transpose()
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
array([[[0, 3]],
|
||||
|
||||
[[1, 4]],
|
||||
|
||||
[[2, 5]]])
|
||||
```
|
||||
|
||||
或者使用缩写属性:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a.T
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
array([[[0, 3]],
|
||||
|
||||
[[1, 4]],
|
||||
|
||||
[[2, 5]]])
|
||||
```
|
||||
|
||||
注意:
|
||||
|
||||
* 对于复数数组,转置并不返回复共轭,只是单纯的交换轴的位置
|
||||
* 转置可以作用于多维数组
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
a = arange(60)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
|
||||
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
|
||||
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
|
||||
51, 52, 53, 54, 55, 56, 57, 58, 59])
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a.shape = 3,4,5
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
array([[[ 0, 1, 2, 3, 4],
|
||||
[ 5, 6, 7, 8, 9],
|
||||
[10, 11, 12, 13, 14],
|
||||
[15, 16, 17, 18, 19]],
|
||||
|
||||
[[20, 21, 22, 23, 24],
|
||||
[25, 26, 27, 28, 29],
|
||||
[30, 31, 32, 33, 34],
|
||||
[35, 36, 37, 38, 39]],
|
||||
|
||||
[[40, 41, 42, 43, 44],
|
||||
[45, 46, 47, 48, 49],
|
||||
[50, 51, 52, 53, 54],
|
||||
[55, 56, 57, 58, 59]]])
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
b = a.T
|
||||
b.shape
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
(5L, 4L, 3L)
|
||||
```
|
||||
|
||||
转置只是交换了轴的位置。
|
||||
|
||||
另一方面,转置返回的是对原数组的另一种view,所以改变转置会改变原来数组的值。
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a = arange(6)
|
||||
a.shape = (2,3)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
array([[0, 1, 2],
|
||||
[3, 4, 5]])
|
||||
```
|
||||
|
||||
修改转置:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
b = a.T
|
||||
b[0,1] = 30
|
||||
|
||||
```
|
||||
|
||||
原数组的值也改变:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
array([[ 0, 1, 2],
|
||||
[30, 4, 5]])
|
||||
```
|
||||
|
||||
## 数组连接
|
||||
|
||||
有时我们需要将不同的数组按照一定的顺序连接起来:
|
||||
|
||||
```py
|
||||
concatenate((a0,a1,...,aN), axis=0)
|
||||
```
|
||||
|
||||
注意,这些数组要用 `()` 包括到一个元组中去。
|
||||
|
||||
除了给定的轴外,这些数组其他轴的长度必须是一样的。
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
x = array([
|
||||
[0,1,2],
|
||||
[10,11,12]
|
||||
])
|
||||
y = array([
|
||||
[50,51,52],
|
||||
[60,61,62]
|
||||
])
|
||||
print x.shape
|
||||
print y.shape
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(2L, 3L)
|
||||
(2L, 3L)
|
||||
|
||||
```
|
||||
|
||||
默认沿着第一维进行连接:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
z = concatenate((x,y))
|
||||
z
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
array([[ 0, 1, 2],
|
||||
[10, 11, 12],
|
||||
[50, 51, 52],
|
||||
[60, 61, 62]])
|
||||
```
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
z.shape
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
(4L, 3L)
|
||||
```
|
||||
|
||||
沿着第二维进行连接:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
z = concatenate((x,y), axis=1)
|
||||
z
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
array([[ 0, 1, 2, 50, 51, 52],
|
||||
[10, 11, 12, 60, 61, 62]])
|
||||
```
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
z.shape
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
(2L, 6L)
|
||||
```
|
||||
|
||||
注意到这里 `x` 和 `y` 的形状是一样的,还可以将它们连接成三维的数组,但是 `concatenate` 不能提供这样的功能,不过可以这样:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
z = array((x,y))
|
||||
|
||||
```
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
z.shape
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
(2L, 2L, 3L)
|
||||
```
|
||||
|
||||
事实上,**Numpy**提供了分别对应这三种情况的函数:
|
||||
|
||||
* vstack
|
||||
* hstack
|
||||
* dstack
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
vstack((x, y)).shape
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
(4L, 3L)
|
||||
```
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
hstack((x, y)).shape
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
(2L, 6L)
|
||||
```
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
dstack((x, y)).shape
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
(2L, 3L, 2L)
|
||||
```
|
||||
|
||||
## Flatten 数组
|
||||
|
||||
`flatten` 方法的作用是将多维数组转化为1维数组:
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
a = array([[0,1],
|
||||
[2,3]])
|
||||
b = a.flatten()
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
array([0, 1, 2, 3])
|
||||
```
|
||||
|
||||
返回的是数组的复制,因此,改变 `b` 并不会影响 `a` 的值:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
b[0] = 10
|
||||
print b
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[10 1 2 3]
|
||||
[[0 1]
|
||||
[2 3]]
|
||||
|
||||
```
|
||||
|
||||
## flat 属性
|
||||
|
||||
还可以使用数组自带的 `flat` 属性:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
a.flat
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
<numpy.flatiter at 0x3d546a0>
|
||||
```
|
||||
|
||||
`a.flat` 相当于返回了所有元组组成的一个迭代器:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
b = a.flat
|
||||
|
||||
```
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
b[0]
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
0
|
||||
```
|
||||
|
||||
但此时修改 `b` 的值会影响 `a` :
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
b[0] = 10
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[[10 1]
|
||||
[ 2 3]]
|
||||
|
||||
```
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
a.flat[:]
|
||||
|
||||
```
|
||||
|
||||
Out[38]:
|
||||
|
||||
```py
|
||||
array([10, 1, 2, 3])
|
||||
```
|
||||
|
||||
## ravel 方法
|
||||
|
||||
除此之外,还可以使用 `ravel` 方法,`ravel` 使用高效的表示方式:
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
a = array([[0,1],
|
||||
[2,3]])
|
||||
b = a.ravel()
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
array([0, 1, 2, 3])
|
||||
```
|
||||
|
||||
修改 `b` 会改变 `a` :
|
||||
|
||||
In [40]:
|
||||
|
||||
```py
|
||||
b[0] = 10
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[40]:
|
||||
|
||||
```py
|
||||
array([[10, 1],
|
||||
[ 2, 3]])
|
||||
```
|
||||
|
||||
但另一种情况下:
|
||||
|
||||
In [41]:
|
||||
|
||||
```py
|
||||
a = array([[0,1],
|
||||
[2,3]])
|
||||
aa = a.transpose()
|
||||
b = aa.ravel()
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[41]:
|
||||
|
||||
```py
|
||||
array([0, 2, 1, 3])
|
||||
```
|
||||
|
||||
In [42]:
|
||||
|
||||
```py
|
||||
b[0] = 10
|
||||
|
||||
```
|
||||
|
||||
In [43]:
|
||||
|
||||
```py
|
||||
aa
|
||||
|
||||
```
|
||||
|
||||
Out[43]:
|
||||
|
||||
```py
|
||||
array([[0, 2],
|
||||
[1, 3]])
|
||||
```
|
||||
|
||||
In [44]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[44]:
|
||||
|
||||
```py
|
||||
array([[0, 1],
|
||||
[2, 3]])
|
||||
```
|
||||
|
||||
可以看到,在这种情况下,修改 `b` 并不会改变 `aa` 的值,原因是我们用来 `ravel` 的对象 `aa` 本身是 `a` 的一个view。
|
||||
|
||||
## atleast_xd 函数
|
||||
|
||||
保证数组至少有 `x` 维:
|
||||
|
||||
In [45]:
|
||||
|
||||
```py
|
||||
x = 1
|
||||
atleast_1d(x)
|
||||
|
||||
```
|
||||
|
||||
Out[45]:
|
||||
|
||||
```py
|
||||
array([1])
|
||||
```
|
||||
|
||||
In [46]:
|
||||
|
||||
```py
|
||||
a = array([1,2,3])
|
||||
b = atleast_2d(a)
|
||||
b.shape
|
||||
|
||||
```
|
||||
|
||||
Out[46]:
|
||||
|
||||
```py
|
||||
(1L, 3L)
|
||||
```
|
||||
|
||||
In [47]:
|
||||
|
||||
```py
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[47]:
|
||||
|
||||
```py
|
||||
array([[1, 2, 3]])
|
||||
```
|
||||
|
||||
In [48]:
|
||||
|
||||
```py
|
||||
c = atleast_3d(b)
|
||||
|
||||
```
|
||||
|
||||
In [49]:
|
||||
|
||||
```py
|
||||
c.shape
|
||||
|
||||
```
|
||||
|
||||
Out[49]:
|
||||
|
||||
```py
|
||||
(1L, 3L, 1L)
|
||||
```
|
||||
|
||||
`x` 可以取值 1,2,3。
|
||||
|
||||
在**Scipy**库中,这些函数被用来保证输入满足一定的条件:“
|
||||
|
||||
| 用法 | **Scipy**中出现次数 |
|
||||
| --- | --- |
|
||||
| value.flaten()
|
||||
value.flat
|
||||
value.ravel() | ~2000次 |
|
||||
| atleast_1d(value)
|
||||
atleast_2d(value) | ~700次 |
|
||||
| asarray(value) | ~4000次 |
|
||||
|
|
@ -0,0 +1,141 @@
|
|||
# 对角线
|
||||
|
||||
这里,使用与之前不同的导入方法:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
使用numpy中的函数前,需要加上 `np.`:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = np.array([11,21,31,12,22,32,13,23,33])
|
||||
a.shape = 3,3
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([[11, 21, 31],
|
||||
[12, 22, 32],
|
||||
[13, 23, 33]])
|
||||
```
|
||||
|
||||
查看它的对角线元素:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.diagonal()
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([11, 22, 33])
|
||||
```
|
||||
|
||||
可以使用偏移来查看它的次对角线,正数表示右移,负数表示左移:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.diagonal(offset=1)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([21, 32])
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a.diagonal(offset=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([12, 23])
|
||||
```
|
||||
|
||||
可以使用花式索引来得到对角线:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
i = [0,1,2]
|
||||
a[i, i]
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([11, 22, 33])
|
||||
```
|
||||
|
||||
可以更新对角线的值:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a[i, i] = 2
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([[ 2, 21, 31],
|
||||
[12, 2, 32],
|
||||
[13, 23, 2]])
|
||||
```
|
||||
|
||||
修改次对角线的值:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
i = np.array([0,1])
|
||||
a[i, i + 1] = 1
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
array([[ 2, 1, 31],
|
||||
[12, 2, 1],
|
||||
[13, 23, 2]])
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a[i + 1, i] = -1
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([[ 2, 1, 31],
|
||||
[-1, 2, 1],
|
||||
[13, -1, 2]])
|
||||
```
|
||||
|
|
@ -0,0 +1,100 @@
|
|||
# 数组与字符串的转换
|
||||
|
||||
## tostring 方法
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = np.array([[1,2],
|
||||
[3,4]],
|
||||
dtype = np.uint8)
|
||||
|
||||
```
|
||||
|
||||
转化为字符串:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.tostring()
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
'\x01\x02\x03\x04'
|
||||
```
|
||||
|
||||
我们可以使用不同的顺序来转换字符串:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.tostring(order='F')
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
'\x01\x03\x02\x04'
|
||||
```
|
||||
|
||||
这里使用了**Fortran**的格式,按照列来读数据。
|
||||
|
||||
## fromstring 函数
|
||||
|
||||
可以使用 `fromstring` 函数从字符串中读出数据,不过要指定类型:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
s = a.tostring()
|
||||
a = np.fromstring(s,
|
||||
dtype=np.uint8)
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([1, 2, 3, 4], dtype=uint8)
|
||||
```
|
||||
|
||||
此时,返回的数组是一维的,需要重新设定维度:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a.shape = 2,2
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([[1, 2],
|
||||
[3, 4]], dtype=uint8)
|
||||
```
|
||||
|
||||
对于文本文件,推荐使用
|
||||
|
||||
* `loadtxt`
|
||||
* `genfromtxt`
|
||||
* `savetxt`
|
||||
|
||||
对于二进制文本文件,推荐使用
|
||||
|
||||
* `save`
|
||||
* `load`
|
||||
* `savez`
|
||||
|
|
@ -0,0 +1,936 @@
|
|||
# 数组属性方法总结
|
||||
|
||||
| | 作用 |
|
||||
| --- | --- |
|
||||
| 1 | **基本属性** |
|
||||
| `a.dtype` | 数组元素类型 `float32,uint8,...` |
|
||||
| `a.shape` | 数组形状 `(m,n,o,...)` |
|
||||
| `a.size` | 数组元素数 |
|
||||
| `a.itemsize` | 每个元素占字节数 |
|
||||
| `a.nbytes` | 所有元素占的字节 |
|
||||
| `a.ndim` | 数组维度 |
|
||||
| 2 | **形状相关** |
|
||||
| `a.flat` | 所有元素的迭代器 |
|
||||
| `a.flatten()` | 返回一个1维数组的复制 |
|
||||
| `a.ravel()` | 返回一个1维数组,高效 |
|
||||
| `a.resize(new_size)` | 改变形状 |
|
||||
| `a.swapaxes(axis1, axis2)` | 交换两个维度的位置 |
|
||||
| `a.transpose(*axex)` | 交换所有维度的位置 |
|
||||
| `a.T` | 转置,`a.transpose()` |
|
||||
| `a.squeeze()` | 去除所有长度为1的维度 |
|
||||
| 3 | **填充复制** |
|
||||
| `a.copy()` | 返回数组的一个复制 |
|
||||
| `a.fill(value)` | 将数组的元组设置为特定值 |
|
||||
| 4 | **转化** |
|
||||
| `a.tolist()` | 将数组转化为列表 |
|
||||
| `a.tostring()` | 转换为字符串 |
|
||||
| `a.astype(dtype)` | 转化为指定类型 |
|
||||
| `a.byteswap(False)` | 转换大小字节序 |
|
||||
| `a.view(type_or_dtype)` | 生成一个使用相同内存,但使用不同的表示方法的数组 |
|
||||
| 5 | **复数** |
|
||||
| `a.imag` | 虚部 |
|
||||
| `a.real` | 实部 |
|
||||
| `a.conjugate()` | 复共轭 |
|
||||
| `a.conj()` | 复共轭(缩写) |
|
||||
| 6 | **保存** |
|
||||
| `a.dump(file)` | 将二进制数据存在file中 |
|
||||
| `a.dump()` | 将二进制数据表示成字符串 |
|
||||
| `a.tofile(fid, sep="",format="%s")` | 格式化ASCⅡ码写入文件 |
|
||||
| 7 | **查找排序** |
|
||||
| `a.nonzero()` | 返回所有非零元素的索引 |
|
||||
| `a.sort(axis=-1)` | 沿某个轴排序 |
|
||||
| `a.argsort(axis=-1)` | 沿某个轴,返回按排序的索引 |
|
||||
| `a.searchsorted(b)` | 返回将b中元素插入a后能保持有序的索引值 |
|
||||
| 8 | **元素数学操作** |
|
||||
| `a.clip(low, high)` | 将数值限制在一定范围内 |
|
||||
| `a.round(decimals=0)` | 近似到指定精度 |
|
||||
| `a.cumsum(axis=None)` | 累加和 |
|
||||
| `a.cumprod(axis=None)` | 累乘积 |
|
||||
| 9 | **约简操作** |
|
||||
| `a.sum(axis=None)` | 求和 |
|
||||
| `a.prod(axis=None)` | 求积 |
|
||||
| `a.min(axis=None)` | 最小值 |
|
||||
| `a.max(axis=None)` | 最大值 |
|
||||
| `a.argmin(axis=None)` | 最小值索引 |
|
||||
| `a.argmax(axis=None)` | 最大值索引 |
|
||||
| `a.ptp(axis=None)` | 最大值减最小值 |
|
||||
| `a.mean(axis=None)` | 平均值 |
|
||||
| `a.std(axis=None)` | 标准差 |
|
||||
| `a.var(axis=None)` | 方差 |
|
||||
| `a.any(axis=None)` | 只要有一个不为0,返回真,逻辑或 |
|
||||
| `a.all(axis=None)` | 所有都不为0,返回真,逻辑与 |
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
from numpy import *
|
||||
|
||||
```
|
||||
|
||||
## 基本属性
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = array([[0, 1, 2, 3], [4, 5, 6, 7]])
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([[0, 1, 2, 3],
|
||||
[4, 5, 6, 7]])
|
||||
```
|
||||
|
||||
数组元素属性:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.dtype
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
dtype('int32')
|
||||
```
|
||||
|
||||
形状:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a.shape
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
(2L, 4L)
|
||||
```
|
||||
|
||||
元素数目:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a.size
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
8
|
||||
```
|
||||
|
||||
元素占字节大小:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a.itemsize
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
4
|
||||
```
|
||||
|
||||
所有元素所占字节:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a.nbytes
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
32
|
||||
```
|
||||
|
||||
数据维度:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a.ndim
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
2
|
||||
```
|
||||
|
||||
## 形状相关
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
for row in a:
|
||||
print row
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[0 1 2 3]
|
||||
[4 5 6 7]
|
||||
|
||||
```
|
||||
|
||||
所有元素的迭代器:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
for elt in a.flat:
|
||||
print elt
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
0
|
||||
1
|
||||
2
|
||||
3
|
||||
4
|
||||
5
|
||||
6
|
||||
7
|
||||
|
||||
```
|
||||
|
||||
所有元素组成的一维数组,按照行排列:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a.flatten()
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([0, 1, 2, 3, 4, 5, 6, 7])
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
a.ravel()
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([0, 1, 2, 3, 4, 5, 6, 7])
|
||||
```
|
||||
|
||||
重新改变形状:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
a.resize((4,2))
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
array([[0, 1],
|
||||
[2, 3],
|
||||
[4, 5],
|
||||
[6, 7]])
|
||||
```
|
||||
|
||||
交换这两个轴的顺序:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
a.swapaxes(0,1)
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
array([[0, 2, 4, 6],
|
||||
[1, 3, 5, 7]])
|
||||
```
|
||||
|
||||
转置:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a.transpose()
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
array([[0, 2, 4, 6],
|
||||
[1, 3, 5, 7]])
|
||||
```
|
||||
|
||||
转置:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
a.T
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
array([[0, 2, 4, 6],
|
||||
[1, 3, 5, 7]])
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
a2 = array([1,2,3])
|
||||
a2.shape
|
||||
|
||||
```
|
||||
|
||||
Out[17]:
|
||||
|
||||
```py
|
||||
(3L,)
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
a2.resize((1,3,1))
|
||||
a2.shape
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
(1L, 3L, 1L)
|
||||
```
|
||||
|
||||
去除长度为1的维度:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
a2 = a2.squeeze()
|
||||
a2.shape
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
(3L,)
|
||||
```
|
||||
|
||||
## 填充复制
|
||||
|
||||
复制:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
b = a.copy()
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
array([[0, 1],
|
||||
[2, 3],
|
||||
[4, 5],
|
||||
[6, 7]])
|
||||
```
|
||||
|
||||
复制不影响原来的数组:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
b[0][0] = -1
|
||||
b # First value changed
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
array([[-1, 1],
|
||||
[ 2, 3],
|
||||
[ 4, 5],
|
||||
[ 6, 7]])
|
||||
```
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
a # original not changed because b is a copy
|
||||
|
||||
```
|
||||
|
||||
Out[22]:
|
||||
|
||||
```py
|
||||
array([[0, 1],
|
||||
[2, 3],
|
||||
[4, 5],
|
||||
[6, 7]])
|
||||
```
|
||||
|
||||
填充:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
b.fill(4)
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[23]:
|
||||
|
||||
```py
|
||||
array([[4, 4],
|
||||
[4, 4],
|
||||
[4, 4],
|
||||
[4, 4]])
|
||||
```
|
||||
|
||||
## 转化
|
||||
|
||||
转化为列表:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
a.tolist()
|
||||
|
||||
```
|
||||
|
||||
Out[24]:
|
||||
|
||||
```py
|
||||
[[0, 1], [2, 3], [4, 5], [6, 7]]
|
||||
```
|
||||
|
||||
转化为字符串:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
a.tostring()
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
'\x00\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04\x00\x00\x00\x05\x00\x00\x00\x06\x00\x00\x00\x07\x00\x00\x00'
|
||||
```
|
||||
|
||||
改变数组元素类型:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
a.astype(float)
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
array([[ 0., 1.],
|
||||
[ 2., 3.],
|
||||
[ 4., 5.],
|
||||
[ 6., 7.]])
