git 项目大瘦身
This commit is contained in:
commit
81abcb3f3a
|
|
@ -0,0 +1,107 @@
|
|||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
.vscode
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
_book/
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# celery beat schedule file
|
||||
celerybeat-schedule
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
node_modules
|
||||
|
|
@ -0,0 +1,674 @@
|
|||
GNU GENERAL PUBLIC LICENSE
|
||||
Version 3, 29 June 2007
|
||||
|
||||
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/>
|
||||
Everyone is permitted to copy and distribute verbatim copies
|
||||
of this license document, but changing it is not allowed.
|
||||
|
||||
Preamble
|
||||
|
||||
The GNU General Public License is a free, copyleft license for
|
||||
software and other kinds of works.
|
||||
|
||||
The licenses for most software and other practical works are designed
|
||||
to take away your freedom to share and change the works. By contrast,
|
||||
the GNU General Public License is intended to guarantee your freedom to
|
||||
share and change all versions of a program--to make sure it remains free
|
||||
software for all its users. We, the Free Software Foundation, use the
|
||||
GNU General Public License for most of our software; it applies also to
|
||||
any other work released this way by its authors. You can apply it to
|
||||
your programs, too.
|
||||
|
||||
When we speak of free software, we are referring to freedom, not
|
||||
price. Our General Public Licenses are designed to make sure that you
|
||||
have the freedom to distribute copies of free software (and charge for
|
||||
them if you wish), that you receive source code or can get it if you
|
||||
want it, that you can change the software or use pieces of it in new
|
||||
free programs, and that you know you can do these things.
|
||||
|
||||
To protect your rights, we need to prevent others from denying you
|
||||
these rights or asking you to surrender the rights. Therefore, you have
|
||||
certain responsibilities if you distribute copies of the software, or if
|
||||
you modify it: responsibilities to respect the freedom of others.
|
||||
|
||||
For example, if you distribute copies of such a program, whether
|
||||
gratis or for a fee, you must pass on to the recipients the same
|
||||
freedoms that you received. You must make sure that they, too, receive
|
||||
or can get the source code. And you must show them these terms so they
|
||||
know their rights.
|
||||
|
||||
Developers that use the GNU GPL protect your rights with two steps:
|
||||
(1) assert copyright on the software, and (2) offer you this License
|
||||
giving you legal permission to copy, distribute and/or modify it.
|
||||
|
||||
For the developers' and authors' protection, the GPL clearly explains
|
||||
that there is no warranty for this free software. For both users' and
|
||||
authors' sake, the GPL requires that modified versions be marked as
|
||||
changed, so that their problems will not be attributed erroneously to
|
||||
authors of previous versions.
|
||||
|
||||
Some devices are designed to deny users access to install or run
|
||||
modified versions of the software inside them, although the manufacturer
|
||||
can do so. This is fundamentally incompatible with the aim of
|
||||
protecting users' freedom to change the software. The systematic
|
||||
pattern of such abuse occurs in the area of products for individuals to
|
||||
use, which is precisely where it is most unacceptable. Therefore, we
|
||||
have designed this version of the GPL to prohibit the practice for those
|
||||
products. If such problems arise substantially in other domains, we
|
||||
stand ready to extend this provision to those domains in future versions
|
||||
of the GPL, as needed to protect the freedom of users.
|
||||
|
||||
Finally, every program is threatened constantly by software patents.
|
||||
States should not allow patents to restrict development and use of
|
||||
software on general-purpose computers, but in those that do, we wish to
|
||||
avoid the special danger that patents applied to a free program could
|
||||
make it effectively proprietary. To prevent this, the GPL assures that
|
||||
patents cannot be used to render the program non-free.
|
||||
|
||||
The precise terms and conditions for copying, distribution and
|
||||
modification follow.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
"This License" refers to version 3 of the GNU General Public License.
|
||||
|
||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
"The Program" refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as "you". "Licensees" and
|
||||
"recipients" may be individuals or organizations.
|
||||
|
||||
To "modify" a work means to copy from or adapt all or part of the work
|
||||
in a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a "modified version" of the
|
||||
earlier work or a work "based on" the earlier work.
|
||||
|
||||
A "covered work" means either the unmodified Program or a work based
|
||||
on the Program.
|
||||
|
||||
To "propagate" a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To "convey" a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through
|
||||
a computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays "Appropriate Legal Notices"
|
||||
to the extent that it includes a convenient and prominently visible
|
||||
feature that (1) displays an appropriate copyright notice, and (2)
|
||||
tells the user that there is no warranty for the work (except to the
|
||||
extent that warranties are provided), that licensees may convey the
|
||||
work under this License, and how to view a copy of this License. If
|
||||
the interface presents a list of user commands or options, such as a
|
||||
menu, a prominent item in the list meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The "source code" for a work means the preferred form of the work
|
||||
for making modifications to it. "Object code" means any non-source
|
||||
form of a work.
|
||||
|
||||
A "Standard Interface" means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that
|
||||
is widely used among developers working in that language.
|
||||
|
||||
The "System Libraries" of an executable work include anything, other
|
||||
than the work as a whole, that (a) is included in the normal form of
|
||||
packaging a Major Component, but which is not part of that Major
|
||||
Component, and (b) serves only to enable use of the work with that
|
||||
Major Component, or to implement a Standard Interface for which an
|
||||
implementation is available to the public in source code form. A
|
||||
"Major Component", in this context, means a major essential component
|
||||
(kernel, window system, and so on) of the specific operating system
|
||||
(if any) on which the executable work runs, or a compiler used to
|
||||
produce the work, or an object code interpreter used to run it.
|
||||
|
||||
The "Corresponding Source" for a work in object code form means all
|
||||
the source code needed to generate, install, and (for an executable
|
||||
work) run the object code and to modify the work, including scripts to
|
||||
control those activities. However, it does not include the work's
|
||||
System Libraries, or general-purpose tools or generally available free
|
||||
programs which are used unmodified in performing those activities but
|
||||
which are not part of the work. For example, Corresponding Source
|
||||
includes interface definition files associated with source files for
|
||||
the work, and the source code for shared libraries and dynamically
|
||||
linked subprograms that the work is specifically designed to require,
|
||||
such as by intimate data communication or control flow between those
|
||||
subprograms and other parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users
|
||||
can regenerate automatically from other parts of the Corresponding
|
||||
Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that
|
||||
same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program. The output from running a
|
||||
covered work is covered by this License only if the output, given its
|
||||
content, constitutes a covered work. This License acknowledges your
|
||||
rights of fair use or other equivalent, as provided by copyright law.
|
||||
|
||||
You may make, run and propagate covered works that you do not
|
||||
convey, without conditions so long as your license otherwise remains
|
||||
in force. You may convey covered works to others for the sole purpose
|
||||
of having them make modifications exclusively for you, or provide you
|
||||
with facilities for running those works, provided that you comply with
|
||||
the terms of this License in conveying all material for which you do
|
||||
not control copyright. Those thus making or running the covered works
|
||||
for you must do so exclusively on your behalf, under your direction
|
||||
and control, on terms that prohibit them from making any copies of
|
||||
your copyrighted material outside their relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under
|
||||
the conditions stated below. Sublicensing is not allowed; section 10
|
||||
makes it unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article
|
||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||
similar laws prohibiting or restricting circumvention of such
|
||||
measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention
|
||||
is effected by exercising rights under this License with respect to
|
||||
the covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's
|
||||
users, your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice;
|
||||
keep intact all notices stating that this License and any
|
||||
non-permissive terms added in accord with section 7 apply to the code;
|
||||
keep intact all notices of the absence of any warranty; and give all
|
||||
recipients a copy of this License along with the Program.
|
||||
|
||||
You may charge any price or no price for each copy that you convey,
|
||||
and you may offer support or warranty protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the
|
||||
terms of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified
|
||||
it, and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is
|
||||
released under this License and any conditions added under section
|
||||
7. This requirement modifies the requirement in section 4 to
|
||||
"keep intact all notices".
|
||||
|
||||
c) You must license the entire work, as a whole, under this
|
||||
License to anyone who comes into possession of a copy. This
|
||||
License will therefore apply, along with any applicable section 7
|
||||
additional terms, to the whole of the work, and all its parts,
|
||||
regardless of how they are packaged. This License gives no
|
||||
permission to license the work in any other way, but it does not
|
||||
invalidate such permission if you have separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your
|
||||
work need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work,
|
||||
and which are not combined with it such as to form a larger program,
|
||||
in or on a volume of a storage or distribution medium, is called an
|
||||
"aggregate" if the compilation and its resulting copyright are not
|
||||
used to limit the access or legal rights of the compilation's users
|
||||
beyond what the individual works permit. Inclusion of a covered work
|
||||
in an aggregate does not cause this License to apply to the other
|
||||
parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms
|
||||
of sections 4 and 5, provided that you also convey the
|
||||
machine-readable Corresponding Source under the terms of this License,
|
||||
in one of these ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium
|
||||
customarily used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a
|
||||
written offer, valid for at least three years and valid for as
|
||||
long as you offer spare parts or customer support for that product
|
||||
model, to give anyone who possesses the object code either (1) a
|
||||
copy of the Corresponding Source for all the software in the
|
||||
product that is covered by this License, on a durable physical
|
||||
medium customarily used for software interchange, for a price no
|
||||
more than your reasonable cost of physically performing this
|
||||
conveying of source, or (2) access to copy the
|
||||
Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This
|
||||
alternative is allowed only occasionally and noncommercially, and
|
||||
only if you received the object code with such an offer, in accord
|
||||
with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated
|
||||
place (gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to
|
||||
copy the object code is a network server, the Corresponding Source
|
||||
may be on a different server (operated by you or a third party)
|
||||
that supports equivalent copying facilities, provided you maintain
|
||||
clear directions next to the object code saying where to find the
|
||||
Corresponding Source. Regardless of what server hosts the
|
||||
Corresponding Source, you remain obligated to ensure that it is
|
||||
available for as long as needed to satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided
|
||||
you inform other peers where the object code and Corresponding
|
||||
Source of the work are being offered to the general public at no
|
||||
charge under subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be
|
||||
included in conveying the object code work.
|
||||
|
||||
A "User Product" is either (1) a "consumer product", which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, "normally used" refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
"Installation Information" for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as
|
||||
part of a transaction in which the right of possession and use of the
|
||||
User Product is transferred to the recipient in perpetuity or for a
|
||||
fixed term (regardless of how the transaction is characterized), the
|
||||
Corresponding Source conveyed under this section must be accompanied
|
||||
by the Installation Information. But this requirement does not apply
|
||||
if neither you nor any third party retains the ability to install
|
||||
modified object code on the User Product (for example, the work has
|
||||
been installed in ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access to a
|
||||
network may be denied when the modification itself materially and
|
||||
adversely affects the operation of the network or violates the rules and
|
||||
protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided,
|
||||
in accord with this section must be in a format that is publicly
|
||||
documented (and with an implementation available to the public in
|
||||
source code form), and must require no special password or key for
|
||||
unpacking, reading or copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
"Additional permissions" are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall
|
||||
be treated as though they were included in this License, to the extent
|
||||
that they are valid under applicable law. If additional permissions
|
||||
apply only to part of the Program, that part may be used separately
|
||||
under those permissions, but the entire Program remains governed by
|
||||
this License without regard to the additional permissions.
|
||||
|
||||
When you convey a copy of a covered work, you may at your option
|
||||
remove any additional permissions from that copy, or from any part of
|
||||
it. (Additional permissions may be written to require their own
|
||||
removal in certain cases when you modify the work.) You may place
|
||||
additional permissions on material, added by you to a covered work,
|
||||
for which you have or can give appropriate copyright permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you
|
||||
add to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some
|
||||
trade names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that
|
||||
material by anyone who conveys the material (or modified versions of
|
||||
it) with contractual assumptions of liability to the recipient, for
|
||||
any liability that these contractual assumptions directly impose on
|
||||
those licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered "further
|
||||
restrictions" within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further
|
||||
restriction, you may remove that term. If a license document contains
|
||||
a further restriction but permits relicensing or conveying under this
|
||||
License, you may add to a covered work material governed by the terms
|
||||
of that license document, provided that the further restriction does
|
||||
not survive such relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you
|
||||
must place, in the relevant source files, a statement of the
|
||||
additional terms that apply to those files, or a notice indicating
|
||||
where to find the applicable terms.
|
||||
|
||||
Additional terms, permissive or non-permissive, may be stated in the
|
||||
form of a separately written license, or stated as exceptions;
|
||||
the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or
|
||||
modify it is void, and will automatically terminate your rights under
|
||||
this License (including any patent licenses granted under the third
|
||||
paragraph of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your
|
||||
license from a particular copyright holder is reinstated (a)
|
||||
provisionally, unless and until the copyright holder explicitly and
|
||||
finally terminates your license, and (b) permanently, if the copyright
|
||||
holder fails to notify you of the violation by some reasonable means
|
||||
prior to 60 days after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is
|
||||
reinstated permanently if the copyright holder notifies you of the
|
||||
violation by some reasonable means, this is the first time you have
|
||||
received notice of violation of this License (for any work) from that
|
||||
copyright holder, and you cure the violation prior to 30 days after
|
||||
your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or
|
||||
run a copy of the Program. Ancillary propagation of a covered work
|
||||
occurring solely as a consequence of using peer-to-peer transmission
|
||||
to receive a copy likewise does not require acceptance. However,
|
||||
nothing other than this License grants you permission to propagate or
|
||||
modify any covered work. These actions infringe copyright if you do
|
||||
not accept this License. Therefore, by modifying or propagating a
|
||||
covered work, you indicate your acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically
|
||||
receives a license from the original licensors, to run, modify and
|
||||
propagate that work, subject to this License. You are not responsible
|
||||
for enforcing compliance by third parties with this License.
|
||||
|
||||
An "entity transaction" is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered
|
||||
work results from an entity transaction, each party to that
|
||||
transaction who receives a copy of the work also receives whatever
|
||||
licenses to the work the party's predecessor in interest had or could
|
||||
give under the previous paragraph, plus a right to possession of the
|
||||
Corresponding Source of the work from the predecessor in interest, if
|
||||
the predecessor has it or can get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the
|
||||
rights granted or affirmed under this License. For example, you may
|
||||
not impose a license fee, royalty, or other charge for exercise of
|
||||
rights granted under this License, and you may not initiate litigation
|
||||
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||
any patent claim is infringed by making, using, selling, offering for
|
||||
sale, or importing the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A "contributor" is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The
|
||||
work thus licensed is called the contributor's "contributor version".
|
||||
|
||||
A contributor's "essential patent claims" are all patent claims
|
||||
owned or controlled by the contributor, whether already acquired or
|
||||
hereafter acquired, that would be infringed by some manner, permitted
|
||||
by this License, of making, using, or selling its contributor version,
|
||||
but do not include claims that would be infringed only as a
|
||||
consequence of further modification of the contributor version. For
|
||||
purposes of this definition, "control" includes the right to grant
|
||||
patent sublicenses in a manner consistent with the requirements of
|
||||
this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to
|
||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||
propagate the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a "patent license" is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To "grant" such a patent license to a
|
||||
party means to make such an agreement or commitment not to enforce a
|
||||
patent against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license,
|
||||
and the Corresponding Source of the work is not available for anyone
|
||||
to copy, free of charge and under the terms of this License, through a
|
||||
publicly available network server or other readily accessible means,
|
||||
then you must either (1) cause the Corresponding Source to be so
|
||||
available, or (2) arrange to deprive yourself of the benefit of the
|
||||
patent license for this particular work, or (3) arrange, in a manner
|
||||
consistent with the requirements of this License, to extend the patent
|
||||
license to downstream recipients. "Knowingly relying" means you have
|
||||
actual knowledge that, but for the patent license, your conveying the
|
||||
covered work in a country, or your recipient's use of the covered work
|
||||
in a country, would infringe one or more identifiable patents in that
|
||||
country that you have reason to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties
|
||||
receiving the covered work authorizing them to use, propagate, modify
|
||||
or convey a specific copy of the covered work, then the patent license
|
||||
you grant is automatically extended to all recipients of the covered
|
||||
work and works based on it.
|
||||
|
||||
A patent license is "discriminatory" if it does not include within
|
||||
the scope of its coverage, prohibits the exercise of, or is
|
||||
conditioned on the non-exercise of one or more of the rights that are
|
||||
specifically granted under this License. You may not convey a covered
|
||||
work if you are a party to an arrangement with a third party that is
|
||||
in the business of distributing software, under which you make payment
|
||||
to the third party based on the extent of your activity of conveying
|
||||
the work, and under which the third party grants, to any of the
|
||||
parties who would receive the covered work from you, a discriminatory
|
||||
patent license (a) in connection with copies of the covered work
|
||||
conveyed by you (or copies made from those copies), or (b) primarily
|
||||
for and in connection with specific products or compilations that
|
||||
contain the covered work, unless you entered into that arrangement,
|
||||
or that patent license was granted, prior to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting
|
||||
any implied license or other defenses to infringement that may
|
||||
otherwise be available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot convey a
|
||||
covered work so as to satisfy simultaneously your obligations under this
|
||||
License and any other pertinent obligations, then as a consequence you may
|
||||
not convey it at all. For example, if you agree to terms that obligate you
|
||||
to collect a royalty for further conveying from those to whom you convey
|
||||
the Program, the only way you could satisfy both those terms and this
|
||||
License would be to refrain entirely from conveying the Program.
|
||||
|
||||
13. Use with the GNU Affero General Public License.
|
||||
|
||||
Notwithstanding any other provision of this License, you have
|
||||
permission to link or combine any covered work with a work licensed
|
||||
under version 3 of the GNU Affero General Public License into a single
|
||||
combined work, and to convey the resulting work. The terms of this
|
||||
License will continue to apply to the part which is the covered work,
|
||||
but the special requirements of the GNU Affero General Public License,
|
||||
section 13, concerning interaction through a network will apply to the
|
||||
combination as such.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
The Free Software Foundation may publish revised and/or new versions of
|
||||
the GNU General Public License from time to time. Such new versions will
|
||||
be similar in spirit to the present version, but may differ in detail to
|
||||
address new problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the
|
||||
Program specifies that a certain numbered version of the GNU General
|
||||
Public License "or any later version" applies to it, you have the
|
||||
option of following the terms and conditions either of that numbered
|
||||
version or of any later version published by the Free Software
|
||||
Foundation. If the Program does not specify a version number of the
|
||||
GNU General Public License, you may choose any version ever published
|
||||
by the Free Software Foundation.
|
||||
|
||||
If the Program specifies that a proxy can decide which future
|
||||
versions of the GNU General Public License can be used, that proxy's
|
||||
public statement of acceptance of a version permanently authorizes you
|
||||
to choose that version for the Program.
|
||||
|
||||
Later license versions may give you additional or different
|
||||
permissions. However, no additional obligations are imposed on any
|
||||
author or copyright holder as a result of your choosing to follow a
|
||||
later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||
SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided
|
||||
above cannot be given local legal effect according to their terms,
|
||||
reviewing courts shall apply local law that most closely approximates
|
||||
an absolute waiver of all civil liability in connection with the
|
||||
Program, unless a warranty or assumption of liability accompanies a
|
||||
copy of the Program in return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
How to Apply These Terms to Your New Programs
|
||||
|
||||
If you develop a new program, and you want it to be of the greatest
|
||||
possible use to the public, the best way to achieve this is to make it
|
||||
free software which everyone can redistribute and change under these terms.
|
||||
|
||||
To do so, attach the following notices to the program. It is safest
|
||||
to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
{one line to give the program's name and a brief idea of what it does.}
|
||||
Copyright (C) {year} {name of author}
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU General Public License as published by
|
||||
the Free Software Foundation, either version 3 of the License, or
|
||||
(at your option) any later version.
|
||||
|
||||
This program is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
GNU General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU General Public License
|
||||
along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
|
||||
Also add information on how to contact you by electronic and paper mail.
|
||||
|
||||
If the program does terminal interaction, make it output a short
|
||||
notice like this when it starts in an interactive mode:
|
||||
|
||||
{project} Copyright (C) {year} {fullname}
|
||||
This program comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
|
||||
This is free software, and you are welcome to redistribute it
|
||||
under certain conditions; type `show c' for details.
|
||||
|
||||
The hypothetical commands `show w' and `show c' should show the appropriate
|
||||
parts of the General Public License. Of course, your program's commands
|
||||
might be different; for a GUI interface, you would use an "about box".
|
||||
|
||||
You should also get your employer (if you work as a programmer) or school,
|
||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||
For more information on this, and how to apply and follow the GNU GPL, see
|
||||
<http://www.gnu.org/licenses/>.
|
||||
|
||||
The GNU General Public License does not permit incorporating your program
|
||||
into proprietary programs. If your program is a subroutine library, you
|
||||
may consider it more useful to permit linking proprietary applications with
|
||||
the library. If this is what you want to do, use the GNU Lesser General
|
||||
Public License instead of this License. But first, please read
|
||||
<http://www.gnu.org/philosophy/why-not-lgpl.html>.
|
||||
|
|
@ -0,0 +1,626 @@
|
|||
<p align="center">
|
||||
<a href="https://www.apachecn.org">
|
||||
<img width="200" src="http://data.apachecn.org/img/logo.jpg">
|
||||
</a>
|
||||
<br >
|
||||
<a href="https://www.apachecn.org/"><img src="https://img.shields.io/badge/%3E-HOME-green.svg"></a>
|
||||
<a href="http://home.apachecn.org/about/"><img src="https://img.shields.io/badge/%3E-ABOUT-green.svg"></a>
|
||||
<a href="mailto:apache@163.com"><img src="https://img.shields.io/badge/%3E-Email-green.svg"></a>
|
||||
</p>
|
||||
|
||||
<h1 align="center"><a href="https://github.com/apachecn/AiLearning">AI learning</a></h1>
|
||||
|
||||
## 组织介绍
|
||||
|
||||
* 合作or侵权,请联系: `apachecn@163.com`
|
||||
* **我们不是 Apache 的官方组织/机构/团体,只是 Apache 技术栈(以及 AI)的爱好者!**
|
||||
* **ApacheCN - 学习机器学习群【629470233】<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=30e5f1123a79867570f665aa3a483ca404b1c3f77737bc01ec520ed5f078ddef"><img border="0" src="http://data.apachecn.org/img/logo/ApacheCN-group.png" alt="ApacheCN - 学习机器学习群[629470233]" title="ApacheCN - 学习机器学习群[629470233]"></a>**
|
||||
|
||||
> **欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远**
|
||||
|
||||
# 路线图
|
||||
|
||||
* 入门只看: 步骤 1 => 2 => 3,你可以当大牛!
|
||||
* 中级补充 - 资料库: <https://github.com/apachecn/ai-roadmap>
|
||||
|
||||
## 1.机器学习 - 基础
|
||||
|
||||
### 基本介绍
|
||||
|
||||
* 资料来源: Machine Learning in Action(机器学习实战-个人笔记)
|
||||
* 统一数据地址: <https://github.com/apachecn/data>
|
||||
* 书籍下载地址: <https://github.com/apachecn/data/tree/master/book>
|
||||
* 机器学习下载地址: <https://github.com/apachecn/data/tree/master/机器学习>
|
||||
* 深度学习数据地址: <https://github.com/apachecn/data/tree/master/深度学习>
|
||||
* 推荐系统数据地址: <https://github.com/apachecn/data/tree/master/推荐系统>
|
||||
* 视频网站:优酷 /bilibili / Acfun / 网易云课堂,可直接在线播放。(最下方有相应链接)
|
||||
* -- 推荐 [红色石头](https://github.com/RedstoneWill): [台湾大学林轩田机器学习笔记](https://github.com/apachecn/ntu-hsuantienlin-ml)
|
||||
* -- 推荐 [机器学习笔记](https://feisky.xyz/machine-learning): https://feisky.xyz/machine-learning
|
||||
|
||||
### 学习文档
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>模块</th>
|
||||
<th>章节</th>
|
||||
<th>类型</th>
|
||||
<th>负责人(GitHub)</th>
|
||||
<th>QQ</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/1.机器学习基础.md"> 第 1 章: 机器学习基础</a></td>
|
||||
<td>介绍</td>
|
||||
<td><a href="https://github.com/ElmaDavies">@毛红动</a></td>
|
||||
<td>1306014226</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/2.k-近邻算法.md">第 2 章: KNN 近邻算法</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/youyj521">@尤永江</a></td>
|
||||
<td>279393323</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/3.决策树.md">第 3 章: 决策树</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/jingwangfei">@景涛</a></td>
|
||||
<td>844300439</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/4.朴素贝叶斯.md">第 4 章: 朴素贝叶斯</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/wnma3mz">@wnma3mz</a><br/><a href="https://github.com/kailian">@分析</a></td>
|
||||
<td>1003324213<br/>244970749</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/5.Logistic回归.md">第 5 章: Logistic回归</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/6.支持向量机.md">第 6 章: SVM 支持向量机</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/VPrincekin">@王德红</a></td>
|
||||
<td>934969547</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>网上组合内容</td>
|
||||
<td><a href="docs/ml/7.集成方法-随机森林和AdaBoost.md">第 7 章: 集成方法(随机森林和 AdaBoost)</a></td>
|
||||
<td>分类</td>
|
||||
<td><a href="https://github.com/jiangzhonglian">@片刻</a></td>
|
||||
<td>529815144</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/8.回归.md">第 8 章: 回归</a></td>
|
||||
<td>回归</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/9.树回归.md">第 9 章: 树回归</a></td>
|
||||
<td>回归</td>
|
||||
<td><a href="https://github.com/DataMonk2017">@微光同尘</a></td>
|
||||
<td>529925688</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/10.k-means聚类.md">第 10 章: K-Means 聚类</a></td>
|
||||
<td>聚类</td>
|
||||
<td><a href="https://github.com/xuzhaoqing">@徐昭清</a></td>
|
||||
<td>827106588</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/11.使用Apriori算法进行关联分析.md">第 11 章: 利用 Apriori 算法进行关联分析</a></td>
|
||||
<td>频繁项集</td>
|
||||
<td><a href="https://github.com/WindZQ">@刘海飞</a></td>
|
||||
<td>1049498972</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/12.使用FP-growth算法来高效发现频繁项集.md">第 12 章: FP-growth 高效发现频繁项集</a></td>
|
||||
<td>频繁项集</td>
|
||||
<td><a href="https://github.com/mikechengwei">@程威</a></td>
|
||||
<td>842725815</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/13.利用PCA来简化数据.md">第 13 章: 利用 PCA 来简化数据</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/lljuan330">@廖立娟</a></td>
|
||||
<td>835670618</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/14.利用SVD简化数据.md">第 14 章: 利用 SVD 来简化数据</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/marsjhao">@张俊皓</a></td>
|
||||
<td>714974242</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>机器学习实战</td>
|
||||
<td><a href="docs/ml/15.大数据与MapReduce.md">第 15 章: 大数据与 MapReduce</a></td>
|
||||
<td>工具</td>
|
||||
<td><a href="https://github.com/wnma3mz">@wnma3mz</a></td>
|
||||
<td>1003324213</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Ml项目实战</td>
|
||||
<td><a href="docs/ml/16.推荐系统.md">第 16 章: 推荐系统(已迁移)</a></td>
|
||||
<td>项目</td>
|
||||
<td><a href="https://github.com/apachecn/RecommenderSystems">推荐系统(迁移后地址)</a></td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>第一期的总结</td>
|
||||
<td><a href="report/2017-04-08_第一期的总结.md">2017-04-08: 第一期的总结</a></td>
|
||||
<td>总结</td>
|
||||
<td>总结</td>
|
||||
<td>529815144</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
|
||||
### 网站视频
|
||||
|
||||
> [知乎问答-爆炸啦-机器学习该怎么入门?](https://www.zhihu.com/question/20691338/answer/248678328)
|
||||
|
||||
当然我知道,第一句就会被吐槽,因为科班出身的人,不屑的吐了一口唾沫,说傻X,还评论 Andrew Ng 的视频。。
|
||||
|
||||
我还知道还有一部分人,看 Andrew Ng 的视频就是看不懂,那神秘的数学推导,那迷之微笑的英文版的教学,我何尝又不是这样走过来的?? 我的心可能比你们都痛,因为我在网上收藏过上10部《机器学习》相关视频,外加国内本土风格的教程:7月+小象 等等,我都很难去听懂,直到有一天,被一个百度的高级算法分析师推荐说:《机器学习实战》还不错,通俗易懂,你去试试??
|
||||
|
||||
我试了试,还好我的Python基础和调试能力还不错,基本上代码都调试过一遍,很多高大上的 "理论+推导",在我眼中变成了几个 "加减乘除+循环",我想这不就是像我这样的程序员想要的入门教程么?
|
||||
|
||||
很多程序员说机器学习 TM 太难学了,是的,真 TM 难学,我想最难的是:没有一本像《机器学习实战》那样的作者愿意以程序员 Coding 角度去给大家讲解!!
|
||||
|
||||
最近几天,GitHub 涨了 300颗 star,加群的200人, 现在还在不断的增加++,我想大家可能都是感同身受吧!
|
||||
|
||||
很多想入门新手就是被忽悠着收藏收藏再收藏,但是最后还是什么都没有学到,也就是"资源收藏家",也许新手要的就是 [MachineLearning(机器学习) 学习路线图](http://www.apachecn.org/map/145.html)。没错,我可以给你们的一份,因为我们还通过视频记录下来我们的学习过程。水平当然也有限,不过对于新手入门,绝对没问题,如果你还不会,那算我输!!
|
||||
|
||||
> 视频怎么看?
|
||||
|
||||

|
||||
|
||||
1. 理论科班出身-建议去学习 Andrew Ng 的视频(Ng 的视频绝对是权威,这个毋庸置疑)
|
||||
2. 编码能力强 - 建议看我们的[《机器学习实战-教学版》](https://space.bilibili.com/97678687/#!/channel/detail?cid=22486)
|
||||
3. 编码能力弱 - 建议看我们的[《机器学习实战-讨论版》](https://space.bilibili.com/97678687/#!/channel/detail?cid=13045),不过在看理论的时候,看 教学版-理论部分;讨论版的废话太多,不过在讲解代码的时候是一行一行讲解的;所以,根据自己的需求,自由的组合。
|
||||
|
||||
> 【免费】数学教学视频 - 可汗学院 入门篇
|
||||
|
||||
* [@于振梓]() 推荐: 可汗学院-网易公开课
|
||||
|
||||
| 概率 | 统计 | 线性代数 |
|
||||
| - | - | - |
|
||||
| [可汗学院(概率)](http://open.163.com/special/Khan/probability.html) | [可汗学院(统计学)](http://open.163.com/special/Khan/khstatistics.html)| [可汗学院(线性代数)](http://open.163.com/special/Khan/linearalgebra.html)
|
||||
|
||||
> 机器学习视频 - ApacheCN 教学版
|
||||
|
||||
|||
|
||||
| - | - |
|
||||
| AcFun | B站 |
|
||||
| <a title="AcFun(机器学习视频)" href="http://www.acfun.cn/u/12540256.aspx#page=1" target="_blank"><img width="290" src="img/MainPage/ApacheCN-ML-AcFun.jpg"></a> | <a title="bilibili(机器学习视频)" href="https://space.bilibili.com/97678687/#!/channel/index" target="_blank"><img width="290" src="img/MainPage/ApacheCN-ML-bilibili.jpg"></a> |
|
||||
| 优酷 | 网易云课堂 |
|
||||
| <a title="YouKu(机器学习视频)" href="http://i.youku.com/apachecn" target="_blank"><img width="290" src="img/MainPage/ApacheCM-ML-youku.jpg"></a> | <a title="WangYiYunKeTang(机器学习视频)" href="http://study.163.com/course/courseMain.htm?courseId=1004582003" target="_blank"><img width="290" src="img/MainPage/ApacheCM-ML-WangYiYunKeTang.png"></a> |
|
||||
|
||||
> 【免费】机器/深度学习视频 - 吴恩达
|
||||
|
||||
| 机器学习 | 深度学习 |
|
||||
| - | - |
|
||||
| [吴恩达机器学习](http://study.163.com/course/courseMain.htm?courseId=1004570029) | [神经网络和深度学习](http://mooc.study.163.com/course/2001281002?tid=2001392029) |
|
||||
|
||||
|
||||
## 2.深度学习
|
||||
|
||||
### 入门基础
|
||||
|
||||
1. [反向传递](/docs/dl/反向传递.md): https://www.cnblogs.com/charlotte77/p/5629865.html
|
||||
2. [CNN原理](/docs/dl/CNN原理.md): http://www.cnblogs.com/charlotte77/p/7759802.html
|
||||
3. [RNN原理](/docs/dl/RNN原理.md): https://blog.csdn.net/qq_39422642/article/details/78676567
|
||||
4. [LSTM原理](/docs/dl/LSTM原理.md): https://blog.csdn.net/weixin_42111770/article/details/80900575
|
||||
|
||||
### Pytorch - 教程
|
||||
|
||||
-- 待更新
|
||||
|
||||
### TensorFlow 2.0 - 教程
|
||||
|
||||
-- 待更新
|
||||
|
||||
> 目录结构:
|
||||
|
||||
* [安装指南](docs/TensorFlow2.x/安装指南.md)
|
||||
* [Kears 快速入门](docs/TensorFlow2.x/Keras快速入门.md)
|
||||
|
||||
## 3.自然语言处理
|
||||
|
||||
学习过程中-内心复杂的变化!!!
|
||||
|
||||
```python
|
||||
自从学习NLP以后,才发现国内与国外的典型区别:
|
||||
1. 对资源的态度是完全相反的:
|
||||
1) 国内:就好像为了名气,举办工作装逼的会议,就是没有干货,全部都是象征性的PPT介绍,不是针对在做的各位
|
||||
2)国外:就好像是为了推动nlp进步一样,分享者各种干货资料和具体的实现。(特别是: python自然语言处理)
|
||||
2. 论文的实现:
|
||||
1) 各种高大上的论文实现,却还是没看到一个像样的GitHub项目!(可能我的搜索能力差了点,一直没找到)
|
||||
2)国外就不举例了,我看不懂!
|
||||
3. 开源的框架
|
||||
1)国外的开源框架: tensorflow/pytorch 文档+教程+视频(官方提供)
|
||||
2) 国内的开源框架: 额额,还真举例不出来!但是牛逼吹得不比国外差!(MXNet虽然有众多国人参与开发,但不能算是国内开源框架。基于MXNet的动手学深度学习(http://zh.d2l.ai & https://discuss.gluon.ai/t/topic/753)中文教程,已经由沐神(李沐)以及阿斯顿·张讲授录制,公开发布(文档+第一季教程+视频)。)
|
||||
每一次深入都要去翻墙,每一次深入都要Google,每一次看着国内的说:哈工大、讯飞、中科大、百度、阿里多牛逼,但是资料还是得国外去找!
|
||||
有时候真的挺恨的!真的有点瞧不起自己国内的技术环境!
|
||||
|
||||
当然谢谢国内很多博客大佬,特别是一些入门的Demo和基本概念。【深入的水平有限,没看懂】
|
||||
```
|
||||
|
||||

|
||||
|
||||
* **【入门须知】必须了解**: <https://github.com/apachecn/AiLearning/tree/master/docs/nlp>
|
||||
* **【入门教程】强烈推荐: PyTorch 自然语言处理**: <https://github.com/apachecn/NLP-with-PyTorch>
|
||||
* Python 自然语言处理 第二版: <https://usyiyi.github.io/nlp-py-2e-zh>
|
||||
* 推荐一个[liuhuanyong大佬](https://github.com/liuhuanyong)整理的nlp全面知识体系: <https://liuhuanyong.github.io>
|
||||
* 开源 - 词向量库集合:
|
||||
* <https://github.com/Embedding/Chinese-Word-Vectors>
|
||||
* <https://github.com/brightmart/nlp_chinese_corpus>
|
||||
* <https://github.com/codemayq/chinese_chatbot_corpus>
|
||||
* <https://github.com/candlewill/Dialog_Corpus>
|
||||
|
||||
|
||||
### 1.使用场景 (百度公开课)
|
||||
|
||||
> 第一部分 入门介绍
|
||||
|
||||
* 1.) [自然语言处理入门介绍](/docs/nlp/1.自然语言处理入门介绍.md)
|
||||
|
||||
> 第二部分 机器翻译
|
||||
|
||||
* 2.) [机器翻译](/docs/nlp/2.机器翻译.md)
|
||||
|
||||
> 第三部分 篇章分析
|
||||
|
||||
* 3.1.) [篇章分析-内容概述](/docs/nlp/3.1.篇章分析-内容概述.md)
|
||||
* 3.2.) [篇章分析-内容标签](/docs/nlp/3.2.篇章分析-内容标签.md)
|
||||
* 3.3.) [篇章分析-情感分析](/docs/nlp/3.3.篇章分析-情感分析.md)
|
||||
* 3.4.) [篇章分析-自动摘要](/docs/nlp/3.4.篇章分析-自动摘要.md)
|
||||
|
||||
> 第四部分 UNIT-语言理解与交互技术
|
||||
|
||||
* 4.) [UNIT-语言理解与交互技术](/docs/nlp/4.UNIT-语言理解与交互技术.md)
|
||||
|
||||
### 应用领域
|
||||
|
||||
#### 中文分词:
|
||||
|
||||
* 构建DAG图
|
||||
* 动态规划查找,综合正反向(正向加权反向输出)求得DAG最大概率路径
|
||||
* 使用了SBME语料训练了一套 HMM + Viterbi 模型,解决未登录词问题
|
||||
|
||||
#### 1.文本分类(Text Classification)
|
||||
|
||||
文本分类是指标记句子或文档,例如电子邮件垃圾邮件分类和情感分析。
|
||||
|
||||
下面是一些很好的初学者文本分类数据集。
|
||||
|
||||
1. [路透社Newswire主题分类](http://kdd.ics.uci.edu/databases/reuters21578/reuters21578.html)(路透社-21578)。1987年路透社出现的一系列新闻文件,按类别编制索引。[另见RCV1,RCV2和TRC2](http://trec.nist.gov/data/reuters/reuters.html)。
|
||||
2. [IMDB电影评论情感分类(斯坦福)](http://ai.stanford.edu/~amaas/data/sentiment)。来自网站imdb.com的一系列电影评论及其积极或消极的情绪。
|
||||
3. [新闻组电影评论情感分类(康奈尔)](http://www.cs.cornell.edu/people/pabo/movie-review-data/)。来自网站imdb.com的一系列电影评论及其积极或消极的情绪。
|
||||
|
||||
有关更多信息,请参阅帖子:
|
||||
[单标签文本分类的数据集](http://ana.cachopo.org/datasets-for-single-label-text-categorization)。
|
||||
|
||||
> 情感分析
|
||||
|
||||
比赛地址: https://www.kaggle.com/c/word2vec-nlp-tutorial
|
||||
|
||||
* 方案一(0.86):WordCount + 朴素 Bayes
|
||||
* 方案二(0.94):LDA + 分类模型(knn/决策树/逻辑回归/svm/xgboost/随机森林)
|
||||
* a) 决策树效果不是很好,这种连续特征不太适合的
|
||||
* b) 通过参数调整 200 个topic,信息量保存效果较优(计算主题)
|
||||
* 方案三(0.72):word2vec + CNN
|
||||
* 说实话:没有一个好的机器,是调不出来一个好的结果 (: 逃
|
||||
|
||||
**通过AUC 来评估模型的效果**
|
||||
|
||||
#### 2.语言模型(Language Modeling)
|
||||
|
||||
语言建模涉及开发一种统计模型,用于预测句子中的下一个单词或一个单词中的下一个单词。它是语音识别和机器翻译等任务中的前置任务。
|
||||
|
||||
它是语音识别和机器翻译等任务中的前置任务。
|
||||
|
||||
下面是一些很好的初学者语言建模数据集。
|
||||
|
||||
1. [古腾堡项目](https://www.gutenberg.org/),一系列免费书籍,可以用纯文本检索各种语言。
|
||||
2. 还有更多正式的语料库得到了很好的研究; 例如:
|
||||
[布朗大学现代美国英语标准语料库](https://en.wikipedia.org/wiki/Brown_Corpus)。大量英语单词样本。
|
||||
[谷歌10亿字语料库](https://github.com/ciprian-chelba/1-billion-word-language-modeling-benchmark)。
|
||||
|
||||
> 新词发现
|
||||
|
||||
* 中文分词新词发现
|
||||
* python3利用互信息和左右信息熵的中文分词新词发现
|
||||
* <https://github.com/zhanzecheng/Chinese_segment_augment>
|
||||
|
||||
> 句子相似度识别
|
||||
|
||||
* 项目地址: https://www.kaggle.com/c/quora-question-pairs
|
||||
* 解决方案: word2vec + Bi-GRU
|
||||
|
||||
> 文本纠错
|
||||
|
||||
* bi-gram + levenshtein
|
||||
|
||||
#### 3.图像字幕(Image Captioning)
|
||||
|
||||
mage字幕是为给定图像生成文本描述的任务。
|
||||
|
||||
下面是一些很好的初学者图像字幕数据集。
|
||||
|
||||
1. [上下文中的公共对象(COCO)](http://mscoco.org/dataset/#overview)。包含超过12万张带描述的图像的集合
|
||||
2. [Flickr 8K](http://nlp.cs.illinois.edu/HockenmaierGroup/8k-pictures.html)。从flickr.com获取的8千个描述图像的集合。
|
||||
3. [Flickr 30K](http://shannon.cs.illinois.edu/DenotationGraph/)。从flickr.com获取的3万个描述图像的集合。
|
||||
欲了解更多,请看帖子:
|
||||
|
||||
[探索图像字幕数据集,2016年](http://sidgan.me/technical/2016/01/09/Exploring-Datasets)
|
||||
|
||||
#### 4.机器翻译(Machine Translation)
|
||||
|
||||
机器翻译是将文本从一种语言翻译成另一种语言的任务。
|
||||
|
||||
下面是一些很好的初学者机器翻译数据集。
|
||||
|
||||
1. [加拿大第36届议会的协调国会议员](https://www.isi.edu/natural-language/download/hansard/)。成对的英语和法语句子。
|
||||
2. [欧洲议会诉讼平行语料库1996-2011](http://www.statmt.org/europarl/)。句子对一套欧洲语言。
|
||||
有大量标准数据集用于年度机器翻译挑战; 看到:
|
||||
|
||||
[统计机器翻译](http://www.statmt.org/)
|
||||
|
||||
> 机器翻译
|
||||
|
||||
* Encoder + Decoder(Attention)
|
||||
* 参考案例: http://pytorch.apachecn.org/cn/tutorials/intermediate/seq2seq_translation_tutorial.html
|
||||
|
||||
#### 5.问答系统(Question Answering)
|
||||
|
||||
问答是一项任务,其中提供了一个句子或文本样本,从中提出问题并且必须回答问题。
|
||||
|
||||
下面是一些很好的初学者问题回答数据集。
|
||||
|
||||
1. [斯坦福问题回答数据集(SQuAD)](https://rajpurkar.github.io/SQuAD-explorer/)。回答有关维基百科文章的问题。
|
||||
2. [Deepmind问题回答语料库](https://github.com/deepmind/rc-data)。从每日邮报回答有关新闻文章的问题。
|
||||
3. [亚马逊问答数据](http://jmcauley.ucsd.edu/data/amazon/qa/)。回答有关亚马逊产品的问题。
|
||||
有关更多信息,请参阅帖子:
|
||||
|
||||
[数据集:我如何获得问答网站的语料库,如Quora或Yahoo Answers或Stack Overflow来分析答案质量?](https://www.quora.com/Datasets-How-can-I-get-corpus-of-a-question-answering-website-like-Quora-or-Yahoo-Answers-or-Stack-Overflow-for-analyzing-answer-quality)
|
||||
|
||||
#### 6.语音识别(Speech Recognition)
|
||||
|
||||
语音识别是将口语的音频转换为人类可读文本的任务。
|
||||
|
||||
下面是一些很好的初学者语音识别数据集。
|
||||
|
||||
1. [TIMIT声学 - 语音连续语音语料库](https://catalog.ldc.upenn.edu/LDC93S1)。不是免费的,但因其广泛使用而上市。口语美国英语和相关的转录。
|
||||
2. [VoxForge](http://voxforge.org/)。用于构建用于语音识别的开源数据库的项目。
|
||||
3. [LibriSpeech ASR语料库](http://www.openslr.org/12/)。从LibriVox收集的大量英语有声读物。
|
||||
|
||||
#### 7.自动文摘(Document Summarization)
|
||||
|
||||
文档摘要是创建较大文档的简短有意义描述的任务。
|
||||
|
||||
下面是一些很好的初学者文档摘要数据集。
|
||||
|
||||
1. [法律案例报告数据集](https://archive.ics.uci.edu/ml/datasets/Legal+Case+Reports)。收集了4000份法律案件及其摘要。
|
||||
2. [TIPSTER文本摘要评估会议语料库](http://www-nlpir.nist.gov/related_projects/tipster_summac/cmp_lg.html)。收集了近200份文件及其摘要。
|
||||
3. [英语新闻文本的AQUAINT语料库](https://catalog.ldc.upenn.edu/LDC2002T31)。不是免费的,而是广泛使用的。新闻文章的语料库。
|
||||
欲了解更多信息:
|
||||
|
||||
[文档理解会议(DUC)任务](http://www-nlpir.nist.gov/projects/duc/data.html)。
|
||||
[在哪里可以找到用于文本摘要的良好数据集?](https://www.quora.com/Where-can-I-find-good-data-sets-for-text-summarization)
|
||||
|
||||
> 命名实体识别
|
||||
|
||||
* Bi-LSTM CRF
|
||||
* 参考案例: http://pytorch.apachecn.org/cn/tutorials/beginner/nlp/advanced_tutorial.html
|
||||
* CRF推荐文档: https://www.jianshu.com/p/55755fc649b1
|
||||
|
||||
> 文本摘要
|
||||
|
||||
* **抽取式**
|
||||
* word2vec + textrank
|
||||
* word2vec推荐文档: https://www.zhihu.com/question/44832436/answer/266068967
|
||||
* textrank推荐文档: https://blog.csdn.net/BaiHuaXiu123/article/details/77847232
|
||||
|
||||
|
||||
## Graph图计算【慢慢更新】
|
||||
|
||||
* 数据集: [data/nlp/graph](data/nlp/graph)
|
||||
* 学习资料: spark graphX实战.pdf 【文件太大不方便提供,自己百度】
|
||||
|
||||
## 知识图谱
|
||||
|
||||
* 知识图谱,我只认 [SimmerChan](https://www.zhihu.com/people/simmerchan): [【知识图谱-给AI装个大脑】](https://zhuanlan.zhihu.com/knowledgegraph)
|
||||
* 说实话,我是看这博主老哥写的博客长大的,写的真的是深入浅出。我很喜欢,所以就分享给大家,希望你们也喜欢。
|
||||
|
||||
### 进一步阅读
|
||||
|
||||
如果您希望更深入,本节提供了其他数据集列表。
|
||||
|
||||
1. [维基百科研究中使用的文本数据集](https://en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research#Text_data)
|
||||
2. [数据集:计算语言学家和自然语言处理研究人员使用的主要文本语料库是什么?](https://www.quora.com/Datasets-What-are-the-major-text-corpora-used-by-computational-linguists-and-natural-language-processing-researchers-and-what-are-the-characteristics-biases-of-each-corpus)
|
||||
3. [斯坦福统计自然语言处理语料库](https://nlp.stanford.edu/links/statnlp.html#Corpora)
|
||||
4. [按字母顺序排列的NLP数据集列表](https://github.com/niderhoff/nlp-datasets)
|
||||
5. [该机构NLTK](http://www.nltk.org/nltk_data/)
|
||||
6. [在DL4J上打开深度学习数据](https://deeplearning4j.org/opendata)
|
||||
7. [NLP数据集](https://github.com/caesar0301/awesome-public-datasets#natural-language)
|
||||
8. 国内开放数据集: https://bosonnlp.com/dev/resource
|
||||
|
||||
## 项目负责人
|
||||
|
||||
> Ml 第一期 (2017-02-27)
|
||||
|
||||
* [@片刻](https://github.com/jiangzhonglian)
|
||||
* [@那伊抹微笑](https://github.com/wangyangting)
|
||||
* [@瑶妹](https://github.com/chenyyx)
|
||||
* [2017-04-08_第一期的总结](/report/2017-04-08_第一期的总结.md)
|
||||
|
||||
> Ml 第二期 (2017-08-14)
|
||||
|
||||
* [@片刻](https://github.com/jiangzhonglian)
|
||||
* [@那伊抹微笑](https://github.com/wangyangting)
|
||||
* [@瑶妹](https://github.com/chenyyx)
|
||||
* [@Mike](https://github.com/mikechengwei)
|
||||
|
||||
> Ml 第三期 (2018-04-16)
|
||||
|
||||
## 项目贡献者
|
||||
|
||||
> Ml 第一期 (2017-02-27)
|
||||
|
||||
* [@侯法超](https://github.com/geekidentity)
|
||||
* [@hello19883](https://github.com/hello19883)
|
||||
* [@徐鑫](https://github.com/sheepmen)
|
||||
* [@ibe](https://github.com/highfei2011)
|
||||
|
||||
> Ml 第二期 (2017-08-14)
|
||||
|
||||
* [@Arithmetic](https://github.com/LeeMoonCh)
|
||||
* [@Veyron C](https://github.com/caopeirui)
|
||||
* [@Cugtyt](https://github.com/Cugtyt)
|
||||
* [@BBruceyuan](https://github.com/hey-bruce)
|
||||
|
||||
> Ml 第三期 (2018-04-16)
|
||||
|
||||
## 群管理员换届
|
||||
|
||||
* [@瑶妹](https://github.com/chenyyx)
|
||||
* [@飞龙](https://github.com/wizardforcel)
|
||||
* [@片刻](https://github.com/jiangzhonglian)
|
||||
* [@伪文艺.](https://github.com/Watermelon233)
|
||||
* [@那伊抹微笑](https://github.com/wangyangting)
|
||||
* [@LAMDA-健忘症]() 永久留任-非常感谢对群的贡献
|
||||
|
||||
> Ml 第一届 (2017-09-01)
|
||||
|
||||
* [@易漠]()
|
||||
* [@Mike](https://github.com/mikechengwei)
|
||||
* [@Books]()
|
||||
* [@李孟禹]()
|
||||
* [@张假飞]()
|
||||
* [@Glassy]()
|
||||
* [@红色石头]()
|
||||
* [@微光同尘]()
|
||||
|
||||
> Ml 第二届 (2018-07-04)
|
||||
|
||||
* [@张假飞]()
|
||||
* [@李孟禹]()
|
||||
* [@小明教主]()
|
||||
* [@平淡的天]()
|
||||
* [@凌少skierゞ]()
|
||||
* [@じ☆νЁ坐看云起]()
|
||||
* [古柳-DesertsX]()
|
||||
* [woodchuck]()
|
||||
* [自由精灵]()
|
||||
* [楚盟]()
|
||||
* [99杆清台]()
|
||||
* [时空守望者@]()
|
||||
* [只想发论文的渣渣]()
|
||||
* [目标: ml劝退专家]()
|
||||
|
||||
> Ml 第三届 (2019-01-01)
|
||||
|
||||
* [只会喊666的存在]()
|
||||
* [codefun007.xyz]()
|
||||
* [荼靡]()
|
||||
* [大鱼]()
|
||||
* [青鸟]()
|
||||
* [古柳-DesertsX]()
|
||||
* [Edge]()
|
||||
* [Alluka]()
|
||||
* [不发篇paper不改名片]()
|
||||
* [FontTian]()
|
||||
* [Bigjing]()
|
||||
* [仁 礼 智 爱]()
|
||||
* [可啪的小乖受]()
|
||||
* [老古董]()
|
||||
* [时空守望者]()
|
||||
* [我好菜啊]()
|
||||
* [Messi 19]()
|
||||
* [萌Jay小公举]()
|
||||
|
||||
> Ml 第四届 (2019-06-01)
|
||||
|
||||
* [佛学爱好者]()
|
||||
* [楚盟]()
|
||||
* [codefun007.xyz]()
|
||||
* [大鱼-群花-声优]()
|
||||
* [大海]()
|
||||
* [Edge]()
|
||||
* [if only]()
|
||||
* [李孟禹]()
|
||||
* [平静]()
|
||||
* [任务做不完]()
|
||||
* [仁礼智爱]()
|
||||
* [园时空守望者@]()
|
||||
* [坐看云起]()
|
||||
* [阿花君霸占路人]()
|
||||
* [烦焖鸡]()
|
||||
* [古柳-DesertsX]()
|
||||
* [青鸟(服务员)]()
|
||||
* [小明教主]()
|
||||
* [zhiqing]()
|
||||
* [SrL.z]()
|
||||
|
||||
**欢迎贡献者不断的追加**
|
||||
|
||||
## 免责声明 - 【只供学习参考】
|
||||
|
||||
* ApacheCN 纯粹出于学习目的与个人兴趣翻译本书
|
||||
* ApacheCN 保留对此版本译文的署名权及其它相关权利
|
||||
|
||||
## **协议**
|
||||
|
||||
* 以各项目协议为准。
|
||||
* ApacheCN 账号下没有协议的项目,一律视为 [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh)。
|
||||
|
||||
---
|
||||
|
||||
## 资料来源:
|
||||
|
||||
* 【比赛收集平台】: https://github.com/iphysresearch/DataSciComp
|
||||
* https://github.com/pbharrin/machinelearninginaction
|
||||
* https://machinelearningmastery.com/datasets-natural-language-processing
|
||||
|
||||
## 感谢信
|
||||
|
||||
最近无意收到群友推送的链接,发现得到大佬高度的认可,并在热心的推广
|
||||
|
||||
在此感谢:
|
||||
|
||||
* [量子位](https://www.zhihu.com/org/liang-zi-wei-48): <https://www.zhihu.com/question/20472776/answer/691646493>
|
||||
* 人工智能前沿讲习: <https://mp.weixin.qq.com/s/f2dqulxOPkt7k5hqPsydyQ>
|
||||
|
||||
## 赞助我们
|
||||
|
||||
<img src="http://data.apachecn.org/img/about/donate.jpg" alt="微信&支付宝" />
|
||||
|
||||
---
|
||||
|
||||
> 特别赞助商(欢迎“私聊”赞助)
|
||||
|
||||
<table>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" valign="middle">
|
||||
<a href="https://coding.net/?utm_source=ApacheCN&utm_medium=banner&utm_campaign=march2019" target="_blank">
|
||||
<img width="1080" src="http://data.apachecn.org/img/SpecialSponsors/CodingNet.png">
|
||||
</a>
|
||||
</td>
|
||||
</tbody>
|
||||
</table>
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
+ [第1章_基础知识](docs/ml/1.机器学习基础.md)
|
||||
+ [第2章_K近邻算法](docs/ml/2.k-近邻算法.md)
|
||||
+ [第3章_决策树算法](docs/ml/3.决策树.md)
|
||||
+ [第4章_朴素贝叶斯](docs/ml/4.朴素贝叶斯.md)
|
||||
+ [第5章_逻辑回归](docs/ml/5.Logistic回归.md)
|
||||
+ [第6章_支持向量机](docs/ml/6.支持向量机.md)
|
||||
+ [支持向量机的几个通俗理解](docs/ml/6.1.支持向量机的几个通俗理解.md)
|
||||
+ [第7章_集成方法](docs/ml/7.集成方法-随机森林和AdaBoost.md)
|
||||
+ [第8章_回归](docs/ml/8.回归.md)
|
||||
+ [第9章_树回归](docs/ml/9.树回归.md)
|
||||
+ [第10章_KMeans聚类](docs/ml/10.k-means聚类.md)
|
||||
+ [第11章_Apriori算法](docs/ml/11.使用Apriori算法进行关联分析.md)
|
||||
+ [第12章_FP-growth算法](docs/ml/12.使用FP-growth算法来高效发现频繁项集.md)
|
||||
+ [第13章_PCA降维](docs/ml/13.利用PCA来简化数据.md)
|
||||
+ [第14章_SVD简化数据](docs/ml/14.利用SVD简化数据.md)
|
||||
+ [第15章_大数据与MapReduce](docs/ml/15.大数据与MapReduce.md)
|
||||
+ [第16章_推荐系统](docs/ml/16.推荐系统.md)
|
||||
+ [为何录制教学版视频](docs/why-to-record-study-ml-video.md)
|
||||
+ [加入我们](docs/join-us.md)
|
||||
|
|
@ -0,0 +1,660 @@
|
|||
# 基础知识
|
||||

|
||||
## 1.数学
|
||||
数学是学不完的,也没有几个人能像博士一样扎实地学好数学基础,入门人工智能领域,其实只需要掌握必要的基础知识就好。AI的数学基础最主要是高等数学、线性代数、概率论与数理统计三门课程,这三门课程是本科必修的。这里整理了一个简易的数学入门文章。
|
||||
数学基础:高等数学
|
||||
[https://zhuanlan.zhihu.com/p/36311622](https://zhuanlan.zhihu.com/p/36311622)
|
||||
数学基础:线性代数
|
||||
[https://zhuanlan.zhihu.com/p/36584206](https://zhuanlan.zhihu.com/p/36584206)
|
||||
数学基础:概率论与数理统计
|
||||
[https://zhuanlan.zhihu.com/p/36584335](https://zhuanlan.zhihu.com/p/36584335)
|
||||
|
||||
机器学习的数学基础资料下载:
|
||||
1.机器学习的数学基础.docx
|
||||
中文版,对高等数学、线性代数、概率论与数理统计三门课的公式做了总结
|
||||
2) 斯坦福大学机器学习的数学基础.pdf
|
||||
原版英文材料,非常全面,建议英语好的同学直接学习这个材料
|
||||
下载链接: [https://pan.baidu.com/s/1LaUlrJzy98CG1Wma9FgBtg](https://pan.baidu.com/s/1LaUlrJzy98CG1Wma9FgBtg) 提取码: hktx
|
||||
|
||||
推荐教材
|
||||
相比国内浙大版和同济版的数学教材,通俗易懂,便于初学者更好地奠定数学基础
|
||||
下载链接:[https://blog.csdn.net/Datawhale/article/details/81744961](https://blog.csdn.net/Datawhale/article/details/81744961)
|
||||
|
||||
## 2.统计学
|
||||
* 入门教材:
|
||||
|
||||
深入浅出统计学
|
||||
* 进阶教材:
|
||||
|
||||
商务与经济统计
|
||||
* 视频
|
||||
|
||||
可汗学院统计学:[http://open.163.com/special/Khan/khstatistics.html](http://open.163.com/special/Khan/khstatistics.html)
|
||||
|
||||
## 3.编程
|
||||
入门人工智能领域,推荐Python这门编程语言。
|
||||
1) Python安装:
|
||||
关于python安装包,我推荐下载Anaconda,Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本Python并存、切换以及各种第三方包安装问题。
|
||||
下载地址:[https://www.](https://link.zhihu.com/?target=https%3A//www.anaconda.com/download/)[anaconda.com/download/](https://link.zhihu.com/?target=https%3A//www.anaconda.com/download/) 推荐选Anaconda (python 3.7版本)
|
||||
|
||||
IDE:推荐使用pycharm,社区版免费
|
||||
下载地址:[https://www.](https://link.zhihu.com/?target=https%3A//www.jetbrains.com/)[jetbrains.com/](https://link.zhihu.com/?target=https%3A//www.jetbrains.com/)
|
||||
|
||||
安装教程:
|
||||
Anaconda+Jupyter notebook+Pycharm:
|
||||
[https://zhuanlan.zhihu.com/p/59027692](https://zhuanlan.zhihu.com/p/59027692)
|
||||
Ubuntu18.04深度学习环境配置(CUDA9+CUDNN7.4+TensorFlow1.8):
|
||||
[https://zhuanlan.zhihu.com/p/50302396](https://zhuanlan.zhihu.com/p/50302396)
|
||||
|
||||
|
||||
2) python入门的资料推荐
|
||||
a.廖雪峰python学习笔记
|
||||
[https://blog.csdn.net/datawhale/article/category/7779959](https://blog.csdn.net/datawhale/article/category/7779959)
|
||||
|
||||
b.python入门笔记
|
||||
作者李金,这个是jupyter notebook文件,把python的主要语法演示了一次,值得推荐。
|
||||
下载链接: [https://pan.baidu.com/s/1IPZI5rygbIh5R5OuTHajzA](https://pan.baidu.com/s/1IPZI5rygbIh5R5OuTHajzA) 提取码: 2bzh
|
||||
|
||||
|
||||
c.南京大学python视频教程
|
||||
这个教程非常值得推荐,python主要语法和常用的库基本涵盖了。
|
||||
查看地址:[https://www.icourse163.org/course/0809NJU004-1001571005?from=study](https://www.icourse163.org/course/0809NJU004-1001571005?from=study)
|
||||
|
||||
看完这三个资料,python基本入门了,可以使用scikit-learn等机器学习库来解决机器学习的
|
||||
问题了。
|
||||
|
||||
3)补充
|
||||
代码规范:
|
||||
[https://zhuanlan.zhihu.com/p/59763076](https://zhuanlan.zhihu.com/p/59763076)
|
||||
numpy练习题:
|
||||
[https://zhuanlan.zhihu.com/p/57872490](https://zhuanlan.zhihu.com/p/57872490)
|
||||
pandas练习题:
|
||||
[https://zhuanlan.zhihu.com/p/56644669](https://zhuanlan.zhihu.com/p/56644669)
|
||||
|
||||
# 数据分析/挖掘
|
||||

|
||||
## 1.数据分析的基础书籍:
|
||||
《利用python进行数据分析》
|
||||
这本书含有大量的实践案例,你将学会如何利用各种Python库(包括NumPy,Pandas、Matplotlib以及IPython等)高效地解决各式各样的数据分析问题。如果把代码都运行一次,基本上就能解决数据分析的大部分问题了。
|
||||
## 2.特征工程:
|
||||
[https://blog.csdn.net/Datawhale/article/details/83033869](https://blog.csdn.net/Datawhale/article/details/83033869)
|
||||
## 3.数据挖掘项目:
|
||||
[https://blog.csdn.net/datawhale/article/details/80847662](https://blog.csdn.net/datawhale/article/details/80847662)
|
||||
# 机器学习
|
||||

|
||||
## 1.公开课 - 吴恩达《Machine Learning》
|
||||
这绝对是机器学习入门的首选课程,没有之一!即便你没有扎实的机器学习所需的扎实的概率论、线性代数等数学基础,也能轻松上手这门机器学习入门课,并体会到机器学习的无穷趣味。
|
||||
|
||||
课程主页
|
||||
[https://www.coursera.org/learn/machine-learning](https://www.coursera.org/learn/machine-learning)
|
||||
|
||||
课程完整思维导图:
|
||||
|
||||

|
||||
|
||||
下载链接:[https://pan.baidu.com/s/16065BpNAP7JEx_PpFHLSOw](https://pan.baidu.com/s/16065BpNAP7JEx_PpFHLSOw)[ ](https://pan.baidu.com/s/16065BpNAP7JEx_PpFHLSOw提取码)提取码:xcmi
|
||||
|
||||
**中文视频**
|
||||
网易云课堂搬运了这门课,并由黄海广等人翻译了中文字幕。
|
||||
|
||||
观看地址:[https://study.163.com/course/introduction.htm?courseId=1004570029&_trace_c_p_k2_=d107b2ac93794ae79c941899f93332a1](https://study.163.com/course/introduction.htm?courseId=1004570029&_trace_c_p_k2_=d107b2ac93794ae79c941899f93332a1)
|
||||
|
||||
**中文笔记及作业代码**
|
||||
[https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes](https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes)
|
||||
|
||||
|
||||
## 2.公开课 - 吴恩达 CS229
|
||||
吴恩达在斯坦福教授的机器学习课程 CS229 与 吴恩达在 Coursera 上的《Machine Learning》相似,但是有更多的数学要求和公式的推导,难度稍难一些。该课程对机器学习和统计模式识别进行了广泛的介绍。主题包括:监督学习(生成/鉴别学习、参数/非参数学习、神经网络、支持向量机);无监督学习(聚类、降维、核方法);学习理论(偏差/方差权衡;VC理论;大幅度利润);强化学习和自适应控制。本课程还将讨论机器学习的最新应用,如机器人控制、数据挖掘、自主导航、生物信息学、语音识别以及文本和Web数据处理。
|
||||
### 课程主页:[http://cs229.stanford.edu/](http://cs229.stanford.edu/)
|
||||
### 中文视频
|
||||
[http://open.163.com/special/opencourse/machinelearning.html](http://open.163.com/special/opencourse/machinelearning.html)
|
||||
### 中文笔记
|
||||
[https://kivy-cn.github.io/Stanford-CS-229-CN/#/](https://kivy-cn.github.io/Stanford-CS-229-CN/#/)
|
||||
### 速查表
|
||||
这份给力的资源贡献者是一名斯坦福的毕业生 Shervine Amidi。作者关于 CS229 整理了一份超级详细的速查表
|
||||
[https://zhuanlan.zhihu.com/p/56534902](https://zhuanlan.zhihu.com/p/56534902)
|
||||
### 作业代码
|
||||
[https://github.com/Sierkinhane/CS229-ML-Implements](https://github.com/Sierkinhane/CS229-ML-Implements)
|
||||
## 3.公开课 - 林轩田《机器学习基石》
|
||||
### 课程介绍
|
||||
台湾大学林轩田老师的《机器学习基石》课程由浅入深、内容全面,基本涵盖了机器学习领域的很多方面。其作为机器学习的入门和进阶资料非常适合。而且林老师的教学风格也很幽默风趣,总让读者在轻松愉快的氛围中掌握知识。这门课比 Ng 的《Machine Learning》稍难一些,侧重于机器学习理论知识。
|
||||
### 中文视频
|
||||
[https://www.bilibili.com/video/av36731342](https://www.bilibili.com/video/av36731342)
|
||||
### 中文笔记
|
||||
[https://redstonewill.com/category/ai-notes/lin-ml-foundations/](https://redstonewill.com/category/ai-notes/lin-ml-foundations/)
|
||||
### 配套教材
|
||||
配套书籍为《Learning From Data》,在线书籍主页:[http://amlbook.com/](http://amlbook.com/)
|
||||
## 4.公开课 - 林轩田《机器学习技法》
|
||||
### 课程介绍
|
||||
《机器学习技法》课程是《机器学习基石》的进阶课程。主要介绍了机器学习领域经典的一些算法,包括支持向量机、决策树、随机森林、神经网络等等。难度要略高于《机器学习基石》,具有很强的实用性。
|
||||
### 中文视频
|
||||
[https://www.bilibili.com/video/av36760800](https://www.bilibili.com/video/av36760800)
|
||||
### 中文笔记
|
||||
[https://redstonewill.com/category/ai-notes/lin-ml-techniques/](https://redstonewill.com/category/ai-notes/lin-ml-techniques/)
|
||||
## 5.书籍 - 《机器学习》
|
||||
周志华的《机器学习》被大家亲切地称为“西瓜书”。这本书非常经典,讲述了机器学习核心数学理论和算法,适合有作为学校的教材或者中阶读者自学使用,入门时学习这本书籍难度稍微偏高了一些。
|
||||

|
||||
这本书配合《机器学习实战》这本书,效果很好!
|
||||
### 读书笔记
|
||||
[https://www.cnblogs.com/limitlessun/p/8505647.html#_label0](https://www.cnblogs.com/limitlessun/p/8505647.html#_label0)
|
||||
### 公式推导
|
||||
[https://datawhalechina.github.io/pumpkin-book/#/](https://datawhalechina.github.io/pumpkin-book/#/)
|
||||
### 课后习题
|
||||
[https://zhuanlan.zhihu.com/c_1013850291887845376](https://zhuanlan.zhihu.com/c_1013850291887845376)
|
||||
|
||||
## 6.书籍 - 《统计学习方法》
|
||||
李航的这本《统计学习方法》堪称经典,包含更加完备和专业的机器学习理论知识,作为夯实理论非常不错。
|
||||

|
||||
### 课讲 PPT
|
||||
[https://github.com/fengdu78/lihang-code/tree/master/ppt](https://github.com/fengdu78/lihang-code/tree/master/ppt)
|
||||
### 读书笔记
|
||||
[http://www.cnblogs.com/limitlessun/p/86111](http://www.cnblogs.com/limitlessun/p/8611103.html)[03.html](http://03.html
|
||||
参考笔记
|
||||
https://zhuanlan.zhihu.com/p/36378498
|
||||
代码实现
|
||||
)
|
||||
|
||||
[https://github.com/SmirkCao/Lihang](https://github.com/SmirkCao/Lihang)
|
||||
### 参考笔记
|
||||
[https://zhuanlan.zhihu.com/p/36378498](http://03.html
|
||||
参考笔记
|
||||
https://zhuanlan.zhihu.com/p/36378498
|
||||
代码实现
|
||||
)
|
||||
### 代码实现
|
||||
[https://github.com/fengdu78/lihang-code/tree/master/code](https://github.com/fengdu78/lihang-code/tree/master/code)
|
||||
## 7.书籍 - 《Scikit-Learn 与 TensorFlow 机器学习实用指南》
|
||||
在经过前面的学习之后,这本《Scikit-Learn 与 TensorFlow 机器学习实用指南》非常适合提升你的机器学习实战编程能力。这本书分为两大部分,第一部分介绍机器学习基础算法,每章都配备 Scikit-Learn 实操项目;第二部分介绍神经网络与深度学习,每章配备 TensorFlow 实操项目。如果只是机器学习,可先看第一部分的内容。
|
||||

|
||||
### 全书代码
|
||||
[https://github.com/ageron/handson-ml](https://github.com/ageron/handson-ml)
|
||||
## 8.实战 - Kaggle 比赛
|
||||
比赛是提升自己机器学习实战能力的最有效的方式,首选 Kaggle 比赛。
|
||||
### Kaggle 主页
|
||||
[https://www.kaggle.com/](https://www.kaggle.com/)
|
||||
### Kaggle 路线
|
||||
[https://github.com/apachecn/kaggle](https://github.com/apachecn/kaggle)
|
||||
## 9.工具 - Scikit-Learn 官方文档
|
||||
Scikit-Learn 作为机器学习一个非常全面的库,是一份不可多得的实战编程手册。
|
||||
### 官方文档
|
||||
[https://scikit-learn.org/stable/index.html](https://scikit-learn.org/stable/index.html)
|
||||
### 中文文档(0.19)
|
||||
[http://sklearn.apachecn.org/#/](http://sklearn.apachecn.org/#/)
|
||||
# 深度学习
|
||||