|
||||
```
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
b = a.copy()
|
||||
b.byteswap(False)
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
array([[ 0, 16777216],
|
||||
[ 33554432, 50331648],
|
||||
[ 67108864, 83886080],
|
||||
[100663296, 117440512]])
|
||||
```
|
||||
|
||||
将它看成16位整数:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
a.view(dtype=int16)
|
||||
|
||||
```
|
||||
|
||||
Out[28]:
|
||||
|
||||
```py
|
||||
array([[0, 0, 1, 0],
|
||||
[2, 0, 3, 0],
|
||||
[4, 0, 5, 0],
|
||||
[6, 0, 7, 0]], dtype=int16)
|
||||
```
|
||||
|
||||
## 复数
|
||||
|
||||
实部:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
b = array([1+2j, 3+4j, 5+6j])
|
||||
b.real
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
array([ 1., 3., 5.])
|
||||
```
|
||||
|
||||
虚部:
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
b.imag
|
||||
|
||||
```
|
||||
|
||||
Out[30]:
|
||||
|
||||
```py
|
||||
array([ 2., 4., 6.])
|
||||
```
|
||||
|
||||
共轭:
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
b.conj()
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
array([ 1.-2.j, 3.-4.j, 5.-6.j])
|
||||
```
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
b.conjugate()
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
array([ 1.-2.j, 3.-4.j, 5.-6.j])
|
||||
```
|
||||
|
||||
## 保存
|
||||
|
||||
保存成文本:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
a.dump("file.txt")
|
||||
|
||||
```
|
||||
|
||||
字符串:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
a.dumps()
|
||||
|
||||
```
|
||||
|
||||
Out[34]:
|
||||
|
||||
```py
|
||||
'\x80\x02cnumpy.core.multiarray\n_reconstruct\nq\x01cnumpy\nndarray\nq\x02K\x00\x85U\x01b\x87Rq\x03(K\x01\x8a\x01\x04\x8a\x01\x02\x86cnumpy\ndtype\nq\x04U\x02i4K\x00K\x01\x87Rq\x05(K\x03U\x01<NNNJ\xff\xff\xff\xffJ\xff\xff\xff\xffK\x00tb\x89U \x00\x00\x00\x00\x01\x00\x00\x00\x02\x00\x00\x00\x03\x00\x00\x00\x04\x00\x00\x00\x05\x00\x00\x00\x06\x00\x00\x00\x07\x00\x00\x00tb.'
|
||||
```
|
||||
|
||||
写入文件:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
a.tofile('foo.csv', sep=',', format="%s")
|
||||
|
||||
```
|
||||
|
||||
## 查找排序
|
||||
|
||||
非零元素的索引:
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
a.nonzero()
|
||||
|
||||
```
|
||||
|
||||
Out[36]:
|
||||
|
||||
```py
|
||||
(array([0, 1, 1, 2, 2, 3, 3], dtype=int64),
|
||||
array([1, 0, 1, 0, 1, 0, 1], dtype=int64))
|
||||
```
|
||||
|
||||
排序:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
b = array([3,2,7,4,1])
|
||||
b.sort()
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
array([1, 2, 3, 4, 7])
|
||||
```
|
||||
|
||||
排序的索引位置:
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
b = array([2,3,1])
|
||||
b.argsort(axis=-1)
|
||||
|
||||
```
|
||||
|
||||
Out[38]:
|
||||
|
||||
```py
|
||||
array([2, 0, 1], dtype=int64)
|
||||
```
|
||||
|
||||
将 `b` 插入 `a` 中的索引,使得 `a` 保持有序:
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
a = array([1,3,4,6])
|
||||
b = array([0,2,5])
|
||||
a.searchsorted(b)
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
array([0, 1, 3], dtype=int64)
|
||||
```
|
||||
|
||||
## 元素数学操作
|
||||
|
||||
限制在一定范围:
|
||||
|
||||
In [40]:
|
||||
|
||||
```py
|
||||
a = array([[4,1,3],[2,1,5]])
|
||||
a.clip(0,2)
|
||||
|
||||
```
|
||||
|
||||
Out[40]:
|
||||
|
||||
```py
|
||||
array([[2, 1, 2],
|
||||
[2, 1, 2]])
|
||||
```
|
||||
|
||||
近似:
|
||||
|
||||
In [41]:
|
||||
|
||||
```py
|
||||
a = array([1.344, 2.449, 2.558])
|
||||
a.round(decimals=2)
|
||||
|
||||
```
|
||||
|
||||
Out[41]:
|
||||
|
||||
```py
|
||||
array([ 1.34, 2.45, 2.56])
|
||||
```
|
||||
|
||||
累加和:
|
||||
|
||||
In [42]:
|
||||
|
||||
```py
|
||||
a = array([[4,1,3],[2,1,5]])
|
||||
a.cumsum(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[42]:
|
||||
|
||||
```py
|
||||
array([ 4, 5, 8, 10, 11, 16])
|
||||
```
|
||||
|
||||
累乘积:
|
||||
|
||||
In [43]:
|
||||
|
||||
```py
|
||||
a.cumprod(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[43]:
|
||||
|
||||
```py
|
||||
array([ 4, 4, 12, 24, 24, 120])
|
||||
```
|
||||
|
||||
## 约简操作
|
||||
|
||||
求和:
|
||||
|
||||
In [44]:
|
||||
|
||||
```py
|
||||
a = array([[4,1,3],[2,1,5]])
|
||||
a.sum(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[44]:
|
||||
|
||||
```py
|
||||
16
|
||||
```
|
||||
|
||||
求积:
|
||||
|
||||
In [45]:
|
||||
|
||||
```py
|
||||
a.prod(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[45]:
|
||||
|
||||
```py
|
||||
120
|
||||
```
|
||||
|
||||
最小值:
|
||||
|
||||
In [46]:
|
||||
|
||||
```py
|
||||
a.min(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[46]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
最大值:
|
||||
|
||||
In [47]:
|
||||
|
||||
```py
|
||||
a.max(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[47]:
|
||||
|
||||
```py
|
||||
5
|
||||
```
|
||||
|
||||
最小值索引:
|
||||
|
||||
In [48]:
|
||||
|
||||
```py
|
||||
a.argmin(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[48]:
|
||||
|
||||
```py
|
||||
1
|
||||
```
|
||||
|
||||
最大值索引:
|
||||
|
||||
In [49]:
|
||||
|
||||
```py
|
||||
a.argmax(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[49]:
|
||||
|
||||
```py
|
||||
5
|
||||
```
|
||||
|
||||
最大间隔:
|
||||
|
||||
In [50]:
|
||||
|
||||
```py
|
||||
a.ptp(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[50]:
|
||||
|
||||
```py
|
||||
4
|
||||
```
|
||||
|
||||
均值:
|
||||
|
||||
In [51]:
|
||||
|
||||
```py
|
||||
a.mean(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[51]:
|
||||
|
||||
```py
|
||||
2.6666666666666665
|
||||
```
|
||||
|
||||
标准差:
|
||||
|
||||
In [52]:
|
||||
|
||||
```py
|
||||
a.std(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[52]:
|
||||
|
||||
```py
|
||||
1.49071198499986
|
||||
```
|
||||
|
||||
方差:
|
||||
|
||||
In [53]:
|
||||
|
||||
```py
|
||||
a.var(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[53]:
|
||||
|
||||
```py
|
||||
2.2222222222222228
|
||||
```
|
||||
|
||||
是否有非零元素:
|
||||
|
||||
In [54]:
|
||||
|
||||
```py
|
||||
a.any(axis=None)
|
||||
|
||||
```
|
||||
|
||||
Out[54]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
是否全部非零:
|
||||
|
||||
In [55]:
|
||||
|
||||
```py
|
||||
a.all()
|
||||
|
||||
```
|
||||
|
||||
Out[55]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
删除生成的文件:
|
||||
|
||||
In [56]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('foo.csv')
|
||||
os.remove('file.txt')
|
||||
|
||||
```
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,129 @@
|
|||
# 矩阵
|
||||
|
||||
使用 `mat` 方法将 `2` 维数组转化为矩阵:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
a = np.array([[1,2,4],
|
||||
[2,5,3],
|
||||
[7,8,9]])
|
||||
A = np.mat(a)
|
||||
A
|
||||
|
||||
```
|
||||
|
||||
Out[1]:
|
||||
|
||||
```py
|
||||
matrix([[1, 2, 4],
|
||||
[2, 5, 3],
|
||||
[7, 8, 9]])
|
||||
```
|
||||
|
||||
也可以使用 **Matlab** 的语法传入一个字符串来生成矩阵:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
A = np.mat('1,2,4;2,5,3;7,8,9')
|
||||
A
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
matrix([[1, 2, 4],
|
||||
[2, 5, 3],
|
||||
[7, 8, 9]])
|
||||
```
|
||||
|
||||
利用分块创造新的矩阵:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a = np.array([[ 1, 2],
|
||||
[ 3, 4]])
|
||||
b = np.array([[10,20],
|
||||
[30,40]])
|
||||
|
||||
np.bmat('a,b;b,a')
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
matrix([[ 1, 2, 10, 20],
|
||||
[ 3, 4, 30, 40],
|
||||
[10, 20, 1, 2],
|
||||
[30, 40, 3, 4]])
|
||||
```
|
||||
|
||||
矩阵与向量的乘法:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
x = np.array([[1], [2], [3]])
|
||||
x
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([[1],
|
||||
[2],
|
||||
[3]])
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
A * x
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
matrix([[17],
|
||||
[21],
|
||||
[50]])
|
||||
```
|
||||
|
||||
`A.I` 表示 `A` 矩阵的逆矩阵:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
print A * A.I
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[[ 1.00000000e+00 0.00000000e+00 0.00000000e+00]
|
||||
[ 0.00000000e+00 1.00000000e+00 2.08166817e-17]
|
||||
[ 2.22044605e-16 -8.32667268e-17 1.00000000e+00]]
|
||||
|
||||
```
|
||||
|
||||
矩阵指数表示矩阵连乘:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print A ** 4
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[[ 6497 9580 9836]
|
||||
[ 7138 10561 10818]
|
||||
[18434 27220 27945]]
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,323 @@
|
|||
# 一般函数
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
## 三角函数
|
||||
|
||||
```py
|
||||
sin(x)
|
||||
cos(x)
|
||||
tan(x)
|
||||
sinh(x)
|
||||
conh(x)
|
||||
tanh(x)
|
||||
arccos(x)
|
||||
arctan(x)
|
||||
arcsin(x)
|
||||
arccosh(x)
|
||||
arctanh(x)
|
||||
arcsinh(x)
|
||||
arctan2(x,y)
|
||||
```
|
||||
|
||||
`arctan2(x,y)` 返回 `arctan(x/y)` 。
|
||||
|
||||
## 向量操作
|
||||
|
||||
```py
|
||||
dot(x,y)
|
||||
inner(x,y)
|
||||
cross(x,y)
|
||||
vdot(x,y)
|
||||
outer(x,y)
|
||||
kron(x,y)
|
||||
tensordot(x,y[,axis])
|
||||
```
|
||||
|
||||
## 其他操作
|
||||
|
||||
```py
|
||||
exp(x)
|
||||
log(x)
|
||||
log10(x)
|
||||
sqrt(x)
|
||||
absolute(x)
|
||||
conjugate(x)
|
||||
negative(x)
|
||||
ceil(x)
|
||||
floor(x)
|
||||
fabs(x)
|
||||
hypot(x)
|
||||
fmod(x)
|
||||
maximum(x,y)
|
||||
minimum(x,y)
|
||||
```
|
||||
|
||||
`hypot` 返回对应点 `(x,y)` 到原点的距离。
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
x = np.array([1,2,3])
|
||||
y = np.array([4,5,6])
|
||||
np.hypot(x,y)
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([ 4.12310563, 5.38516481, 6.70820393])
|
||||
```
|
||||
|
||||
## 类型处理
|
||||
|
||||
```py
|
||||
iscomplexobj
|
||||
iscomplex
|
||||
isrealobj
|
||||
isreal
|
||||
imag
|
||||
real
|
||||
real_if_close
|
||||
isscalar
|
||||
isneginf
|
||||
isposinf
|
||||
isinf
|
||||
isfinite
|
||||
isnan
|
||||
nan_to_num
|
||||
common_type
|
||||
typename
|
||||
```
|
||||
|
||||
正无穷:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
np.inf
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
inf
|
||||
```
|
||||
|
||||
负无穷:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
-np.inf
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
-inf
|
||||
```
|
||||
|
||||
非法值(Not a number):
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
np.nan
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
nan
|
||||
```
|
||||
|
||||
检查是否为无穷:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
np.isinf(1.0)
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
np.isinf(np.inf)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
np.isinf(-np.inf)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
非法值:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
np.array([0]) / 0.0
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
c:\Miniconda\lib\site-packages\IPython\kernel\__main__.py:1: RuntimeWarning: invalid value encountered in divide
|
||||
if __name__ == '__main__':
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([ nan])
|
||||
```
|
||||
|
||||
这并不会报错,而是返回一个非法值。
|
||||
|
||||
只有 `0/0` 会得到 `nan`,非0值除以0会得到无穷:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a = np.arange(5.0)
|
||||
b = a / 0.0
|
||||
b
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
c:\Miniconda\lib\site-packages\IPython\kernel\__main__.py:2: RuntimeWarning: divide by zero encountered in divide
|
||||
from IPython.kernel.zmq import kernelapp as app
|
||||
c:\Miniconda\lib\site-packages\IPython\kernel\__main__.py:2: RuntimeWarning: invalid value encountered in divide
|
||||
from IPython.kernel.zmq import kernelapp as app
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([ nan, inf, inf, inf, inf])
|
||||
```
|
||||
|
||||
`nan` 与任何数进行比较都是 `False`:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
b == np.nan
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([False, False, False, False, False], dtype=bool)
|
||||
```
|
||||
|
||||
想要找出 `nan` 值需要使用 `isnan`:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
np.isnan(b)
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([ True, False, False, False, False], dtype=bool)
|
||||
```
|
||||
|
||||
## 修改形状
|
||||
|
||||
```py
|
||||
atleast_1d
|
||||
atleast_2d
|
||||
atleast_3d
|
||||
expand_dims
|
||||
apply_over_axes
|
||||
apply_along_axis
|
||||
hstack
|
||||
vstack
|
||||
dstack
|
||||
column_stack
|
||||
hsplit
|
||||
vsplit
|
||||
dsplit
|
||||
split
|
||||
squeeze
|
||||
```
|
||||
|
||||
## 其他有用函数
|
||||
|
||||
```py
|
||||
fix
|
||||
mod
|
||||
amax
|
||||
amin
|
||||
ptp
|
||||
sum
|
||||
cumsum
|
||||
prod
|
||||
cumprod
|
||||
diff
|
||||
angle
|
||||
|
||||
unwrap
|
||||
sort_complex
|
||||
trim_zeros
|
||||
fliplr
|
||||
flipud
|
||||
rot90
|
||||
diag
|
||||
eye
|
||||
select
|
||||
extract
|
||||
insert
|
||||
|
||||
roots
|
||||
poly
|
||||
any
|
||||
all
|
||||
disp
|
||||
unique
|
||||
nansum
|
||||
nanmax
|
||||
nanargmax
|
||||
nanargmin
|
||||
nanmin
|
||||
```
|
||||
|
||||
`nan` 开头的函数会进行相应的操作,但是忽略 `nan` 值。
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,241 @@
|
|||
# 二元运算
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
## 四则运算
|
||||
|
||||
| 运算 | 函数 |
|
||||
| --- | --- |
|
||||
| `a + b` | `add(a,b)` |
|
||||
| `a - b` | `subtract(a,b)` |
|
||||
| `a * b` | `multiply(a,b)` |
|
||||
| `a / b` | `divide(a,b)` |
|
||||
| `a ** b` | `power(a,b)` |
|
||||
| `a % b` | `remainder(a,b)` |
|
||||
|
||||
以乘法为例,数组与标量相乘,相当于数组的每个元素乘以这个标量:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2])
|
||||
a * 3
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([3, 6])
|
||||
```
|
||||
|
||||
数组逐元素相乘:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2])
|
||||
b = np.array([3,4])
|
||||
a * b
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([3, 8])
|
||||
```
|
||||
|
||||
使用函数:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
np.multiply(a, b)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([3, 8])
|
||||
```
|
||||
|
||||
事实上,函数还可以接受第三个参数,表示将结果存入第三个参数中:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
np.multiply(a, b, a)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([3, 8])
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([3, 8])
|
||||
```
|
||||
|
||||
## 比较和逻辑运算
|
||||
|
||||
| 运算 | 函数< |
|
||||
| --- | --- |
|
||||
| `==` | `equal` |
|
||||
| `!=` | `not_equal` |
|
||||
| `>` | `greater` |
|
||||
| `>=` | `greater_equal` |
|
||||
| `<` | `less` |
|
||||
| `<=` | `less_equal` |
|
||||
| | `logical_and` |
|
||||
| | `logical_or` |
|
||||
| | `logical_xor` |
|
||||
| | `logical_not` |
|
||||
| `&` | `bitwise_and` |
|
||||
| | `bitwise_or` |
|
||||
| `^` | `bitwise_xor` |
|
||||
| `~` | `invert` |
|
||||
| `>>` | `right_shift` |
|
||||
| `<<` | `left_shift` |
|
||||
|
||||
等于操作也是逐元素比较的:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = np.array([[1,2,3,4],
|
||||
[2,3,4,5]])
|
||||
b = np.array([[1,2,5,4],
|
||||
[1,3,4,5]])
|
||||
a == b
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([[ True, True, False, True],
|
||||
[False, True, True, True]], dtype=bool)
|
||||
```
|
||||
|
||||
这意味着,如果我们在条件中要判断两个数组是否一样时,不能直接使用
|
||||
|
||||
```py
|
||||
if a == b:
|
||||
```
|
||||
|
||||
而要使用:
|
||||
|
||||
```py
|
||||
if all(a==b):
|
||||
```
|
||||
|
||||
对于浮点数,由于存在精度问题,使用函数 `allclose` 会更好:
|
||||
|
||||
```py
|
||||
if allclose(a,b):
|
||||
```
|
||||
|
||||
`logical_and` 也是逐元素的 `and` 操作:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a = np.array([0,1,2])
|
||||
b = np.array([0,10,0])
|
||||
|
||||
np.logical_and(a, b)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
array([False, True, False], dtype=bool)
|
||||
```
|
||||
|
||||
`0` 被认为是 `False`,非零则是 `True`。
|
||||
|
||||
比特操作:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2,4,8])
|
||||
b = np.array([16,32,64,128])
|
||||
|
||||
a | b
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([ 17, 34, 68, 136])
|
||||
```
|
||||
|
||||
取反:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2,3,4], np.uint8)
|
||||
~a
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([254, 253, 252, 251], dtype=uint8)
|
||||
```
|
||||
|
||||
左移:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a << 3
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([ 8, 16, 24, 32], dtype=uint8)
|
||||
```
|
||||
|
||||
要注意的是 `&` 的运算优先于比较运算如 `>` 等,所以必要时候需要加上括号:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2,4,8])
|
||||
b = np.array([16,32,64,128])
|
||||
|
||||
(a > 3) & (b < 100)
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([False, False, True, False], dtype=bool)
|
||||
```
|
||||
|
|
@ -0,0 +1,317 @@
|
|||
# ufunc 对象
|
||||
|
||||
**Numpy** 有两种基本对象:`ndarray (N-dimensional array object)` 和 `ufunc (universal function object)`。`ndarray` 是存储单一数据类型的多维数组,而 `ufunc` 则是能够对数组进行处理的函数。
|
||||
|
||||
例如,我们之前所接触到的二元操作符对应的 **Numpy** 函数,如 `add`,就是一种 `ufunc` 对象,它可以作用于数组的每个元素。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = np.array([0,1,2])
|
||||
b = np.array([2,3,4])
|
||||
|
||||
np.add(a, b)
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([2, 4, 6])
|
||||
```
|
||||
|
||||
查看支持的方法:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
dir(np.add)
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
['__call__',
|
||||
'__class__',
|
||||
'__delattr__',
|
||||
'__doc__',
|
||||
'__format__',
|
||||
'__getattribute__',
|
||||
'__hash__',
|
||||
'__init__',
|
||||
'__name__',
|
||||
'__new__',
|
||||
'__reduce__',
|
||||
'__reduce_ex__',
|
||||
'__repr__',
|
||||
'__setattr__',
|
||||
'__sizeof__',
|
||||
'__str__',
|
||||
'__subclasshook__',
|
||||
'accumulate',
|
||||
'at',
|
||||
'identity',
|
||||
'nargs',
|
||||
'nin',
|
||||
'nout',
|
||||
'ntypes',
|
||||
'outer',
|
||||
'reduce',
|
||||
'reduceat',
|
||||
'signature',
|
||||
'types']
|
||||
```
|
||||
|
||||
除此之外,大部分能够作用于数组的数学函数如三角函数等,都是 `ufunc` 对象。
|
||||
|
||||
特别地,对于二元操作符所对应的 `ufunc` 对象,支持以下方法:
|
||||
|
||||
## reduce 方法
|
||||
|
||||
```py
|
||||
op.reduce(a)
|
||||
```
|
||||
|
||||
将`op`沿着某个轴应用,使得数组 `a` 的维数降低一维。
|
||||
|
||||
add 作用到一维数组上相当于求和:
|
||||
|
||||
$$ \begin{align} y & = add.recuce(a) \\ & = a[0] + a[1] + ... + a[N-1] \\ & = \sum_{n=0}^{N-1} a[n] \end{align} $$In [4]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2,3,4])
|
||||
|
||||
np.add.reduce(a)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
10
|
||||
```
|
||||
|
||||
多维数组默认只按照第一维进行运算:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a = np.array([[1,2,3],[4,5,6]])
|
||||
|
||||
np.add.reduce(a)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([5, 7, 9])
|
||||
```
|
||||
|
||||
指定维度:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
np.add.reduce(a, 1)
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([ 6, 15])
|
||||
```
|
||||
|
||||
作用于字符串:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
a = np.array(['ab', 'cd', 'ef'], np.object)
|
||||
|
||||
np.add.reduce(a)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
'abcdef'
|
||||
```
|
||||
|
||||
逻辑运算:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
a = np.array([1,1,0,1])
|
||||
|
||||
np.logical_and.reduce(a)
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
np.logical_or.reduce(a)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
## accumulate 方法
|
||||
|
||||
```py
|
||||
op.accumulate(a)
|
||||
```
|
||||
|
||||
`accumulate` 可以看成保存 `reduce` 每一步的结果所形成的数组。
|
||||
|
||||
$$ \begin{align} y & = add.accumulate(a) \\ & = \left[\sum_{n=0}^{0} a[n], \sum_{n=0}^{1} a[n], ..., \sum_{n=0}^{N-1} a[n]\right] \end{align} $$
|
||||
|
||||
与之前类似:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
a = np.array([1,2,3,4])
|
||||
|
||||
np.add.accumulate(a)
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([ 1, 3, 6, 10])
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
a = np.array(['ab', 'cd', 'ef'], np.object)
|
||||
|
||||
np.add.accumulate(a)
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array(['ab', 'abcd', 'abcdef'], dtype=object)
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
a = np.array([1,1,0,1])
|
||||
|
||||
np.logical_and.accumulate(a)
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
array([ True, True, False, False], dtype=bool)
|
||||
```
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
np.logical_or.accumulate(a)
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
array([ True, True, True, True], dtype=bool)
|
||||
```
|
||||
|
||||
## reduceat 方法
|
||||
|
||||
```py
|
||||
op.reduceat(a, indices)
|
||||
```
|
||||
|
||||
`reduceat` 方法将操作符运用到指定的下标上,返回一个与 `indices` 大小相同的数组:
|
||||
|
||||
$$ \begin{align} y & = add.reduceat(a, indices) \\ & = \left[\sum_{n=indice[0]}^{indice[1]-1} a[n], \sum_{n=indice[1]}^{indice[2]-1} a[n], ..., \sum_{n=indice[-1]}^{N-1} a[n]\right] \end{align} $$In [14]:
|
||||
|
||||
```py
|
||||
a = np.array([0, 10, 20, 30, 40, 50])
|
||||
indices = np.array([1,4])
|
||||
|
||||
np.add.reduceat(a, indices)
|
||||
|
||||
```
|
||||
|
||||
Out[14]:
|
||||
|
||||
```py
|
||||
array([60, 90])
|
||||
```
|
||||
|
||||
这里,`indices` 为 `[1, 4]`,所以 `60` 表示从下标1(包括)加到下标4(不包括)的结果,`90` 表示从下标4(包括)加到结尾的结果。
|
||||
|
||||
## outer 方法
|
||||
|
||||
```py
|
||||
op.outer(a, b)
|
||||
```
|
||||
|
||||
对于 `a` 中每个元素,将 `op` 运用到它和 `b` 的每一个元素上所得到的结果:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
a = np.array([0,1])
|
||||
b = np.array([1,2,3])
|
||||
|
||||
np.add.outer(a, b)
|
||||
|
||||
```
|
||||
|
||||
Out[15]:
|
||||
|
||||
```py
|
||||
array([[1, 2, 3],
|
||||
[2, 3, 4]])
|
||||
```
|
||||
|
||||
注意有顺序的区别:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
np.add.outer(b, a)
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
array([[1, 2],
|
||||
[2, 3],
|
||||
[3, 4]])
|
||||
```
|
||||
|
|
@ -0,0 +1,136 @@
|
|||
# choose 函数实现条件筛选
|
||||
|
||||
对于数组,我们有时候需要进行类似 `switch` 和 `case` 进行条件选择,此时使用 choose 函数十分方便:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
control = np.array([[1,0,1],
|
||||
[2,1,0],
|
||||
[1,2,2]])
|
||||
|
||||
np.choose(control, [10, 11, 12])
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
array([[11, 10, 11],
|
||||
[12, 11, 10],
|
||||
[11, 12, 12]])
|
||||
```
|
||||
|
||||
在上面的例子中,`choose` 将 `0,1,2` 对应的值映射为了 `10, 11, 12`,这里的 `0,1,2` 表示对应的下标。
|
||||
|
||||
事实上, `choose` 不仅仅能接受下标参数,还可以接受下标所在的位置:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
i0 = np.array([[0,1,2],
|
||||
[3,4,5],
|
||||
[6,7,8]])
|
||||
i2 = np.array([[20,21,22],
|
||||
[23,24,25],
|
||||
[26,27,28]])
|
||||
control = np.array([[1,0,1],
|
||||
[2,1,0],
|
||||
[1,2,2]])
|
||||
|
||||
np.choose(control, [i0, 10, i2])
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([[10, 1, 10],
|
||||
[23, 10, 5],
|
||||
[10, 27, 28]])
|
||||
```
|
||||
|
||||
这里,`control` 传入第一个 `1` 对应的是 10,传入的第一个 `0` 对应于 `i0` 相应位置的值即 `1`,剩下的以此类推。
|
||||
|
||||
下面的例子将数组中所有小于 `10` 的值变成了 `10`。
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a = np.array([[ 0, 1, 2],
|
||||
[10,11,12],
|
||||
[20,21,22]])
|
||||
|
||||
a < 10
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([[ True, True, True],
|
||||
[False, False, False],
|
||||
[False, False, False]], dtype=bool)
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
np.choose(a < 10, (a, 10))
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([[10, 10, 10],
|
||||
[10, 11, 12],
|
||||
[20, 21, 22]])
|
||||
```
|
||||
|
||||
下面的例子将数组中所有小于 10 的值变成了 10,大于 15 的值变成了 15。
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
a = np.array([[ 0, 1, 2],
|
||||
[10,11,12],
|
||||
[20,21,22]])
|
||||
|
||||
lt = a < 10
|
||||
gt = a > 15
|
||||
|
||||
choice = lt + 2 * gt
|
||||
choice
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([[1, 1, 1],
|
||||
[0, 0, 0],
|
||||
[2, 2, 2]])
|
||||
```
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
np.choose(choice, (a, 10, 15))
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([[10, 10, 10],
|
||||
[10, 11, 12],
|
||||
[15, 15, 15]])
|
||||
```
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,735 @@
|
|||
# 数组读写
|
||||
|
||||
## 从文本中读取数组
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
### 空格(制表符)分割的文本
|
||||
|
||||
假设我们有这样的一个空白分割的文件:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
%%writefile myfile.txt
|
||||
2.1 2.3 3.2 1.3 3.1
|
||||
6.1 3.1 4.2 2.3 1.8
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing myfile.txt
|
||||
|
||||
```
|
||||
|
||||
为了生成数组,我们首先将数据转化成一个列表组成的列表,再将这个列表转换为数组:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
data = []
|
||||
|
||||
with open('myfile.txt') as f:
|
||||
# 每次读一行
|
||||
for line in f:
|
||||
fileds = line.split()
|
||||
row_data = [float(x) for x in fileds]
|
||||
data.append(row_data)
|
||||
|
||||
data = np.array(data)
|
||||
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
array([[ 2.1, 2.3, 3.2, 1.3, 3.1],
|
||||
[ 6.1, 3.1, 4.2, 2.3, 1.8]])
|
||||
```
|
||||
|
||||
不过,更简便的是使用 `loadtxt` 方法:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
data = np.loadtxt('myfile.txt')
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([[ 2.1, 2.3, 3.2, 1.3, 3.1],
|
||||
[ 6.1, 3.1, 4.2, 2.3, 1.8]])
|
||||
```
|
||||
|
||||
### 逗号分隔文件
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
%%writefile myfile.txt
|
||||
2.1, 2.3, 3.2, 1.3, 3.1
|
||||
6.1, 3.1, 4.2, 2.3, 1.8
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting myfile.txt
|
||||
|
||||
```
|
||||
|
||||
对于逗号分隔的文件(通常为`.csv`格式),我们可以稍微修改之前繁琐的过程,将 `split` 的参数变成 `','`即可。
|
||||
|
||||
不过,`loadtxt` 函数也可以读这样的文件,只需要制定分割符的参数即可:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
data = np.loadtxt('myfile.txt', delimiter=',')
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([[ 2.1, 2.3, 3.2, 1.3, 3.1],
|
||||
[ 6.1, 3.1, 4.2, 2.3, 1.8]])
|
||||
```
|
||||
|
||||
### loadtxt 函数
|
||||
|
||||
```py
|
||||
loadtxt(fname, dtype=<type 'float'>,
|
||||
comments='#', delimiter=None,
|
||||
converters=None, skiprows=0,
|
||||
usecols=None, unpack=False, ndmin=0)
|
||||
```
|
||||
|
||||
`loadtxt` 有很多可选参数,其中 `delimiter` 就是刚才用到的分隔符参数。
|
||||
|
||||
`skiprows` 参数表示忽略开头的行数,可以用来读写含有标题的文本
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
%%writefile myfile.txt
|
||||
X Y Z MAG ANG
|
||||
2.1 2.3 3.2 1.3 3.1
|
||||
6.1 3.1 4.2 2.3 1.8
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting myfile.txt
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
np.loadtxt('myfile.txt', skiprows=1)
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([[ 2.1, 2.3, 3.2, 1.3, 3.1],
|
||||
[ 6.1, 3.1, 4.2, 2.3, 1.8]])
|
||||
```
|
||||
|
||||
此外,有一个功能更为全面的 `genfromtxt` 函数,能处理更多的情况,但相应的速度和效率会慢一些。
|
||||
|
||||
```py
|
||||
genfromtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None,
|
||||
skiprows=0, skip_header=0, skip_footer=0, converters=None,
|
||||
missing='', missing_values=None, filling_values=None, usecols=None,
|
||||
names=None, excludelist=None, deletechars=None, replace_space='_',
|
||||
autostrip=False, case_sensitive=True, defaultfmt='f%i', unpack=None,
|
||||
usemask=False, loose=True, invalid_raise=True)
|
||||
```
|
||||
|
||||
### loadtxt 的更多特性
|
||||
|
||||
对于这样一个文件:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
%%writefile myfile.txt
|
||||
-- BEGINNING OF THE FILE
|
||||
% Day, Month, Year, Skip, Power
|
||||
01, 01, 2000, x876, 13 % wow!
|
||||
% we don't want have Jan 03rd
|
||||
04, 01, 2000, xfed, 55
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting myfile.txt
|
||||
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
data = np.loadtxt('myfile.txt',
|
||||
skiprows=1, #忽略第一行
|
||||
dtype=np.int, #数组类型
|
||||
delimiter=',', #逗号分割
|
||||
usecols=(0,1,2,4), #指定使用哪几列数据
|
||||
comments='%' #百分号为注释符
|
||||
)
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
array([[ 1, 1, 2000, 13],
|
||||
[ 4, 1, 2000, 55]])
|
||||
```
|
||||
|
||||
### loadtxt 自定义转换方法
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
%%writefile myfile.txt
|
||||
2010-01-01 2.3 3.2
|
||||
2011-01-01 6.1 3.1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting myfile.txt
|
||||
|
||||
```
|
||||
|
||||
假设我们的文本包含日期,我们可以使用 `datetime` 在 `loadtxt` 中处理:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
import datetime
|
||||
|
||||
def date_converter(s):
|
||||
return datetime.datetime.strptime(s, "%Y-%m-%d")
|
||||
|
||||
data = np.loadtxt('myfile.txt',
|
||||
dtype=np.object, #数据类型为对象
|
||||
converters={0:date_converter, #第一列使用自定义转换方法
|
||||
1:float, #第二第三使用浮点数转换
|
||||
2:float})
|
||||
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[13]:
|
||||
|
||||
```py
|
||||
array([[datetime.datetime(2010, 1, 1, 0, 0), 2.3, 3.2],
|
||||
[datetime.datetime(2011, 1, 1, 0, 0), 6.1, 3.1]], dtype=object)
|
||||
```
|
||||
|
||||
移除 `myfile.txt`:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('myfile.txt')
|
||||
|
||||
```
|
||||
|
||||
### 读写各种格式的文件
|
||||
|
||||
如下表所示:
|
||||
|
||||
| 文件格式 | 使用的包 | 函数 |
|
||||
| --- | --- | --- |
|
||||
| txt | numpy | loadtxt, genfromtxt, fromfile, savetxt, tofile |
|
||||
| csv | csv | reader, writer |
|
||||
| Matlab | scipy.io | loadmat, savemat |
|
||||
| hdf | pytables, h5py | |
|
||||
| NetCDF | netCDF4, scipy.io.netcdf | netCDF4.Dataset, scipy.io.netcdf.netcdf_file |
|
||||
| **文件格式** | **使用的包** | **备注** |
|
||||
| wav | scipy.io.wavfile | 音频文件 |
|
||||
| jpeg,png,... | PIL, scipy.misc.pilutil | 图像文件 |
|
||||
| fits | pyfits | 天文图像 |
|
||||
|
||||
此外, `pandas` ——一个用来处理时间序列的包中包含处理各种文件的方法,具体可参见它的文档:
|
||||
|
||||
[http://pandas.pydata.org/pandas-docs/stable/io.html](http://pandas.pydata.org/pandas-docs/stable/io.html)
|
||||
|
||||
## 将数组写入文件
|
||||
|
||||
`savetxt` 可以将数组写入文件,默认使用科学计数法的形式保存:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
data = np.array([[1,2],
|
||||
[3,4]])
|
||||
|
||||
np.savetxt('out.txt', data)
|
||||
|
||||
```
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
with open('out.txt') as f:
|
||||
for line in f:
|
||||
print line,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1.000000000000000000e+00 2.000000000000000000e+00
|
||||
3.000000000000000000e+00 4.000000000000000000e+00
|
||||
|
||||
```
|
||||
|
||||
也可以使用类似**C**语言中 `printf` 的方式指定输出的格式:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
data = np.array([[1,2],
|
||||
[3,4]])
|
||||
|
||||
np.savetxt('out.txt', data, fmt="%d") #保存为整数
|
||||
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
with open('out.txt') as f:
|
||||
for line in f:
|
||||
print line,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 2
|
||||
3 4
|
||||
|
||||
```
|
||||
|
||||
逗号分隔的输出:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
data = np.array([[1,2],
|
||||
[3,4]])
|
||||
|
||||
np.savetxt('out.txt', data, fmt="%.2f", delimiter=',') #保存为2位小数的浮点数,用逗号分隔
|
||||
|
||||
```
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
with open('out.txt') as f:
|
||||
for line in f:
|
||||
print line,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1.00,2.00
|
||||
3.00,4.00
|
||||
|
||||
```
|
||||
|
||||
复数值默认会加上括号:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
data = np.array([[1+1j,2],
|
||||
[3,4]])
|
||||
|
||||
np.savetxt('out.txt', data, fmt="%.2f", delimiter=',') #保存为2位小数的浮点数,用逗号分隔
|
||||
|
||||
```
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
with open('out.txt') as f:
|
||||
for line in f:
|
||||
print line,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(1.00+1.00j), (2.00+0.00j)
|
||||
(3.00+0.00j), (4.00+0.00j)
|
||||
|
||||
```
|
||||
|
||||
更多参数:
|
||||
|
||||
```py
|
||||
savetxt(fname,
|
||||
X,
|
||||
fmt='%.18e',
|
||||
delimiter=' ',
|
||||
newline='\n',
|
||||
header='',
|
||||
footer='',
|
||||
comments='# ')
|
||||
```
|
||||
|
||||
移除 `out.txt`:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('out.txt')
|
||||
|
||||
```
|
||||
|
||||
## Numpy 二进制格式
|
||||
|
||||
数组可以储存成二进制格式,单个的数组保存为 `.npy` 格式,多个数组保存为多个`.npy`文件组成的 `.npz` 格式,每个 `.npy` 文件包含一个数组。
|
||||
|
||||
与文本格式不同,二进制格式保存了数组的 `shape, dtype` 信息,以便完全重构出保存的数组。
|
||||
|
||||
保存的方法:
|
||||
|
||||
* `save(file, arr)` 保存单个数组,`.npy` 格式
|
||||
* `savez(file, *args, **kwds)` 保存多个数组,无压缩的 `.npz` 格式
|
||||
* `savez_compressed(file, *args, **kwds)` 保存多个数组,有压缩的 `.npz` 格式
|
||||
|
||||
读取的方法:
|
||||
|
||||
* `load(file, mmap_mode=None)` 对于 `.npy`,返回保存的数组,对于 `.npz`,返回一个名称-数组对组成的字典。
|
||||
|
||||
### 单个数组的读写
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
a = np.array([[1.0,2.0], [3.0,4.0]])
|
||||
|
||||
fname = 'afile.npy'
|
||||
np.save(fname, a)
|
||||
|
||||
```
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
aa = np.load(fname)
|
||||
aa
|
||||
|
||||
```
|
||||
|
||||
Out[25]:
|
||||
|
||||
```py
|
||||
array([[ 1., 2.],
|
||||
[ 3., 4.]])
|
||||
```
|
||||
|
||||
删除生成的文件:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('afile.npy')
|
||||
|
||||
```
|
||||
|
||||
### 二进制与文本大小比较
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
a = np.arange(10000.)
|
||||
|
||||
```
|
||||
|
||||
保存为文本:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
np.savetxt('a.txt', a)
|
||||
|
||||
```
|
||||
|
||||
查看大小:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.stat('a.txt').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[29]:
|
||||
|
||||
```py
|
||||
260000L
|
||||
```
|
||||
|
||||
保存为二进制:
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
np.save('a.npy', a)
|
||||
|
||||
```
|
||||
|
||||
查看大小:
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
os.stat('a.npy').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[31]:
|
||||
|
||||
```py
|
||||
80080L
|
||||
```
|
||||
|
||||
删除生成的文件:
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
os.remove('a.npy')
|
||||
os.remove('a.txt')
|
||||
|
||||
```
|
||||
|
||||
可以看到,二进制文件大约是文本文件的三分之一。
|
||||
|
||||
### 保存多个数组
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
a = np.array([[1.0,2.0],
|
||||
[3.0,4.0]])
|
||||
b = np.arange(1000)
|
||||
|
||||
```
|
||||
|
||||
保存多个数组:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
np.savez('data.npz', a=a, b=b)
|
||||
|
||||
```
|
||||
|
||||
查看里面包含的文件:
|
||||
|
||||
In [35]:
|
||||
|
||||
```py
|
||||
!unzip -l data.npz
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Archive: data.npz
|
||||
Length Date Time Name
|
||||
--------- ---------- ----- ----
|
||||
112 2015/08/10 00:46 a.npy
|
||||
4080 2015/08/10 00:46 b.npy
|
||||
--------- -------
|
||||
4192 2 files
|
||||
|
||||
```
|
||||
|
||||
载入数据:
|
||||
|
||||
In [36]:
|
||||
|
||||
```py
|
||||
data = np.load('data.npz')
|
||||
|
||||
```
|
||||
|
||||
载入后可以像字典一样进行操作:
|
||||
|
||||
In [37]:
|
||||
|
||||
```py
|
||||
data.keys()
|
||||
|
||||
```
|
||||
|
||||
Out[37]:
|
||||
|
||||
```py
|
||||
['a', 'b']
|
||||
```
|
||||
|
||||
In [38]:
|
||||
|
||||
```py
|
||||
data['a']
|
||||
|
||||
```
|
||||
|
||||
Out[38]:
|
||||
|
||||
```py
|
||||
array([[ 1., 2.],
|
||||
[ 3., 4.]])
|
||||
```
|
||||
|
||||
In [39]:
|
||||
|
||||
```py
|
||||
data['b'].shape
|
||||
|
||||
```
|
||||
|
||||
Out[39]:
|
||||
|
||||
```py
|
||||
(1000L,)
|
||||
```
|
||||
|
||||
删除文件:
|
||||
|
||||
In [40]:
|
||||
|
||||
```py
|
||||
# 要先删除 data,否则删除时会报错
|
||||
del data
|
||||
|
||||
os.remove('data.npz')
|
||||
|
||||
```
|
||||
|
||||
### 压缩文件
|
||||
|
||||
当数据比较整齐时:
|
||||
|
||||
In [41]:
|
||||
|
||||
```py
|
||||
a = np.arange(20000.)