|
||||
## 1.公开课 - 吴恩达《Deep Learning》
|
||||
在吴恩达开设了机器学习课程之后,发布的《Deep Learning》课程也备受好评,吴恩达老师的课程最大的特点就是将知识循序渐进的传授给你,是入门学习不可多得良好视频资料。整个专题共包括五门课程:01.神经网络和深度学习;02.改善深层神经网络-超参数调试、正则化以及优化;03.结构化机器学习项目;04.卷积神经网络;05.序列模型。
|
||||
### 课程视频
|
||||
网易云课堂:[https://mooc.study.163.com/university/deeplearning_ai#/c](https://mooc.study.163.com/university/deeplearning_ai#/c)
|
||||
Coursera: [https://www.coursera.org/specializations/deep-learning](https://www.coursera.org/specializations/deep-learning)
|
||||
|
||||
### 课程笔记
|
||||
之前编写过吴恩达老师机器学习个人笔记黄海广博士带领团队整理了中文笔记
|
||||
地址:[https://github.com/fengdu78/deeplearning_ai_books](https://github.com/fengdu78/deeplearning_ai_books)
|
||||
### 参考论文
|
||||
吴恩达老师在课程中提到了很多优秀论文,黄海广博士整理如下:
|
||||
[https://github.com/fengdu78/deeplearning_ai_books/tree/master/%E5%8F%82%E8%80%83%E8%AE%BA%E6%96%87](https://github.com/fengdu78/deeplearning_ai_books/tree/master/%E5%8F%82%E8%80%83%E8%AE%BA%E6%96%87)
|
||||
|
||||
### 课程PPT及课后作业
|
||||
吴恩达深度学习课程,包含课程的课件、课后作业和一些其他资料:
|
||||
[https://github.com/stormstone/deeplearning.ai](https://github.com/stormstone/deeplearning.ai)
|
||||
|
||||
## 2.公开课 - Fast.ai《程序员深度学习实战》
|
||||
说到深度学习的公开课,与吴恩达《Deep Learning》并驾齐驱的另一门公开课便是由Fast.ai出品的《程序员深度学习实战》。这门课最大的特点便是**“自上而下”**而不是**“自下而上”**,是绝佳的通过实战学习深度学习的课程。
|
||||
### 视频地址
|
||||
B站地址(英文字幕):
|
||||
[https://www.bilibili.com/video/av18904696?from=search&seid=10813837536595120136](https://www.bilibili.com/video/av18904696?from=search&seid=10813837536595120136)
|
||||
CSDN地址(2017版中文字幕):
|
||||
[https://edu.csdn.net/course/detail/5192](https://edu.csdn.net/course/detail/5192)
|
||||
### 课程笔记
|
||||
英文笔记原文:
|
||||
[https://medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-1-602f73869197](https://medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-1-602f73869197)
|
||||
由ApacheCN组织进行的中文翻译:
|
||||
[https://github.com/apachecn/fastai-ml-dl-notes-zh](https://github.com/apachecn/fastai-ml-dl-notes-zh)
|
||||
|
||||
## 3.公开课-CS230 Deep Learning
|
||||
### 课程介绍
|
||||
斯坦福的深度学习课程CS230在4月2日刚刚开课,对应的全套PPT也随之上线。从内容来看,今年的课程与去年的差别不大,涵盖了CNNs, RNNs, LSTM, Adam, Dropout, BatchNorm, Xavier/He initialization 等深度学习的基本模型,涉及医疗、自动驾驶、手语识别、音乐生成和自然语言处理等领域。
|
||||
|
||||
Datawhale整理了该门课程的详细介绍及参考资料
|
||||
[https://mp.weixin.qq.com/s/kA-L8t5mGq6jExMBRjyg4g](https://mp.weixin.qq.com/s/kA-L8t5mGq6jExMBRjyg4g)
|
||||
###
|
||||
## 4.书籍-复旦教授邱锡鹏《神经网络与深度学习》
|
||||
本书是入门深度学习领域的极佳教材,主要介绍了神经网络与深度学习中的基础知识、主要模型(前馈网络、卷积网络、循环网络等)以及在计算机视觉、自然语言处理等领域的应用。
|
||||
[https://mp.weixin.qq.com/s/-NaDpXsxvu4DpXqVNXIAvQ](https://mp.weixin.qq.com/s/-NaDpXsxvu4DpXqVNXIAvQ)
|
||||
|
||||
## 5.书籍 -《深度学习》
|
||||

|
||||
完成以上学习后,想要更加系统的建立深度学习的知识体系,阅读《深度学习》准没错。该书从浅入深介绍了基础数学知识、机器学习经验以及现阶段深度学习的理论和发展,它能帮助人工智能技术爱好者和从业人员在三位专家学者的思维带领下全方位了解深度学习。
|
||||
### 书籍介绍
|
||||
《深度学习》通常又被称为花书,深度学习领域最经典的畅销书。由全球知名的三位专家IanGoodfellow、YoshuaBengio和AaronCourville撰写,是深度学习领域奠基性的经典教材。全书的内容包括3个部分:第1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第2部分系统深入地讲解现今已成熟的深度学习方法和技术;第3部分讨论某些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。该书被大众尊称为“AI圣经”。
|
||||
|
||||
### 在线阅读
|
||||
该书由众多网友众包翻译,电子版在以下地址获得:
|
||||
[https://github.com/exacity/deeplearningbook-chinese](https://github.com/exacity/deeplearningbook-chinese)
|
||||
|
||||
## 6.书籍 -《深度学习 500 问》
|
||||
当你看完了所有的视频,研习了AI圣经,一定充满了满脑子问号,此时不如来深度学习面试中常见的500个问题。
|
||||
### 书籍介绍
|
||||
DeepLearning-500-questions,作者是川大的一名优秀毕业生谈继勇。该项目以深度学习面试问答形式,收集了 500 个问题和答案。内容涉及了常用的概率知识、线性代数、机器学习、深度学习、计算机视觉等热点问题,该书目前尚未完结,却已经收获了Github 2.4w stars。
|
||||
### 项目地址
|
||||
[https://github.com/scutan90/DeepLearning-500-questions](https://github.com/scutan90/DeepLearning-500-questions)
|
||||
|
||||
## 7.工具 - TensorFlow 官方文档
|
||||
进行深度学习怎么离得开TensorFlow
|
||||
### 官方文档
|
||||
[https://www.tensorflow.org/api_docs/python/tf](https://www.tensorflow.org/api_docs/python/tf)
|
||||
### 中文文档
|
||||
[https://github.com/jikexueyuanwiki/tensorflow-zh](https://github.com/jikexueyuanwiki/tensorflow-zh)
|
||||
|
||||
## 7.工具 - PyTorch官方文档
|
||||
PyTorch是进行深度学习的另一个主流框架
|
||||
### 官方文档
|
||||
[https://pytorch.org/docs/stable/index.html](https://pytorch.org/docs/stable/index.html)
|
||||
### 中文文档(版本0.3)
|
||||
[https://github.com/apachecn/pytorch-doc-zh](https://github.com/apachecn/pytorch-doc-zh)
|
||||
# 强化学习
|
||||

|
||||
## 1.公开课 - David Silver《Reinforcement Learning》
|
||||
同吴恩达的课程对于机器学习和深度学习初学者的意义一样,David Silver的这门课程绝对是大多数人学习强化学习必选的课程。课程从浅到深,把强化学习的内容娓娓道来,极其详尽。不过由于强化学习本身的难度,听讲这门课还是有一定的门槛,建议还是在大致了解这个领域之后观看该视频学习效果更佳,更容易找到学习的重点。另外,由于强化学习领域飞速地发展,最前沿的知识(特别是与深度学习相关的)没有被涵盖在这个课程中,需要另外补充。
|
||||
### 课程介绍
|
||||
该课程对强化学习领域做了相当详尽的讲解,其主要内容有:马尔可夫决策过程(强化学习的基础理论)、动态规划、免模型预测(蒙特卡洛学习、时序差分学习和λ时序差分强化学习)、免模型控制(On-policy Learning和Off-policy Learning)、价值函数的近似表示、策略梯度算法、集成学习与计划、探索与利用以及实例演示。
|
||||
|
||||
### 视频地址
|
||||
B站地址(中文字幕):
|
||||
[https://www.bilibili.com/video/av45357759?from=search&seid=9547815852611563503](https://www.bilibili.com/video/av45357759?from=search&seid=9547815852611563503)
|
||||
课程原地址:
|
||||
[https://www.youtube.com/watch?v=2pWv7GOvuf0](https://www.youtube.com/watch?v=2pWv7GOvuf0)
|
||||
|
||||
### 课程资料
|
||||
课程PPT:
|
||||
[http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html](http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html)
|
||||
课程笔记:
|
||||
[https://www.zhihu.com/people/qqiang00/posts](https://www.zhihu.com/people/qqiang00/posts)
|
||||
|
||||
## 2.公开课 - 李宏毅《深度强化学习》
|
||||
David Silver的课程虽然内容详尽,但前沿的很多内容都没有被包括在内,这时,台大李宏毅的《深度强化学习》就是学习前沿动态的不二之选。李宏毅老师讲课非常幽默风趣,并且浅显易懂,而且对于大多数初学者来说,中文教学可谓是福音。当然,这门课程也有着没有对理论知识做太多详尽地展开、内容主要围绕着深度强化学习进行等缺陷,但这并不妨碍其成为初学者们的首选之一。
|
||||
### 课程介绍
|
||||
该课程上线于2018年,基本涵盖了当年的前沿技术,其主要内容有:策略梯度算法(David Silver的课程中提到的算法大多都在这部分的内容中提到,但其主要是从神经网络的角度出发)、Q-learning(这部分涵盖了大量的Q-learning优化的讲解)、Actor-Critic、Sparse Reward 和 Imitation Learning。
|
||||
### 视频地址
|
||||
B站地址(中文字幕):
|
||||
[https://www.bilibili.com/video/av24724071?from=search&seid=9547815852611563503](https://www.bilibili.com/video/av24724071?from=search&seid=9547815852611563503)
|
||||
课程原地址:
|
||||
[https://www.youtube.com/watch?v=2pWv7GOvuf0](https://www.youtube.com/watch?v=2pWv7GOvuf0)
|
||||
|
||||
### 课程资料
|
||||
课程PPT:
|
||||
[http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html](http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html)
|
||||
课程笔记:
|
||||
[https://blog.csdn.net/cindy_1102/article/details/87905272](https://blog.csdn.net/cindy_1102/article/details/87905272)
|
||||
|
||||
|
||||
# 前沿 Paper
|
||||

|
||||
## Arxiv
|
||||
### Arxiv Stats
|
||||
Arxiv 机器学习最新论文检索,主页地址:
|
||||
[https://arxiv.or](https://arxiv.org/list/stat.ML/recent?ref=bestofml.com)[g/list/stat.ML](https://arxiv.org/list/stat.ML/recent?ref=bestofml.com)[/recent?ref=bestofml.com](https://arxiv.org/list/stat.ML/recent?ref=bestofml.com)
|
||||
### Arxiv Sanity Preserver
|
||||
Andrej Karpathy 开发了 Arxiv Sanity Preserver,帮助分类、搜索和过滤特征,主页地址:
|
||||
[ht](http://www.arxiv-sanity.com/?ref=bestofml.com)[tp://www.arxiv-sanity.com/?ref=bestofml.co](http://www.arxiv-sanity.com/?ref=bestofml.com)[m](http://www.arxiv-sanity.com/?ref=bestofml.com)
|
||||
## Papers with Code
|
||||
### Papers with Code(Browse state-of-the-art)
|
||||
这个网站叫做 Browse state-of-the-art。它将 ArXiv 上的最新深度学习论文与 GitHub 上的开源代码联系起来。该项目目前包含了 651 个排行榜,1016 个深度学习任务,795 个数据集,以及重磅的 10257 个含复现代码的优秀论文。简直就是一个寻找论文和代码的利器。它将 1016 个深度学习任务分成了 16 大类,涉及了深度学习的各个方面。
|
||||
|
||||
主页地址:
|
||||
[https://paperswithcode.com/sota](https://paperswithcode.com/sota)
|
||||
|
||||
举两个例子:
|
||||
|
||||
(1)CV:[https://paperswithcode.com/area/computer-vision](https://paperswithcode.com/area/computer-vision)
|
||||
(2)NLP:[https://paperswithcode.com/area/natural-language-processing](https://paperswithcode.com/area/natural-language-processing)
|
||||
|
||||
介绍:[https://redstonewill.com/2039/](https://redstonewill.com/2039/)
|
||||
### Papers with Code(Sorted by stars)
|
||||
这份资源收集了 AI 领域从 2013 - 2018 年所有的论文,并按照在 GitHub 上的标星数量进行排序。GitHub 项目地址:
|
||||
[https://github.com/zziz/pwc](https://github.com/zziz/pwc)
|
||||
## Deep Learning Papers(Reading Roadmap)
|
||||
如果你是深度学习领域的新手,你可能会遇到的第一个问题是“我应该从哪篇论文开始阅读?”下面是一个深入学习论文的阅读路线图!GitHub 项目地址:
|
||||
[https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap](https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap)
|
||||
|
||||
这份深度学习论文阅读路线分为三大块:
|
||||
|
||||
**1 Deep Learning History and Basics**
|
||||
**2 Deep Learning Method**
|
||||
**3 Applications**
|
||||
## Deep Learning Object Detection
|
||||
目标检测(Object Detection)是深度学习 CV 领域的一个核心研究领域和重要分支。纵观 2013 年到 2019 年,从最早的 R-CNN、Fast R-CNN 到后来的 YOLO v2、YOLO v3 再到今年的 M2Det,新模型层出不穷,性能也越来越好!本资源对目标检测近几年的发展和相关论文做出一份系统介绍,总结一份超全的文献 paper 列表。
|
||||
|
||||

|
||||
|
||||
GitHub 项目地址:
|
||||
[https://github.com/hoya012/deep_learning_object_detection](https://github.com/hoya012/deep_learning_object_detection)
|
||||
|
||||
介绍:[https://redstonewill.com/1934/](https://redstonewill.com/1934/)
|
||||
## 知名会议
|
||||
**NeurIPS**:[https://nips.cc/](https://nips.cc/)
|
||||
**ICML**:[https://icml.cc/](https://icml.cc/)
|
||||
**ICLR**:[https://iclr.cc/](https://iclr.cc/)
|
||||
**AAAI**:[https://aaai.org/Conferences/AAAI-19/](https://aaai.org/Conferences/AAAI-19/)
|
||||
**IJCAI**:[https://www.ijcai.org/](https://www.ijcai.org/)
|
||||
**UAI**:[http://www.auai.org/uai2019/index.php](http://www.auai.org/uai2019/index.php)
|
||||
|
||||
### 计算机视觉:
|
||||
**CVPR**:[http://cvpr2019.thecvf.com/](http://cvpr2019.thecvf.com/)
|
||||
**ECCV**:[https://eccv2018.org/program/main-conference/](https://eccv2018.org/program/main-conference/)
|
||||
**ICCV**:[http://iccv2019.thecvf.com/](http://iccv2019.thecvf.com/)
|
||||
|
||||
### 自然语言处理:
|
||||
**ACL**:[http://www.aclcargo.com/](http://www.aclcargo.com/)
|
||||
**EMNLP**:[https://www.aclweb.org/portal/content/emnlp-2018](https://www.aclweb.org/portal/content/emnlp-2018)
|
||||
**NAACL**:[https://naacl2019.org/](https://naacl2019.org/)
|
||||
### 知名期刊
|
||||
**JAIR**:[https://www.jair.org/index.php/jair](https://www.jair.org/index.php/jair)
|
||||
**JMLR**:[http://www.jmlr.org/](http://www.jmlr.org/)
|
||||
### 其它
|
||||
机器人方面,有 CoRL(学习)、ICAPS(规划,包括但不限于机器人)、ICRA、IROS、RSS;对于更理论性的研究,有 AISTATS、COLT、KDD。
|
||||
# 理论应用
|
||||

|
||||
## 自然语言处理
|
||||
|
||||
1. NLP是什么
|
||||
|
||||
自然语言处理(NLP,Natural Language Processing)是研究计算机处理人类语言的一门技术,目的是弥补人类交流(自然语言)和计算机理解(机器语言)之间的差距。NLP包含句法语义分析、信息抽取、文本挖掘、机器翻译、信息检索、问答系统和对话系统等领域。
|
||||
|
||||
1. 课程推荐
|
||||
|
||||
① CS224n 斯坦福深度自然语言处理课
|
||||
17版中文字幕 [https://www.bilibili.com/video/av41393758/?p=1](https://www.bilibili.com/video/av41393758/?p=1)
|
||||
课程笔记:[http://www.hankcs.com/?s=CS224n%E7%AC%94%E8%AE%B0](http://www.hankcs.com/?s=CS224n%E7%AC%94%E8%AE%B0)
|
||||
2019版课程主页:[http://web.stanford.edu/class/cs224n/](http://web.stanford.edu/class/cs224n/) (需科学上网)
|
||||
② 自然语言处理 - Dan Jurafsky 和 Chris Manning
|
||||
B站英文字幕版:[https://www.bilibili.com/video/av35805262/](https://www.bilibili.com/video/av35805262/)
|
||||
学术激流网:[http://academictorrents.com/details/d2c8f8f1651740520b7dfab23438d89bc8c0c0ab](http://academictorrents.com/details/d2c8f8f1651740520b7dfab23438d89bc8c0c0ab)
|
||||
|
||||
1. 书籍推荐
|
||||
|
||||
① Python自然语言处理
|
||||
中英文版
|
||||
>入门读物,整本书不仅涉及了语料库的操作,也对传统的基于规则的方法有所涉及。全书包括了分词(tokenization)、词性标注(POS)、语块(Chunk)标注、句法剖析与语义剖析等方面,是nlp中不错的一本实用教程。
|
||||
|
||||
② 自然语言处理综论
|
||||
中英文版
|
||||
>By Daniel Jurafsky和James H. Martin
|
||||
>权威性杠杠的!经典的NLP教科书,涵盖了经典自然语言处理、统计自然语言处理、语音识别和计算语言学等方面。
|
||||
|
||||
③ 统计自然语言处理基础
|
||||
中英文版
|
||||
>By Chris Manning和HinrichSchütze
|
||||
>更高级的统计NLP方法,在统计基本部分和n元语法部分介绍地都很不错
|
||||
|
||||
1. 博客推荐
|
||||
|
||||
我爱自然语言处理网站 [http://www.52nlp.cn/](http://www.52nlp.cn/)
|
||||
>TFIDF、文档相似度等等网站上都有通俗易懂的解释
|
||||
|
||||
语言日志博客(Mark Liberman)[http://languagelog.ldc.upenn.edu/nll/](http://languagelog.ldc.upenn.edu/nll/)
|
||||
natural language processing blog [https://nlpers.blogspot.com/](https://nlpers.blogspot.com/)
|
||||
>美国Hal Daumé III维护的一个natural language processing的博客,经常评论最新学术动态,值得关注。有关于ACL、NAACL等学术会议的参会感想和对论文的点评
|
||||
### 5.项目推荐
|
||||
基于LSTM的中文问答系统 [https://github.com/S-H-Y-GitHub/QA](https://github.com/S-H-Y-GitHub/QA)
|
||||
基于RNN的文本生成器 [https://github.com/karpathy/char-rnn](https://github.com/karpathy/char-rnn)
|
||||
基于char-rnn的汪峰歌词生成器 [https://github.com/phunterlau/wangfeng-rnn](https://github.com/phunterlau/wangfeng-rnn)
|
||||
用RNN生成手写数字 [https://github.com/skaae/lasagne-draw](https://github.com/skaae/lasagne-draw)
|
||||
1. 开源NLP工具包
|
||||
|
||||
中文NLP相关: [https://github.com/crownpku/Awesome-Chinese-NLP](https://github.com/crownpku/Awesome-Chinese-NLP)
|
||||
英文NLP相关:
|
||||
>NLTK [http://www.nltk.org/](http://www.nltk.org/)
|
||||
>TextBlob: [http://textblob.readthedocs.org/en/dev/](http://textblob.readthedocs.org/en/dev/)
|
||||
>Gensim: [http://radimrehurek.com/gensim/](http://radimrehurek.com/gensim/)
|
||||
>Pattern: [http://www.clips.ua.ac.be/pattern](http://www.clips.ua.ac.be/pattern)
|
||||
>Spacy:: [http://spacy.io](http://spacy.io)
|
||||
>Orange: [http://orange.biolab.si/features/](http://orange.biolab.si/features/)
|
||||
>Pineapple: [https://github.com/proycon/pynlpl](https://github.com/proycon/pynlpl)
|
||||
1. 相关论文
|
||||
|
||||
100 Must-Read NLP Papers [https://github.com/mhagiwara/100-nlp-papers](https://github.com/mhagiwara/100-nlp-papers)
|
||||
## **计算机视觉**
|
||||
1. 计算机视觉的应用
|
||||
| 计算机视觉的应用 | 无人驾驶 |
|
||||
|:----:|:----:|:----:|:----:|
|
||||
| | 无人安防 |
|
||||
| | 人脸识别 |
|
||||
| | 车辆车牌识别 |
|
||||
| | 以图搜图 |
|
||||
| | VR/AR |
|
||||
| | 3D重构 |
|
||||
| | 无人机 |
|
||||
| | 医学图像分析 |
|
||||
| | 其他 |
|
||||
|
||||
### 2.课程推荐
|
||||
**Stanford CS223B**
|
||||
比较适合基础,适合刚刚入门的同学,跟深度学习的结合相对来说会少一点,不会整门课讲深度学习,而是主要讲计算机视觉,方方面面都会讲到
|
||||
|
||||
李飞飞:CS231n课程
|
||||
[https://mp.weixin.qq.com/s/-NaDpXsxvu4DpXqVNXIAvQ](https://mp.weixin.qq.com/s/-NaDpXsxvu4DpXqVNXIAvQ)
|
||||
### 3.书籍推荐
|
||||
1)入门学习:《**Computer Vision:Models, Learning and Inference**》
|
||||
2)经典权威的参考资料:《**Computer Vision:Algorithms and Applications**》
|
||||
3)理论实践:《**OpenCV3编程入门**》
|
||||
## **推荐系统**
|
||||
### 1.推荐系统是什么
|
||||
推荐系统就是自动联系用户和物品的一种工具,它能够在信息过载的环境中帮助用户发现令他们感兴趣的信息,也能将信息推送给对它们感兴趣的用户。 推荐系统属于资讯过滤的一种应用。
|
||||
### 2.推荐课程
|
||||
推荐系统专项课程《[Recommender Systems Specialization](https://www.coursera.org/specializations/recommender-systems)》
|
||||
这个系列由4门子课程和1门毕业项目课程组成,包括推荐系统导论,最近邻协同过滤,推荐系统评价,矩阵分解和高级技术等。
|
||||
观看地址:[https://www.coursera.org/specializations/recommender-systems](https://www.coursera.org/specializations/recommender-systems)
|
||||
### 3.书籍推荐
|
||||
《推荐系统实践》(项亮 著)
|
||||
《推荐系统》(Dietmar Jannach等 著,蒋凡 译)
|
||||
《用户网络行为画像》(牛温佳等 著)
|
||||
《Recommender Systems Handbook》(Paul B·Kantor等 著)
|
||||
### 4.算法库
|
||||
**LibRec**
|
||||
LibRec是一个Java版本的覆盖了70余个各类型推荐算法的推荐系统开源算法库,由国内的推荐系统大牛郭贵冰创办,目前已更新到2.0版本,它有效地解决了评分预测和物品推荐两大关键的推荐问题。
|
||||
项目地址: [https://github.com/guoguibing/librec](https://github.com/guoguibing/librec)
|
||||
官网:[官网https://www.librec.net/](https://www.librec.net/)
|
||||
**LibMF**
|
||||
C++版本开源推荐系统,主要实现了基于矩阵分解的推荐系统。针对SGD(随即梯度下降)优化方法在并行计算中存在的 locking problem 和 memory discontinuity问题,提出了一种 矩阵分解的高效算法FPSGD(Fast Parallel SGD),根据计算节点的个数来划分评分矩阵block,并分配计算节点。
|
||||
项目地址:[http://www.csie.ntu.edu.tw/~cjlin/libmf/](http://www.csie.ntu.edu.tw/~cjlin/libmf/)
|
||||
**SurPRISE**
|
||||
一个Python版本的开源推荐系统,有多种经典推荐算法
|
||||
项目地址:[http://surpriselib.com/](http://surpriselib.com/)
|
||||
**Neural Collaborative Filtering**
|
||||
神经协同过滤推荐算法的Python实现
|
||||
项目地址:[https://github.com/hexiangnan/neural_collaborative_filtering](https://github.com/hexiangnan/neural_collaborative_filtering)
|
||||
**Crab**
|
||||
基于Python开发的开源推荐软件,其中实现有item和user的协同过滤
|
||||
项目地址:[http://muricoca.github.io/crab/](http://muricoca.github.io/crab/)
|
||||
|
||||
### 5.常用数据集
|
||||
**MovieLen**
|
||||
地址:[https://grouplens.org/datasets/movielens/](https://grouplens.org/datasets/movielens/)
|
||||
MovieLens数据集中,用户对自己看过的电影进行评分,分值为1~5。MovieLens包括两个不同大小的库,适用于不同规模的算法。小规模的库是943个独立用户对1 682部电影作的10 000次评分的数据;大规模的库是6 040个独立用户对3 900部电影作的大约100万次评分。适用于传统的推荐任务
|
||||
**Douban**
|
||||
地址:[https://www.cse.cuhk.edu.hk/irwin.king.new/pub/data/douban](https://www.cse.cuhk.edu.hk/irwin.king.new/pub/data/douban)
|
||||
Douban是豆瓣的匿名数据集,它包含了12万用户和5万条电影数据,是用户对电影的评分信息和用户间的社交信息,适用于社会化推荐任务。
|
||||
**BookCrossing**
|
||||
地址:[http://www2.informatik.uni-freiburg.de/~cziegler/BX/](http://www2.informatik.uni-freiburg.de/~cziegler/BX/)
|
||||
这个数据集是网上的Book-Crossing图书社区的278858个用户对271379本书进行的评分,包括显式和隐式的评分。这些用户的年龄等人口统计学属性(demographic feature)都以匿名的形式保存并供分析。这个数据集是由Cai-Nicolas Ziegler使用爬虫程序在2004年从Book-Crossing图书社区上采集的。
|
||||
**Jester Joke**
|
||||
地址:[http://eigentaste.berkeley.edu/dataset/](http://eigentaste.berkeley.edu/dataset/)
|
||||
Jester Joke是一个网上推荐和分享笑话的网站。这个数据集有73496个用户对100个笑话作的410万次评分。评分范围是−10~10的连续实数。这些数据是由加州大学伯克利分校的Ken Goldberg公布的。
|
||||
**Netflix**
|
||||
[地址:http://academictorrents.com/details/9b13183dc4d60676b773c9e2cd6de5e5542cee9a](http://academictorrents.com/details/9b13183dc4d60676b773c9e2cd6de5e5542cee9a)
|
||||
这个数据集来自于电影租赁网址Netflix的数据库。Netflix于2005年底公布此数据集并设立百万美元的奖金(netflix prize),征集能够使其推荐系统性能上升10%的推荐算法和架构。这个数据集包含了480 189个匿名用户对大约17 770部电影作的大约10亿次评分。
|
||||
Usenet Newsgroups(http://qwone.com/~jason/20Newsgroups/)
|
||||
这个数据集包括20个新闻组的用户浏览数据。最新的应用是在KDD 2007上的论文。新闻组的内容和讨论的话题包括计算机技术、摩托车、篮球、政治等。用户们对这些话题进行评价和反馈。
|
||||
**UCI库**
|
||||
地址:[https://archive.ics.uci.edu/ml/datasets.html](https://archive.ics.uci.edu/ml/datasets.html)
|
||||
UCI库是Blake等人在1998年开放的一个用于机器学习和评测的数据库,其中存储大量用于模型训练的标注样本,可用于推荐系统的性能测试数据。
|
||||
### 6.推荐论文
|
||||
经典必读论文整理,包括综述文章、传统经典推荐文章、社会化推荐文章、基于深度学习的推荐系统文章、专门用于解决冷启动的文章、POI相关的论文、利用哈希技术来加速推荐的文章以及推荐系统中经典的探索与利用问题的相关文章等。
|
||||
项目地址: [https://github.com/hongleizhang/RSPapers](https://github.com/hongleizhang/RSPapers)
|
||||
### 7.推荐项目
|
||||
今日头条推荐系统机制介绍,面向内容创作者
|
||||
[分享人:项亮,今日头条推荐算法架构师](https://v.qq.com/x/page/f0800qavik7.html?)
|
||||
[https://v.qq.com/x/page/f0800qavik7.html?](https://v.qq.com/x/page/f0800qavik7.html?)
|
||||
|
||||
3分钟了解今日头条推荐系统原理
|
||||
[https://v.qq.com/x/page/g05349lb80j.html?](https://v.qq.com/x/page/g05349lb80j.html?)
|
||||
|
||||
facebook是如何为十亿人推荐好友的
|
||||
[https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/](https://code.facebook.com/posts/861999383875667/recommending-items-to-more-than-a-billion-people/)
|
||||
|
||||
Netflix的个性化和推荐系统架构
|
||||
[http://techblog.netflix.com/2013/03/system-architectures-for.html](http://techblog.netflix.com/2013/03/system-architectures-for.html)
|
||||
|
||||
## 风控模型(评分卡模型)
|
||||
### 1.评分卡模型简介
|
||||
评分卡模型时在银行、互金等公司与借贷相关业务中最常见也是最重要的模型之一。简而言之它的作用就是对客户进行打分,来对客户是否优质进行评判。根据评分卡模型应用的业务阶段不用,评分卡模型主要分为三大类:A卡(Application score card)申请评分卡、B卡(Behavior score card)行为评分卡、C卡(Collection score card)催收评分卡。其中申请评分卡用于贷前,行为评分卡用于贷中,催收评分卡用于贷后,这三种评分卡在我们的信贷业务的整个生命周期都至关重要。
|
||||
### 2.推荐书籍
|
||||
《信用风险评分卡研究——基于SAS的开发与实施》
|
||||
### 3.评分卡模型建模过程
|
||||
(1)样本选取:确定训练样本、测试样本的观察窗(特征的时间跨度)与表现窗(标签的时间跨度),且样本的标签定义是什么?一般情况下风险评分卡的标签都是考虑客户某一段时间内的延滞情况。
|
||||
(2)特征准备:原始特征、衍生变量
|
||||
(3)数据清洗:根据业务需求对缺失值或异常值等进行处理
|
||||
(4)特征筛选:根据特征的IV值(特征对模型的贡献度)、PSI(特征的稳定性)来进行特征筛选,IV值越大越好(但是一个特征的IV值超过一定阈值可能要考虑是否用到未来数据),PSI越小越好(一般建模时取特征的PSI小于等于0.01)
|
||||
(5)对特征进行WOE转换,即对特征进行分箱操作,注意在进行WOE转换时要注重特征的可解释性
|
||||
(6)建立模型,在建立模型过程中可根据模型和变量的统计量判断模型中包含和不包含每个变量时的模型质量来进行变量的二次筛选。
|
||||
(7)评分卡模型一般关注的指标是KS值(衡量的是好坏样本累计分部之间的差值)、模型的PSI(即模型整体的稳定性)、AUC值等。
|
||||
## **知识图谱**
|
||||
### 1.知识图谱是什么
|
||||
知识图谱是一种结构化数据的处理方法,它涉及知识的提取、表示、存储、检索等一系列技术。从渊源上讲,它是知识表示与推理、数据库、信息检索、自然语言处理等多种技术发展的融合。
|
||||
### 2.推荐资料
|
||||
[为什么需要知识图谱?什么是知识图谱?——KG的前世今生](https://zhuanlan.zhihu.com/p/31726910)
|
||||
[什么是知识图谱?](https://zhuanlan.zhihu.com/p/34393554)
|
||||
[智能搜索时代:知识图谱有何价值?](https://zhuanlan.zhihu.com/p/35982177?from=1084395010&wm=9848_0009&weiboauthoruid=5249689143)
|
||||
[百度王海峰:知识图谱是 AI 的基石](http://www.infoq.com/cn/news/2017/11/Knowledge-map-cornerstone-AI#0-tsina-1-5001-397232819ff9a47a7b7e80a40613cfe1)
|
||||
[译文|从知识抽取到RDF知识图谱可视化](http://rdc.hundsun.com/portal/article/907.html?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io)
|
||||
### **3.主要内容**
|
||||
1. **知识提取**
|
||||
|
||||
构建kg首先需要解决的是数据,知识提取是要解决结构化数据生成的问题。我们可以用自然语言处理的方法,也可以利用规则。
|
||||
* 使用规则:
|
||||
* 正则表达式:
|
||||
|
||||
正则表达式(Regular Expression, regex)是字符串处理的基本功。数据爬取、数据清洗、实体提取、关系提取,都离不开regex。
|
||||
推荐资料入门:
|
||||
* [精通正则表达式](https://book.douban.com/subject/2154713/)
|
||||
* regexper 可视化: [例 [a-z]*(\d{4}(\D+))](https://regexper.com/#%5Ba-z%5D*(%5Cd%7B4%7D(%5CD%2B)))
|
||||
* pythex 在线测试正则表达式 [http://pythex.org/](http://pythex.org/)
|
||||
|
||||
推荐资料进阶:
|
||||
* re2 一个更快的Cython实现 [https://pypi.python.org/pypi/re2/](https://pypi.python.org/pypi/re2/)
|
||||
* Parsley 更人性化的正则表达语法 [http://parsley.readthedocs.io/en/latest/tutorial.html](http://parsley.readthedocs.io/en/latest/tutorial.html)
|
||||
|
||||
* 中文分词和词性标注
|
||||
|
||||
分词也是后续所有处理的基础,词性(Part of Speech, POS)就是中学大家学过的动词、名词、形容词等等的词的分类。一般的分词工具都会有词性标注的选项。
|
||||
推荐资料入门:
|
||||
* jieba 中文分词包 [https://github.com/fxsjy/jieba](https://github.com/fxsjy/jieba)
|
||||
* 中文词性标记集 [https://github.com/memect/kg-beijing/wiki/中文词性标记集](https://github.com/memect/kg-beijing/wiki/%E4%B8%AD%E6%96%87%E8%AF%8D%E6%80%A7%E6%A0%87%E8%AE%B0%E9%9B%86)
|
||||
|
||||
推荐资料进阶:
|
||||
* genius 采用 CRF条件随机场算法 [https://github.com/duanhongyi/genius](https://github.com/duanhongyi/genius)
|
||||
* Stanford CoreNLP分词 [https://blog.csdn.net/guolindonggld/article/details/72795022](https://blog.csdn.net/guolindonggld/article/details/72795022)
|
||||
|
||||
* 命名实体识别
|
||||
|
||||
命名实体识别(NER)是信息提取应用领域的重要基础工具,一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
|
||||
|
||||
推荐资料:
|
||||
* Stanford CoreNLP 进行中文命名实体识别 [https://blog.csdn.net/guolindonggld/article/details/72795022](https://blog.csdn.net/guolindonggld/article/details/72795022)
|
||||
* 使用深度学习:
|
||||
|
||||
使用自然语言处理的方法,一般是给定schema,从非结构化数据中抽取特定领域的三元组(spo),如最近[百度举办的比赛](http://lic2019.ccf.org.cn/kg)就是使用DL模型进行信息抽取。
|
||||
|
||||
* 序列标注
|
||||
|
||||
使用序列生出模型,主要是标记出三元组中subject及object的起始位置,从而抽取信息。
|
||||
推荐资料:
|
||||
* 序列标注问题 [https://www.cnblogs.com/jiangxinyang/p/9368482.html](https://www.cnblogs.com/jiangxinyang/p/9368482.html)
|
||||
|
||||
|
||||
* seq2seq
|
||||
|
||||
使用seq2seq端到端的模型,主要借鉴文本摘要的思想,将三元组看成是非结构化文本的摘要,从而进行抽取,其中还涉及Attention机制。
|
||||
|
||||
推荐资料:
|
||||
* seq2seq详解 [https://blog.csdn.net/irving_zhang/article/details/78889364](https://blog.csdn.net/irving_zhang/article/details/78889364)
|
||||
* 详解从Seq2Seq模型到Attention模型 [https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/](https://caicai.science/2018/10/06/attention%E6%80%BB%E8%A7%88/)
|
||||
|
||||
1. **知识表示**
|
||||
|
||||
知识表示(Knowledge Representation,KR,也译为知识表现)是研究如何将结构化数据组织,以便于机器处理和人的理解的方法。
|
||||
|
||||
需要熟悉下面内容:
|
||||
* JSON和YAML
|
||||
* json库 [https://docs.python.org/2/library/json.html](https://docs.python.org/2/library/json.html)
|
||||
* PyYAML是Python里的Yaml处理库 [http://pyyaml.org/wiki/PyYAML](http://pyyaml.org/wiki/PyYAML)
|
||||
* RDF和OWL
|
||||
* RDF和OWL语义 [http://blog.memect.cn/?p=871](http://blog.memect.cn/?p=871)
|
||||
* JSON-LD
|
||||
* JSON-LD主页 [http://json-ld.org/](http://json-ld.org/)
|
||||
|
||||
1. **知识存储**
|
||||
|
||||
需要熟悉常见的图数据库
|
||||
* 知识链接的方式:字符串、外键、URI
|
||||
* PostgreSQL及其JSON扩展
|
||||
* Psycopg包操作PostgreSQL [http://initd.org/psycopg/docs/](http://initd.org/psycopg/docs/)
|
||||
* 图数据库 Neo4j和OrientDB
|
||||
* Neo4j的Python接口 [https://neo4j.com/developer/python/](https://neo4j.com/developer/python/)
|
||||
* OrientDB:[http://orientdb.com/orientdb/](http://orientdb.com/orientdb/)
|
||||
* RDF数据库Stardog
|
||||
* Stardog官网:[http://stardog.com/](http://stardog.com/)
|
||||
|
||||
1. **知识检索**
|
||||
|
||||
需要熟悉常见的检索技术
|
||||
* ElasticSearch
|
||||
|
||||
ES教程: [http://joelabrahamsson.com/elasticsearch-101/](http://joelabrahamsson.com/elasticsearch-101/)
|
||||
|
||||
1. 相关术语及技术路线
|
||||
* [本体](https://www.zhihu.com/question/19558514)
|
||||
* [RDF](https://www.w3.org/RDF/)
|
||||
* [Apache Jena](https://jena.apache.org/)
|
||||
* [D2RQ](http://d2rq.org/getting-started)
|
||||
* Protege构建本体系列
|
||||
* [protege](https://protege.stanford.edu/)
|
||||
* [protege使用](https://zhuanlan.zhihu.com/p/32389370)
|
||||
* 开发语言
|
||||
* python或java
|
||||
* 图数据库技术
|
||||
* [Neo4j](https://neo4j.com/)
|
||||
* [AllegroGraph](https://franz.com/agraph/allegrograph/)
|
||||
* 可视化技术
|
||||
* [d3.js](https://d3js.org/)
|
||||
* [Cytoscape.js](http://js.cytoscape.org/)
|
||||
* 分词技术
|
||||
* [jieba](https://github.com/fxsjy/jieba)
|
||||
* [hanlp](https://github.com/hankcs/HanLP)
|
||||
### 5.项目实战
|
||||
* [基于知识图谱的问答](https://github.com/kangzhun/KnowledgeGraph-QA-Service)
|
||||
* [Agriculture_KnowledgeGraph](https://github.com/qq547276542/Agriculture_KnowledgeGraph)
|
||||
# 贡献平台
|
||||
由知名开源平台,AI技术平台以及领域专家:ApacheCN,Datawhale,AI有道和黄海广博士联合整理贡献。
|
||||
参与名单:
|
||||
ApacheCN:片刻,李翔宇,飞龙,王翔
|
||||
Datawhale:范晶晶,马晶敏,李碧涵,李福,光城,居居,康兵兵,郑家豪
|
||||
AI有道:红色石头
|
||||
# 平台介绍
|
||||
* **Datawhale**:一个专注于AI领域的开源组织,上海交通大学国家级孵化项目,目前有7个独立团队,聚集了一群有开源精神和探索精神的团队成员,汇聚了来自各个高校和企业的优秀学习者,致力于构建纯粹的学习圈子和优质的开源项目,提供的组队学习涵盖了数据分析,数据挖掘,机器学习,深度学习,编程等16个内容领域。
|
||||
|
||||

|
||||
* **AI有道**:一个专注于 AI 领域的技术公众号。公众号主要涉及人工智能领域 Python、ML 、CV、NLP 等前沿知识、干货笔记和优质资源!我们致力于为广大人工智能爱好者提供优质的 AI 资源和切实可行的 AI 学习路线。
|
||||
|
||||

|
||||
* **黄博(机器学习初学者)**:机器学习课程在国内还不够普及,大部分初学者还是很迷茫,走了很多弯路,黄海广博士希望能尽自己的微薄之力,为机器学习初学者提供一个学习交流的平台。
|
||||
|
||||