|
||||
|
||||
```
|
||||
|
||||
无压缩大小:
|
||||
|
||||
In [42]:
|
||||
|
||||
```py
|
||||
np.savez('a.npz', a=a)
|
||||
os.stat('a.npz').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[42]:
|
||||
|
||||
```py
|
||||
160188L
|
||||
```
|
||||
|
||||
有压缩大小:
|
||||
|
||||
In [43]:
|
||||
|
||||
```py
|
||||
np.savez_compressed('a2.npz', a=a)
|
||||
os.stat('a2.npz').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[43]:
|
||||
|
||||
```py
|
||||
26885L
|
||||
```
|
||||
|
||||
大约有 6x 的压缩效果。
|
||||
|
||||
当数据比较混乱时:
|
||||
|
||||
In [44]:
|
||||
|
||||
```py
|
||||
a = np.random.rand(20000.)
|
||||
|
||||
```
|
||||
|
||||
无压缩大小:
|
||||
|
||||
In [45]:
|
||||
|
||||
```py
|
||||
np.savez('a.npz', a=a)
|
||||
os.stat('a.npz').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[45]:
|
||||
|
||||
```py
|
||||
160188L
|
||||
```
|
||||
|
||||
有压缩大小:
|
||||
|
||||
In [46]:
|
||||
|
||||
```py
|
||||
np.savez_compressed('a2.npz', a=a)
|
||||
os.stat('a2.npz').st_size
|
||||
|
||||
```
|
||||
|
||||
Out[46]:
|
||||
|
||||
```py
|
||||
151105L
|
||||
```
|
||||
|
||||
只有大约 1.06x 的压缩效果。
|
||||
|
||||
In [47]:
|
||||
|
||||
```py
|
||||
os.remove('a.npz')
|
||||
os.remove('a2.npz')
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,494 @@
|
|||
# 结构化数组
|
||||
|
||||
假设我们要保存这样的数据:
|
||||
|
||||
| | name | age | wgt |
|
||||
| --- | --- | --- | --- |
|
||||
| 0 | dan | 1 | 23.1 |
|
||||
| 1 | ann | 0 | 25.1 |
|
||||
| 2 | sam | 2 | 8.3 |
|
||||
|
||||
希望定义一个一维数组,每个元素有三个属性 `name, age, wgt`,此时我们需要使用结构化数组。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
定义数组 `a`:
|
||||
|
||||
| 0 | 1 | 2 | 3 |
|
||||
| --- | --- | --- | --- |
|
||||
| 1.0 | 2.0 | 3.0 | 4.0 |
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = np.array([1.0,2.0,3.0,4.0], np.float32)
|
||||
|
||||
```
|
||||
|
||||
使用 `view` 方法,将 `a` 对应的内存按照复数来解释:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a.view(np.complex64)
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
array([ 1.+2.j, 3.+4.j], dtype=complex64)
|
||||
```
|
||||
|
||||
| 0 | 1 | 2 | 3 |
|
||||
| --- | --- | --- | --- |
|
||||
| 1.0 | 2.0 | 3.0 | 4.0 |
|
||||
| real | imag | real | imag |
|
||||
|
||||
事实上,我们可以把复数看成一个结构体,第一部分是实部,第二部分是虚部,这样这个数组便可以看成是一个结构化数组。
|
||||
|
||||
换句话说,我们只需要换种方式解释这段内存,便可以得到结构化数组的效果!
|
||||
|
||||
| 0 | 1 | 2 | 3 |
|
||||
| --- | --- | --- | --- |
|
||||
| 1.0 | 2.0 | 3.0 | 4.0 |
|
||||
| mass | vol | mass | vol |
|
||||
|
||||
例如,我们可以将第一个浮点数解释为质量,第二个浮点数解释为速度,则这段内存还可以看成是包含两个域(质量和速度)的结构体。
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
my_dtype = np.dtype([('mass', 'float32'), ('vol', 'float32')])
|
||||
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a.view(my_dtype)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([(1.0, 2.0), (3.0, 4.0)],
|
||||
dtype=[('mass', '<f4'), ('vol', '<f4')])
|
||||
```
|
||||
|
||||
这里,我们使用 `dtype` 创造了自定义的结构类型,然后用自定义的结构来解释数组 `a` 所占的内存。
|
||||
|
||||
这里 `f4` 表示四字节浮点数,`<` 表示小字节序。
|
||||
|
||||
利用这个自定义的结构类型,我们可以这样初始化结构化数组:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
my_data = np.array([(1,1), (1,2), (2,1), (1,3)], my_dtype)
|
||||
|
||||
print my_data
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[(1.0, 1.0) (1.0, 2.0) (2.0, 1.0) (1.0, 3.0)]
|
||||
|
||||
```
|
||||
|
||||
第一个元素:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
my_data[0]
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
(1.0, 1.0)
|
||||
```
|
||||
|
||||
得到第一个元素的速度信息,可以使用域的名称来索引:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
my_data[0]['vol']
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
1.0
|
||||
```
|
||||
|
||||
得到所有的质量信息:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
my_data['mass']
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([ 1., 1., 2., 1.], dtype=float32)
|
||||
```
|
||||
|
||||
自定义排序规则,先按速度,再按质量:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
my_data.sort(order=('vol', 'mass'))
|
||||
|
||||
print my_data
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[(1.0, 1.0) (2.0, 1.0) (1.0, 2.0) (1.0, 3.0)]
|
||||
|
||||
```
|
||||
|
||||
回到最初的例子,定义一个人的结构类型:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
person_dtype = np.dtype([('name', 'S10'), ('age', 'int'), ('weight', 'float')])
|
||||
|
||||
```
|
||||
|
||||
查看类型所占字节数:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
person_dtype.itemsize
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
22
|
||||
```
|
||||
|
||||
产生一个 3 x 4 共12人的空结构体数组:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
people = np.empty((3,4), person_dtype)
|
||||
|
||||
```
|
||||
|
||||
分别赋值:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
people['name'] = [['Brad', 'Jane', 'John', 'Fred'],
|
||||
['Henry', 'George', 'Brain', 'Amy'],
|
||||
['Ron', 'Susan', 'Jennife', 'Jill']]
|
||||
|
||||
```
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
people['age'] = [[33, 25, 47, 54],
|
||||
[29, 61, 32, 27],
|
||||
[19, 33, 18, 54]]
|
||||
|
||||
```
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
people['weight'] = [[135., 105., 255., 140.],
|
||||
[154., 202., 137., 187.],
|
||||
[188., 135., 88., 145.]]
|
||||
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
print people
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[[('Brad', 33, 135.0) ('Jane', 25, 105.0) ('John', 47, 255.0)
|
||||
('Fred', 54, 140.0)]
|
||||
[('Henry', 29, 154.0) ('George', 61, 202.0) ('Brain', 32, 137.0)
|
||||
('Amy', 27, 187.0)]
|
||||
[('Ron', 19, 188.0) ('Susan', 33, 135.0) ('Jennife', 18, 88.0)
|
||||
('Jill', 54, 145.0)]]
|
||||
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
people[-1,-1]
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
('Jill', 54, 145.0)
|
||||
```
|
||||
|
||||
## 从文本中读取结构化数组
|
||||
|
||||
我们有这样一个文件:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
%%writefile people.txt
|
||||
name age weight
|
||||
amy 11 38.2
|
||||
john 10 40.3
|
||||
bill 12 21.2
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing people.txt
|
||||
|
||||
```
|
||||
|
||||
利用 `loadtxt` 指定数据类型,从这个文件中读取结构化数组:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
person_dtype = np.dtype([('name', 'S10'), ('age', 'int'), ('weight', 'float')])
|
||||
|
||||
people = np.loadtxt('people.txt',
|
||||
skiprows=1,
|
||||
dtype=person_dtype)
|
||||
|
||||
people
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
array([('amy', 11, 38.2), ('john', 10, 40.3), ('bill', 12, 21.2)],
|
||||
dtype=[('name', 'S10'), ('age', '<i4'), ('weight', '<f8')])
|
||||
```
|
||||
|
||||
查看 `name` 域:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
people['name']
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
array(['amy', 'john', 'bill'],
|
||||
dtype='|S10')
|
||||
```
|
||||
|
||||
删除文件:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('people.txt')
|
||||
|
||||
```
|
||||
|
||||
对于下面的文件:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
%%writefile wood.csv
|
||||
item,material,number
|
||||
100,oak,33
|
||||
110,maple,14
|
||||
120,oak,7
|
||||
145,birch,3
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing wood.csv
|
||||
|
||||
```
|
||||
|
||||
定义转换函数处理材料属性,使之对应一个整数:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
tree_to_int = dict(oak = 1,
|
||||
maple=2,
|
||||
birch=3)
|
||||
|
||||
def convert(s):
|
||||
return tree_to_int.get(s, 0)
|
||||
|
||||
```
|
||||
|
||||
使用 `genfromtxt` 载入数据,可以自动从第一行读入属性名称:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
data = np.genfromtxt('wood.csv',
|
||||
delimiter=',', # 逗号分隔
|
||||
dtype=np.int, # 数据类型
|
||||
names=True, # 从第一行读入域名
|
||||
converters={1:convert}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[26]:
|
||||
|
||||
```py
|
||||
array([(100, 1, 33), (110, 2, 14), (120, 1, 7), (145, 3, 3)],
|
||||
dtype=[('item', '<i4'), ('material', '<i4'), ('number', '<i4')])
|
||||
```
|
||||
|
||||
查看域:
|
||||
|
||||
In [27]:
|
||||
|
||||
```py
|
||||
data['material']
|
||||
|
||||
```
|
||||
|
||||
Out[27]:
|
||||
|
||||
```py
|
||||
array([1, 2, 1, 3])
|
||||
```
|
||||
|
||||
删除文件:
|
||||
|
||||
In [28]:
|
||||
|
||||
```py
|
||||
os.remove('wood.csv')
|
||||
|
||||
```
|
||||
|
||||
## 嵌套类型
|
||||
|
||||
有时候,结构数组中的域可能包含嵌套的结构,例如,在我们希望在二维平面上纪录一个质点的位置和质量:
|
||||
|
||||
| position | mass |
|
||||
| x | y |
|
||||
|
||||
那么它的类型可以这样嵌套定义:
|
||||
|
||||
In [29]:
|
||||
|
||||
```py
|
||||
particle_dtype = np.dtype([('position', [('x', 'float'),
|
||||
('y', 'float')]),
|
||||
('mass', 'float')
|
||||
])
|
||||
|
||||
```
|
||||
|
||||
假设数据文件如下:
|
||||
|
||||
In [30]:
|
||||
|
||||
```py
|
||||
%%writefile data.txt
|
||||
2.0 3.0 42.0
|
||||
2.1 4.3 32.5
|
||||
1.2 4.6 32.3
|
||||
4.5 -6.4 23.3
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Overwriting data.txt
|
||||
|
||||
```
|
||||
|
||||
读取数据:
|
||||
|
||||
In [31]:
|
||||
|
||||
```py
|
||||
data = np.loadtxt('data.txt', dtype=particle_dtype)
|
||||
|
||||
```
|
||||
|
||||
In [32]:
|
||||
|
||||
```py
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[32]:
|
||||
|
||||
```py
|
||||
array([((2.0, 3.0), 42.0), ((2.1, 4.3), 32.5), ((1.2, 4.6), 32.3),
|
||||
((4.5, -6.4), 23.3)],
|
||||
dtype=[('position', [('x', '<f8'), ('y', '<f8')]), ('mass', '<f8')])
|
||||
```
|
||||
|
||||
查看位置的 `x` 轴:
|
||||
|
||||
In [33]:
|
||||
|
||||
```py
|
||||
data['position']['x']
|
||||
|
||||
```
|
||||
|
||||
Out[33]:
|
||||
|
||||
```py
|
||||
array([ 2\. , 2.1, 1.2, 4.5])
|
||||
```
|
||||
|
||||
删除生成的文件:
|
||||
|
||||
In [34]:
|
||||
|
||||
```py
|
||||
os.remove('data.txt')
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,138 @@
|
|||
# 记录数组
|
||||
|
||||
记录数组(`record array`)与结构数组类似:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
质点类型:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
partical_dtype = np.dtype([('mass', 'float'),
|
||||
('velocity', 'float')])
|
||||
|
||||
```
|
||||
|
||||
生成记录数组要使用 `numpy.rec` 里的 `fromrecords` 方法:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
from numpy import rec
|
||||
|
||||
particals_rec = rec.fromrecords([(1,1), (1,2), (2,1), (1,3)],
|
||||
dtype = partical_dtype)
|
||||
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
particals_rec
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
rec.array([(1.0, 1.0), (1.0, 2.0), (2.0, 1.0), (1.0, 3.0)],
|
||||
dtype=[('mass', '<f8'), ('velocity', '<f8')])
|
||||
```
|
||||
|
||||
在记录数组中,域可以通过属性来获得:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
particals_rec.mass
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
array([ 1., 1., 2., 1.])
|
||||
```
|
||||
|
||||
也可以通过域来查询:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
particals_rec['mass']
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
array([ 1., 1., 2., 1.])
|
||||
```
|
||||
|
||||
不过,记录数组的运行效率要比结构化数组要慢一些。
|
||||
|
||||
也可以通过将一个结构化数组看成记录数组:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
particals = np.array([(1,1), (1,2), (2,1), (1,3)],
|
||||
dtype = partical_dtype)
|
||||
|
||||
```
|
||||
|
||||
使用 `view` 方法看成 `recarray` :
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
particals_rec = particals.view(np.recarray)
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
particals_rec.mass
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
array([ 1., 1., 2., 1.])
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
particals_rec.velocity
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
array([ 1., 2., 1., 3.])
|
||||
```
|
||||
|
||||
对于自定义的类型,可以通过它的 `names` 属性查看它有哪些域:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
particals.dtype.names
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
('mass', 'velocity')
|
||||
```
|
||||
|
|
@ -0,0 +1,33 @@
|
|||
# 内存映射
|
||||
|
||||
**Numpy** 有对内存映射的支持。
|
||||
|
||||
内存映射也是一种处理文件的方法,主要的函数有:
|
||||
|
||||
* `memmap`
|
||||
* `frombuffer`
|
||||
* `ndarray constructor`
|
||||
|
||||
内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而且在对该文件进行操作之前必须首先对文件进行映射。
|
||||
|
||||
使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行I/O操作,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
|
||||
|
||||
## memmap
|
||||
|
||||
```py
|
||||
memmap(filename,
|
||||
dtype=uint8,
|
||||
mode='r+'
|
||||
offset=0
|
||||
shape=None
|
||||
order=0)
|
||||
```
|
||||
|
||||
`mode` 表示文件被打开的类型:
|
||||
|
||||
* `r` 只读
|
||||
* `c` 复制+写,但是不改变源文件
|
||||
* `r+` 读写,使用 `flush` 方法会将更改的内容写入文件
|
||||
* `w+` 写,如果存在则将数据覆盖
|
||||
|
||||
`offset` 表示从第几个位置开始。
|
||||
|
|
@ -0,0 +1,260 @@
|
|||
# 从 Matlab 到 Numpy
|
||||
|
||||
## Numpy 和 Matlab 比较
|
||||
|
||||
**`Numpy`** 和 **`Matlab`** 有很多相似的地方,但 **`Numpy`** 并非 **`Matlab`** 的克隆,它们之间存在很多差异,例如:
|
||||
|
||||
| `MATLAB®` | `Numpy` |
|
||||
| --- | --- |
|
||||
| 基本类型为双精度浮点数组,以二维矩阵为主 | 基本类型为 `ndarray`,有特殊的 `matrix` 类 |
|
||||
| 1-based 索引 | 0-based 索引 |
|
||||
| 脚本主要用于线性代数计算 | 可以使用其他的 **Python** 特性 |
|
||||
| 采用值传递的方式进行计算
|
||||
切片返回复制 | 采用引用传递的方式进行计算
|
||||
切片返回引用 |
|
||||
| 文件名必须和函数名相同 | 函数可以在任何地方任何文件中定义 |
|
||||
| 收费 | 免费 |
|
||||
| 2D,3D图像支持 | 依赖第三方库如 `matplotlib` 等 |
|
||||
| 完全的编译环境 | 依赖于 **Python** 提供的编译环境 |
|
||||
|
||||
## array 还是 matrix?
|
||||
|
||||
`Numpy` 中不仅提供了 `array` 这个基本类型,还提供了支持矩阵操作的类 `matrix`,但是一般推荐使用 `array`:
|
||||
|
||||
* 很多 `numpy` 函数返回的是 `array`,不是 `matrix`
|
||||
* 在 `array` 中,逐元素操作和矩阵操作有着明显的不同
|
||||
* 向量可以不被视为矩阵
|
||||
|
||||
具体说来:
|
||||
|
||||
* `*, dot(), multiply()`
|
||||
* `array`:`*` -逐元素乘法,`dot()` -矩阵乘法
|
||||
* `matrix`:`*` -矩阵乘法,`multiply()` -逐元素乘法
|
||||
* 处理向量
|
||||
* `array`:形状为 `1xN, Nx1, N` 的向量的意义是不同的,类似于 `A[:,1]` 的操作返回的是一维数组,形状为 `N`,一维数组的转置仍是自己本身
|
||||
* `matrix`:形状为 `1xN, Nx1`,`A[:,1]` 返回的是二维 `Nx1` 矩阵
|
||||
* 高维数组
|
||||
* `array`:支持大于2的维度
|
||||
* `matrix`:维度只能为2
|
||||
* 属性
|
||||
* `array`:`.T` 表示转置
|
||||
* `matrix`:`.H` 表示复共轭转置,`.I` 表示逆,`.A` 表示转化为 `array` 类型
|
||||
* 构造函数
|
||||
* `array`:`array` 函数接受一个(嵌套)序列作为参数——`array([[1,2,3],[4,5,6]])`
|
||||
* `matrix`:`matrix` 函数额外支持字符串参数——`matrix("[1 2 3; 4 5 6]")`
|
||||
|
||||
其优缺点各自如下:
|
||||
|
||||
* **`array`**
|
||||
|
||||
* `[GOOD]` 一维数组既可以看成列向量,也可以看成行向量。`v` 在 `dot(A,v)` 被看成列向量,在 `dot(v,A)` 中被看成行向量,这样省去了转置的麻烦
|
||||
* `[BAD!]` 矩阵乘法需要使用 `dot()` 函数,如: `dot(dot(A,B),C)` vs `A*B*C`
|
||||
* `[GOOD]` 逐元素乘法很简单: `A*B`
|
||||
* `[GOOD]` 作为基本类型,是很多基于 `numpy` 的第三方库函数的返回类型
|
||||
* `[GOOD]` 所有的操作 `*,/,+,**,...` 都是逐元素的
|
||||
* `[GOOD]` 可以处理任意维度的数据
|
||||
* `[GOOD]` 张量运算
|
||||
* **`matrix`**
|
||||
|
||||
* `[GOOD]` 类似与 **`MATLAB`** 的操作
|
||||
* `[BAD!]` 最高维度为2
|
||||
* `[BAD!]` 最低维度也为2
|
||||
* `[BAD!]` 很多函数返回的是 `array`,即使传入的参数是 `matrix`
|
||||
* `[GOOD]` `A*B` 是矩阵乘法
|
||||
* `[BAD!]` 逐元素乘法需要调用 `multiply` 函数
|
||||
* `[BAD!]` `/` 是逐元素操作
|
||||
|
||||
当然在实际使用中,二者的使用取决于具体情况。
|
||||
|
||||
二者可以互相转化:
|
||||
|
||||
* `asarray` :返回数组
|
||||
* `asmatrix`(或者`mat`) :返回矩阵
|
||||
* `asanyarray` :返回数组或者数组的子类,注意到矩阵是数组的一个子类,所以输入是矩阵的时候返回的也是矩阵
|
||||
|
||||
## 类 Matlab 函数
|
||||
|
||||
有很多类似的函数:
|
||||
|
||||
* `ones, zeros, empty, eye, rand, repmat`
|
||||
|
||||
通常这些函数的返回值是 `array`,不过 `numpy` 提供了一个 `matlib` 的子模块,子模块中的这些函数返回值为 `matrix`:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy
|
||||
import numpy.matlib
|
||||
|
||||
```
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
a = numpy.ones(7)
|
||||
|
||||
print a.shape
|
||||
print type(a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(7L,)
|
||||
<type 'numpy.ndarray'>
|
||||
|
||||
```
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
a = numpy.matlib.ones(7)
|
||||
|
||||
print a.shape
|
||||
print type(a)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(1L, 7L)
|
||||
<class 'numpy.matrixlib.defmatrix.matrix'>
|
||||
|
||||
```
|
||||
|
||||
`mat` 函数将一个数组转化为矩阵:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
a = numpy.array([1,2,3])
|
||||
|
||||
b = numpy.mat(a)
|
||||
|
||||
print type(b)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<class 'numpy.matrixlib.defmatrix.matrix'>
|
||||
|
||||
```
|
||||
|
||||
有些函数被放到子模块中了,例如调用 `rand()` 函数需要使用 `numpy.random.rand()` (或者从 `matlib` 模块中生成矩阵):
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
a = numpy.random.rand(10)
|
||||
print a
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[ 0.66007267 0.34794294 0.5040946 0.65044648 0.74763248 0.42486999
|
||||
0.90922612 0.69071747 0.33541076 0.08570178]
|
||||
|
||||
```
|
||||
|
||||
## 等效操作
|
||||
|
||||
假定我们已经这样导入了 `Numpy`:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
from numpy import *
|
||||
import scipy.linalg
|
||||
|
||||
```
|
||||
|
||||
以下 `linalg` 表示的是 `numpy.linalg`,与 `scipy.linalg` 不同。
|
||||
|
||||
注意:**`MATLAB`** 与 **`Numpy`** 下标之间有这样几处不同:
|
||||
|
||||
* `1-base` vs `0-base`
|
||||
* `()` vs `[]`
|
||||
* `MATLAB`:`beg(:step):end`,包含结束值 `end`
|
||||
* `Numpy`:`beg:end(:step)`,不包含结束值 `end`
|
||||
|
||||
| MATLAB | Numpy | 注释 |
|
||||
| --- | --- | --- |
|
||||
| `help func` | `info(func)`, `help(func)`, `func?`(IPython) | 查看函数帮助 |
|
||||
| `which func` | | 查看函数在什么地方定义 |
|
||||
| `type func` | `source(func)`, `func??`(IPython) | 查看函数源代码 |
|
||||
| `a && b` | `a and b` | 逻辑 `AND` |
|
||||
| `1*i, 1*j, 1i, 1j` | `1j` | 复数 |
|
||||
| `eps` | `spacing(1)` | `1` 与最近浮点数的距离 |
|
||||
| `ndims(a)` | `ndim(a), a.ndim` | `a` 的维数 |
|
||||
| `numel(a)` | `size(a), a.size` | `a` 的元素个数 |
|
||||
| `size(a)` | `shape(a), a.shape` | `a` 的形状 |
|
||||
| `size(a,n)` | `a.shape[n-1]` | 第 n 维的大小 |
|
||||
| `a(2,5)` | `a[1,4]` | 第 2 行第 5 列元素 |
|
||||
| `a(2,:)` | `a[1], a[1,:]` | 第 2 行 |
|
||||
| `a(1:5,:)` | `a[0:5]` | 第 1 至 5 行 |
|
||||
| `a(end-4:end,:)` | `a[-5:]` | 后 5 行 |
|
||||
| `a(1:3,5:9)` | `a[0:3][:,4:9]` | 特定行列(1~3 行,5~9 列) |
|
||||
| `a([2,4,5],[1,3])` | `a[ix_([1,3,4],[0,2])]` | 特定行列(2,4,5 行的 1,3 列) |
|
||||
| `a(3:2:21,:)` | `a[2:21:2,:]` | 特定行列(3,5,...,21 行) |
|
||||
| `a(1:2:end,:)` | `a[ ::2,:]` | 奇数行 |
|
||||
| `a([1:end 1],:)` | `a[r_[:len(a),0]]` | 将第一行添加到末尾 |
|
||||
| `a.'` | `a.T` | 转置 |
|
||||
| `a ./ b` | `a/b` | 逐元素除法 |
|
||||
| `(a>0.5)` | `(a>0.5)` | 各个元素是否大于 0.5 |
|
||||
| `find(a>0.5)` | `nonzero(a>0.5)` | 大于 0.5 的位置 |
|
||||
| `a(a<0.5)=0` | `a[a<0.5]=0` | 小于 0.5 的设为 0 |
|
||||
| `a(:) = 3` | `a[:] = 3` | 所有元素设为 3 |
|
||||
| `y=x` | `y=x.copy()` | 将 y 设为 x |
|
||||
| `y=x(2,:)` | `y=x[1,:].copy()` | 注意值传递和引用传递的区别 |
|
||||
| `y=x(:)` | `y=x.flatten(1)` | 将矩阵变为一个向量,这里 `1` 表示沿着列进行转化 |
|
||||
| `max(max(a))` | `a.max()` | 最大值 |
|
||||
| `max(a)` | `a.max(0)` | 每一列的最大值 |
|
||||
| `max(a,[],2)` | `a.max(1)` | 每一行的最大值 |
|
||||
| `max(a,b)` | `maximum(a,b)` | 逐元素比较,取较大的值 |
|
||||
| `a & b` | `logical_and(a, b)` | 逻辑 AND |
|
||||
| `bitand(a, b)` | `a & b` | 逐比特 AND |
|
||||
| `inv(a)` | `linalg.inv(a)` | a 的逆 |
|
||||
| `pinv(a)` | `linalg.inv(a)` | 伪逆 |
|
||||
| `rank(a)` | `linalg.matrix_rank(a)` | 秩 |
|
||||
| `a\b` | `linalg.solve(a,b)(如果a是方阵),linalg.lstsq(a,b)` | 解 `a x = b` |
|
||||
| `b/a` | 求解 `a.T x.T = b.T` | 解 `x a = b` |
|
||||
| `[U,S,V]=svd(a)` | `U, S, Vh = linalg.svd(a), V = Vh.T` | 奇异值分解 |
|
||||
| `chol(a)` | `linalg.cholesky(a).T` | Cholesky 分解 |
|
||||
| `[V,D]=eig(a)` | `D,V = linalg.eig(a)` | 特征值分解 |
|
||||
| `[V,D]=eig(a,b)` | `V,D = scipy.linalg.eig(a,b)` | |
|
||||
| `[V,D]=eigs(a,k)` | | 前 k 大特征值对应的特征向量 |
|
||||
| `` | `` | |
|
||||
| `` | `` | |
|
||||
| `` | `` | |
|
||||
| `` | `` | |
|
||||
|
||||
| MATLAB | numpy.array | numpy.matrix | 注释 |
|
||||
| --- | --- | --- | --- |
|
||||
| `[1,2,3;4,5,6]` | `array([[1.,2.,3.],[4.,5.,6.]])` | `mat([[1.,2.,3.],[4.,5.,6.]]), mat('1,2,3;4,5,6')` | `2x3` 矩阵 |
|
||||
| `[a b;c d]` | `vstack([hstack([a,b]), hsatck([c,d])]])` | `bmat('a b;c d')` | 分块矩阵构造 |
|
||||
| `a(end)` | `a[-1]` | `a[:,-1][0,0]` | 最后一个元素 |
|
||||
| `a'` | `a.conj().T` | `a.H` | 复共轭转置 |
|
||||
| `a * b` | `dot(a,b)` | `a * b` | 矩阵乘法 |
|
||||
| `a .* b` | `a * b` | `multiply(a,b)` | 逐元素乘法 |
|
||||
| `a.^3` | `a**3` | `power(a,3)` | 逐元素立方 |
|
||||
| `a(:,find(v>0.5))` | `a[:,nonzero(v>0.5)[0]]` | `a[:,nonzero(v.A>0.5)[0]]` | 找出行向量 `v>0.5` 对应的 `a` 中的列 |
|
||||
| `a(:,find(v>0.5))` | `a[:,v.T>0.5]` | `a[:,v.T>0.5)]` | 找出列向量 `v>0.5` 对应的 `a` 中的列 |
|
||||
| `a .* (a>0.5)` | `a * (a>0.5)` | `mat(a.A * (a>0.5).A)` | 将所有小于 0.5 的元素设为 0 |
|
||||
| `1:10` | `arange(1.,11.), r_[1.:11.], r_[1:10:10j]` | `mat(arange(1.,11.)), r_[1.:11., 'r']` | 这里 `1.` 是为了将其转化为浮点数组 |
|
||||
| `0:9` | `arange(10.), r_[:10.], r_[:9:10j]` | `mat(arange(10.)), r_[:10., 'r']` | |
|
||||
| `[1:10]'` | `arange(1.,11.)[:,newaxis]` | `r_[1.:11.,'c']` | 列向量 |
|
||||
| `zeros, ones, eye, diag, linspace` | `zeros, ones, eye, diag, linspace` | `mat(...)` | |
|
||||
| `rand(3,4)` | `random.rand(3,4)` | `mat(...)` | 0~1 随机数 |
|
||||
| `[x,y]=meshgrid(0:8,0:5)` | `mgrid[0:9., 0:6.], meshgrid(r_[0:9.],r_[0:6.])` | `mat(...)` | 网格 |
|
||||
| | `ogrid[0:9.,0:6.], ix_(r_[0:9.],r_[0:6.])` | `mat()` | 建议在 `Numpy` 中使用 |
|
||||
| `[x,y]=meshgrid([1,2,4],[2,4,5])` | `meshgrid([1,2,4],[2,4,5])` | `mat(...)` | |
|
||||
| | `ix_([1,2,4],[2,4,5])` | `mat(...)` | |
|
||||
| `repmat(a, m, n)` | `tile(a, (m,n))` | `mat(...)` | 产生 `m x n` 个 `a` |
|
||||
| `[a b]` | `c_[a,b]` | `concatenate((a,b),1)` | 列对齐连接 |
|
||||
| `[a; b]` | `r_[a,b]` | `concatenate((a,b))` | 行对齐连接 |
|
||||
| `norm(v)` | `sqrt(dot(v,v)), linalg.norm(v)` | `sqrt(dot(v.A,v.A)), linalg.norm(v)` | 模 |
|
||||
| `[Q,R,P]=qr(a,0)` | `Q,R = scipy.linalg.qr(a)` | `mat(...)` | QR 分解 |
|
||||
| `[L,U,P]=lu(a)` | `L,U = Sci.linalg.lu(a)` | `mat(...)` | LU 分解 |
|
||||
| `fft(a)` | `fft(a)` | `mat(...)` | FFT |
|
||||
| `ifft(a)` | `ifft(a)` | `mat(...)` | IFFT |
|
||||
| `sort(a)` | `sort(a),a.sort` | `mat(...)` | 排序 |
|
||||
|
||||
参考:[http://wiki.scipy.org/NumPy_for_Matlab_Users#whichNotes](http://wiki.scipy.org/NumPy_for_Matlab_Users#whichNotes)
|
||||
|
|
@ -0,0 +1 @@
|
|||
# 04\. Scipy
|
||||
|
|
@ -0,0 +1,199 @@
|
|||
# SCIentific PYthon 简介
|
||||
|
||||
**`Ipython`** 提供了一个很好的解释器界面。
|
||||
|
||||
**`Matplotlib`** 提供了一个类似 **`Matlab`** 的画图工具。
|
||||
|
||||
**`Numpy`** 提供了 `ndarray` 对象,可以进行快速的向量化计算。
|
||||
|
||||
**`Scipy`** 是 **`Python`** 中进行科学计算的一个第三方库,以 **`Numpy`** 为基础。
|
||||
|
||||
**`Pandas`** 是处理时间序列数据的第三方库,提供一个类似 **`R`** 语言的环境。
|
||||
|
||||
**`StatsModels`** 是一个统计库,着重于统计模型。
|
||||
|
||||
**`Scikits`** 以 **`Scipy`** 为基础,提供如 **`scikits-learn` 机器学习**和**`scikits-image` 图像处理**等高级用法。
|
||||
|
||||
## Scipy
|
||||
|
||||
**`Scipy`** 由不同科学计算领域的子模块组成:
|
||||
|
||||
| 子模块 | 描述 |
|
||||
| --- | --- |
|
||||
| `cluster` | 聚类算法 |
|
||||
| `constants` | 物理数学常数 |
|
||||
| `fftpack` | 快速傅里叶变换 |
|
||||
| `integrate` | 积分和常微分方程求解 |
|
||||
| `interpolate` | 插值 |
|
||||
| `io` | 输入输出 |
|
||||
| `linalg` | 线性代数 |
|
||||
| `odr` | 正交距离回归 |
|
||||
| `optimize` | 优化和求根 |
|
||||
| `signal` | 信号处理 |
|
||||
| `sparse` | 稀疏矩阵 |
|
||||
| `spatial` | 空间数据结构和算法 |
|
||||
| `special` | 特殊方程 |
|
||||
| `stats` | 统计分布和函数 |
|
||||
| `weave` | C/C++ 积分 |
|
||||
|
||||
在使用 **`Scipy`** 之前,为了方便,假定这些基础的模块已经被导入:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import numpy as np
|
||||
import scipy as sp
|
||||
import matplotlib as mpl
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
```
|
||||
|
||||
使用 **Scipy** 中的子模块时,需要分别导入:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
from scipy import linalg, optimize
|
||||
|
||||
```
|
||||
|
||||
对于一些常用的函数,这些在子模块中的函数可以在 `scipy` 命名空间中调用。另一方面,由于 **`Scipy`** 以 **`Numpy`** 为基础,因此很多基础的 **`Numpy`** 函数可以在`scipy` 命名空间中直接调用。
|
||||
|
||||
我们可以使用 `numpy` 中的 `info` 函数来查看函数的文档:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
np.info(optimize.fmin)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
fmin(func, x0, args=(), xtol=0.0001, ftol=0.0001, maxiter=None, maxfun=None,
|
||||
full_output=0, disp=1, retall=0, callback=None)
|
||||
|
||||
Minimize a function using the downhill simplex algorithm.
|
||||
|
||||
This algorithm only uses function values, not derivatives or second
|
||||
derivatives.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
func : callable func(x,*args)
|
||||
The objective function to be minimized.
|
||||
x0 : ndarray
|
||||
Initial guess.
|
||||
args : tuple, optional
|
||||
Extra arguments passed to func, i.e. ``f(x,*args)``.
|
||||
callback : callable, optional
|
||||
Called after each iteration, as callback(xk), where xk is the
|
||||
current parameter vector.
|
||||
xtol : float, optional
|
||||
Relative error in xopt acceptable for convergence.
|
||||
ftol : number, optional
|
||||
Relative error in func(xopt) acceptable for convergence.
|
||||
maxiter : int, optional
|
||||
Maximum number of iterations to perform.
|
||||
maxfun : number, optional
|
||||
Maximum number of function evaluations to make.
|
||||
full_output : bool, optional
|
||||
Set to True if fopt and warnflag outputs are desired.
|
||||
disp : bool, optional
|
||||
Set to True to print convergence messages.
|
||||
retall : bool, optional
|
||||
Set to True to return list of solutions at each iteration.
|
||||
|
||||
Returns
|
||||
-------
|
||||
xopt : ndarray
|
||||
Parameter that minimizes function.
|
||||
fopt : float
|
||||
Value of function at minimum: ``fopt = func(xopt)``.
|
||||
iter : int
|
||||
Number of iterations performed.
|
||||
funcalls : int
|
||||
Number of function calls made.
|
||||
warnflag : int
|
||||
1 : Maximum number of function evaluations made.
|
||||
2 : Maximum number of iterations reached.
|
||||
allvecs : list
|
||||
Solution at each iteration.
|
||||
|
||||
See also
|
||||
--------
|
||||
minimize: Interface to minimization algorithms for multivariate
|
||||
functions. See the 'Nelder-Mead' `method` in particular.
|
||||
|
||||
Notes
|
||||
-----
|
||||
Uses a Nelder-Mead simplex algorithm to find the minimum of function of
|
||||
one or more variables.
|
||||
|
||||
This algorithm has a long history of successful use in applications.
|
||||
But it will usually be slower than an algorithm that uses first or
|
||||
second derivative information. In practice it can have poor
|
||||
performance in high-dimensional problems and is not robust to
|
||||
minimizing complicated functions. Additionally, there currently is no
|
||||
complete theory describing when the algorithm will successfully
|
||||
converge to the minimum, or how fast it will if it does.
|
||||
|
||||
References
|
||||
----------
|
||||
.. [1] Nelder, J.A. and Mead, R. (1965), "A simplex method for function
|
||||
minimization", The Computer Journal, 7, pp. 308-313
|
||||
|
||||
.. [2] Wright, M.H. (1996), "Direct Search Methods: Once Scorned, Now
|
||||
Respectable", in Numerical Analysis 1995, Proceedings of the
|
||||
1995 Dundee Biennial Conference in Numerical Analysis, D.F.
|
||||
Griffiths and G.A. Watson (Eds.), Addison Wesley Longman,
|
||||
Harlow, UK, pp. 191-208.
|
||||
|
||||
```
|
||||
|
||||
可以用 `lookfor` 来查询特定关键词相关的函数:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
np.lookfor("resize array")
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Search results for 'resize array'
|
||||
---------------------------------
|
||||
numpy.chararray.resize
|
||||
Change shape and size of array in-place.
|
||||
numpy.ma.resize
|
||||
Return a new masked array with the specified size and shape.
|
||||
numpy.oldnumeric.ma.resize
|
||||
The original array's total size can be any size.
|
||||
numpy.resize
|
||||
Return a new array with the specified shape.
|
||||
numpy.chararray
|
||||
chararray(shape, itemsize=1, unicode=False, buffer=None, offset=0,
|
||||
numpy.memmap
|
||||
Create a memory-map to an array stored in a *binary* file on disk.
|
||||
numpy.ma.mvoid.resize
|
||||
.. warning::
|
||||
|
||||
```
|
||||
|
||||
还可以指定查找的模块:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
np.lookfor("remove path", module="os")
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Search results for 'remove path'
|
||||
--------------------------------
|
||||
os.removedirs
|
||||
removedirs(path)
|
||||
os.walk
|
||||
Directory tree generator.