|
||||
* **ApacheCN**:一个致力于提供优质开源项目的开源组织,致力于AI文档翻译,Kaggle比赛交流、LeetCode算法刷题、大数据交流等项目。我们希望做出广大 AI 爱好者真正需要的东西,打造真正有价值的长尾作品。官方网址:[http://www.apachecn.org/](http://www.apachecn.org/),点击阅读原文即可查看。
|
||||
|
||||
##
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,400 @@
|
|||
# Keras 快速入门
|
||||
|
||||
* 安装: `pip install keras`
|
||||
|
||||
> Keras 发展生态支持
|
||||
|
||||
* 1.Keras 的开发主要由谷歌支持,Keras API 以 tf.keras 的形式包装在 TensorFlow 中。
|
||||
* 2.微软维护着 Keras 的 CNTK 后端。
|
||||
* 3.亚马逊 AWS 正在开发 MXNet 支持。
|
||||
* 4.其他提供支持的公司包括 NVIDIA、优步、苹果(通过 CoreML)等。
|
||||
|
||||
## Keras dataset 生产数据
|
||||
|
||||
```py
|
||||
# With Numpy arrays
|
||||
data = np.random.random((1000, 32))
|
||||
labels = np.random.random((1000, 10))
|
||||
|
||||
model.evaluate(data, labels, batch_size=32)
|
||||
|
||||
# With a Dataset
|
||||
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
|
||||
dataset = dataset.batch(32)
|
||||
|
||||
model.evaluate(dataset)
|
||||
```
|
||||
|
||||
|
||||
## Keras Sequential 顺序模型
|
||||
|
||||
顺序模型是多个网络层的线性堆叠,目前支持2中方式
|
||||
|
||||
### 构造模型
|
||||
|
||||
> 1.构造器: 构建 Sequential 模型
|
||||
|
||||
```py
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Dense, Activation
|
||||
|
||||
model = Sequential([
|
||||
Dense(32, input_shape=(784,)),
|
||||
Activation('relu'),
|
||||
Dense(10),
|
||||
Activation('softmax'),
|
||||
])
|
||||
```
|
||||
|
||||
> 2.add(): 构建 Sequential 模型
|
||||
|
||||
```py
|
||||
from keras.models import Sequential
|
||||
from keras.layers import Dense, Activation
|
||||
|
||||
model = Sequential()
|
||||
model.add(Dense(32, input_dim=784))
|
||||
model.add(Activation('relu'))
|
||||
model.add(Dense(10)
|
||||
model.add(Activation('softmax'))
|
||||
```
|
||||
|
||||
### Dense: <https://keras.io/zh/layers/core>
|
||||
|
||||
Dense 指的是配置全连接层
|
||||
|
||||
```py
|
||||
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
|
||||
|
||||
# 参数
|
||||
* units: 正整数,输出空间维度。
|
||||
* activation: 激活函数 (详见 activations)。 若不指定,则不使用激活函数 (即,「线性」激活: a(x) = x)。
|
||||
* use_bias: 布尔值,该层是否使用偏置向量。
|
||||
* kernel_initializer: kernel 权值矩阵的初始化器 (详见 initializers)。
|
||||
* bias_initializer: 偏置向量的初始化器 (see initializers).
|
||||
* kernel_regularizer: 运用到 kernel 权值矩阵的正则化函数 (详见 regularizer)。
|
||||
* bias_regularizer: 运用到偏置向的的正则化函数 (详见 regularizer)。
|
||||
* activity_regularizer: 运用到层的输出的正则化函数 (它的 "activation")。 (详见 regularizer)。
|
||||
* kernel_constraint: 运用到 kernel 权值矩阵的约束函数 (详见 constraints)。
|
||||
* bias_constraint: 运用到偏置向量的约束函数 (详见 constraints)。
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```py
|
||||
# 作为 Sequential 模型的第一层
|
||||
model = Sequential()
|
||||
# 现在模型就会以尺寸为 (*, 16) 的数组作为输入,
|
||||
# 其输出数组的尺寸为 (*, 32)
|
||||
model.add(Dense(32, input_shape=(16,)))
|
||||
|
||||
# 在第一层之后,你就不再需要指定输入的尺寸了:
|
||||
model.add(Dense(32))
|
||||
```
|
||||
|
||||
### Activation 激活函数: <https://keras-cn.readthedocs.io/en/latest/other/activations>
|
||||
|
||||
> 激活函数: 将线性问题变成非线性(回归问题变为分类问题),简单计算难度和复杂性。
|
||||
|
||||
|
||||
|
||||
sigmoid
|
||||
|
||||
hard_sigmoid
|
||||
|
||||
tanh
|
||||
|
||||
relu
|
||||
|
||||
softmax: 对输入数据的最后一维进行softmax,输入数据应形如(nb_samples, nb_timesteps, nb_dims)或(nb_samples,nb_dims)
|
||||
|
||||
elu
|
||||
|
||||
selu: 可伸缩的指数线性单元(Scaled Exponential Linear Unit),参考Self-Normalizing Neural Networks
|
||||
|
||||
softplus
|
||||
|
||||
softsign
|
||||
|
||||
linear
|
||||
|
||||
|
||||
|
||||
## Keras compile 过程
|
||||
|
||||
```py
|
||||
model.compile(optimizer='rmsprop',
|
||||
loss='categorical_crossentropy',
|
||||
metrics=['accuracy'])
|
||||
|
||||
model.fit(x_train, y_train, epochs=5)
|
||||
model.evaluate(x_test, y_test, verbose=2)
|
||||
```
|
||||
|
||||
### 优化器 optimizer: <https://keras.io/optimizers>
|
||||
|
||||
|
||||
> SGD
|
||||
|
||||
|
||||
```py
|
||||
keras.optimizers.SGD(learning_rate=0.01, momentum=0.0, nesterov=False)
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```py
|
||||
from keras import optimizers
|
||||
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
|
||||
model.compile(loss='mean_squared_error', optimizer=sgd)
|
||||
```
|
||||
|
||||
|
||||
> RMSprop
|
||||
|
||||
```py
|
||||
keras.optimizers.RMSprop(learning_rate=0.001, rho=0.9)
|
||||
```
|
||||
|
||||
> Adagrad
|
||||
|
||||
```py
|
||||
keras.optimizers.Adagrad(learning_rate=0.01)
|
||||
```
|
||||
|
||||
|
||||
> Adadelta
|
||||
|
||||
```py
|
||||
keras.optimizers.Adadelta(learning_rate=1.0, rho=0.95)
|
||||
```
|
||||
|
||||
> Adam
|
||||
|
||||
```py
|
||||
keras.optimizers.Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999, amsgrad=False)
|
||||
```
|
||||
|
||||
|
||||
> Adamax
|
||||
|
||||
```py
|
||||
keras.optimizers.Adamax(learning_rate=0.002, beta_1=0.9, beta_2=0.999)
|
||||
```
|
||||
|
||||
|
||||
> Nadam
|
||||
|
||||
```py
|
||||
keras.optimizers.Nadam(learning_rate=0.002, beta_1=0.9, beta_2=0.999)
|
||||
```
|
||||
|
||||
|
||||
### 损失函数 loss: <https://keras.io/losses>
|
||||
|
||||
|
||||
#### 回归
|
||||
|
||||
> mean_squared_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_squared_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
#### 二分类
|
||||
|
||||
> binary_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.binary_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)
|
||||
```
|
||||
|
||||
|
||||
#### 多分类
|
||||
|
||||
> categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.categorical_crossentropy(y_true, y_pred, from_logits=False, label_smoothing=0)
|
||||
```
|
||||
|
||||
### 评价函数 metrics: <https://keras.io/zh/metrics>
|
||||
|
||||
评价函数: 用来衡量`真实值`和`预测值`的差异
|
||||
|
||||
> binary_accuracy
|
||||
|
||||
对二分类问题,计算在所有预测值上的平均正确率
|
||||
|
||||
```py
|
||||
binary_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> categorical_accuracy
|
||||
|
||||
对多分类问题,计算再所有预测值上的平均正确率
|
||||
|
||||
```py
|
||||
categorical_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> sparse_categorical_accuracy
|
||||
|
||||
与categorical_accuracy相同,在对稀疏的目标值预测时有用
|
||||
|
||||
```py
|
||||
sparse_categorical_accuracy(y_true, y_pred)
|
||||
```
|
||||
|
||||
> top_k_categorical_accuracy
|
||||
|
||||
计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
|
||||
|
||||
```py
|
||||
top_k_categorical_accuracy(y_true, y_pred, k=5)
|
||||
```
|
||||
|
||||
> sparse_top_k_categorical_accuracy
|
||||
|
||||
与top_k_categorical_accracy作用相同,但适用于稀疏情况
|
||||
|
||||
```py
|
||||
sparse_top_k_categorical_accuracy(y_true, y_pred, k=5)
|
||||
```
|
||||
|
||||
|
||||
## Keras load/save 模型持久化
|
||||
|
||||
> 保存模型
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Save entire model to a HDF5 file
|
||||
model.save('my_model.h5')
|
||||
|
||||
# Recreate the exact same model, including weights and optimizer.
|
||||
model = tf.keras.models.load_model('my_model.h5')
|
||||
```
|
||||
|
||||
> 仅保存权重值
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Save weights to a TensorFlow Checkpoint file
|
||||
model.save_weights('./weights/my_model')
|
||||
# Restore the model's state,
|
||||
# this requires a model with the same architecture.
|
||||
model.load_weights('./weights/my_model')
|
||||
|
||||
|
||||
# Save weights to a HDF5 file
|
||||
model.save_weights('my_model.h5', save_format='h5')
|
||||
# Restore the model's state
|
||||
model.load_weights('my_model.h5')
|
||||
```
|
||||
|
||||
> 仅保存模型配置
|
||||
|
||||
```py
|
||||
import tensorflow as tf
|
||||
|
||||
# Serialize a model to json format
|
||||
json_string = model.to_json()
|
||||
fresh_model = tf.keras.models.model_from_json(json_string)
|
||||
|
||||
# Serialize a model to yaml format
|
||||
yaml_string = model.to_yaml()
|
||||
fresh_model = tf.keras.models.model_from_yaml(yaml_string)
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
补充损失函数
|
||||
|
||||
> mean_absolute_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_absolute_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> mean_absolute_percentage_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_absolute_percentage_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> mean_squared_logarithmic_error
|
||||
|
||||
```py
|
||||
keras.losses.mean_squared_logarithmic_error(y_true, y_pred)
|
||||
```
|
||||
|
||||
> squared_hinge
|
||||
|
||||
```
|
||||
keras.losses.squared_hinge(y_true, y_pred)
|
||||
|
||||
```
|
||||
|
||||
> hinge
|
||||
|
||||
```py
|
||||
keras.losses.hinge(y_true, y_pred)
|
||||
```
|
||||
|
||||
> categorical_hinge
|
||||
|
||||
```py
|
||||
keras.losses.categorical_hinge(y_true, y_pred)
|
||||
```
|
||||
|
||||
> logcosh
|
||||
|
||||
```py
|
||||
keras.losses.logcosh(y_true, y_pred)
|
||||
```
|
||||
|
||||
|
||||
> huber_loss
|
||||
|
||||
```py
|
||||
keras.losses.huber_loss(y_true, y_pred, delta=1.0)
|
||||
```
|
||||
|
||||
|
||||
> sparse_categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.sparse_categorical_crossentropy(y_true, y_pred, from_logits=False, axis=-1)
|
||||
```
|
||||
|
||||
|
||||
> kullback_leibler_divergence
|
||||
|
||||
```py
|
||||
keras.losses.kullback_leibler_divergence(y_true, y_pred)
|
||||
```
|
||||
|
||||
> poisson
|
||||
|
||||
```py
|
||||
keras.losses.poisson(y_true, y_pred)
|
||||
```
|
||||
|
||||
> cosine_proximity
|
||||
|
||||
```py
|
||||
keras.losses.cosine_proximity(y_true, y_pred, axis=-1)
|
||||
```
|
||||
|
||||
> is_categorical_crossentropy
|
||||
|
||||
```py
|
||||
keras.losses.is_categorical_crossentropy(loss)
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,185 @@
|
|||
# Ubuntu16.04安装TensorFlow2.x CPU和GPU必备指南
|
||||
|
||||
* CPU安装: `pip install tensorflow`
|
||||
* GPU安装: `pip install tensorflow-gpu` 【**`别慌,GPU需要先安装以下内容`**】
|
||||
* 注意: 不要同时安装
|
||||
|
||||
> 硬件要求
|
||||
|
||||
支持以下启用GPU的设备:
|
||||
|
||||
* 具有CUDA®Compute Capability 3.5或更高版本的NVIDIA®GPU卡。请参阅[支持CUDA的GPU卡](https://developer.nvidia.com/cuda-gpus)列表 。
|
||||
|
||||
> 软件需求
|
||||
|
||||
您的系统上必须安装以下NVIDIA®软件:
|
||||
|
||||
* NVIDIA®GPU [驱动程序](https://www.nvidia.com/drivers) CUDA 10.0需要410.x或更高版本。
|
||||
* [CUDA®工具包](https://developer.nvidia.com/cuda-toolkit-archive) - TensorFlow支持CUDA 10.0(TensorFlow> = 1.13.0)
|
||||
* [CUPTI](http://docs.nvidia.com/cuda/cupti/)随附CUDA工具包。
|
||||
* [cuDNN SDK](https://developer.nvidia.com/cudnn)(> = 7.4.1)
|
||||
* *(可选)* [TensorRT 5.0](https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html) 可以改善延迟和吞吐量,以在某些模型上进行推断。
|
||||
|
||||
|
||||
## 1.安装 NVIDIA 驱动
|
||||
|
||||
```shell
|
||||
$ wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1604/x86_64/nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
|
||||
$ sudo apt install ./nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
|
||||
$ sudo apt-get update
|
||||
|
||||
$ ubuntu-drivers devices # 查看推荐的版本安装
|
||||
== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
|
||||
modalias : pci:v000010DEd000017C8sv00001458sd000036B6bc03sc00i00
|
||||
vendor : NVIDIA Corporation
|
||||
model : GM200 [GeForce GTX 980 Ti]
|
||||
driver : nvidia-387 - third-party non-free
|
||||
driver : nvidia-410 - third-party non-free
|
||||
driver : nvidia-384 - third-party non-free
|
||||
driver : nvidia-430 - third-party free recommended # 推荐安装
|
||||
driver : xserver-xorg-video-nouveau - distro free builtin
|
||||
driver : nvidia-396 - third-party non-free
|
||||
driver : nvidia-390 - third-party non-free
|
||||
driver : nvidia-418 - third-party non-free
|
||||
driver : nvidia-415 - third-party free
|
||||
|
||||
# –no-install-recommends参数来避免安装非必须的文件,从而减小镜像的体积
|
||||
$ sudo apt-get install --no-install-recommends nvidia-430 -y
|
||||
正在读取软件包列表... 完成
|
||||
正在分析软件包的依赖关系树
|
||||
正在读取状态信息... 完成
|
||||
将会同时安装下列软件:
|
||||
lib32gcc1 libc-dev-bin libc6 libc6-dbg libc6-dev libc6-i386
|
||||
建议安装:
|
||||
glibc-doc
|
||||
推荐安装:
|
||||
libcuda1-430 nvidia-opencl-icd-430
|
||||
下列【新】软件包将被安装:
|
||||
lib32gcc1 libc6-i386 nvidia-430
|
||||
下列软件包将被升级:
|
||||
libc-dev-bin libc6 libc6-dbg libc6-dev
|
||||
升级了 4 个软件包,新安装了 3 个软件包,要卸载 0 个软件包,有 260 个软件包未被升级。
|
||||
需要下载 99.7 MB/111 MB 的归档。
|
||||
解压缩后会消耗 429 MB 的额外空间。
|
||||
您希望继续执行吗? [Y/n] Y
|
||||
获取:1 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu xenial/main amd64 nvidia-430 amd64 430.26-0ubuntu0~gpu16.04.1 [99.7 MB]
|
||||
25% [1 nvidia-430 492 kB/99.7 MB 0%] 563 B/s 2天 0小时 58分 14秒58秒
|
||||
...
|
||||
92% [1 nvidia-430 93.0 MB/99.7 MB 93%] 4,111 B/s 27分 28秒
|
||||
已下载 7,180 kB,耗时 4分 26秒 (26.9 kB/s)
|
||||
|
||||
Running module version sanity check.
|
||||
- Original module
|
||||
- No original module exists within this kernel
|
||||
- Installation
|
||||
- Installing to /lib/modules/4.10.0-28-generic/updates/dkms/
|
||||
|
||||
depmod....
|
||||
|
||||
DKMS: install completed.
|
||||
正在处理用于 libc-bin (2.23-0ubuntu10) 的触发器 ...
|
||||
正在处理用于 initramfs-tools (0.122ubuntu8.14) 的触发器 ...
|
||||
update-initramfs: Generating /boot/initrd.img-4.10.0-28-generic
|
||||
|
||||
# $ sudo reboot # 安装完需要重启电脑
|
||||
$ sudo nvidia-smi
|
||||
```
|
||||
|
||||
这里面大家需要注意的是: 采用在终端输入 `ubuntu-drivers devices` 会提示推荐你用什么版本,我的设备显示不出来,所以安装的是418.43这个型号的驱动。(目前最新版本)
|
||||
|
||||
注意事项一:官网下载地址
|
||||
推荐网址:(https://www.geforce.cn/drivers)只有这个GeForce型号的,别的型号推荐去其对应的网址查询。
|
||||
|
||||
注意事项二:不要在下面这个网址下载,不是不能,最直接的官网,对应的东西最新,也最详细
|
||||
网址如下(https://www.nvidia.com/Download/index.aspx?lang=cn)
|
||||
|
||||
理由:
|
||||
* (1)上面的网址,选择驱动型号,点进去可以看到许多详细的信息,尤其是它支持什么样的显卡,都有,特别详细。
|
||||
* (2)这个网址在我写博客(2019.3.6)为止,还没有GTX1660Ti的Ubuntu驱动
|
||||
|
||||
注意事项三:具体操作见网上别人写好的。
|
||||
|
||||
## 2.安装 CUDA 1.0 + cuDNN 7
|
||||
|
||||
> CUDA
|
||||
|
||||
下面这个网址是tensorflow各环境参数对应版本图(https://tensorflow.google.cn/install/source)可供参考。cuda和cudnn对应关系应该没问题,但是tensorflow版本不能过高,否则会出错。
|
||||
|
||||
注意事项一:下载地址
|
||||
cuda下载网址为:(https://developer.nvidia.com/),右上角搜索“CUDA Toolkit Archive”,点击第一个(最新的)的进去,里面有许多版本可供选择,切记!切记!切记!目前网友的说法是:tensorflow只能支持cuda9.0及以下版本。
|
||||
|
||||
注意事项二:选择run下载,而不选择del
|
||||
这个具体是什么原因,没搞明白,网友也强烈推荐run,我之前试过del的,失败了,所以大家尽量采用run这种方法。可能有人没明白说明意思,你在选择的时候多留个心眼就注意到了。
|
||||
|
||||
> cuDNN
|
||||
|
||||
官网网址如下
|
||||
网址:<https://developer.nvidia.com/cudnn>
|
||||
需要注册,我是从别人那直接过来的,就没注册,大家需要的自己去,这个安装相对简单。
|
||||
|
||||
同样有验证的过程,这个相对来说是简单的,没什么需要太注意的,跟着网上的走就好了。
|
||||
|
||||
|
||||
> 执行命令
|
||||
|
||||
```shell
|
||||
$ sudo apt-get install gnupg-curl
|
||||
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
|
||||
$ sudo dpkg -i cuda-repo-ubuntu1604_10.0.130-1_amd64.deb
|
||||
$ sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
|
||||
$ sudo apt-get update -y
|
||||
|
||||
# sudo apt-get install cuda
|
||||
$ sudo apt-get install --no-install-recommends \
|
||||
cuda-10-0 \
|
||||
libcudnn7=7.6.2.24-1+cuda10.0 \
|
||||
libcudnn7-dev=7.6.2.24-1+cuda10.0
|
||||
|
||||
$ sudo apt-get install -y --no-install-recommends libnvinfer5=5.1.5-1+cuda10.0 libnvinfer-dev=5.1.5-1+cuda10.0
|
||||
```
|
||||
|
||||
## 3.安装TensorFlow并验证
|
||||
|
||||
* GPU安装: `sudo pip3 install tensorflow-gpu`
|
||||
|
||||
```shell
|
||||
from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
|
||||
import tensorflow as tf
|
||||
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
>>> from __future__ import absolute_import, division, print_function, unicode_literals
|
||||
>>>
|
||||
>>> import tensorflow as tf
|
||||
|
||||
>>> print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
|
||||
2019-10-10 16:12:15.524570: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1
|
||||
2019-10-10 16:12:15.537451: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.538341: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties:
|
||||
name: GeForce GTX 980 Ti major: 5 minor: 2 memoryClockRate(GHz): 1.2405
|
||||
pciBusID: 0000:01:00.0
|
||||
2019-10-10 16:12:15.538489: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.0
|
||||
2019-10-10 16:12:15.539261: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10.0
|
||||
2019-10-10 16:12:15.539899: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10.0
|
||||
2019-10-10 16:12:15.540081: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10.0
|
||||
2019-10-10 16:12:15.540886: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10.0
|
||||
2019-10-10 16:12:15.541540: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10.0
|
||||
2019-10-10 16:12:15.543506: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
|
||||
2019-10-10 16:12:15.543601: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.544469: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:1006] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
|
||||
2019-10-10 16:12:15.545326: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0
|
||||
Num GPUs Available: 1
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
信息来源:
|
||||
|
||||
* <https://tensorflow.google.cn/install/gpu>
|
||||
* <https://tensorflow.google.cn/guide/gpu>
|
||||
* <https://blog.csdn.net/qq_44774398/article/details/99832436>
|
||||
* <https://blog.csdn.net/weixin_43012220/article/details/88241766>
|
||||
|
|
@ -0,0 +1,673 @@
|
|||
# CNN原理
|
||||
|
||||
> 建议:看懂原理就行
|
||||
|
||||
# [【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理](https://www.cnblogs.com/charlotte77/p/7759802.html)
|
||||
|
||||
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度。有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可以识别手写数字,我们要采用卷积神经网络CNN来进行别呢?CNN到底是怎么识别的?用CNN有哪些优势呢?我们下面就来简单分析一下。在讲CNN之前,为避免完全零基础的人看不懂后面的讲解,我们先简单回顾一下传统的神经网络的基本知识。
|
||||
|
||||
* * *
|
||||
|
||||
**神经网络的预备知识**
|
||||
|
||||
** 为什么要用神经网络?**
|
||||
|
||||
* 特征提取的高效性。
|
||||
|
||||
大家可能会疑惑,对于同一个分类任务,我们可以用机器学习的算法来做,为什么要用神经网络呢?大家回顾一下,一个分类任务,我们在用机器学习算法来做时,首先要明确feature和label,然后把这个数据"灌"到算法里去训练,最后保存模型,再来预测分类的准确性。但是这就有个问题,即我们需要实现确定好特征,每一个特征即为一个维度,特征数目过少,我们可能无法精确的分类出来,即我们所说的欠拟合,如果特征数目过多,可能会导致我们在分类过程中过于注重某个特征导致分类错误,即过拟合。
|
||||
|
||||
举个简单的例子,现在有一堆数据集,让我们分类出西瓜和冬瓜,如果只有两个特征:形状和颜色,可能没法分区来;如果特征的维度有:形状、颜色、瓜瓤颜色、瓜皮的花纹等等,可能很容易分类出来;如果我们的特征是:形状、颜色、瓜瓤颜色、瓜皮花纹、瓜蒂、瓜籽的数量,瓜籽的颜色、瓜籽的大小、瓜籽的分布情况、瓜籽的XXX等等,很有可能会过拟合,譬如有的冬瓜的瓜籽数量和西瓜的类似,模型训练后这类特征的权重较高,就很容易分错。这就导致我们在特征工程上需要花很多时间和精力,才能使模型训练得到一个好的效果。然而神经网络的出现使我们不需要做大量的特征工程,譬如提前设计好特征的内容或者说特征的数量等等,我们可以直接把数据灌进去,让它自己训练,自我“修正”,即可得到一个较好的效果。
|
||||
|
||||
* 数据格式的简易性
|
||||
|
||||
在一个传统的机器学习分类问题中,我们“灌”进去的数据是不能直接灌进去的,需要对数据进行一些处理,譬如量纲的归一化,格式的转化等等,不过在神经网络里我们不需要额外的对数据做过多的处理,具体原因可以看后面的详细推导。
|
||||
|
||||
* 参数数目的少量性
|
||||
|
||||
在面对一个分类问题时,如果用SVM来做,我们需要调整的参数需要调整核函数,惩罚因子,松弛变量等等,不同的参数组合对于模型的效果也不一样,想要迅速而又准确的调到最适合模型的参数需要对背后理论知识的深入了解(当然,如果你说全部都试一遍也是可以的,但是花的时间可能会更多),对于一个基本的三层神经网络来说(输入-隐含-输出),我们只需要初始化时给每一个神经元上随机的赋予一个权重w和偏置项b,在训练过程中,这两个参数会不断的修正,调整到最优质,使模型的误差最小。所以从这个角度来看,我们对于调参的背后理论知识并不需要过于精通(只不过做多了之后可能会有一些经验,在初始值时赋予的值更科学,收敛的更快罢了)
|
||||
|
||||
** 有哪些应用?**
|
||||
|
||||
应用非常广,不过大家注意一点,我们现在所说的神经网络,并不能称之为深度学习,神经网络很早就出现了,只不过现在因为不断的加深了网络层,复杂化了网络结构,才成为深度学习,并在图像识别、图像检测、语音识别等等方面取得了不错的效果。
|
||||
|
||||
**基本网络结构**
|
||||
|
||||
一个神经网络最简单的结构包括输入层、隐含层和输出层,每一层网络有多个神经元,上一层的神经元通过激活函数映射到下一层神经元,每个神经元之间有相对应的权值,输出即为我们的分类类别。
|
||||
|
||||
** 详细数学推导**
|
||||
|
||||
去年中旬我参考吴恩达的UFLDL和mattmazur的博客写了篇文章详细讲解了一个最简单的神经网络从前向传播到反向传播的直观推导,大家可以先看看这篇文章--[一文弄懂神经网络中的反向传播法--BackPropagation](http://www.cnblogs.com/charlotte77/p/5629865.html)。
|
||||
|
||||
** 优缺点**
|
||||
|
||||
前面说了很多优点,这里就不多说了,简单说说缺点吧。我们试想一下如果加深我们的网络层,每一个网络层增加神经元的数量,那么参数的个数将是M*N(m为网络层数,N为每层神经元个数),所需的参数会非常多,参数一多,模型就复杂了,越是复杂的模型就越不好调参,也越容易过拟合。此外我们从神经网络的反向传播的过程来看,梯度在反向传播时,不断的迭代会导致梯度越来越小,即梯度消失的情况,梯度一旦趋于0,那么权值就无法更新,这个神经元相当于是不起作用了,也就很难导致收敛。尤其是在图像领域,用最基本的神经网络,是不太合适的。后面我们会详细讲讲为啥不合适。
|
||||
|
||||
* * *
|
||||
|
||||
**为什么要用卷积神经网络?**
|
||||
|
||||
** 传统神经网络的劣势**
|
||||
|
||||
前面说到在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有 `28 * 28 =784` 个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有: `784*15*10+15+10=117625` 个,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。(评论中有同学对这个参数计算不太理解,我简单说一下:图片是由像素点组成的,用矩阵表示的, `28*28` 的矩阵,肯定是没法直接放到神经元里的,我们得把它“拍平”,变成一个`28*28=784` 的一列向量,这一列向量和隐含层的15个神经元连接,就有 `784*15=11760` 个权重w,隐含层和最后的输出层的10个神经元连接,就有 `11760*10=117600` 个权重w,再加上隐含层的偏置项15个和输出层的偏置项10个,就是:117625个参数了)
|
||||
|
||||
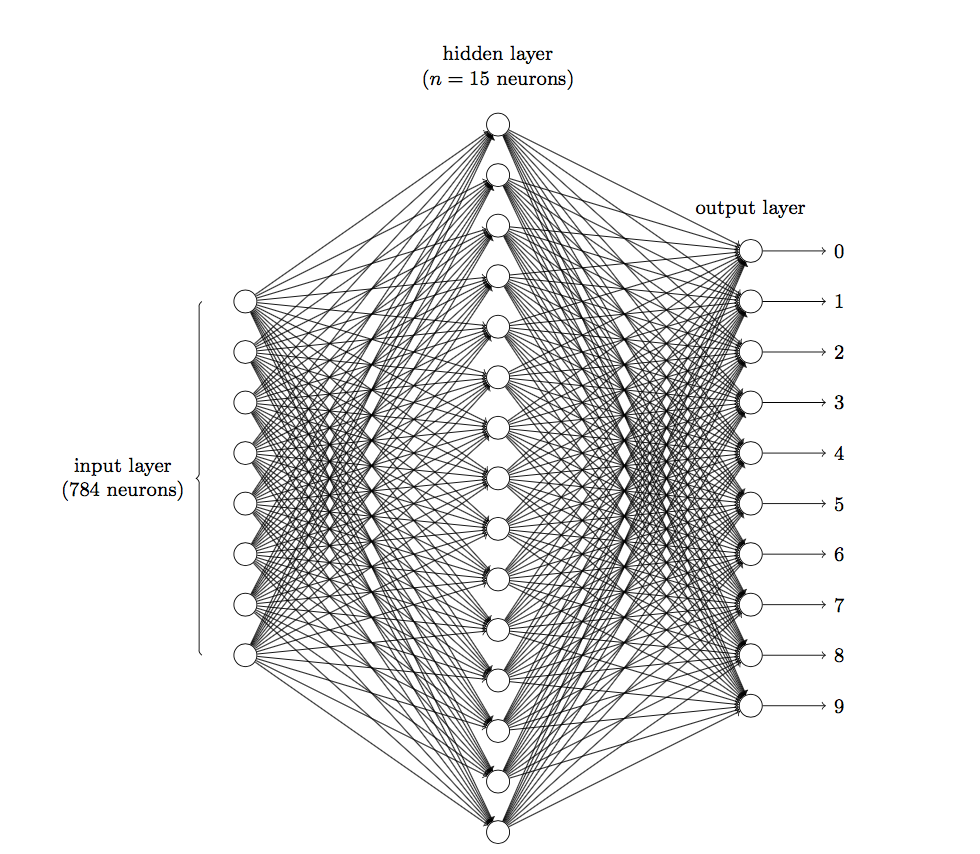
|
||||
|
||||
图1 三层神经网络识别手写数字
|
||||
|
||||
** 卷积神经网络是什么?**
|
||||
|
||||
** 三个基本层**
|
||||
|
||||
* **卷积层(Convolutional Layer)**
|
||||
|
||||
上文提到我们用传统的三层神经网络需要大量的参数,原因在于每个神经元都和相邻层的神经元相连接,但是思考一下,这种连接方式是必须的吗?全连接层的方式对于图像数据来说似乎显得不这么友好,因为图像本身具有“二维空间特征”,通俗点说就是局部特性。譬如我们看一张猫的图片,可能看到猫的眼镜或者嘴巴就知道这是张猫片,而不需要说每个部分都看完了才知道,啊,原来这个是猫啊。所以如果我们可以用某种方式对一张图片的某个典型特征识别,那么这张图片的类别也就知道了。这个时候就产生了卷积的概念。举个例子,现在有一个4*4的图像,我们设计两个卷积核,看看运用卷积核后图片会变成什么样。
|
||||
|
||||
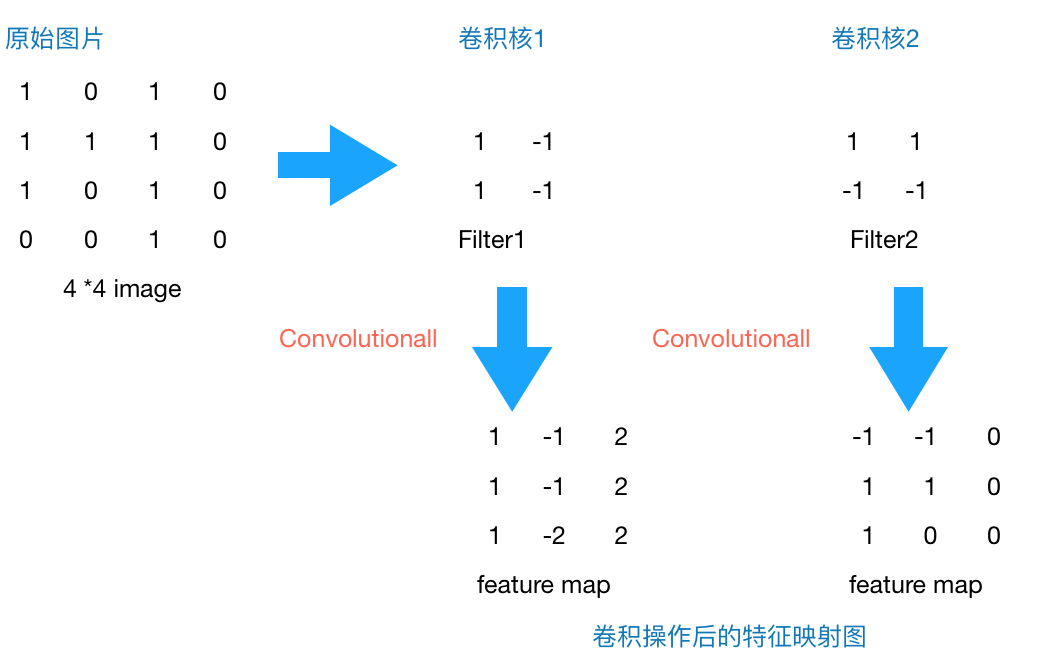
|
||||
|
||||
图2 4*4 image与两个2*2的卷积核操作结果
|
||||
|
||||
由上图可以看到,原始图片是一张灰度图片,每个位置表示的是像素值,0表示白色,1表示黑色,(0,1)区间的数值表示灰色。对于这个4*4的图像,我们采用两个2*2的卷积核来计算。设定步长为1,即每次以2*2的固定窗口往右滑动一个单位。以第一个卷积核filter1为例,计算过程如下:
|
||||
|
||||
```python
|
||||
feature_map1(1,1) = 1*1 + 0*(-1) + 1*1 + 1*(-1) = 1
|
||||
feature_map1(1,2) = 0*1 + 1*(-1) + 1*1 + 1*(-1) = -1
|
||||
...
|
||||
feature_map1(3,3) = 1*1 + 0*(-1) + 1*1 + 0*(-1) = 2
|
||||
```
|
||||
|
||||
可以看到这就是最简单的内积公式。feature_map1(1,1)表示在通过第一个卷积核计算完后得到的feature_map的第一行第一列的值,随着卷积核的窗口不断的滑动,我们可以计算出一个3\*3的feature_map1;同理可以计算通过第二个卷积核进行卷积运算后的feature_map2,那么这一层卷积操作就完成了。feature_map尺寸计算公式:[ (原图片尺寸 -卷积核尺寸)/ 步长 ] + 1。这一层我们设定了两个2\*2的卷积核,在paddlepaddle里是这样定义的:
|
||||
|
||||
|
||||
```python
|
||||
conv_pool_1 = paddle.networks.simple_img_conv_pool(
|
||||
input=img,
|
||||
filter_size=3,
|
||||
num_filters=2,
|
||||
num_channel=1,
|
||||
pool_stride=1,
|
||||
act=paddle.activation.Relu())
|
||||
```
|
||||
|
||||
|
||||
这里调用了networks里simple_img_conv_pool函数,激活函数是Relu(修正线性单元),我们来看一看源码里外层接口是如何定义的:
|
||||
|
||||
|
||||
```python
|
||||
def simple_img_conv_pool(input,
|
||||
filter_size,
|
||||
num_filters,
|
||||
pool_size,
|
||||
name=None,
|
||||
pool_type=None,
|
||||
act=None,
|
||||
groups=1,
|
||||
conv_stride=1,
|
||||
conv_padding=0,
|
||||
bias_attr=None,
|
||||
num_channel=None,
|
||||
param_attr=None,
|
||||
shared_bias=True,
|
||||
conv_layer_attr=None,
|
||||
pool_stride=1,
|
||||
pool_padding=0,
|
||||
pool_layer_attr=None):
|
||||
"""
|
||||
Simple image convolution and pooling group.
|
||||
Img input => Conv => Pooling => Output.
|
||||
:param name: group name.
|
||||
:type name: basestring
|
||||
:param input: input layer.
|
||||
:type input: LayerOutput
|
||||
:param filter_size: see img_conv_layer for details.
|
||||
:type filter_size: int
|
||||
:param num_filters: see img_conv_layer for details.
|
||||
:type num_filters: int
|
||||
:param pool_size: see img_pool_layer for details.
|
||||
:type pool_size: int
|
||||
:param pool_type: see img_pool_layer for details.
|
||||
:type pool_type: BasePoolingType
|
||||
:param act: see img_conv_layer for details.
|
||||
:type act: BaseActivation
|
||||
:param groups: see img_conv_layer for details.
|
||||
:type groups: int
|
||||
:param conv_stride: see img_conv_layer for details.
|
||||
:type conv_stride: int
|
||||
:param conv_padding: see img_conv_layer for details.
|
||||
:type conv_padding: int
|
||||
:param bias_attr: see img_conv_layer for details.
|
||||
:type bias_attr: ParameterAttribute
|
||||
:param num_channel: see img_conv_layer for details.
|
||||
:type num_channel: int
|
||||
:param param_attr: see img_conv_layer for details.
|
||||
:type param_attr: ParameterAttribute
|
||||
:param shared_bias: see img_conv_layer for details.
|
||||
:type shared_bias: bool
|
||||
:param conv_layer_attr: see img_conv_layer for details.
|
||||
:type conv_layer_attr: ExtraLayerAttribute
|
||||
:param pool_stride: see img_pool_layer for details.
|
||||
:type pool_stride: int
|
||||
:param pool_padding: see img_pool_layer for details.
|
||||
:type pool_padding: int
|
||||
:param pool_layer_attr: see img_pool_layer for details.
|
||||
:type pool_layer_attr: ExtraLayerAttribute
|
||||
:return: layer's output
|
||||
:rtype: LayerOutput
|
||||
"""
|
||||
_conv_ = img_conv_layer(
|
||||
name="%s_conv" % name,
|
||||
input=input,
|
||||
filter_size=filter_size,
|
||||
num_filters=num_filters,
|
||||
num_channels=num_channel,
|
||||
act=act,
|
||||
groups=groups,
|
||||
stride=conv_stride,
|
||||
padding=conv_padding,
|
||||
bias_attr=bias_attr,
|
||||
param_attr=param_attr,
|
||||
shared_biases=shared_bias,
|
||||
layer_attr=conv_layer_attr)
|
||||
return img_pool_layer(
|
||||
name="%s_pool" % name,
|
||||
input=_conv_,
|
||||
pool_size=pool_size,
|
||||
pool_type=pool_type,
|
||||
stride=pool_stride,
|
||||
padding=pool_padding,
|
||||
layer_attr=pool_layer_attr)
|
||||
```
|
||||
|
||||
我们在 [Paddle/python/paddle/v2/framework/nets.py](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/framework/nets.py) 里可以看到simple_img_conv_pool这个函数的定义:
|
||||
|
||||
```python
|
||||
def simple_img_conv_pool(input,
|
||||
num_filters,
|
||||
filter_size,
|
||||
pool_size,
|
||||
pool_stride,
|
||||
act,
|
||||
pool_type='max',
|
||||
main_program=None,
|
||||
startup_program=None):
|
||||
conv_out = layers.conv2d(
|
||||
input=input,
|
||||
num_filters=num_filters,
|
||||
filter_size=filter_size,
|
||||
act=act,
|
||||
main_program=main_program,
|
||||
startup_program=startup_program)
|
||||
|
||||
pool_out = layers.pool2d(
|
||||
input=conv_out,
|
||||
pool_size=pool_size,
|
||||
pool_type=pool_type,
|
||||
pool_stride=pool_stride,
|
||||
main_program=main_program,
|
||||
startup_program=startup_program)
|
||||
return pool_out
|
||||
```
|
||||
|
||||
可以看到这里面有两个输出,conv_out是卷积输出值,pool_out是池化输出值,最后只返回池化输出的值。conv_out和pool_out分别又调用了layers.py的conv2d和pool2d,去layers.py里我们可以看到conv2d和pool2d是如何实现的:
|
||||
|
||||
conv2d:
|
||||
|
||||
```python
|
||||
def conv2d(input,
|
||||
num_filters,
|
||||
name=None,
|
||||
filter_size=[1, 1],
|
||||
act=None,
|
||||
groups=None,
|
||||
stride=[1, 1],
|
||||
padding=None,
|
||||
bias_attr=None,
|
||||
param_attr=None,
|
||||
main_program=None,
|
||||
startup_program=None):
|
||||
helper = LayerHelper('conv2d', **locals())
|
||||
dtype = helper.input_dtype()
|
||||
|
||||
num_channels = input.shape[1]
|
||||
if groups is None:
|
||||
num_filter_channels = num_channels
|
||||
else:
|
||||
if num_channels % groups is not 0:
|
||||
raise ValueError("num_channels must be divisible by groups.")
|
||||
num_filter_channels = num_channels / groups
|
||||
|
||||
if isinstance(filter_size, int):
|
||||
filter_size = [filter_size, filter_size]
|
||||
if isinstance(stride, int):
|
||||
stride = [stride, stride]
|
||||
if isinstance(padding, int):
|
||||
padding = [padding, padding]
|
||||
|
||||
input_shape = input.shape
|
||||
filter_shape = [num_filters, num_filter_channels] + filter_size
|
||||
|
||||
std = (2.0 / (filter_size[0]**2 * num_channels))**0.5
|
||||
filter = helper.create_parameter(
|
||||
attr=helper.param_attr,
|
||||
shape=filter_shape,
|
||||
dtype=dtype,
|
||||
initializer=NormalInitializer(0.0, std, 0))
|
||||
pre_bias = helper.create_tmp_variable(dtype)
|
||||
|
||||
helper.append_op(
|
||||
type='conv2d',
|
||||
inputs={
|
||||
'Input': input,
|
||||
'Filter': filter,
|
||||
},
|
||||
outputs={"Output": pre_bias},
|
||||
attrs={'strides': stride,
|
||||
'paddings': padding,
|
||||
'groups': groups})
|
||||
|
||||
pre_act = helper.append_bias_op(pre_bias, 1)
|
||||
|
||||
return helper.append_activation(pre_act)
|
||||
```
|
||||
|
||||
pool2d:
|
||||
|
||||
```python
|
||||
def pool2d(input,
|
||||
pool_size,
|
||||
pool_type,
|
||||
pool_stride=[1, 1],
|
||||
pool_padding=[0, 0],
|
||||
global_pooling=False,
|
||||
main_program=None,
|
||||
startup_program=None):
|
||||
if pool_type not in ["max", "avg"]:
|
||||
raise ValueError(
|
||||
"Unknown pool_type: '%s'. It can only be 'max' or 'avg'.",
|
||||
str(pool_type))
|
||||
if isinstance(pool_size, int):
|
||||
pool_size = [pool_size, pool_size]
|
||||
if isinstance(pool_stride, int):
|
||||
pool_stride = [pool_stride, pool_stride]
|
||||
if isinstance(pool_padding, int):
|
||||
pool_padding = [pool_padding, pool_padding]
|
||||
|
||||
helper = LayerHelper('pool2d', **locals())
|
||||
dtype = helper.input_dtype()
|
||||
pool_out = helper.create_tmp_variable(dtype)
|
||||
|
||||
helper.append_op(
|
||||
type="pool2d",
|
||||
inputs={"X": input},
|
||||
outputs={"Out": pool_out},
|
||||
attrs={
|
||||
"poolingType": pool_type,
|
||||
"ksize": pool_size,
|
||||
"globalPooling": global_pooling,
|
||||
"strides": pool_stride,
|
||||
"paddings": pool_padding
|
||||
})
|
||||
|
||||
return pool_out
|
||||
```
|
||||
|
||||
大家可以看到,具体的实现方式还调用了[layers_helper.py](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/framework/layer_helper.py):
|
||||
|
||||
```python
|
||||
import copy
|
||||
import itertools
|
||||
|
||||
from paddle.v2.framework.framework import Variable, g_main_program, \
|
||||
g_startup_program, unique_name, Program
|
||||
from paddle.v2.framework.initializer import ConstantInitializer, \
|
||||
UniformInitializer
|
||||
|
||||
|
||||
class LayerHelper(object):
|
||||
def __init__(self, layer_type, **kwargs):
|
||||
self.kwargs = kwargs
|
||||
self.layer_type = layer_type
|
||||
name = self.kwargs.get('name', None)
|
||||
if name is None:
|
||||
self.kwargs['name'] = unique_name(self.layer_type)
|
||||
|
||||
@property
|
||||
def name(self):
|
||||
return self.kwargs['name']
|
||||
|
||||
@property
|
||||
def main_program(self):
|
||||
prog = self.kwargs.get('main_program', None)
|
||||
if prog is None:
|
||||
return g_main_program
|
||||
else:
|
||||
return prog
|
||||
|
||||
@property
|
||||
def startup_program(self):
|
||||
prog = self.kwargs.get('startup_program', None)
|
||||
if prog is None:
|
||||
return g_startup_program
|
||||
else:
|
||||
return prog
|
||||
|
||||
def append_op(self, *args, **kwargs):
|
||||
return self.main_program.current_block().append_op(*args, **kwargs)
|
||||
|
||||
def multiple_input(self, input_param_name='input'):
|
||||
inputs = self.kwargs.get(input_param_name, [])
|
||||
type_error = TypeError(
|
||||
"Input of {0} layer should be Variable or sequence of Variable".
|
||||
format(self.layer_type))
|
||||
if isinstance(inputs, Variable):
|
||||
inputs = [inputs]
|
||||
elif not isinstance(inputs, list) and not isinstance(inputs, tuple):
|
||||
raise type_error
|
||||
else:
|
||||
for each in inputs:
|
||||
if not isinstance(each, Variable):
|
||||
raise type_error
|
||||
return inputs
|
||||
|
||||
def input(self, input_param_name='input'):
|
||||
inputs = self.multiple_input(input_param_name)
|
||||
if len(inputs) != 1:
|
||||
raise "{0} layer only takes one input".format(self.layer_type)
|
||||
return inputs[0]
|
||||
|
||||
@property
|
||||
def param_attr(self):
|
||||
default = {'name': None, 'initializer': UniformInitializer()}
|
||||
actual = self.kwargs.get('param_attr', None)
|
||||
if actual is None:
|
||||
actual = default
|
||||
for default_field in default.keys():
|
||||
if default_field not in actual:
|
||||
actual[default_field] = default[default_field]
|
||||
return actual
|
||||
|
||||
def bias_attr(self):
|
||||
default = {'name': None, 'initializer': ConstantInitializer()}
|
||||
bias_attr = self.kwargs.get('bias_attr', None)
|
||||
if bias_attr is True:
|
||||
bias_attr = default
|
||||
|
||||
if isinstance(bias_attr, dict):
|
||||
for default_field in default.keys():
|
||||
if default_field not in bias_attr:
|
||||
bias_attr[default_field] = default[default_field]
|
||||
return bias_attr
|
||||
|
||||
def multiple_param_attr(self, length):
|
||||
param_attr = self.param_attr
|
||||
if isinstance(param_attr, dict):
|
||||
param_attr = [param_attr]
|
||||
|
||||
if len(param_attr) != 1 and len(param_attr) != length:
|
||||
raise ValueError("parameter number mismatch")
|
||||
elif len(param_attr) == 1 and length != 1:
|
||||
tmp = [None] * length
|
||||
for i in xrange(length):
|
||||
tmp[i] = copy.deepcopy(param_attr[0])
|
||||
param_attr = tmp
|
||||
return param_attr
|
||||
|
||||
def iter_inputs_and_params(self, input_param_name='input'):
|
||||
inputs = self.multiple_input(input_param_name)
|
||||
param_attrs = self.multiple_param_attr(len(inputs))
|
||||
for ipt, param_attr in itertools.izip(inputs, param_attrs):
|
||||
yield ipt, param_attr
|
||||
|
||||
def input_dtype(self, input_param_name='input'):
|
||||
inputs = self.multiple_input(input_param_name)
|
||||
dtype = None
|
||||
for each in inputs:
|
||||
if dtype is None:
|
||||
dtype = each.data_type
|
||||
elif dtype != each.data_type:
|
||||
raise ValueError("Data Type mismatch")
|
||||
return dtype
|
||||
|
||||
def create_parameter(self, attr, shape, dtype, suffix='w',
|
||||
initializer=None):
|
||||
# Deepcopy the attr so that parameters can be shared in program
|
||||
attr_copy = copy.deepcopy(attr)
|
||||
if initializer is not None:
|
||||
attr_copy['initializer'] = initializer
|
||||
if attr_copy['name'] is None:
|
||||
attr_copy['name'] = unique_name(".".join([self.name, suffix]))
|
||||
self.startup_program.global_block().create_parameter(
|
||||
dtype=dtype, shape=shape, **attr_copy)
|
||||
return self.main_program.global_block().create_parameter(
|
||||
name=attr_copy['name'], dtype=dtype, shape=shape)
|
||||
|
||||
def create_tmp_variable(self, dtype):
|
||||
return self.main_program.current_block().create_var(
|
||||
name=unique_name(".".join([self.name, 'tmp'])),
|
||||
dtype=dtype,
|
||||
persistable=False)
|
||||
|
||||
def create_variable(self, *args, **kwargs):
|
||||
return self.main_program.current_block().create_var(*args, **kwargs)
|
||||
|
||||
def create_global_variable(self, persistable=False, *args, **kwargs):
|
||||
return self.main_program.global_block().create_var(
|
||||
*args, persistable=persistable, **kwargs)
|
||||
|
||||
def set_variable_initializer(self, var, initializer):
|
||||
assert isinstance(var, Variable)
|
||||
self.startup_program.global_block().create_var(
|
||||
name=var.name,
|
||||
type=var.type,
|
||||
dtype=var.data_type,
|
||||
shape=var.shape,
|
||||
persistable=True,
|
||||
initializer=initializer)
|
||||
|
||||
def append_bias_op(self, input_var, num_flatten_dims=None):
|
||||
"""
|
||||
Append bias operator and return its output. If the user does not set
|
||||
bias_attr, append_bias_op will return input_var
|
||||
|
||||
:param input_var: the input variable. The len(input_var.shape) is larger
|
||||
or equal than 2.
|
||||
:param num_flatten_dims: The input tensor will be flatten as a matrix
|
||||
when adding bias.
|
||||
`matrix.shape = product(input_var.shape[0:num_flatten_dims]), product(
|
||||
input_var.shape[num_flatten_dims:])`
|
||||
"""
|
||||
if num_flatten_dims is None:
|
||||
num_flatten_dims = self.kwargs.get('num_flatten_dims', None)
|
||||
if num_flatten_dims is None:
|
||||
num_flatten_dims = 1
|
||||
|
||||
size = list(input_var.shape[num_flatten_dims:])
|
||||
bias_attr = self.bias_attr()
|
||||
if not bias_attr:
|
||||
return input_var
|
||||
|
||||
b = self.create_parameter(
|
||||
attr=bias_attr, shape=size, dtype=input_var.data_type, suffix='b')
|
||||
tmp = self.create_tmp_variable(dtype=input_var.data_type)
|
||||
self.append_op(
|
||||
type='elementwise_add',
|
||||
inputs={'X': [input_var],
|
||||
'Y': [b]},
|
||||
outputs={'Out': [tmp]})
|
||||
return tmp
|
||||
|
||||
def append_activation(self, input_var):
|
||||
act = self.kwargs.get('act', None)
|
||||
if act is None:
|
||||
return input_var
|
||||
if isinstance(act, basestring):
|
||||
act = {'type': act}
|
||||
tmp = self.create_tmp_variable(dtype=input_var.data_type)
|
||||
act_type = act.pop('type')
|
||||
self.append_op(
|
||||
type=act_type,
|
||||
inputs={"X": [input_var]},
|
||||
outputs={"Y": [tmp]},
|
||||
attrs=act)
|
||||
return tmp
|
||||
```
|
||||
|
||||
详细的源码细节我们下一节会讲这里指写一下实现的方式和调用的函数。
|
||||
|
||||
所以这个卷积过程就完成了。从上文的计算中我们可以看到,同一层的神经元可以共享卷积核,那么对于高位数据的处理将会变得非常简单。并且使用卷积核后图片的尺寸变小,方便后续计算,并且我们不需要手动去选取特征,只用设计好卷积核的尺寸,数量和滑动的步长就可以让它自己去训练了,省时又省力啊。
|
||||
|
||||
**为什么卷积核有效?**
|
||||
|
||||
那么问题来了,虽然我们知道了卷积核是如何计算的,但是为什么使用卷积核计算后分类效果要由于普通的神经网络呢?我们仔细来看一下上面计算的结果。通过第一个卷积核计算后的feature_map是一个三维数据,在第三列的绝对值最大,说明原始图片上对应的地方有一条垂直方向的特征,即像素数值变化较大;而通过第二个卷积核计算后,第三列的数值为0,第二行的数值绝对值最大,说明原始图片上对应的地方有一条水平方向的特征。
|
||||
|
||||
仔细思考一下,这个时候,我们设计的两个卷积核分别能够提取,或者说检测出原始图片的特定的特征。此时我们其实就可以把卷积核就理解为特征提取器啊!现在就明白了,为什么我们只需要把图片数据灌进去,设计好卷积核的尺寸、数量和滑动的步长就可以让自动提取出图片的某些特征,从而达到分类的效果啊!
|
||||
|
||||
**注**:1.此处的卷积运算是两个卷积核大小的矩阵的内积运算,不是矩阵乘法。即相同位置的数字相乘再相加求和。不要弄混淆了。
|
||||
|
||||
2.卷积核的公式有很多,这只是最简单的一种。我们所说的卷积核在数字信号处理里也叫滤波器,那滤波器的种类就多了,均值滤波器,高斯滤波器,拉普拉斯滤波器等等,不过,不管是什么滤波器,都只是一种数学运算,无非就是计算更复杂一点。
|
||||
|
||||
3.每一层的卷积核大小和个数可以自己定义,不过一般情况下,根据实验得到的经验来看,会在越靠近输入层的卷积层设定少量的卷积核,越往后,卷积层设定的卷积核数目就越多。具体原因大家可以先思考一下,小结里会解释原因。
|
||||
|
||||
* **池化层(Pooling Layer)**
|
||||
|
||||
通过上一层2*2的卷积核操作后,我们将原始图像由4*4的尺寸变为了3*3的一个新的图片。池化层的主要目的是通过降采样的方式,在不影响图像质量的情况下,压缩图片,减少参数。简单来说,假设现在设定池化层采用MaxPooling,大小为2*2,步长为1,取每个窗口最大的数值重新,那么图片的尺寸就会由3*3变为2*2:(3-2)+1=2。从上例来看,会有如下变换:
|
||||
|
||||
|
||||
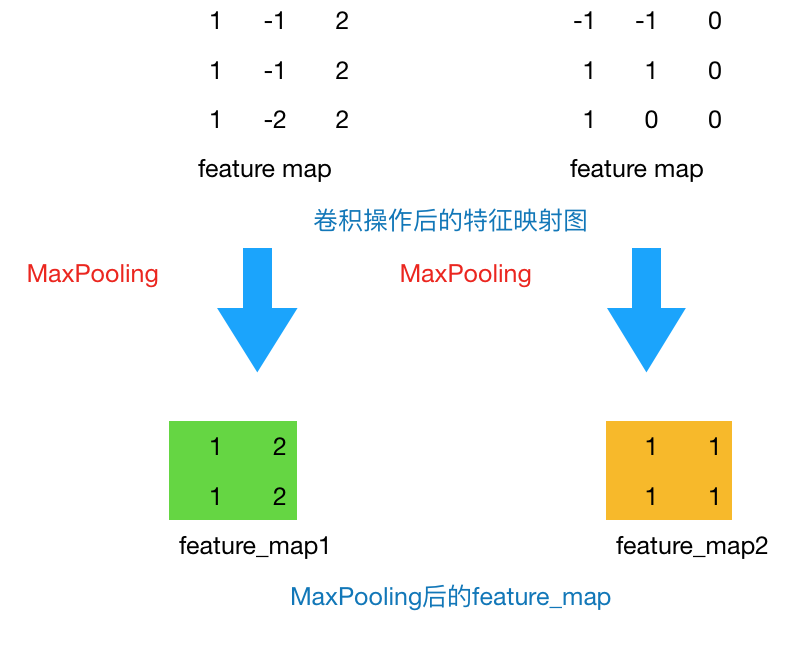
|
||||
|
||||
图3 Max Pooling结果
|
||||
|
||||
通常来说,池化方法一般有一下两种:
|
||||
|
||||
* MaxPooling:取滑动窗口里最大的值
|
||||
* AveragePooling:取滑动窗口内所有值的平均值
|
||||
|
||||
为什么采用Max Pooling?
|
||||
|
||||
从计算方式来看,算是最简单的一种了,取max即可,但是这也引发一个思考,为什么需要Max Pooling,意义在哪里?如果我们只取最大值,那其他的值被舍弃难道就没有影响吗?不会损失这部分信息吗?如果认为这些信息是可损失的,那么是否意味着我们在进行卷积操作后仍然产生了一些不必要的冗余信息呢?
|
||||
|
||||
其实从上文分析卷积核为什么有效的原因来看,每一个卷积核可以看做一个特征提取器,不同的卷积核负责提取不同的特征,我们例子中设计的第一个卷积核能够提取出“垂直”方向的特征,第二个卷积核能够提取出“水平”方向的特征,那么我们对其进行Max Pooling操作后,提取出的是真正能够识别特征的数值,其余被舍弃的数值,对于我提取特定的特征并没有特别大的帮助。那么在进行后续计算使,减小了feature map的尺寸,从而减少参数,达到减小计算量,缺不损失效果的情况。
|
||||
|
||||
不过并不是所有情况Max Pooling的效果都很好,有时候有些周边信息也会对某个特定特征的识别产生一定效果,那么这个时候舍弃这部分“不重要”的信息,就不划算了。所以具体情况得具体分析,如果加了Max Pooling后效果反而变差了,不如把卷积后不加Max Pooling的结果与卷积后加了Max Pooling的结果输出对比一下,看看Max Pooling是否对卷积核提取特征起了反效果。
|
||||
|
||||
Zero Padding
|
||||
|
||||
所以到现在为止,我们的图片由4*4,通过卷积层变为3*3,再通过池化层变化2*2,如果我们再添加层,那么图片岂不是会越变越小?这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用3*3的卷积核,那么变换后的图片尺寸与原图片尺寸相同,如下图所示:
|
||||
|
||||
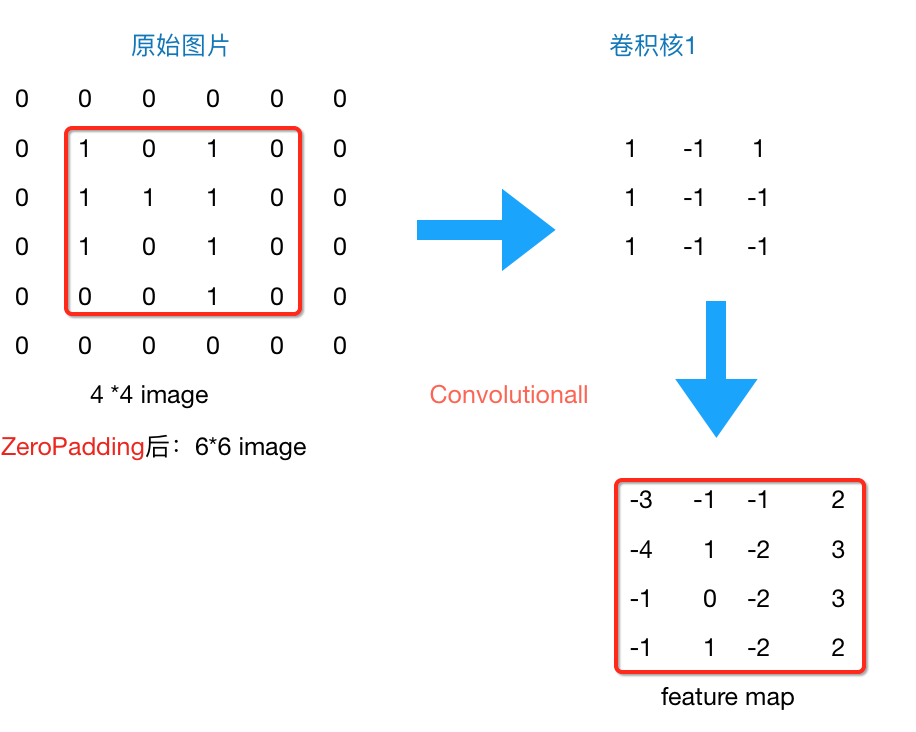
|
||||
|
||||
图4 zero padding结果
|
||||
|
||||
通常情况下,我们希望图片做完卷积操作后保持图片大小不变,所以我们一般会选择尺寸为3*3的卷积核和1的zero padding,或者5*5的卷积核与2的zero padding,这样通过计算后,可以保留图片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1
|
||||
|
||||
注:这里的width也可换成height,此处是默认正方形的卷积核,weight = height,如果两者不相等,可以分开计算,分别补零。
|
||||
|
||||
* **Flatten层 & Fully Connected Layer**
|
||||
|
||||
到这一步,其实我们的一个完整的“卷积部分”就算完成了,如果想要叠加层数,一般也是叠加“Conv-MaxPooing",通过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。
|
||||
|
||||
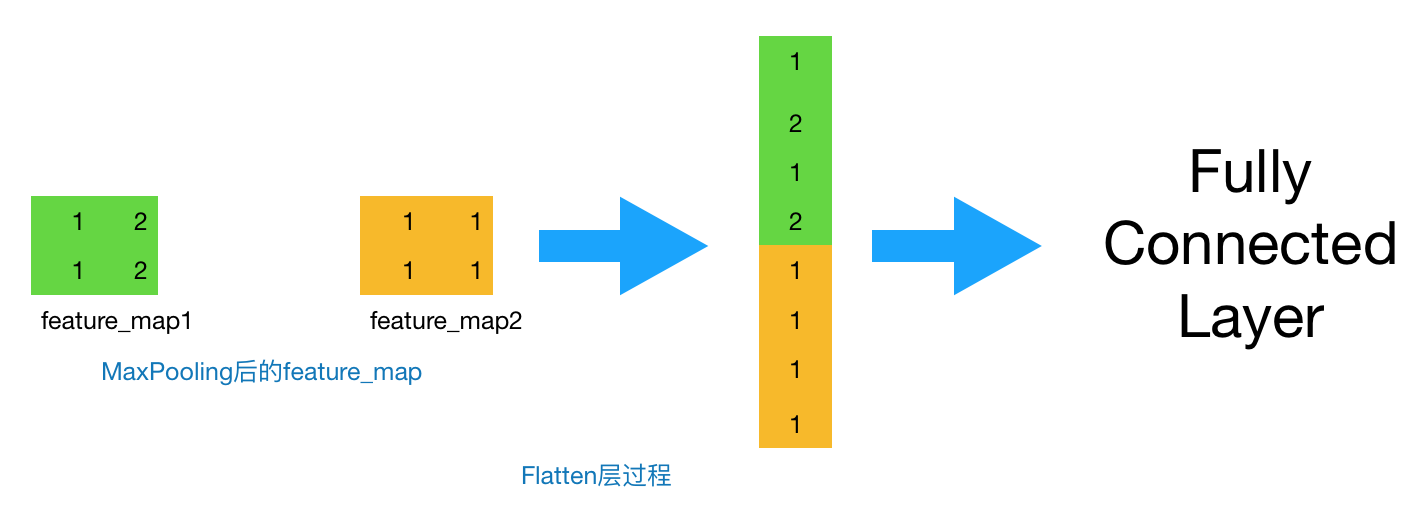
|
||||
|
||||
图5 Flatten过程
|
||||
|
||||
|
||||
|
||||
* **小结**
|
||||
|
||||
这一节我们介绍了最基本的卷积神经网络的基本层的定义,计算方式和起的作用。有几个小问题可以供大家思考一下:
|
||||
|
||||
1.卷积核的尺寸必须为正方形吗?可以为长方形吗?如果是长方形应该怎么计算?
|
||||
|
||||
2.卷积核的个数如何确定?每一层的卷积核的个数都是相同的吗?
|
||||
|
||||
3.步长的向右和向下移动的幅度必须是一样的吗?
|
||||
|
||||
如果对上面的讲解真的弄懂了的话,其实这几个问题并不难回答。下面给出我的想法,可以作为参考:
|
||||
|
||||
1.卷积核的尺寸不一定非得为正方形。长方形也可以,只不过通常情况下为正方形。如果要设置为长方形,那么首先得保证这层的输出形状是整数,不能是小数。如果你的图像是边长为 28 的正方形。那么卷积层的输出就满足 [ (28 - kernel_size)/ stride ] + 1 ,这个数值得是整数才行,否则没有物理意义。譬如,你算得一个边长为 3.6 的 feature map 是没有物理意义的。 pooling 层同理。FC 层的输出形状总是满足整数,其唯一的要求就是整个训练过程中 FC 层的输入得是定长的。如果你的图像不是正方形。那么在制作数据时,可以缩放到统一大小(非正方形),再使用非正方形的 kernel_size 来使得卷积层的输出依然是整数。总之,撇开网络结果设定的好坏不谈,其本质上就是在做算术应用题:如何使得各层的输出是整数。
|
||||
|
||||
|
||||
2.由经验确定。通常情况下,靠近输入的卷积层,譬如第一层卷积层,会找出一些共性的特征,如手写数字识别中第一层我们设定卷积核个数为5个,一般是找出诸如"横线"、“竖线”、“斜线”等共性特征,我们称之为basic feature,经过max pooling后,在第二层卷积层,设定卷积核个数为20个,可以找出一些相对复杂的特征,如“横折”、“左半圆”、“右半圆”等特征,越往后,卷积核设定的数目越多,越能体现label的特征就越细致,就越容易分类出来,打个比方,如果你想分类出“0”的数字,你看到这个特征,能推测是什么数字呢?只有越往后,检测识别的特征越多,试过能识别这几个特征,那么我就能够确定这个数字是“0”。
|
||||
|
||||
|
||||
3.有stride_w和stride_h,后者表示的就是上下步长。如果用stride,则表示stride_h=stride_w=stride。
|
||||
|
||||
* * *
|
||||
|
||||
* ***手写数字识别的CNN网络结构**
|
||||
|
||||
上面我们了解了卷积神经网络的基本结构后,现在来具体看一下在实际数据---手写数字识别中是如何操作的。上文中我定义了一个最基本的CNN网络。如下(代码详见[github](https://github.com/huxiaoman7/PaddlePaddle_code))
|
||||
|
||||
|
||||
```python
|
||||
def convolutional_neural_network_org(img):
|
||||
# first conv layer
|
||||
conv_pool_1 = paddle.networks.simple_img_conv_pool(
|
||||
input=img,
|
||||
filter_size=3,
|
||||
num_filters=20,
|
||||
num_channel=1,
|
||||
pool_size=2,
|
||||
pool_stride=2,
|
||||
act=paddle.activation.Relu())
|
||||
# second conv layer
|
||||
conv_pool_2 = paddle.networks.simple_img_conv_pool(
|
||||
input=conv_pool_1,
|
||||
filter_size=5,
|
||||
num_filters=50,
|
||||
num_channel=20,
|
||||
pool_size=2,
|
||||
pool_stride=2,
|
||||
act=paddle.activation.Relu())
|
||||
# fully-connected layer
|
||||
predict = paddle.layer.fc(
|
||||
input=conv_pool_2, size=10, act=paddle.activation.Softmax())
|
||||
return predict
|
||||
```
|
||||
|
||||
那么它的网络结构是:
|
||||
|
||||
conv1----> conv2---->fully Connected layer
|
||||
|
||||
非常简单的网络结构。第一层我们采取的是 `3*3` 的正方形卷积核,个数为20个,深度为1,stride为2,pooling尺寸为 `2*2`,激活函数采取的为RELU;第二层只对卷积核的尺寸、个数和深度做了些变化,分别为 `5*5` ,50个和20;最后链接一层全连接,设定10个label作为输出,采用Softmax函数作为分类器,输出每个label的概率。
|
||||
|
||||
那么这个时候我考虑的问题是,既然上面我们已经了解了卷积核,改变卷积核的大小是否会对我的结果造成影响?增多卷积核的数目能够提高准确率?于是我做了个实验:
|
||||
|
||||
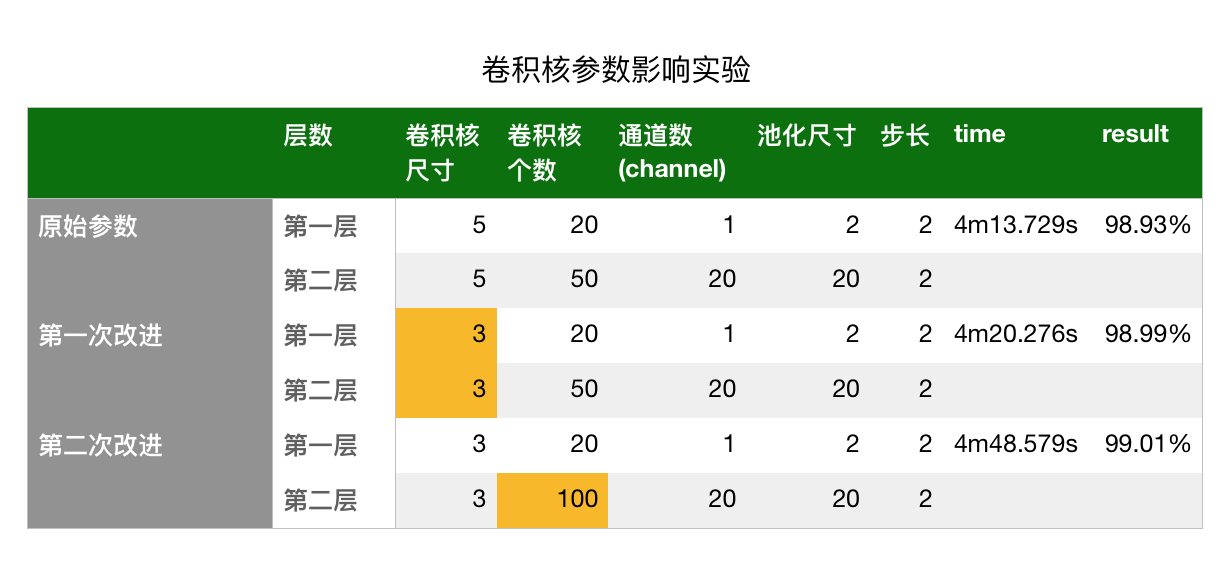
|
||||
|
||||
* 第一次改进:仅改变第一层与第二层的卷积核数目的大小,其他保持不变。可以看到结果提升了0.06%
|
||||
* 第二次改进:保持3*3的卷积核大小,仅改变第二层的卷积核数目,其他保持不变,可以看到结果相较于原始参数提升了0.08%
|
||||
|
||||
由以上结果可以看出,改变卷积核的大小与卷积核的数目会对结果产生一定影响,在目前手写数字识别的项目中,缩小卷积核尺寸,增加卷积核数目都会提高准确率。不过以上实验只是一个小测试,有兴趣的同学可以多做几次实验,看看参数带来的具体影响,下篇文章我们会着重分析参数的影响。
|
||||
|
||||
这篇文章主要介绍了神经网络的预备知识,卷积神经网络的常见的层及基本的计算过程,看完后希望大家明白以下几个知识点:
|
||||
|
||||
> * 为什么卷积神经网络更适合于图像分类?相比于传统的神经网络优势在哪里?
|
||||
> * 卷积层中的卷积过程是如何计算的?为什么卷积核是有效的?
|
||||
> * 卷积核的个数如何确定?应该选择多大的卷积核对于模型来说才是有效的?尺寸必须为正方形吗?如果是长方形因该怎么做?
|
||||
> * 步长的大小会对模型的效果产生什么样的影响?垂直方向和水平方向的步长是否得设定为相同的?
|
||||
> * 为什么要采用池化层,Max Pooling有什么好处?
|
||||
> * Zero Padding有什么作用?如果已知一个feature map的尺寸,如何确定zero padding的数目?
|
||||
|
||||
上面的问题,有些在文章中已经详细讲过,有些大家可以根据文章的内容多思考一下。最后给大家留几个问题思考一下:
|
||||
|
||||
> * 为什么改变卷积核的大小能够提高结果的准确率?卷积核大小对于分类结果是如何影响的?
|
||||
> * 卷积核的参数是怎么求的?一开始随机定义一个,那么后来是如何训练才能使这个卷积核识别某些特定的特征呢?
|
||||
> * 1*1的卷积核有意义吗?为什么有些网络层结构里会采用1*1的卷积核?
|
||||
|
||||
|
||||
|
||||
下篇文章我们会着重讲解以下几点:
|
||||
|
||||
> * 卷积核的参数如何确定?随机初始化一个数值后,是如何训练得到一个能够识别某些特征的卷积核的?
|
||||
> * CNN是如何进行反向传播的?
|
||||
> * 如何调整CNN里的参数?
|
||||
> * 如何设计最适合的CNN网络结构?
|
||||
> * 能够不用调用框架的api,手写一个CNN,并和paddlepaddle里的实现过程做对比,看看有哪些可以改进的?
|
||||
|
||||
ps:本篇文章是基于个人对CNN的理解来写的,本人能力有限,有些地方可能写的不是很严谨,如有错误或疏漏之处,请留言给我,我一定会仔细核实并修改的^_^!不接受无脑喷哦~此外,文中的图表结构均为自己所做,希望不要被人随意抄袭,可以进行非商业性质的转载,需要转载留言或发邮件即可,希望能够尊重劳动成果,谢谢!有不懂的也请留言给我,我会尽力解答的哈~
|
||||
|
||||
---
|
||||
|
||||
* 作者:Charlotte77
|
||||
* 出处:http://www.cnblogs.com/charlotte77/
|
||||
* 本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
# LSTM原理
|
||||
|
||||
# 长短期记忆网络(Long Short-Term Memory,LSTM)及其变体双向LSTM和GRU
|
||||
|
||||
**LSTM**(Long Short-Term Memory)长短期记忆网络,是一种时间递归神经网络,**适合于处理和预测时间序列中间隔和延迟相对较长的重要事件**。LSTM是解决循环神经网络RNN结构中存在的“梯度消失”问题而提出的,是一种特殊的循环神经网络。最常见的一个例子就是:当我们要预测“the clouds are in the (...)"的时候, 这种情况下,相关的信息和预测的词位置之间的间隔很小,RNN会使用先前的信息预测出词是”sky“。但是如果想要预测”I grew up in France ... I speak fluent (...)”,语言模型推测下一个词可能是一种语言的名字,但是具体是什么语言,需要用到间隔很长的前文中France,在这种情况下,RNN因为“梯度消失”的问题,并不能利用间隔很长的信息,然而,LSTM在设计上明确避免了长期依赖的问题,这主要归功于LSTM精心设计的“门”结构(输入门、遗忘门和输出门)消除或者增加信息到细胞状态的能力,使得LSTM能够记住长期的信息。
|
||||
|
||||
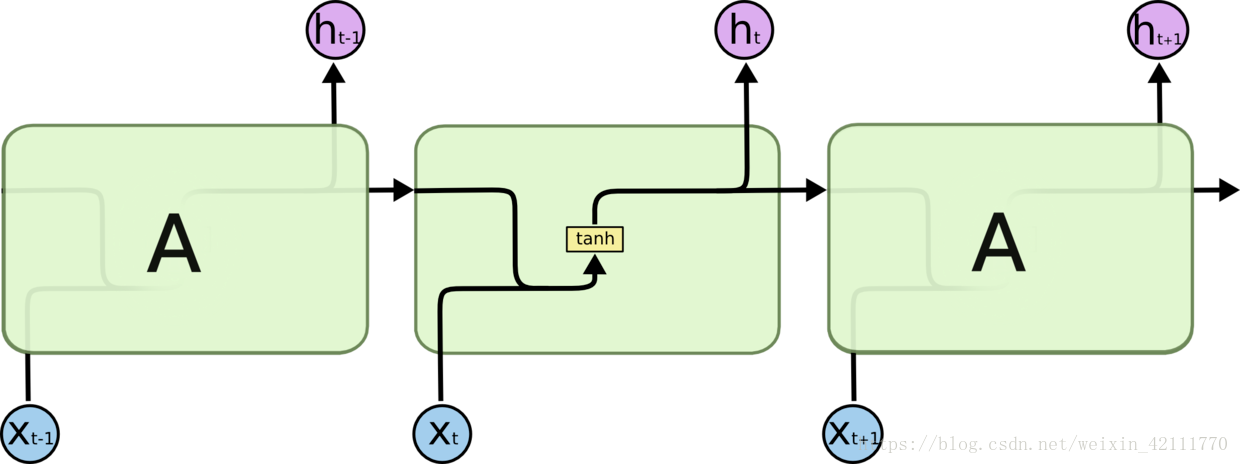 vs 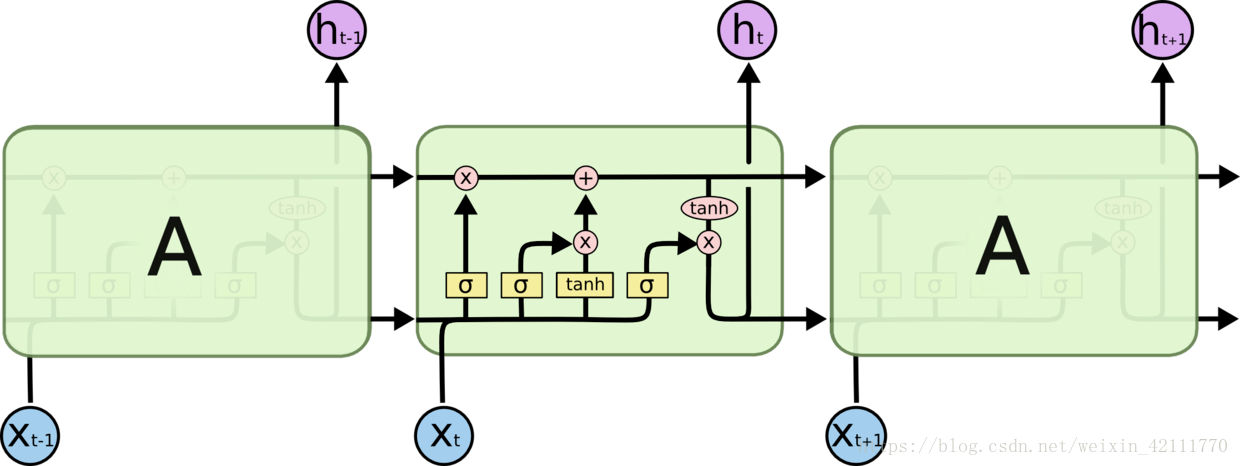
|
||||
|
||||
标准的RNN结构都具有一种重复神经网络模块的链式形式,一般是一个tanh层进行重复的学习(如上图左边图),而在LSTM中(上图右边图),重复的模块中有四个特殊的结构。**贯穿在图上方的水平线为细胞状态(cell),黄色的矩阵是学习得到的神经网络层,粉色的圆圈表示运算操作,黑色的箭头表示向量的传输**,整体看来,不仅仅是h在随着时间流动,细胞状态c也在随着时间流动,细胞状态c代表着长期记忆。
|
||||
|
||||
上面我们提到LSTM之所以能够记住长期的信息,在于设计的“门”结构,“门”结构是一种让信息选择式通过的方法,包括一个sigmoid神经网络层和一个pointwise乘法操作,如下图所示结构。复习一下sigmoid函数,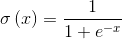,sigmoid输出为0到1之间的数组,一般用在二分类问题,输出值接近0代表“不允许通过”,趋向1代表“允许通过”。
|
||||
|
||||
|
||||
|
||||
|
||||
**在LSTM中,第一阶段是遗忘门,遗忘层决定哪些信息需要从细胞状态中被遗忘,下一阶段是输入门,输入门确定哪些新信息能够被存放到细胞状态中,最后一个阶段是输出门,输出门确定输出什么值**。下面我们把LSTM就着各个门的子结构和数学表达式进行分析。
|
||||
|
||||
* 遗忘门:遗忘门是以上一层的输出和本层要输入的序列数据作为输入,通过一个激活函数sigmoid,得到输出为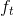。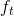的输出取值在[0,1]区间,表示上一层细胞状态被遗忘的概率,1是“完全保留”,0是“完全舍弃”
|
||||
|
||||
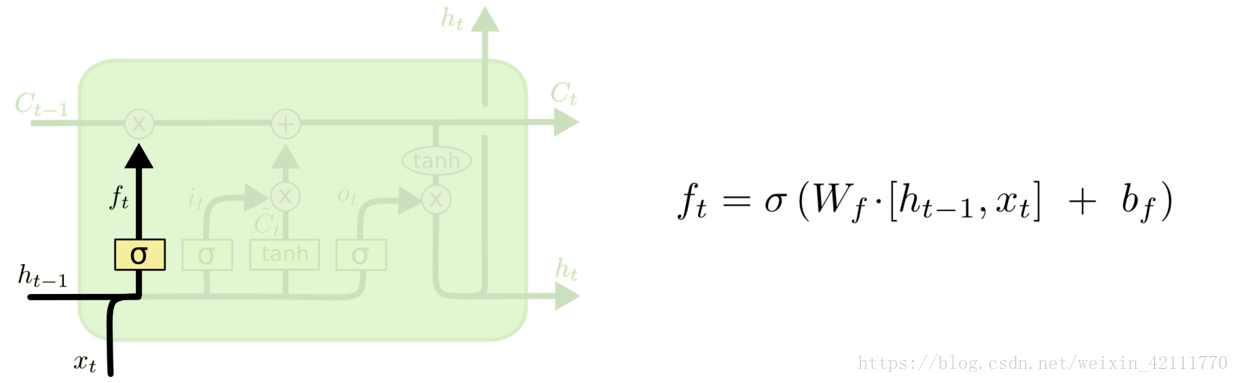
|
||||
|
||||
|
||||
* 输入门:输入门包含两个部分,第一部分使用sigmoid激活函数,输出为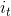,第二部分使用tanh激活函数,输出为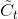。**【个人通俗理解: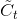在RNN网络中就是本层的输出,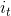是在[0,1]区间取值,表示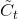中的信息被保留的程度,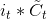表示该层被保留的新信息】**
|
||||
|
||||
|
||||
|
||||
|
||||
到目前为止,是遗忘门的输出,控制着上一层细胞状态被遗忘的程度,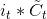为输入门的两个输出乘法运算,表示有多少新信息被保留,基于此,我们就可以把新信息更新这一层的细胞状态。
|
||||
|
||||
|
||||
|
||||
|
||||
* 输出门:输出门用来控制该层的细胞状态有多少被过滤。首先使用sigmoid激活函数得到一个[0,1]区间取值的,接着将细胞状态通过tanh激活函数处理后与相乘,即是本层的输出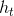。
|
||||
|
||||
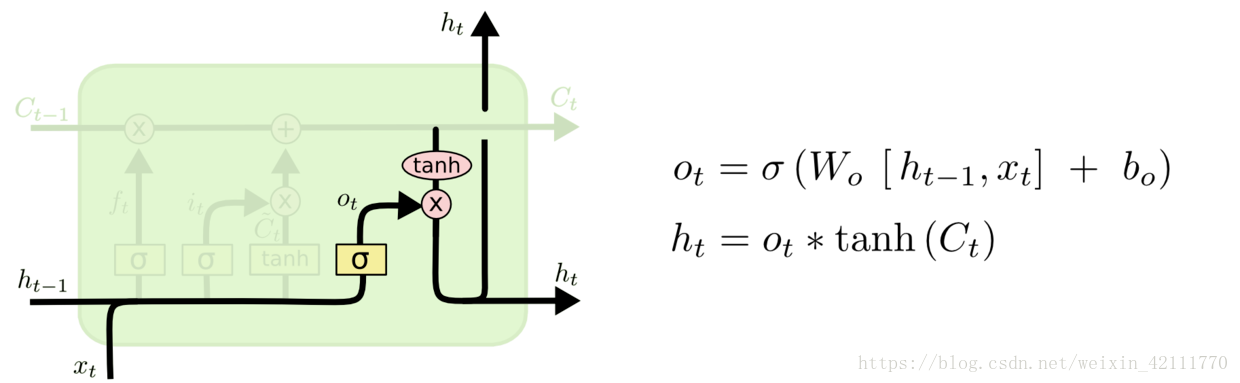
|
||||
|
||||
|
||||
至此,终于将LSTM的结构理解了,现在有很多LSTM结构的变形,只要把这个母体结构理解了,再去理解变形的结构应该不会再有多麻烦了。
|
||||
|
||||
**双向LSTM**
|
||||
|
||||
双向RNN由两个普通的RNN所组成,一个正向的RNN,利用过去的信息,一个逆序的RNN,利用未来的信息,这样在时刻t,既能够使用t-1时刻的信息,又能够利用到t+1时刻的信息。一般来说,由于双向LSTM能够同时利用过去时刻和未来时刻的信息,会比单向LSTM最终的预测更加准确。下图为双向LSTM的结构。
|
||||
|
||||

|
||||
|
||||
|
||||
* 为正向的RNN,参与正向计算,t时刻的输入为t时刻的序列数据和t-1时刻的输出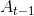
|
||||
* 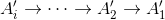为逆向的RNN,参与反向计算,t时刻的输入为t时刻的序列数据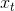和t+1时刻的输出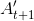
|
||||
* t时刻的最终输出值取决于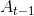和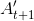
|
||||
|
||||
**GRU(Gated Recurrent Unit)**是LSTM最流行的一个变体,比LSTM模型要简单
|
||||
|
||||

|
||||
|
||||
|
||||
GRU包括两个门,一个重置门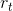和更新门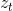。这两个门的激活函数为sigmoid函数,在[0,1]区间取值。
|
||||
|
||||
候选隐含状态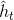使用重置门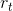来控制t-1时刻信息的输入,如果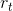结果为0,那么上一个隐含状态的输出信息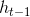将被丢弃。也就是说,**重置门决定过去有多少信息被遗忘,有助于捕捉时序数据中短期的依赖关系**。
|
||||
|
||||
|
||||
隐含状态使用更新门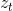对上一时刻隐含状态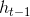和候选隐含状态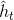进行更新。更新门控制过去的隐含状态在当前时刻的重要性,**如果更新门一直趋近于1,t时刻之前的隐含状态将一直保存下来并全传递到t时刻,****更新门有助于捕捉时序数据中中长期的依赖关系**。
|
||||
|
|
@ -0,0 +1,144 @@
|
|||
# RNN原理
|
||||
|
||||
# 循环神经网络(RNN)原理通俗解释
|
||||
|
||||
## 1.RNN怎么来的?
|
||||
|
||||
循环神经网络的应用场景比较多,比如暂时能写论文,写程序,写诗,但是,(总是会有但是的),但是他们现在还不能正常使用,学习出来的东西没有逻辑,所以要想真正让它更有用,路还很远。
|
||||
|
||||
这是一般的神经网络应该有的结构:
|
||||
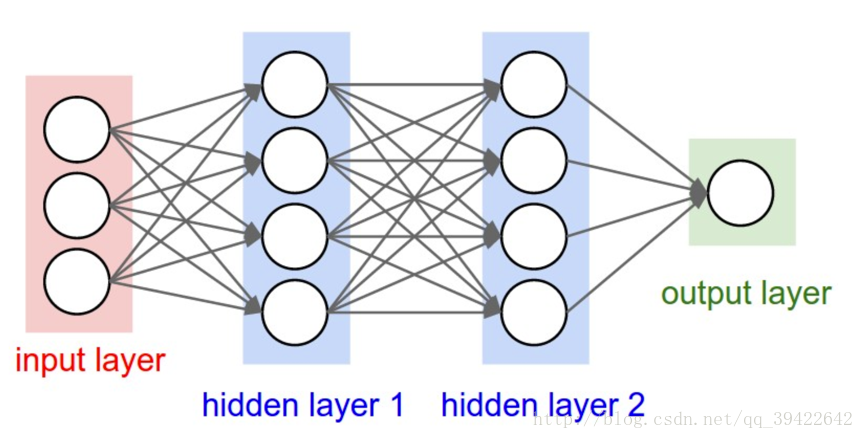
|
||||
|
||||
既然我们已经有了人工神经网络和卷积神经网络,为什么还要循环神经网络?
|
||||
原因很简单,无论是卷积神经网络,还是人工神经网络,他们的前提假设都是:元素之间是相互独立的,**输入与输出也是独立的**,比如猫和狗。
|
||||
但现实世界中,很多元素都是相互连接的,比如股票随时间的变化,一个人说了:我喜欢旅游,其中最喜欢的地方是云南,以后有机会一定要去___这里填空,人应该都知道是填“云南“。因为我们是根据上下文的内容推断出来的,但机会要做到这一步就相当得难了。因此,就有了现在的循环神经网络,他的本质是**:像人一样拥有记忆的能力。**因此,他的输出就依赖于当前的输入和记忆。
|
||||
|
||||
## 2.RNN的网络结构及原理
|
||||
|
||||
它的网络结构如下:
|
||||
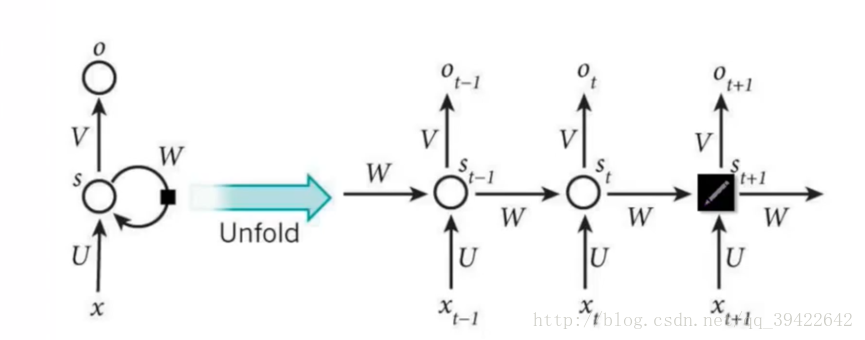
|
||||
其中每个圆圈可以看作是一个单元,而且每个单元做的事情也是一样的,因此可以折叠呈左半图的样子。用一句话解释RNN,就是**一个单元结构重复使用**。
|
||||
|
||||
RNN是一个序列到序列的模型,假设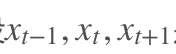是一个输入:“我是中国“,那么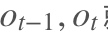就应该对应”是”,”中国”这两个,预测下一个词最有可能是什么?就是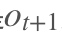应该是”人”的概率比较大。
|
||||
|
||||
因此,我们可以做这样的定义:
|
||||
|
||||