|
||||
|
||||
```
|
||||
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,336 @@
|
|||
# 稀疏矩阵
|
||||
|
||||
`Scipy` 提供了稀疏矩阵的支持(`scipy.sparse`)。
|
||||
|
||||
稀疏矩阵主要使用 位置 + 值 的方法来存储矩阵的非零元素,根据存储和使用方式的不同,有如下几种类型的稀疏矩阵:
|
||||
|
||||
| 类型 | 描述 |
|
||||
| --- | --- |
|
||||
| `bsr_matrix(arg1[, shape, dtype, copy, blocksize])` | Block Sparse Row matrix |
|
||||
| `coo_matrix(arg1[, shape, dtype, copy])` | A sparse matrix in COOrdinate format. |
|
||||
| `csc_matrix(arg1[, shape, dtype, copy])` | Compressed Sparse Column matrix |
|
||||
| `csr_matrix(arg1[, shape, dtype, copy])` | Compressed Sparse Row matrix |
|
||||
| `dia_matrix(arg1[, shape, dtype, copy])` | Sparse matrix with DIAgonal storage |
|
||||
| `dok_matrix(arg1[, shape, dtype, copy])` | Dictionary Of Keys based sparse matrix. |
|
||||
| `lil_matrix(arg1[, shape, dtype, copy])` | Row-based linked list sparse matrix |
|
||||
|
||||
在这些存储格式中:
|
||||
|
||||
* COO 格式在构建矩阵时比较高效
|
||||
* CSC 和 CSR 格式在乘法计算时比较高效
|
||||
|
||||
## 构建稀疏矩阵
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
from scipy.sparse import *
|
||||
import numpy as np
|
||||
|
||||
```
|
||||
|
||||
创建一个空的稀疏矩阵:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
coo_matrix((2,3))
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
<2x3 sparse matrix of type '<type 'numpy.float64'>'
|
||||
with 0 stored elements in COOrdinate format>
|
||||
```
|
||||
|
||||
也可以使用一个已有的矩阵或数组或列表中创建新矩阵:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
A = coo_matrix([[1,2,0],[0,0,3],[4,0,5]])
|
||||
print A
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(0, 0) 1
|
||||
(0, 1) 2
|
||||
(1, 2) 3
|
||||
(2, 0) 4
|
||||
(2, 2) 5
|
||||
|
||||
```
|
||||
|
||||
不同格式的稀疏矩阵可以相互转化:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
type(A)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
scipy.sparse.coo.coo_matrix
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
B = A.tocsr()
|
||||
type(B)
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
scipy.sparse.csr.csr_matrix
|
||||
```
|
||||
|
||||
可以转化为普通矩阵:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
C = A.todense()
|
||||
C
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
matrix([[1, 2, 0],
|
||||
[0, 0, 3],
|
||||
[4, 0, 5]])
|
||||
```
|
||||
|
||||
与向量的乘法:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
v = np.array([1,0,-1])
|
||||
A.dot(v)
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
array([ 1, -3, -1])
|
||||
```
|
||||
|
||||
还可以传入一个 `(data, (row, col))` 的元组来构建稀疏矩阵:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
I = np.array([0,3,1,0])
|
||||
J = np.array([0,3,1,2])
|
||||
V = np.array([4,5,7,9])
|
||||
A = coo_matrix((V,(I,J)),shape=(4,4))
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
print A
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(0, 0) 4
|
||||
(3, 3) 5
|
||||
(1, 1) 7
|
||||
(0, 2) 9
|
||||
|
||||
```
|
||||
|
||||
COO 格式的稀疏矩阵在构建的时候只是简单的将坐标和值加到后面,对于重复的坐标不进行处理:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
I = np.array([0,0,1,3,1,0,0])
|
||||
J = np.array([0,2,1,3,1,0,0])
|
||||
V = np.array([1,1,1,1,1,1,1])
|
||||
B = coo_matrix((V,(I,J)),shape=(4,4))
|
||||
print B
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(0, 0) 1
|
||||
(0, 2) 1
|
||||
(1, 1) 1
|
||||
(3, 3) 1
|
||||
(1, 1) 1
|
||||
(0, 0) 1
|
||||
(0, 0) 1
|
||||
|
||||
```
|
||||
|
||||
转换成 CSR 格式会自动将相同坐标的值合并:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
C = B.tocsr()
|
||||
print C
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(0, 0) 3
|
||||
(0, 2) 1
|
||||
(1, 1) 2
|
||||
(3, 3) 1
|
||||
|
||||
```
|
||||
|
||||
## 求解微分方程
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
from scipy.sparse import lil_matrix
|
||||
from scipy.sparse.linalg import spsolve
|
||||
from numpy.linalg import solve, norm
|
||||
from numpy.random import rand
|
||||
|
||||
```
|
||||
|
||||
构建 `1000 x 1000` 的稀疏矩阵:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
A = lil_matrix((1000, 1000))
|
||||
A[0, :100] = rand(100)
|
||||
A[1, 100:200] = A[0, :100]
|
||||
A.setdiag(rand(1000))
|
||||
|
||||
```
|
||||
|
||||
转化为 CSR 之后,用 `spsolve` 求解 $Ax=b$:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
A = A.tocsr()
|
||||
b = rand(1000)
|
||||
x = spsolve(A, b)
|
||||
|
||||
```
|
||||
|
||||
转化成正常数组之后求解:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
x_ = solve(A.toarray(), b)
|
||||
|
||||
```
|
||||
|
||||
查看误差:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
err = norm(x-x_)
|
||||
err
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
6.4310987107687431e-13
|
||||
```
|
||||
|
||||
## sparse.find 函数
|
||||
|
||||
返回一个三元组,表示稀疏矩阵中非零元素的 `(row, col, value)`:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
from scipy import sparse
|
||||
|
||||
row, col, val = sparse.find(C)
|
||||
print row, col, val
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[0 0 1 3] [0 2 1 3] [3 1 2 1]
|
||||
|
||||
```
|
||||
|
||||
## sparse.issparse 函数
|
||||
|
||||
查看一个对象是否为稀疏矩阵:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
sparse.issparse(B)
|
||||
|
||||
```
|
||||
|
||||
Out[18]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
sparse.isspmatrix(B.todense())
|
||||
|
||||
```
|
||||
|
||||
Out[19]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
|
||||
还可以查询是否为指定格式的稀疏矩阵:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
sparse.isspmatrix_coo(B)
|
||||
|
||||
```
|
||||
|
||||
Out[20]:
|
||||
|
||||
```py
|
||||
True
|
||||
```
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
sparse.isspmatrix_csr(B)
|
||||
|
||||
```
|
||||
|
||||
Out[21]:
|
||||
|
||||
```py
|
||||
False
|
||||
```
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,39 @@
|
|||
# 稀疏矩阵的线性代数
|
||||
|
||||
对于稀疏矩阵来说,其线性代数操作可以使用 `scipy.sparse.linalg` 实现:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import scipy.sparse.linalg
|
||||
|
||||
```
|
||||
|
||||
## 矩阵操作
|
||||
|
||||
* `scipy.sparse.linalg.inv`
|
||||
* 稀疏矩阵求逆
|
||||
* `scipy.sparse.linalg.expm`
|
||||
* 求稀疏矩阵的指数函数
|
||||
|
||||
## 矩阵范数
|
||||
|
||||
* `scipy.sparse.linalg.norm`
|
||||
* 稀疏矩阵求范数
|
||||
|
||||
## 线性方程组求解
|
||||
|
||||
提供了一系列求解方法: [http://docs.scipy.org/doc/scipy/reference/sparse.linalg.html#solving-linear-problems](http://docs.scipy.org/doc/scipy/reference/sparse.linalg.html#solving-linear-problems)
|
||||
|
||||
主要使用的是迭代方法求解。
|
||||
|
||||
## 特征值分解和奇异值分解
|
||||
|
||||
对于特别大的矩阵,原来的方法可能需要太大的内存,考虑使用这两个方法替代:
|
||||
|
||||
* `scipy.sparse.linalg.eigs`
|
||||
* 返回前 k 大的特征值和特征向量
|
||||
* `scipy.sparse.linalg.svds`
|
||||
* 返回前 k 大的奇异值和奇异向量
|
||||
|
||||
## <font color="red">所有的这些操作既可以在稀疏矩阵上使用,也可以在普通矩阵上使用。</font>
|
||||
|
|
@ -0,0 +1 @@
|
|||
# 05\. Python 进阶
|
||||
|
|
@ -0,0 +1,182 @@
|
|||
# sys 模块简介
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import sys
|
||||
|
||||
```
|
||||
|
||||
## 命令行参数
|
||||
|
||||
`sys.argv` 显示传入的参数:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
%%writefile print_args.py
|
||||
import sys
|
||||
print sys.argv
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing print_args.py
|
||||
|
||||
```
|
||||
|
||||
运行这个程序:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
%run print_args.py 1 foo
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['print_args.py', '1', 'foo']
|
||||
|
||||
```
|
||||
|
||||
第一个参数 (`sys.args[0]`) 表示的始终是执行的文件名,然后依次显示传入的参数。
|
||||
|
||||
删除刚才生成的文件:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('print_args.py')
|
||||
|
||||
```
|
||||
|
||||
## 异常消息
|
||||
|
||||
`sys.exc_info()` 可以显示 `Exception` 的信息,返回一个 `(type, value, traceback)` 组成的三元组,可以与 `try/catch` 块一起使用:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
try:
|
||||
x = 1/0
|
||||
except Exception:
|
||||
print sys.exc_info()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(<type 'exceptions.ZeroDivisionError'>, ZeroDivisionError('integer division or modulo by zero',), <traceback object at 0x0000000003C6FA08>)
|
||||
|
||||
```
|
||||
|
||||
`sys.exc_clear()` 用于清除所有的异常消息。
|
||||
|
||||
## 标准输入输出流
|
||||
|
||||
* sys.stdin
|
||||
* sys.stdout
|
||||
* sys.stderr
|
||||
|
||||
## 退出Python
|
||||
|
||||
`sys.exit(arg=0)` 用于退出 Python。`0` 或者 `None` 表示正常退出,其他值表示异常。
|
||||
|
||||
## Python Path
|
||||
|
||||
`sys.path` 表示 Python 搜索模块的路径和查找顺序:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
sys.path
|
||||
|
||||
```
|
||||
|
||||
Out[6]:
|
||||
|
||||
```py
|
||||
['',
|
||||
'C:\\Anaconda\\python27.zip',
|
||||
'C:\\Anaconda\\DLLs',
|
||||
'C:\\Anaconda\\lib',
|
||||
'C:\\Anaconda\\lib\\plat-win',
|
||||
'C:\\Anaconda\\lib\\lib-tk',
|
||||
'C:\\Anaconda',
|
||||
'C:\\Anaconda\\lib\\site-packages',
|
||||
'C:\\Anaconda\\lib\\site-packages\\Sphinx-1.3.1-py2.7.egg',
|
||||
'C:\\Anaconda\\lib\\site-packages\\cryptography-0.9.1-py2.7-win-amd64.egg',
|
||||
'C:\\Anaconda\\lib\\site-packages\\win32',
|
||||
'C:\\Anaconda\\lib\\site-packages\\win32\\lib',
|
||||
'C:\\Anaconda\\lib\\site-packages\\Pythonwin',
|
||||
'C:\\Anaconda\\lib\\site-packages\\setuptools-17.1.1-py2.7.egg',
|
||||
'C:\\Anaconda\\lib\\site-packages\\IPython\\extensions']
|
||||
```
|
||||
|
||||
在程序中可以修改,添加新的路径。
|
||||
|
||||
## 操作系统信息
|
||||
|
||||
`sys.platform` 显示当前操作系统信息:
|
||||
|
||||
* `Windows: win32`
|
||||
* `Mac OSX: darwin`
|
||||
* `Linux: linux2`
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
sys.platform
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
'win32'
|
||||
```
|
||||
|
||||
返回 `Windows` 操作系统的版本:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
sys.getwindowsversion()
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
sys.getwindowsversion(major=6, minor=2, build=9200, platform=2, service_pack='')
|
||||
```
|
||||
|
||||
标准库中有 `planform` 模块提供更详细的信息。
|
||||
|
||||
## Python 版本信息
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
sys.version
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
'2.7.10 |Anaconda 2.3.0 (64-bit)| (default, May 28 2015, 16:44:52) [MSC v.1500 64 bit (AMD64)]'
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
sys.version_info
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
sys.version_info(major=2, minor=7, micro=10, releaselevel='final', serial=0)
|
||||
```
|
||||
|
|
@ -0,0 +1,227 @@
|
|||
# 与操作系统进行交互:os 模块
|
||||
|
||||
`os` 模块提供了对系统文件进行操作的方法:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import os
|
||||
|
||||
```
|
||||
|
||||
## 文件路径操作
|
||||
|
||||
* `os.remove(path)` 或 `os.unlink(path)` :删除指定路径的文件。路径可以是全名,也可以是当前工作目录下的路径。
|
||||
* `os.removedirs`:删除文件,并删除中间路径中的空文件夹
|
||||
* `os.chdir(path)`:将当前工作目录改变为指定的路径
|
||||
* `os.getcwd()`:返回当前的工作目录
|
||||
* `os.curdir`:表示当前目录的符号
|
||||
* `os.rename(old, new)`:重命名文件
|
||||
* `os.renames(old, new)`:重命名文件,如果中间路径的文件夹不存在,则创建文件夹
|
||||
* `os.listdir(path)`:返回给定目录下的所有文件夹和文件名,不包括 `'.'` 和 `'..'` 以及子文件夹下的目录。(`'.'` 和 `'..'` 分别指当前目录和父目录)
|
||||
* `os.mkdir(name)`:产生新文件夹
|
||||
* `os.makedirs(name)`:产生新文件夹,如果中间路径的文件夹不存在,则创建文件夹
|
||||
|
||||
当前目录:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
os.getcwd()
|
||||
|
||||
```
|
||||
|
||||
Out[2]:
|
||||
|
||||
```py
|
||||
'/home/lijin/notes-python/05\. advanced python'
|
||||
```
|
||||
|
||||
当前目录的符号:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
os.curdir
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
'.'
|
||||
```
|
||||
|
||||
当前目录下的文件:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
os.listdir(os.curdir)
|
||||
|
||||
```
|
||||
|
||||
Out[4]:
|
||||
|
||||
```py
|
||||
['05.01 overview of the sys module.ipynb',
|
||||
'05.05 datetime.ipynb',
|
||||
'05.13 decorator usage.ipynb',
|
||||
'.ipynb_checkpoints',
|
||||
'05.03 comma separated values.ipynb',
|
||||
'05.02 interacting with the OS - os.ipynb',
|
||||
'05.10 generators.ipynb',
|
||||
'05.15 scope.ipynb',
|
||||
'05.12 decorators.ipynb',
|
||||
'05.09 iterators.ipynb',
|
||||
'my_database.sqlite',
|
||||
'05.11 context managers and the with statement.ipynb',
|
||||
'05.16 dynamic code execution.ipynb',
|
||||
'05.14 the operator functools itertools toolz fn funcy module.ipynb',
|
||||
'05.04 regular expression.ipynb',
|
||||
'05.07 object-relational mappers.ipynb',
|
||||
'05.08 functions.ipynb',
|
||||
'05.06 sql databases.ipynb']
|
||||
```
|
||||
|
||||
产生文件:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
f = open("test.file", "w")
|
||||
f.close()
|
||||
|
||||
print "test.file" in os.listdir(os.curdir)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
True
|
||||
|
||||
```
|
||||
|
||||
重命名文件:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
os.rename("test.file", "test.new.file")
|
||||
|
||||
print "test.file" in os.listdir(os.curdir)
|
||||
print "test.new.file" in os.listdir(os.curdir)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
False
|
||||
True
|
||||
|
||||
```
|
||||
|
||||
删除文件:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
os.remove("test.new.file")
|
||||
|
||||
```
|
||||
|
||||
## 系统常量
|
||||
|
||||
当前操作系统的换行符:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
# windows 为 \r\n
|
||||
os.linesep
|
||||
|
||||
```
|
||||
|
||||
Out[8]:
|
||||
|
||||
```py
|
||||
'\n'
|
||||
```
|
||||
|
||||
当前操作系统的路径分隔符:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
os.sep
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
'/'
|
||||
```
|
||||
|
||||
当前操作系统的环境变量中的分隔符(`';'` 或 `':'`):
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
os.pathsep
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
':'
|
||||
```
|
||||
|
||||
## 其他
|
||||
|
||||
`os.environ` 是一个存储所有环境变量的值的字典,可以修改。
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
os.environ["USER"]
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
'lijin'
|
||||
```
|
||||
|
||||
`os.urandom(len)` 返回指定长度的随机字节。
|
||||
|
||||
## os.path 模块
|
||||
|
||||
不同的操作系统使用不同的路径规范,这样当我们在不同的操作系统下进行操作时,可能会带来一定的麻烦,而 `os.path` 模块则帮我们解决了这个问题。
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
import os.path
|
||||
|
||||
```
|
||||
|
||||
### 测试
|
||||
|
||||
* `os.path.isfile(path)` :检测一个路径是否为普通文件
|
||||
* `os.path.isdir(path)`:检测一个路径是否为文件夹
|
||||
* `os.path.exists(path)`:检测路径是否存在
|
||||
* `os.path.isabs(path)`:检测路径是否为绝对路径
|
||||
|
||||
### split 和 join
|
||||
|
||||
* `os.path.split(path)`:拆分一个路径为 `(head, tail)` 两部分
|
||||
* `os.path.join(a, *p)`:使用系统的路径分隔符,将各个部分合成一个路径
|
||||
|
||||
### 其他
|
||||
|
||||
* `os.path.abspath()`:返回路径的绝对路径
|
||||
* `os.path.dirname(path)`:返回路径中的文件夹部分
|
||||
* `os.path.basename(path)`:返回路径中的文件部分
|
||||
* `os.path.slitext(path)`:将路径与扩展名分开
|
||||
* `os.path.expanduser(path)`:展开 `'~'` 和 `'~user'`
|
||||
|
|
@ -0,0 +1,250 @@
|
|||
# CSV 文件和 csv 模块
|
||||
|
||||
标准库中有自带的 `csv` (逗号分隔值) 模块处理 `csv` 格式的文件:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import csv
|
||||
|
||||
```
|
||||
|
||||
## 读 csv 文件
|
||||
|
||||
假设我们有这样的一个文件:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
%%file data.csv
|
||||
"alpha 1", 100, -1.443
|
||||
"beat 3", 12, -0.0934
|
||||
"gamma 3a", 192, -0.6621
|
||||
"delta 2a", 15, -4.515
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing data.csv
|
||||
|
||||
```
|
||||
|
||||
打开这个文件,并产生一个文件 reader:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
fp = open("data.csv")
|
||||
r = csv.reader(fp)
|
||||
|
||||
```
|
||||
|
||||
可以按行迭代数据:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
for row in r:
|
||||
print row
|
||||
|
||||
fp.close()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['alpha 1', ' 100', ' -1.443']
|
||||
['beat 3', ' 12', ' -0.0934']
|
||||
['gamma 3a', ' 192', ' -0.6621']
|
||||
['delta 2a', ' 15', ' -4.515']
|
||||
|
||||
```
|
||||
|
||||
默认数据内容都被当作字符串处理,不过可以自己进行处理:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
data = []
|
||||
|
||||
with open('data.csv') as fp:
|
||||
r = csv.reader(fp)
|
||||
for row in r:
|
||||
data.append([row[0], int(row[1]), float(row[2])])
|
||||
|
||||
data
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
[['alpha 1', 100, -1.443],
|
||||
['beat 3', 12, -0.0934],
|
||||
['gamma 3a', 192, -0.6621],
|
||||
['delta 2a', 15, -4.515]]
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('data.csv')
|
||||
|
||||
```
|
||||
|
||||
## 写 csv 文件
|
||||
|
||||
可以使用 `csv.writer` 写入文件,不过相应地,传入的应该是以写方式打开的文件,不过一般要用 `'wb'` 即二进制写入方式,防止出现换行不正确的问题:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
data = [('one', 1, 1.5), ('two', 2, 8.0)]
|
||||
with open('out.csv', 'wb') as fp:
|
||||
w = csv.writer(fp)
|
||||
w.writerows(data)
|
||||
|
||||
```
|
||||
|
||||
显示结果:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
!cat 'out.csv'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
one,1,1.5
|
||||
two,2,8.0
|
||||
|
||||
```
|
||||
|
||||
## 更换分隔符
|
||||
|
||||
默认情况下,`csv` 模块默认 `csv` 文件都是由 `excel` 产生的,实际中可能会遇到这样的问题:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
data = [('one, \"real\" string', 1, 1.5), ('two', 2, 8.0)]
|
||||
with open('out.csv', 'wb') as fp:
|
||||
w = csv.writer(fp)
|
||||
w.writerows(data)
|
||||
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
!cat 'out.csv'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
"one, ""real"" string",1,1.5
|
||||
two,2,8.0
|
||||
|
||||
```
|
||||
|
||||
可以修改分隔符来处理这组数据:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
data = [('one, \"real\" string', 1, 1.5), ('two', 2, 8.0)]
|
||||
with open('out.psv', 'wb') as fp:
|
||||
w = csv.writer(fp, delimiter="|")
|
||||
w.writerows(data)
|
||||
|
||||
```
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
!cat 'out.psv'
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
"one, ""real"" string"|1|1.5
|
||||
two|2|8.0
|
||||
|
||||
```
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('out.psv')
|
||||
os.remove('out.csv')
|
||||
|
||||
```
|
||||
|
||||
## 其他选项
|
||||
|
||||
`numpy.loadtxt()` 和 `pandas.read_csv()` 可以用来读写包含很多数值数据的 `csv` 文件:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
%%file trades.csv
|
||||
Order,Date,Stock,Quantity,Price
|
||||
A0001,2013-12-01,AAPL,1000,203.4
|
||||
A0002,2013-12-01,MSFT,1500,167.5
|
||||
A0003,2013-12-02,GOOG,1500,167.5
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing trades.csv
|
||||
|
||||
```
|
||||
|
||||
使用 `pandas` 进行处理,生成一个 `DataFrame` 对象:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
import pandas
|
||||
df = pandas.read_csv('trades.csv', index_col=0)
|
||||
print df
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Date Stock Quantity Price
|
||||
Order
|
||||
A0001 2013-12-01 AAPL 1000 203.4
|
||||
A0002 2013-12-01 MSFT 1500 167.5
|
||||
A0003 2013-12-02 GOOG 1500 167.5
|
||||
|
||||
```
|
||||
|
||||
通过名字进行索引:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
df['Quantity'] * df['Price']
|
||||
|
||||
```
|
||||
|
||||
Out[16]:
|
||||
|
||||
```py
|
||||
Order
|
||||
A0001 203400
|
||||
A0002 251250
|
||||
A0003 251250
|
||||
dtype: float64
|
||||
```
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('trades.csv')
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,271 @@
|
|||
# 正则表达式和 re 模块
|
||||
|
||||
## 正则表达式
|
||||
|
||||
[正则表达式](http://baike.baidu.com/view/94238.htm)是用来匹配字符串或者子串的一种模式,匹配的字符串可以很具体,也可以很一般化。
|
||||
|
||||
`Python` 标准库提供了 `re` 模块。
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import re
|
||||
|
||||
```
|
||||
|
||||
## re.match & re.search
|
||||
|
||||
在 `re` 模块中, `re.match` 和 `re.search` 是常用的两个方法:
|
||||
|
||||
```py
|
||||
re.match(pattern, string[, flags])
|
||||
re.search(pattern, string[, flags])
|
||||
```
|
||||
|
||||
两者都寻找第一个匹配成功的部分,成功则返回一个 `match` 对象,不成功则返回 `None`,不同之处在于 `re.match` 只匹配字符串的开头部分,而 `re.search` 匹配的则是整个字符串中的子串。
|
||||
|
||||
## re.findall & re.finditer
|
||||
|
||||
`re.findall(pattern, string)` 返回所有匹配的对象, `re.finditer` 则返回一个迭代器。
|
||||
|
||||
## re.split
|
||||
|
||||
`re.split(pattern, string[, maxsplit])` 按照 `pattern` 指定的内容对字符串进行分割。
|
||||
|
||||
## re.sub
|
||||
|
||||
`re.sub(pattern, repl, string[, count])` 将 `pattern` 匹配的内容进行替换。
|
||||
|
||||
## re.compile
|
||||
|
||||
`re.compile(pattern)` 生成一个 `pattern` 对象,这个对象有匹配,替换,分割字符串的方法。
|
||||
|
||||
## 正则表达式规则
|
||||
|
||||
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义:
|
||||
|
||||
| 子表达式 | 匹配内容 |
|
||||
| --- | --- |
|
||||
| `.` | 匹配除了换行符之外的内容 |
|
||||
| `\w` | 匹配所有字母和数字字符 |
|
||||
| `\d` | 匹配所有数字,相当于 `[0-9]` |
|
||||
| `\s` | 匹配空白,相当于 `[\t\n\t\f\v]` |
|
||||
| `\W,\D,\S` | 匹配对应小写字母形式的补 |
|
||||
| `[...]` | 表示可以匹配的集合,支持范围表示如 `a-z`, `0-9` 等 |
|
||||
| `(...)` | 表示作为一个整体进行匹配 |
|
||||
| ¦ | 表示逻辑或 |
|
||||
| `^` | 表示匹配后面的子表达式的补 |
|
||||
| `*` | 表示匹配前面的子表达式 0 次或更多次 |
|
||||
| `+` | 表示匹配前面的子表达式 1 次或更多次 |
|
||||
| `?` | 表示匹配前面的子表达式 0 次或 1 次 |
|
||||
| `{m}` | 表示匹配前面的子表达式 m 次 |
|
||||
| `{m,}` | 表示匹配前面的子表达式至少 m 次 |
|
||||
| `{m,n}` | 表示匹配前面的子表达式至少 m 次,至多 n 次 |
|
||||
|
||||
例如:
|
||||
|
||||
* `ca*t 匹配: ct, cat, caaaat, ...`
|
||||
* `ab\d|ac\d 匹配: ab1, ac9, ...`
|
||||
* `([^a-q]bd) 匹配: rbd, 5bd, ...`
|
||||
|
||||
## 例子
|
||||
|
||||
假设我们要匹配这样的字符串:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
string = 'hello world'
|
||||
pattern = 'hello (\w+)'
|
||||
|
||||
match = re.match(pattern, string)
|
||||
print match
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<_sre.SRE_Match object at 0x0000000003A5DA80>
|
||||
|
||||
```
|
||||
|
||||
一旦找到了符合条件的部分,我们便可以使用 `group` 方法查看匹配的部分:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
if match is not None:
|
||||
print match.group(0)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello world
|
||||
|
||||
```
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
if match is not None:
|
||||
print match.group(1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
world
|
||||
|
||||
```
|
||||
|
||||
我们可以改变 string 的内容:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
string = 'hello there'
|
||||
pattern = 'hello (\w+)'
|
||||
|
||||
match = re.match(pattern, string)
|
||||
if match is not None:
|
||||
print match.group(0)
|
||||
print match.group(1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
hello there
|
||||
there
|
||||
|
||||
```
|
||||
|
||||
通常,`match.group(0)` 匹配整个返回的内容,之后的 `1,2,3,...` 返回规则中每个括号(按照括号的位置排序)匹配的部分。
|
||||
|
||||
如果某个 `pattern` 需要反复使用,那么我们可以将它预先编译:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
pattern1 = re.compile('hello (\w+)')
|
||||
|
||||
match = pattern1.match(string)
|
||||
if match is not None:
|
||||
print match.group(1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
there
|
||||
|
||||
```
|
||||
|
||||
由于元字符的存在,所以对于一些特殊字符,我们需要使用 `'\'` 进行逃逸字符的处理,使用表达式 `'\\'` 来匹配 `'\'` 。
|
||||
|
||||
但事实上,`Python` 本身对逃逸字符也是这样处理的:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
pattern = '\\'
|
||||
print pattern
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
\
|
||||
|
||||
```
|
||||
|
||||
因为逃逸字符的问题,我们需要使用四个 `'\\\\'` 来匹配一个单独的 `'\'`:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
pattern = '\\\\'
|
||||
path = "C:\\foo\\bar\\baz.txt"
|
||||
print re.split(pattern, path)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['C:', 'foo', 'bar', 'baz.txt']
|
||||
|
||||
```
|
||||
|
||||
这样看起来十分麻烦,好在 `Python` 提供了 `raw string` 来忽略对逃逸字符串的处理,从而可以这样进行匹配:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
pattern = r'\\'
|
||||
path = r"C:\foo\bar\baz.txt"
|
||||
print re.split(pattern, path)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
['C:', 'foo', 'bar', 'baz.txt']
|
||||
|
||||
```
|
||||
|
||||
如果规则太多复杂,正则表达式不一定是个好选择。
|
||||
|
||||
## Numpy 的 fromregex()
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
%%file test.dat
|
||||
1312 foo
|
||||
1534 bar
|
||||
444 qux
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Writing test.dat
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
fromregex(file, pattern, dtype)
|
||||
```
|
||||
|
||||
`dtype` 中的内容与 `pattern` 的括号一一对应:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
pattern = "(\d+)\s+(...)"
|
||||
dt = [('num', 'int64'), ('key', 'S3')]
|
||||
|
||||
from numpy import fromregex
|
||||
output = fromregex('test.dat', pattern, dt)
|
||||
print output
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[(1312L, 'foo') (1534L, 'bar') (444L, 'qux')]
|
||||
|
||||
```
|
||||
|
||||
显示 `num` 项:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
print output['num']
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1312 1534 444]
|
||||
|
||||
```
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('test.dat')
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,187 @@
|
|||
# datetime 模块
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import datetime as dt
|
||||
|
||||
```
|
||||
|
||||
`datetime` 提供了基础时间和日期的处理。
|
||||
|
||||
## date 对象
|
||||
|
||||
可以使用 `date(year, month, day)` 产生一个 `date` 对象:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
d1 = dt.date(2007, 9, 25)
|
||||
d2 = dt.date(2008, 9, 25)
|
||||
|
||||
```
|
||||
|
||||
可以格式化 `date` 对象的输出:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
print d1
|
||||
print d1.strftime('%A, %m/%d/%y')
|
||||
print d1.strftime('%a, %m-%d-%Y')
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2007-09-25
|
||||
Tuesday, 09/25/07
|
||||
Tue, 09-25-2007
|
||||
|
||||
```
|
||||
|
||||
可以看两个日期相差多久:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
print d2 - d1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
366 days, 0:00:00
|
||||
|
||||
```
|
||||
|
||||
返回的是一个 `timedelta` 对象:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
d = d2 - d1
|
||||
print d.days
|
||||
print d.seconds
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
366
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
查看今天的日期:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
print dt.date.today()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2015-09-10
|
||||
|
||||
```
|
||||
|
||||
## time 对象
|
||||
|
||||
可以使用 `time(hour, min, sec, us)` 产生一个 `time` 对象:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
t1 = dt.time(15, 38)
|
||||
t2 = dt.time(18)
|
||||
|
||||
```
|
||||
|
||||
改变显示格式:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
print t1
|
||||
print t1.strftime('%I:%M, %p')
|
||||
print t1.strftime('%H:%M:%S, %p')
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
15:38:00
|
||||
03:38, PM
|
||||
15:38:00, PM
|
||||
|
||||
```
|
||||
|
||||
因为没有具体的日期信息,所以 `time` 对象不支持减法操作。
|
||||
|
||||
## datetime 对象
|
||||
|
||||
可以使用 `datetime(year, month, day, hr, min, sec, us)` 来创建一个 `datetime` 对象。
|
||||
|
||||
获得当前时间:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
d1 = dt.datetime.now()
|
||||
print d1
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2015-09-10 20:58:50.148000
|
||||
|
||||
```
|
||||
|
||||
给当前的时间加上 `30` 天,`timedelta` 的参数是 `timedelta(day, hr, min, sec, us)`:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
d2 = d1 + dt.timedelta(30)
|
||||
print d2
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2015-10-10 20:58:50.148000
|
||||
|
||||
```
|
||||
|
||||
除此之外,我们还可以通过一些指定格式的字符串来创建 `datetime` 对象:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
print dt.datetime.strptime('2/10/01', '%m/%d/%y')
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2001-02-10 00:00:00
|
||||
|
||||
```
|
||||
|
||||
## datetime 格式字符表
|
||||
|
||||
| 字符 | 含义 |
|
||||
| --- | --- |
|
||||
| `%a` | 星期英文缩写 |
|
||||
| `%A` | 星期英文 |
|
||||
| `%w` | 一星期的第几天,`[0(sun),6]` |
|
||||
| `%b` | 月份英文缩写 |
|
||||
| `%B` | 月份英文 |
|
||||
| `%d` | 日期,`[01,31]` |
|
||||
| `%H` | 小时,`[00,23]` |
|
||||
| `%I` | 小时,`[01,12]` |
|
||||
| `%j` | 一年的第几天,`[001,366]` |
|
||||
| `%m` | 月份,`[01,12]` |
|
||||
| `%M` | 分钟,`[00,59]` |
|
||||
| `%p` | AM 和 PM |
|
||||
| `%S` | 秒钟,`[00,61]` (大概是有闰秒的存在) |
|
||||
| `%U` | 一年中的第几个星期,星期日为第一天,`[00,53]` |
|
||||
| `%W` | 一年中的第几个星期,星期一为第一天,`[00,53]` |
|
||||
| `%y` | 没有世纪的年份 |
|
||||
| `%Y` | 完整的年份 |
|
||||
|
|
@ -0,0 +1,143 @@
|
|||
# SQL 数据库
|
||||
|
||||
`Python` 提供了一系列标准的数据库的 API,这里我们介绍 sqlite 数据库的用法,其他的数据库的用法大同小异:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
import sqlite3 as db
|
||||
|
||||
```
|
||||
|
||||
首先我们要建立或者连接到一个数据库上:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
connection = db.connect("my_database.sqlite")
|
||||
|
||||
```
|
||||
|
||||
不同的数据库有着不同的连接方法,例如 cx-oracle 数据库的链接方式为:
|
||||
|
||||
```py
|
||||
connection = db.connect(username, password, host, port, 'XE')
|
||||
```
|
||||
|
||||
一旦建立连接,我们可以利用它的 `cursor()` 来执行 SQL 语句:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
cursor = connection.cursor()
|
||||
cursor.execute("""CREATE TABLE IF NOT EXISTS orders(
|
||||
order_id TEXT PRIMARY KEY,
|
||||
date TEXT,
|
||||
symbol TEXT,
|
||||
quantity INTEGER,
|
||||
price NUMBER)""")
|
||||
cursor.execute("""INSERT INTO orders VALUES
|
||||
('A0001', '2013-12-01', 'AAPL', 1000, 203.4)""")
|
||||
connection.commit()
|
||||
|
||||
```
|
||||
|
||||
不过为了安全起见,一般不将数据内容写入字符串再传入,而是使用这样的方式:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
orders = [
|
||||
("A0002","2013-12-01","MSFT",1500,167.5),
|
||||
("A0003","2013-12-02","GOOG",1500,167.5)
|
||||
]
|
||||
cursor.executemany("""INSERT INTO orders VALUES
|
||||
(?, ?, ?, ?, ?)""", orders)
|
||||
connection.commit()
|
||||
|
||||
```
|
||||
|
||||
cx-oracle 数据库使用不同的方式:
|
||||
|
||||
```py
|
||||
cursor.executemany("""INSERT INTO orders VALUES
|
||||
(:order_id, :date, :symbol, :quantity, :price)""",
|
||||
orders)
|
||||
```
|
||||
|
||||
查看支持的数据库格式:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
db.paramstyle
|
||||
|
||||
```
|
||||
|
||||
Out[5]:
|
||||
|
||||
```py
|
||||
'qmark'
|
||||
```
|
||||
|
||||
在 `query` 语句执行之后,我们需要进行 `commit`,否则数据库将不会接受这些变化,如果想撤销某个 `commit`,可以使用 `rollback()` 方法撤销到上一次 `commit()` 的结果:
|
||||
|
||||
```py
|
||||
try:
|
||||
... # perform some operations
|
||||
except:
|
||||
connection.rollback()
|
||||
raise
|
||||
else:
|
||||
connection.commit()
|
||||
```
|
||||
|
||||
使用 `SELECT` 语句对数据库进行查询:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
stock = 'MSFT'
|
||||
cursor.execute("""SELECT *
|
||||
FROM orders
|
||||
WHERE symbol=?
|
||||
ORDER BY quantity""", (stock,))
|
||||
for row in cursor:
|
||||
print row
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(u'A0002', u'2013-12-01', u'MSFT', 1500, 167.5)
|
||||
|
||||
```
|
||||
|
||||
`cursor.fetchone()` 返回下一条内容, `cursor.fetchall()` 返回所有查询到的内容组成的列表(可能非常大):
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
stock = 'AAPL'
|
||||
cursor.execute("""SELECT *
|
||||
FROM orders
|
||||
WHERE symbol=?
|
||||
ORDER BY quantity""", (stock,))
|
||||
cursor.fetchall()
|
||||
|
||||
```
|
||||
|
||||
Out[7]:
|
||||
|
||||
```py
|
||||
[(u'A0001', u'2013-12-01', u'AAPL', 1000, 203.4)]
|
||||
```
|
||||
|
||||
关闭数据库:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
cursor.close()
|
||||
connection.close()
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,149 @@
|
|||
# 对象关系映射
|
||||
|
||||
数据库中的记录可以与一个 `Python` 对象对应。
|
||||
|
||||
例如对于上一节中的数据库:
|
||||
|
||||
| Order | Date | Stock | Quantity | Price |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| A0001 | 2013-12-01 | AAPL | 1000 | 203.4 |
|
||||
| A0002 | 2013-12-01 | MSFT | 1500 | 167.5 |
|
||||
| A0003 | 2013-12-02 | GOOG | 1500 | 167.5 |
|
||||
|
||||
可以用一个类来描述:
|
||||
|
||||
| Attr. | Method |
|
||||
| --- | --- |
|
||||
| Order id | Cost |
|
||||
| Date | |
|
||||
| Stock | |
|
||||
| Quant. | |
|
||||
| Price | |
|
||||
|
||||
可以使用 `sqlalchemy` 来实现这种对应:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
from sqlalchemy import Column, Date, Float, Integer, String
|
||||
|
||||
Base = declarative_base()
|
||||
|
||||
class Order(Base):
|
||||
__tablename__ = 'orders'
|
||||
|
||||
order_id = Column(String, primary_key=True)
|
||||
date = Column(Date)
|
||||
symbol = Column(String)
|
||||
quantity = Column(Integer)
|
||||
price = Column(Float)
|
||||
|
||||
def get_cost(self):
|
||||
return self.quantity*self.price
|
||||
|
||||
```
|
||||
|
||||
生成一个 `Order` 对象:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
import datetime
|
||||
order = Order(order_id='A0004', date=datetime.date.today(), symbol='MSFT', quantity=-1000, price=187.54)
|
||||
|
||||
```
|
||||
|
||||
调用方法:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
order.get_cost()
|
||||
|
||||
```
|
||||
|
||||
Out[3]:
|
||||
|
||||
```py
|
||||
-187540.0
|
||||
```
|
||||
|
||||
使用上一节生成的数据库产生一个 `session`:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
from sqlalchemy import create_engine
|
||||
from sqlalchemy.orm import sessionmaker
|
||||
|
||||
engine = create_engine("sqlite:///my_database.sqlite") # 相当于 connection
|
||||
Session = sessionmaker(bind=engine) # 相当于 cursor
|
||||
session = Session()
|
||||
|
||||
```
|
||||
|
||||
使用这个 `session` 向数据库中添加刚才生成的对象:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
session.add(order)
|
||||
session.commit()
|
||||
|
||||
```
|
||||
|
||||
显示是否添加成功:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
for row in engine.execute("SELECT * FROM orders"):
|
||||
print row
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
(u'A0001', u'2013-12-01', u'AAPL', 1000, 203.4)
|
||||
(u'A0002', u'2013-12-01', u'MSFT', 1500, 167.5)
|
||||
(u'A0003', u'2013-12-02', u'GOOG', 1500, 167.5)
|
||||
(u'A0004', u'2015-09-10', u'MSFT', -1000, 187.54)
|
||||
|
||||
```
|
||||
|
||||
使用 `filter` 进行查询,返回的是 `Order` 对象的列表:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
for order in session.query(Order).filter(Order.symbol=="AAPL"):
|
||||
print order.order_id, order.date, order.get_cost()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
A0001 2013-12-01 203400.0
|
||||
|
||||
```
|
||||
|
||||
返回列表的第一个:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
order_2 = session.query(Order).filter(Order.order_id=='A0002').first()
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
order_2.symbol
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
u'MSFT'
|
||||
```
|
||||
|
|
@ -0,0 +1,535 @@
|
|||
# 函数进阶:参数传递,高阶函数,lambda 匿名函数,global 变量,递归
|
||||
|
||||
## 函数是基本类型
|
||||
|
||||
在 `Python` 中,函数是一种基本类型的对象,这意味着
|
||||
|
||||
* 可以将函数作为参数传给另一个函数
|
||||
* 将函数作为字典的值储存
|
||||
* 将函数作为另一个函数的返回值
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
def square(x):
|
||||
"""Square of x."""
|
||||
return x*x
|
||||
|
||||
def cube(x):
|
||||
"""Cube of x."""