|
||||
|
||||
。因为我们当前时刻的输出是由记忆和当前时刻的输入决定的,就像你现在大四,你的知识是由大四学到的知识(当前输入)和大三以及大三以前学到的东西的(记忆)的结合,RNN在这点上也类似,神经网络最擅长做的就是通过一系列参数把很多内容整合到一起,然后学习这个参数,因此就定义了RNN的基础:
|
||||
|
||||
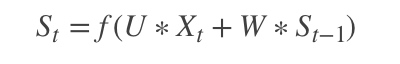
|
||||
|
||||
大家可能会很好奇,为什么还要加一个f()函数,其实这个函数是神经网络中的激活函数,但为什么要加上它呢?
|
||||
举个例子,假如你在大学学了非常好的解题方法,那你初中那时候的解题方法还要用吗?显然是不用了的。RNN的想法也一样,既然我能记忆了,那我当然是只记重要的信息啦,其他不重要的,就肯定会忘记,是吧。但是在神经网络中什么最适合过滤信息呀?肯定是激活函数嘛,因此在这里就套用一个激活函数,来做一个非线性映射,来过滤信息,这个激活函数可能为tanh,也可为其他。
|
||||
|
||||
假设你大四快毕业了,要参加考研,请问你参加考研是不是先记住你学过的内容然后去考研,还是直接带几本书去参加考研呢?很显然嘛,那RNN的想法就是预测的时候带着当前时刻的记忆
|
||||
去预测。假如你要预测“我是中国“的下一个词出现的概率,这里已经很显然了,运用softmax来预测每个词出现的概率再合适不过了,但预测不能直接带用一个矩阵来预测呀,所有预测的时候还要带一个权重矩阵V,用公式表示为:
|
||||
|
||||
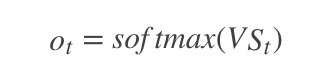
|
||||
|
||||
|
||||
其中就表示时刻t的输出。
|
||||
|
||||
RNN中的结构细节:
|
||||
1.可以把St当作隐状态,捕捉了之前时间点上的信息。就像你去考研一样,考的时候记住了你能记住的所有信息。
|
||||
2.Ot是由当前时间以及之前所有的记忆得到的。就是你考研之后做的考试卷子,是用你的记忆得到的。
|
||||
3.很可惜的是,St并不能捕捉之前所有时间点的信息。就像你考研不能记住所有的英语单词一样。
|
||||
4.和卷积神经网络一样,这里的网络中每个cell都共享了一组参数(U,V,W),这样就能极大的降低计算量了。
|
||||
5.Ot在很多情况下都是不存在的,因为很多任务,比如文本情感分析,都是只关注最后的结果的。就像考研之后选择学校,学校不会管你到底怎么努力,怎么心酸的准备考研,而只关注你最后考了多少分。
|
||||
|
||||
## 3.RNN的改进1:双向RNN
|
||||
|
||||
在有些情况,比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法。如图是双向RNN的图解:
|
||||
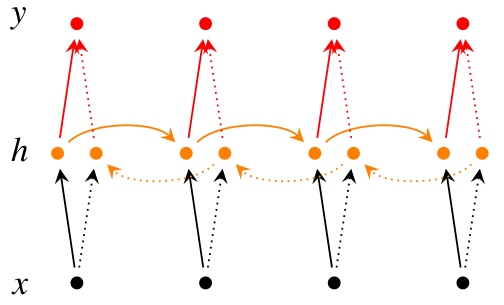
|
||||
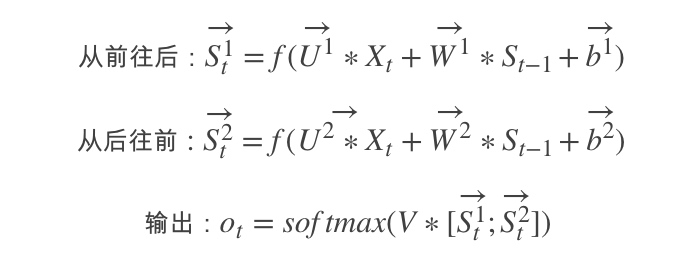
|
||||
|
||||
这里的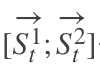做的是一个拼接,如果他们都是1000x1维的,拼接在一起就是1000x2维的了。
|
||||
|
||||
双向RNN需要的内存是单向RNN的两倍,因为在同一时间点,双向RNN需要保存两个方向上的权重参数,在分类的时候,需要同时输入两个隐藏层输出的信息。
|
||||
|
||||
## 4.RNN的改进2:深层双向RNN
|
||||
|
||||
深层双向RNN 与双向RNN相比,多了几个隐藏层,因为他的想法是很多信息记一次记不下来,比如你去考研,复习考研英语的时候,背英语单词一定不会就看一次就记住了所有要考的考研单词吧,你应该也是带着先前几次背过的单词,然后选择那些背过,但不熟的内容,或者没背过的单词来背吧。
|
||||
|
||||
深层双向RNN就是基于这么一个想法,他的输入有两方面,第一就是前一时刻的隐藏层传过来的信息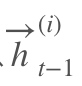,和当前时刻上一隐藏层传过来的信息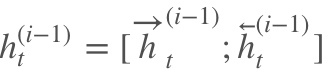,包括前向和后向的。
|
||||
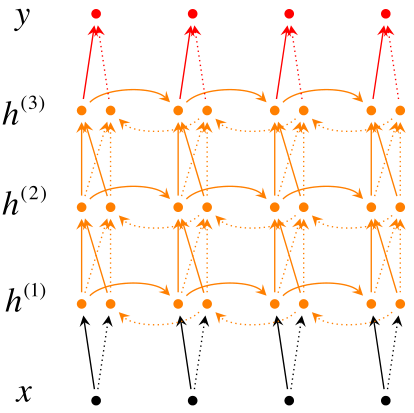
|
||||
|
||||
我们用公式来表示是这样的:
|
||||
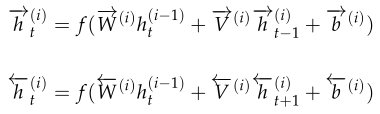
|
||||
然后再利用最后一层来进行分类,分类公式如下:
|
||||
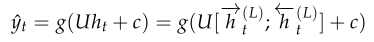
|
||||
|
||||
### 4.1 Pyramidal RNN
|
||||
|
||||
其他类似的网络还有Pyramidal RNN:
|
||||
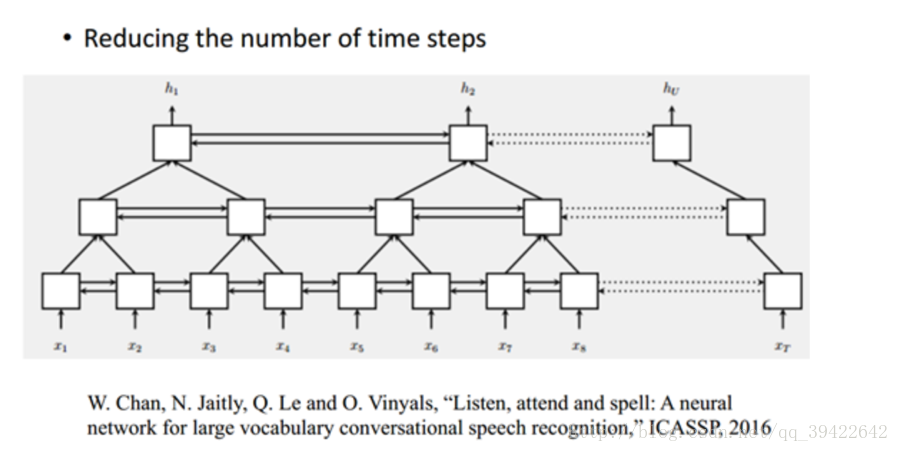
|
||||
我们现在有一个很长的输入序列,可以看到这是一个双向的RNN,上图是谷歌的W.Chan做的一个测试,它原先要做的是语音识别,他要用序列到序列的模型做语音识别,序列到序列就是说,输入一个序列然后就输出一个序列。
|
||||
|
||||
由图我们发现,上一层的两个输出,作为当前层的输入,如果是非常长的序列的话,这样做的话,每一层的序列都比上一层要短,但当前层的输入f(x)也会随之增多,貌似看一起相互抵消,运算量并没有什么改进。
|
||||
|
||||
但我们知道,对于一层来说,它是从前往后转的,比如要预测一个股市的变化,以天为单位,假如要预测明天的股市变化,你就要用今天,以及今天之前的所有数据,我们暂时无法只用昨天的数据,不用今天的数据,预测明天的数据,也即是说,预测必须具有连续性。
|
||||
但每一层的f运算是可以并行的,从这个角度来看,运算量还是可以接受的,特别是在原始输入序列较短的时候还是有优势的。
|
||||
|
||||
## 5.RNN的训练-BPTT
|
||||
|
||||
如前面我们讲的,如果要预测t时刻的输出,我们必须先利用上一时刻(t-1)的记忆和当前时刻的输入,得到t时刻的记忆:
|
||||
|
||||
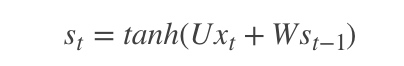
|
||||
|
||||
然后利用当前时刻的记忆,通过softmax分类器输出每个词出现的概率:
|
||||
|
||||
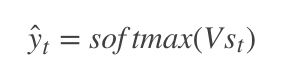
|
||||
|
||||
为了找出模型最好的参数,U,W,V,我们就要知道当前参数得到的结果怎么样,因此就要定义我们的损失函数,用交叉熵损失函数:
|
||||
|
||||
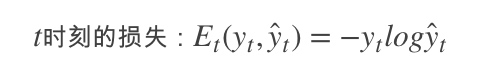
|
||||
|
||||
其中
|
||||
t时刻的标准答案,是一个只有一个是1,其他都是0的向量; 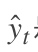是我们预测出来的结果,与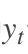
|
||||
的维度一样,但它是一个概率向量,里面是每个词出现的概率。因为对结果的影响,肯定不止一个时刻,因此需要把所有时刻的造成的损失都加起来:
|
||||
|
||||
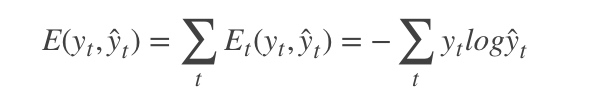
|
||||
|
||||
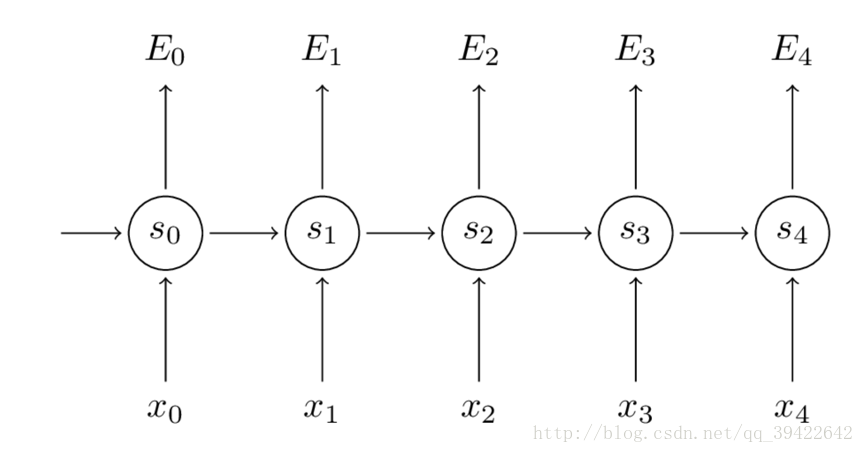
|
||||
|
||||
如图所示,你会发现每个cell都会有一个损失,我们已经定义好了损失函数,接下来就是熟悉的一步了,那就是根据损失函数利用SGD来求解最优参数,在CNN中使用反向传播BP算法来求解最优参数,但在RNN就要用到BPTT,它和BP算法的本质区别,也是CNN和RNN的本质区别:CNN没有记忆功能,它的输出仅依赖与输入,但RNN有记忆功能,它的输出不仅依赖与当前输入,还依赖与当前的记忆。这个记忆是序列到序列的,也就是当前时刻收到上一时刻的影响,比如股市的变化。
|
||||
|
||||
因此,在对参数求偏导的时候,对当前时刻求偏导,一定会涉及前一时刻,我们用例子看一下:
|
||||
|
||||
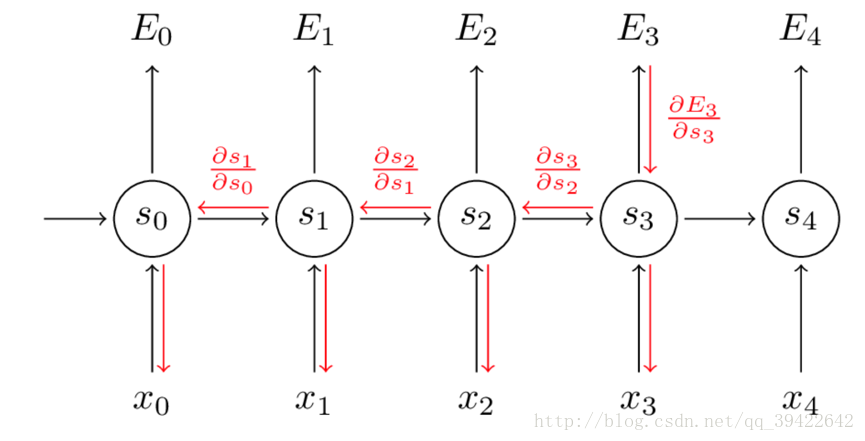
|
||||
|
||||
假设我们对E3的W求偏导:它的损失首先来源于预测的输出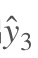
|
||||
,预测的输出又是来源于当前时刻的记忆s3,当前的记忆又是来源于当前的输出和截止到上一时刻的记忆: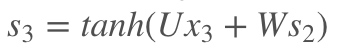
|
||||
因此,根据链式法则可以有:
|
||||
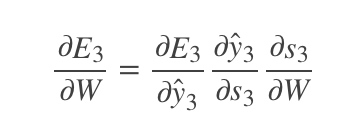
|
||||
|
||||
但是,你会发现,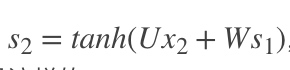
|
||||
,也就是s2里面的函数还包含了W,因此,这个链式法则还没到底,就像图上画的那样,所以真正的链式法则是这样的:
|
||||
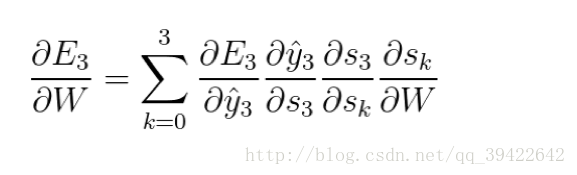
|
||||
我们要把当前时刻造成的损失,和以往每个时刻造成的损失加起来,因为我们每一个时刻都用到了权重参数W。和以往的网络不同,一般的网络,比如人工神经网络,参数是不同享的,但在循环神经网络,和CNN一样,设立了参数共享机制,来降低模型的计算量。
|
||||
|
||||
## 6.RNN与CNN的结合应用:看图说话
|
||||
|
||||
在图像处理中,目前做的最好的是CNN,而自然语言处理中,表现比较好的是RNN,因此,我们能否把他们结合起来,一起用呢?那就是看图说话了,这个原理也比较简单,举个小栗子:假设我们有CNN的模型训练了一个网络结构,比如是这个
|
||||
|
||||
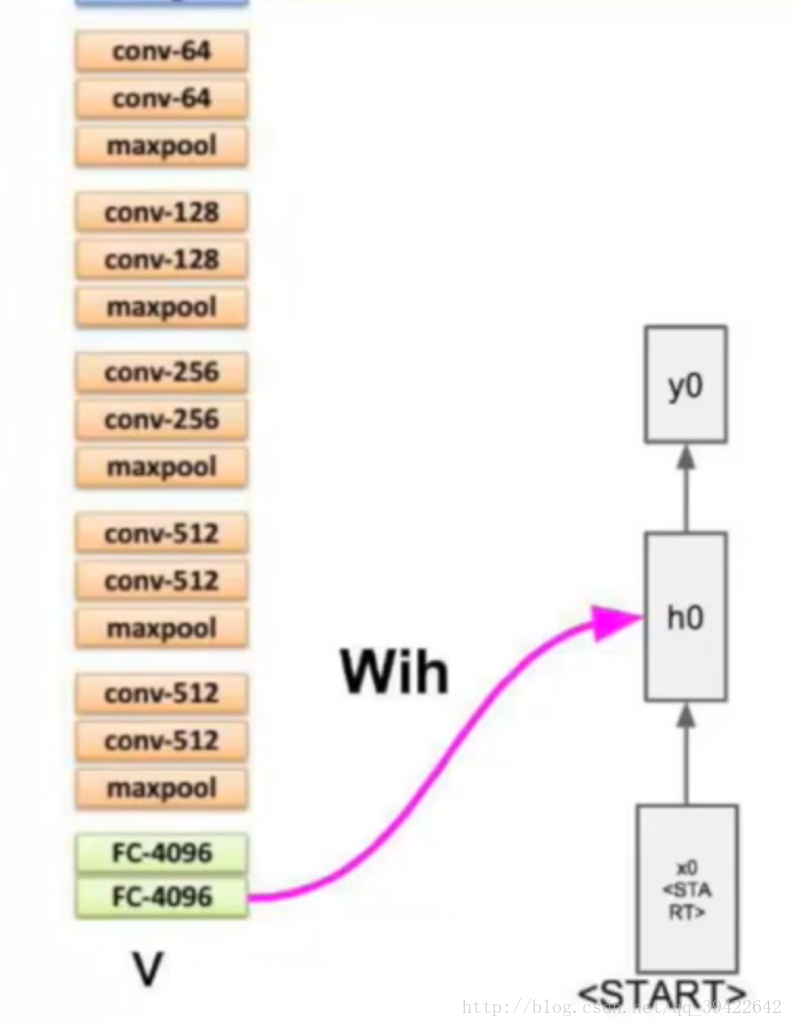
|
||||
|
||||
最后我们不是要分类嘛,那在分类前,是不是已经拿到了图像的特征呀,那我们能不能把图像的特征拿出来,放到RNN的输入里,让他学习呢?
|
||||
|
||||
之前的RNN是这样的:
|
||||
|
||||
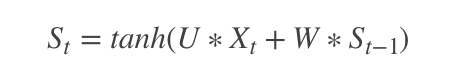
|
||||
|
||||
我们把图像的特征加在里面,可以得到:
|
||||
|
||||
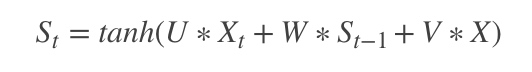
|
||||
|
||||
其中的X就是图像的特征。如果用的是上面的CNN网络,X应该是一个4096X1的向量。
|
||||
|
||||
注:这个公式只在第一步做,后面每次更新就没有V了,因为给RNN数据只在第一次迭代的时候给。
|
||||
|
||||
## 7.RNN项目练手
|
||||
|
||||
RNN可以写歌词,写诗等,这有个项目可以玩玩,还不错。
|
||||
[Tensorflow实现RNN](https://github.com/hzy46/Char-RNN-TensorFlow)
|
||||
|
|
@ -0,0 +1,412 @@
|
|||
# 反向传递
|
||||
|
||||
> 建议:一定要看懂推导过程
|
||||
|
||||
# [一文弄懂神经网络中的反向传播法——BackPropagation](https://www.cnblogs.com/charlotte77/p/5629865.html)
|
||||
|
||||
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进行补充,但是补充的又是错的,难怪觉得有问题。反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
|
||||
|
||||
说到神经网络,大家看到这个图应该不陌生:
|
||||
|
||||
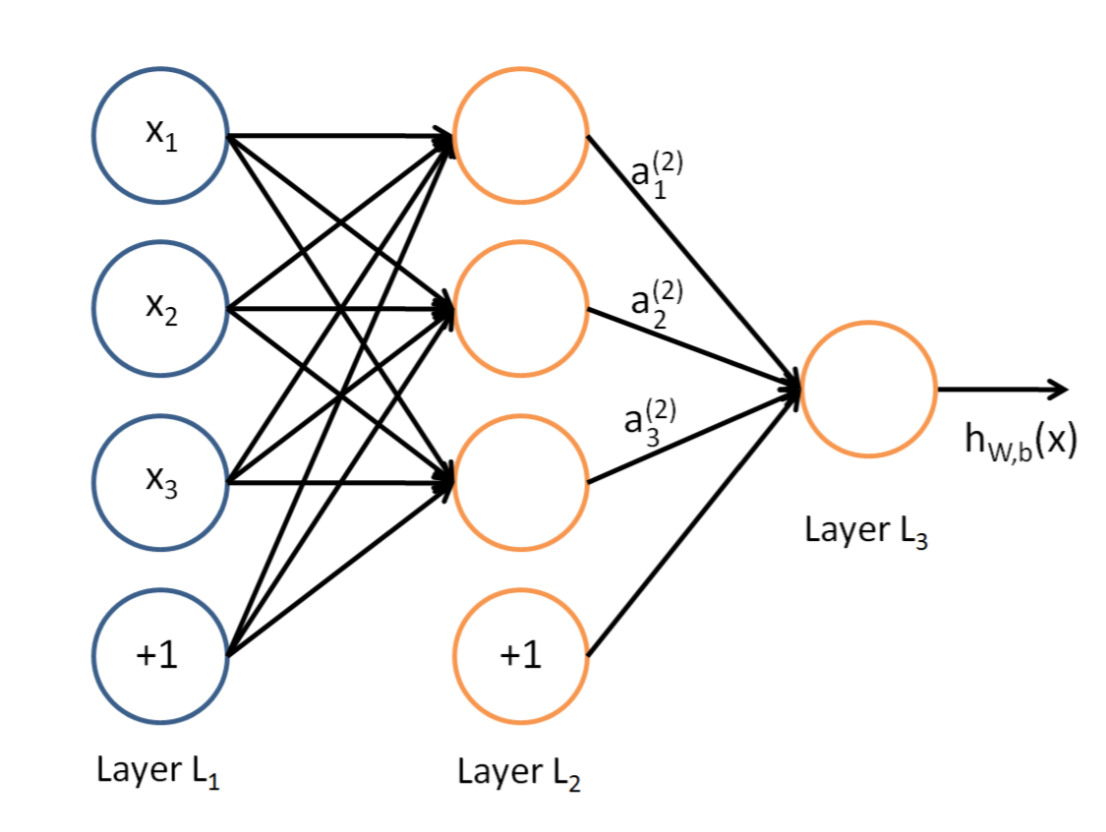
|
||||
|
||||
这是典型的三层神经网络的基本构成,Layer L1是输入层,Layer L2是隐含层,Layer L3是隐含层,我们现在手里有一堆数据{x1,x2,x3,...,xn},输出也是一堆数据{y1,y2,y3,...,yn},现在要他们在隐含层做某种变换,让你把数据灌进去后得到你期望的输出。如果你希望你的输出和原始输入一样,那么就是最常见的自编码模型(Auto-Encoder)。可能有人会问,为什么要输入输出都一样呢?有什么用啊?其实应用挺广的,在图像识别,文本分类等等都会用到,我会专门再写一篇Auto-Encoder的文章来说明,包括一些变种之类的。如果你的输出和原始输入不一样,那么就是很常见的人工神经网络了,相当于让原始数据通过一个映射来得到我们想要的输出数据,也就是我们今天要讲的话题。
|
||||
|
||||
本文直接举一个例子,带入数值演示反向传播法的过程,公式的推导等到下次写Auto-Encoder的时候再写,其实也很简单,感兴趣的同学可以自己推导下试试:)(注:本文假设你已经懂得基本的神经网络构成,如果完全不懂,可以参考Poll写的笔记:[[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html))
|
||||
|
||||
假设,你有这样一个网络层:
|
||||
|
||||
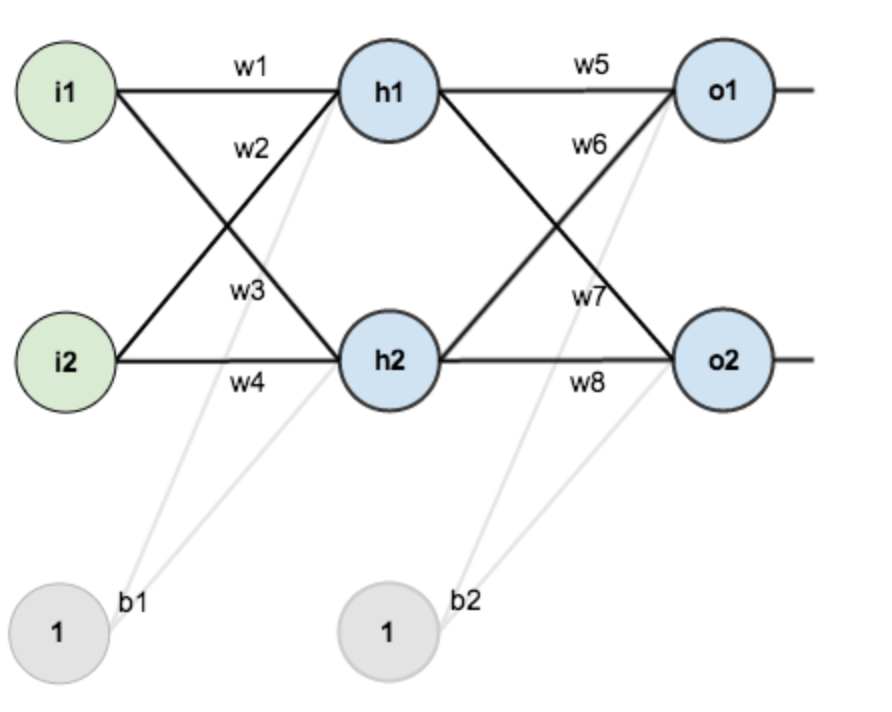
|
||||
|
||||
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项b2,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
|
||||
|
||||
现在对他们赋上初值,如下图:
|
||||
|
||||
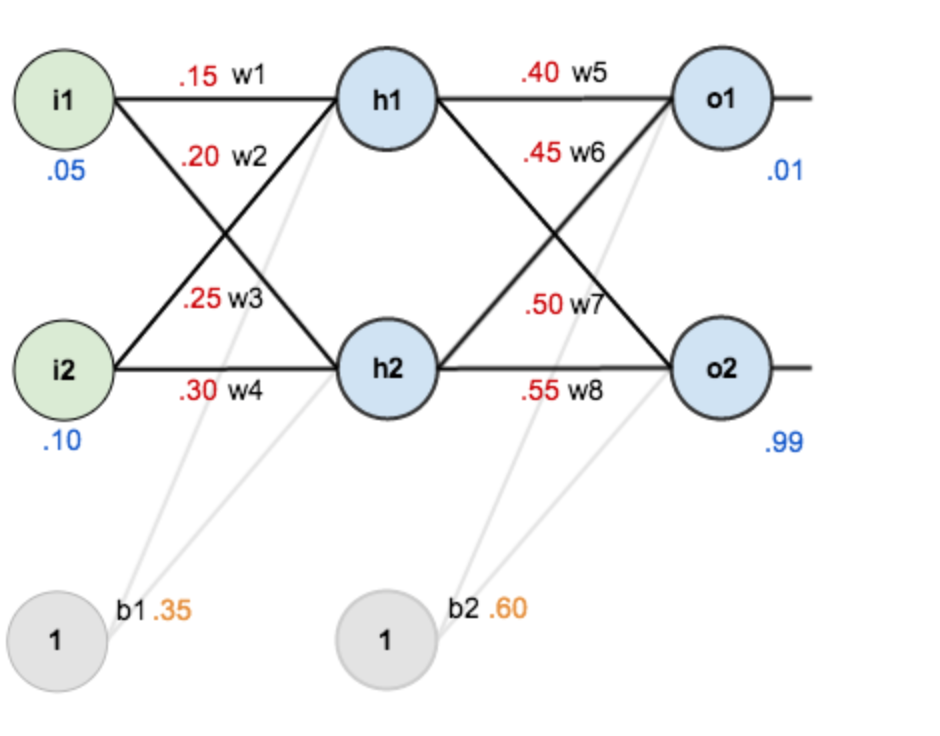
|
||||
|
||||
其中,输入数据 i1=0.05,i2=0.10;
|
||||
|
||||
输出数据 o1=0.01,o2=0.99;
|
||||
|
||||
初始权重 w1=0.15,w2=0.20,w3=0.25,w4=0.30;
|
||||
|
||||
w5=0.40,w6=0.45,w7=0.50,w8=0.55
|
||||
|
||||
目标:给出输入数据i1,i2(0.05和0.10),使输出尽可能与原始输出o1,o2(0.01和0.99)接近。
|
||||
|
||||
**Step 1 前向传播**
|
||||
|
||||
1.输入层---->隐含层:
|
||||
|
||||
计算神经元h1的输入加权和:
|
||||
|
||||
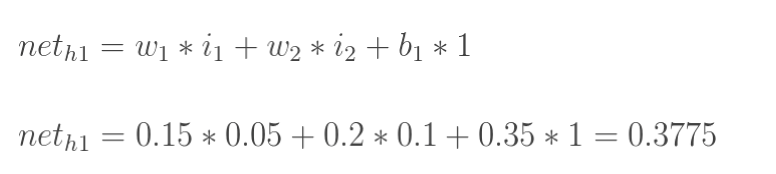
|
||||
|
||||
神经元h1的输出o1:(此处用到激活函数为sigmoid函数):
|
||||
|
||||
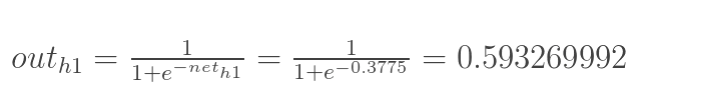
|
||||
|
||||
同理,可计算出神经元h2的输出o2:
|
||||
|
||||
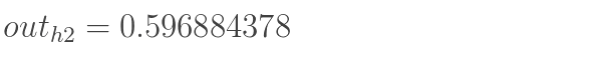
|
||||
|
||||
2.隐含层---->输出层:
|
||||
|
||||
计算输出层神经元o1和o2的值:
|
||||
|
||||
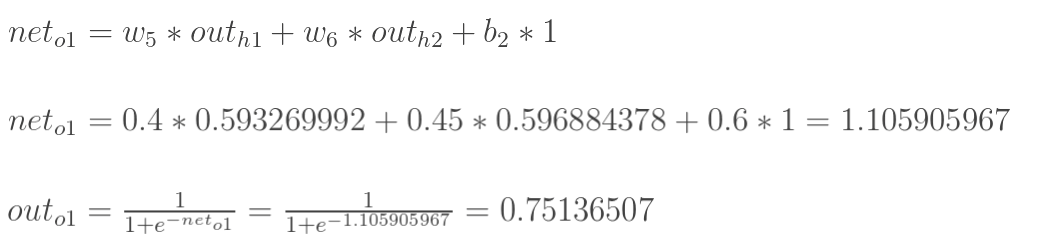
|
||||
|
||||
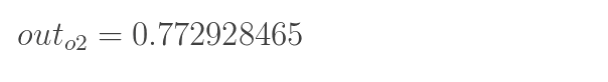
|
||||
|
||||
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
|
||||
|
||||
**Step 2 反向传播**
|
||||
|
||||
1.计算总误差
|
||||
|
||||
总误差:(square error)
|
||||
|
||||
|
||||
|
||||
但是有两个输出,所以分别计算o1和o2的误差,总误差为两者之和:
|
||||
|
||||
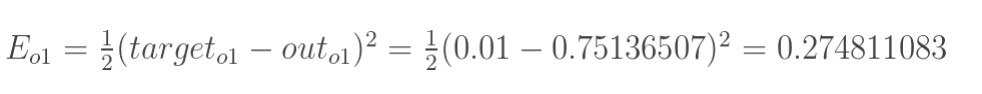
|
||||
|
||||

|
||||
|
||||
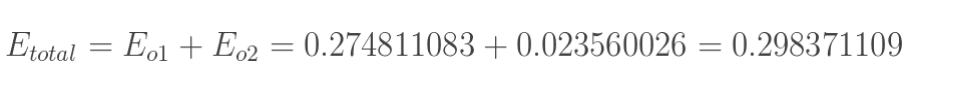
|
||||
|
||||
2.隐含层---->输出层的权值更新:
|
||||
|
||||
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
|
||||
|
||||
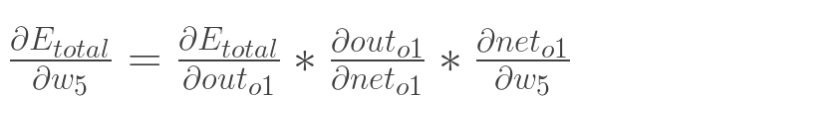
|
||||
|
||||
下面的图可以更直观的看清楚误差是怎样反向传播的:
|
||||
|
||||
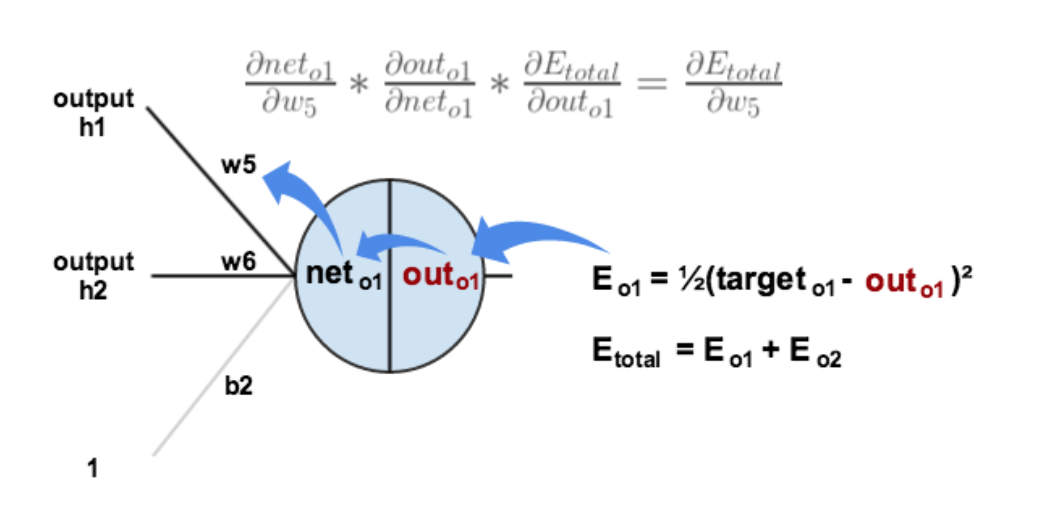
|
||||
|
||||
现在我们来分别计算每个式子的值:
|
||||
|
||||
计算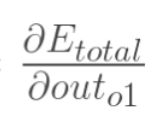:
|
||||
|
||||
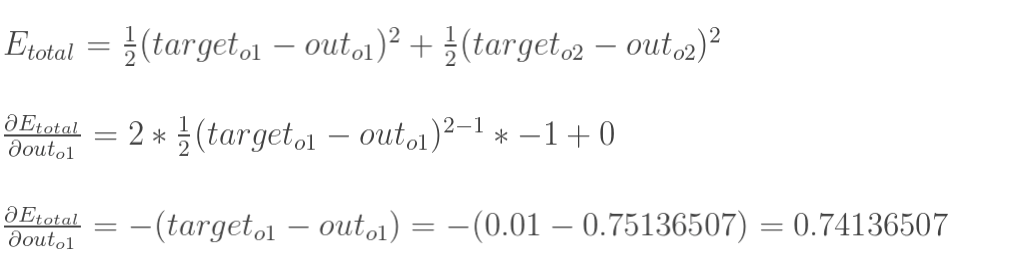
|
||||
|
||||
计算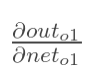:
|
||||
|
||||

|
||||
|
||||
(这一步实际上就是对sigmoid函数求导,比较简单,可以自己推导一下)
|
||||
|
||||
计算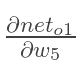:
|
||||
|
||||
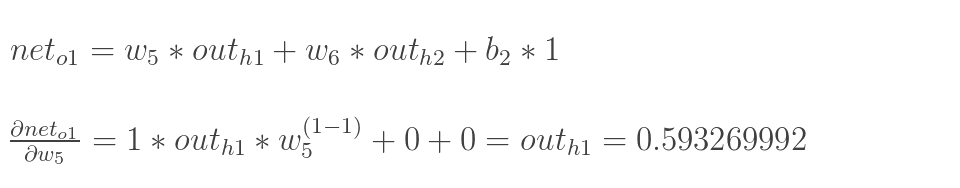
|
||||
|
||||
最后三者相乘:
|
||||
|
||||

|
||||
|
||||
这样我们就计算出整体误差E(total)对w5的偏导值。
|
||||
|
||||
回过头来再看看上面的公式,我们发现:
|
||||
|
||||
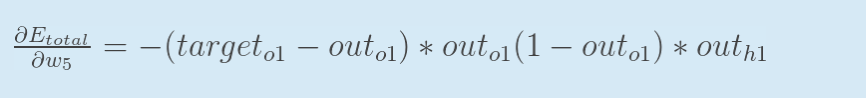
|
||||
|
||||
为了表达方便,用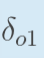来表示输出层的误差:
|
||||
|
||||
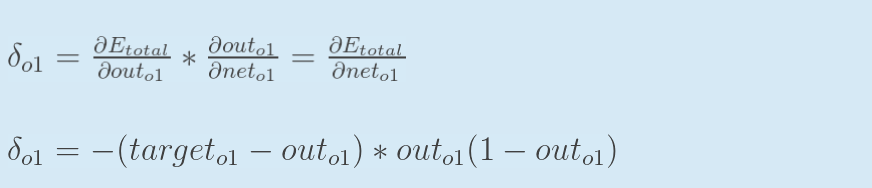
|
||||
|
||||
因此,整体误差E(total)对w5的偏导公式可以写成:
|
||||
|
||||

|
||||
|
||||
如果输出层误差计为负的话,也可以写成:
|
||||
|
||||

|
||||
|
||||
最后我们来更新w5的值:
|
||||
|
||||
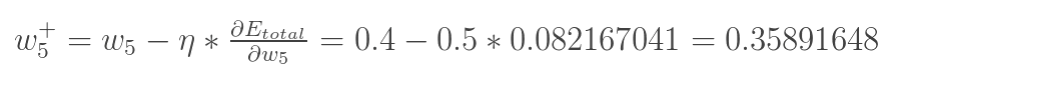
|
||||
|
||||
(其中,是学习速率,这里我们取0.5)
|
||||
|
||||
同理,可更新w6,w7,w8:
|
||||
|
||||

|
||||
|
||||
3.隐含层---->隐含层的权值更新:
|
||||
|
||||
方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
|
||||
|
||||
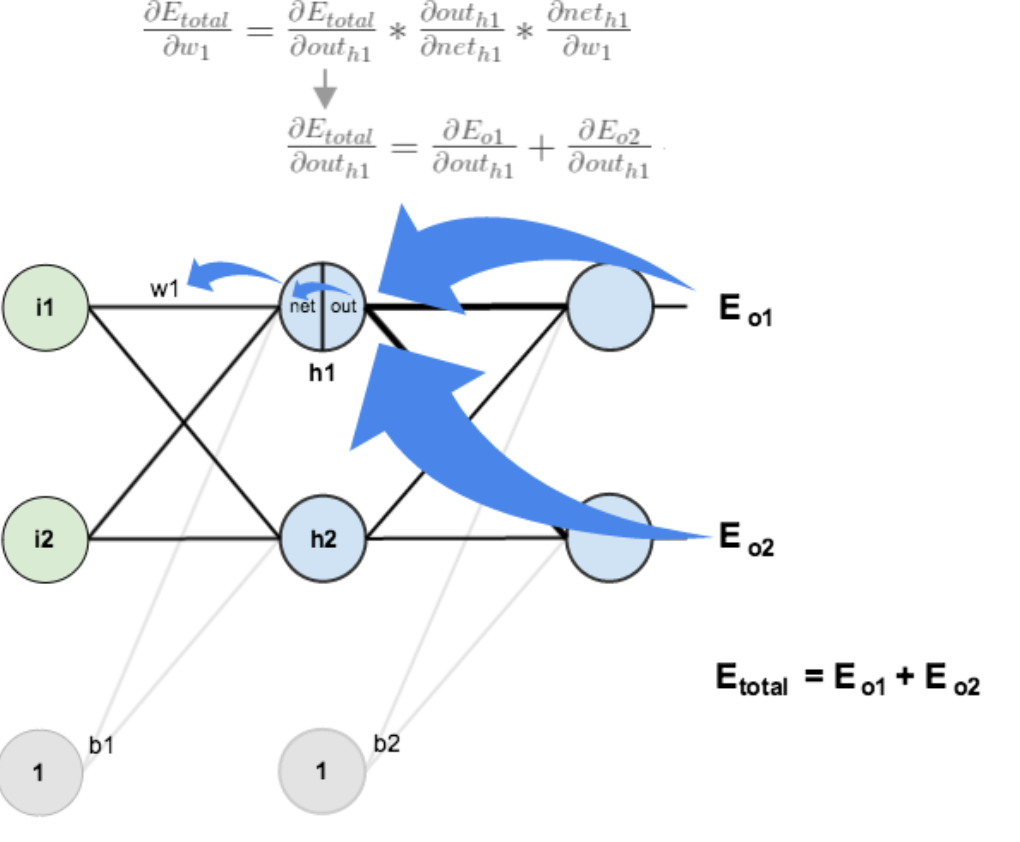
|
||||
|
||||
计算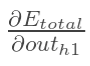:
|
||||
|
||||

|
||||
|
||||
先计算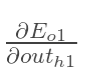:
|
||||
|
||||
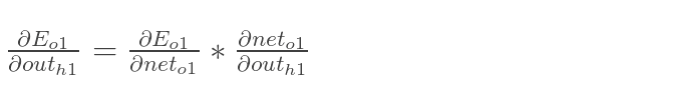
|
||||
|
||||
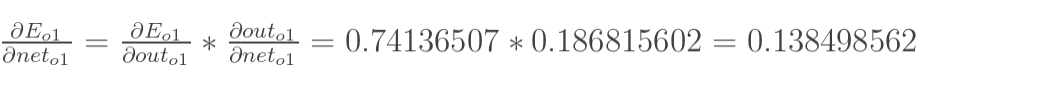
|
||||
|
||||
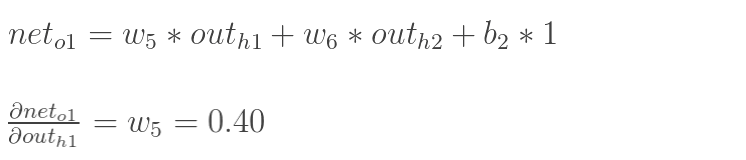
|
||||
|
||||
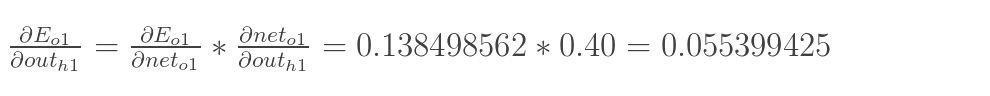
|
||||
|
||||
同理,计算出:
|
||||
|
||||
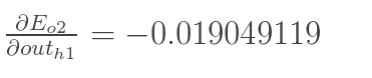
|
||||
|
||||
两者相加得到总值:
|
||||
|
||||
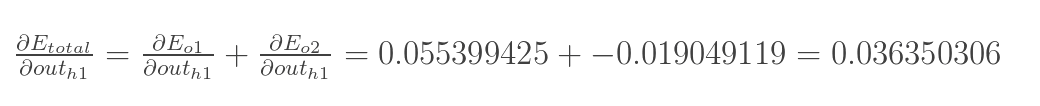
|
||||
|
||||
再计算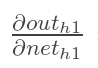:
|
||||
|
||||

|
||||
|
||||
再计算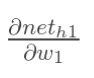:
|
||||
|
||||
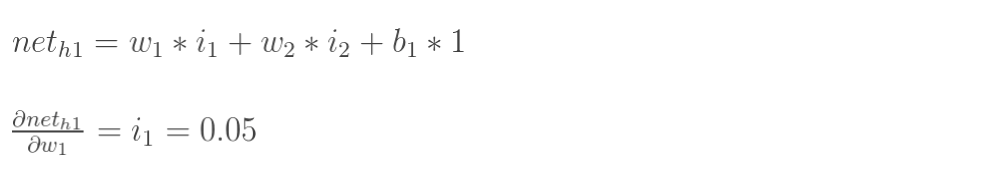
|
||||
|
||||
最后,三者相乘:
|
||||
|
||||

|
||||
|
||||
为了简化公式,用sigma(h1)表示隐含层单元h1的误差:
|
||||
|
||||

|
||||
|
||||
最后,更新w1的权值:
|
||||
|
||||

|
||||
|
||||
同理,额可更新w2,w3,w4的权值:
|
||||
|
||||

|
||||
|
||||
这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734](原输入为[0.01,0.99]),证明效果还是不错的。
|
||||
|
||||
代码(Python):
|
||||
|
||||
|
||||
```python
|
||||
#coding:utf-8
|
||||
import random
|
||||
import math
|
||||
|
||||
#
|
||||
# 参数解释:
|
||||
# "pd_" :偏导的前缀
|
||||
# "d_" :导数的前缀
|
||||
# "w_ho" :隐含层到输出层的权重系数索引
|
||||
# "w_ih" :输入层到隐含层的权重系数的索引
|
||||
|
||||
class NeuralNetwork:
|
||||
LEARNING_RATE = 0.5
|
||||
|
||||
def __init__(self, num_inputs, num_hidden, num_outputs, hidden_layer_weights = None, hidden_layer_bias = None, output_layer_weights = None, output_layer_bias = None):
|
||||
self.num_inputs = num_inputs
|
||||
|
||||
self.hidden_layer = NeuronLayer(num_hidden, hidden_layer_bias)
|
||||
self.output_layer = NeuronLayer(num_outputs, output_layer_bias)
|
||||
|
||||
self.init_weights_from_inputs_to_hidden_layer_neurons(hidden_layer_weights)
|
||||
self.init_weights_from_hidden_layer_neurons_to_output_layer_neurons(output_layer_weights)
|
||||
|
||||
def init_weights_from_inputs_to_hidden_layer_neurons(self, hidden_layer_weights):
|
||||
weight_num = 0
|
||||
for h in range(len(self.hidden_layer.neurons)):
|
||||
for i in range(self.num_inputs):
|
||||
if not hidden_layer_weights:
|
||||
self.hidden_layer.neurons[h].weights.append(random.random())
|
||||
else:
|
||||
self.hidden_layer.neurons[h].weights.append(hidden_layer_weights[weight_num])
|
||||
weight_num += 1
|
||||
|
||||
def init_weights_from_hidden_layer_neurons_to_output_layer_neurons(self, output_layer_weights):
|
||||
weight_num = 0
|
||||
for o in range(len(self.output_layer.neurons)):
|
||||
for h in range(len(self.hidden_layer.neurons)):
|
||||
if not output_layer_weights:
|
||||
self.output_layer.neurons[o].weights.append(random.random())
|
||||
else:
|
||||
self.output_layer.neurons[o].weights.append(output_layer_weights[weight_num])
|
||||
weight_num += 1
|
||||
|
||||
def inspect(self):
|
||||
print('------')
|
||||
print('* Inputs: {}'.format(self.num_inputs))
|
||||
print('------')
|
||||
print('Hidden Layer')
|
||||
self.hidden_layer.inspect()
|
||||
print('------')
|
||||
print('* Output Layer')
|
||||
self.output_layer.inspect()
|
||||
print('------')
|
||||
|
||||
def feed_forward(self, inputs):
|
||||
hidden_layer_outputs = self.hidden_layer.feed_forward(inputs)
|
||||
return self.output_layer.feed_forward(hidden_layer_outputs)
|
||||
|
||||
def train(self, training_inputs, training_outputs):
|
||||
self.feed_forward(training_inputs)
|
||||
|
||||
# 1. 输出神经元的值
|
||||
pd_errors_wrt_output_neuron_total_net_input = [0] * len(self.output_layer.neurons)
|
||||
for o in range(len(self.output_layer.neurons)):
|
||||
|
||||
# ∂E/∂zⱼ
|
||||
pd_errors_wrt_output_neuron_total_net_input[o] = self.output_layer.neurons[o].calculate_pd_error_wrt_total_net_input(training_outputs[o])
|
||||
|
||||
# 2. 隐含层神经元的值
|
||||
pd_errors_wrt_hidden_neuron_total_net_input = [0] * len(self.hidden_layer.neurons)
|
||||
for h in range(len(self.hidden_layer.neurons)):
|
||||
|
||||
# dE/dyⱼ = Σ ∂E/∂zⱼ * ∂z/∂yⱼ = Σ ∂E/∂zⱼ * wᵢⱼ
|
||||
d_error_wrt_hidden_neuron_output = 0
|
||||
for o in range(len(self.output_layer.neurons)):
|
||||
d_error_wrt_hidden_neuron_output += pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].weights[h]
|
||||
|
||||
# ∂E/∂zⱼ = dE/dyⱼ * ∂zⱼ/∂
|
||||
pd_errors_wrt_hidden_neuron_total_net_input[h] = d_error_wrt_hidden_neuron_output * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_input()
|
||||
|
||||
# 3. 更新输出层权重系数
|
||||
for o in range(len(self.output_layer.neurons)):
|
||||
for w_ho in range(len(self.output_layer.neurons[o].weights)):
|
||||
|
||||
# ∂Eⱼ/∂wᵢⱼ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢⱼ
|
||||
pd_error_wrt_weight = pd_errors_wrt_output_neuron_total_net_input[o] * self.output_layer.neurons[o].calculate_pd_total_net_input_wrt_weight(w_ho)
|
||||
|
||||
# Δw = α * ∂Eⱼ/∂wᵢ
|
||||
self.output_layer.neurons[o].weights[w_ho] -= self.LEARNING_RATE * pd_error_wrt_weight
|
||||
|
||||
# 4. 更新隐含层的权重系数
|
||||
for h in range(len(self.hidden_layer.neurons)):
|
||||
for w_ih in range(len(self.hidden_layer.neurons[h].weights)):
|
||||
|
||||
# ∂Eⱼ/∂wᵢ = ∂E/∂zⱼ * ∂zⱼ/∂wᵢ
|
||||
pd_error_wrt_weight = pd_errors_wrt_hidden_neuron_total_net_input[h] * self.hidden_layer.neurons[h].calculate_pd_total_net_input_wrt_weight(w_ih)
|
||||
|
||||
# Δw = α * ∂Eⱼ/∂wᵢ
|
||||
self.hidden_layer.neurons[h].weights[w_ih] -= self.LEARNING_RATE * pd_error_wrt_weight
|
||||
|
||||
def calculate_total_error(self, training_sets):
|
||||
total_error = 0
|
||||
for t in range(len(training_sets)):
|
||||
training_inputs, training_outputs = training_sets[t]
|
||||
self.feed_forward(training_inputs)
|
||||
for o in range(len(training_outputs)):
|
||||
total_error += self.output_layer.neurons[o].calculate_error(training_outputs[o])
|
||||
return total_error
|
||||
|
||||
class NeuronLayer:
|
||||
def __init__(self, num_neurons, bias):
|
||||
|
||||
# 同一层的神经元共享一个截距项b
|
||||
self.bias = bias if bias else random.random()
|
||||
|
||||
self.neurons = []
|
||||
for i in range(num_neurons):
|
||||
self.neurons.append(Neuron(self.bias))
|
||||
|
||||
def inspect(self):
|
||||
print('Neurons:', len(self.neurons))
|
||||
for n in range(len(self.neurons)):
|
||||
print(' Neuron', n)
|
||||
for w in range(len(self.neurons[n].weights)):
|
||||
print(' Weight:', self.neurons[n].weights[w])
|
||||
print(' Bias:', self.bias)
|
||||
|
||||
def feed_forward(self, inputs):
|
||||
outputs = []
|
||||
for neuron in self.neurons:
|
||||
outputs.append(neuron.calculate_output(inputs))
|
||||
return outputs
|
||||
|
||||
def get_outputs(self):
|
||||
outputs = []
|
||||
for neuron in self.neurons:
|
||||
outputs.append(neuron.output)
|
||||
return outputs
|
||||
|
||||
class Neuron:
|
||||
def __init__(self, bias):
|
||||
self.bias = bias
|
||||
self.weights = []
|
||||
|
||||
def calculate_output(self, inputs):
|
||||
self.inputs = inputs
|
||||
self.output = self.squash(self.calculate_total_net_input())
|
||||
return self.output
|
||||
|
||||
def calculate_total_net_input(self):
|
||||
total = 0
|
||||
for i in range(len(self.inputs)):
|
||||
total += self.inputs[i] * self.weights[i]
|
||||
return total + self.bias
|
||||
|
||||
# 激活函数sigmoid
|
||||
def squash(self, total_net_input):
|
||||
return 1 / (1 + math.exp(-total_net_input))
|
||||
|
||||
|
||||
def calculate_pd_error_wrt_total_net_input(self, target_output):
|
||||
return self.calculate_pd_error_wrt_output(target_output) * self.calculate_pd_total_net_input_wrt_input();
|
||||
|
||||
# 每一个神经元的误差是由平方差公式计算的
|
||||
def calculate_error(self, target_output):
|
||||
return 0.5 * (target_output - self.output) ** 2
|
||||
|
||||
|
||||
def calculate_pd_error_wrt_output(self, target_output):
|
||||
return -(target_output - self.output)
|
||||
|
||||
|
||||
def calculate_pd_total_net_input_wrt_input(self):
|
||||
return self.output * (1 - self.output)
|
||||
|
||||
|
||||
def calculate_pd_total_net_input_wrt_weight(self, index):
|
||||
return self.inputs[index]
|
||||
|
||||
|
||||
# 文中的例子:
|
||||
|
||||
nn = NeuralNetwork(2, 2, 2, hidden_layer_weights=[0.15, 0.2, 0.25, 0.3], hidden_layer_bias=0.35, output_layer_weights=[0.4, 0.45, 0.5, 0.55], output_layer_bias=0.6)
|
||||
for i in range(10000):
|
||||
nn.train([0.05, 0.1], [0.01, 0.09])
|
||||
print(i, round(nn.calculate_total_error([[[0.05, 0.1], [0.01, 0.09]]]), 9))
|
||||
|
||||
|
||||
#另外一个例子,可以把上面的例子注释掉再运行一下:
|
||||
|
||||
# training_sets = [
|
||||
# [[0, 0], [0]],
|
||||
# [[0, 1], [1]],
|
||||
# [[1, 0], [1]],
|
||||
# [[1, 1], [0]]
|
||||
# ]
|
||||
|
||||
# nn = NeuralNetwork(len(training_sets[0][0]), 5, len(training_sets[0][1]))
|
||||
# for i in range(10000):
|
||||
# training_inputs, training_outputs = random.choice(training_sets)
|
||||
# nn.train(training_inputs, training_outputs)
|
||||
# print(i, nn.calculate_total_error(training_sets))
|
||||
```
|
||||
|
||||
最后写到这里就结束了,现在还不会用latex编辑数学公式,本来都直接想写在草稿纸上然后扫描了传上来,但是觉得太影响阅读体验了。以后会用公式编辑器后再重把公式重新编辑一遍。稳重使用的是sigmoid激活函数,实际还有几种不同的激活函数可以选择,具体的可以参考文献[3],最后推荐一个在线演示神经网络变化的网址:http://www.emergentmind.com/neural-network,可以自己填输入输出,然后观看每一次迭代权值的变化,很好玩~如果有错误的或者不懂的欢迎留言:)
|
||||
|
||||
参考文献:
|
||||
|
||||
1. Poll的笔记:[[Mechine Learning & Algorithm] 神经网络基础](http://www.cnblogs.com/maybe2030/p/5597716.html)(http://www.cnblogs.com/maybe2030/p/5597716.html#3457159 )
|
||||
2. Rachel_Zhang:http://blog.csdn.net/abcjennifer/article/details/7758797
|
||||
3. http://www.cedar.buffalo.edu/%7Esrihari/CSE574/Chap5/Chap5.3-BackProp.pdf
|
||||
4. https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
|
||||
|
||||
---
|
||||
|
||||
* 作者:Charlotte77
|
||||
* 出处:http://www.cnblogs.com/charlotte77/
|
||||
* 本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
<a href="http://www.apachecn.org"><strong>ApacheCN</strong></a> 一直是一个 崇尚开源,鼓励共享,共同进步,谦(zhuang)虚(bi)包(che)容(dan) 的组织,我们的 github 地址是: https://github.com/apachecn 。组织中的每个成员都是乐于分享的 open source person,也正是因为这个原因,我们才能在人海茫茫的世界中相遇(从最初的网聊,到后边的面基,直到现在每天都会见面...)。
|
||||
|
||||
扯了这么多,我们接下来说正题。。。
|
||||
|
||||
在 2017年2月27日,我们发现,现在的互联网兵家必争之地已经悄悄发生了变化,从原来的 Big Data (大数据)悄悄移到了 AI (人工智能)领域。经过讨论,当机立断定下了进军 AI 的目标,具体讨论细节,请看 <a href="http://cwiki.apachecn.org/pages/viewpage.action?pageId=8159323">2017-02-27 机器学习活动正式启动</a> 。而进军 AI 的首个根据地就是 MachineLearning (机器学习)。既然我们是 ApacheCN ,既然我们崇尚开源,既然我们乐于分享,既然我们...(哪儿那么多既然...),我们何不将我们学习 机器学习 的过程使用视频录制下来,分享出来,以便其他人学习的时候不再踩这些坑。本着这个原则,我们的第一期机器学习活动开始了,随之产生的是我们《机器学习讨论版》(公开到了 <a href="https://space.bilibili.com/97678687/#!/index">bilibili </a>和<a href="http://i.youku.com/apachecn"> youku</a>)。
|
||||
|
||||
《机器学习讨论版》毕竟也是我们刚开始学习 机器学习 的记录视频,很多地方理解不透彻,讲解不是很清楚,但是公开以后同样也吸引了很多人观看,当然也引来了观看视频的人的部分吐槽(ToT....比如,有人吐槽: 你们录视频还磕瓜子 。。。因为这是线下以讨论组的方式聚在一起交流学习的,所以瓜子也要磕,东西也要吃,还要喝饮料呢 。。。)。因为当时录制视频的方式 : 共同讨论和学习的过程,更适合线下交流【线下,偏向交流】,这个也是被网友吐槽最激烈的点。当然也有网友留言,虽然扯淡归扯淡,但是大家在扯淡的过程中将每个算法的原理讲解清楚了(虽然我是不苟言笑的,但是听到这个我还是炒鸡开心 ^_^)。就这样,我们的《机器学习讨论版》录制就慢慢完成了,一次又一次传到视频网站上。。。
|
||||
|
||||
后来(我总算学会了如何去爱),当我们基本把《机器学习实战》整本书都学习完成之后,对机器学习有了更加深刻的了解。基于之前我们的机器学习活动第一期录制的《机器学习讨论版》不够完善,细节讲解不透彻,我们又上路了。。。在2017年07月07日的时候,<a href="http://cwiki.apachecn.org/pages/viewpage.action?pageId=10030404">线下组织学习活动</a>,一起讨论了一下,第二期机器学习视频录制是不是有必要,最后我们得出结论,既然做,我们就要做到最好(管他三七二十一,上去就是一把梭。。。)。首先我们给第二期机器学习视频教程取了一个简单易懂而又不乏帅气的名字——《机器学习教学版》,由于教学版相对第一期视频来说,是更加正式的,我们在讲解视频之前都会进行预演(但是这相当耗费时间,我记得一次光预演就花了 4 个多小时),预演通过之后,才会进行正式的录制。经过我们几个的这段时间的学习和录制,现在《机器学习教学版》已经在各大影院(<a href="http://i.youku.com/apachecn">youku</a>,<a href="https://space.bilibili.com/97678687/#!/index">bilibili</a>,<a href="http://www.acfun.cn/u/12540256.aspx#page=1">AcFun</a>)上线了。。。教学版现在仍在录制过程中,如果哪一天你们找不到我们了,我们一定是躲在某个角落录视频。。。
|
||||
|
||||
等到《机器学习教学版》录制完成之后,我们打算将重点放置在 sklearn 以及更装逼的 deep learning ,tensorFlow 上,既然要装逼,怎么能停下脚步呢?只要低头走路就好了,说不定哪天抬起头就能摸到天了,是吧。。。
|
||||
|
||||
当然我们也知道,想要把这件事情给做好的话,不是说靠一个人就能搞定的。需要更多的朋友,更多爱分享的人,一起来做这么件事情了。
|
||||
|
||||
所以,如果你也有想法的话,赶紧联系我们,一起来装币吧 。。。联系方式在文章的尾巴 。。
|
||||
|
||||
<img class="alignnone size-medium wp-image-90" src="http://www.apachecn.org/wp-content/uploads/2017/08/apachecn-go-far-go-together-768x576-300x225.jpg" alt="" width="300" height="225" />
|
||||
|
||||
QQ : 1042658081(大佬们请私聊我 。。。)
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,47 @@
|
|||
# 线性回归和逻辑回归的 MLE 视角
|
||||
|
||||
## 线性回归
|
||||
|
||||
令 $z = w^T x + b$,得到:
|
||||
|
||||
$y = z + \epsilon, \, \epsilon \sim N(0, \sigma^2)$
|
||||
|
||||
于是:
|
||||
|
||||
$y|x \sim N(z, \sigma^2)$
|
||||
|
||||
为啥是 $y|x$,因为判别模型的输出只能是 $y|x$。
|
||||
|
||||
它的概率密度函数:
|
||||
|
||||
$f_{Y|X}(y)=\frac{1}{\sqrt{2 \pi} \sigma} \exp(\frac{-(y -z)^2}{2\sigma^2}) \\ = A \exp(-B (y - z)^2), \, A, B > 0$
|
||||
|
||||
计算损失函数:
|
||||
|
||||
$L = -\sum_i \log f_{Y|X}(y^{(i)}) \\ = -\sum_i(\log A - B(y^{(i)} - z^{(i)})^2) \\ = B \sum_i(y^{(i)} - z^{(i)})^2 + C$
|
||||
|
||||
所以 $\min L$ 就相当于 $\min (y^{(i)} - z^{(i)})^2$。结果和最小二乘是一样的。
|
||||
|
||||
## 逻辑回归
|
||||
|
||||
令 $z = w^T x + b, a = \sigma(z)$,我们观察到在假设中:
|
||||
|
||||
$P(y=1|x) = a \\ P(y=0|x) = 1 - a$
|
||||
|
||||
也就是说:
|
||||
|
||||
$y|x \sim B(1, a)$
|
||||
|
||||
> 其实任何二分类器的输出都是伯努利分布。因为变量只能取两个值,加起来得一,所以只有一种分布。
|
||||
|
||||
它的概率质量函数(因为是离散分布,只有概率质量函数,不过无所谓):
|
||||
|
||||
$p_{Y|X}(y) = a^y(1-a)^{1-y}$
|
||||
|
||||
然后计算损失函数:
|
||||
|
||||
$L = -\sum_i \log p_{Y|X}(y^{(i)}) \\ = -\sum_i(y^{(i)} \log a^{(i)} + (1-y^{(i)})\log(1-a^{(i)}))$
|
||||
|
||||
和交叉熵是一致的。
|
||||
|
||||
可以看出,在线性回归的场景下,MLE 等价于最小二乘,在逻辑回归的场景下,MLE 等价于交叉熵。但不一定 MLE 在所有模型中都是这样。
|
||||
|
|
@ -0,0 +1,239 @@
|
|||
# 第1章 机器学习基础
|
||||
|
||||

|
||||
|
||||
## 机器学习 概述
|
||||
|
||||
`机器学习(Machine Learning,ML)` 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
|
||||
它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
|
||||
|
||||
1. 海量的数据
|
||||
2. 获取有用的信息
|
||||
|
||||
## 机器学习 研究意义
|
||||
|
||||
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
|
||||
|
||||
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
|
||||
## 机器学习 场景
|
||||
|
||||
* 例如:识别动物猫
|
||||
* 模式识别(官方标准):人们通过大量的经验,得到结论,从而判断它就是猫。
|
||||
* 机器学习(数据学习):人们通过阅读进行学习,观察它会叫、小眼睛、两只耳朵、四条腿、一条尾巴,得到结论,从而判断它就是猫。
|
||||
* 深度学习(深入数据):人们通过深入了解它,发现它会'喵喵'的叫、与同类的猫科动物很类似,得到结论,从而判断它就是猫。(深度学习常用领域:语音识别、图像识别)
|
||||
|
||||
* 模式识别(pattern recognition): 模式识别是最古老的(作为一个术语而言,可以说是很过时的)。
|
||||
* 我们把环境与客体统称为“模式”,识别是对模式的一种认知,是如何让一个计算机程序去做一些看起来很“智能”的事情。
|
||||
* 通过融于智慧和直觉后,通过构建程序,识别一些事物,而不是人,例如: 识别数字。
|
||||
* 机器学习(machine learning): 机器学习是最基础的(当下初创公司和研究实验室的热点领域之一)。
|
||||
* 在90年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。
|
||||
* “机器学习”强调的是,在给计算机程序(或者机器)输入一些数据后,它必须做一些事情,那就是学习这些数据,而这个学习的步骤是明确的。
|
||||
* 机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身性能的学科。
|
||||
* 深度学习(deep learning): 深度学习是非常崭新和有影响力的前沿领域,我们甚至不会去思考-后深度学习时代。
|
||||
* 深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
|
||||
|
||||
* 参考地址:
|
||||
* [深度学习 vs 机器学习 vs 模式识别](http://www.csdn.net/article/2015-03-24/2824301)
|
||||
* [深度学习 百科资料](http://baike.baidu.com/link?url=76P-uA4EBrC3G-I__P1tqeO7eoDS709Kp4wYuHxc7GNkz_xn0NxuAtEohbpey7LUa2zUQLJxvIKUx4bnrEfOmsWLKbDmvG1PCoRkJisMTQka6-QReTrIxdYY3v93f55q)
|
||||
|
||||
|
||||
> 机器学习已应用于多个领域,远远超出大多数人的想象,横跨:计算机科学、工程技术和统计学等多个学科。
|
||||
|
||||
* 搜索引擎: 根据你的搜索点击,优化你下次的搜索结果,是机器学习来帮助搜索引擎判断哪个结果更适合你(也判断哪个广告更适合你)。
|
||||
* 垃圾邮件: 会自动的过滤垃圾广告邮件到垃圾箱内。
|
||||
* 超市优惠券: 你会发现,你在购买小孩子尿布的时候,售货员会赠送你一张优惠券可以兑换6罐啤酒。
|
||||
* 邮局邮寄: 手写软件自动识别寄送贺卡的地址。
|
||||
* 申请贷款: 通过你最近的金融活动信息进行综合评定,决定你是否合格。
|
||||
|
||||
|
||||
## 机器学习 组成
|
||||
|
||||
### 主要任务
|
||||
|
||||
* 分类(classification):将实例数据划分到合适的类别中。
|
||||
* 应用实例:判断网站是否被黑客入侵(二分类 ),手写数字的自动识别(多分类)
|
||||
* 回归(regression):主要用于预测数值型数据。
|
||||
* 应用实例:股票价格波动的预测,房屋价格的预测等。
|
||||
|
||||
### 监督学习(supervised learning)
|
||||
|
||||
* 必须确定目标变量的值,以便机器学习算法可以发现特征和目标变量之间的关系。在监督学习中,给定一组数据,我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系。 (包括:分类和回归)
|
||||
* 样本集:训练数据 + 测试数据
|
||||
* 训练样本 = 特征(feature) + 目标变量(label: 分类-离散值/回归-连续值)
|
||||
* 特征通常是训练样本集的列,它们是独立测量得到的。
|
||||
* 目标变量: 目标变量是机器学习预测算法的测试结果。
|
||||
* 在分类算法中目标变量的类型通常是标称型(如:真与假),而在回归算法中通常是连续型(如:1~100)。
|
||||
* 监督学习需要注意的问题:
|
||||
* 偏置方差权衡
|
||||
* 功能的复杂性和数量的训练数据
|
||||
* 输入空间的维数
|
||||
* 噪声中的输出值
|
||||
* `知识表示`:
|
||||
* 可以采用规则集的形式【例如:数学成绩大于90分为优秀】
|
||||
* 可以采用概率分布的形式【例如:通过统计分布发现,90%的同学数学成绩,在70分以下,那么大于70分定为优秀】
|
||||
* 可以使用训练样本集中的一个实例【例如:通过样本集合,我们训练出一个模型实例,得出 年轻,数学成绩中高等,谈吐优雅,我们认为是优秀】
|
||||
|
||||
### 非监督学习(unsupervised learing)
|
||||
|
||||
* 在机器学习,无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。
|
||||
* 无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。
|
||||
* 数据没有类别信息,也不会给定目标值。
|
||||
* 非监督学习包括的类型:
|
||||
* 聚类:在无监督学习中,将数据集分成由类似的对象组成多个类的过程称为聚类。
|
||||
* 密度估计:通过样本分布的紧密程度,来估计与分组的相似性。
|
||||
* 此外,无监督学习还可以减少数据特征的维度,以便我们可以使用二维或三维图形更加直观地展示数据信息。
|
||||
### 强化学习
|
||||
这个算法可以训练程序做出某一决定。程序在某一情况下尝试所有的可能行动,记录不同行动的结果并试着找出最好的一次尝试来做决定。 属于这一类算法的有马尔可夫决策过程。
|
||||
### 训练过程
|
||||
|
||||
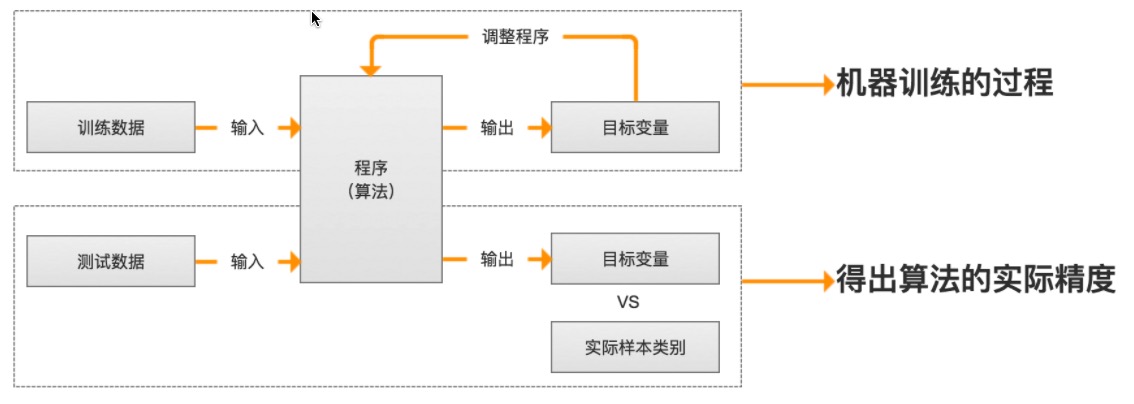
|
||||
|
||||
### 算法汇总
|
||||
|
||||

|
||||
|
||||
|
||||
## 机器学习 使用
|
||||
|
||||
> 选择算法需要考虑的两个问题
|
||||
|
||||
1. 算法场景
|
||||
* 预测明天是否下雨,因为可以用历史的天气情况做预测,所以选择监督学习算法
|
||||
* 给一群陌生的人进行分组,但是我们并没有这些人的类别信息,所以选择无监督学习算法、通过他们身高、体重等特征进行处理。
|
||||
2. 需要收集或分析的数据是什么
|
||||
|
||||
> 举例
|
||||
|
||||
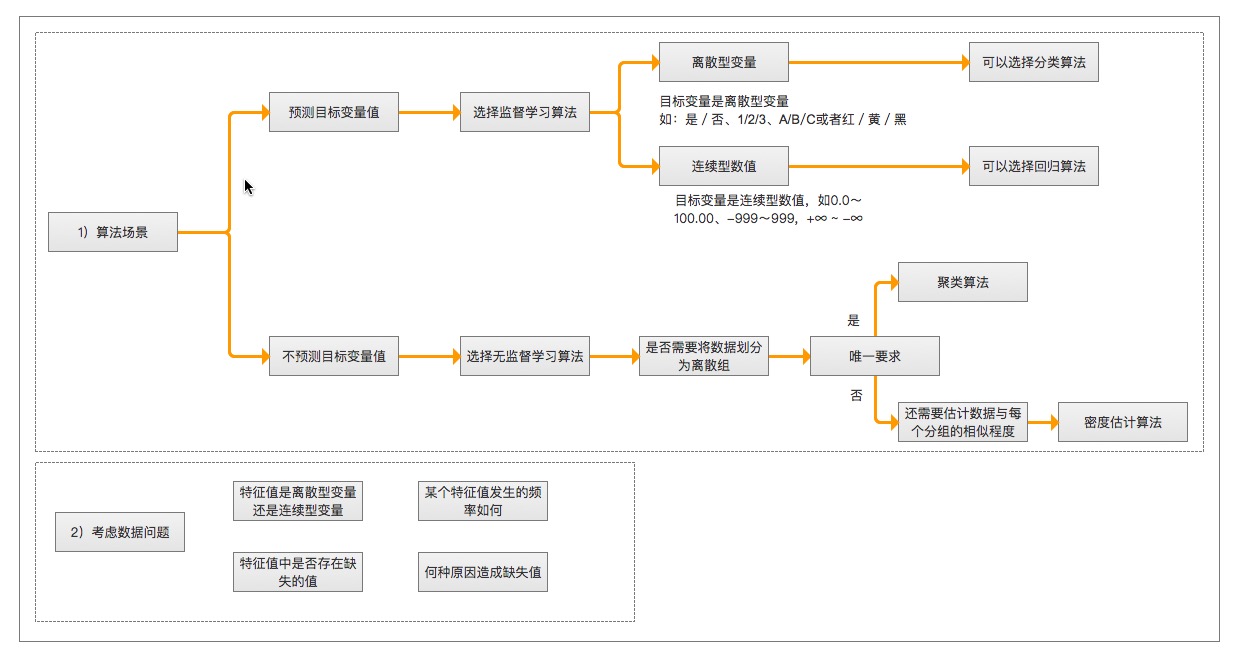
|
||||
|
||||
> 机器学习 开发流程
|
||||
|
||||
|
||||
1. 收集数据: 收集样本数据
|
||||
2. 准备数据: 注意数据的格式
|
||||
3. 分析数据: 为了确保数据集中没有垃圾数据;
|
||||
* 如果是算法可以处理的数据格式或可信任的数据源,则可以跳过该步骤;
|
||||
* 另外该步骤需要人工干预,会降低自动化系统的价值。
|
||||
4. 训练算法: [机器学习算法核心]如果使用无监督学习算法,由于不存在目标变量值,则可以跳过该步骤
|
||||
5. 测试算法: [机器学习算法核心]评估算法效果
|
||||
6. 使用算法: 将机器学习算法转为应用程序
|
||||
|
||||
## 机器学习 数学基础
|
||||
* 微积分
|
||||
* 统计学/概率论
|
||||
* 线性代数
|
||||
## 机器学习 工具
|
||||
|
||||
### Python语言
|
||||
|
||||
1. 可执行伪代码
|
||||
2. Python比较流行:使用广泛、代码范例多、丰富模块库,开发周期短
|
||||
3. Python语言的特色:清晰简练、易于理解
|
||||
4. Python语言的缺点:唯一不足的是性能问题
|
||||
5. Python相关的库
|
||||
* 科学函数库:`SciPy`、`NumPy`(底层语言:C和Fortran)
|
||||
* 绘图工具库:`Matplotlib`
|
||||
* 数据分析库 `Pandas`
|
||||
### 数学工具
|
||||
* Matlab
|
||||
## 附:机器学习专业术语
|
||||
* 模型(model):计算机层面的认知
|
||||
* 学习算法(learning algorithm),从数据中产生模型的方法
|
||||
* 数据集(data set):一组记录的合集
|
||||
* 示例(instance):对于某个对象的描述
|
||||
* 样本(sample):也叫示例
|
||||
* 属性(attribute):对象的某方面表现或特征
|
||||
* 特征(feature):同属性
|
||||
* 属性值(attribute value):属性上的取值
|
||||
* 属性空间(attribute space):属性张成的空间
|
||||
* 样本空间/输入空间(samplespace):同属性空间
|
||||
* 特征向量(feature vector):在属性空间里每个点对应一个坐标向量,把一个示例称作特征向量
|
||||
* 维数(dimensionality):描述样本参数的个数(也就是空间是几维的)
|
||||
* 学习(learning)/训练(training):从数据中学得模型
|
||||
* 训练数据(training data):训练过程中用到的数据
|
||||
* 训练样本(training sample):训练用到的每个样本
|
||||
* 训练集(training set):训练样本组成的集合
|
||||
* 假设(hypothesis):学习模型对应了关于数据的某种潜在规则
|
||||
* 真相(ground-truth):真正存在的潜在规律
|
||||
* 学习器(learner):模型的另一种叫法,把学习算法在给定数据和参数空间的实例化
|
||||
* 预测(prediction):判断一个东西的属性
|
||||
* 标记(label):关于示例的结果信息,比如我是一个“好人”。
|
||||
* 样例(example):拥有标记的示例
|
||||
* 标记空间/输出空间(label space):所有标记的集合
|
||||
* 分类(classification):预测是离散值,比如把人分为好人和坏人之类的学习任务
|
||||
* 回归(regression):预测值是连续值,比如你的好人程度达到了0.9,0.6之类的
|
||||
* 二分类(binary classification):只涉及两个类别的分类任务
|
||||
* 正类(positive class):二分类里的一个
|
||||
* 反类(negative class):二分类里的另外一个
|
||||
* 多分类(multi-class classification):涉及多个类别的分类
|
||||
* 测试(testing):学习到模型之后对样本进行预测的过程
|
||||
* 测试样本(testing sample):被预测的样本
|
||||
* 聚类(clustering):把训练集中的对象分为若干组
|
||||
* 簇(cluster):每一个组叫簇
|
||||
* 监督学习(supervised learning):典范--分类和回归
|
||||
* 无监督学习(unsupervised learning):典范--聚类
|
||||
* 未见示例(unseen instance):“新样本“,没训练过的样本
|
||||
* 泛化(generalization)能力:学得的模型适用于新样本的能力
|
||||
* 分布(distribution):样本空间的全体样本服从的一种规律
|
||||
* 独立同分布(independent and identically distributed,简称i,i,d.):获得的每个样本都是独立地从这个分布上采样获得的。
|
||||
|
||||
## 机器学习基础补充
|
||||
|
||||
### 数据集的划分
|
||||
|
||||
* 训练集(Training set) —— 学习样本数据集,通过匹配一些参数来建立一个模型,主要用来训练模型。类比考研前做的解题大全。
|
||||
* 验证集(validation set) —— 对学习出来的模型,调整模型的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。类比 考研之前做的模拟考试。
|
||||
* 测试集(Test set) —— 测试训练好的模型的分辨能力。类比 考研。这次真的是一考定终身。
|
||||
|
||||
### 模型拟合程度
|
||||
|
||||
* 欠拟合(Underfitting):模型没有很好地捕捉到数据特征,不能够很好地拟合数据,对训练样本的一般性质尚未学好。类比,光看书不做题觉得自己什么都会了,上了考场才知道自己啥都不会。
|
||||
* 过拟合(Overfitting):模型把训练样本学习“太好了”,可能把一些训练样本自身的特性当做了所有潜在样本都有的一般性质,导致泛化能力下降。类比,做课后题全都做对了,超纲题也都认为是考试必考题目,上了考场还是啥都不会。
|
||||
|
||||
通俗来说,欠拟合和过拟合都可以用一句话来说,欠拟合就是:“你太天真了!”,过拟合就是:“你想太多了!”。
|
||||
|
||||
### 常见的模型指标
|
||||
|
||||
* 正确率 —— 提取出的正确信息条数 / 提取出的信息条数
|
||||
* 召回率 —— 提取出的正确信息条数 / 样本中的信息条数
|
||||
* F 值 —— 正确率 * 召回率 * 2 / (正确率 + 召回率)(F值即为正确率和召回率的调和平均值)
|
||||
|
||||
举个例子如下:
|
||||
|
||||
举个例子如下:
|
||||
某池塘有 1400 条鲤鱼,300 只虾,300 只乌龟。现在以捕鲤鱼为目的。撒了一张网,逮住了 700 条鲤鱼,200 只
|
||||
虾, 100 只乌龟。那么这些指标分别如下:
|
||||
正确率 = 700 / (700 + 200 + 100) = 70%
|
||||
召回率 = 700 / 1400 = 50%
|
||||
F 值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
|
||||
|
||||
### 模型
|
||||
|
||||
* 分类问题 —— 说白了就是将一些未知类别的数据分到现在已知的类别中去。比如,根据你的一些信息,判断你是高富帅,还是穷屌丝。评判分类效果好坏的三个指标就是上面介绍的三个指标:正确率,召回率,F值。
|
||||
* 回归问题 —— 对数值型连续随机变量进行预测和建模的监督学习算法。回归往往会通过计算 误差(Error)来确定模型的精确性。
|
||||
* 聚类问题 —— 聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。聚类问题的标准一般基于距离:簇内距离(Intra-cluster Distance) 和 簇间距离(Inter-cluster Distance) 。簇内距离是越小越好,也就是簇内的元素越相似越好;而簇间距离越大越好,也就是说簇间(不同簇)元素越不相同越好。一般的,衡量聚类问题会给出一个结合簇内距离和簇间距离的公式。
|
||||
|
||||
下面这个图可以比较直观地展示出来:
|
||||
|
||||
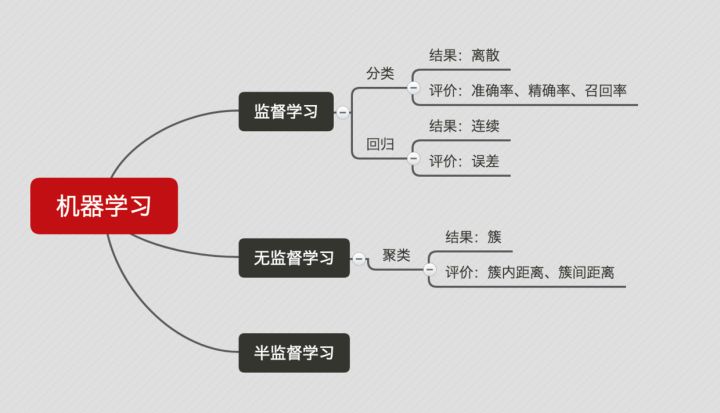
|
||||
|
||||
### 特征工程的一些小东西
|
||||
|
||||
* 特征选择 —— 也叫特征子集选择(FSS,Feature Subset Selection)。是指从已有的 M 个特征(Feature)中选择 N 个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。
|
||||
|
||||
* 特征提取 —— 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点,连续的曲线或者连续的区域。
|
||||
|
||||
下面给出一个特征工程的图:
|
||||
|
||||
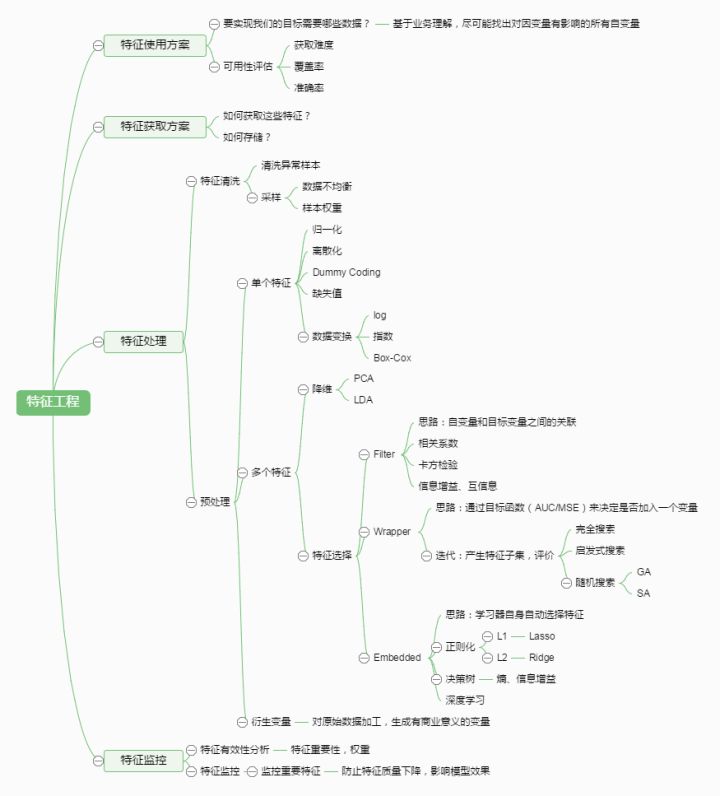
|
||||
|
||||
### 其他
|
||||
|
||||
* Learning rate —— 学习率,通俗地理解,可以理解为步长,步子大了,很容易错过最佳结果。就是本来目标尽在咫尺,可是因为我迈的步子很大,却一下子走过了。步子小了呢,就是同样的距离,我却要走很多很多步,这样导致训练的耗时费力还不讨好。
|
||||
* 一个总结的知识点很棒的链接 :https://zhuanlan.zhihu.com/p/25197792
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,235 @@
|
|||
|
||||
# 第 10 章 K-Means(K-均值)聚类算法
|
||||
|
||||

|
||||
## 聚类
|
||||
聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来说,你并不清楚这个数据集内部有多少种类的动物,你能做的只是利用聚类方法将它自动按照特征分为多类,然后人为给出这个聚类结果的定义(即簇识别)。例如,你将一个动物集分为了三簇(类),然后通过观察这三类动物的特征,你为每一个簇起一个名字,如大象、狗、猫等,这就是聚类的基本思想。
|
||||
|
||||
至于“相似”这一概念,是利用距离这个评价标准来衡量的,我们通过计算对象与对象之间的距离远近来判断它们是否属于同一类别,即是否是同一个簇。至于距离如何计算,科学家们提出了许多种距离的计算方法,其中欧式距离是最为简单和常用的,除此之外还有曼哈顿距离和余弦相似性距离等。
|
||||
|
||||
欧式距离,我想大家再熟悉不过了,但为免有一些基础薄弱的同学,在此再说明一下,它的定义为:
|
||||
对于x点(坐标为(x1,x2,x3,...,xn))和 y点(坐标为(y1,y2,y3,...,yn)),两者的欧式距离为
|
||||

|
||||
在二维平面,它就是我们初中时就学过的两点距离公式
|
||||
|
||||
## K-Means 算法
|
||||
|
||||
K-Means 是发现给定数据集的 K 个簇的聚类算法, 之所以称之为 `K-均值` 是因为它可以发现 K 个不同的簇, 且每个簇的中心采用簇中所含值的均值计算而成.
|
||||
簇个数 K 是用户指定的, 每一个簇通过其质心(centroid), 即簇中所有点的中心来描述.
|
||||
聚类与分类算法的最大区别在于, 分类的目标类别已知, 而聚类的目标类别是未知的.
|
||||
|
||||
**优点**:
|
||||
* 属于无监督学习,无须准备训练集
|
||||
* 原理简单,实现起来较为容易
|
||||
* 结果可解释性较好
|
||||
|
||||
**缺点**:
|
||||
* **需手动设置k值**。 在算法开始预测之前,我们需要手动设置k值,即估计数据大概的类别个数,不合理的k值会使结果缺乏解释性
|
||||
* 可能收敛到局部最小值, 在大规模数据集上收敛较慢
|
||||
* 对于异常点、离群点敏感
|
||||
|
||||
使用数据类型 : 数值型数据
|
||||
|
||||
|
||||
### K-Means 场景
|
||||
kmeans,如前所述,用于数据集内种类属性不明晰,希望能够通过数据挖掘出或自动归类出有相似特点的对象的场景。其商业界的应用场景一般为挖掘出具有相似特点的潜在客户群体以便公司能够重点研究、对症下药。
|
||||
|
||||
例如,在2000年和2004年的美国总统大选中,候选人的得票数比较接近或者说非常接近。任一候选人得到的普选票数的最大百分比为50.7%而最小百分比为47.9% 如果1%的选民将手中的选票投向另外的候选人,那么选举结果就会截然不同。 实际上,如果妥善加以引导与吸引,少部分选民就会转换立场。尽管这类选举者占的比例较低,但当候选人的选票接近时,这些人的立场无疑会对选举结果产生非常大的影响。如何找出这类选民,以及如何在有限的预算下采取措施来吸引他们? 答案就是聚类(Clustering)。
|
||||
|
||||
那么,具体如何实施呢?首先,收集用户的信息,可以同时收集用户满意或不满意的信息,这是因为任何对用户重要的内容都可能影响用户的投票结果。然后,将这些信息输入到某个聚类算法中。接着,对聚类结果中的每一个簇(最好选择最大簇 ), 精心构造能够吸引该簇选民的消息。最后, 开展竞选活动并观察上述做法是否有效。
|
||||
|
||||
另一个例子就是产品部门的市场调研了。为了更好的了解自己的用户,产品部门可以采用聚类的方法得到不同特征的用户群体,然后针对不同的用户群体可以对症下药,为他们提供更加精准有效的服务。
|
||||
|
||||
### K-Means 术语
|
||||
|
||||
* 簇: 所有数据的点集合,簇中的对象是相似的。
|
||||
* 质心: 簇中所有点的中心(计算所有点的均值而来).
|
||||
* SSE: Sum of Sqared Error(误差平方和), 它被用来评估模型的好坏,SSE 值越小,表示越接近它们的质心. 聚类效果越好。由于对误差取了平方,因此更加注重那些远离中心的点(一般为边界点或离群点)。详情见kmeans的评价标准。
|
||||
|
||||
有关 `簇` 和 `质心` 术语更形象的介绍, 请参考下图:
|
||||
|
||||
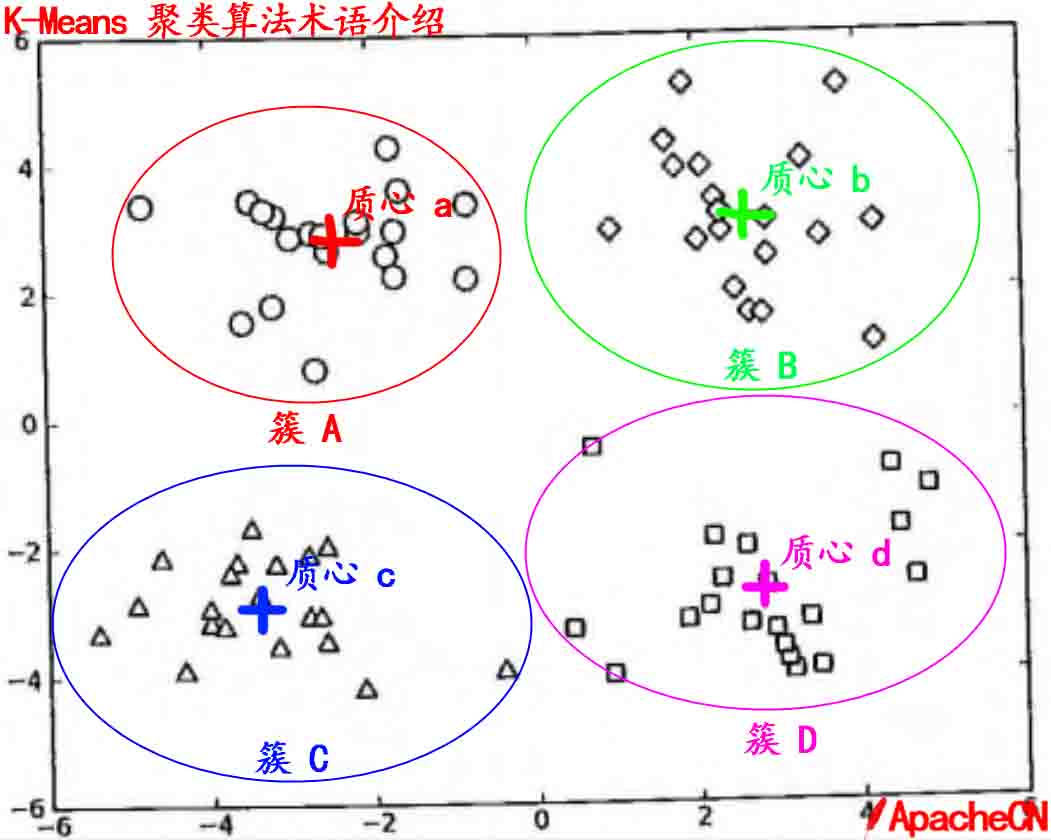
|
||||
|
||||
### K-Means 工作流程
|
||||
1. 首先, 随机确定 K 个初始点作为质心(**不必是数据中的点**)。
|
||||
2. 然后将数据集中的每个点分配到一个簇中, 具体来讲, 就是为每个点找到距其最近的质心, 并将其分配该质心所对应的簇. 这一步完成之后, 每个簇的质心更新为该簇所有点的平均值.
|
||||
3.重复上述过程直到数据集中的所有点都距离它所对应的质心最近时结束。
|
||||
|
||||
上述过程的 `伪代码` 如下:
|
||||
|
||||
* 创建 k 个点作为起始质心(通常是随机选择)
|
||||
* 当任意一个点的簇分配结果发生改变时(不改变时算法结束)
|
||||
* 对数据集中的每个数据点
|
||||
* 对每个质心
|
||||
* 计算质心与数据点之间的距离
|
||||
* 将数据点分配到距其最近的簇
|
||||
* 对每一个簇, 计算簇中所有点的均值并将均值作为质心
|
||||
|
||||
### K-Means 开发流程
|
||||
|
||||
```
|
||||
收集数据:使用任意方法
|
||||
准备数据:需要数值型数据类计算距离, 也可以将标称型数据映射为二值型数据再用于距离计算
|
||||
分析数据:使用任意方法
|
||||
训练算法:不适用于无监督学习,即无监督学习不需要训练步骤
|
||||
测试算法:应用聚类算法、观察结果.可以使用量化的误差指标如误差平方和(后面会介绍)来评价算法的结果.
|
||||
使用算法:可以用于所希望的任何应用.通常情况下, 簇质心可以代表整个簇的数据来做出决策.
|
||||
```
|
||||
### K-Means 的评价标准
|
||||
k-means算法因为手动选取k值和初始化随机质心的缘故,每一次的结果不会完全一样,而且由于手动选取k值,我们需要知道我们选取的k值是否合理,聚类效果好不好,那么如何来评价某一次的聚类效果呢?也许将它们画在图上直接观察是最好的办法,但现实是,我们的数据不会仅仅只有两个特征,一般来说都有十几个特征,而观察十几维的空间对我们来说是一个无法完成的任务。因此,我们需要一个公式来帮助我们判断聚类的性能,这个公式就是**SSE** (Sum of Squared Error, 误差平方和 ),它其实就是每一个点到其簇内质心的距离的平方值的总和,这个数值对应kmeans函数中**clusterAssment**矩阵的第一列之和。 **SSE**值越小表示数据点越接近于它们的质心,聚类效果也越好。 因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低**SSE**值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
|
||||
|
||||
### K-Means 聚类算法函数
|
||||
|
||||
#### 从文件加载数据集
|
||||
|
||||
```python
|
||||
# 从文本中构建矩阵,加载文本文件,然后处理
|
||||
def loadDataSet(fileName): # 通用函数,用来解析以 tab 键分隔的 floats(浮点数),例如: 1.658985 4.285136
|
||||
dataMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
curLine = line.strip().split('\t')
|
||||
fltLine = map(float,curLine) # 映射所有的元素为 float(浮点数)类型
|
||||
dataMat.append(fltLine)
|
||||
return dataMat
|
||||
```
|
||||
|
||||
#### 计算两个向量的欧氏距离
|
||||
|
||||
```python
|
||||
# 计算两个向量的欧式距离(可根据场景选择其他距离公式)
|
||||
def distEclud(vecA, vecB):
|
||||
return sqrt(sum(power(vecA - vecB, 2))) # la.norm(vecA-vecB)
|
||||
```
|
||||
|
||||
#### 构建一个包含 K 个随机质心的集合
|
||||
|
||||
```python
|
||||
# 为给定数据集构建一个包含 k 个随机质心的集合。随机质心必须要在整个数据集的边界之内,这可以通过找到数据集每一维的最小和最大值来完成。然后生成 0~1.0 之间的随机数并通过取值范围和最小值,以便确保随机点在数据的边界之内。
|
||||
def randCent(dataSet, k):
|
||||
n = shape(dataSet)[1] # 列的数量,即数据的特征个数
|
||||
centroids = mat(zeros((k,n))) # 创建k个质心矩阵
|
||||
for j in range(n): # 创建随机簇质心,并且在每一维的边界内
|
||||
minJ = min(dataSet[:,j]) # 最小值
|
||||
rangeJ = float(max(dataSet[:,j]) - minJ) # 范围 = 最大值 - 最小值
|
||||
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1)) # 随机生成,mat为numpy函数,需要在最开始写上 from numpy import *
|
||||
return centroids
|
||||
```
|
||||
|
||||
#### K-Means 聚类算法
|
||||
|
||||
```python
|
||||
# k-means 聚类算法
|
||||
# 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
|
||||
# 这个过程重复数次,直到数据点的簇分配结果不再改变位置。
|
||||
# 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似,也可能会陷入局部最小值)
|
||||
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
|
||||
m = shape(dataSet)[0] # 行数,即数据个数
|
||||
clusterAssment = mat(zeros((m, 2))) # 创建一个与 dataSet 行数一样,但是有两列的矩阵,用来保存簇分配结果
|
||||
centroids = createCent(dataSet, k) # 创建质心,随机k个质心
|
||||
clusterChanged = True
|
||||
while clusterChanged:
|
||||
clusterChanged = False
|
||||
for i in range(m): # 循环每一个数据点并分配到最近的质心中去
|
||||
minDist = inf; minIndex = -1
|
||||
for j in range(k):
|
||||
distJI = distMeas(centroids[j,:],dataSet[i,:]) # 计算数据点到质心的距离
|
||||
if distJI < minDist: # 如果距离比 minDist(最小距离)还小,更新 minDist(最小距离)和最小质心的 index(索引)
|
||||
minDist = distJI; minIndex = j
|
||||
if clusterAssment[i, 0] != minIndex: # 簇分配结果改变
|
||||
clusterChanged = True # 簇改变
|
||||
clusterAssment[i, :] = minIndex,minDist**2 # 更新簇分配结果为最小质心的 index(索引),minDist(最小距离)的平方
|
||||
print centroids
|
||||
for cent in range(k): # 更新质心
|
||||
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A==cent)[0]] # 获取该簇中的所有点
|
||||
centroids[cent,:] = mean(ptsInClust, axis=0) # 将质心修改为簇中所有点的平均值,mean 就是求平均值的
|
||||
return centroids, clusterAssment
|
||||
```
|
||||
|
||||
#### 测试函数
|
||||
1. 测试一下以上的基础函数是否可以如预期运行, 请看: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/10.kmeans/kMeans.py>
|
||||
2. 测试一下 kMeans 函数是否可以如预期运行, 请看: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/10.kmeans/kMeans.py>
|
||||
|
||||
参考运行结果如下:
|
||||
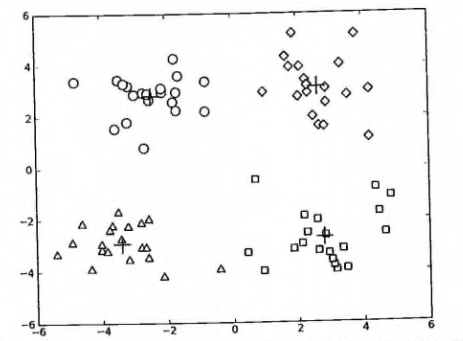
|
||||
|
||||
|
||||
|
||||
### K-Means 聚类算法的缺陷
|
||||
> 在 kMeans 的函数测试中,可能偶尔会陷入局部最小值(局部最优的结果,但不是全局最优的结果).
|
||||
|
||||
局部最小值的的情况如下:
|
||||
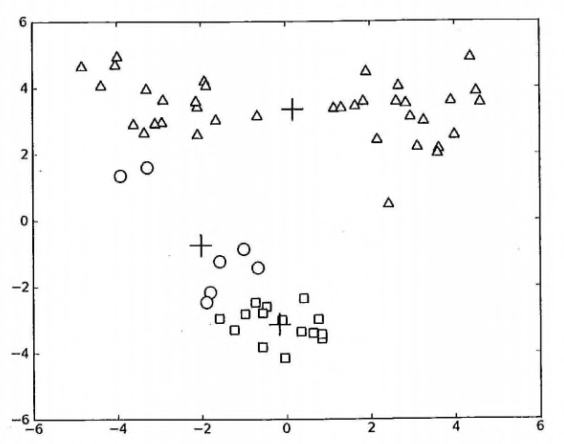
|
||||
出现这个问题有很多原因,可能是k值取的不合适,可能是距离函数不合适,可能是最初随机选取的质心靠的太近,也可能是数据本身分布的问题。
|
||||
|
||||
为了解决这个问题,我们可以对生成的簇进行后处理,一种方法是将具有最大**SSE**值的簇划分成两个簇。具体实现时可以将最大簇包含的点过滤出来并在这些点上运行K-均值算法,令k设为2。
|
||||
|
||||
为了保持簇总数不变,可以将某两个簇进行合并。从上图中很明显就可以看出,应该将上图下部两个出错的簇质心进行合并。那么问题来了,我们可以很容易对二维数据上的聚类进行可视化, 但是如果遇到40维的数据应该如何去做?
|
||||
|
||||
有两种可以量化的办法:合并最近的质心,或者合并两个使得**SSE**增幅最小的质心。 第一种思路通过计算所有质心之间的距离, 然后合并距离最近的两个点来实现。第二种方法需要合并两个簇然后计算总**SSE**值。必须在所有可能的两个簇上重复上述处理过程,直到找到合并最佳的两个簇为止。
|
||||
|
||||
因为上述后处理过程实在是有些繁琐,所以有更厉害的大佬提出了另一个称之为二分K-均值(bisecting K-Means)的算法.
|
||||
|
||||
### 二分 K-Means 聚类算法
|
||||
该算法首先将所有点作为一个簇,然后将该簇一分为二。
|
||||
之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分时候可以最大程度降低 SSE(平方和误差)的值。
|
||||
上述基于 SSE 的划分过程不断重复,直到得到用户指定的簇数目为止。
|
||||
|
||||
#### 二分 K-Means 聚类算法伪代码
|
||||
* 将所有点看成一个簇
|
||||
* 当簇数目小于 k 时
|
||||
* 对于每一个簇
|
||||
* 计算总误差
|
||||
* 在给定的簇上面进行 KMeans 聚类(k=2)
|
||||
* 计算将该簇一分为二之后的总误差
|
||||
* 选择使得误差最小的那个簇进行划分操作
|
||||
|
||||
另一种做法是选择 SSE 最大的簇进行划分,直到簇数目达到用户指定的数目位置。
|
||||
接下来主要介绍该做法的python2代码实现
|
||||
|
||||
#### 二分 K-Means 聚类算法代码
|
||||
|
||||
```python
|
||||
# 二分 KMeans 聚类算法, 基于 kMeans 基础之上的优化,以避免陷入局部最小值
|
||||
def biKMeans(dataSet, k, distMeas=distEclud):
|
||||
m = shape(dataSet)[0]
|
||||
clusterAssment = mat(zeros((m,2))) # 保存每个数据点的簇分配结果和平方误差
|
||||
centroid0 = mean(dataSet, axis=0).tolist()[0] # 质心初始化为所有数据点的均值
|
||||
centList =[centroid0] # 初始化只有 1 个质心的 list
|
||||
for j in range(m): # 计算所有数据点到初始质心的距离平方误差
|
||||
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
|
||||
while (len(centList) < k): # 当质心数量小于 k 时
|
||||
lowestSSE = inf
|
||||
for i in range(len(centList)): # 对每一个质心
|
||||
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:] # 获取当前簇 i 下的所有数据点
|
||||
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas) # 将当前簇 i 进行二分 kMeans 处理
|
||||
sseSplit = sum(splitClustAss[:,1]) # 将二分 kMeans 结果中的平方和的距离进行求和
|
||||
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1]) # 将未参与二分 kMeans 分配结果中的平方和的距离进行求和
|
||||
print "sseSplit, and notSplit: ",sseSplit,sseNotSplit
|
||||
if (sseSplit + sseNotSplit) < lowestSSE: # 总的(未拆分和已拆分)误差和越小,越相似,效果越优化,划分的结果更好(注意:这里的理解很重要,不明白的地方可以和我们一起讨论)
|
||||
bestCentToSplit = i
|
||||
bestNewCents = centroidMat
|
||||
bestClustAss = splitClustAss.copy()
|
||||
lowestSSE = sseSplit + sseNotSplit
|
||||
# 找出最好的簇分配结果
|
||||
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) # 调用二分 kMeans 的结果,默认簇是 0,1. 当然也可以改成其它的数字
|
||||
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit # 更新为最佳质心
|
||||
print 'the bestCentToSplit is: ',bestCentToSplit
|
||||
print 'the len of bestClustAss is: ', len(bestClustAss)
|
||||
# 更新质心列表
|
||||
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0] # 更新原质心 list 中的第 i 个质心为使用二分 kMeans 后 bestNewCents 的第一个质心
|
||||
centList.append(bestNewCents[1,:].tolist()[0]) # 添加 bestNewCents 的第二个质心
|
||||
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss # 重新分配最好簇下的数据(质心)以及SSE
|
||||
return mat(centList), clusterAssment
|
||||
```
|
||||
|
||||
#### 测试二分 KMeans 聚类算法
|
||||
* 测试一下二分 KMeans 聚类算法,请看: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/10.kmeans/kMeans.py>
|
||||
|
||||
上述函数可以运行多次,聚类会收敛到全局最小值,而原始的 kMeans() 函数偶尔会陷入局部最小值。
|
||||
运行参考结果如下:
|
||||
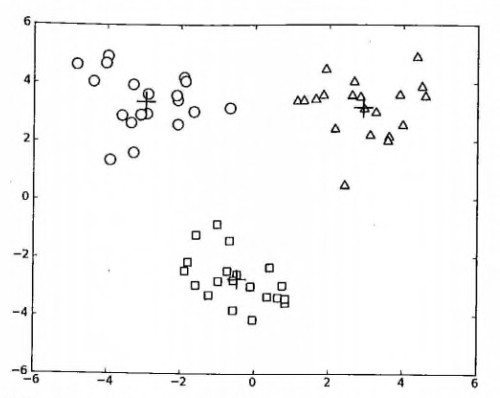
|
||||
|
||||
* **作者:[那伊抹微笑](http://cwiki.apachecn.org/display/~xuxin), [清都江水郎](http://cwiki.apachecn.org/display/~xuzhaoqing)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,396 @@
|
|||
|
||||
# 第 11 章 使用 Apriori 算法进行关联分析
|
||||
|
||||

|
||||
|
||||
## 关联分析
|
||||
关联分析是一种在大规模数据集中寻找有趣关系的任务。
|
||||
这些关系可以有两种形式:
|
||||
* 频繁项集(frequent item sets): 经常出现在一块的物品的集合。
|
||||
* 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。
|
||||
|
||||
## 相关术语
|
||||
* 关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 `关联分析(associati analysis)` 或者 `关联规则学习(association rule learning)` 。
|
||||
下面是用一个 `杂货店` 例子来说明这两个概念,如下图所示:
|
||||

|
||||
|
||||
* 频繁项集: {葡萄酒, 尿布, 豆奶} 就是一个频繁项集的例子。
|
||||
* 关联规则: 尿布 -> 葡萄酒 就是一个关联规则。这意味着如果顾客买了尿布,那么他很可能会买葡萄酒。
|
||||
|
||||
那么 `频繁` 的定义是什么呢?怎么样才算频繁呢?
|
||||
度量它们的方法有很多种,这里我们来简单的介绍下支持度和可信度。
|
||||
* 支持度: 数据集中包含该项集的记录所占的比例。例如上图中,{豆奶} 的支持度为 4/5。{豆奶, 尿布} 的支持度为 3/5。
|
||||
* 可信度: 针对一条诸如 {尿布} -> {葡萄酒} 这样具体的关联规则来定义的。这条规则的 `可信度` 被定义为 `支持度({尿布, 葡萄酒})/支持度({尿布})`,从图中可以看出 支持度({尿布, 葡萄酒}) = 3/5,支持度({尿布}) = 4/5,所以 {尿布} -> {葡萄酒} 的可信度 = 3/5 / 4/5 = 3/4 = 0.75。
|
||||
|
||||
`支持度` 和 `可信度` 是用来量化 `关联分析` 是否成功的一个方法。
|
||||
假设想找到支持度大于 0.8 的所有项集,应该如何去做呢?
|
||||
一个办法是生成一个物品所有可能组合的清单,然后对每一种组合统计它出现的频繁程度,但是当物品成千上万时,上述做法就非常非常慢了。
|
||||
我们需要详细分析下这种情况并讨论下 Apriori 原理,该原理会减少关联规则学习时所需的计算量。
|
||||
|
||||
## Apriori 原理
|
||||
|
||||
假设我们一共有 4 个商品: 商品0, 商品1, 商品2, 商品3。
|
||||
所有可能的情况如下:
|
||||
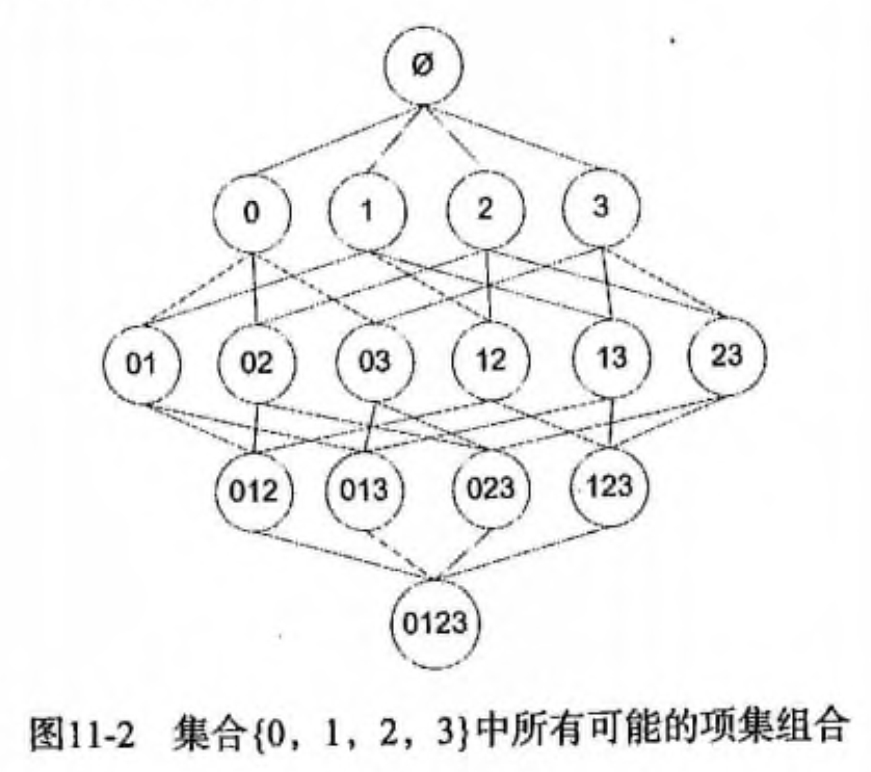
|
||||
如果我们计算所有组合的支持度,也需要计算 15 次。即 2^N - 1 = 2^4 - 1 = 15。
|
||||
随着物品的增加,计算的次数呈指数的形式增长 ...
|
||||
为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。
|
||||
例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。
|
||||
该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 `非频繁项集`,那么它的所有超集也是非频繁项集,如下图所示:
|
||||
|
||||
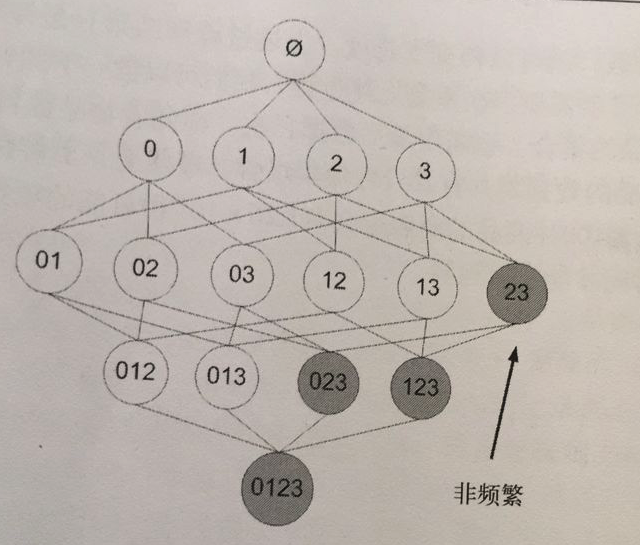
|
||||
|
||||
在图中我们可以看到,已知灰色部分 {2,3} 是 `非频繁项集`,那么利用上面的知识,我们就可以知道 {0,2,3} {1,2,3} {0,1,2,3} 都是 `非频繁的`。
|
||||
也就是说,计算出 {2,3} 的支持度,知道它是 `非频繁` 的之后,就不需要再计算 {0,2,3} {1,2,3} {0,1,2,3} 的支持度,因为我们知道这些集合不会满足我们的要求。
|
||||
使用该原理就可以避免项集数目的指数增长,从而在合理的时间内计算出频繁项集。
|
||||
|
||||
Apriori 算法优缺点
|
||||
|
||||
```
|
||||
* 优点:易编码实现
|
||||
* 缺点:在大数据集上可能较慢
|
||||
* 适用数据类型:数值型 或者 标称型数据。
|
||||
```
|
||||
|
||||
Apriori 算法流程步骤:
|
||||
|
||||
```
|
||||
* 收集数据:使用任意方法。
|
||||
* 准备数据:任何数据类型都可以,因为我们只保存集合。
|
||||
* 分析数据:使用任意方法。
|
||||
* 训练数据:使用Apiori算法来找到频繁项集。
|
||||
* 测试算法:不需要测试过程。
|
||||
* 使用算法:用于发现频繁项集以及物品之间的关联规则。
|
||||
```
|
||||
|
||||
## Apriori 算法的使用
|
||||
前面提到,关联分析的目标包括两项: 发现 `频繁项集` 和发现 `关联规则`。
|
||||
首先需要找到 `频繁项集`,然后才能发现 `关联规则`。
|
||||
`Apriori` 算法是发现 `频繁项集` 的一种方法。
|
||||
Apriori 算法的两个输入参数分别是最小支持度和数据集。
|
||||
该算法首先会生成所有单个物品的项集列表。
|
||||
接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度要求的集合会被去掉。
|
||||
燃尽后对生下来的集合进行组合以声场包含两个元素的项集。
|
||||
接下来再重新扫描交易记录,去掉不满足最小支持度的项集。
|
||||
该过程重复进行直到所有项集被去掉。
|
||||
|
||||
### 生成候选项集
|
||||
|
||||
下面会创建一个用于构建初始集合的函数,也会创建一个通过扫描数据集以寻找交易记录子集的函数,
|
||||
数据扫描的伪代码如下:
|
||||
* 对数据集中的每条交易记录 tran
|
||||
* 对每个候选项集 can
|
||||
* 检查一下 can 是否是 tran 的子集: 如果是则增加 can 的计数值
|
||||
* 对每个候选项集
|
||||
* 如果其支持度不低于最小值,则保留该项集
|
||||
* 返回所有频繁项集列表
|
||||
以下是一些辅助函数。
|
||||
|
||||
#### 加载数据集
|
||||
|
||||
```python
|
||||
# 加载数据集
|
||||
def loadDataSet():
|
||||
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
|
||||
```
|
||||
|
||||
#### 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
|
||||
|
||||
```python
|
||||
# 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
|
||||
def createC1(dataSet):
|
||||
"""createC1(创建集合 C1)
|
||||
|
||||
Args:
|
||||
dataSet 原始数据集
|
||||
Returns:
|
||||
frozenset 返回一个 frozenset 格式的 list
|
||||
"""
|
||||
|
||||
C1 = []
|
||||
for transaction in dataSet:
|
||||
for item in transaction:
|
||||
if not [item] in C1:
|
||||
# 遍历所有的元素,如果不在 C1 出现过,那么就 append
|
||||
C1.append([item])
|
||||
# 对数组进行 `从小到大` 的排序
|
||||
print 'sort 前=', C1
|
||||
C1.sort()
|
||||
# frozenset 表示冻结的 set 集合,元素无改变;可以把它当字典的 key 来使用
|
||||
print 'sort 后=', C1
|
||||
print 'frozenset=', map(frozenset, C1)
|
||||
return map(frozenset, C1)
|
||||
```
|
||||
|
||||
#### 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
|
||||
|
||||
```python
|
||||
# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
|
||||
def scanD(D, Ck, minSupport):
|
||||
"""scanD(计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度 minSupport 的数据)
|
||||
|
||||
Args:
|
||||
D 数据集
|
||||
Ck 候选项集列表
|
||||
minSupport 最小支持度
|
||||
Returns:
|
||||
retList 支持度大于 minSupport 的集合
|
||||
supportData 候选项集支持度数据
|
||||
"""
|
||||
|
||||
# ssCnt 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8
|
||||
ssCnt = {}
|
||||
for tid in D:
|
||||
for can in Ck:
|
||||
# s.issubset(t) 测试是否 s 中的每一个元素都在 t 中
|
||||
if can.issubset(tid):
|
||||
if not ssCnt.has_key(can):
|
||||
ssCnt[can] = 1
|
||||
else:
|
||||
ssCnt[can] += 1
|
||||
numItems = float(len(D)) # 数据集 D 的数量
|
||||
retList = []
|
||||
supportData = {}
|
||||
for key in ssCnt:
|
||||
# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量
|
||||
support = ssCnt[key]/numItems
|
||||
if support >= minSupport:
|
||||
# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值
|
||||
retList.insert(0, key)
|
||||
# 存储所有的候选项(key)和对应的支持度(support)
|
||||
supportData[key] = support
|
||||
return retList, supportData
|
||||
```
|
||||
|
||||
完整代码地址: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/11.Apriori/apriori.py>
|
||||
|
||||
### 组织完整的 Apriori 算法
|
||||
|
||||
#### 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
|
||||
|
||||
```python
|
||||
# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
|
||||
def aprioriGen(Lk, k):
|
||||
"""aprioriGen(输入频繁项集列表 Lk 与返回的元素个数 k,然后输出候选项集 Ck。
|
||||
例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
|
||||
仅需要计算一次,不需要将所有的结果计算出来,然后进行去重操作
|
||||
这是一个更高效的算法)
|
||||
|
||||
Args:
|
||||
Lk 频繁项集列表
|
||||
k 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)
|
||||
Returns:
|
||||
retList 元素两两合并的数据集
|
||||
"""
|
||||
|
||||
retList = []
|
||||
lenLk = len(Lk)
|
||||
for i in range(lenLk):
|
||||
for j in range(i+1, lenLk):
|
||||
L1 = list(Lk[i])[: k-2]
|
||||
L2 = list(Lk[j])[: k-2]
|
||||
# print '-----i=', i, k-2, Lk, Lk[i], list(Lk[i])[: k-2]
|
||||
# print '-----j=', j, k-2, Lk, Lk[j], list(Lk[j])[: k-2]
|
||||
L1.sort()
|
||||
L2.sort()
|
||||
# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集
|
||||
# if first k-2 elements are equal
|
||||
if L1 == L2:
|
||||
# set union
|
||||
# print 'union=', Lk[i] | Lk[j], Lk[i], Lk[j]
|
||||
retList.append(Lk[i] | Lk[j])
|
||||
return retList
|
||||
```
|
||||
|
||||
#### 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
|
||||
|
||||
```python
|
||||
# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
|
||||
def apriori(dataSet, minSupport=0.5):
|
||||
"""apriori(首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)
|
||||
|
||||
Args:
|
||||
dataSet 原始数据集
|
||||
minSupport 支持度的阈值
|
||||
Returns:
|
||||
L 频繁项集的全集
|
||||
supportData 所有元素和支持度的全集
|
||||
"""
|
||||
# C1 即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
|
||||
C1 = createC1(dataSet)
|
||||
# 对每一行进行 set 转换,然后存放到集合中
|
||||
D = map(set, dataSet)
|
||||
print 'D=', D
|
||||
# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
|
||||
L1, supportData = scanD(D, C1, minSupport)
|
||||
# print "L1=", L1, "\n", "outcome: ", supportData
|
||||
|
||||
# L 加了一层 list, L 一共 2 层 list
|
||||
L = [L1]
|
||||
k = 2
|
||||
# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1
|
||||
while (len(L[k-2]) > 0):
|
||||
print 'k=', k, L, L[k-2]
|
||||
Ck = aprioriGen(L[k-2], k) # 例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
|
||||
print 'Ck', Ck
|
||||
|
||||
Lk, supK = scanD(D, Ck, minSupport) # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
|
||||
# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
|
||||
supportData.update(supK)
|
||||
if len(Lk) == 0:
|
||||
break
|
||||
# Lk 表示满足频繁子项的集合,L 元素在增加,例如:
|
||||
# l=[[set(1), set(2), set(3)]]
|
||||
# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]
|
||||
L.append(Lk)
|
||||
k += 1
|
||||
# print 'k=', k, len(L[k-2])
|
||||
return L, supportData
|
||||
```
|
||||
|
||||
到这一步,我们就找出我们所需要的 `频繁项集` 和他们的 `支持度` 了,接下来再找出关联规则即可!
|
||||
|
||||
完整代码地址: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/11.Apriori/apriori.py>
|
||||
|
||||
## 从频繁项集中挖掘关联规则
|
||||
|
||||
前面我们介绍了用于发现 `频繁项集` 的 Apriori 算法,现在要解决的问题是如何找出 `关联规则`。
|
||||
|
||||
要找到 `关联规则`,我们首先从一个 `频繁项集` 开始。
|
||||
我们知道集合中的元素是不重复的,但我们想知道基于这些元素能否获得其它内容。
|
||||
某个元素或某个元素集合可能会推导出另一个元素。
|
||||
从先前 `杂货店` 的例子可以得到,如果有一个频繁项集 {豆奶,莴苣},那么就可能有一条关联规则 “豆奶 -> 莴苣”。
|
||||
这意味着如果有人买了豆奶,那么在统计上他会购买莴苣的概率比较大。
|
||||
但是,这一条件反过来并不总是成立。
|
||||
也就是说 “豆奶 -> 莴苣” 统计上显著,那么 “莴苣 -> 豆奶” 也不一定成立。
|
||||
|
||||
前面我们给出了 `频繁项集` 的量化定义,即它满足最小支持度要求。
|
||||
对于 `关联规则`,我们也有类似的量化方法,这种量化指标称之为 `可信度`。
|
||||
一条规则 A -> B 的可信度定义为 support(A | B) / support(A)。(注意: 在 python 中 | 表示集合的并操作,而数学书集合并的符号是 U)。
|
||||
`A | B` 是指所有出现在集合 A 或者集合 B 中的元素。
|
||||
由于我们先前已经计算出所有 `频繁项集` 的支持度了,现在我们要做的只不过是提取这些数据做一次除法运算即可。
|
||||
|
||||
### 一个频繁项集可以产生多少条关联规则呢?
|
||||
如下图所示,给出的是项集 {0,1,2,3} 产生的所有关联规则:
|
||||
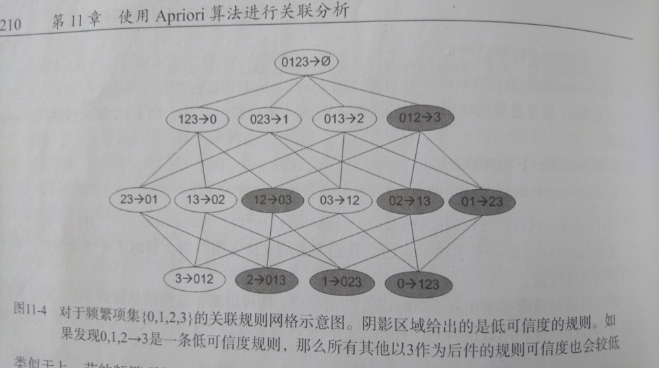
|
||||
与我们前面的 `频繁项集` 生成一样,我们可以为每个频繁项集产生许多关联规则。
|
||||
如果能减少规则的数目来确保问题的可解析,那么计算起来就会好很多。
|
||||
通过观察,我们可以知道,如果某条规则并不满足 `最小可信度` 要求,那么该规则的所有子集也不会满足 `最小可信度` 的要求。
|
||||
如上图所示,假设 `123 -> 3` 并不满足最小可信度要求,那么就知道任何左部为 {0,1,2} 子集的规则也不会满足 `最小可信度` 的要求。
|
||||
即 `12 -> 03` , `02 -> 13` , `01 -> 23` , `2 -> 013`, ` 1 -> 023`, `0 -> 123` 都不满足 `最小可信度` 要求。
|
||||
|
||||
可以利用关联规则的上述性质属性来减少需要测试的规则数目,跟先前 Apriori 算法的套路一样。
|
||||
以下是一些辅助函数:
|
||||
|
||||
#### 计算可信度
|
||||
|
||||
```python
|
||||
# 计算可信度(confidence)
|
||||
def calcConf(freqSet, H
|
||||
, supportData, brl, minConf=0.7):
|
||||
"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
|
||||
|
||||
Args:
|
||||
freqSet 频繁项集中的元素,例如: frozenset([1, 3])
|
||||
H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
|
||||
supportData 所有元素的支持度的字典
|
||||
brl 关联规则列表的空数组
|
||||
minConf 最小可信度
|
||||
Returns:
|
||||
prunedH 记录 可信度大于阈值的集合
|
||||
"""
|
||||
# 记录可信度大于最小可信度(minConf)的集合
|
||||
prunedH = []
|
||||
for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度
|
||||
|
||||
# print 'confData=', freqSet, H, conseq, freqSet-conseq
|
||||
conf = supportData[freqSet]/supportData[freqSet-conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]
|
||||
if conf >= minConf:
|
||||
# 只要买了 freqSet-conseq 集合,一定会买 conseq 集合(freqSet-conseq 集合和 conseq 集合是全集)
|
||||
print freqSet-conseq, '-->', conseq, 'conf:', conf
|
||||
brl.append((freqSet-conseq, conseq, conf))
|
||||
prunedH.append(conseq)
|
||||
return prunedH
|
||||
````
|
||||
|
||||
#### 递归计算频繁项集的规则
|
||||
|
||||
```python
|
||||
# 递归计算频繁项集的规则
|
||||
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
|
||||
"""rulesFromConseq
|
||||
|
||||
Args:
|
||||
freqSet 频繁项集中的元素,例如: frozenset([2, 3, 5])
|
||||
H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
supportData 所有元素的支持度的字典
|
||||
brl 关联规则列表的数组
|
||||
minConf 最小可信度
|
||||
"""
|
||||
# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制
|
||||
# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...
|
||||
# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
# 那么 m = len(H[0]) 的递归的值依次为 1 2
|
||||
# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。
|
||||
m = len(H[0])
|
||||
if (len(freqSet) > (m + 1)):
|
||||
print 'freqSet******************', len(freqSet), m + 1, freqSet, H, H[0]
|
||||
# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]
|
||||
# 第二次 。。。没有第二次,递归条件判断时已经退出了
|
||||
Hmp1 = aprioriGen(H, m+1)
|
||||
# 返回可信度大于最小可信度的集合
|
||||
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
|
||||
print 'Hmp1=', Hmp1
|
||||
print 'len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freqSet)
|
||||
# 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
|
||||
if (len(Hmp1) > 1):
|
||||
print '----------------------', Hmp1
|
||||
# print len(freqSet), len(Hmp1[0]) + 1
|
||||
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
|
||||
```
|
||||
|
||||
#### 生成关联规则
|
||||
|
||||
```python
|
||||
# 生成关联规则
|
||||
def generateRules(L, supportData, minConf=0.7):
|
||||
"""generateRules
|
||||
|
||||
Args:
|
||||
L 频繁项集列表
|
||||
supportData 频繁项集支持度的字典
|
||||
minConf 最小置信度
|
||||
Returns:
|
||||
bigRuleList 可信度规则列表(关于 (A->B+置信度) 3个字段的组合)
|
||||
"""
|
||||
bigRuleList = []
|
||||
# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]
|
||||
for i in range(1, len(L)):
|
||||
# 获取频繁项集中每个组合的所有元素
|
||||
for freqSet in L[i]:
|
||||
# 假设:freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]
|
||||
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
|
||||
H1 = [frozenset([item]) for item in freqSet]
|
||||
# 2 个的组合,走 else, 2 个以上的组合,走 if
|
||||
if (i > 1):
|
||||
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
|
||||
else:
|
||||
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
|
||||
return bigRuleList
|
||||
```
|
||||
|
||||
到这里为止,通过调用 generateRules 函数即可得出我们所需的 `关联规则`。
|
||||
|
||||
* 分级法: 频繁项集->关联规则
|
||||
* 1.首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
|
||||
* 2.接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
|
||||
* 如下图:
|
||||
* 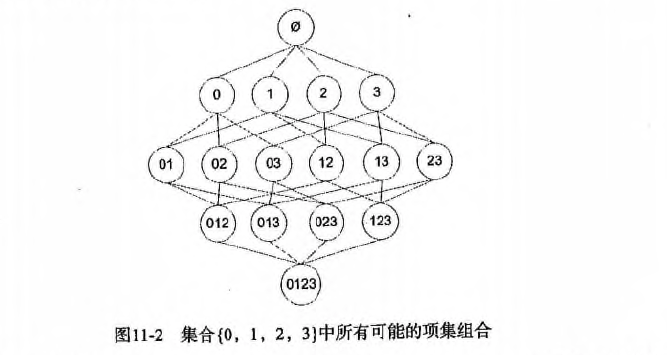
|
||||
* 最后: 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是否有优化空间呢? 下一章:FP-growth算法等着你的到来
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,102 @@
|
|||
|
||||
# 第12章 使用FP-growth算法来高效发现频繁项集
|
||||
|
||||

|
||||
|
||||
## 前言
|
||||
在 [第11章]() 时我们已经介绍了用 `Apriori` 算法发现 `频繁项集` 与 `关联规则`。
|
||||
本章将继续关注发现 `频繁项集` 这一任务,并使用 `FP-growth` 算法更有效的挖掘 `频繁项集`。
|
||||
|
||||
## FP-growth 算法简介
|
||||
|
||||
* 一种非常好的发现频繁项集算法。
|
||||
* 基于Apriori算法构建,但是数据结构不同,使用叫做 `FP树` 的数据结构结构来存储集合。下面我们会介绍这种数据结构。
|
||||
|
||||
## FP-growth 算法步骤
|
||||
- 基于数据构建FP树
|
||||
- 从FP树种挖掘频繁项集
|
||||
|
||||
## FP树 介绍
|
||||
* FP树的节点结构如下:
|
||||
|
||||
```python
|
||||
class treeNode:
|
||||
def __init__(self, nameValue, numOccur, parentNode):
|
||||
self.name = nameValue # 节点名称
|
||||
self.count = numOccur # 节点出现次数
|
||||
self.nodeLink = None # 不同项集的相同项通过nodeLink连接在一起
|
||||
# needs to be updated
|
||||
self.parent = parentNode # 指向父节点
|
||||
self.children = {} # 存储叶子节点
|
||||
```
|
||||
|
||||
## FP-growth 原理
|
||||
基于数据构建FP树
|
||||
|
||||
步骤1:
|
||||
1. 遍历所有的数据集合,计算所有项的支持度。
|
||||
2. 丢弃非频繁的项。
|
||||
3. 基于 支持度 降序排序所有的项。
|
||||
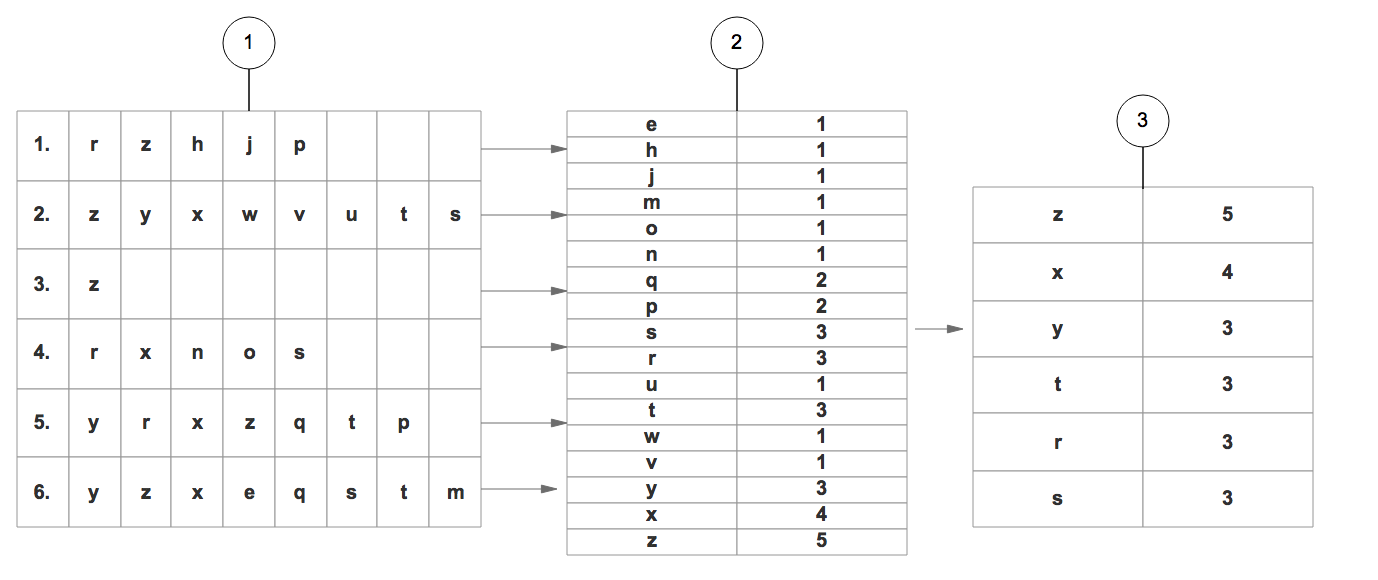
|
||||
4. 所有数据集合按照得到的顺序重新整理。
|
||||
5. 重新整理完成后,丢弃每个集合末尾非频繁的项。
|
||||
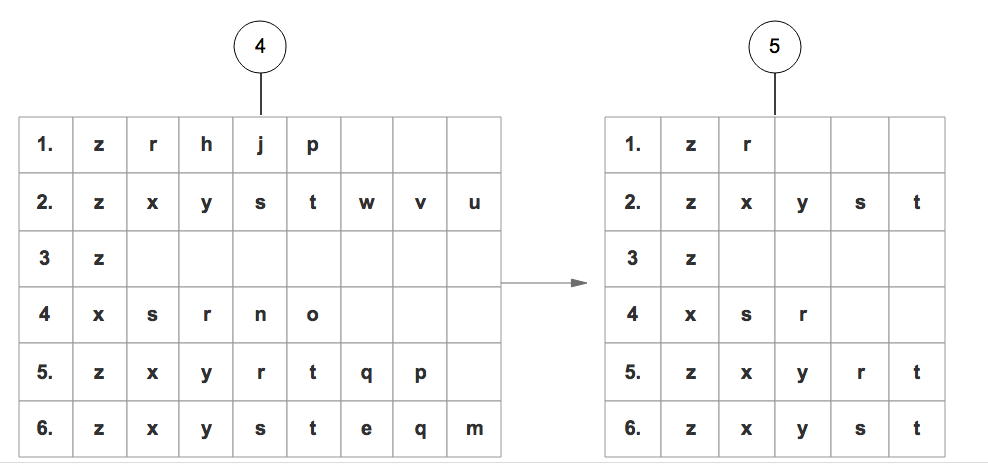
|
||||
|
||||
步骤2:
|
||||
6. 读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项。
|
||||
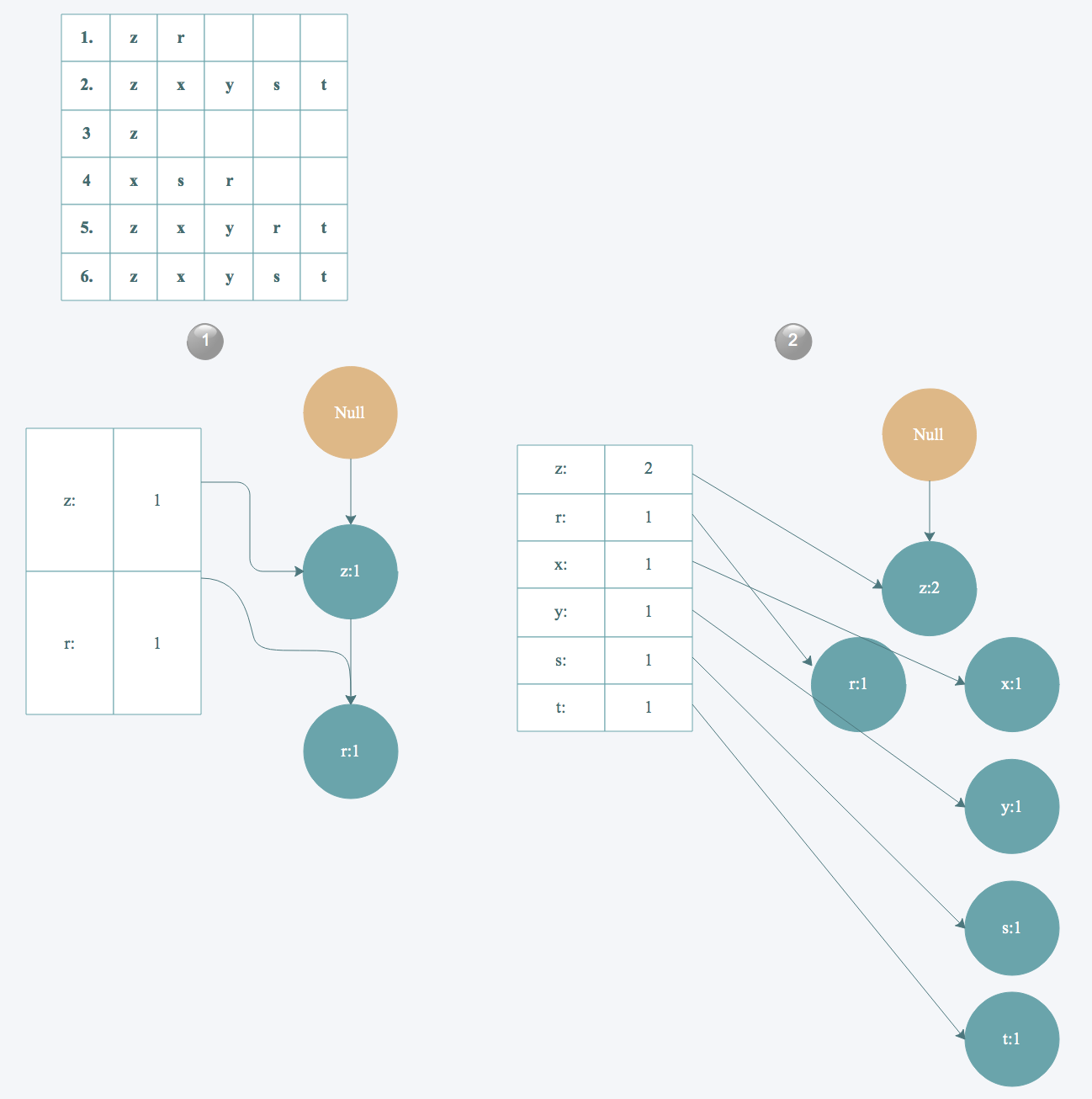
|
||||
最终得到下面这样一棵FP树
|
||||
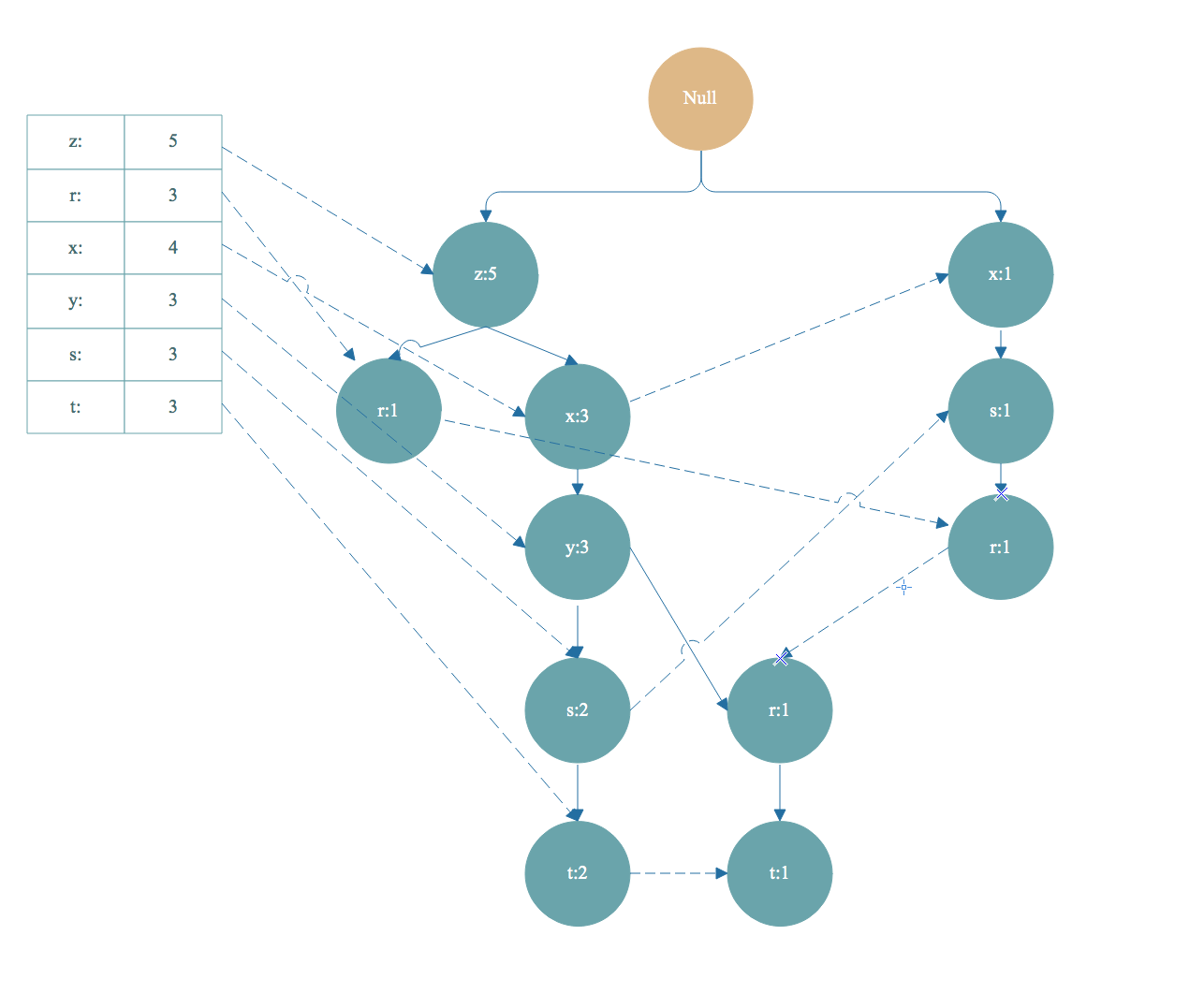
|
||||
|
||||
|
||||
从FP树中挖掘出频繁项集
|
||||
|
||||
步骤3:
|
||||
1. 对头部链表进行降序排序
|
||||
2. 对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集。
|
||||

|
||||
如上图,从头部链表 t 节点开始遍历,t 节点加入到频繁项集。找到以 t 节点为结尾的路径如下:
|
||||
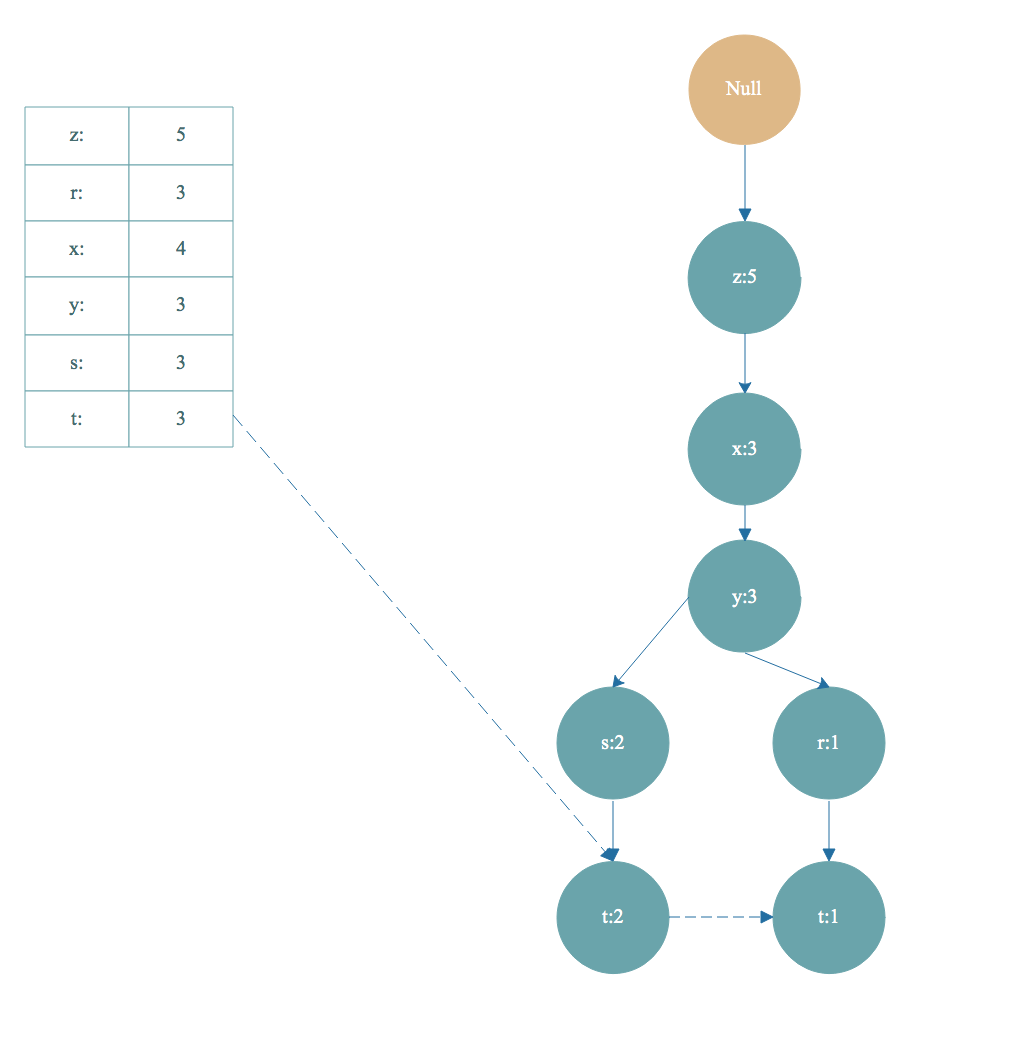
|
||||
去掉FP树中的t节点,得到条件模式基<左边路径,左边是值>[z,x,y,s,t]:2,[z,x,y,r,t]:1 。条件模式基的值取决于末尾节点 t ,因为 t 的出现次数最小,一个频繁项集的支持度由支持度最小的项决定。所以 t 节点的条件模式基的值可以理解为对于以 t 节点为末尾的前缀路径出现次数。
|
||||
|
||||
3. 条件模式基继续构造条件 FP树, 得到频繁项集,和之前的频繁项组合起来,这是一个递归遍历头部链表生成FP树的过程,递归截止条件是生成的FP树的头部链表为空。
|
||||
根据步骤 2 得到的条件模式基 [z,x,y,s,t]:2,[z,x,y,r,t]:1 作为数据集继续构造出一棵FP树,计算支持度,去除非频繁项,集合按照支持度降序排序,重复上面构造FP树的步骤。最后得到下面 t-条件FP树 :
|
||||
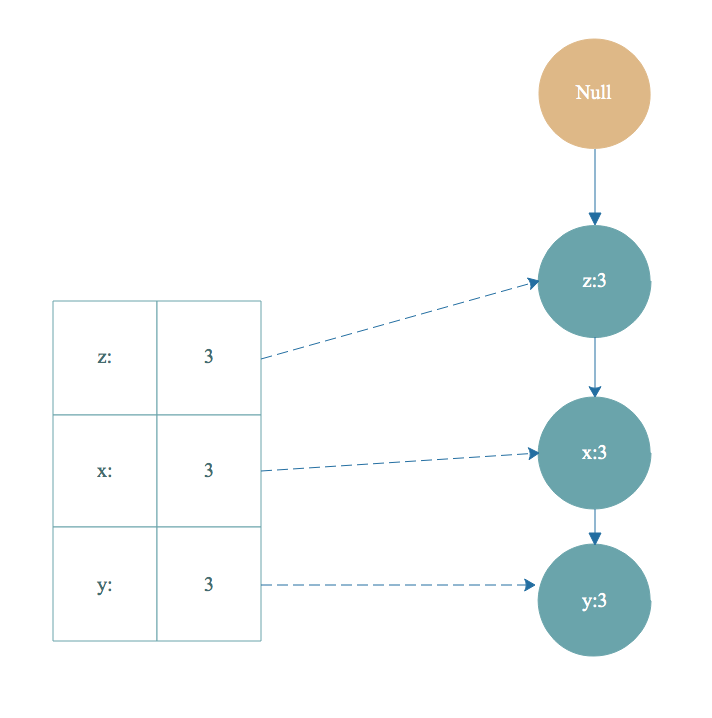
|
||||
然后根据 t-条件FP树 的头部链表进行遍历,从 y 开始。得到频繁项集 ty 。然后又得到 y 的条件模式基,构造出 ty的条件FP树,即 ty-条件FP树。继续遍历ty-条件FP树的头部链表,得到频繁项集 tyx,然后又得到频繁项集 tyxz. 然后得到构造tyxz-条件FP树的头部链表是空的,终止遍历。我们得到的频繁项集有 t->ty->tyz->tyzx,这只是一小部分。
|
||||
* 条件模式基:头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。
|
||||
* 条件FP树:以条件模式基为数据集构造的FP树叫做条件FP树。
|
||||
|
||||
FP-growth 算法优缺点:
|
||||
|
||||
```
|
||||
* 优点: 1. 因为 FP-growth 算法只需要对数据集遍历两次,所以速度更快。
|
||||
2. FP树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。
|
||||
3. 不需要生成候选集。
|
||||
4. 比Apriori更快。
|
||||
* 缺点: 1. FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
|
||||
2. 构建FP-Tree是比较昂贵的。
|
||||
* 适用数据类型:标称型数据(离散型数据)。
|
||||
```
|
||||
|
||||
|
||||
## FP-growth 代码讲解
|
||||
完整代码地址: <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/12.FrequentPattemTree/fpGrowth.py>
|
||||
|
||||
main 方法大致步骤:
|
||||
```python
|
||||
if __name__ == "__main__":
|
||||
simpDat = loadSimpDat() #加载数据集。
|
||||
initSet = createInitSet(simpDat) #对数据集进行整理,相同集合进行合并。
|
||||
myFPtree, myHeaderTab = createTree(initSet, 3)#创建FP树。
|
||||
freqItemList = []
|
||||
mineTree(myFPtree, myHeaderTab, 3, set([]), freqItemList) #递归的从FP树中挖掘出频繁项集。
|
||||
print freqItemList
|
||||
```
|
||||
大家看懂原理,再仔细跟踪一下代码。基本就没有问题了。
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[mikechengwei](https://github.com/mikechengwei)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,226 @@
|
|||
# 第13章 利用 PCA 来简化数据
|
||||
|
||||

|
||||
|
||||
## 降维技术
|
||||
|
||||
> 场景
|
||||
|
||||
* 我们正通过电视观看体育比赛,在电视的显示器上有一个球。
|
||||
* 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点。
|
||||
* 人们实时的将显示器上的百万像素转换成为一个三维图像,该图像就给出运动场上球的位置。
|
||||
* 在这个过程中,人们已经将百万像素点的数据,降至为三维。这个过程就称为`降维(dimensionality reduction)`
|
||||
|
||||
> 数据显示 并非大规模特征下的唯一难题,对数据进行简化还有如下一系列的原因:
|
||||
|
||||
* 1) 使得数据集更容易使用
|
||||
* 2) 降低很多算法的计算开销
|
||||
* 3) 去除噪音
|
||||
* 4) 使得结果易懂
|
||||
|
||||
> 适用范围:
|
||||
|
||||
* 在已标注与未标注的数据上都有降维技术。
|
||||
* 这里我们将主要关注未标注数据上的降维技术,将技术同样也可以应用于已标注的数据。
|
||||
|
||||
> 在以下3种降维技术中, PCA的应用目前最为广泛,因此本章主要关注PCA。
|
||||
|
||||
* 1) 主成分分析(Principal Component Analysis, PCA)
|
||||
* `通俗理解:就是找出一个最主要的特征,然后进行分析。`
|
||||
* `例如: 考察一个人的智力情况,就直接看数学成绩就行(存在:数学、语文、英语成绩)`
|
||||
* 2) 因子分析(Factor Analysis)
|
||||
* `通俗理解:将多个实测变量转换为少数几个综合指标。它反映一种降维的思想,通过降维将相关性高的变量聚在一起,从而减少需要分析的变量的数量,而减少问题分析的复杂性`
|
||||
* `例如: 考察一个人的整体情况,就直接组合3样成绩(隐变量),看平均成绩就行(存在:数学、语文、英语成绩)`
|
||||
* 应用的领域:社会科学、金融和其他领域
|
||||
* 在因子分析中,我们
|
||||
* 假设观察数据的成分中有一些观察不到的隐变量(latent variable)。
|
||||
* 假设观察数据是这些隐变量和某些噪音的线性组合。
|
||||
* 那么隐变量的数据可能比观察数据的数目少,也就说通过找到隐变量就可以实现数据的降维。
|
||||
* 3) 独立成分分析(Independ Component Analysis, ICA)
|
||||
* `通俗理解:ICA 认为观测信号是若干个独立信号的线性组合,ICA 要做的是一个解混过程。`
|
||||
* `例如:我们去ktv唱歌,想辨别唱的是什么歌曲?ICA 是观察发现是原唱唱的一首歌【2个独立的声音(原唱/主唱)】。`
|
||||
* ICA 是假设数据是从 N 个数据源混合组成的,这一点和因子分析有些类似,这些数据源之间在统计上是相互独立的,而在 PCA 中只假设数据是不 相关(线性关系)的。
|
||||
* 同因子分析一样,如果数据源的数目少于观察数据的数目,则可以实现降维过程。
|
||||
|
||||
|
||||
## PCA
|
||||
|
||||
### PCA 概述
|
||||
|
||||
主成分分析(Principal Component Analysis, PCA):`通俗理解:就是找出一个最主要的特征,然后进行分析。`
|
||||
|
||||
### PCA 场景
|
||||
|
||||
`例如: 考察一个人的智力情况,就直接看数学成绩就行(存在:数学、语文、英语成绩)`
|
||||
|
||||
### PCA 原理
|
||||
|
||||
> PCA 工作原理
|
||||
|
||||
1. 找出第一个主成分的方向,也就是数据 `方差最大` 的方向。
|
||||
2. 找出第二个主成分的方向,也就是数据 `方差次大` 的方向,并且该方向与第一个主成分方向 `正交(orthogonal 如果是二维空间就叫垂直)`。
|
||||
3. 通过这种方式计算出所有的主成分方向。
|
||||
4. 通过数据集的协方差矩阵及其特征值分析,我们就可以得到这些主成分的值。
|
||||
5. 一旦得到了协方差矩阵的特征值和特征向量,我们就可以保留最大的 N 个特征。这些特征向量也给出了 N 个最重要特征的真实结构,我们就可以通过将数据乘上这 N 个特征向量 从而将它转换到新的空间上。
|
||||
|
||||
为什么正交?
|
||||
|
||||
1. 正交是为了数据有效性损失最小
|
||||
2. 正交的一个原因是特征值的特征向量是正交的
|
||||
|
||||
例如下图:
|
||||
|
||||
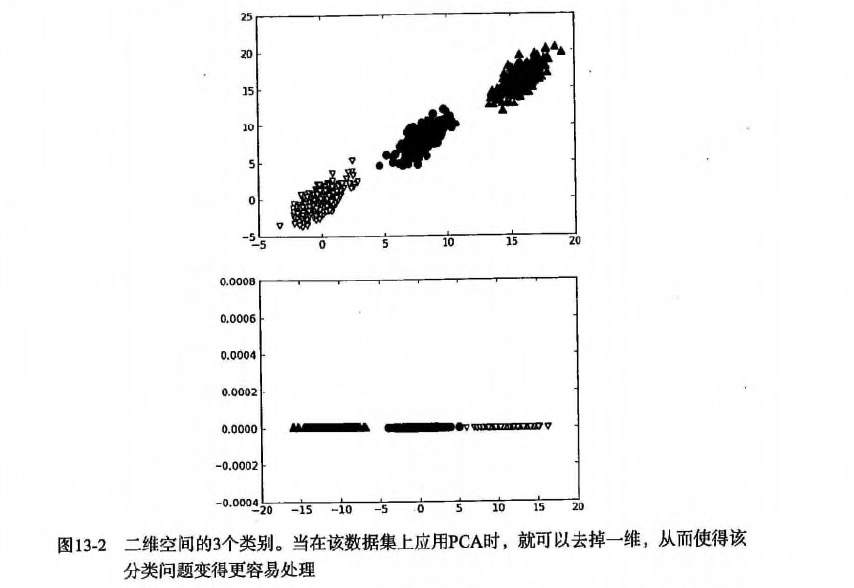
|
||||
|
||||
> PCA 优缺点
|
||||
|
||||
```
|
||||
优点:降低数据的复杂性,识别最重要的多个特征。
|
||||
缺点:不一定需要,且可能损失有用信息。
|
||||
适用数据类型:数值型数据。
|
||||
```
|
||||
|
||||
### 项目案例: 对半导体数据进行降维处理
|
||||
|
||||
#### 项目概述
|
||||
|
||||
```
|
||||
半导体是在一些极为先进的工厂中制造出来的。设备的生命早期有限,并且花费极其巨大。
|
||||
虽然通过早期测试和频繁测试来发现有瑕疵的产品,但仍有一些存在瑕疵的产品通过测试。
|
||||
如果我们通过机器学习技术用于发现瑕疵产品,那么它就会为制造商节省大量的资金。
|
||||
|
||||
具体来讲,它拥有590个特征。我们看看能否对这些特征进行降维处理。
|
||||
|
||||
对于数据的缺失值的问题,我们有一些处理方法(参考第5章)
|
||||
目前该章节处理的方案是:将缺失值NaN(Not a Number缩写),全部用平均值来替代(如果用0来处理的策略就太差劲了)。
|
||||
```
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集数据:提供文本文件
|
||||
|
||||
文件名:secom.data
|
||||
|
||||
文本文件数据格式如下:
|
||||
|
||||
```
|
||||
3030.93 2564 2187.7333 1411.1265 1.3602 100 97.6133 0.1242 1.5005 0.0162 -0.0034 0.9455 202.4396 0 7.9558 414.871 10.0433 0.968 192.3963 12.519 1.4026 -5419 2916.5 -4043.75 751 0.8955 1.773 3.049 64.2333 2.0222 0.1632 3.5191 83.3971 9.5126 50.617 64.2588 49.383 66.3141 86.9555 117.5132 61.29 4.515 70 352.7173 10.1841 130.3691 723.3092 1.3072 141.2282 1 624.3145 218.3174 0 4.592 4.841 2834 0.9317 0.9484 4.7057 -1.7264 350.9264 10.6231 108.6427 16.1445 21.7264 29.5367 693.7724 0.9226 148.6009 1 608.17 84.0793 NaN NaN 0 0.0126 -0.0206 0.0141 -0.0307 -0.0083 -0.0026 -0.0567 -0.0044 7.2163 0.132 NaN 2.3895 0.969 1747.6049 0.1841 8671.9301 -0.3274 -0.0055 -0.0001 0.0001 0.0003 -0.2786 0 0.3974 -0.0251 0.0002 0.0002 0.135 -0.0042 0.0003 0.0056 0 -0.2468 0.3196 NaN NaN NaN NaN 0.946 0 748.6115 0.9908 58.4306 0.6002 0.9804 6.3788 15.88 2.639 15.94 15.93 0.8656 3.353 0.4098 3.188 -0.0473 0.7243 0.996 2.2967 1000.7263 39.2373 123 111.3 75.2 46.2 350.671 0.3948 0 6.78 0.0034 0.0898 0.085 0.0358 0.0328 12.2566 0 4.271 10.284 0.4734 0.0167 11.8901 0.41 0.0506 NaN NaN 1017 967 1066 368 0.09 0.048 0.095 2 0.9 0.069 0.046 0.725 0.1139 0.3183 0.5888 0.3184 0.9499 0.3979 0.16 0 0 20.95 0.333 12.49 16.713 0.0803 5.72 0 11.19 65.363 0 0 0 0 0 0 0.292 5.38 20.1 0.296 10.62 10.3 5.38 4.04 16.23 0.2951 8.64 0 10.3 97.314 0 0.0772 0.0599 0.07 0.0547 0.0704 0.052 0.0301 0.1135 3.4789 0.001 NaN 0.0707 0.0211 175.2173 0.0315 1940.3994 0 0.0744 0.0546 0 0 0 0 0 0 0 0 0 0.0027 0.004 0 0 0 0 NaN NaN NaN NaN 0.0188 0 219.9453 0.0011 2.8374 0.0189 0.005 0.4269 0 0 0 0 0 0 0 0 0 0 0 0.0472 40.855 4.5152 30.9815 33.9606 22.9057 15.9525 110.2144 0.131 0 2.5883 0.001 0.0319 0.0197 0.012 0.0109 3.9321 0 1.5123 3.5811 0.1337 0.0055 3.8447 0.1077 0.0167 NaN NaN 418.1363 398.3185 496.1582 158.333 0.0373 0.0202 0.0462 0.6083 0.3032 0.02 0.0174 0.2827 0.0434 0.1342 0.2419 0.1343 0.367 0.1431 0.061 0 0 0 6.2698 0.1181 3.8208 5.3737 0.0254 1.6252 0 3.2461 18.0118 0 0 0 0 0 0 0.0752 1.5989 6.5893 0.0913 3.0911 8.4654 1.5989 1.2293 5.3406 0.0867 2.8551 0 2.9971 31.8843 NaN NaN 0 0.0215 0.0274 0.0315 0.0238 0.0206 0.0238 0.0144 0.0491 1.2708 0.0004 NaN 0.0229 0.0065 55.2039 0.0105 560.2658 0 0.017 0.0148 0.0124 0.0114 0 0 0 0 0 0 0 0.001 0.0013 0 0 0 0 NaN NaN NaN NaN 0.0055 0 61.5932 0.0003 0.9967 0.0082 0.0017 0.1437 0 0 0 0 0 0 0 0 0 0 0 0.0151 14.2396 1.4392 5.6188 3.6721 2.9329 2.1118 24.8504 29.0271 0 6.9458 2.738 5.9846 525.0965 0 3.4641 6.0544 0 53.684 2.4788 4.7141 1.7275 6.18 3.275 3.6084 18.7673 33.1562 26.3617 49.0013 10.0503 2.7073 3.1158 3.1136 44.5055 42.2737 1.3071 0.8693 1.1975 0.6288 0.9163 0.6448 1.4324 0.4576 0.1362 0 0 0 5.9396 3.2698 9.5805 2.3106 6.1463 4.0502 0 1.7924 29.9394 0 0 0 0 0 0 6.2052 311.6377 5.7277 2.7864 9.7752 63.7987 24.7625 13.6778 2.3394 31.9893 5.8142 0 1.6936 115.7408 0 613.3069 291.4842 494.6996 178.1759 843.1138 0 53.1098 0 48.2091 0.7578 NaN 2.957 2.1739 10.0261 17.1202 22.3756 0 0 0 0 0 0 0 0 0 0 0 0 64.6707 0 0 0 0 0 NaN NaN NaN NaN 1.9864 0 29.3804 0.1094 4.856 3.1406 0.5064 6.6926 0 0 0 0 0 0 0 0 0 0 0 2.057 4.0825 11.5074 0.1096 0.0078 0.0026 7.116 1.0616 395.57 75.752 0.4234 12.93 0.78 0.1827 5.7349 0.3363 39.8842 3.2687 1.0297 1.0344 0.4385 0.1039 42.3877 NaN NaN NaN NaN NaN NaN NaN NaN 533.85 2.1113 8.95 0.3157 3.0624 0.1026 1.6765 14.9509 NaN NaN NaN NaN 0.5005 0.0118 0.0035 2.363 NaN NaN NaN NaN
|
||||
3095.78 2465.14 2230.4222 1463.6606 0.8294 100 102.3433 0.1247 1.4966 -0.0005 -0.0148 0.9627 200.547 0 10.1548 414.7347 9.2599 0.9701 191.2872 12.4608 1.3825 -5441.5 2604.25 -3498.75 -1640.25 1.2973 2.0143 7.39 68.4222 2.2667 0.2102 3.4171 84.9052 9.7997 50.6596 64.2828 49.3404 64.9193 87.5241 118.1188 78.25 2.773 70 352.2445 10.0373 133.1727 724.8264 1.2887 145.8445 1 631.2618 205.1695 0 4.59 4.842 2853 0.9324 0.9479 4.682 0.8073 352.0073 10.3092 113.98 10.9036 19.1927 27.6301 697.1964 1.1598 154.3709 1 620.3582 82.3494 NaN NaN 0 -0.0039 -0.0198 0.0004 -0.044 -0.0358 -0.012 -0.0377 0.0017 6.8043 0.1358 NaN 2.3754 0.9894 1931.6464 0.1874 8407.0299 0.1455 -0.0015 0 -0.0005 0.0001 0.5854 0 -0.9353 -0.0158 -0.0004 -0.0004 -0.0752 -0.0045 0.0002 0.0015 0 0.0772 -0.0903 NaN NaN NaN NaN 0.9425 0 731.2517 0.9902 58.668 0.5958 0.9731 6.5061 15.88 2.541 15.91 15.88 0.8703 2.771 0.4138 3.272 -0.0946 0.8122 0.9985 2.2932 998.1081 37.9213 98 80.3 81 56.2 219.7679 0.2301 0 5.7 0.0049 0.1356 0.06 0.0547 0.0204 12.3319 0 6.285 13.077 0.5666 0.0144 11.8428 0.35 0.0437 NaN NaN 568 59 297 3277 0.112 0.115 0.124 2.2 1.1 0.079 0.561 1.0498 0.1917 0.4115 0.6582 0.4115 1.0181 0.2315 0.325 0 0 17.99 0.439 10.14 16.358 0.0892 6.92 0 9.05 82.986 0 0 0 0 0 0 0.222 3.74 19.59 0.316 11.65 8.02 3.74 3.659 15.078 0.358 8.96 0 8.02 134.25 0 0.0566 0.0488 0.1651 0.1578 0.0468 0.0987 0.0734 0.0747 3.9578 0.005 NaN 0.0761 0.0014 128.4285 0.0238 1988 0 0.0203 0.0236 0 0 0 0 0 0 0 0 0 0.0064 0.0036 0 0 0 0 NaN NaN NaN NaN 0.0154 0 193.0287 0.0007 3.8999 0.0187 0.0086 0.5749 0 0 0 0 0 0 0 0 0 0 0 0.0411 29.743 3.6327 29.0598 28.9862 22.3163 17.4008 83.5542 0.0767 0 1.8459 0.0012 0.044 0.0171 0.0154 0.0069 3.9011 0 2.1016 3.9483 0.1662 0.0049 3.7836 0.1 0.0139 NaN NaN 233.9865 26.5879 139.2082 1529.7622 0.0502 0.0561 0.0591 0.8151 0.3464 0.0291 0.1822 0.3814 0.0715 0.1667 0.263 0.1667 0.3752 0.0856 0.1214 0 0 0 5.6522 0.1417 2.9939 5.2445 0.0264 1.8045 0 2.7661 23.623 0 0 0 0 0 0 0.0778 1.1506 5.9247 0.0878 3.3604 7.7421 1.1506 1.1265 5.0108 0.1013 2.4278 0 2.489 41.708 NaN NaN 0 0.0142 0.023 0.0768 0.0729 0.0143 0.0513 0.0399 0.0365 1.2474 0.0017 NaN 0.0248 0.0005 46.3453 0.0069 677.1873 0 0.0053 0.0059 0.0081 0.0033 0 0 0 0 0 0 0 0.0022 0.0013 0 0 0 0 NaN NaN NaN NaN 0.0049 0 65.0999 0.0002 1.1655 0.0068 0.0027 0.1921 0 0 0 0 0 0 0 0 0 0 0 0.012 10.5837 1.0323 4.3465 2.5939 3.2858 2.5197 15.015 27.7464 0 5.5695 3.93 9.0604 0 368.9713 2.1196 6.1491 0 61.8918 3.1531 6.1188 1.4857 6.1911 2.8088 3.1595 10.4383 2.2655 8.4887 199.7866 8.6336 5.7093 1.6779 3.2153 48.5294 37.5793 16.4174 1.2364 1.9562 0.8123 1.0239 0.834 1.5683 0.2645 0.2751 0 0 0 5.1072 4.3737 7.6142 2.2568 6.9233 4.7448 0 1.4336 40.4475 0 0 0 0 0 0 4.7415 463.2883 5.5652 3.0652 10.2211 73.5536 19.4865 13.243 2.1627 30.8643 5.8042 0 1.2928 163.0249 0 0 246.7762 0 359.0444 130.635 820.79 194.4371 0 58.1666 3.6822 NaN 3.2029 0.1441 6.6487 12.6788 23.6469 0 0 0 0 0 0 0 0 0 0 0 0 141.4365 0 0 0 0 0 NaN NaN NaN NaN 1.6292 0 26.397 0.0673 6.6475 3.131 0.8832 8.837 0 0 0 0 0 0 0 0 0 0 0 1.791 2.9799 9.5796 0.1096 0.0078 0.0026 7.116 1.3526 408.798 74.64 0.7193 16 1.33 0.2829 7.1196 0.4989 53.1836 3.9139 1.7819 0.9634 0.1745 0.0375 18.1087 NaN NaN NaN NaN NaN NaN NaN NaN 535.0164 2.4335 5.92 0.2653 2.0111 0.0772 1.1065 10.9003 0.0096 0.0201 0.006 208.2045 0.5019 0.0223 0.0055 4.4447 0.0096 0.0201 0.006 208.2045
|
||||
2932.61 2559.94 2186.4111 1698.0172 1.5102 100 95.4878 0.1241 1.4436 0.0041 0.0013 0.9615 202.0179 0 9.5157 416.7075 9.3144 0.9674 192.7035 12.5404 1.4123 -5447.75 2701.75 -4047 -1916.5 1.3122 2.0295 7.5788 67.1333 2.3333 0.1734 3.5986 84.7569 8.659 50.153 64.1114 49.847 65.8389 84.7327 118.6128 14.37 5.434 70 364.3782 9.8783 131.8027 734.7924 1.2992 141.0845 1 637.2655 185.7574 0 4.486 4.748 2936 0.9139 0.9447 4.5873 23.8245 364.5364 10.1685 115.6273 11.3019 16.1755 24.2829 710.5095 0.8694 145.8 1 625.9636 84.7681 140.6972 485.2665 0 -0.0078 -0.0326 -0.0052 0.0213 -0.0054 -0.1134 -0.0182 0.0287 7.1041 0.1362 NaN 2.4532 0.988 1685.8514 0.1497 9317.1698 0.0553 0.0006 -0.0013 0 0.0002 -0.1343 0 -0.1427 0.1218 0.0006 -0.0001 0.0134 -0.0026 -0.0016 -0.0006 0.0013 -0.0301 -0.0728 NaN NaN NaN 0.4684 0.9231 0 718.5777 0.9899 58.4808 0.6015 0.9772 6.4527 15.9 2.882 15.94 15.95 0.8798 3.094 0.4777 3.272 -0.1892 0.8194 0.9978 2.2592 998.444 42.0579 89 126.4 96.5 45.1001 306.038 0.3263 0 8.33 0.0038 0.0754 0.0483 0.0619 0.0221 8.266 0 4.819 8.443 0.4909 0.0177 8.2054 0.47 0.0497 NaN NaN 562 788 759 2100 0.187 0.117 0.068 2.1 1.4 0.123 0.319 1.0824 0.0369 0.3141 0.5753 0.3141 0.9677 0.2706 0.326 0 0 17.78 0.745 13.31 22.912 0.1959 9.21 0 17.87 60.11 0 0 0 0 0 0 0.139 5.09 19.75 0.949 9.71 16.73 5.09 11.059 22.624 0.1164 13.3 0 16.73 79.618 0 0.0339 0.0494 0.0696 0.0406 0.0401 0.084 0.0349 0.0718 2.4266 0.0014 NaN 0.0963 0.0152 182.4956 0.0284 839.6006 0 0.0192 0.017 0 0 0 0 0 0 0 0 0 0.0062 0.004 0 0 0 0 NaN NaN NaN 0.1729 0.0273 0 104.4042 0.0007 4.1446 0.0733 0.0063 0.4166 0 0 0 0 0 0 0 0 0 0 0 0.0487 29.621 3.9133 23.551 41.3837 32.6256 15.7716 97.3868 0.1117 0 2.5274 0.0012 0.0249 0.0152 0.0157 0.0075 2.8705 0 1.5306 2.5493 0.1479 0.0059 2.8046 0.1185 0.0167 NaN NaN 251.4536 329.6406 325.0672 902.4576 0.08 0.0583 0.0326 0.6964 0.4031 0.0416 0.1041 0.3846 0.0151 0.1288 0.2268 0.1288 0.3677 0.1175 0.1261 0 0 0 5.7247 0.2682 3.8541 6.1797 0.0546 2.568 0 4.6067 16.0104 0 0 0 0 0 0 0.0243 1.5481 5.9453 0.2777 3.16 8.9855 1.5481 2.9844 6.2277 0.0353 3.7663 0 5.6983 24.7959 13.5664 15.4488 0 0.0105 0.0208 0.0327 0.0171 0.0116 0.0428 0.0154 0.0383 0.7786 0.0005 NaN 0.0302 0.0046 58.0575 0.0092 283.6616 0 0.0054 0.0043 0.003 0.0037 0 0 0 0 0 0 0 0.0021 0.0015 0 0 0 0 NaN NaN NaN 0.0221 0.01 0 28.7334 0.0003 1.2356 0.019 0.002 0.1375 0 0 0 0 0 0 0 0 0 0 0 0.019 11.4871 1.1798 4.0782 4.3102 3.7696 2.0627 18.0233 21.6062 0 8.7236 3.0609 5.2231 0 0 2.2943 4.0917 0 50.6425 2.0261 5.2707 1.8268 4.2581 3.7479 3.522 10.3162 29.1663 18.7546 109.5747 14.2503 5.765 0.8972 3.1281 60 70.9161 8.8647 1.2771 0.4264 0.6263 0.8973 0.6301 1.4698 0.3194 0.2748 0 0 0 4.8795 7.5418 10.0984 3.1182 15.079 6.528 0 2.8042 32.3594 0 0 0 0 0 0 3.0301 21.3645 5.4178 9.3327 8.3977 148.0287 31.4674 45.5423 3.1842 13.3923 9.1221 0 2.6727 93.9245 0 434.2674 151.7665 0 190.3869 746.915 74.0741 191.7582 250.1742 34.1573 1.0281 NaN 3.9238 1.5357 10.8251 18.9849 9.0113 0 0 0 0 0 0 0 0 0 0 0 0 240.7767 244.2748 0 0 0 0 NaN NaN NaN 36.9067 2.9626 0 14.5293 0.0751 7.087 12.1831 0.6451 6.4568 0 0 0 0 0 0 0 0 0 0 0 2.1538 2.9667 9.3046 0.1096 0.0078 0.0026 7.116 0.7942 411.136 74.654 0.1832 16.16 0.85 0.0857 7.1619 0.3752 23.0713 3.9306 1.1386 1.5021 0.3718 0.1233 24.7524 267.064 0.9032 1.1 0.6219 0.4122 0.2562 0.4119 68.8489 535.0245 2.0293 11.21 0.1882 4.0923 0.064 2.0952 9.2721 0.0584 0.0484 0.0148 82.8602 0.4958 0.0157 0.0039 3.1745 0.0584 0.0484 0.0148 82.8602
|
||||
2988.72 2479.9 2199.0333 909.7926 1.3204 100 104.2367 0.1217 1.4882 -0.0124 -0.0033 0.9629 201.8482 0 9.6052 422.2894 9.6924 0.9687 192.1557 12.4782 1.4011 -5468.25 2648.25 -4515 -1657.25 1.3137 2.0038 7.3145 62.9333 2.6444 0.2071 3.3813 84.9105 8.6789 50.51 64.1125 49.49 65.1951 86.6867 117.0442 76.9 1.279 70 363.0273 9.9305 131.8027 733.8778 1.3027 142.5427 1 637.3727 189.9079 0 4.486 4.748 2936 0.9139 0.9447 4.5873 24.3791 361.4582 10.2112 116.1818 13.5597 15.6209 23.4736 710.4043 0.9761 147.6545 1 625.2945 70.2289 160.321 464.9735 0 -0.0555 -0.0461 -0.04 0.04 0.0676 -0.1051 0.0028 0.0277 7.5925 0.1302 NaN 2.4004 0.9904 1752.0968 0.1958 8205.7 0.0697 -0.0003 -0.0021 -0.0001 0.0002 0.0411 0 0.0177 -0.0195 -0.0002 0 -0.0699 -0.0059 0.0003 0.0003 0.0021 -0.0483 -0.118 NaN NaN NaN 0.4647 0.9564 0 709.0867 0.9906 58.6635 0.6016 0.9761 6.4935 15.55 3.132 15.61 15.59 1.366 2.48 0.5176 3.119 0.2838 0.7244 0.9961 2.3802 980.451 41.1025 127 118 123.7 47.8 162.432 0.1915 0 5.51 0.003 0.114 0.0393 0.0613 0.019 13.2651 0 9.073 15.241 1.3029 0.015 11.9738 0.35 0.0699 NaN NaN 859 355 3433 3004 0.068 0.108 0.1 1.7 0.9 0.086 0.241 0.9386 0.0356 0.2618 0.4391 0.2618 0.8567 0.2452 0.39 0 0 16.22 0.693 14.67 22.562 0.1786 5.69 0 18.2 52.571 0 0 0 0 0 0 0.139 5.92 23.6 1.264 10.63 13.56 5.92 11.382 24.32 0.3458 9.56 0 21.97 104.95 0 0.1248 0.0463 0.1223 0.0354 0.0708 0.0754 0.0643 0.0932 5.5398 0.0023 NaN 0.0764 0.0015 152.0885 0.0573 820.3999 0 0.0152 0.0149 0 0 0 0 0 0 0 0 0 0.0067 0.004 0 0 0 0 NaN NaN NaN 0.0191 0.0234 0 94.0954 0.001 3.2119 0.0406 0.0072 0.4212 0 0 0 0 0 0 0 0 0 0 0 0.0513 31.83 3.1959 33.896 37.8477 44.3906 16.9347 50.3631 0.0581 0 2.1775 0.0007 0.0417 0.0115 0.0172 0.0063 4.2154 0 2.896 4.0526 0.3882 0.0049 3.9403 0.0916 0.0245 NaN NaN 415.5048 157.0889 1572.6896 1377.4276 0.0285 0.0445 0.0465 0.6305 0.3046 0.0286 0.0824 0.3483 0.0128 0.1004 0.1701 0.1004 0.3465 0.0973 0.1675 0 0 0 5.444 0.2004 4.19 6.3329 0.0479 1.7339 0 4.966 15.7375 0 0 0 0 0 0 0.0243 1.7317 6.6262 0.3512 3.2699 9.402 1.7317 3.0672 6.6839 0.0928 3.0229 0 6.3292 29.0339 8.4026 4.8851 0 0.0407 0.0198 0.0531 0.0167 0.0224 0.0422 0.0273 0.0484 1.8222 0.0006 NaN 0.0252 0.0004 45.7058 0.0188 309.8492 0 0.0046 0.0049 0.0028 0.0034 0 0 0 0 0 0 0 0.0024 0.0014 0 0 0 0 NaN NaN NaN 0.0038 0.0068 0 32.4228 0.0003 1.1135 0.0132 0.0023 0.1348 0 0 0 0 0 0 0 0 0 0 0 0.0155 13.3972 1.1907 5.6363 3.9482 4.9881 2.1737 17.8537 14.5054 0 5.286 2.4643 7.6602 317.7362 0 1.9689 6.5718 0 94.4594 3.6091 13.442 1.5441 6.2313 2.8049 4.9898 15.7089 13.4051 76.0354 181.2641 5.176 5.3899 1.3671 2.7013 34.0336 41.5236 7.1274 1.1054 0.4097 0.5183 0.6849 0.529 1.3141 0.2829 0.3332 0 0 0 4.468 6.9785 11.1303 3.0744 13.7105 3.9918 0 2.8555 27.6824 0 0 0 0 0 0 3.0301 24.2831 6.5291 12.3786 9.1494 100.0021 37.8979 48.4887 3.4234 35.4323 6.4746 0 3.5135 149.4399 0 225.0169 100.4883 305.75 88.5553 104.666 71.7583 0 336.766 72.9635 1.767 NaN 3.1817 0.1488 8.6804 29.2542 9.9979 0 0 711.6418 0 0 0 0 0 0 0 0 0 113.5593 0 0 0 0 0 NaN NaN NaN 4.12 2.4416 0 13.2699 0.0977 5.4751 6.7553 0.7404 6.4865 0 0 0 0 0 0 0 0 0 0 0 2.1565 3.2465 7.7754 0.1096 0.0078 0.0026 7.116 1.165 372.822 72.442 1.8804 131.68 39.33 0.6812 56.9303 17.4781 161.4081 35.3198 54.2917 1.1613 0.7288 0.271 62.7572 268.228 0.6511 7.32 0.163 3.5611 0.067 2.729 25.0363 530.5682 2.0253 9.33 0.1738 2.8971 0.0525 1.7585 8.5831 0.0202 0.0149 0.0044 73.8432 0.499 0.0103 0.0025 2.0544 0.0202 0.0149 0.0044 73.8432
|
||||
3032.24 2502.87 2233.3667 1326.52 1.5334 100 100.3967 0.1235 1.5031 -0.0031 -0.0072 0.9569 201.9424 0 10.5661 420.5925 10.3387 0.9735 191.6037 12.4735 1.3888 -5476.25 2635.25 -3987.5 117 1.2887 1.9912 7.2748 62.8333 3.1556 0.2696 3.2728 86.3269 8.7677 50.248 64.1511 49.752 66.1542 86.1468 121.4364 76.39 2.209 70 353.34 10.4091 176.3136 789.7523 1.0341 138.0882 1 667.7418 233.5491 0 4.624 4.894 2865 0.9298 0.9449 4.6414 -12.2945 355.0809 9.7948 144.0191 21.9782 32.2945 44.1498 745.6025 0.9256 146.6636 1 645.7636 65.8417 NaN NaN 0 -0.0534 0.0183 -0.0167 -0.0449 0.0034 -0.0178 -0.0123 -0.0048 7.5017 0.1342 NaN 2.453 0.9902 1828.3846 0.1829 9014.46 0.0448 -0.0077 -0.0001 -0.0001 -0.0001 0.2189 0 -0.6704 -0.0167 0.0004 -0.0003 0.0696 -0.0045 0.0002 0.0078 0 -0.0799 -0.2038 NaN NaN NaN NaN 0.9424 0 796.595 0.9908 58.3858 0.5913 0.9628 6.3551 15.75 3.148 15.73 15.71 0.946 3.027 0.5328 3.299 -0.5677 0.778 1.001 2.3715 993.1274 38.1448 119 143.2 123.1 48.8 296.303 0.3744 0 3.64 0.0041 0.0634 0.0451 0.0623 0.024 14.2354 0 9.005 12.506 0.4434 0.0126 13.9047 0.43 0.0538 NaN NaN 699 283 1747 1443 0.147 0.04 0.113 3.9 0.8 0.101 0.499 0.576 0.0631 0.3053 0.583 0.3053 0.8285 0.1308 0.922 0 0 15.24 0.282 10.85 37.715 0.1189 3.98 0 25.54 72.149 0 0 0 0 0 0 0.25 5.52 15.76 0.519 10.71 19.77 5.52 8.446 33.832 0.3951 9.09 0 19.77 92.307 0 0.0915 0.0506 0.0769 0.1079 0.0797 0.1047 0.0924 0.1015 4.1338 0.003 NaN 0.0802 0.0004 69.151 0.197 1406.4004 0 0.0227 0.0272 0 0 0 0 0 0 0 0 0 0.0067 0.0031 0 0 0 0 NaN NaN NaN NaN 0.024 0 149.2172 0.0006 2.5775 0.0177 0.0214 0.4051 0 0 0 0 0 0 0 0 0 0 0 0.0488 19.862 3.6163 34.125 55.9626 53.0876 17.4864 88.7672 0.1092 0 1.0929 0.0013 0.0257 0.0116 0.0163 0.008 4.4239 0 3.2376 3.6536 0.1293 0.004 4.3474 0.1275 0.0181 NaN NaN 319.1252 128.0296 799.5884 628.3083 0.0755 0.0181 0.0476 1.35 0.2698 0.032 0.1541 0.2155 0.031 0.1354 0.2194 0.1354 0.3072 0.0582 0.3574 0 0 0 4.8956 0.0766 2.913 11.0583 0.0327 1.1229 0 7.3296 23.116 0 0 0 0 0 0 0.0822 1.6216 4.7279 0.1773 3.155 9.7777 1.6216 2.5923 10.5352 0.1301 3.0939 0 6.3767 32.0537 NaN NaN 0 0.0246 0.0221 0.0329 0.0522 0.0256 0.0545 0.0476 0.0463 1.553 0.001 NaN 0.0286 0.0001 21.0312 0.0573 494.7368 0 0.0063 0.0077 0.0052 0.0027 0 0 0 0 0 0 0 0.0025 0.0012 0 0 0 0 NaN NaN NaN NaN 0.0089 0 57.2692 0.0002 0.8495 0.0065 0.0077 0.1356 0 0 0 0 0 0 0 0 0 0 0 0.0165 7.1493 1.1704 5.3823 4.7226 4.9184 2.185 22.3369 24.4142 0 3.6256 3.3208 4.2178 0 866.0295 2.5046 7.0492 0 85.2255 2.9734 4.2892 1.2943 7.257 3.4473 3.8754 12.7642 10.739 43.8119 0 11.4064 2.0088 1.5533 6.2069 25.3521 37.4691 15.247 0.6672 0.7198 0.6076 0.9088 0.6136 1.2524 0.1518 0.7592 0 0 0 4.3131 2.7092 6.1538 4.7756 11.4945 2.8822 0 3.8248 30.8924 0 0 0 0 0 0 5.3863 44.898 4.4384 5.2987 7.4365 89.9529 17.0927 19.1303 4.5375 42.6838 6.1979 0 3.0615 140.1953 0 171.4486 276.881 461.8619 240.1781 0 587.3773 748.1781 0 55.1057 2.2358 NaN 3.2712 0.0372 3.7821 107.6905 15.6016 0 293.1396 0 0 0 0 0 0 0 0 0 0 148.0663 0 0 0 0 0 NaN NaN NaN NaN 2.5512 0 18.7319 0.0616 4.4146 2.9954 2.2181 6.3745 0 0 0 0 0 0 0 0 0 0 0 2.0579 1.9999 9.4805 0.1096 0.0078 0.0026 7.116 1.4636 399.914 79.156 1.0388 19.63 1.98 0.4287 9.7608 0.8311 70.9706 4.9086 2.5014 0.9778 0.2156 0.0461 22.05 NaN NaN NaN NaN NaN NaN NaN NaN 532.0155 2.0275 8.83 0.2224 3.1776 0.0706 1.6597 10.9698 NaN NaN NaN NaN 0.48 0.4766 0.1045 99.3032 0.0202 0.0149 0.0044 73.8432
|
||||
```
|
||||
|
||||
> 准备数据:将value为NaN的求均值
|
||||
|
||||
```python
|
||||
def replaceNanWithMean():
|
||||
datMat = loadDataSet('data/13.PCA/secom.data', ' ')
|
||||
numFeat = shape(datMat)[1]
|
||||
for i in range(numFeat):
|
||||
# 对value不为NaN的求均值
|
||||
# .A 返回矩阵基于的数组
|
||||
meanVal = mean(datMat[nonzero(~isnan(datMat[:, i].A))[0], i])
|
||||
# 将value为NaN的值赋值为均值
|
||||
datMat[nonzero(isnan(datMat[:, i].A))[0],i] = meanVal
|
||||
return datMat
|
||||
```
|
||||
|
||||
> 分析数据:统计分析 N 的阈值
|
||||
|
||||

|
||||
|
||||
> PCA 数据降维
|
||||
|
||||
在等式 Av=入v 中,v 是特征向量, 入是特征值。<br/>
|
||||
表示 如果特征向量 v 被某个矩阵 A 左乘,那么它就等于某个标量 入 乘以 v.<br/>
|
||||
幸运的是: Numpy 中有寻找特征向量和特征值的模块 linalg,它有 eig() 方法,该方法用于求解特征向量和特征值。
|
||||
|
||||
```python
|
||||
def pca(dataMat, topNfeat=9999999):
|
||||
"""pca
|
||||
|
||||
Args:
|
||||
dataMat 原数据集矩阵
|
||||
topNfeat 应用的N个特征
|
||||
Returns:
|
||||
lowDDataMat 降维后数据集
|
||||
reconMat 新的数据集空间
|
||||
"""
|
||||
|
||||
# 计算每一列的均值
|
||||
meanVals = mean(dataMat, axis=0)
|
||||
# print 'meanVals', meanVals
|
||||
|
||||
# 每个向量同时都减去 均值
|
||||
meanRemoved = dataMat - meanVals
|
||||
# print 'meanRemoved=', meanRemoved
|
||||
|
||||
# cov协方差=[(x1-x均值)*(y1-y均值)+(x2-x均值)*(y2-y均值)+...+(xn-x均值)*(yn-y均值)+]/(n-1)
|
||||
'''
|
||||
方差:(一维)度量两个随机变量关系的统计量
|
||||
协方差: (二维)度量各个维度偏离其均值的程度
|
||||
协方差矩阵:(多维)度量各个维度偏离其均值的程度
|
||||
|
||||
当 cov(X, Y)>0时,表明X与Y正相关;(X越大,Y也越大;X越小Y,也越小。这种情况,我们称为“正相关”。)
|
||||
当 cov(X, Y)<0时,表明X与Y负相关;
|
||||
当 cov(X, Y)=0时,表明X与Y不相关。
|
||||
'''
|
||||
covMat = cov(meanRemoved, rowvar=0)
|
||||
|
||||
# eigVals为特征值, eigVects为特征向量
|
||||
eigVals, eigVects = linalg.eig(mat(covMat))
|
||||
# print 'eigVals=', eigVals
|
||||
# print 'eigVects=', eigVects
|
||||
# 对特征值,进行从小到大的排序,返回从小到大的index序号
|
||||
# 特征值的逆序就可以得到topNfeat个最大的特征向量
|
||||
'''
|
||||
>>> x = np.array([3, 1, 2])
|
||||
>>> np.argsort(x)
|
||||
array([1, 2, 0]) # index,1 = 1; index,2 = 2; index,0 = 3
|
||||
>>> y = np.argsort(x)
|
||||
>>> y[::-1]
|
||||
array([0, 2, 1])
|
||||
>>> y[:-3:-1]
|
||||
array([0, 2]) # 取出 -1, -2
|
||||
>>> y[:-6:-1]
|
||||
array([0, 2, 1])
|
||||
'''
|
||||
eigValInd = argsort(eigVals)
|
||||
# print 'eigValInd1=', eigValInd
|
||||
|
||||
# -1表示倒序,返回topN的特征值[-1 到 -(topNfeat+1) 但是不包括-(topNfeat+1)本身的倒叙]
|
||||
eigValInd = eigValInd[:-(topNfeat+1):-1]
|
||||
# print 'eigValInd2=', eigValInd
|
||||
# 重组 eigVects 最大到最小
|
||||
redEigVects = eigVects[:, eigValInd]
|
||||
# print 'redEigVects=', redEigVects.T
|
||||
# 将数据转换到新空间
|
||||
# --- (1567, 590) (590, 20)
|
||||
# print "---", shape(meanRemoved), shape(redEigVects)
|
||||
lowDDataMat = meanRemoved * redEigVects
|
||||
reconMat = (lowDDataMat * redEigVects.T) + meanVals
|
||||
# print 'lowDDataMat=', lowDDataMat
|
||||
# print 'reconMat=', reconMat
|
||||
return lowDDataMat, reconMat
|
||||
```
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/13.PCA/pca.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/13.PCA/pca.py>
|
||||
|
||||
### 要点补充
|
||||
|
||||
```
|
||||
降维技术使得数据变的更易使用,并且它们往往能够去除数据中的噪音,使得其他机器学习任务更加精确。
|
||||
降维往往作为预处理步骤,在数据应用到其他算法之前清洗数据。
|
||||
比较流行的降维技术: 独立成分分析、因子分析 和 主成分分析, 其中又以主成分分析应用最广泛。
|
||||
|
||||
本章中的PCA将所有的数据集都调入了内存,如果无法做到,就需要其他的方法来寻找其特征值。
|
||||
如果使用在线PCA分析的方法,你可以参考一篇优秀的论文 "Incremental Eigenanalysis for Classification"。
|
||||
下一章要讨论的奇异值分解方法也可以用于特征值分析。
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,433 @@
|
|||
# 第14章 利用SVD简化数据
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## SVD 概述
|
||||
|
||||
```
|
||||
奇异值分解(SVD, Singular Value Decomposition):
|
||||
提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征。从生物信息学到金融学,SVD 是提取信息的强大工具。
|
||||
```
|
||||
|
||||
## SVD 场景
|
||||
|
||||
> 信息检索-隐性语义检索(Latent Semantic Indexing, LSI)或 隐形语义分析(Latent Semantic Analysis, LSA)
|
||||
|
||||
隐性语义索引:矩阵 = 文档 + 词语
|
||||
* 是最早的 SVD 应用之一,我们称利用 SVD 的方法为隐性语义索引(LSI)或隐性语义分析(LSA)。
|
||||
|
||||
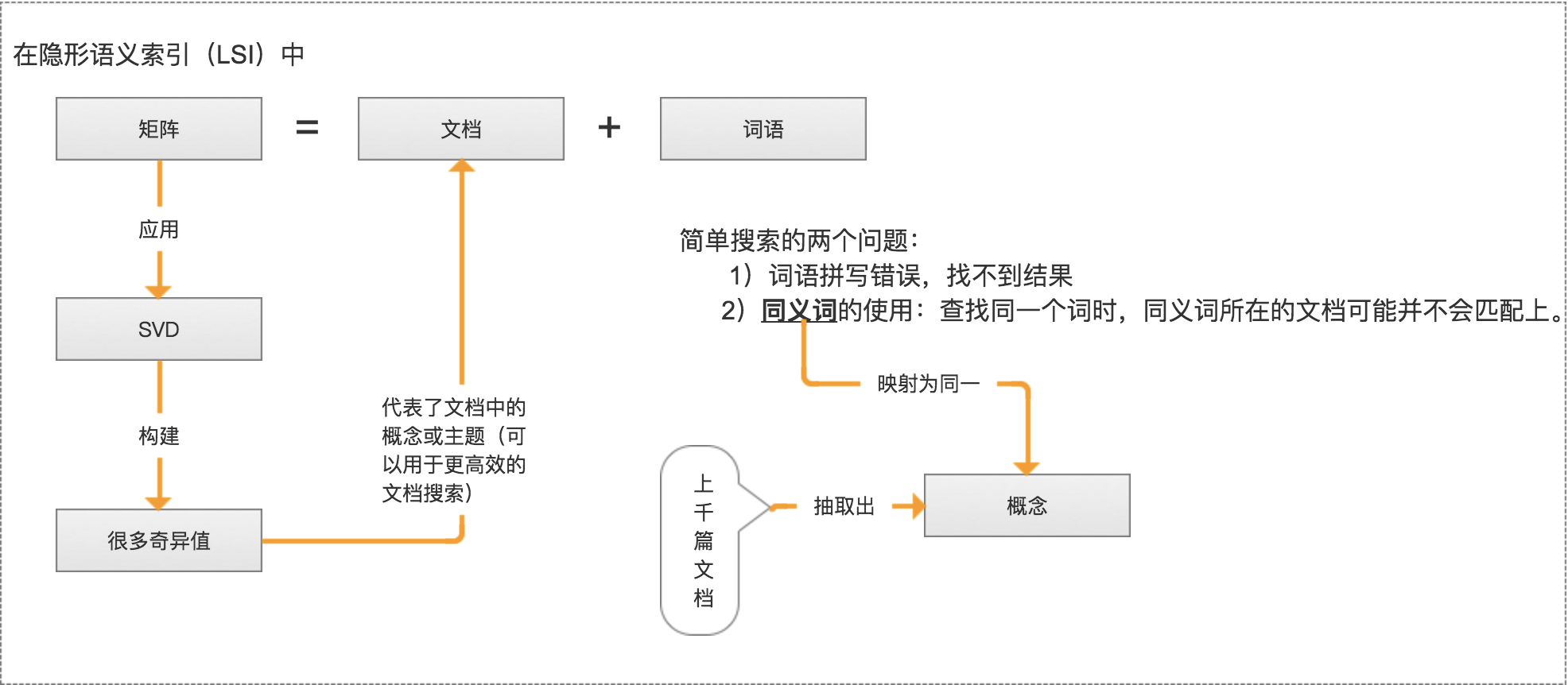
|
||||
|
||||
> 推荐系统
|
||||
|
||||
1. 利用 SVD 从数据中构建一个主题空间。
|
||||
2. 再在该空间下计算其相似度。(从高维-低维空间的转化,在低维空间来计算相似度,SVD 提升了推荐系统的效率。)
|
||||
|
||||
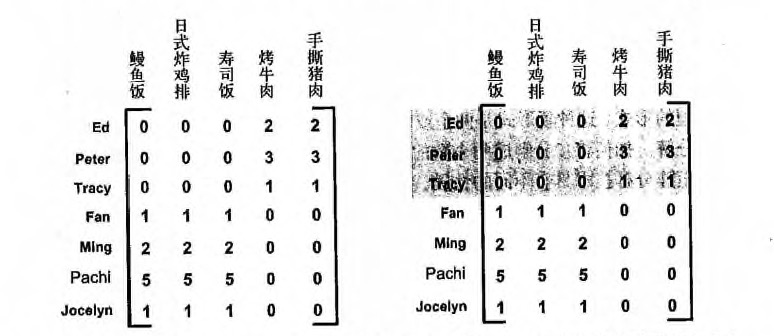
|
||||
|
||||
* 上图右边标注的为一组共同特征,表示美式 BBQ 空间;另一组在上图右边未标注的为日式食品 空间。
|
||||
|
||||
> 图像压缩
|
||||
|
||||
例如:`32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
|
||||
|
||||
|
||||
## SVD 原理
|
||||
|
||||
### SVD 工作原理
|
||||
|
||||
> 矩阵分解
|
||||
|
||||
* 矩阵分解是将数据矩阵分解为多个独立部分的过程。
|
||||
* 矩阵分解可以将原始矩阵表示成新的易于处理的形式,这种新形式是两个或多个矩阵的乘积。(类似代数中的因数分解)
|
||||
* 举例:如何将12分解成两个数的乘积?(1,12)、(2,6)、(3,4)都是合理的答案。
|
||||
|
||||
> SVD 是矩阵分解的一种类型,也是矩阵分解最常见的技术
|
||||
|
||||
* SVD 将原始的数据集矩阵 Data 分解成三个矩阵 U、∑、V
|
||||
* 举例:如果原始矩阵 \\(Data_{m*n}\\) 是m行n列,
|
||||
* \\(U_{m * k}\\) 表示m行k列
|
||||
* \\(∑_{k * k}\\) 表示k行k列
|
||||
* \\(V_{k * n}\\) 表示k行n列。
|
||||
|
||||
\\(Data_{m*n} = U_{m\*k} \* ∑_{k\*k} \* V_{k\*n}\\)
|
||||
|
||||

|
||||
|
||||
具体的案例:(大家可以试着推导一下:https://wenku.baidu.com/view/b7641217866fb84ae45c8d17.html )
|
||||
|
||||

|
||||
|
||||
* 上述分解中会构建出一个矩阵∑,该矩阵只有对角元素,其他元素均为0(近似于0)。另一个惯例就是,∑的对角元素是从大到小排列的。这些对角元素称为奇异值。
|
||||
* 奇异值与特征值(PCA 数据中重要特征)是有关系的。这里的奇异值就是矩阵 \\(Data * Data^T\\) 特征值的平方根。
|
||||
* 普遍的事实:在某个奇异值的数目(r 个=>奇异值的平方和累加到总值的90%以上)之后,其他的奇异值都置为0(近似于0)。这意味着数据集中仅有 r 个重要特征,而其余特征则都是噪声或冗余特征。
|
||||
|
||||
### SVD 算法特点
|
||||
|
||||
```
|
||||
优点:简化数据,去除噪声,优化算法的结果
|
||||
缺点:数据的转换可能难以理解
|
||||
使用的数据类型:数值型数据
|
||||
```
|
||||
|
||||
## 推荐系统
|
||||
|
||||
### 推荐系统 概述
|
||||
|
||||
`推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。`
|
||||
|
||||
### 推荐系统 场景
|
||||
|
||||
1. Amazon 会根据顾客的购买历史向他们推荐物品
|
||||
2. Netflix 会向其用户推荐电影
|
||||
3. 新闻网站会对用户推荐新闻频道
|
||||
|
||||
### 推荐系统 要点
|
||||
|
||||
> 基于协同过滤(collaborative filtering) 的推荐引擎
|
||||
|
||||
* 利用Python 实现 SVD(Numpy 有一个称为 linalg 的线性代数工具箱)
|
||||
* 协同过滤:是通过将用户和其他用户的数据进行对比来实现推荐的。
|
||||
* 当知道了两个用户或两个物品之间的相似度,我们就可以利用已有的数据来预测未知用户的喜好。
|
||||
|
||||
> 基于物品的相似度和基于用户的相似度:物品比较少则选择物品相似度,用户比较少则选择用户相似度。【矩阵还是小一点好计算】
|
||||
|
||||
* 基于物品的相似度:计算物品之间的距离。【耗时会随物品数量的增加而增加】
|
||||
* 由于物品A和物品C 相似度(相关度)很高,所以给买A的人推荐C。
|
||||
|
||||
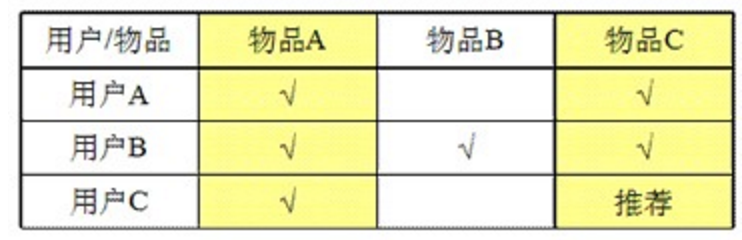
|
||||
|
||||
* 基于用户的相似度:计算用户之间的距离。【耗时会随用户数量的增加而增加】
|
||||
* 由于用户A和用户C 相似度(相关度)很高,所以A和C是兴趣相投的人,对于C买的物品就会推荐给A。
|
||||
|
||||
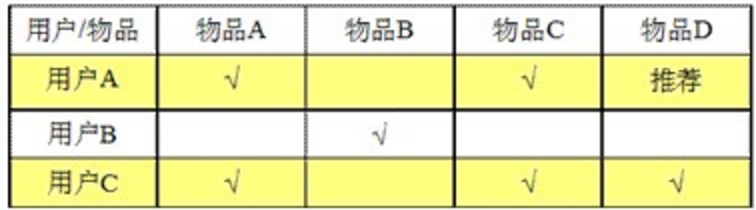
|
||||
|
||||
> 相似度计算
|
||||
|
||||
* inA, inB 对应的是 列向量
|
||||
1. 欧氏距离:指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。二维或三维中的欧氏距离就是两点之间的实际距离。
|
||||
* 相似度= 1/(1+欧式距离)
|
||||
* `相似度= 1.0/(1.0 + la.norm(inA - inB))`
|
||||
* 物品对越相似,它们的相似度值就越大。
|
||||
2. 皮尔逊相关系数:度量的是两个向量之间的相似度。
|
||||
* 相似度= 0.5 + 0.5*corrcoef() 【皮尔逊相关系数的取值范围从 -1 到 +1,通过函数0.5 + 0.5\*corrcoef()这个函数计算,把值归一化到0到1之间】
|
||||
* `相似度= 0.5 + 0.5 * corrcoef(inA, inB, rowvar = 0)[0][1]`
|
||||
* 相对欧氏距离的优势:它对用户评级的量级并不敏感。
|
||||
3. 余弦相似度:计算的是两个向量夹角的余弦值。
|
||||
* 余弦值 = (A·B)/(||A||·||B||) 【余弦值的取值范围也在-1到+1之间】
|
||||
* 相似度= 0.5 + 0.5*余弦值
|
||||
* `相似度= 0.5 + 0.5*( float(inA.T*inB) / la.norm(inA)*la.norm(inB))`
|
||||
* 如果夹角为90度,则相似度为0;如果两个向量的方向相同,则相似度为1.0。
|
||||
|
||||
> 推荐系统的评价
|
||||
|
||||
* 采用交叉测试的方法。【拆分数据为训练集和测试集】
|
||||
* 推荐引擎评价的指标: 最小均方根误差(Root mean squared error, RMSE),也称标准误差(Standard error),就是计算均方误差的平均值然后取其平方根。
|
||||
* 如果RMSE=1, 表示相差1个星级;如果RMSE=2.5, 表示相差2.5个星级。
|
||||
|
||||
### 推荐系统 原理
|
||||
|
||||
* 推荐系统的工作过程:给定一个用户,系统会为此用户返回N个最好的推荐菜。
|
||||
* 实现流程大致如下:
|
||||
1. 寻找用户没有评级的菜肴,即在用户-物品矩阵中的0值。
|
||||
2. 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说:我们认为用户可能会对物品的打分(这就是相似度计算的初衷)。
|
||||
3. 对这些物品的评分从高到低进行排序,返回前N个物品。
|
||||
|
||||
|
||||
### 项目案例: 餐馆菜肴推荐系统
|
||||
|
||||
#### 项目概述
|
||||
|
||||
`假如一个人在家决定外出吃饭,但是他并不知道该到哪儿去吃饭,该点什么菜。推荐系统可以帮他做到这两点。`
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集 并 准备数据
|
||||
|
||||
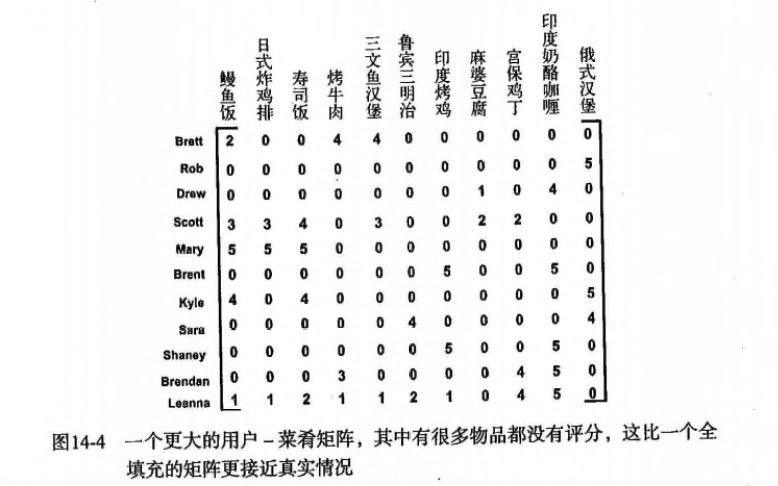
|
||||
|
||||
```python
|
||||
def loadExData3():
|
||||
# 利用SVD提高推荐效果,菜肴矩阵
|
||||
"""
|
||||
行:代表人
|
||||
列:代表菜肴名词
|
||||
值:代表人对菜肴的评分,0表示未评分
|
||||
"""
|
||||
return[[2, 0, 0, 4, 4, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
|
||||
[0, 0, 0, 0, 0, 0, 0, 1, 0, 4, 0],
|
||||
[3, 3, 4, 0, 3, 0, 0, 2, 2, 0, 0],
|
||||
[5, 5, 5, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
|
||||
[4, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5],
|
||||
[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 4],
|
||||
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
|
||||
[0, 0, 0, 3, 0, 0, 0, 0, 4, 5, 0],
|
||||
[1, 1, 2, 1, 1, 2, 1, 0, 4, 5, 0]]
|
||||
```
|
||||
|
||||
> 分析数据: 这里不做过多的讨论(当然此处可以对比不同距离之间的差别)
|
||||
|
||||
> 训练算法: 通过调用 recommend() 函数进行推荐
|
||||
|
||||
recommend() 会调用 基于物品相似度 或者是 基于SVD,得到推荐的物品评分。
|
||||
|
||||
* 1.基于物品相似度
|
||||
|
||||
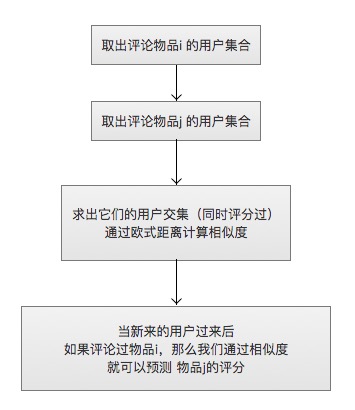
|
||||
|
||||

|
||||
|
||||
```python
|
||||
# 基于物品相似度的推荐引擎
|
||||
def standEst(dataMat, user, simMeas, item):
|
||||
"""standEst(计算某用户未评分物品中,以对该物品和其他物品评分的用户的物品相似度,然后进行综合评分)
|
||||
|
||||
Args:
|
||||
dataMat 训练数据集
|
||||
user 用户编号
|
||||
simMeas 相似度计算方法
|
||||
item 未评分的物品编号
|
||||
Returns:
|
||||
ratSimTotal/simTotal 评分(0~5之间的值)
|
||||
"""
|
||||
# 得到数据集中的物品数目
|
||||
n = shape(dataMat)[1]
|
||||
# 初始化两个评分值
|
||||
simTotal = 0.0
|
||||
ratSimTotal = 0.0
|
||||
# 遍历行中的每个物品(对用户评过分的物品进行遍历,并将它与其他物品进行比较)
|
||||
for j in range(n):
|
||||
userRating = dataMat[user, j]
|
||||
# 如果某个物品的评分值为0,则跳过这个物品
|
||||
if userRating == 0:
|
||||
continue
|
||||
# 寻找两个用户都评级的物品
|
||||
# 变量 overLap 给出的是两个物品当中已经被评分的那个元素的索引ID
|
||||
# logical_and 计算x1和x2元素的真值。
|
||||
overLap = nonzero(logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0]
|
||||
# 如果相似度为0,则两着没有任何重合元素,终止本次循环
|
||||
if len(overLap) == 0:
|
||||
similarity = 0
|
||||
# 如果存在重合的物品,则基于这些重合物重新计算相似度。
|
||||
else:
|
||||
similarity = simMeas(dataMat[overLap, item], dataMat[overLap, j])
|
||||
# print 'the %d and %d similarity is : %f'(iten,j,similarity)
|
||||
# 相似度会不断累加,每次计算时还考虑相似度和当前用户评分的乘积
|
||||
# similarity 用户相似度, userRating 用户评分
|
||||
simTotal += similarity
|
||||
ratSimTotal += similarity * userRating
|
||||
if simTotal == 0:
|
||||
return 0
|
||||
# 通过除以所有的评分总和,对上述相似度评分的乘积进行归一化,使得最后评分在0~5之间,这些评分用来对预测值进行排序
|
||||
else:
|
||||
return ratSimTotal/simTotal
|
||||
```
|
||||
|
||||
* 2.基于SVD(参考地址:http://www.codeweblog.com/svd-%E7%AC%94%E8%AE%B0/)
|
||||
|
||||
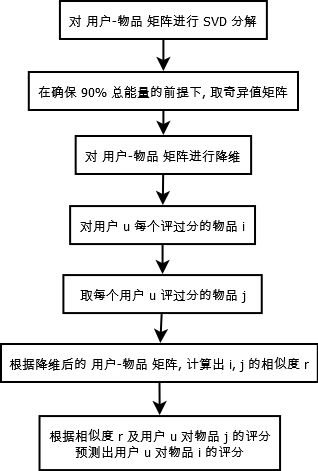
|
||||
|
||||
```python
|
||||
# 基于SVD的评分估计
|
||||
# 在recommend() 中,这个函数用于替换对standEst()的调用,该函数对给定用户给定物品构建了一个评分估计值
|
||||
def svdEst(dataMat, user, simMeas, item):
|
||||
"""svdEst(计算某用户未评分物品中,以对该物品和其他物品评分的用户的物品相似度,然后进行综合评分)
|
||||
|
||||
Args:
|
||||
dataMat 训练数据集
|
||||
user 用户编号
|
||||
simMeas 相似度计算方法
|
||||
item 未评分的物品编号
|
||||
Returns:
|
||||
ratSimTotal/simTotal 评分(0~5之间的值)
|
||||
"""
|
||||
# 物品数目
|
||||
n = shape(dataMat)[1]
|
||||
# 对数据集进行SVD分解
|
||||
simTotal = 0.0
|
||||
ratSimTotal = 0.0
|
||||
# 奇异值分解
|
||||
# 在SVD分解之后,我们只利用包含了90%能量值的奇异值,这些奇异值会以NumPy数组的形式得以保存
|
||||
U, Sigma, VT = la.svd(dataMat)
|
||||
|
||||
# # 分析 Sigma 的长度取值
|
||||
# analyse_data(Sigma, 20)
|
||||
|
||||
# 如果要进行矩阵运算,就必须要用这些奇异值构建出一个对角矩阵
|
||||
Sig4 = mat(eye(4) * Sigma[: 4])
|
||||
# 利用U矩阵将物品转换到低维空间中,构建转换后的物品(物品+4个主要的特征)
|
||||
xformedItems = dataMat.T * U[:, :4] * Sig4.I
|
||||
# 对于给定的用户,for循环在用户对应行的元素上进行遍历,
|
||||
# 这和standEst()函数中的for循环的目的一样,只不过这里的相似度计算时在低维空间下进行的。
|
||||
for j in range(n):
|
||||
userRating = dataMat[user, j]
|
||||
if userRating == 0 or j == item:
|
||||
continue
|
||||
# 相似度的计算方法也会作为一个参数传递给该函数
|
||||
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
|
||||
# for 循环中加入了一条print语句,以便了解相似度计算的进展情况。如果觉得累赘,可以去掉
|
||||
print 'the %d and %d similarity is: %f' % (item, j, similarity)
|
||||
# 对相似度不断累加求和
|
||||
simTotal += similarity
|
||||
# 对相似度及对应评分值的乘积求和
|
||||
ratSimTotal += similarity * userRating
|
||||
if simTotal == 0:
|
||||
return 0
|
||||
else:
|
||||
# 计算估计评分
|
||||
return ratSimTotal/simTotal
|
||||
```
|
||||
|
||||
排序获取最后的推荐结果
|
||||
|
||||
```python
|
||||
# recommend()函数,就是推荐引擎,它默认调用standEst()函数,产生了最高的N个推荐结果。
|
||||
# 如果不指定N的大小,则默认值为3。该函数另外的参数还包括相似度计算方法和估计方法
|
||||
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
|
||||
# 寻找未评级的物品
|
||||
# 对给定的用户建立一个未评分的物品列表
|
||||
unratedItems = nonzero(dataMat[user, :].A == 0)[1]
|
||||
# 如果不存在未评分物品,那么就退出函数
|
||||
if len(unratedItems) == 0:
|
||||
return 'you rated everything'
|
||||
# 物品的编号和评分值
|
||||
itemScores = []
|
||||
# 在未评分物品上进行循环
|
||||
for item in unratedItems:
|
||||
estimatedScore = estMethod(dataMat, user, simMeas, item)
|
||||
# 寻找前N个未评级物品,调用standEst()来产生该物品的预测得分,该物品的编号和估计值会放在一个元素列表itemScores中
|
||||
itemScores.append((item, estimatedScore))
|
||||
# 按照估计得分,对该列表进行排序并返回。列表逆排序,第一个值就是最大值
|
||||
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[: N]
|
||||
```
|
||||
|
||||
> 测试 和 项目调用,可直接参考我们的代码
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/14.SVD/svdRecommend.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/14.SVD/svdRecommend.py>
|
||||
|
||||
#### 要点补充
|
||||
|
||||
> 基于内容(content-based)的推荐
|
||||
|
||||
1. 通过各种标签来标记菜肴
|
||||
2. 将这些属性作为相似度计算所需要的数据
|
||||
3. 这就是:基于内容的推荐。
|
||||
|
||||
> 构建推荐引擎面临的挑战
|
||||
|
||||
问题
|
||||
* 1)在大规模的数据集上,SVD分解会降低程序的速度
|
||||
* 2)存在其他很多规模扩展性的挑战性问题,比如矩阵的表示方法和计算相似度得分消耗资源。
|
||||
* 3)如何在缺乏数据时给出好的推荐-称为冷启动【简单说:用户不会喜欢一个无效的物品,而用户不喜欢的物品又无效】
|
||||
|
||||
建议
|
||||
* 1)在大型系统中,SVD分解(可以在程序调入时运行一次)每天运行一次或者其频率更低,并且还要离线运行。
|
||||
* 2)在实际中,另一个普遍的做法就是离线计算并保存相似度得分。(物品相似度可能被用户重复的调用)
|
||||
* 3)冷启动问题,解决方案就是将推荐看成是搜索问题,通过各种标签/属性特征进行`基于内容的推荐`。
|
||||
|
||||
### 项目案例: 基于 SVD 的图像压缩
|
||||
|
||||
> 收集 并 准备数据
|
||||
|
||||
将文本数据转化为矩阵
|
||||
|
||||
```python
|
||||
# 加载并转换数据
|
||||
def imgLoadData(filename):
|
||||
myl = []
|
||||
# 打开文本文件,并从文件以数组方式读入字符
|
||||
for line in open(filename).readlines():
|
||||
newRow = []
|
||||
for i in range(32):
|
||||
newRow.append(int(line[i]))
|
||||
myl.append(newRow)
|
||||
# 矩阵调入后,就可以在屏幕上输出该矩阵
|
||||
myMat = mat(myl)
|
||||
return myMat
|
||||
```
|
||||
|
||||
> 分析数据: 分析 Sigma 的长度个数
|
||||
|
||||
通常保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并去除噪声。
|
||||
|
||||
```python
|
||||
def analyse_data(Sigma, loopNum=20):
|
||||
"""analyse_data(分析 Sigma 的长度取值)
|
||||
|
||||
Args:
|
||||
Sigma Sigma的值
|
||||
loopNum 循环次数
|
||||
"""
|
||||
# 总方差的集合(总能量值)
|
||||
Sig2 = Sigma**2
|
||||
SigmaSum = sum(Sig2)
|
||||
for i in range(loopNum):
|
||||
SigmaI = sum(Sig2[:i+1])
|
||||
'''
|
||||
根据自己的业务情况,就行处理,设置对应的 Singma 次数
|
||||
|
||||
通常保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并取出噪声。
|
||||
'''
|
||||
print '主成分:%s, 方差占比:%s%%' % (format(i+1, '2.0f'), format(SigmaI/SigmaSum*100, '4.2f'))
|
||||
```
|
||||
|
||||
> 使用算法: 对比使用 SVD 前后的数据差异对比,对于存储大家可以试着写写
|
||||
|
||||
|
||||
例如:`32*32=1024 => 32*2+2*1+32*2=130`(2*1表示去掉了除对角线的0), 几乎获得了10倍的压缩比。
|
||||
|
||||
```python
|
||||
# 打印矩阵
|
||||
def printMat(inMat, thresh=0.8):
|
||||
# 由于矩阵保护了浮点数,因此定义浅色和深色,遍历所有矩阵元素,当元素大于阀值时打印1,否则打印0
|
||||
for i in range(32):
|
||||
for k in range(32):
|
||||
if float(inMat[i, k]) > thresh:
|
||||
print 1,
|
||||
else:
|
||||
print 0,
|
||||
print ''
|
||||
|
||||
|
||||
# 实现图像压缩,允许基于任意给定的奇异值数目来重构图像
|
||||
def imgCompress(numSV=3, thresh=0.8):
|
||||
"""imgCompress( )
|
||||
|
||||
Args:
|
||||
numSV Sigma长度
|
||||
thresh 判断的阈值
|
||||
"""
|
||||
# 构建一个列表
|
||||
myMat = imgLoadData('data/14.SVD/0_5.txt')
|
||||
|
||||
print "****original matrix****"
|
||||
# 对原始图像进行SVD分解并重构图像e
|
||||
printMat(myMat, thresh)
|
||||
|
||||
# 通过Sigma 重新构成SigRecom来实现
|
||||
# Sigma是一个对角矩阵,因此需要建立一个全0矩阵,然后将前面的那些奇异值填充到对角线上。
|
||||
U, Sigma, VT = la.svd(myMat)
|
||||
# SigRecon = mat(zeros((numSV, numSV)))
|
||||
# for k in range(numSV):
|
||||
# SigRecon[k, k] = Sigma[k]
|
||||
|
||||
# 分析插入的 Sigma 长度
|
||||
analyse_data(Sigma, 20)
|
||||
|
||||
SigRecon = mat(eye(numSV) * Sigma[: numSV])
|
||||
reconMat = U[:, :numSV] * SigRecon * VT[:numSV, :]
|
||||
print "****reconstructed matrix using %d singular values *****" % numSV
|
||||
printMat(reconMat, thresh)
|
||||
```
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/14.SVD/svdRecommend.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/14.SVD/svdRecommend.py>
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [1988](http://cwiki.apachecn.org/display/~lihuisong)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,223 @@
|
|||
# 第15章 大数据与MapReduce
|
||||
|
||||

|
||||
|
||||
## 大数据 概述
|
||||
|
||||
`大数据: 收集到的数据已经远远超出了我们的处理能力。`
|
||||
|
||||
|
||||
## 大数据 场景
|
||||
|
||||
```
|
||||
假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。
|
||||
对于你来说,可能很想识别那些有购物意愿的用户。
|
||||
那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。
|
||||
接下来:我们讲讲 MapRedece 如何来解决这样的问题
|
||||
```
|
||||
|
||||
|
||||
## MapRedece
|
||||
|
||||
### Hadoop 概述
|
||||
|
||||
```
|
||||
Hadoop 是 MapRedece 框架的一个免费开源实现。
|
||||
MapReduce: 分布式的计算框架,可以将单个计算作业分配给多台计算机执行。
|
||||
```
|
||||
|
||||
### MapRedece 原理
|
||||
|
||||
> MapRedece 工作原理
|
||||
|
||||
* 主节点控制 MapReduce 的作业流程
|
||||
* MapReduce 的作业可以分成map任务和reduce任务
|
||||
* map 任务之间不做数据交流,reduce 任务也一样
|
||||
* 在 map 和 reduce 阶段中间,有一个 sort 和 combine 阶段
|
||||
* 数据被重复存放在不同的机器上,以防止某个机器失效
|
||||
* mapper 和 reducer 传输的数据形式为 key/value对
|
||||
|
||||

|
||||
|
||||
> MapRedece 特点
|
||||
|
||||
```
|
||||
优点: 使程序以并行的方式执行,可在短时间内完成大量工作。
|
||||
缺点: 算法必须经过重写,需要对系统工程有一定的理解。
|
||||
适用数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
### Hadoop 流(Python 调用)
|
||||
|
||||
> 理论简介
|
||||
|
||||
例如: Hadoop流可以像Linux命令一样执行
|
||||
|
||||
```Shell
|
||||
cat inputFile.txt | python mapper.py | sort | python reducer.py > outputFile.txt
|
||||
```
|
||||
|
||||
类似的Hadoop流就可以在多台机器上分布式执行,用户可以通过Linux命令来测试Python语言编写的MapReduce脚本。
|
||||
|
||||
> 实战脚本
|
||||
|
||||
```
|
||||
# 测试 Mapper
|
||||
# Linux
|
||||
cat data/15.BigData_MapReduce/inputFile.txt | python src/python/15.BigData_MapReduce/mrMeanMapper.py
|
||||
# Window
|
||||
# python src/python/15.BigData_MapReduce/mrMeanMapper.py < data/15.BigData_MapReduce/inputFile.txt
|
||||
|
||||
# 测试 Reducer
|
||||
# Linux
|
||||
cat data/15.BigData_MapReduce/inputFile.txt | python src/python/15.BigData_MapReduce/mrMeanMapper.py | python src/python/15.BigData_MapReduce/mrMeanReducer.py
|
||||
# Window
|
||||
# python src/python/15.BigData_MapReduce/mrMeanMapper.py < data/15.BigData_MapReduce/inputFile.txt | python src/python/15.BigData_MapReduce/mrMeanReducer.py
|
||||
```
|
||||
|
||||
### MapReduce 机器学习
|
||||
|
||||
#### Mahout in Action
|
||||
|
||||
1. 简单贝叶斯:它属于为数不多的可以很自然的使用MapReduce的算法。通过统计在某个类别下某特征的概率。
|
||||
2. k-近邻算法:高维数据下(如文本、图像和视频)流行的近邻查找方法是局部敏感哈希算法。
|
||||
3. 支持向量机(SVM):使用随机梯度下降算法求解,如Pegasos算法。
|
||||
4. 奇异值分解:Lanczos算法是一个有效的求解近似特征值的算法。
|
||||
5. k-均值聚类:canopy算法初始化k个簇,然后再运行K-均值求解结果。
|
||||
|
||||
### 使用 mrjob 库将 MapReduce 自动化
|
||||
|
||||
> 理论简介
|
||||
|
||||
* MapReduce 作业流自动化的框架:Cascading 和 Oozie.
|
||||
* mrjob 是一个不错的学习工具,与2010年底实现了开源,来之于 Yelp(一个餐厅点评网站).
|
||||
|
||||
```Shell
|
||||
python src/python/15.BigData_MapReduce/mrMean.py < data/15.BigData_MapReduce/inputFile.txt > data/15.BigData_MapReduce/myOut.txt
|
||||
```
|
||||
|
||||
> 实战脚本
|
||||
|
||||
```
|
||||
# 测试 mrjob的案例
|
||||
# 先测试一下mapper方法
|
||||
# python src/python/15.BigData_MapReduce/mrMean.py --mapper < data/15.BigData_MapReduce/inputFile.txt
|
||||
# 运行整个程序,移除 --mapper 就行
|
||||
python src/python/15.BigData_MapReduce/mrMean.py < data/15.BigData_MapReduce/inputFile.txt
|
||||
```
|
||||
|
||||
### 项目案例:分布式 SVM 的 Pegasos 算法
|
||||
|
||||
Pegasos是指原始估计梯度求解器(Peimal Estimated sub-GrAdient Solver)
|
||||
|
||||
#### Pegasos 工作原理
|
||||
|
||||
1. 从训练集中随机挑选一些样本点添加到待处理列表中
|
||||
2. 按序判断每个样本点是否被正确分类
|
||||
* 如果是则忽略
|
||||
* 如果不是则将其加入到待更新集合。
|
||||
3. 批处理完毕后,权重向量按照这些错分的样本进行更新。
|
||||
|
||||
上述算法伪代码如下:
|
||||
|
||||
```
|
||||
将 回归系数w 初始化为0
|
||||
对每次批处理
|
||||
随机选择 k 个样本点(向量)
|
||||
对每个向量
|
||||
如果该向量被错分:
|
||||
更新权重向量 w
|
||||
累加对 w 的更新
|
||||
```
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:数据按文本格式存放。
|
||||
准备数据:输入数据已经是可用的格式,所以不需任何准备工作。如果你需要解析一个大规模的数据集,建议使用 map 作业来完成,从而达到并行处理的目的。
|
||||
分析数据:无。
|
||||
训练算法:与普通的 SVM 一样,在分类器训练上仍需花费大量的时间。
|
||||
测试算法:在二维空间上可视化之后,观察超平面,判断算法是否有效。
|
||||
使用算法:本例不会展示一个完整的应用,但会展示如何在大数据集上训练SVM。该算法其中一个应用场景就是本文分类,通常在文本分类里可能有大量的文档和成千上万的特征。
|
||||
```
|
||||
|
||||
> 收集数据
|
||||
|
||||
文本文件数据格式如下:
|
||||
|
||||
```python
|
||||
0.365032 2.465645 -1
|
||||
-2.494175 -0.292380 -1
|
||||
-3.039364 -0.123108 -1
|
||||
1.348150 0.255696 1
|
||||
2.768494 1.234954 1
|
||||
1.232328 -0.601198 1
|
||||
```
|
||||
|
||||
> 准备数据
|
||||
|
||||
```python
|
||||
def loadDataSet(fileName):
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
# dataMat.append([float(lineArr[0]), float(lineArr[1]), float(lineArr[2])])
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
```
|
||||
|
||||
> 分析数据: 无
|
||||
|
||||
> 训练算法
|
||||
|
||||
```python
|
||||
def batchPegasos(dataSet, labels, lam, T, k):
|
||||
"""batchPegasos()
|
||||
|
||||
Args:
|
||||
dataMat 特征集合
|
||||
labels 分类结果集合
|
||||
lam 固定值
|
||||
T 迭代次数
|
||||
k 待处理列表大小
|
||||
Returns:
|
||||
w 回归系数
|
||||
"""
|
||||
m, n = shape(dataSet)
|
||||
w = zeros(n) # 回归系数
|
||||
dataIndex = range(m)
|
||||
for t in range(1, T+1):
|
||||
wDelta = mat(zeros(n)) # 重置 wDelta
|
||||
|
||||
# 它是学习率,代表了权重调整幅度的大小。(也可以理解为随机梯度的步长,使它不断减小,便于拟合)
|
||||
# 输入T和K分别设定了迭代次数和待处理列表的大小。在T次迭代过程中,每次需要重新计算eta
|
||||
eta = 1.0/(lam*t)
|
||||
random.shuffle(dataIndex)
|
||||
for j in range(k): # 全部的训练集 内循环中执行批处理,将分类错误的值全部做累加后更新权重向量
|
||||
i = dataIndex[j]
|
||||
p = predict(w, dataSet[i, :]) # mapper 代码
|
||||
|
||||
# 如果预测正确,并且预测结果的绝对值>=1,因为最大间隔为1, 认为没问题。
|
||||
# 否则算是预测错误, 通过预测错误的结果,来累计更新w.
|
||||
if labels[i]*p < 1: # mapper 代码
|
||||
wDelta += labels[i]*dataSet[i, :].A # 累积变化
|
||||
# w通过不断的随机梯度的方式来优化
|
||||
w = (1.0 - 1/t)*w + (eta/k)*wDelta # 在每个 T上应用更改
|
||||
# print '-----', w
|
||||
# print '++++++', w
|
||||
return w
|
||||
```
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/pegasos.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/pegasos.py>
|
||||
|
||||
运行方式:`python /opt/git/MachineLearning/src/python/15.BigData_MapReduce/mrSVM.py < data/15.BigData_MapReduce/inputFile.txt`
|
||||
[MR版本的代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/mrSVM.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/15.BigData_MapReduce/mrSVM.py>
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,86 @@
|
|||
# 第16章 推荐系统
|
||||
|
||||
## 背景与挖掘目标
|
||||
|
||||
随着互联网的快速发展,用户很难快速从海量信息中寻找到自己感兴趣的信息。因此诞生了:搜索引擎+推荐系统
|
||||
|
||||
本章节-推荐系统:
|
||||
|
||||
1. 帮助用户发现其感兴趣和可能感兴趣的信息。
|
||||
2. 让网站价值信息脱颖而出,得到广大用户的认可。
|
||||
3. 提高用户对网站的忠诚度和关注度,建立稳固用户群体。
|
||||
|
||||
## 分析方法与过程
|
||||
|
||||
本案例的目标是对用户进行推荐,即以一定的方式将用户与物品(本次指网页)之间建立联系。
|
||||
|
||||
由于用户访问网站的数据记录很多,如果不对数据进行分类处理,对所有的记录直接采用推荐系统进行推荐,这样会存在一下问题。
|
||||
|
||||
1. 数据量太大意味着物品数与用户数很多,在模型构建用户与物品稀疏矩阵时,出现设备内存空间不够的情况,并且模型计算需要消耗大量的时间。
|
||||
2. 用户区别很大,不同的用户关注的信息不一样,因此,即使能够得到推荐结果,其效果也会不好。
|
||||
|
||||
为了避免出现上述问题,需要进行分类处理与分析。
|
||||
|
||||
正常的情况下,需要对用户的兴趣爱好以及需求进行分类。
|
||||
因为在用户访问记录中,没有记录用户访问页面时间的长短,因此不容易判断用户兴趣爱好。
|
||||
因此,本文根据用户浏览的网页信息进行分析处理,主要采用以下方法处理:以用户浏览网页的类型进行分类,然后对每个类型中的内容进行推荐。
|
||||
|
||||
分析过程如下:
|
||||
|
||||
* 从系统中获取用户访问网站的原始记录。
|
||||
* 对数据进行多维分析,包括用户访问内容,流失用户分析以及用户分类等分析。
|
||||
* 对数据进行预处理,包含数据去重、数据变换和数据分类鞥处理过程。
|
||||
* 以用户访问html后缀的页面为关键条件,对数据进行处理。
|
||||
* 对比多种推荐算法进行推荐,通过模型评价,得到比较好的智能推荐模型。通过模型对样本数据进行预测,获得推荐结果。
|
||||
|
||||
|
||||
|
||||
## 主流推荐算法
|
||||
|
||||
| 推荐方法 | 描述 |
|
||||
| --- | --- |
|
||||
| 基于内容推荐 | |
|
||||
| 协同过滤推荐 | |
|
||||
| 基于规则推荐 | |
|
||||
| 基于效用推荐 | |
|
||||
| 基于知识推荐 | |
|
||||
| 组合推荐 | |
|
||||
|
||||
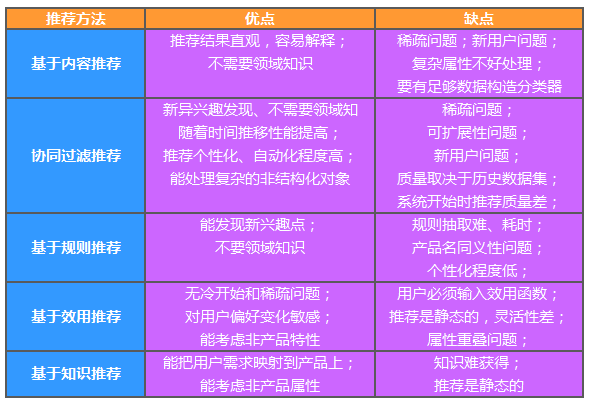
|
||||
|
||||
### 基于知识推荐
|
||||
|
||||
基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因它们所用的功能知识不同而有明显区别。效用知识(Functional Knowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。
|
||||
|
||||
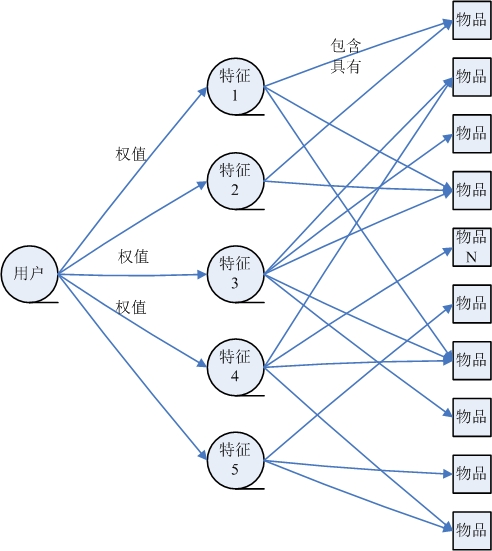
|
||||
|
||||
### 协同过滤推荐
|
||||
|
||||
* memory-based推荐
|
||||
* Item-based方法
|
||||
* User-based方法
|
||||
* Memory-based推荐方法通过执行最近邻搜索,把每一个Item或者User看成一个向量,计算其他所有Item或者User与它的相似度。有了Item或者User之间的两两相似度之后,就可以进行预测与推荐了。
|
||||
* model-based推荐
|
||||
* Model-based推荐最常见的方法为Matrix factorization.
|
||||
* 矩阵分解通过把原始的评分矩阵R分解为两个矩阵相乘,并且只考虑有评分的值,训练时不考虑missing项的值。R矩阵分解成为U与V两个矩阵后,评分矩阵R中missing的值就可以通过U矩阵中的某列和V矩阵的某行相乘得到
|
||||
* 矩阵分解的目标函数: U矩阵与V矩阵的可以通过梯度下降(gradient descent)算法求得,通过交替更新u与v多次迭代收敛之后可求出U与V。
|
||||
* 矩阵分解背后的核心思想,找到两个矩阵,它们相乘之后得到的那个矩阵的值,与评分矩阵R中有值的位置中的值尽可能接近。这样一来,分解出来的两个矩阵相乘就尽可能还原了评分矩阵R,因为有值的地方,值都相差得尽可能地小,那么missing的值通过这样的方式计算得到,比较符合趋势。
|
||||
* 协同过滤中主要存在如下两个问题:稀疏性与冷启动问题。已有的方案通常会通过引入多个不同的数据源或者辅助信息(Side information)来解决这些问题,用户的Side information可以是用户的基本个人信息、用户画像信息等,而Item的Side information可以是物品的content信息等。
|
||||
|
||||
## 效果评估
|
||||
|
||||
1. 召回率和准确率 【人为统计分析】
|
||||
2. F值(P-R曲线) 【偏重:非均衡问题】
|
||||
3. ROC和AUC 【偏重:不同结果的对比】
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
> 摘录的原文地址:
|
||||
|
||||
* [推荐系统中常用算法 以及优点缺点对比](http://www.36dsj.com/archives/9519)
|
||||
* [推荐算法的基于知识推荐](https://zhidao.baidu.com/question/2013524494179442228.html)
|
||||
* [推荐系统中基于深度学习的混合协同过滤模型](http://www.iteye.com/news/32100)
|
||||
|
|
@ -0,0 +1,567 @@
|
|||
# 第2章 k-近邻算法
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## KNN 概述
|
||||
|
||||
`k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。`
|
||||
|
||||
**一句话总结:近朱者赤近墨者黑!**
|
||||
|
||||
`k 近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k 近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。`
|
||||
|
||||
`k 近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。`
|
||||
|
||||
## KNN 场景
|
||||
|
||||
电影可以按照题材分类,那么如何区分 `动作片` 和 `爱情片` 呢?<br/>
|
||||
1. 动作片:打斗次数更多
|
||||
2. 爱情片:亲吻次数更多
|
||||
|
||||
基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。
|
||||
|
||||

|
||||
|
||||
```
|
||||
现在根据上面我们得到的样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。
|
||||
假定 k=3,则三个最靠近的电影依次是, He's Not Really into Dudes 、 Beautiful Woman 和 California Man。
|
||||
knn 算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
|
||||
```
|
||||
|
||||
## KNN 原理
|
||||
|
||||
> KNN 工作原理
|
||||
|
||||
1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
|
||||
2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
|
||||
1. 计算新数据与样本数据集中每条数据的距离。
|
||||
2. 对求得的所有距离进行排序(从小到大,越小表示越相似)。
|
||||
3. 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
|
||||
3. 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
|
||||
|
||||
> KNN 通俗理解
|
||||
|
||||
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
|
||||
|
||||
> KNN 开发流程
|
||||
|
||||
```
|
||||
收集数据:任何方法
|
||||
准备数据:距离计算所需要的数值,最好是结构化的数据格式
|
||||
分析数据:任何方法
|
||||
训练算法:此步骤不适用于 k-近邻算法
|
||||
测试算法:计算错误率
|
||||
使用算法:输入样本数据和结构化的输出结果,然后运行 k-近邻算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
```
|
||||
|
||||
> KNN 算法特点
|
||||
|
||||
```
|
||||
优点:精度高、对异常值不敏感、无数据输入假定
|
||||
缺点:计算复杂度高、空间复杂度高
|
||||
适用数据范围:数值型和标称型
|
||||
```
|
||||
|
||||
## KNN 项目案例
|
||||
|
||||
### 项目案例1: 优化约会网站的配对效果
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/2.KNN/kNN.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/2.KNN/kNN.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人:
|
||||
* 不喜欢的人
|
||||
* 魅力一般的人
|
||||
* 极具魅力的人
|
||||
|
||||
她希望:
|
||||
1. 工作日与魅力一般的人约会
|
||||
2. 周末与极具魅力的人约会
|
||||
3. 不喜欢的人则直接排除掉
|
||||
|
||||
现在她收集到了一些约会网站未曾记录的数据信息,这更有助于匹配对象的归类。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供文本文件
|
||||
准备数据:使用 Python 解析文本文件
|
||||
分析数据:使用 Matplotlib 画二维散点图
|
||||
训练算法:此步骤不适用于 k-近邻算法
|
||||
测试算法:使用海伦提供的部分数据作为测试样本。
|
||||
测试样本和非测试样本的区别在于:
|
||||
测试样本是已经完成分类的数据,如果预测分类与实际类别不同,则标记为一个错误。
|
||||
使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
```
|
||||
|
||||
> 收集数据:提供文本文件
|
||||
|
||||
海伦把这些约会对象的数据存放在文本文件 [datingTestSet2.txt](/data/2.KNN/datingTestSet2.txt) 中,总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
|
||||
|
||||
* 每年获得的飞行常客里程数
|
||||
* 玩视频游戏所耗时间百分比
|
||||
* 每周消费的冰淇淋公升数
|
||||
|
||||
文本文件数据格式如下:
|
||||
```
|
||||
40920 8.326976 0.953952 3
|
||||
14488 7.153469 1.673904 2
|
||||
26052 1.441871 0.805124 1
|
||||
75136 13.147394 0.428964 1
|
||||
38344 1.669788 0.134296 1
|
||||
```
|
||||
> 准备数据:使用 Python 解析文本文件
|
||||
|
||||
将文本记录转换为 NumPy 的解析程序
|
||||
|
||||
```python
|
||||
def file2matrix(filename):
|
||||
"""
|
||||
Desc:
|
||||
导入训练数据
|
||||
parameters:
|
||||
filename: 数据文件路径
|
||||
return:
|
||||
数据矩阵 returnMat 和对应的类别 classLabelVector
|
||||
"""
|
||||
fr = open(filename)
|
||||
# 获得文件中的数据行的行数
|
||||
numberOfLines = len(fr.readlines())
|
||||
# 生成对应的空矩阵
|
||||
# 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
|
||||
returnMat = zeros((numberOfLines, 3)) # prepare matrix to return
|
||||
classLabelVector = [] # prepare labels return
|
||||
fr = open(filename)
|
||||
index = 0
|
||||
for line in fr.readlines():
|
||||
# str.strip([chars]) --返回已移除字符串头尾指定字符所生成的新字符串
|
||||
line = line.strip()
|
||||
# 以 '\t' 切割字符串
|
||||
listFromLine = line.split('\t')
|
||||
# 每列的属性数据
|
||||
returnMat[index, :] = listFromLine[0:3]
|
||||
# 每列的类别数据,就是 label 标签数据
|
||||
classLabelVector.append(int(listFromLine[-1]))
|
||||
index += 1
|
||||
# 返回数据矩阵returnMat和对应的类别classLabelVector
|
||||
return returnMat, classLabelVector
|
||||
```
|
||||
|
||||
> 分析数据:使用 Matplotlib 画二维散点图
|
||||
|
||||
```python
|
||||
import matplotlib
|
||||
import matplotlib.pyplot as plt
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.scatter(datingDataMat[:, 0], datingDataMat[:, 1], 15.0*array(datingLabels), 15.0*array(datingLabels))
|
||||
plt.show()
|
||||
```
|
||||
|
||||
下图中采用矩阵的第一和第二列属性得到很好的展示效果,清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。
|
||||
|
||||
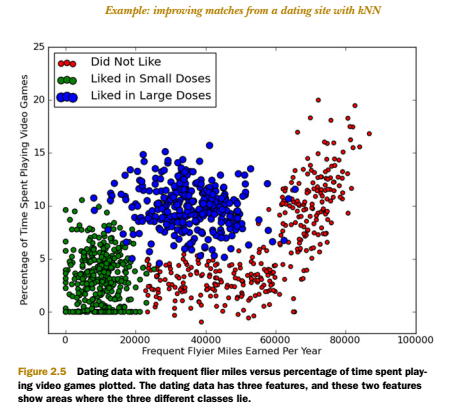
|
||||
|
||||
* 归一化数据 (归一化是一个让权重变为统一的过程,更多细节请参考: https://www.zhihu.com/question/19951858 )
|
||||
|
||||
| 序号 | 玩视频游戏所耗时间百分比 | 每年获得的飞行常客里程数 | 每周消费的冰淇淋公升数 | 样本分类 |
|
||||
| ------------- |:-------------:| -----:| -----:| -----:|
|
||||
| 1 | 0.8 | 400 | 0.5 | 1 |
|
||||
| 2 | 12 | 134 000 | 0.9 | 3 |
|
||||
| 3 | 0 | 20 000 | 1.1 | 2 |
|
||||
| 4 | 67 | 32 000 | 0.1 | 2 |
|
||||
|
||||
样本3和样本4的距离:
|
||||
$$\sqrt{(0-67)^2 + (20000-32000)^2 + (1.1-0.1)^2 }$$
|
||||
|
||||
归一化特征值,消除特征之间量级不同导致的影响
|
||||
|
||||
**归一化定义:** 我是这样认为的,归一化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。 方法有如下:
|
||||
|
||||
1) 线性函数转换,表达式如下:
|
||||
|
||||
y=(x-MinValue)/(MaxValue-MinValue)
|
||||
|
||||
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
|
||||
|
||||
2) 对数函数转换,表达式如下:
|
||||
|
||||
y=log10(x)
|
||||
|
||||
说明:以10为底的对数函数转换。
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
3) 反余切函数转换,表达式如下:
|
||||
|
||||
y=arctan(x)*2/PI
|
||||
|
||||
如图:
|
||||
|
||||
|
||||
|
||||
4) 式(1)将输入值换算为[-1,1]区间的值,在输出层用式(2)换算回初始值,其中和分别表示训练样本集中负荷的最大值和最小值。
|
||||
|
||||
|
||||
在统计学中,归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。
|
||||
|
||||
|
||||
```python
|
||||
def autoNorm(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
归一化特征值,消除特征之间量级不同导致的影响
|
||||
parameter:
|
||||
dataSet: 数据集
|
||||
return:
|
||||
归一化后的数据集 normDataSet. ranges和minVals即最小值与范围,并没有用到
|
||||
|
||||
归一化公式:
|
||||
Y = (X-Xmin)/(Xmax-Xmin)
|
||||
其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。
|
||||
"""
|
||||
# 计算每种属性的最大值、最小值、范围
|
||||
minVals = dataSet.min(0)
|
||||
maxVals = dataSet.max(0)
|
||||
# 极差
|
||||
ranges = maxVals - minVals
|
||||
normDataSet = zeros(shape(dataSet))
|
||||
m = dataSet.shape[0]
|
||||
# 生成与最小值之差组成的矩阵
|
||||
normDataSet = dataSet - tile(minVals, (m, 1))
|
||||
# 将最小值之差除以范围组成矩阵
|
||||
normDataSet = normDataSet / tile(ranges, (m, 1)) # element wise divide
|
||||
return normDataSet, ranges, minVals
|
||||
```
|
||||
|
||||
> 训练算法:此步骤不适用于 k-近邻算法
|
||||
|
||||
因为测试数据每一次都要与全量的训练数据进行比较,所以这个过程是没有必要的。
|
||||
|
||||
kNN 算法伪代码:
|
||||
|
||||
对于每一个在数据集中的数据点:
|
||||
计算目标的数据点(需要分类的数据点)与该数据点的距离
|
||||
将距离排序:从小到大
|
||||
选取前K个最短距离
|
||||
选取这K个中最多的分类类别
|
||||
返回该类别来作为目标数据点的预测值
|
||||
```python
|
||||
def classify0(inX, dataSet, labels, k):
|
||||
dataSetSize = dataSet.shape[0]
|
||||
#距离度量 度量公式为欧氏距离
|
||||
diffMat = tile(inX, (dataSetSize,1)) – dataSet
|
||||
sqDiffMat = diffMat**2
|
||||
sqDistances = sqDiffMat.sum(axis=1)
|
||||
distances = sqDistances**0.5
|
||||
|
||||
#将距离排序:从小到大
|
||||
sortedDistIndicies = distances.argsort()
|
||||
#选取前K个最短距离, 选取这K个中最多的分类类别
|
||||
classCount={}
|
||||
for i in range(k):
|
||||
voteIlabel = labels[sortedDistIndicies[i]]
|
||||
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
|
||||
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
|
||||
return sortedClassCount[0][0]
|
||||
```
|
||||
|
||||
|
||||
> 测试算法:使用海伦提供的部分数据作为测试样本。如果预测分类与实际类别不同,则标记为一个错误。
|
||||
|
||||
kNN 分类器针对约会网站的测试代码
|
||||
|
||||
```python
|
||||
def datingClassTest():
|
||||
"""
|
||||
Desc:
|
||||
对约会网站的测试方法
|
||||
parameters:
|
||||
none
|
||||
return:
|
||||
错误数
|
||||
"""
|
||||
# 设置测试数据的的一个比例(训练数据集比例=1-hoRatio)
|
||||
hoRatio = 0.1 # 测试范围,一部分测试一部分作为样本
|
||||
# 从文件中加载数据
|
||||
datingDataMat, datingLabels = file2matrix('data/2.KNN/datingTestSet2.txt') # load data setfrom file
|
||||
# 归一化数据
|
||||
normMat, ranges, minVals = autoNorm(datingDataMat)
|
||||
# m 表示数据的行数,即矩阵的第一维
|
||||
m = normMat.shape[0]
|
||||
# 设置测试的样本数量, numTestVecs:m表示训练样本的数量
|
||||
numTestVecs = int(m * hoRatio)
|
||||
print 'numTestVecs=', numTestVecs
|
||||
errorCount = 0.0
|
||||
for i in range(numTestVecs):
|
||||
# 对数据测试
|
||||
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
|
||||
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
|
||||
if (classifierResult != datingLabels[i]): errorCount += 1.0
|
||||
print "the total error rate is: %f" % (errorCount / float(numTestVecs))
|
||||
print errorCount
|
||||
```
|
||||
|
||||
> 使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
|
||||
|
||||
约会网站预测函数
|
||||
|
||||
```python
|
||||
def classifyPerson():
|
||||
resultList = ['not at all', 'in small doses', 'in large doses']
|
||||
percentTats = float(raw_input("percentage of time spent playing video games ?"))
|
||||
ffMiles = float(raw_input("frequent filer miles earned per year?"))
|
||||
iceCream = float(raw_input("liters of ice cream consumed per year?"))
|
||||
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
|
||||
normMat, ranges, minVals = autoNorm(datingDataMat)
|
||||
inArr = array([ffMiles, percentTats, iceCream])
|
||||
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels, 3)
|
||||
print "You will probably like this person: ", resultList[classifierResult - 1]
|
||||
```
|
||||
|
||||
实际运行效果如下:
|
||||
|
||||
```python
|
||||
>>> classifyPerson()
|
||||
percentage of time spent playing video games?10
|
||||
frequent flier miles earned per year?10000
|
||||
liters of ice cream consumed per year?0.5
|
||||
You will probably like this person: in small doses
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 项目案例2: 手写数字识别系统
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/2.KNN/kNN.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/2.KNN/kNN.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
构造一个能识别数字 0 到 9 的基于 KNN 分类器的手写数字识别系统。
|
||||
|
||||
需要识别的数字是存储在文本文件中的具有相同的色彩和大小:宽高是 32 像素 * 32 像素的黑白图像。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供文本文件。
|
||||
准备数据:编写函数 img2vector(), 将图像格式转换为分类器使用的向量格式
|
||||
分析数据:在 Python 命令提示符中检查数据,确保它符合要求
|
||||
训练算法:此步骤不适用于 KNN
|
||||
测试算法:编写函数使用提供的部分数据集作为测试样本,测试样本与非测试样本的
|
||||
区别在于测试样本是已经完成分类的数据,如果预测分类与实际类别不同,
|
||||
则标记为一个错误
|
||||
使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取
|
||||
数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统
|
||||
```
|
||||
|
||||
> 收集数据: 提供文本文件
|
||||
|
||||
目录 [trainingDigits](/data/2.KNN/trainingDigits) 中包含了大约 2000 个例子,每个例子内容如下图所示,每个数字大约有 200 个样本;目录 [testDigits](/data/2.KNN/testDigits) 中包含了大约 900 个测试数据。
|
||||
|
||||

|
||||
|
||||
> 准备数据: 编写函数 img2vector(), 将图像文本数据转换为分类器使用的向量
|
||||
|
||||
将图像文本数据转换为向量
|
||||
|
||||
```python
|
||||
def img2vector(filename):
|
||||
returnVect = zeros((1,1024))
|
||||
fr = open(filename)
|
||||
for i in range(32):
|
||||
lineStr = fr.readline()
|
||||
for j in range(32):
|
||||
returnVect[0,32*i+j] = int(lineStr[j])
|
||||
return returnVect
|
||||
```
|
||||
|
||||
> 分析数据:在 Python 命令提示符中检查数据,确保它符合要求
|
||||
|
||||
在 Python 命令行中输入下列命令测试 img2vector 函数,然后与文本编辑器打开的文件进行比较:
|
||||
|
||||
```python
|
||||
>>> testVector = kNN.img2vector('testDigits/0_13.txt')
|
||||
>>> testVector[0,0:32]
|
||||
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
|
||||
>>> testVector[0,32:64]
|
||||
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
|
||||
```
|
||||
|
||||
> 训练算法:此步骤不适用于 KNN
|
||||
|
||||
因为测试数据每一次都要与全量的训练数据进行比较,所以这个过程是没有必要的。
|
||||
|
||||
> 测试算法:编写函数使用提供的部分数据集作为测试样本,如果预测分类与实际类别不同,则标记为一个错误
|
||||
|
||||
```python
|
||||
def handwritingClassTest():
|
||||
# 1. 导入训练数据
|
||||
hwLabels = []
|
||||
trainingFileList = listdir('data/2.KNN/trainingDigits') # load the training set
|
||||
m = len(trainingFileList)
|
||||
trainingMat = zeros((m, 1024))
|
||||
# hwLabels存储0~9对应的index位置, trainingMat存放的每个位置对应的图片向量
|
||||
for i in range(m):
|
||||
fileNameStr = trainingFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
hwLabels.append(classNumStr)
|
||||
# 将 32*32的矩阵->1*1024的矩阵
|
||||
trainingMat[i, :] = img2vector('data/2.KNN/trainingDigits/%s' % fileNameStr)
|
||||
|
||||
# 2. 导入测试数据
|
||||
testFileList = listdir('data/2.KNN/testDigits') # iterate through the test set
|
||||
errorCount = 0.0
|
||||
mTest = len(testFileList)
|
||||
for i in range(mTest):
|
||||
fileNameStr = testFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
vectorUnderTest = img2vector('data/2.KNN/testDigits/%s' % fileNameStr)
|
||||
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
|
||||
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
|
||||
if (classifierResult != classNumStr): errorCount += 1.0
|
||||
print "\nthe total number of errors is: %d" % errorCount
|
||||
print "\nthe total error rate is: %f" % (errorCount / float(mTest))
|
||||
```
|
||||
|
||||
> 使用算法:本例没有完成此步骤,若你感兴趣可以构建完整的应用程序,从图像中提取数字,并完成数字识别,美国的邮件分拣系统就是一个实际运行的类似系统。
|
||||
|
||||
## KNN 小结
|
||||
|
||||
KNN 是什么?定义: 监督学习? 非监督学习?
|
||||
|
||||
KNN 是一个简单的无显示学习过程,非泛化学习的监督学习模型。在分类和回归中均有应用。
|
||||
|
||||
### 基本原理
|
||||
|
||||
简单来说: 通过距离度量来计算查询点(query point)与每个训练数据点的距离,然后选出与查询点(query point)相近的K个最邻点(K nearest neighbors),使用分类决策来选出对应的标签来作为该查询点的标签。
|
||||
|
||||
### KNN 三要素
|
||||
|
||||
>K, K的取值
|
||||
|
||||
>>>>对查询点标签影响显著(效果拔群)。k值小的时候 近似误差小,估计误差大。 k值大 近似误差大,估计误差小。
|
||||
|
||||
>>>>如果选择较小的 k 值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,k 值的减小就意味着整体模型变得复杂,容易发生过拟合。
|
||||
|
||||
>>>>如果选择较大的 k 值,就相当于用较大的邻域中的训练实例进行预测。其优点是可以减少学习的估计误差。但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。 k 值的增大就意味着整体的模型变得简单。
|
||||
|
||||
>>>>太大太小都不太好,可以用交叉验证(cross validation)来选取适合的k值。
|
||||
|
||||
>>>>近似误差和估计误差,请看这里:https://www.zhihu.com/question/60793482
|
||||
|
||||
>距离度量 Metric/Distance Measure
|
||||
|
||||
>>>>距离度量 通常为 欧式距离(Euclidean distance),还可以是 Minkowski 距离 或者 曼哈顿距离。也可以是 地理空间中的一些距离公式。(更多细节可以参看 sklearn 中 valid_metric 部分)
|
||||
|
||||
>分类决策 (decision rule)
|
||||
|
||||
>>>>分类决策 在 分类问题中 通常为通过少数服从多数 来选取票数最多的标签,在回归问题中通常为 K个最邻点的标签的平均值。
|
||||
|
||||
### 算法:(sklearn 上有三种)
|
||||
|
||||
>Brute Force 暴力计算/线性扫描
|
||||
|
||||
>KD Tree 使用二叉树根据数据维度来平分参数空间。
|
||||
|
||||
>Ball Tree 使用一系列的超球体来平分训练数据集。
|
||||
|
||||
>树结构的算法都有建树和查询两个过程。Brute Force 没有建树的过程。
|
||||
|
||||
>算法特点:
|
||||
|
||||
>>>>优点: High Accuracy, No Assumption on data, not sensitive to outliers
|
||||
|
||||
>>>>缺点:时间和空间复杂度 高
|
||||
|
||||
>>>>适用范围: continuous values and nominal values
|
||||
|
||||
>相似同源产物:
|
||||
|
||||
>>>>radius neighbors 根据制定的半径来找寻邻点
|
||||
|
||||
>影响算法因素:
|
||||
|
||||
>>>>N 数据集样本数量(number of samples), D 数据维度 (number of features)
|
||||
|
||||
>总消耗:
|
||||
|
||||
>>>>Brute Force: O[DN^2]
|
||||
|
||||
>>>>此处考虑的是最蠢的方法:把所有训练的点之间的距离都算一遍。当然有更快的实现方式, 比如 O(ND + kN) 和 O(NDK) , 最快的是 O[DN] 。感兴趣的可以阅读这个链接: [k-NN computational complexity](https://stats.stackexchange.com/questions/219655/k-nn-computational-complexity)
|
||||
|
||||
>>>>KD Tree: O[DN log(N)]
|
||||
|
||||
>>>>Ball Tree: O[DN log(N)] 跟 KD Tree 处于相同的数量级,虽然建树时间会比 KD Tree 久一点,但是在高结构的数据,甚至是高纬度的数据中,查询速度有很大的提升。
|
||||
|
||||
>查询所需消耗:
|
||||
|
||||
>>>>Brute Force: O[DN]
|
||||
|
||||
>>>>KD Tree: 当维度比较小的时候, 比如 D<20, O[Dlog(N)] 。相反,将会趋向于 O[DN]
|
||||
|
||||
>>>>Ball Tree: O[Dlog(N)]
|
||||
|
||||
>>>>当数据集比较小的时候,比如 N<30的时候,Brute Force 更有优势。
|
||||
|
||||
>Intrinsic Dimensionality(本征维数) 和 Sparsity(稀疏度)
|
||||
|
||||
>>>>数据的 intrinsic dimensionality 是指数据所在的流形的维数 d < D , 在参数空间可以是线性或非线性的。稀疏度指的是数据填充参数空间的程度(这与“稀疏”矩阵中使用的概念不同, 数据矩阵可能没有零项, 但是从这个意义上来讲,它的结构 仍然是 "稀疏" 的)。
|
||||
|
||||
>>>>Brute Force 的查询时间不受影响。
|
||||
|
||||
>>>>对于 KD Tree 和 Ball Tree的查询时间, 较小本征维数且更稀疏的数据集的查询时间更快。KD Tree 的改善由于通过坐标轴来平分参数空间的自身特性 没有Ball Tree 显著。
|
||||
|
||||
>k的取值 (k 个邻点)
|
||||
|
||||
>>>>Brute Force 的查询时间基本不受影响。
|
||||
|
||||
>>>>但是对于 KD Tree 和 Ball Tree , k越大,查询时间越慢。
|
||||
|
||||
>>>>k 在N的占比较大的时候,使用 Brute Force 比较好。
|
||||
|
||||
>Number of Query Points (查询点数量, 即测试数据的数量)
|
||||
|
||||
>>>>查询点较少的时候用Brute Force。查询点较多的时候可以使用树结构算法。
|
||||
|
||||
>关于 sklearn 中模型的一些额外干货:
|
||||
|
||||
>>>>如果KD Tree,Ball Tree 和Brute Force 应用场景傻傻分不清楚,可以直接使用 含有algorithm='auto'的模组。 algorithm='auto' 自动为您选择最优算法。
|
||||
>>>>有 regressor 和 classifier 可以来选择。
|
||||
|
||||
>>>>metric/distance measure 可以选择。 另外距离 可以通过weight 来加权。
|
||||
|
||||
>leaf size 对KD Tree 和 Ball Tree 的影响
|
||||
|
||||
>>>>建树时间:leaf size 比较大的时候,建树时间也就快点。
|
||||
|
||||
>>>>查询时间: leaf size 太大太小都不太好。如果leaf size 趋向于 N(训练数据的样本数量),算法其实就是 brute force了。如果leaf size 太小了,趋向于1,那查询的时候 遍历树的时间就会大大增加。leaf size 建议的数值是 30,也就是默认值。
|
||||
|
||||
>>>>内存: leaf size 变大,存树结构的内存变小。
|
||||
|
||||
>Nearest Centroid Classifier
|
||||
|
||||
>>>>分类决策是哪个标签的质心与测试点最近,就选哪个标签。
|
||||
|
||||
>>>>该模型假设在所有维度中方差相同。 是一个很好的base line。
|
||||
|
||||
>进阶版: Nearest Shrunken Centroid
|
||||
|
||||
>>>>可以通过shrink_threshold来设置。
|
||||
|
||||
>>>>作用: 可以移除某些影响分类的特征,例如移除噪音特征的影响
|
||||
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,417 @@
|
|||
|
||||
# 第3章 决策树
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## 决策树 概述
|
||||
|
||||
`决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。`
|
||||
|
||||
`决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。`
|
||||
|
||||
`决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。`
|
||||
|
||||
## 决策树 场景
|
||||
|
||||
一个叫做 "二十个问题" 的游戏,游戏的规则很简单:参与游戏的一方在脑海中想某个事物,其他参与者向他提问,只允许提 20 个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围,最后得到游戏的答案。
|
||||
|
||||
一个邮件分类系统,大致工作流程如下:
|
||||
|
||||

|
||||
|
||||
```
|
||||
首先检测发送邮件域名地址。如果地址为 myEmployer.com, 则将其放在分类 "无聊时需要阅读的邮件"中。
|
||||
如果邮件不是来自这个域名,则检测邮件内容里是否包含单词 "曲棍球" , 如果包含则将邮件归类到 "需要及时处理的朋友邮件",
|
||||
如果不包含则将邮件归类到 "无需阅读的垃圾邮件" 。
|
||||
```
|
||||
|
||||
决策树的定义:
|
||||
|
||||
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性(features),叶结点表示一个类(labels)。
|
||||
|
||||
用决策树对需要测试的实例进行分类:从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点;这时,每一个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直至达到叶结点。最后将实例分配到叶结点的类中。
|
||||
|
||||
## 决策树 原理
|
||||
|
||||
### 决策树 须知概念
|
||||
|
||||
#### 信息熵 & 信息增益
|
||||
|
||||
熵(entropy):
|
||||
熵指的是体系的混乱的程度,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。
|
||||
|
||||
信息论(information theory)中的熵(香农熵):
|
||||
是一种信息的度量方式,表示信息的混乱程度,也就是说:信息越有序,信息熵越低。例如:火柴有序放在火柴盒里,熵值很低,相反,熵值很高。
|
||||
|
||||
信息增益(information gain):
|
||||
在划分数据集前后信息发生的变化称为信息增益。
|
||||
|
||||
### 决策树 工作原理
|
||||
|
||||
如何构造一个决策树?<br/>
|
||||
我们使用 createBranch() 方法,如下所示:
|
||||
|
||||
```
|
||||
def createBranch():
|
||||
'''
|
||||
此处运用了迭代的思想。 感兴趣可以搜索 迭代 recursion, 甚至是 dynamic programing。
|
||||
'''
|
||||
检测数据集中的所有数据的分类标签是否相同:
|
||||
If so return 类标签
|
||||
Else:
|
||||
寻找划分数据集的最好特征(划分之后信息熵最小,也就是信息增益最大的特征)
|
||||
划分数据集
|
||||
创建分支节点
|
||||
for 每个划分的子集
|
||||
调用函数 createBranch (创建分支的函数)并增加返回结果到分支节点中
|
||||
return 分支节点
|
||||
```
|
||||
|
||||
### 决策树 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任何方法。
|
||||
准备数据:树构造算法 (这里使用的是ID3算法,只适用于标称型数据,这就是为什么数值型数据必须离散化。 还有其他的树构造算法,比如CART)
|
||||
分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
|
||||
训练算法:构造树的数据结构。
|
||||
测试算法:使用训练好的树计算错误率。
|
||||
使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
```
|
||||
|
||||
### 决策树 算法特点
|
||||
|
||||
```
|
||||
优点:计算复杂度不高,输出结果易于理解,数据有缺失也能跑,可以处理不相关特征。
|
||||
缺点:容易过拟合。
|
||||
适用数据类型:数值型和标称型。
|
||||
```
|
||||
|
||||
## 决策树 项目案例
|
||||
|
||||
### 项目案例1: 判定鱼类和非鱼类
|
||||
|
||||
#### 项目概述
|
||||
|
||||
根据以下 2 个特征,将动物分成两类:鱼类和非鱼类。
|
||||
|
||||
特征:
|
||||
1. 不浮出水面是否可以生存
|
||||
2. 是否有脚蹼
|
||||
|
||||
#### 开发流程
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/3.DecisionTree/DecisionTree.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/3.DecisionTree/DecisionTree.py>
|
||||
|
||||
```
|
||||
收集数据:可以使用任何方法
|
||||
准备数据:树构造算法(这里使用的是ID3算法,因此数值型数据必须离散化。)
|
||||
分析数据:可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
训练算法:构造树结构
|
||||
测试算法:使用习得的决策树执行分类
|
||||
使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义
|
||||
```
|
||||
|
||||
> 收集数据:可以使用任何方法
|
||||
|
||||

|
||||
|
||||
我们利用 createDataSet() 函数输入数据
|
||||
|
||||
```python
|
||||
def createDataSet():
|
||||
dataSet = [[1, 1, 'yes'],
|
||||
[1, 1, 'yes'],
|
||||
[1, 0, 'no'],
|
||||
[0, 1, 'no'],
|
||||
[0, 1, 'no']]
|
||||
labels = ['no surfacing', 'flippers']
|
||||
return dataSet, labels
|
||||
```
|
||||
> 准备数据:树构造算法
|
||||
|
||||
此处,由于我们输入的数据本身就是离散化数据,所以这一步就省略了。
|
||||
|
||||
> 分析数据:可以使用任何方法,构造树完成之后,我们可以将树画出来。
|
||||
|
||||

|
||||
|
||||
计算给定数据集的香农熵的函数
|
||||
|
||||
```python
|
||||
def calcShannonEnt(dataSet):
|
||||
# 求list的长度,表示计算参与训练的数据量
|
||||
numEntries = len(dataSet)
|
||||
# 计算分类标签label出现的次数
|
||||
labelCounts = {}
|
||||
# the the number of unique elements and their occurrence
|
||||
for featVec in dataSet:
|
||||
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
|
||||
currentLabel = featVec[-1]
|
||||
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
|
||||
if currentLabel not in labelCounts.keys():
|
||||
labelCounts[currentLabel] = 0
|
||||
labelCounts[currentLabel] += 1
|
||||
|
||||
# 对于 label 标签的占比,求出 label 标签的香农熵
|
||||
shannonEnt = 0.0
|
||||
for key in labelCounts:
|
||||
# 使用所有类标签的发生频率计算类别出现的概率。
|
||||
prob = float(labelCounts[key])/numEntries
|
||||
# 计算香农熵,以 2 为底求对数
|
||||
shannonEnt -= prob * log(prob, 2)
|
||||
return shannonEnt
|
||||
```
|
||||
|
||||
按照给定特征划分数据集
|
||||
|
||||
`将指定特征的特征值等于 value 的行剩下列作为子数据集。`
|
||||
|
||||
```python
|
||||
def splitDataSet(dataSet, index, value):
|
||||
"""splitDataSet(通过遍历dataSet数据集,求出index对应的colnum列的值为value的行)
|
||||
就是依据index列进行分类,如果index列的数据等于 value的时候,就要将 index 划分到我们创建的新的数据集中
|
||||
Args:
|
||||
dataSet 数据集 待划分的数据集
|
||||
index 表示每一行的index列 划分数据集的特征
|
||||
value 表示index列对应的value值 需要返回的特征的值。
|
||||
Returns:
|
||||
index列为value的数据集【该数据集需要排除index列】
|
||||
"""
|
||||
retDataSet = []
|
||||
for featVec in dataSet:
|
||||
# index列为value的数据集【该数据集需要排除index列】
|
||||
# 判断index列的值是否为value
|
||||
if featVec[index] == value:
|
||||
# chop out index used for splitting
|
||||
# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行
|
||||
reducedFeatVec = featVec[:index]
|
||||
'''
|
||||
请百度查询一下: extend和append的区别
|
||||
music_media.append(object) 向列表中添加一个对象object
|
||||
music_media.extend(sequence) 把一个序列seq的内容添加到列表中 (跟 += 在list运用类似, music_media += sequence)
|
||||
1、使用append的时候,是将object看作一个对象,整体打包添加到music_media对象中。
|
||||
2、使用extend的时候,是将sequence看作一个序列,将这个序列和music_media序列合并,并放在其后面。
|
||||
music_media = []
|
||||
music_media.extend([1,2,3])
|
||||
print music_media
|
||||
#结果:
|
||||
#[1, 2, 3]
|
||||
|
||||
music_media.append([4,5,6])
|
||||
print music_media
|
||||
#结果:
|
||||
#[1, 2, 3, [4, 5, 6]]
|
||||
|
||||
music_media.extend([7,8,9])
|
||||
print music_media
|
||||
#结果:
|
||||
#[1, 2, 3, [4, 5, 6], 7, 8, 9]
|
||||
'''
|
||||
reducedFeatVec.extend(featVec[index+1:])
|
||||
# [index+1:]表示从跳过 index 的 index+1行,取接下来的数据
|
||||
# 收集结果值 index列为value的行【该行需要排除index列】
|
||||
retDataSet.append(reducedFeatVec)
|
||||
return retDataSet
|
||||
```
|
||||
|
||||
选择最好的数据集划分方式
|
||||
|
||||
```python
|
||||
def chooseBestFeatureToSplit(dataSet):
|
||||
"""chooseBestFeatureToSplit(选择最好的特征)
|
||||
|
||||
Args:
|
||||
dataSet 数据集
|
||||
Returns:
|
||||
bestFeature 最优的特征列
|
||||
"""
|
||||
# 求第一行有多少列的 Feature, 最后一列是label列嘛
|
||||
numFeatures = len(dataSet[0]) - 1
|
||||
# 数据集的原始信息熵
|
||||
baseEntropy = calcShannonEnt(dataSet)
|
||||
# 最优的信息增益值, 和最优的Featurn编号
|
||||
bestInfoGain, bestFeature = 0.0, -1
|
||||
# iterate over all the features
|
||||
for i in range(numFeatures):
|
||||
# create a list of all the examples of this feature
|
||||
# 获取对应的feature下的所有数据
|
||||
featList = [example[i] for example in dataSet]
|
||||
# get a set of unique values
|
||||
# 获取剔重后的集合,使用set对list数据进行去重
|
||||
uniqueVals = set(featList)
|
||||
# 创建一个临时的信息熵
|
||||
newEntropy = 0.0
|
||||
# 遍历某一列的value集合,计算该列的信息熵
|
||||
# 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。
|
||||
for value in uniqueVals:
|
||||
subDataSet = splitDataSet(dataSet, i, value)
|
||||
# 计算概率
|
||||
prob = len(subDataSet)/float(len(dataSet))
|
||||
# 计算信息熵
|
||||
newEntropy += prob * calcShannonEnt(subDataSet)
|
||||
# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值
|
||||
# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
|
||||
infoGain = baseEntropy - newEntropy
|
||||
print 'infoGain=', infoGain, 'bestFeature=', i, baseEntropy, newEntropy
|
||||
if (infoGain > bestInfoGain):
|
||||
bestInfoGain = infoGain
|
||||
bestFeature = i
|
||||
return bestFeature
|
||||
```
|
||||
|
||||
```
|
||||
问:上面的 newEntropy 为什么是根据子集计算的呢?
|
||||
答:因为我们在根据一个特征计算香农熵的时候,该特征的分类值是相同,这个特征这个分类的香农熵为 0;
|
||||
这就是为什么计算新的香农熵的时候使用的是子集。
|
||||
```
|
||||
|
||||
> 训练算法:构造树的数据结构
|
||||
|
||||
创建树的函数代码如下:
|
||||
|
||||
```python
|
||||
def createTree(dataSet, labels):
|
||||
classList = [example[-1] for example in dataSet]
|
||||
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
|
||||
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
|
||||
# count() 函数是统计括号中的值在list中出现的次数
|
||||
if classList.count(classList[0]) == len(classList):
|
||||
return classList[0]
|
||||
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
|
||||
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
|
||||
if len(dataSet[0]) == 1:
|
||||
return majorityCnt(classList)
|
||||
|
||||
# 选择最优的列,得到最优列对应的label含义
|
||||
bestFeat = chooseBestFeatureToSplit(dataSet)
|
||||
# 获取label的名称
|
||||
bestFeatLabel = labels[bestFeat]
|
||||
# 初始化myTree
|
||||
myTree = {bestFeatLabel: {}}
|
||||
# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
|
||||
# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list
|
||||
del(labels[bestFeat])
|
||||
# 取出最优列,然后它的branch做分类
|
||||
featValues = [example[bestFeat] for example in dataSet]
|
||||
uniqueVals = set(featValues)
|
||||
for value in uniqueVals:
|
||||
# 求出剩余的标签label
|
||||
subLabels = labels[:]
|
||||
# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()
|
||||
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
|
||||
# print 'myTree', value, myTree
|
||||
return myTree
|
||||
```
|
||||
|
||||
> 测试算法:使用决策树执行分类
|
||||
|
||||
```python
|
||||
def classify(inputTree, featLabels, testVec):
|
||||
"""classify(给输入的节点,进行分类)
|
||||
|
||||
Args:
|
||||
inputTree 决策树模型
|
||||
featLabels Feature标签对应的名称
|
||||
testVec 测试输入的数据
|
||||
Returns:
|
||||
classLabel 分类的结果值,需要映射label才能知道名称
|
||||
"""
|
||||
# 获取tree的根节点对于的key值
|
||||
firstStr = inputTree.keys()[0]
|
||||
# 通过key得到根节点对应的value
|
||||
secondDict = inputTree[firstStr]
|
||||
# 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类
|
||||
featIndex = featLabels.index(firstStr)
|
||||
# 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类
|
||||
key = testVec[featIndex]
|
||||
valueOfFeat = secondDict[key]
|
||||
print '+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat
|
||||
# 判断分枝是否结束: 判断valueOfFeat是否是dict类型
|
||||
if isinstance(valueOfFeat, dict):
|
||||
classLabel = classify(valueOfFeat, featLabels, testVec)
|
||||
else:
|
||||
classLabel = valueOfFeat
|
||||
return classLabel
|
||||
```
|
||||
|
||||
> 使用算法:此步骤可以适用于任何监督学习任务,而使用决策树可以更好地理解数据的内在含义。
|
||||
|
||||
|
||||
### 项目案例2: 使用决策树预测隐形眼镜类型
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/3.DecisionTree/DecisionTree.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/3.DecisionTree/DecisionTree.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
隐形眼镜类型包括硬材质、软材质以及不适合佩戴隐形眼镜。我们需要使用决策树预测患者需要佩戴的隐形眼镜类型。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
1. 收集数据: 提供的文本文件。
|
||||
2. 解析数据: 解析 tab 键分隔的数据行
|
||||
3. 分析数据: 快速检查数据,确保正确地解析数据内容,使用 createPlot() 函数绘制最终的树形图。
|
||||
4. 训练算法: 使用 createTree() 函数。
|
||||
5. 测试算法: 编写测试函数验证决策树可以正确分类给定的数据实例。
|
||||
6. 使用算法: 存储树的数据结构,以便下次使用时无需重新构造树。
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
|
||||
文本文件数据格式如下:
|
||||
|
||||
```
|
||||
young myope no reduced no lenses
|
||||
pre myope no reduced no lenses
|
||||
presbyopic myope no reduced no lenses
|
||||
```
|
||||
|
||||
> 解析数据:解析 tab 键分隔的数据行
|
||||
|
||||
```python
|
||||
lecses = [inst.strip().split('\t') for inst in fr.readlines()]
|
||||
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
|
||||
```
|
||||
|
||||
> 分析数据:快速检查数据,确保正确地解析数据内容,使用 createPlot() 函数绘制最终的树形图。
|
||||
|
||||
```python
|
||||
>>> treePlotter.createPlot(lensesTree)
|
||||
```
|
||||
|
||||
> 训练算法:使用 createTree() 函数
|
||||
|
||||
```python
|
||||
>>> lensesTree = trees.createTree(lenses, lensesLabels)
|
||||
>>> lensesTree
|
||||
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic':{'yes':
|
||||
{'prescript':{'hyper':{'age':{'pre':'no lenses', 'presbyopic':
|
||||
'no lenses', 'young':'hard'}}, 'myope':'hard'}}, 'no':{'age':{'pre':
|
||||
'soft', 'presbyopic':{'prescript': {'hyper':'soft', 'myope':
|
||||
'no lenses'}}, 'young':'soft'}}}}}
|
||||
```
|
||||
|
||||
> 测试算法: 编写测试函数验证决策树可以正确分类给定的数据实例。
|
||||
|
||||
> 使用算法: 存储树的数据结构,以便下次使用时无需重新构造树。
|
||||
|
||||
使用 pickle 模块存储决策树
|
||||
|
||||
```python
|
||||
def storeTree(inputTree, filename):
|
||||
import pickle
|
||||
fw = open(filename, 'wb')
|
||||
pickle.dump(inputTree, fw)
|
||||
fw.close()
|
||||
|
||||
def grabTree(filename):
|
||||
import pickle
|
||||
fr = open(filename, 'rb')
|
||||
return pickle.load(fr)
|
||||
```
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,794 @@
|
|||
|
||||
# 第4章 基于概率论的分类方法:朴素贝叶斯
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## 朴素贝叶斯 概述
|
||||
|
||||
`贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。`
|
||||
|
||||
## 贝叶斯理论 & 条件概率
|
||||
|
||||
### 贝叶斯理论
|
||||
|
||||
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
|
||||
|
||||

|
||||
|
||||
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
|
||||
* 如果 p1(x,y) > p2(x,y) ,那么类别为1
|
||||
* 如果 p2(x,y) > p1(x,y) ,那么类别为2
|
||||
|
||||
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
|
||||
|
||||
### 条件概率
|
||||
|
||||
如果你对 p(x,y|c1) 符号很熟悉,那么可以跳过本小节。
|
||||
|
||||
有一个装了 7 块石头的罐子,其中 3 块是白色的,4 块是黑色的。如果从罐子中随机取出一块石头,那么是白色石头的可能性是多少?由于取石头有 7 种可能,其中 3 种为白色,所以取出白色石头的概率为 3/7 。那么取到黑色石头的概率又是多少呢?很显然,是 4/7 。我们使用 P(white) 来表示取到白色石头的概率,其概率值可以通过白色石头数目除以总的石头数目来得到。
|
||||
|
||||
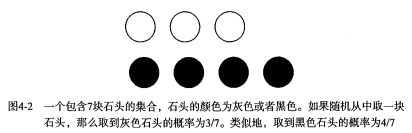
|
||||
|
||||
如果这 7 块石头如下图所示,放在两个桶中,那么上述概率应该如何计算?
|
||||
|
||||
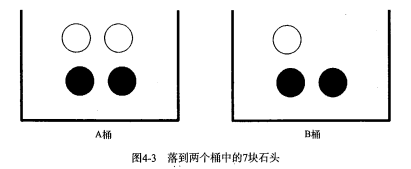
|
||||
|
||||
计算 P(white) 或者 P(black) ,如果事先我们知道石头所在桶的信息是会改变结果的。这就是所谓的条件概率(conditional probablity)。假定计算的是从 B 桶取到白色石头的概率,这个概率可以记作 P(white|bucketB) ,我们称之为“在已知石头出自 B 桶的条件下,取出白色石头的概率”。很容易得到,P(white|bucketA) 值为 2/4 ,P(white|bucketB) 的值为 1/3 。
|
||||
|
||||
条件概率的计算公式如下:
|
||||
|
||||
P(white|bucketB) = P(white and bucketB) / P(bucketB)
|
||||
|
||||
首先,我们用 B 桶中白色石头的个数除以两个桶中总的石头数,得到 P(white and bucketB) = 1/7 .其次,由于 B 桶中有 3 块石头,而总石头数为 7 ,于是 P(bucketB) 就等于 3/7 。于是又 P(white|bucketB) = P(white and bucketB) / P(bucketB) = (1/7) / (3/7) = 1/3 。
|
||||
|
||||
另外一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知 P(x|c),要求 P(c|x),那么可以使用下面的计算方法:
|
||||
|
||||
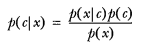
|
||||
|
||||
### 使用条件概率来分类
|
||||
|
||||
上面我们提到贝叶斯决策理论要求计算两个概率 p1(x, y) 和 p2(x, y):
|
||||
* 如果 p1(x, y) > p2(x, y), 那么属于类别 1;
|
||||
* 如果 p2(x, y) > p1(X, y), 那么属于类别 2.
|
||||
|
||||
这并不是贝叶斯决策理论的所有内容。使用 p1() 和 p2() 只是为了尽可能简化描述,而真正需要计算和比较的是 p(c1|x, y) 和 p(c2|x, y) .这些符号所代表的具体意义是: 给定某个由 x、y 表示的数据点,那么该数据点来自类别 c1 的概率是多少?数据点来自类别 c2 的概率又是多少?注意这些概率与概率 p(x, y|c1) 并不一样,不过可以使用贝叶斯准则来交换概率中条件与结果。具体地,应用贝叶斯准则得到:
|
||||
|
||||
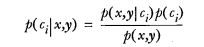
|
||||
|
||||
使用上面这些定义,可以定义贝叶斯分类准则为:
|
||||
* 如果 P(c1|x, y) > P(c2|x, y), 那么属于类别 c1;
|
||||
* 如果 P(c2|x, y) > P(c1|x, y), 那么属于类别 c2.
|
||||
|
||||
在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
|
||||
|
||||
我们假设特征之间 **相互独立** 。所谓 <b>独立(independence)</b> 指的是统计意义上的独立,即一个特征或者单词出现的可能性与它和其他单词相邻没有关系,比如说,“我们”中的“我”和“们”出现的概率与这两个字相邻没有任何关系。这个假设正是朴素贝叶斯分类器中 朴素(naive) 一词的含义。朴素贝叶斯分类器中的另一个假设是,<b>每个特征同等重要</b>。
|
||||
|
||||
<b>Note:</b> 朴素贝叶斯分类器通常有两种实现方式: 一种基于伯努利模型实现,一种基于多项式模型实现。这里采用前一种实现方式。该实现方式中并不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的。
|
||||
|
||||
## 朴素贝叶斯 场景
|
||||
|
||||
机器学习的一个重要应用就是文档的自动分类。
|
||||
|
||||
在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
|
||||
|
||||
朴素贝叶斯是上面介绍的贝叶斯分类器的一个扩展,是用于文档分类的常用算法。下面我们会进行一些朴素贝叶斯分类的实践项目。
|
||||
|
||||
## 朴素贝叶斯 原理
|
||||
|
||||
### 朴素贝叶斯 工作原理
|
||||
|
||||
```
|
||||
提取所有文档中的词条并进行去重
|
||||
获取文档的所有类别
|
||||
计算每个类别中的文档数目
|
||||
对每篇训练文档:
|
||||
对每个类别:
|
||||
如果词条出现在文档中-->增加该词条的计数值(for循环或者矩阵相加)
|
||||
增加所有词条的计数值(此类别下词条总数)
|
||||
对每个类别:
|
||||
对每个词条:
|
||||
将该词条的数目除以总词条数目得到的条件概率(P(词条|类别))
|
||||
返回该文档属于每个类别的条件概率(P(类别|文档的所有词条))
|
||||
```
|
||||
|
||||
### 朴素贝叶斯 开发流程
|
||||
|
||||
```
|
||||
收集数据: 可以使用任何方法。
|
||||
准备数据: 需要数值型或者布尔型数据。
|
||||
分析数据: 有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
|
||||
训练算法: 计算不同的独立特征的条件概率。
|
||||
测试算法: 计算错误率。
|
||||
使用算法: 一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
|
||||
```
|
||||
|
||||
### 朴素贝叶斯 算法特点
|
||||
|
||||
```
|
||||
优点: 在数据较少的情况下仍然有效,可以处理多类别问题。
|
||||
缺点: 对于输入数据的准备方式较为敏感。
|
||||
适用数据类型: 标称型数据。
|
||||
```
|
||||
|
||||
## 朴素贝叶斯 项目案例
|
||||
|
||||
### 项目案例1: 屏蔽社区留言板的侮辱性言论
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/4.NaiveBayes/bayes.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/4.NaiveBayes/bayes.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
构建一个快速过滤器来屏蔽在线社区留言板上的侮辱性言论。如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标识为内容不当。对此问题建立两个类别: 侮辱类和非侮辱类,使用 1 和 0 分别表示。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据: 可以使用任何方法
|
||||
准备数据: 从文本中构建词向量
|
||||
分析数据: 检查词条确保解析的正确性
|
||||
训练算法: 从词向量计算概率
|
||||
测试算法: 根据现实情况修改分类器
|
||||
使用算法: 对社区留言板言论进行分类
|
||||
```
|
||||
|
||||
> 收集数据: 可以使用任何方法
|
||||
|
||||
本例是我们自己构造的词表:
|
||||
|
||||
```python
|
||||
def loadDataSet():
|
||||
"""
|
||||
创建数据集
|
||||
:return: 单词列表postingList, 所属类别classVec
|
||||
"""
|
||||
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #[0,0,1,1,1......]
|
||||
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
|
||||
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
|
||||
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
|
||||
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
|
||||
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
|
||||
classVec = [0, 1, 0, 1, 0, 1] # 1 is abusive, 0 not
|
||||
return postingList, classVec
|
||||
```
|
||||
|
||||
> 准备数据: 从文本中构建词向量
|
||||
|
||||
```python
|
||||
def createVocabList(dataSet):
|
||||
"""
|
||||
获取所有单词的集合
|
||||
:param dataSet: 数据集
|
||||
:return: 所有单词的集合(即不含重复元素的单词列表)
|
||||
"""
|
||||
vocabSet = set([]) # create empty set
|
||||
for document in dataSet:
|
||||
# 操作符 | 用于求两个集合的并集
|
||||
vocabSet = vocabSet | set(document) # union of the two sets
|
||||
return list(vocabSet)
|
||||
|
||||
|
||||
def setOfWords2Vec(vocabList, inputSet):
|
||||
"""
|
||||
遍历查看该单词是否出现,出现该单词则将该单词置1
|
||||
:param vocabList: 所有单词集合列表
|
||||
:param inputSet: 输入数据集
|
||||
:return: 匹配列表[0,1,0,1...],其中 1与0 表示词汇表中的单词是否出现在输入的数据集中
|
||||
"""
|
||||
# 创建一个和词汇表等长的向量,并将其元素都设置为0
|
||||
returnVec = [0] * len(vocabList)# [0,0......]
|
||||
# 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
|
||||
for word in inputSet:
|
||||
if word in vocabList:
|
||||
returnVec[vocabList.index(word)] = 1
|
||||
else:
|
||||
print "the word: %s is not in my Vocabulary!" % word
|
||||
return returnVec
|
||||
```
|
||||
|
||||
> 分析数据: 检查词条确保解析的正确性
|
||||
|
||||
检查函数执行情况,检查词表,不出现重复单词,需要的话,可以对其进行排序。
|
||||
|
||||
```python
|
||||
>>> listOPosts, listClasses = bayes.loadDataSet()
|
||||
>>> myVocabList = bayes.createVocabList(listOPosts)
|
||||
>>> myVocabList
|
||||
['cute', 'love', 'help', 'garbage', 'quit', 'I', 'problems', 'is', 'park',
|
||||
'stop', 'flea', 'dalmation', 'licks', 'food', 'not', 'him', 'buying', 'posting', 'has', 'worthless', 'ate', 'to', 'maybe', 'please', 'dog', 'how',
|
||||
'stupid', 'so', 'take', 'mr', 'steak', 'my']
|
||||
```
|
||||
|
||||
检查函数有效性。例如:myVocabList 中索引为 2 的元素是什么单词?应该是是 help 。该单词在第一篇文档中出现了,现在检查一下看看它是否出现在第四篇文档中。
|
||||
|
||||
```python
|
||||
>>> bayes.setOfWords2Vec(myVocabList, listOPosts[0])
|
||||
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]
|
||||
|
||||
>>> bayes.setOfWords2Vec(myVocabList, listOPosts[3])
|
||||
[0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
|
||||
```
|
||||
|
||||
> 训练算法: 从词向量计算概率
|
||||
|
||||
现在已经知道了一个词是否出现在一篇文档中,也知道该文档所属的类别。接下来我们重写贝叶斯准则,将之前的 x, y 替换为 <b>w</b>. 粗体的 <b>w</b> 表示这是一个向量,即它由多个值组成。在这个例子中,数值个数与词汇表中的词个数相同。
|
||||
|
||||
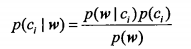
|
||||
|
||||
我们使用上述公式,对每个类计算该值,然后比较这两个概率值的大小。
|
||||
|
||||
问: 上述代码实现中,为什么没有计算P(w)?
|
||||
|
||||
答:根据上述公式可知,我们右边的式子等同于左边的式子,由于对于每个ci,P(w)是固定的。并且我们只需要比较左边式子值的大小来决策分类,那么我们就可以简化为通过比较右边分子值得大小来做决策分类。
|
||||
|
||||
首先可以通过类别 i (侮辱性留言或者非侮辱性留言)中的文档数除以总的文档数来计算概率 p(ci) 。接下来计算 p(<b>w</b> | ci) ,这里就要用到朴素贝叶斯假设。如果将 w 展开为一个个独立特征,那么就可以将上述概率写作 p(w0, w1, w2...wn | ci) 。这里假设所有词都互相独立,该假设也称作条件独立性假设(例如 A 和 B 两个人抛骰子,概率是互不影响的,也就是相互独立的,A 抛 2点的同时 B 抛 3 点的概率就是 1/6 * 1/6),它意味着可以使用 p(w0 | ci)p(w1 | ci)p(w2 | ci)...p(wn | ci) 来计算上述概率,这样就极大地简化了计算的过程。
|
||||
|
||||
朴素贝叶斯分类器训练函数
|
||||
|
||||
```python
|
||||
def _trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据原版
|
||||
:param trainMatrix: 文件单词矩阵 [[1,0,1,1,1....],[],[]...]
|
||||
:param trainCategory: 文件对应的类别[0,1,1,0....],列表长度等于单词矩阵数,其中的1代表对应的文件是侮辱性文件,0代表不是侮辱性矩阵
|
||||
:return:
|
||||
"""
|
||||
# 文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率,即trainCategory中所有的1的个数,
|
||||
# 代表的就是多少个侮辱性文件,与文件的总数相除就得到了侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
p0Num = zeros(numWords) # [0,0,0,.....]
|
||||
p1Num = zeros(numWords) # [0,0,0,.....]
|
||||
|
||||
# 整个数据集单词出现总数
|
||||
p0Denom = 0.0
|
||||
p1Denom = 0.0
|
||||
for i in range(numTrainDocs):
|
||||
# 是否是侮辱性文件
|
||||
if trainCategory[i] == 1:
|
||||
# 如果是侮辱性文件,对侮辱性文件的向量进行加和
|
||||
p1Num += trainMatrix[i] #[0,1,1,....] + [0,1,1,....]->[0,2,2,...]
|
||||
# 对向量中的所有元素进行求和,也就是计算所有侮辱性文件中出现的单词总数
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[P(F1|C1),P(F2|C1),P(F3|C1),P(F4|C1),P(F5|C1)....]列表
|
||||
# 即 在1类别下,每个单词出现的概率
|
||||
p1Vect = p1Num / p1Denom# [1,2,3,5]/90->[1/90,...]
|
||||
# 类别0,即正常文档的[P(F1|C0),P(F2|C0),P(F3|C0),P(F4|C0),P(F5|C0)....]列表
|
||||
# 即 在0类别下,每个单词出现的概率
|
||||
p0Vect = p0Num / p0Denom
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
```
|
||||
|
||||
> 测试算法: 根据现实情况修改分类器
|
||||
|
||||
在利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算 p(w0|1) * p(w1|1) * p(w2|1)。如果其中一个概率值为 0,那么最后的乘积也为 0。为降低这种影响,可以将所有词的出现数初始化为 1,并将分母初始化为 2 (取1 或 2 的目的主要是为了保证分子和分母不为0,大家可以根据业务需求进行更改)。
|
||||
|
||||
另一个遇到的问题是下溢出,这是由于太多很小的数相乘造成的。当计算乘积 p(w0|ci) * p(w1|ci) * p(w2|ci)... p(wn|ci) 时,由于大部分因子都非常小,所以程序会下溢出或者得到不正确的答案。(用 Python 尝试相乘许多很小的数,最后四舍五入后会得到 0)。一种解决办法是对乘积取自然对数。在代数中有 ln(a * b) = ln(a) + ln(b), 于是通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。
|
||||
|
||||
下图给出了函数 f(x) 与 ln(f(x)) 的曲线。可以看出,它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
|
||||
|
||||
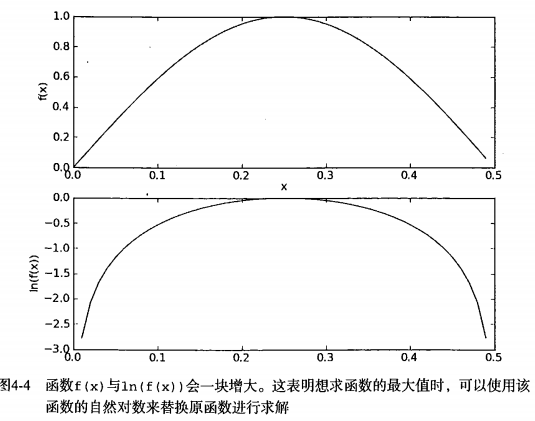
|
||||
|
||||
```python
|
||||
def trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据优化版本
|
||||
:param trainMatrix: 文件单词矩阵
|
||||
:param trainCategory: 文件对应的类别
|
||||
:return:
|
||||
"""
|
||||
# 总文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 总单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
# p0Num 正常的统计
|
||||
# p1Num 侮辱的统计
|
||||
p0Num = ones(numWords)#[0,0......]->[1,1,1,1,1.....]
|
||||
p1Num = ones(numWords)
|
||||
|
||||
# 整个数据集单词出现总数,2.0根据样本/实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整)
|
||||
# p0Denom 正常的统计
|
||||
# p1Denom 侮辱的统计
|
||||
p0Denom = 2.0
|
||||
p1Denom = 2.0
|
||||
for i in range(numTrainDocs):
|
||||
if trainCategory[i] == 1:
|
||||
# 累加辱骂词的频次
|
||||
p1Num += trainMatrix[i]
|
||||
# 对每篇文章的辱骂的频次 进行统计汇总
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
p1Vect = log(p1Num / p1Denom)
|
||||
# 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
p0Vect = log(p0Num / p0Denom)
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
|
||||
```
|
||||
|
||||
|
||||
> 使用算法: 对社区留言板言论进行分类
|
||||
|
||||
朴素贝叶斯分类函数
|
||||
|
||||
```python
|
||||
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
|
||||
"""
|
||||
使用算法:
|
||||
# 将乘法转换为加法
|
||||
乘法:P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
|
||||
加法:P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
:param vec2Classify: 待测数据[0,1,1,1,1...],即要分类的向量
|
||||
:param p0Vec: 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
:param p1Vec: 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
:param pClass1: 类别1,侮辱性文件的出现概率
|
||||
:return: 类别1 or 0
|
||||
"""
|
||||
# 计算公式 log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
# 大家可能会发现,上面的计算公式,没有除以贝叶斯准则的公式的分母,也就是 P(w) (P(w) 指的是此文档在所有的文档中出现的概率)就进行概率大小的比较了,
|
||||
# 因为 P(w) 针对的是包含侮辱和非侮辱的全部文档,所以 P(w) 是相同的。
|
||||
# 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。
|
||||
# 我的理解是:这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来
|
||||
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # P(w|c1) * P(c1) ,即贝叶斯准则的分子
|
||||
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) # P(w|c0) * P(c0) ,即贝叶斯准则的分子·
|
||||
if p1 > p0:
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def testingNB():
|
||||
"""
|
||||
测试朴素贝叶斯算法
|
||||
"""
|
||||
# 1. 加载数据集
|
||||
listOPosts, listClasses = loadDataSet()
|
||||
# 2. 创建单词集合
|
||||
myVocabList = createVocabList(listOPosts)
|
||||
# 3. 计算单词是否出现并创建数据矩阵
|
||||
trainMat = []
|
||||
for postinDoc in listOPosts:
|
||||
# 返回m*len(myVocabList)的矩阵, 记录的都是0,1信息
|
||||
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
|
||||
# 4. 训练数据
|
||||
p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
|
||||
# 5. 测试数据
|
||||
testEntry = ['love', 'my', 'dalmation']
|
||||
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
|
||||
print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)
|
||||
testEntry = ['stupid', 'garbage']
|
||||
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
|
||||
print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)
|
||||
```
|
||||
|
||||
|
||||
### 项目案例2: 使用朴素贝叶斯过滤垃圾邮件
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/4.NaiveBayes/bayes.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/4.NaiveBayes/bayes.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
完成朴素贝叶斯的一个最著名的应用: 电子邮件垃圾过滤。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
使用朴素贝叶斯对电子邮件进行分类
|
||||
|
||||
```
|
||||
收集数据: 提供文本文件
|
||||
准备数据: 将文本文件解析成词条向量
|
||||
分析数据: 检查词条确保解析的正确性
|
||||
训练算法: 使用我们之前建立的 trainNB() 函数
|
||||
测试算法: 使用朴素贝叶斯进行交叉验证
|
||||
使用算法: 构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上
|
||||
```
|
||||
|
||||
> 收集数据: 提供文本文件
|
||||
|
||||
文本文件内容如下:
|
||||
|
||||
```
|
||||
Hi Peter,
|
||||
|
||||
With Jose out of town, do you want to
|
||||
meet once in a while to keep things
|
||||
going and do some interesting stuff?
|
||||
|
||||
Let me know
|
||||
Eugene
|
||||
```
|
||||
|
||||
> 准备数据: 将文本文件解析成词条向量
|
||||
|
||||
使用正则表达式来切分文本
|
||||
|
||||
```python
|
||||
>>> mySent = 'This book is the best book on Python or M.L. I have ever laid eyes upon.'
|
||||
>>> import re
|
||||
>>> regEx = re.compile('\\W*')
|
||||
>>> listOfTokens = regEx.split(mySent)
|
||||
>>> listOfTokens
|
||||
['This', 'book', 'is', 'the', 'best', 'book', 'on', 'Python', 'or', 'M.L.', 'I', 'have', 'ever', 'laid', 'eyes', 'upon', '']
|
||||
```
|
||||
|
||||
> 分析数据: 检查词条确保解析的正确性
|
||||
|
||||
> 训练算法: 使用我们之前建立的 trainNB0() 函数
|
||||
|
||||
```python
|
||||
def trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据优化版本
|
||||
:param trainMatrix: 文件单词矩阵
|
||||
:param trainCategory: 文件对应的类别
|
||||
:return:
|
||||
"""
|
||||
# 总文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 总单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
# p0Num 正常的统计
|
||||
# p1Num 侮辱的统计
|
||||
p0Num = ones(numWords)#[0,0......]->[1,1,1,1,1.....]
|
||||
p1Num = ones(numWords)
|
||||
|
||||
# 整个数据集单词出现总数,2.0根据样本/实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整)
|
||||
# p0Denom 正常的统计
|
||||
# p1Denom 侮辱的统计
|
||||
p0Denom = 2.0
|
||||
p1Denom = 2.0
|
||||
for i in range(numTrainDocs):
|
||||
if trainCategory[i] == 1:
|
||||
# 累加辱骂词的频次
|
||||
p1Num += trainMatrix[i]
|
||||
# 对每篇文章的辱骂的频次 进行统计汇总
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
p1Vect = log(p1Num / p1Denom)
|
||||
# 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
p0Vect = log(p0Num / p0Denom)
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
```
|
||||
|
||||
> 测试算法: 使用朴素贝叶斯进行交叉验证
|
||||
|
||||
文件解析及完整的垃圾邮件测试函数
|
||||
|
||||
```python
|
||||
# 切分文本
|
||||
def textParse(bigString):
|
||||
'''
|
||||
Desc:
|
||||
接收一个大字符串并将其解析为字符串列表
|
||||
Args:
|
||||
bigString -- 大字符串
|
||||
Returns:
|
||||
去掉少于 2 个字符的字符串,并将所有字符串转换为小写,返回字符串列表
|
||||
'''
|
||||
import re
|
||||
# 使用正则表达式来切分句子,其中分隔符是除单词、数字外的任意字符串
|
||||
listOfTokens = re.split(r'\W*', bigString)
|
||||
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
|
||||
|
||||
def spamTest():
|
||||
'''
|
||||
Desc:
|
||||
对贝叶斯垃圾邮件分类器进行自动化处理。
|
||||
Args:
|
||||
none
|
||||
Returns:
|
||||
对测试集中的每封邮件进行分类,若邮件分类错误,则错误数加 1,最后返回总的错误百分比。
|
||||
'''
|
||||
docList = []
|
||||
classList = []
|
||||
fullText = []
|
||||
for i in range(1, 26):
|
||||
# 切分,解析数据,并归类为 1 类别
|
||||
wordList = textParse(open('data/4.NaiveBayes/email/spam/%d.txt' % i).read())
|
||||
docList.append(wordList)
|
||||
classList.append(1)
|
||||
# 切分,解析数据,并归类为 0 类别
|
||||
wordList = textParse(open('data/4.NaiveBayes/email/ham/%d.txt' % i).read())
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(0)
|
||||
# 创建词汇表
|
||||
vocabList = createVocabList(docList)
|
||||
trainingSet = range(50)
|
||||
testSet = []
|
||||
# 随机取 10 个邮件用来测试
|
||||
for i in range(10):
|
||||
# random.uniform(x, y) 随机生成一个范围为 x ~ y 的实数
|
||||
randIndex = int(random.uniform(0, len(trainingSet)))
|
||||
testSet.append(trainingSet[randIndex])
|
||||
del(trainingSet[randIndex])
|
||||
trainMat = []
|
||||
trainClasses = []
|
||||
for docIndex in trainingSet:
|
||||
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
|
||||
trainClasses.append(classList[docIndex])
|
||||
p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
|
||||
errorCount = 0
|
||||
for docIndex in testSet:
|
||||
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
|
||||
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
|
||||
errorCount += 1
|
||||
print 'the errorCount is: ', errorCount
|
||||
print 'the testSet length is :', len(testSet)
|
||||
print 'the error rate is :', float(errorCount)/len(testSet)
|
||||
```
|
||||
|
||||
> 使用算法: 构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上
|
||||
|
||||
|
||||
### 项目案例3: 使用朴素贝叶斯分类器从个人广告中获取区域倾向
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/4.NaiveBayes/bayes.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/4.NaiveBayes/bayes.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
广告商往往想知道关于一个人的一些特定人口统计信息,以便能更好地定向推销广告。
|
||||
|
||||
我们将分别从美国的两个城市中选取一些人,通过分析这些人发布的信息,来比较这两个城市的人们在广告用词上是否不同。如果结论确实不同,那么他们各自常用的词是哪些,从人们的用词当中,我们能否对不同城市的人所关心的内容有所了解。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据: 从 RSS 源收集内容,这里需要对 RSS 源构建一个接口
|
||||
准备数据: 将文本文件解析成词条向量
|
||||
分析数据: 检查词条确保解析的正确性
|
||||
训练算法: 使用我们之前建立的 trainNB0() 函数
|
||||
测试算法: 观察错误率,确保分类器可用。可以修改切分程序,以降低错误率,提高分类结果
|
||||
使用算法: 构建一个完整的程序,封装所有内容。给定两个 RSS 源,改程序会显示最常用的公共词
|
||||
```
|
||||
|
||||
> 收集数据: 从 RSS 源收集内容,这里需要对 RSS 源构建一个接口
|
||||
|
||||
也就是导入 RSS 源,我们使用 python 下载文本,在http://code.google.com/p/feedparser/ 下浏览相关文档,安装 feedparse,首先解压下载的包,并将当前目录切换到解压文件所在的文件夹,然后在 python 提示符下输入:
|
||||
|
||||
```python
|
||||
>>> python setup.py install
|
||||
```
|
||||
|
||||
> 准备数据: 将文本文件解析成词条向量
|
||||
|
||||
文档词袋模型
|
||||
|
||||
我们将每个词的出现与否作为一个特征,这可以被描述为 <b>词集模型(set-of-words model)</b>。如果一个词在文档中出现不止一次,这可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法被称为 <b>词袋模型(bag-of-words model)</b>。在词袋中,每个单词可以出现多次,而在词集中,每个词只能出现一次。为适应词袋模型,需要对函数 setOfWords2Vec() 稍加修改,修改后的函数为 bagOfWords2Vec() 。
|
||||
|
||||
如下给出了基于词袋模型的朴素贝叶斯代码。它与函数 setOfWords2Vec() 几乎完全相同,唯一不同的是每当遇到一个单词时,它会增加词向量中的对应值,而不只是将对应的数值设为 1 。
|
||||
|
||||
```python
|
||||
def bagOfWords2VecMN(vocaList, inputSet):
|
||||
returnVec = [0] * len(vocabList)
|
||||
for word in inputSet:
|
||||
if word in vocaList:
|
||||
returnVec[vocabList.index(word)] += 1
|
||||
return returnVec
|
||||
```
|
||||
|
||||
```python
|
||||
#创建一个包含在所有文档中出现的不重复词的列表
|
||||
def createVocabList(dataSet):
|
||||
vocabSet=set([]) #创建一个空集
|
||||
for document in dataSet:
|
||||
vocabSet=vocabSet|set(document) #创建两个集合的并集
|
||||
return list(vocabSet)
|
||||
def setOfWords2VecMN(vocabList,inputSet):
|
||||
returnVec=[0]*len(vocabList) #创建一个其中所含元素都为0的向量
|
||||
for word in inputSet:
|
||||
if word in vocabList:
|
||||
returnVec[vocabList.index(word)]+=1
|
||||
return returnVec
|
||||
|
||||
#文件解析
|
||||
def textParse(bigString):
|
||||
import re
|
||||
listOfTokens=re.split(r'\W*',bigString)
|
||||
return [tok.lower() for tok in listOfTokens if len(tok)>2]
|
||||
```
|
||||
|
||||
> 分析数据: 检查词条确保解析的正确性
|
||||
|
||||
> 训练算法: 使用我们之前建立的 trainNB0() 函数
|
||||
|
||||
```python
|
||||
def trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据优化版本
|
||||
:param trainMatrix: 文件单词矩阵
|
||||
:param trainCategory: 文件对应的类别
|
||||
:return:
|
||||
"""
|
||||
# 总文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 总单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
# p0Num 正常的统计
|
||||
# p1Num 侮辱的统计
|
||||
# 避免单词列表中的任何一个单词为0,而导致最后的乘积为0,所以将每个单词的出现次数初始化为 1
|
||||
p0Num = ones(numWords)#[0,0......]->[1,1,1,1,1.....]
|
||||
p1Num = ones(numWords)
|
||||
|
||||
# 整个数据集单词出现总数,2.0根据样本/实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整)
|
||||
# p0Denom 正常的统计
|
||||
# p1Denom 侮辱的统计
|
||||
p0Denom = 2.0
|
||||
p1Denom = 2.0
|
||||
for i in range(numTrainDocs):
|
||||
if trainCategory[i] == 1:
|
||||
# 累加辱骂词的频次
|
||||
p1Num += trainMatrix[i]
|
||||
# 对每篇文章的辱骂的频次 进行统计汇总
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
p1Vect = log(p1Num / p1Denom)
|
||||
# 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
p0Vect = log(p0Num / p0Denom)
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
```
|
||||
|
||||
> 测试算法: 观察错误率,确保分类器可用。可以修改切分程序,以降低错误率,提高分类结果
|
||||
|
||||
```python
|
||||
#RSS源分类器及高频词去除函数
|
||||
def calcMostFreq(vocabList,fullText):
|
||||
import operator
|
||||
freqDict={}
|
||||
for token in vocabList: #遍历词汇表中的每个词
|
||||
freqDict[token]=fullText.count(token) #统计每个词在文本中出现的次数
|
||||
sortedFreq=sorted(freqDict.iteritems(),key=operator.itemgetter(1),reverse=True) #根据每个词出现的次数从高到底对字典进行排序
|
||||
return sortedFreq[:30] #返回出现次数最高的30个单词
|
||||
def localWords(feed1,feed0):
|
||||
import feedparser
|
||||
docList=[];classList=[];fullText=[]
|
||||
minLen=min(len(feed1['entries']),len(feed0['entries']))
|
||||
for i in range(minLen):
|
||||
wordList=textParse(feed1['entries'][i]['summary']) #每次访问一条RSS源
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(1)
|
||||
wordList=textParse(feed0['entries'][i]['summary'])
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(0)
|
||||
vocabList=createVocabList(docList)
|
||||
top30Words=calcMostFreq(vocabList,fullText)
|
||||
for pairW in top30Words:
|
||||
if pairW[0] in vocabList:vocabList.remove(pairW[0]) #去掉出现次数最高的那些词
|
||||
trainingSet=range(2*minLen);testSet=[]
|
||||
for i in range(20):
|
||||
randIndex=int(random.uniform(0,len(trainingSet)))
|
||||
testSet.append(trainingSet[randIndex])
|
||||
del(trainingSet[randIndex])
|
||||
trainMat=[];trainClasses=[]
|
||||
for docIndex in trainingSet:
|
||||
trainMat.append(bagOfWords2VecMN(vocabList,docList[docIndex]))
|
||||
trainClasses.append(classList[docIndex])
|
||||
p0V,p1V,pSpam=trainNBO(array(trainMat),array(trainClasses))
|
||||
errorCount=0
|
||||
for docIndex in testSet:
|
||||
wordVector=bagOfWords2VecMN(vocabList,docList[docIndex])
|
||||
if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]:
|
||||
errorCount+=1
|
||||
print 'the error rate is:',float(errorCount)/len(testSet)
|
||||
return vocabList,p0V,p1V
|
||||
|
||||
#朴素贝叶斯分类函数
|
||||
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
|
||||
p1=sum(vec2Classify*p1Vec)+log(pClass1)
|
||||
p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1)
|
||||
if p1>p0:
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
```
|
||||
|
||||
> 使用算法: 构建一个完整的程序,封装所有内容。给定两个 RSS 源,改程序会显示最常用的公共词
|
||||
|
||||
函数 localWords() 使用了两个 RSS 源作为参数,RSS 源要在函数外导入,这样做的原因是 RSS 源会随时间而改变,重新加载 RSS 源就会得到新的数据
|
||||
|
||||
```python
|
||||
>>> reload(bayes)
|
||||
<module 'bayes' from 'bayes.pyc'>
|
||||
>>> import feedparser
|
||||
>>> ny=feedparser.parse('http://newyork.craigslist.org/stp/index.rss')
|
||||
>>> sy=feedparser.parse('http://sfbay.craigslist.org/stp/index.rss')
|
||||
>>> vocabList,pSF,pNY=bayes.localWords(ny,sf)
|
||||
the error rate is: 0.2
|
||||
>>> vocabList,pSF,pNY=bayes.localWords(ny,sf)
|
||||
the error rate is: 0.3
|
||||
>>> vocabList,pSF,pNY=bayes.localWords(ny,sf)
|
||||
the error rate is: 0.55
|
||||
```
|
||||
为了得到错误率的精确估计,应该多次进行上述实验,然后取平均值
|
||||
|
||||
接下来,我们要分析一下数据,显示地域相关的用词
|
||||
|
||||
可以先对向量pSF与pNY进行排序,然后按照顺序打印出来,将下面的代码添加到文件中:
|
||||
|
||||
```python
|
||||
#最具表征性的词汇显示函数
|
||||
def getTopWords(ny,sf):
|
||||
import operator
|
||||
vocabList,p0V,p1V=localWords(ny,sf)
|
||||
topNY=[];topSF=[]
|
||||
for i in range(len(p0V)):
|
||||
if p0V[i]>-6.0:topSF.append((vocabList[i],p0V[i]))
|
||||
if p1V[i]>-6.0:topNY.append((vocabList[i],p1V[i]))
|
||||
sortedSF=sorted(topSF,key=lambda pair:pair[1],reverse=True)
|
||||
print "SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**"
|
||||
for item in sortedSF:
|
||||
print item[0]
|
||||
sortedNY=sorted(topNY,key=lambda pair:pair[1],reverse=True)
|
||||
print "NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**"
|
||||
for item in sortedNY:
|
||||
print item[0]
|
||||
```
|
||||
|
||||
函数 getTopWords() 使用两个 RSS 源作为输入,然后训练并测试朴素贝叶斯分类器,返回使用的概率值。然后创建两个列表用于元组的存储,与之前返回排名最高的 X 个单词不同,这里可以返回大于某个阈值的所有词,这些元组会按照它们的条件概率进行排序。
|
||||
|
||||
保存 bayes.py 文件,在python提示符下输入:
|
||||
|
||||
```python
|
||||
>>> reload(bayes)
|
||||
<module 'bayes' from 'bayes.pyc'>
|
||||
>>> bayes.getTopWords(ny,sf)
|
||||
the error rate is: 0.55
|
||||
SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**
|
||||
how
|
||||
last
|
||||
man
|
||||
...
|
||||
veteran
|
||||
still
|
||||
ends
|
||||
late
|
||||
off
|
||||
own
|
||||
know
|
||||
NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**
|
||||
someone
|
||||
meet
|
||||
...
|
||||
apparel
|
||||
recalled
|
||||
starting
|
||||
strings
|
||||
```
|
||||
|
||||
当注释掉用于移除高频词的三行代码,然后比较注释前后的分类性能,去掉这几行代码之后,错误率为54%,,而保留这些代码得到的错误率为70%。这里观察到,这些留言中出现次数最多的前30个词涵盖了所有用词的30%,vocabList的大小约为3000个词,也就是说,词汇表中的一小部分单词却占据了所有文本用词的一大部分。产生这种现象的原因是因为语言中大部分都是冗余和结构辅助性内容。另一个常用的方法是不仅移除高频词,同时从某个预定高频词中移除结构上的辅助词,该词表称为停用词表。
|
||||
|
||||
从最后输出的单词,可以看出程序输出了大量的停用词,可以移除固定的停用词看看结果如何,这样做的话,分类错误率也会降低。
|
||||
|
||||
|
||||
***
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
||||
|
|
@ -0,0 +1,651 @@
|
|||
# 第5章 Logistic回归
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## Logistic 回归 概述
|
||||
|
||||
`Logistic 回归 或者叫逻辑回归 虽然名字有回归,但是它是用来做分类的。其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类。`
|
||||
|
||||
## 须知概念
|
||||
|
||||
### Sigmoid 函数
|
||||
|
||||
#### 回归 概念
|
||||
|
||||
假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。进而可以得到对这些点的拟合直线方程,那么我们根据这个回归方程,怎么进行分类呢?请看下面。
|
||||
|
||||
#### 二值型输出分类函数
|
||||
|
||||
我们想要的函数应该是: 能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出 0 或 1.或许你之前接触过具有这种性质的函数,该函数称为 `海维塞得阶跃函数(Heaviside step function)`,或者直接称为 `单位阶跃函数`。然而,海维塞得阶跃函数的问题在于: 该函数在跳跃点上从 0 瞬间跳跃到 1,这个瞬间跳跃过程有时很难处理。幸好,另一个函数也有类似的性质(可以输出 0 或者 1 的性质),且数学上更易处理,这就是 Sigmoid 函数。 Sigmoid 函数具体的计算公式如下:
|
||||
|
||||
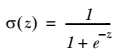
|
||||
|
||||
下图给出了 Sigmoid 函数在不同坐标尺度下的两条曲线图。当 x 为 0 时,Sigmoid 函数值为 0.5 。随着 x 的增大,对应的 Sigmoid 值将逼近于 1 ; 而随着 x 的减小, Sigmoid 值将逼近于 0 。如果横坐标刻度足够大, Sigmoid 函数看起来很像一个阶跃函数。
|
||||
|
||||
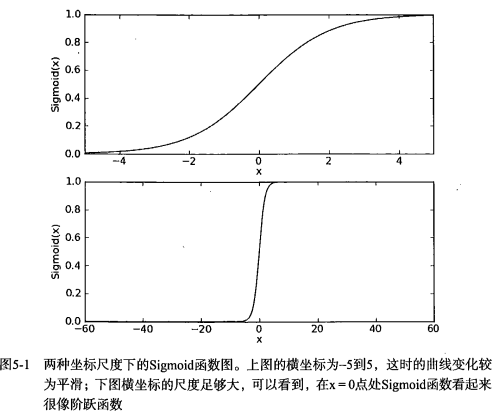
|
||||
|
||||
因此,为了实现 Logistic 回归分类器,我们可以在每个特征上都乘以一个回归系数(如下公式所示),然后把所有结果值相加,将这个总和代入 Sigmoid 函数中,进而得到一个范围在 0~1 之间的数值。任何大于 0.5 的数据被分入 1 类,小于 0.5 即被归入 0 类。所以,Logistic 回归也是一种概率估计,比如这里Sigmoid 函数得出的值为0.5,可以理解为给定数据和参数,数据被分入 1 类的概率为0.5。想对Sigmoid 函数有更多了解,可以点开[此链接](https://www.desmos.com/calculator/bgontvxotm)跟此函数互动。
|
||||
|
||||
### 基于最优化方法的回归系数确定
|
||||
|
||||
Sigmoid 函数的输入记为 z ,由下面公式得到:
|
||||
|
||||
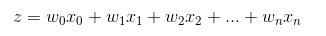
|
||||
|
||||
如果采用向量的写法,上述公式可以写成 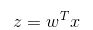 ,它表示将这两个数值向量对应元素相乘然后全部加起来即得到 z 值。其中的向量 x 是分类器的输入数据,向量 w 也就是我们要找到的最佳参数(系数),从而使得分类器尽可能地精确。为了寻找该最佳参数,需要用到最优化理论的一些知识。我们这里使用的是——梯度上升法(Gradient Ascent)。
|
||||
|
||||
|
||||
### 梯度上升法
|
||||
|
||||
#### 梯度的介绍
|
||||
需要一点点向量方面的数学知识
|
||||
|
||||
```
|
||||
向量 = 值 + 方向
|
||||
梯度 = 向量
|
||||
梯度 = 梯度值 + 梯度方向
|
||||
```
|
||||
|
||||
#### 梯度上升法的思想
|
||||
要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为 ▽ ,则函数 f(x, y) 的梯度由下式表示:
|
||||
|
||||
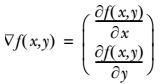
|
||||
|
||||
这个梯度意味着要沿 x 的方向移动 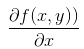 ,沿 y 的方向移动 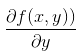 。其中,函数f(x, y) 必须要在待计算的点上有定义并且可微。下图是一个具体的例子。
|
||||
|
||||
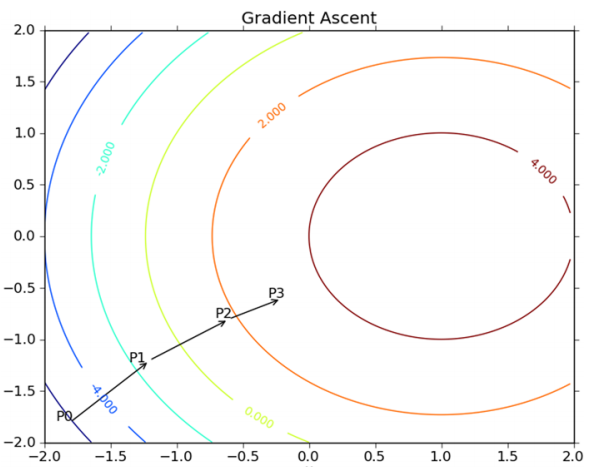
|
||||
|
||||
上图展示的,梯度上升算法到达每个点后都会重新估计移动的方向。从 P0 开始,计算完该点的梯度,函数就根据梯度移动到下一点 P1。在 P1 点,梯度再次被重新计算,并沿着新的梯度方向移动到 P2 。如此循环迭代,直到满足停止条件。迭代过程中,梯度算子总是保证我们能选取到最佳的移动方向。
|
||||
|
||||
上图中的梯度上升算法沿梯度方向移动了一步。可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记作 α 。用向量来表示的话,梯度上升算法的迭代公式如下:
|
||||
|
||||
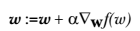
|
||||
|
||||
该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或者算法达到某个可以允许的误差范围。
|
||||
|
||||
介绍一下几个相关的概念:
|
||||
```
|
||||
例如:y = w0 + w1x1 + w2x2 + ... + wnxn
|
||||
梯度:参考上图的例子,二维图像,x方向代表第一个系数,也就是 w1,y方向代表第二个系数也就是 w2,这样的向量就是梯度。
|
||||
α:上面的梯度算法的迭代公式中的阿尔法,这个代表的是移动步长(step length)。移动步长会影响最终结果的拟合程度,最好的方法就是随着迭代次数更改移动步长。
|
||||
步长通俗的理解,100米,如果我一步走10米,我需要走10步;如果一步走20米,我只需要走5步。这里的一步走多少米就是步长的意思。
|
||||
▽f(w):代表沿着梯度变化的方向。
|
||||
```
|
||||
|
||||
|
||||
问:有人会好奇为什么有些书籍上说的是梯度下降法(Gradient Decent)?
|
||||
|
||||
答: 其实这个两个方法在此情况下本质上是相同的。关键在于代价函数(cost function)或者叫目标函数(objective function)。如果目标函数是损失函数,那就是最小化损失函数来求函数的最小值,就用梯度下降。 如果目标函数是似然函数(Likelihood function),就是要最大化似然函数来求函数的最大值,那就用梯度上升。在逻辑回归中, 损失函数和似然函数无非就是互为正负关系。
|
||||
|
||||
只需要在迭代公式中的加法变成减法。因此,对应的公式可以写成
|
||||
|
||||
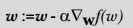
|
||||
|
||||
|
||||
**局部最优现象 (Local Optima)**
|
||||
|
||||
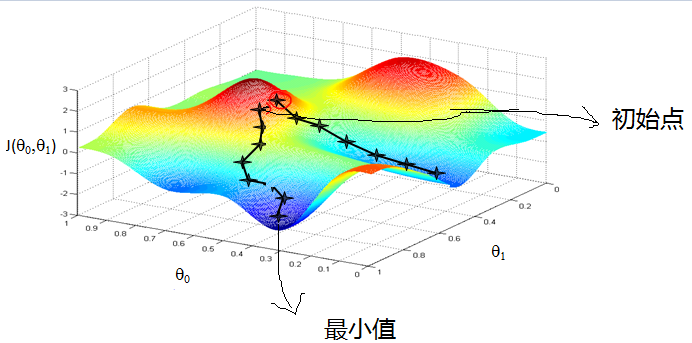
|
||||
|
||||
上图表示参数 θ 与误差函数 J(θ) 的关系图 (这里的误差函数是损失函数,所以我们要最小化损失函数),红色的部分是表示 J(θ) 有着比较高的取值,我们需要的是,能够让 J(θ) 的值尽量的低。也就是深蓝色的部分。θ0,θ1 表示 θ 向量的两个维度(此处的θ0,θ1是x0和x1的系数,也对应的是上文w0和w1)。
|
||||
|
||||
可能梯度下降的最终点并非是全局最小点,可能是一个局部最小点,如我们上图中的右边的梯度下降曲线,描述的是最终到达一个局部最小点,这是我们重新选择了一个初始点得到的。
|
||||
|
||||
看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点。
|
||||
|
||||
## Logistic 回归 原理
|
||||
|
||||
### Logistic 回归 工作原理
|
||||
|
||||
```
|
||||
每个回归系数初始化为 1
|
||||
重复 R 次:
|
||||
计算整个数据集的梯度
|
||||
使用 步长 x 梯度 更新回归系数的向量
|
||||
返回回归系数
|
||||
```
|
||||
|
||||
### Logistic 回归 开发流程
|
||||
|
||||
```
|
||||
收集数据: 采用任意方法收集数据
|
||||
准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
|
||||
分析数据: 采用任意方法对数据进行分析。
|
||||
训练算法: 大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
|
||||
测试算法: 一旦训练步骤完成,分类将会很快。
|
||||
使用算法: 首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
|
||||
```
|
||||
|
||||
### Logistic 回归 算法特点
|
||||
|
||||
```
|
||||
优点: 计算代价不高,易于理解和实现。
|
||||
缺点: 容易欠拟合,分类精度可能不高。
|
||||
适用数据类型: 数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 附加 方向导数与梯度
|
||||
|
||||

|
||||
|
||||
## Logistic 回归 项目案例
|
||||
|
||||
### 项目案例1: 使用 Logistic 回归在简单数据集上的分类
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/5.Logistic/logistic.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/5.Logistic/logistic.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
在一个简单的数据集上,采用梯度上升法找到 Logistic 回归分类器在此数据集上的最佳回归系数
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据: 可以使用任何方法
|
||||
准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
|
||||
分析数据: 画出决策边界
|
||||
训练算法: 使用梯度上升找到最佳参数
|
||||
测试算法: 使用 Logistic 回归进行分类
|
||||
使用算法: 对简单数据集中数据进行分类
|
||||
```
|
||||
|
||||
> 收集数据: 可以使用任何方法
|
||||
|
||||
我们采用存储在 TestSet.txt 文本文件中的数据,存储格式如下:
|
||||
|
||||
```
|
||||
-0.017612 14.053064 0
|
||||
-1.395634 4.662541 1
|
||||
-0.752157 6.538620 0
|
||||
-1.322371 7.152853 0
|
||||
0.423363 11.054677 0
|
||||
```
|
||||
|
||||
绘制在图中,如下图所示:
|
||||
|
||||
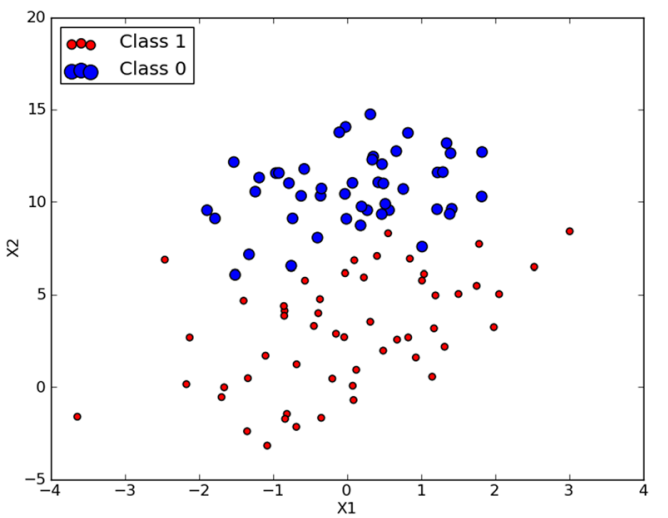
|
||||
|
||||
> 准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
|
||||
|
||||
```python
|
||||
# 解析数据
|
||||
def loadDataSet(file_name):
|
||||
'''
|
||||
Desc:
|
||||
加载并解析数据
|
||||
Args:
|
||||
file_name -- 要解析的文件路径
|
||||
Returns:
|
||||
dataMat -- 原始数据的特征
|
||||
labelMat -- 原始数据的标签,也就是每条样本对应的类别。即目标向量
|
||||
'''
|
||||
# dataMat为原始数据, labelMat为原始数据的标签
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(file_name)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split()
|
||||
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(int(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
```
|
||||
|
||||
> 分析数据: 采用任意方法对数据进行分析,此处不需要
|
||||
|
||||
> 训练算法: 使用梯度上升找到最佳参数
|
||||
|
||||
定义sigmoid阶跃函数
|
||||
|
||||
```python
|
||||
# sigmoid阶跃函数
|
||||
def sigmoid(inX):
|
||||
# return 1.0 / (1 + exp(-inX))
|
||||
|
||||
# Tanh是Sigmoid的变形,与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好。
|
||||
return 2 * 1.0/(1+exp(-2*inX)) - 1
|
||||
```
|
||||
|
||||
Logistic 回归梯度上升优化算法
|
||||
|
||||
```python
|
||||
# 正常的处理方案
|
||||
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
# 转化为矩阵[[1,1,2],[1,1,2]....]
|
||||
dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
|
||||
# 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
|
||||
# transpose() 行列转置函数
|
||||
# 将行向量转化为列向量 => 矩阵的转置
|
||||
labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
|
||||
# m->数据量,样本数 n->特征数
|
||||
m,n = shape(dataMatrix)
|
||||
# print m, n, '__'*10, shape(dataMatrix.transpose()), '__'*100
|
||||
# alpha代表向目标移动的步长
|
||||
alpha = 0.001
|
||||
# 迭代次数
|
||||
maxCycles = 500
|
||||
# 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
|
||||
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
|
||||
weights = ones((n,1))
|
||||
for k in range(maxCycles): #heavy on matrix operations
|
||||
# m*3 的矩阵 * 3*1 的矩阵 = m*1的矩阵
|
||||
# 那么乘上矩阵的意义,就代表:通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# print 'dataMatrix====', dataMatrix
|
||||
# print 'weights====', weights
|
||||
# n*3 * 3*1 = n*1
|
||||
h = sigmoid(dataMatrix*weights) # 矩阵乘法
|
||||
# print 'hhhhhhh====', h
|
||||
# labelMat是实际值
|
||||
error = (labelMat - h) # 向量相减
|
||||
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
|
||||
weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
|
||||
return array(weights)
|
||||
```
|
||||
|
||||
大家看到这儿可能会有一些疑惑,就是,我们在迭代中更新我们的回归系数,后边的部分是怎么计算出来的?为什么会是 alpha * dataMatrix.transpose() * error ?因为这就是我们所求的梯度,也就是对 f(w) 对 w 求一阶导数。具体推导如下:
|
||||
|
||||

|
||||
可参考http://blog.csdn.net/achuo/article/details/51160101
|
||||
|
||||
画出数据集和 Logistic 回归最佳拟合直线的函数
|
||||
|
||||
```python
|
||||
def plotBestFit(dataArr, labelMat, weights):
|
||||
'''
|
||||
Desc:
|
||||
将我们得到的数据可视化展示出来
|
||||
Args:
|
||||
dataArr:样本数据的特征
|
||||
labelMat:样本数据的类别标签,即目标变量
|
||||
weights:回归系数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
|
||||
n = shape(dataArr)[0]
|
||||
xcord1 = []; ycord1 = []
|
||||
xcord2 = []; ycord2 = []
|
||||
for i in range(n):
|
||||
if int(labelMat[i])== 1:
|
||||
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
|
||||
else:
|
||||
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
|
||||
ax.scatter(xcord2, ycord2, s=30, c='green')
|
||||
x = arange(-3.0, 3.0, 0.1)
|
||||
"""
|
||||
y的由来,卧槽,是不是没看懂?
|
||||
首先理论上是这个样子的。
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
w0*x0+w1*x1+w2*x2=f(x)
|
||||
x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
|
||||
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
|
||||
"""
|
||||
y = (-weights[0]-weights[1]*x)/weights[2]
|
||||
ax.plot(x, y)
|
||||
plt.xlabel('X'); plt.ylabel('Y')
|
||||
plt.show()
|
||||
```
|
||||
|
||||
> 测试算法: 使用 Logistic 回归进行分类
|
||||
|
||||
```python
|
||||
def testLR():
|
||||
# 1.收集并准备数据
|
||||
dataMat, labelMat = loadDataSet("data/5.Logistic/TestSet.txt")
|
||||
|
||||
# print dataMat, '---\n', labelMat
|
||||
# 2.训练模型, f(x)=a1*x1+b2*x2+..+nn*xn中 (a1,b2, .., nn).T的矩阵值
|
||||
# 因为数组没有是复制n份, array的乘法就是乘法
|
||||
dataArr = array(dataMat)
|
||||
# print dataArr
|
||||
weights = gradAscent(dataArr, labelMat)
|
||||
# weights = stocGradAscent0(dataArr, labelMat)
|
||||
# weights = stocGradAscent1(dataArr, labelMat)
|
||||
# print '*'*30, weights
|
||||
|
||||
# 数据可视化
|
||||
plotBestFit(dataArr, labelMat, weights)
|
||||
```
|
||||
|
||||
> 使用算法: 对简单数据集中数据进行分类
|
||||
|
||||
#### 注意
|
||||
|
||||
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理 100 个左右的数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为 `随机梯度上升算法`。由于可以在新样本到来时对分类器进行增量式更新,因而随机梯度上升算法是一个在线学习(online learning)算法。与 “在线学习” 相对应,一次处理所有数据被称作是 “批处理” (batch) 。
|
||||
|
||||
随机梯度上升算法可以写成如下的伪代码:
|
||||
|
||||
```
|
||||
所有回归系数初始化为 1
|
||||
对数据集中每个样本
|
||||
计算该样本的梯度
|
||||
使用 alpha x gradient 更新回归系数值
|
||||
返回回归系数值
|
||||
```
|
||||
|
||||
以下是随机梯度上升算法的实现代码:
|
||||
|
||||
```python
|
||||
# 随机梯度上升
|
||||
# 梯度上升优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
|
||||
# 随机梯度上升一次只用一个样本点来更新回归系数
|
||||
def stocGradAscent0(dataMatrix, classLabels):
|
||||
m,n = shape(dataMatrix)
|
||||
alpha = 0.01
|
||||
# n*1的矩阵
|
||||
# 函数ones创建一个全1的数组
|
||||
weights = ones(n) # 初始化长度为n的数组,元素全部为 1
|
||||
for i in range(m):
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
|
||||
h = sigmoid(sum(dataMatrix[i]*weights))
|
||||
# print 'dataMatrix[i]===', dataMatrix[i]
|
||||
# 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
|
||||
error = classLabels[i] - h
|
||||
# 0.01*(1*1)*(1*n)
|
||||
print weights, "*"*10 , dataMatrix[i], "*"*10 , error
|
||||
weights = weights + alpha * error * dataMatrix[i]
|
||||
return weights
|
||||
```
|
||||
|
||||
可以看到,随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别: 第一,后者的变量 h 和误差 error 都是向量,而前者则全是数值;第二,前者没有矩阵的转换过程,所有变量的数据类型都是 NumPy 数组。
|
||||
|
||||
判断优化算法优劣的可靠方法是看它是否收敛,也就是说参数是否达到了稳定值,是否还会不断地变化?下图展示了随机梯度上升算法在 200 次迭代过程中回归系数的变化情况。其中的系数2,也就是 X2 只经过了 50 次迭代就达到了稳定值,但系数 1 和 0 则需要更多次的迭代。如下图所示:
|
||||
|
||||
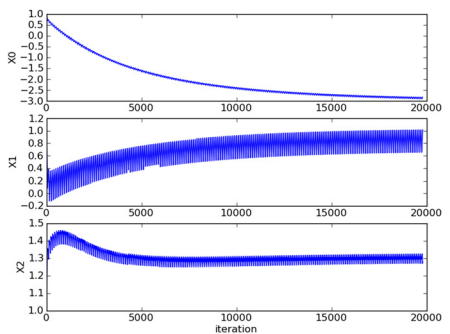
|
||||
|
||||
针对这个问题,我们改进了之前的随机梯度上升算法,如下:
|
||||
|
||||
```python
|
||||
# 随机梯度上升算法(随机化)
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
m,n = shape(dataMatrix)
|
||||
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
|
||||
# 随机梯度, 循环150,观察是否收敛
|
||||
for j in range(numIter):
|
||||
# [0, 1, 2 .. m-1]
|
||||
dataIndex = range(m)
|
||||
for i in range(m):
|
||||
# i和j的不断增大,导致alpha的值不断减少,但是不为0
|
||||
alpha = 4/(1.0+j+i)+0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
|
||||
# 随机产生一个 0~len()之间的一个值
|
||||
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
|
||||
randIndex = int(random.uniform(0,len(dataIndex)))
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
|
||||
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]]*weights))
|
||||
error = classLabels[dataIndex[randIndex]] - h
|
||||
# print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
|
||||
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
|
||||
del(dataIndex[randIndex])
|
||||
return weights
|
||||
```
|
||||
|
||||
上面的改进版随机梯度上升算法,我们修改了两处代码。
|
||||
|
||||
第一处改进为 alpha 的值。alpha 在每次迭代的时候都会调整,这回缓解上面波动图的数据波动或者高频波动。另外,虽然 alpha 会随着迭代次数不断减少,但永远不会减小到 0,因为我们在计算公式中添加了一个常数项。
|
||||
|
||||
第二处修改为 randIndex 更新,这里通过随机选取样本拉来更新回归系数。这种方法将减少周期性的波动。这种方法每次随机从列表中选出一个值,然后从列表中删掉该值(再进行下一次迭代)。
|
||||
|
||||
程序运行之后能看到类似于下图的结果图。
|
||||
|
||||
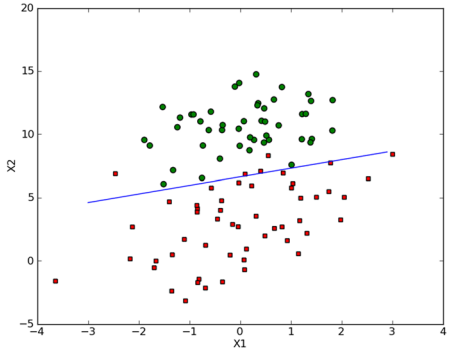
|
||||
|
||||
|
||||
### 项目案例2: 从疝气病症预测病马的死亡率
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/5.Logistic/logistic.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/5.Logistic/logistic.py>
|
||||
|
||||
#### 项目概述
|
||||
|
||||
使用 Logistic 回归来预测患有疝病的马的存活问题。疝病是描述马胃肠痛的术语。然而,这种病不一定源自马的胃肠问题,其他问题也可能引发马疝病。这个数据集中包含了医院检测马疝病的一些指标,有的指标比较主观,有的指标难以测量,例如马的疼痛级别。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据: 给定数据文件
|
||||
准备数据: 用 Python 解析文本文件并填充缺失值
|
||||
分析数据: 可视化并观察数据
|
||||
训练算法: 使用优化算法,找到最佳的系数
|
||||
测试算法: 为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,
|
||||
通过改变迭代的次数和步长的参数来得到更好的回归系数
|
||||
使用算法: 实现一个简单的命令行程序来收集马的症状并输出预测结果并非难事,
|
||||
这可以作为留给大家的一道习题
|
||||
```
|
||||
|
||||
> 收集数据: 给定数据文件
|
||||
|
||||
病马的训练数据已经给出来了,如下形式存储在文本文件中:
|
||||
|
||||
```
|
||||
1.000000 1.000000 39.200000 88.000000 20.000000 0.000000 0.000000 4.000000 1.000000 3.000000 4.000000 2.000000 0.000000 0.000000 0.000000 4.000000 2.000000 50.000000 85.000000 2.000000 2.000000 0.000000
|
||||
2.000000 1.000000 38.300000 40.000000 24.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 33.000000 6.700000 0.000000 0.000000 1.000000
|
||||
```
|
||||
|
||||
> 准备数据: 用 Python 解析文本文件并填充缺失值
|
||||
|
||||
处理数据中的缺失值
|
||||
|
||||
假设有100个样本和20个特征,这些数据都是机器收集回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?此时是否要扔掉整个数据?这种情况下,另外19个特征怎么办?
|
||||
它们是否还可以用?答案是肯定的。因为有时候数据相当昂贵,扔掉和重新获取都是不可取的,所以必须采用一些方法来解决这个问题。
|
||||
|
||||
下面给出了一些可选的做法:
|
||||
* 使用可用特征的均值来填补缺失值;
|
||||
* 使用特殊值来填补缺失值,如 -1;
|
||||
* 忽略有缺失值的样本;
|
||||
* 使用有相似样本的均值添补缺失值;
|
||||
* 使用另外的机器学习算法预测缺失值。
|
||||
|
||||
现在,我们对下一节要用的数据集进行预处理,使其可以顺利地使用分类算法。在预处理需要做两件事:
|
||||
* 所有的缺失值必须用一个实数值来替换,因为我们使用的 NumPy 数据类型不允许包含缺失值。我们这里选择实数 0 来替换所有缺失值,恰好能适用于 Logistic 回归。这样做的直觉在于,我们需要的是一个在更新时不会影响系数的值。回归系数的更新公式如下:
|
||||
|
||||
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
|
||||
|
||||
如果 dataMatrix 的某个特征对应值为 0,那么该特征的系数将不做更新,即:
|
||||
|
||||
weights = weights
|
||||
|
||||
另外,由于 Sigmoid(0) = 0.5 ,即它对结果的预测不具有任何倾向性,因此我们上述做法也不会对误差造成任何影响。基于上述原因,将缺失值用 0 代替既可以保留现有数据,也不需要对优化算法进行修改。此外,该数据集中的特征取值一般不为 0,因此在某种意义上说它也满足 “特殊值” 这个要求。
|
||||
|
||||
* 如果在测试数据集中发现了一条数据的类别标签已经缺失,那么我们的简单做法是将该条数据丢弃。这是因为类别标签与特征不同,很难确定采用某个合适的值来替换。采用 Logistic 回归进行分类时这种做法是合理的,而如果采用类似 kNN 的方法,则保留该条数据显得更加合理。
|
||||
|
||||
原始的数据集经过预处理后,保存成两个文件: horseColicTest.txt 和 horseColicTraining.txt 。
|
||||
|
||||
> 分析数据: 可视化并观察数据
|
||||
|
||||
将数据使用 MatPlotlib 打印出来,观察数据是否是我们想要的格式
|
||||
|
||||
> 训练算法: 使用优化算法,找到最佳的系数
|
||||
|
||||
下面给出 原始的梯度上升算法,随机梯度上升算法,改进版随机梯度上升算法 的代码:
|
||||
|
||||
```python
|
||||
# 正常的处理方案
|
||||
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
# 转化为矩阵[[1,1,2],[1,1,2]....]
|
||||
dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
|
||||
# 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
|
||||
# transpose() 行列转置函数
|
||||
# 将行向量转化为列向量 => 矩阵的转置
|
||||
labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
|
||||
# m->数据量,样本数 n->特征数
|
||||
m,n = shape(dataMatrix)
|
||||
# print m, n, '__'*10, shape(dataMatrix.transpose()), '__'*100
|
||||
# alpha代表向目标移动的步长
|
||||
alpha = 0.001
|
||||
# 迭代次数
|
||||
maxCycles = 500
|
||||
# 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
|
||||
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
|
||||
weights = ones((n,1))
|
||||
for k in range(maxCycles): #heavy on matrix operations
|
||||
# m*3 的矩阵 * 3*1 的单位矩阵 = m*1的矩阵
|
||||
# 那么乘上单位矩阵的意义,就代表:通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# print 'dataMatrix====', dataMatrix
|
||||
# print 'weights====', weights
|
||||
# n*3 * 3*1 = n*1
|
||||
h = sigmoid(dataMatrix*weights) # 矩阵乘法
|
||||
# print 'hhhhhhh====', h
|
||||
# labelMat是实际值
|
||||
error = (labelMat - h) # 向量相减
|
||||
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
|
||||
weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
|
||||
return array(weights)
|
||||
|
||||
|
||||
# 随机梯度上升
|
||||
# 梯度上升优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
|
||||
# 随机梯度上升一次只用一个样本点来更新回归系数
|
||||
def stocGradAscent0(dataMatrix, classLabels):
|
||||
m,n = shape(dataMatrix)
|
||||
alpha = 0.01
|
||||
# n*1的矩阵
|
||||
# 函数ones创建一个全1的数组
|
||||
weights = ones(n) # 初始化长度为n的数组,元素全部为 1
|
||||
for i in range(m):
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
|
||||
h = sigmoid(sum(dataMatrix[i]*weights))
|
||||
# print 'dataMatrix[i]===', dataMatrix[i]
|
||||
# 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
|
||||
error = classLabels[i] - h
|
||||
# 0.01*(1*1)*(1*n)
|
||||
print weights, "*"*10 , dataMatrix[i], "*"*10 , error
|
||||
weights = weights + alpha * error * dataMatrix[i]
|
||||
return weights
|
||||
|
||||
|
||||
# 随机梯度上升算法(随机化)
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
m,n = shape(dataMatrix)
|
||||
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
|
||||
# 随机梯度, 循环150,观察是否收敛
|
||||
for j in range(numIter):
|
||||
# [0, 1, 2 .. m-1]
|
||||
dataIndex = range(m)
|
||||
for i in range(m):
|
||||
# i和j的不断增大,导致alpha的值不断减少,但是不为0
|
||||
alpha = 4/(1.0+j+i)+0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
|
||||
# 随机产生一个 0~len()之间的一个值
|
||||
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
|
||||
randIndex = int(random.uniform(0,len(dataIndex)))
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
|
||||
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]]*weights))
|
||||
error = classLabels[dataIndex[randIndex]] - h
|
||||
# print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
|
||||
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
|
||||
del(dataIndex[randIndex])
|
||||
return weights
|
||||
|
||||
```
|
||||
|
||||
> 测试算法: 为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,通过改变迭代的次数和步长的参数来得到更好的回归系数
|
||||
|
||||
Logistic 回归分类函数
|
||||
|
||||
```python
|
||||
# 分类函数,根据回归系数和特征向量来计算 Sigmoid的值
|
||||
def classifyVector(inX, weights):
|
||||
'''
|
||||
Desc:
|
||||
最终的分类函数,根据回归系数和特征向量来计算 Sigmoid 的值,大于0.5函数返回1,否则返回0
|
||||
Args:
|
||||
inX -- 特征向量,features
|
||||
weights -- 根据梯度下降/随机梯度下降 计算得到的回归系数
|
||||
Returns:
|
||||
如果 prob 计算大于 0.5 函数返回 1
|
||||
否则返回 0
|
||||
'''
|
||||
prob = sigmoid(sum(inX*weights))
|
||||
if prob > 0.5: return 1.0
|
||||
else: return 0.0
|
||||
|
||||
# 打开测试集和训练集,并对数据进行格式化处理
|
||||
def colicTest():
|
||||
'''
|
||||
Desc:
|
||||
打开测试集和训练集,并对数据进行格式化处理
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
errorRate -- 分类错误率
|
||||
'''
|
||||
frTrain = open('data/5.Logistic/horseColicTraining.txt')
|
||||
frTest = open('data/5.Logistic/horseColicTest.txt')
|
||||
trainingSet = []
|
||||
trainingLabels = []
|
||||
# 解析训练数据集中的数据特征和Labels
|
||||
# trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签
|
||||
for line in frTrain.readlines():
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(21):
|
||||
lineArr.append(float(currLine[i]))
|
||||
trainingSet.append(lineArr)
|
||||
trainingLabels.append(float(currLine[21]))
|
||||
# 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights
|
||||
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 500)
|
||||
errorCount = 0
|
||||
numTestVec = 0.0
|
||||
# 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率
|
||||
for line in frTest.readlines():
|
||||
numTestVec += 1.0
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(21):
|
||||
lineArr.append(float(currLine[i]))
|
||||
if int(classifyVector(array(lineArr), trainWeights)) != int(currLine[21]):
|
||||
errorCount += 1
|
||||
errorRate = (float(errorCount) / numTestVec)
|
||||
print "the error rate of this test is: %f" % errorRate
|
||||
return errorRate
|
||||
|
||||
|
||||
# 调用 colicTest() 10次并求结果的平均值
|
||||
def multiTest():
|
||||
numTests = 10
|
||||
errorSum = 0.0
|
||||
for k in range(numTests):
|
||||
errorSum += colicTest()
|
||||
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))
|
||||
```
|
||||
|
||||
> 使用算法: 实现一个简单的命令行程序来收集马的症状并输出预测结果并非难事,这可以作为留给大家的一道习题
|
||||
|
||||
# 额外内容(可选读)
|
||||
|
||||
在上文中,当Sigmoid函数大于 0.5 的数据被分入 1 类,小于 0.5 即被归入 0 类。其实0.5也是可以改动的。 比如大于 0.9 的数据被分入 1 类,小于 0.9 即被归入 0 类。
|
||||
|
||||
## Logistic回归 和 最大熵模型
|
||||
|
||||
Logistic回归和最大熵模型 都属于对数线性模型 (log linear model)。 当类标签(class label)只有两个的时候,最大熵模型就是 logistic 回归模型。 学习它们的模型一般采用极大似然估计或者正则化的极大似然估计。Logistic 回归和最大熵模型学习可以形式化为无约束最优化问题。(关于最大熵模型,可以阅读《统计学习方法》 第六章。)
|
||||
|
||||
## 其他算法
|
||||
|
||||
除了梯度下降,随机梯度下降,还有Conjugate Gradient,BFGS,L-BFGS,他们不需要指定alpha值(步长),而且比梯度下降更快,在现实中应用的也比较多。 当然这些算法相比随机梯度要复杂。
|
||||
|
||||
综上这些算法都有一个共通的缺点就是他们都是不断去逼近真实值,永远只是一个真实值的近似值而已。
|
||||
|
||||
## 多标签分类
|
||||
|
||||
逻辑回归也可以用作于多标签分类。 思路如下:
|
||||
|
||||
假设我们标签A中有a0,a1,a2....an个标签,对于每个标签 ai (ai 是标签A之一),我们训练一个逻辑回归分类器。
|
||||
|
||||
即,训练该标签的逻辑回归分类器的时候,将ai看作一类标签,非ai的所有标签看作一类标签。那么相当于整个数据集里面只有两类标签:ai 和其他。
|
||||
|
||||
剩下步骤就跟我们训练正常的逻辑回归分类器一样了。
|
||||
|
||||
测试数据的时候,将查询点套用在每个逻辑回归分类器中的Sigmoid 函数,取值最高的对应标签为查询点的标签。
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[羊三](http://cwiki.apachecn.org/display/~xuxin) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,319 @@
|
|||
# SVM
|
||||
|
||||
> 声明
|
||||
|
||||
```
|
||||
阅读本文前,需要您懂一些高等数学、概率论、线性代数的相关知识,以便更好理解。
|
||||
```
|
||||
|
||||
```
|
||||
下面这些关于 SVM 的理解,是根据知乎和其他博客或者网站中查询到的资料加以整理,
|
||||
并结合 ApacheCN 这段时间的撸代码和相关研究得到,有理解有误的地方还望大家指出,谢谢。
|
||||
再次感谢网上的大佬们的无私贡献。
|
||||
|
||||
ApacheCN: http://www.apachecn.org/
|
||||
ApacheCN MachineLearning github: https://github.com/apachecn/AiLearning
|
||||
|
||||
网上资料参考链接:https://www.zhihu.com/question/21094489
|
||||
http://docs.opencv.org/2.4/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
|
||||
https://zhuanlan.zhihu.com/p/26891427?utm_medium=social&utm_source=qq
|
||||
https://zhuanlan.zhihu.com/p/21308801?utm_medium=social&utm_source=qq
|
||||
http://blog.csdn.net/v_july_v/article/details/7624837
|
||||
```
|
||||
|
||||
## Overview
|
||||
### What's the SVM?
|
||||
|
||||
^_^ 首先,支持向量机不是一种机器,而是一种机器学习算法。
|
||||
|
||||
1、SVM - Support Vector Machine ,俗称支持向量机,是一种 supervised learning (监督学习)算法,属于 classification (分类)的范畴。
|
||||
|
||||
2、在数据挖掘的应用中,与 unsupervised learning (无监督学习)的 Clustering(聚类)相对应和区别。
|
||||
|
||||
3、广泛应用于 Machine Learning (机器学习),Computer Vision (计算机视觉,装逼一点说,就是 cv)和 Data Mining (数据挖掘)当中。
|
||||
|
||||
### “ Machine (机)” 是什么?
|
||||
|
||||
Classification Machine,是分类器,这个没什么好说的。也可以理解为算法,机器学习领域里面常常用 “机” 也就是 machine 这个字表示算法。
|
||||
|
||||
### “支持向量” 又是什么?
|
||||
|
||||
<b>通俗理解</b>:
|
||||
support vector (支持向量)的意思就是 <b>数据集中的某些点</b>,位置比较特殊。比如 x+y-2=0 这条直线,直线上面区域 x+y-2>0 的全是 A 类,下面的 x+y-2<0 的全是 B 类,我们找这条直线的时候,一般就看聚集在一起的两类数据,他们各自的 <b>最边缘</b> 位置的点,也就是最靠近划分直线的那几个点,而其他点对这条直线的最终位置的确定起不了作用,所以我姑且叫这些点叫 “支持点”(意思就是有用的点),但是在数学上,没这种说法,数学里的点,又可以叫向量,比如 二维点 (x,y) 就是二维向量,三维度的就是三维向量 (x,y,z)。所以 “<b>支持点</b>” 改叫 “<b>支持向量</b>” ,听起来比较专业,而且又装逼,何乐而不为呢?是吧...
|
||||
|
||||
<b>不通俗的理解</b>:
|
||||
在 maximum margin (最大间隔)上的这些点就叫 “支持向量”,我想补充的是为啥这些点就叫 “支持向量” ,因为最后的 classification machine (分类器)的表达式里只含有这些 “支持向量” 的信息,而与其他数据点无关:
|
||||
|
||||

|
||||
|
||||
在这个表达式中,只有支持向量的系数  不等于 0 。
|
||||
|
||||
如果还是不怎么理解,不要紧,看下图:
|
||||
|
||||

|
||||
|
||||
“支持向量” 就是图中用紫色框框圈出来的点...
|
||||
|
||||
|
||||
## Concept (相关概念)
|
||||
|
||||
我们先看一张图
|
||||
|
||||

|
||||
|
||||
`linearly separable (线性可分)`: 如上图中的两组数据,它们之间已经分的足够开了,因此很容易就可以在图中画出一条直线将两组数据点分开。在这种情况下,这组数据就被称为<b>线性可分数据</b>。
|
||||
|
||||
`separating hyperplane(分隔超平面)`: 上述将数据集分隔开来的直线称为<b>分隔超平面</b>。
|
||||
|
||||
`hyperplane(超平面)`: 在上面给出的例子中,由于数据点都在二维平面上,所以此时分隔超平面就只是一条直线。但是,如果所给的数据集是三维的,那么此时用来分隔数据的就是一个平面。显而易见,更高纬度的情况可以依此类推。如果数据是 1024 维的,那么就需要一个 1023 维的某某对象(不是你们的男(女)票)来对数据进行分隔。这个 1023 维的某某对象到底应该叫什么呢? N-1 维呢?该对象被称为<b>超平面</b>,也就是分类的决策边界。分布在超平面一侧的所有数据都属于某个类别,而分布在另一侧的所有数据则属于另一个类别。
|
||||
|
||||
`margin(间隔)`: 我们希望能通过上述的方式来构建分类器,即如果数据点离决策边界越远,那么其最后的预测结果也就越可信。既然这样,我们希望找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能远。这里所说的点到分隔面的距离就是 <b>间隔</b>。我们希望间隔尽可能地大,这是因为如果我们犯错或者在有限数据上训练分类器的话,我们希望分类器尽可能健壮。
|
||||
|
||||
`支持向量(support vector)` : 就是上面所说的离分隔超平面最近的那些点。
|
||||
|
||||
`分类器` : 分类器就是给定一个样本的数据,判定这个样本属于哪个类别的算法。例如在股票涨跌预测中,我们认为前一天的交易量和收盘价对于第二天的涨跌是有影响的,那么分类器就是通过样本的交易量和收盘价预测第二天的涨跌情况的算法。
|
||||
|
||||
`特征` : 在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。
|
||||
|
||||
`线性分类器` : 线性分类器是分类器中的一种,就是判定分类结果的根据是通过特征的线性组合得到的,不能通过特征的非线性运算结果作为判定根据。还以上面的股票涨跌预测问题为例,判断的依据只能是前一天的交易量和收盘价的线性组合,不能将交易量和收盘价进行开方,平方等运算。
|
||||
|
||||
## How does it work? (SVM 原理)
|
||||
|
||||
### 1、引用知乎上 [@简之](https://www.zhihu.com/people/wangjianzhi/answers) 大佬的回答:
|
||||
|
||||
首先我们讲个故事:
|
||||
|
||||
在很久以前的情人节,大侠要去救他的爱人,但魔鬼和他玩了一个游戏。
|
||||
|
||||
魔鬼在桌子上似乎有规律放了两种颜色的球,说:“你用一根棍分开它们?要求:尽量在放更多球之后,仍然适用。”
|
||||
|
||||

|
||||
|
||||
于是大侠这样放,干的不错?
|
||||
|
||||

|
||||
|
||||
然后魔鬼,又在桌上放了更多的球,似乎有一个球站错了阵营。
|
||||
|
||||

|
||||
|
||||
SVM 就是试图把棍放在最佳位置,好让在棍的两边有尽可能大的间隙。
|
||||
|
||||

|
||||
|
||||
现在即使魔鬼放了更多的球,棍仍然是一个好的分界线。
|
||||
|
||||

|
||||
|
||||
然后,在 SVM 工具箱中有另一个更加重要的 trick。 魔鬼看到大侠已经学会了一个 trick ,于是魔鬼给了大侠一个新的挑战。
|
||||
|
||||

|
||||
|
||||
现在,大侠没有棍可以很好帮他分开两种球了,现在怎么办呢?当然像所有武侠片中一样大侠桌子一拍,球飞到空中。然后,凭借大侠的轻功,大侠抓起一张纸,插到了两种球的中间。
|
||||
|
||||

|
||||
|
||||
现在,从魔鬼的角度看这些球,这些球看起来像是被一条曲线分开了。
|
||||
|
||||

|
||||
|
||||
再之后,无聊的大人们,把这些球叫做 <b>「data」</b>,把棍子叫做 <b>「classifier」</b>, 最大间隙 trick 叫做<b>「optimization」</b>, 拍桌子叫做<b>「kernelling」</b>, 那张纸叫做<b>「hyperplane」</b> 。
|
||||
|
||||
有梯子的童鞋,可以看一下这个地方,看视频来更直观的感受:
|
||||
|
||||
https://www.youtube.com/watch?v=3liCbRZPrZA
|
||||
|
||||
|
||||
### 2、引用知乎 [@开膛手水货](https://www.zhihu.com/people/kai-tang-shou-xin/answers) 大佬的回答,我认为是超级通俗的一个版本:
|
||||
|
||||
支持向量机是用来解决分类问题的。
|
||||
|
||||
先考虑最简单的情况,豌豆和米粒,用晒子很快可以分开,小颗粒漏下去,大颗粒保留。
|
||||
|
||||
用一个函数来表示就是当直径 d 大于某个值 D ,就判定为豌豆,小于某个值就是米粒。
|
||||
|
||||
d>D, 豌豆
|
||||
|
||||
d<D,米粒
|
||||
|
||||
在数轴上就是在d左边就是米粒,右边就是绿豆,这是一维的情况。
|
||||
|
||||
但是实际问题没这么简单,考虑的问题不单单是尺寸,一个花的两个品种,怎么分类?
|
||||
|
||||
假设决定他们分类的有两个属性,花瓣尺寸和颜色。单独用一个属性来分类,像刚才分米粒那样,就不行了。这个时候我们设置两个值 尺寸 x 和颜色 y.
|
||||
|
||||
我们把所有的数据都丢到 x-y 平面上作为点,按道理如果只有这两个属性决定了两个品种,数据肯定会按两类聚集在这个二维平面上。
|
||||
|
||||
我们只要找到一条直线,把这两类划分开来,分类就很容易了,以后遇到一个数据,就丢进这个平面,看在直线的哪一边,就是哪一类。
|
||||
|
||||
比如 x+y-2=0 这条直线,我们把数据 (x,y) 代入,只要认为 x+y-2>0 的就是 A 类, x+y-2<0 的就是 B 类。
|
||||
|
||||
以此类推,还有三维的,四维的,N维的 属性的分类,这样构造的也许就不是直线,而是平面,超平面。
|
||||
|
||||
一个三维的函数分类 :x+y+z-2=0,这就是个分类的平面了。
|
||||
|
||||
有时候,分类的那条线不一定是直线,还有可能是曲线,我们通过某些函数来转换,就可以转化成刚才的哪种多维的分类问题,这个就是核函数的思想。
|
||||
|
||||
例如:分类的函数是个圆形 x^2+y^2-4=0 。这个时候令 x^2=a ; y^2=b ,还不就变成了a+b-4=0 这种直线问题了。
|
||||
|
||||
这就是支持向量机的思想。
|
||||
|
||||
### 3、引用 [@胡KF](https://www.zhihu.com/people/hu-kf/answers) 大佬的回答(这个需要一些数学知识):
|
||||
|
||||
如图的例子,(训练集)红色点是我们已知的分类1,(训练集)蓝色点是已知的分类2,我们想寻找一个分隔超平面(图中绿线)(因为示例是二维数据点,所以只是一条线,如果数据是三维的就是平面,如果是三维以上就是超平面)把这两类完全分开,这样的话再来一个样本点需要我们预测的话,我们就可以根据这个分界超平面预测出分类结果。
|
||||
|
||||

|
||||
|
||||
那我们如何选择这个分类超平面呢?从数学上说,超平面的公式是,也就是说如何选取这个 (是个向量)。
|
||||
|
||||
传统方法是根据最小二乘错误法(least squared error),首先随便定选取一个随机平面,也就是随机选取  和 ,然后想必会在训练集中产生大量的错误分类,也就是说, 结果应该大于 0 的时候小于 0 ,应该小于 0 的时候大于 0 。这时候有一个错误损失,也就是说对于所有错误的分类,他们的平方和(least squared error) 为:  , 最小二乘法的目标就是让这个值趋于最小,对  求导取 0 ,采用梯度下降算法,可以求出错误平方和的极值,求出最优的  ,也就是求出最优的超平面。(可以证明,如果基函数是指数族函数,求出的超平面是全局最优的)。
|
||||
|
||||
那我们 SVM 算法的思路是怎样的呢?
|
||||
|
||||
不同于传统的最小二乘策略的思想,我们采用一种新的思路,这个分界面有什么样的特征呢?
|
||||
|
||||
第一,它 “夹” 在两类样本点之间;第二,它离两类样本点中所有 “离它最近的点” ,都离它尽可能的远。如图所示:
|
||||
|
||||

|
||||
|
||||
在虚线上的点,就是我们所找到的离分解超平面最近的样本点,X 类中找到了一个,O 类找到了两个。我们需要分类超平面离这三个样本点都尽可能的远,也就是说,它处在两条虚线的中间。这就是我们找到的分界超平面。
|
||||
|
||||
另外,这里我们就可以解释什么是 “支持向量” 了,支持向量就是虚线上的离分类超平面最近的样本点,因为每一个样本点都是一个多维的向量,向量的每一个维度都是这个样本点的一个特征。比如在根据身高,体重,特征进行男女分类的时候,每一个人是一个向量,向量有两个维度,第一维是身高,第二维是体重。
|
||||
|
||||
介绍完 SVM 的基本思想,我们来探讨一下如何用数学的方法进行 SVM 分类。
|
||||
|
||||
首先我们需要把刚刚说的最大间隔分类器的思想用数学公式表达出来。先定义几何间隔的概念,几何间隔就是在多维空间中一个多维点到一个超平面的距离,根据向量的知识可以算出来