|
||||
return x*x*x
|
||||
|
||||
```
|
||||
|
||||
作为字典的值:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
funcs = {
|
||||
'square': square,
|
||||
'cube': cube,
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
x = 2
|
||||
|
||||
print square(x)
|
||||
print cube(x)
|
||||
|
||||
for func in sorted(funcs):
|
||||
print func, funcs[func](x)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4
|
||||
8
|
||||
cube 8
|
||||
square 4
|
||||
|
||||
```
|
||||
|
||||
## 函数参数
|
||||
|
||||
### 引用传递
|
||||
|
||||
`Python` 中的函数传递方式是 `call by reference` 即引用传递,例如,对于这样的用法:
|
||||
|
||||
```py
|
||||
x = [10, 11, 12]
|
||||
f(x)
|
||||
```
|
||||
|
||||
传递给函数 `f` 的是一个指向 `x` 所包含内容的引用,如果我们修改了这个引用所指向内容的值(例如 `x[0]=999`),那么外面的 `x` 的值也会被改变。不过如果我们在函数中赋给 `x` 一个新的值(例如另一个列表),那么在函数外面的 `x` 的值不会改变:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
def mod_f(x):
|
||||
x[0] = 999
|
||||
return x
|
||||
|
||||
x = [1, 2, 3]
|
||||
|
||||
print x
|
||||
print mod_f(x)
|
||||
print x
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2, 3]
|
||||
[999, 2, 3]
|
||||
[999, 2, 3]
|
||||
|
||||
```
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
def no_mod_f(x):
|
||||
x = [4, 5, 6]
|
||||
return x
|
||||
|
||||
x = [1,2,3]
|
||||
|
||||
print x
|
||||
print no_mod_f(x)
|
||||
print x
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 2, 3]
|
||||
[4, 5, 6]
|
||||
[1, 2, 3]
|
||||
|
||||
```
|
||||
|
||||
### 默认参数是可变的!
|
||||
|
||||
函数可以传递默认参数,默认参数的绑定发生在函数定义的时候,以后每次调用默认参数时都会使用同一个引用。
|
||||
|
||||
这样的机制会导致这种情况的发生:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
def f(x = []):
|
||||
x.append(1)
|
||||
return x
|
||||
|
||||
```
|
||||
|
||||
理论上说,我们希望调用 `f()` 时返回的是 `[1]`, 但事实上:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
print f()
|
||||
print f()
|
||||
print f()
|
||||
print f(x = [9,9,9])
|
||||
print f()
|
||||
print f()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1]
|
||||
[1, 1]
|
||||
[1, 1, 1]
|
||||
[9, 9, 9, 1]
|
||||
[1, 1, 1, 1]
|
||||
[1, 1, 1, 1, 1]
|
||||
|
||||
```
|
||||
|
||||
而我们希望看到的应该是这样:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
def f(x = None):
|
||||
if x is None:
|
||||
x = []
|
||||
x.append(1)
|
||||
return x
|
||||
|
||||
print f()
|
||||
print f()
|
||||
print f()
|
||||
print f(x = [9,9,9])
|
||||
print f()
|
||||
print f()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1]
|
||||
[1]
|
||||
[1]
|
||||
[9, 9, 9, 1]
|
||||
[1]
|
||||
[1]
|
||||
|
||||
```
|
||||
|
||||
## 高阶函数
|
||||
|
||||
以函数作为参数,或者返回一个函数的函数是高阶函数,常用的例子有 `map` 和 `filter` 函数:
|
||||
|
||||
`map(f, sq)` 函数将 `f` 作用到 `sq` 的每个元素上去,并返回结果组成的列表,相当于:
|
||||
|
||||
```py
|
||||
[f(s) for s in sq]
|
||||
|
||||
```
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
map(square, range(5))
|
||||
|
||||
```
|
||||
|
||||
Out[9]:
|
||||
|
||||
```py
|
||||
[0, 1, 4, 9, 16]
|
||||
```
|
||||
|
||||
`filter(f, sq)` 函数的作用相当于,对于 `sq` 的每个元素 `s`,返回所有 `f(s)` 为 `True` 的 `s` 组成的列表,相当于:
|
||||
|
||||
```py
|
||||
[s for s in sq if f(s)]
|
||||
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
def is_even(x):
|
||||
return x % 2 == 0
|
||||
|
||||
filter(is_even, range(5))
|
||||
|
||||
```
|
||||
|
||||
Out[10]:
|
||||
|
||||
```py
|
||||
[0, 2, 4]
|
||||
```
|
||||
|
||||
一起使用:
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
map(square, filter(is_even, range(5)))
|
||||
|
||||
```
|
||||
|
||||
Out[11]:
|
||||
|
||||
```py
|
||||
[0, 4, 16]
|
||||
```
|
||||
|
||||
`reduce(f, sq)` 函数接受一个二元操作函数 `f(x,y)`,并对于序列 `sq` 每次合并两个元素:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
def my_add(x, y):
|
||||
return x + y
|
||||
|
||||
reduce(my_add, [1,2,3,4,5])
|
||||
|
||||
```
|
||||
|
||||
Out[12]:
|
||||
|
||||
```py
|
||||
15
|
||||
```
|
||||
|
||||
传入加法函数,相当于对序列求和。
|
||||
|
||||
返回一个函数:
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
def make_logger(target):
|
||||
def logger(data):
|
||||
with open(target, 'a') as f:
|
||||
f.write(data + '\n')
|
||||
return logger
|
||||
|
||||
foo_logger = make_logger('foo.txt')
|
||||
foo_logger('Hello')
|
||||
foo_logger('World')
|
||||
|
||||
```
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
!cat foo.txt
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
Hello
|
||||
World
|
||||
|
||||
```
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
import os
|
||||
os.remove('foo.txt')
|
||||
|
||||
```
|
||||
|
||||
## 匿名函数
|
||||
|
||||
在使用 `map`, `filter`,`reduce` 等函数的时候,为了方便,对一些简单的函数,我们通常使用匿名函数的方式进行处理,其基本形式是:
|
||||
|
||||
```py
|
||||
lambda <variables>: <expression>
|
||||
```
|
||||
|
||||
例如,我们可以将这个:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
print map(square, range(5))
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[0, 1, 4, 9, 16]
|
||||
|
||||
```
|
||||
|
||||
用匿名函数替换为:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
print map(lambda x: x * x, range(5))
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[0, 1, 4, 9, 16]
|
||||
|
||||
```
|
||||
|
||||
匿名函数虽然写起来比较方便(省去了定义函数的烦恼),但是有时候会比较难于阅读:
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
s1 = reduce(lambda x, y: x+y, map(lambda x: x**2, range(1,10)))
|
||||
print(s1)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
285
|
||||
|
||||
```
|
||||
|
||||
当然,更简单地,我们可以写成这样:
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
s2 = sum(x**2 for x in range(1, 10))
|
||||
print s2
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
285
|
||||
|
||||
```
|
||||
|
||||
# global 变量
|
||||
|
||||
一般来说,函数中是可以直接使用全局变量的值的:
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
x = 15
|
||||
|
||||
def print_x():
|
||||
print x
|
||||
|
||||
print_x()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
15
|
||||
|
||||
```
|
||||
|
||||
但是要在函数中修改全局变量的值,需要加上 `global` 关键字:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
x = 15
|
||||
|
||||
def print_newx():
|
||||
global x
|
||||
x = 18
|
||||
print x
|
||||
|
||||
print_newx()
|
||||
|
||||
print x
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
18
|
||||
18
|
||||
|
||||
```
|
||||
|
||||
如果不加上这句 `global` 那么全局变量的值不会改变:
|
||||
|
||||
In [22]:
|
||||
|
||||
```py
|
||||
x = 15
|
||||
|
||||
def print_newx():
|
||||
x = 18
|
||||
print x
|
||||
|
||||
print_newx()
|
||||
|
||||
print x
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
18
|
||||
15
|
||||
|
||||
```
|
||||
|
||||
## 递归
|
||||
|
||||
递归是指函数在执行的过程中调用了本身,一般用于分治法,不过在 `Python` 中这样的用法十分地小,所以一般不怎么使用:
|
||||
|
||||
Fibocacci 数列:
|
||||
|
||||
In [23]:
|
||||
|
||||
```py
|
||||
def fib1(n):
|
||||
"""Fib with recursion."""
|
||||
|
||||
# base case
|
||||
if n==0 or n==1:
|
||||
return 1
|
||||
# recurssive caae
|
||||
else:
|
||||
return fib1(n-1) + fib1(n-2)
|
||||
|
||||
print [fib1(i) for i in range(10)]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
|
||||
|
||||
```
|
||||
|
||||
一个更高效的非递归版本:
|
||||
|
||||
In [24]:
|
||||
|
||||
```py
|
||||
def fib2(n):
|
||||
"""Fib without recursion."""
|
||||
a, b = 0, 1
|
||||
for i in range(1, n+1):
|
||||
a, b = b, a+b
|
||||
return b
|
||||
|
||||
print [fib2(i) for i in range(10)]
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
|
||||
|
||||
```
|
||||
|
||||
速度比较:
|
||||
|
||||
In [25]:
|
||||
|
||||
```py
|
||||
%timeit fib1(20)
|
||||
%timeit fib2(20)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
100 loops, best of 3: 5.35 ms per loop
|
||||
100000 loops, best of 3: 2.2 µs per loop
|
||||
|
||||
```
|
||||
|
||||
对于第一个递归函数来说,调用 `fib(n+2)` 的时候计算 `fib(n+1), fib(n)`,调用 `fib(n+1)` 的时候也计算了一次 `fib(n)`,这样造成了重复计算。
|
||||
|
||||
使用缓存机制的递归版本,这里利用了默认参数可变的性质,构造了一个缓存:
|
||||
|
||||
In [26]:
|
||||
|
||||
```py
|
||||
def fib3(n, cache={0: 1, 1: 1}):
|
||||
"""Fib with recursion and caching."""
|
||||
|
||||
try:
|
||||
return cache[n]
|
||||
except KeyError:
|
||||
cache[n] = fib3(n-1) + fib3(n-2)
|
||||
return cache[n]
|
||||
|
||||
print [fib3(i) for i in range(10)]
|
||||
|
||||
%timeit fib1(20)
|
||||
%timeit fib2(20)
|
||||
%timeit fib3(20)
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
|
||||
100 loops, best of 3: 5.37 ms per loop
|
||||
100000 loops, best of 3: 2.19 µs per loop
|
||||
The slowest run took 150.16 times longer than the fastest. This could mean that an intermediate result is being cached
|
||||
1000000 loops, best of 3: 230 ns per loop
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,379 @@
|
|||
# 迭代器
|
||||
|
||||
## 简介
|
||||
|
||||
迭代器对象可以在 `for` 循环中使用:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
x = [2, 4, 6]
|
||||
|
||||
for n in x:
|
||||
print n
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2
|
||||
4
|
||||
6
|
||||
|
||||
```
|
||||
|
||||
其好处是不需要对下标进行迭代,但是有些情况下,我们既希望获得下标,也希望获得对应的值,那么可以将迭代器传给 `enumerate` 函数,这样每次迭代都会返回一组 `(index, value)` 组成的元组:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
x = [2, 4, 6]
|
||||
|
||||
for i, n in enumerate(x):
|
||||
print 'pos', i, 'is', n
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
pos 0 is 2
|
||||
pos 1 is 4
|
||||
pos 2 is 6
|
||||
|
||||
```
|
||||
|
||||
迭代器对象必须实现 `__iter__` 方法:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
x = [2, 4, 6]
|
||||
i = x.__iter__()
|
||||
print i
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<listiterator object at 0x0000000003CAE630>
|
||||
|
||||
```
|
||||
|
||||
`__iter__()` 返回的对象支持 `next` 方法,返回迭代器中的下一个元素:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
print i.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
当下一个元素不存在时,会 `raise` 一个 `StopIteration` 错误:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
print i.next()
|
||||
print i.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
4
|
||||
6
|
||||
|
||||
```
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
i.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
---------------------------------------------------------------------------
|
||||
StopIteration Traceback (most recent call last)
|
||||
<ipython-input-6-e590fe0d22f8> in <module>()
|
||||
----> 1 i.next()
|
||||
|
||||
StopIteration:
|
||||
```
|
||||
|
||||
很多标准库函数返回的是迭代器:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
r = reversed(x)
|
||||
print r
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<listreverseiterator object at 0x0000000003D615F8>
|
||||
|
||||
```
|
||||
|
||||
调用它的 `next()` 方法:
|
||||
|
||||
In [8]:
|
||||
|
||||
```py
|
||||
print r.next()
|
||||
print r.next()
|
||||
print r.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
6
|
||||
4
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
字典对象的 `iterkeys, itervalues, iteritems` 方法返回的都是迭代器:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
x = {'a':1, 'b':2, 'c':3}
|
||||
i = x.iteritems()
|
||||
print i
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<dictionary-itemiterator object at 0x0000000003D51B88>
|
||||
|
||||
```
|
||||
|
||||
迭代器的 `__iter__` 方法返回它本身:
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
print i.__iter__()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<dictionary-itemiterator object at 0x0000000003D51B88>
|
||||
|
||||
```
|
||||
|
||||
In [11]:
|
||||
|
||||
```py
|
||||
print i.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
('a', 1)
|
||||
|
||||
```
|
||||
|
||||
## 自定义迭代器
|
||||
|
||||
自定义一个 list 的取反迭代器:
|
||||
|
||||
In [12]:
|
||||
|
||||
```py
|
||||
class ReverseListIterator(object):
|
||||
|
||||
def __init__(self, list):
|
||||
self.list = list
|
||||
self.index = len(list)
|
||||
|
||||
def __iter__(self):
|
||||
return self
|
||||
|
||||
def next(self):
|
||||
self.index -= 1
|
||||
if self.index >= 0:
|
||||
return self.list[self.index]
|
||||
else:
|
||||
raise StopIteration
|
||||
|
||||
```
|
||||
|
||||
In [13]:
|
||||
|
||||
```py
|
||||
x = range(10)
|
||||
for i in ReverseListIterator(x):
|
||||
print i,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
9 8 7 6 5 4 3 2 1 0
|
||||
|
||||
```
|
||||
|
||||
只要我们定义了这三个方法,我们可以返回任意迭代值:
|
||||
|
||||
In [14]:
|
||||
|
||||
```py
|
||||
class Collatz(object):
|
||||
|
||||
def __init__(self, start):
|
||||
self.value = start
|
||||
|
||||
def __iter__(self):
|
||||
return self
|
||||
|
||||
def next(self):
|
||||
if self.value == 1:
|
||||
raise StopIteration
|
||||
elif self.value % 2 == 0:
|
||||
self.value = self.value / 2
|
||||
else:
|
||||
self.value = 3 * self.value + 1
|
||||
return self.value
|
||||
|
||||
```
|
||||
|
||||
这里我们实现 [Collatz 猜想](http://baike.baidu.com/view/736196.htm):
|
||||
|
||||
* 奇数 n:返回 3n + 1
|
||||
* 偶数 n:返回 n / 2
|
||||
|
||||
直到 n 为 1 为止:
|
||||
|
||||
In [15]:
|
||||
|
||||
```py
|
||||
for x in Collatz(7):
|
||||
print x,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
|
||||
|
||||
```
|
||||
|
||||
不过迭代器对象存在状态,会出现这样的问题:
|
||||
|
||||
In [16]:
|
||||
|
||||
```py
|
||||
i = Collatz(7)
|
||||
for x, y in zip(i, i):
|
||||
print x, y
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22 11
|
||||
34 17
|
||||
52 26
|
||||
13 40
|
||||
20 10
|
||||
5 16
|
||||
8 4
|
||||
2 1
|
||||
|
||||
```
|
||||
|
||||
一个比较好的解决方法是将迭代器和可迭代对象分开处理,这里提供了一个二分树的中序遍历实现:
|
||||
|
||||
In [17]:
|
||||
|
||||
```py
|
||||
class BinaryTree(object):
|
||||
def __init__(self, value, left=None, right=None):
|
||||
self.value = value
|
||||
self.left = left
|
||||
self.right = right
|
||||
|
||||
def __iter__(self):
|
||||
return InorderIterator(self)
|
||||
|
||||
```
|
||||
|
||||
In [18]:
|
||||
|
||||
```py
|
||||
class InorderIterator(object):
|
||||
|
||||
def __init__(self, node):
|
||||
self.node = node
|
||||
self.stack = []
|
||||
|
||||
def next(self):
|
||||
if len(self.stack) > 0 or self.node is not None:
|
||||
while self.node is not None:
|
||||
self.stack.append(self.node)
|
||||
self.node = self.node.left
|
||||
node = self.stack.pop()
|
||||
self.node = node.right
|
||||
return node.value
|
||||
else:
|
||||
raise StopIteration()
|
||||
|
||||
```
|
||||
|
||||
In [19]:
|
||||
|
||||
```py
|
||||
tree = BinaryTree(
|
||||
left=BinaryTree(
|
||||
left=BinaryTree(1),
|
||||
value=2,
|
||||
right=BinaryTree(
|
||||
left=BinaryTree(3),
|
||||
value=4,
|
||||
right=BinaryTree(5)
|
||||
),
|
||||
),
|
||||
value=6,
|
||||
right=BinaryTree(
|
||||
value=7,
|
||||
right=BinaryTree(8)
|
||||
)
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
In [20]:
|
||||
|
||||
```py
|
||||
for value in tree:
|
||||
print value,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 2 3 4 5 6 7 8
|
||||
|
||||
```
|
||||
|
||||
不会出现之前的问题:
|
||||
|
||||
In [21]:
|
||||
|
||||
```py
|
||||
for x,y in zip(tree, tree):
|
||||
print x, y
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 1
|
||||
2 2
|
||||
3 3
|
||||
4 4
|
||||
5 5
|
||||
6 6
|
||||
7 7
|
||||
8 8
|
||||
|
||||
```
|
||||
|
|
@ -0,0 +1,250 @@
|
|||
# 生成器
|
||||
|
||||
`while` 循环通常有这样的形式:
|
||||
|
||||
```py
|
||||
<do setup>
|
||||
result = []
|
||||
while True:
|
||||
<generate value>
|
||||
result.append(value)
|
||||
if <done>:
|
||||
break
|
||||
|
||||
```
|
||||
|
||||
使用迭代器实现这样的循环:
|
||||
|
||||
```py
|
||||
class GenericIterator(object):
|
||||
def __init__(self, ...):
|
||||
<do setup>
|
||||
# 需要额外储存状态
|
||||
<store state>
|
||||
def next(self):
|
||||
<load state>
|
||||
<generate value>
|
||||
if <done>:
|
||||
raise StopIteration()
|
||||
<store state>
|
||||
return value
|
||||
|
||||
```
|
||||
|
||||
更简单的,可以使用生成器:
|
||||
|
||||
```py
|
||||
def generator(...):
|
||||
<do setup>
|
||||
while True:
|
||||
<generate value>
|
||||
# yield 说明这个函数可以返回多个值!
|
||||
yield value
|
||||
if <done>:
|
||||
break
|
||||
|
||||
```
|
||||
|
||||
生成器使用 `yield` 关键字将值输出,而迭代器则通过 `next` 的 `return` 将值返回;与迭代器不同的是,生成器会自动记录当前的状态,而迭代器则需要进行额外的操作来记录当前的状态。
|
||||
|
||||
对于之前的 `collatz` 猜想,简单循环的实现如下:
|
||||
|
||||
In [1]:
|
||||
|
||||
```py
|
||||
def collatz(n):
|
||||
sequence = []
|
||||
while n != 1:
|
||||
if n % 2 == 0:
|
||||
n /= 2
|
||||
else:
|
||||
n = 3*n + 1
|
||||
sequence.append(n)
|
||||
return sequence
|
||||
|
||||
for x in collatz(7):
|
||||
print x,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
|
||||
|
||||
```
|
||||
|
||||
迭代器的版本如下:
|
||||
|
||||
In [2]:
|
||||
|
||||
```py
|
||||
class Collatz(object):
|
||||
def __init__(self, start):
|
||||
self.value = start
|
||||
|
||||
def __iter__(self):
|
||||
return self
|
||||
|
||||
def next(self):
|
||||
if self.value == 1:
|
||||
raise StopIteration()
|
||||
elif self.value % 2 == 0:
|
||||
self.value = self.value/2
|
||||
else:
|
||||
self.value = 3*self.value + 1
|
||||
return self.value
|
||||
|
||||
for x in Collatz(7):
|
||||
print x,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
|
||||
|
||||
```
|
||||
|
||||
生成器的版本如下:
|
||||
|
||||
In [3]:
|
||||
|
||||
```py
|
||||
def collatz(n):
|
||||
while n != 1:
|
||||
if n % 2 == 0:
|
||||
n /= 2
|
||||
else:
|
||||
n = 3*n + 1
|
||||
yield n
|
||||
|
||||
for x in collatz(7):
|
||||
print x,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
|
||||
|
||||
```
|
||||
|
||||
事实上,生成器也是一种迭代器:
|
||||
|
||||
In [4]:
|
||||
|
||||
```py
|
||||
x = collatz(7)
|
||||
print x
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<generator object collatz at 0x0000000003B63750>
|
||||
|
||||
```
|
||||
|
||||
它支持 `next` 方法,返回下一个 `yield` 的值:
|
||||
|
||||
In [5]:
|
||||
|
||||
```py
|
||||
print x.next()
|
||||
print x.next()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
22
|
||||
11
|
||||
|
||||
```
|
||||
|
||||
`__iter__` 方法返回的是它本身:
|
||||
|
||||
In [6]:
|
||||
|
||||
```py
|
||||
print x.__iter__()
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
<generator object collatz at 0x0000000003B63750>
|
||||
|
||||
```
|
||||
|
||||
之前的二叉树迭代器可以改写为更简单的生成器模式来进行中序遍历:
|
||||
|
||||
In [7]:
|
||||
|
||||
```py
|
||||
class BinaryTree(object):
|
||||
def __init__(self, value, left=None, right=None):
|
||||
self.value = value
|
||||
self.left = left
|
||||
self.right = right
|
||||
|
||||
def __iter__(self):
|
||||
# 将迭代器设为生成器方法
|
||||
return self.inorder()
|
||||
|
||||
def inorder(self):
|
||||
# traverse the left branch
|
||||
if self.left is not None:
|
||||
for value in self.left:
|
||||
yield value
|
||||
|
||||
# yield node's value
|
||||
yield self.value
|
||||
|
||||
# traverse the right branch
|
||||
if self.right is not None:
|
||||
for value in self.right:
|
||||
yield value
|
||||
|
||||
```
|
||||
|
||||
非递归的实现:
|
||||
|
||||
In [9]:
|
||||
|
||||
```py
|
||||
def inorder(self):
|
||||
node = self
|
||||
stack = []
|
||||
while len(stack) > 0 or node is not None:
|
||||
while node is not None:
|
||||
stack.append(node)
|
||||
node = node.left
|
||||
node = stack.pop()
|
||||
yield node.value
|
||||
node = node.right
|
||||
|
||||
```
|
||||
|
||||
In [10]:
|
||||
|
||||
```py
|
||||
tree = BinaryTree(
|
||||
left=BinaryTree(
|
||||
left=BinaryTree(1),
|
||||
value=2,
|
||||
right=BinaryTree(
|
||||
left=BinaryTree(3),
|
||||
value=4,
|
||||
right=BinaryTree(5)
|
||||
),
|
||||
),
|
||||
value=6,
|
||||
right=BinaryTree(
|
||||
value=7,
|
||||
right=BinaryTree(8)
|
||||
)
|
||||
)
|
||||
for value in tree:
|
||||
print value,
|
||||
|
||||
```
|
||||
|
||||
```py
|
||||
1 2 3 4 5 6 7 8
|
||||
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue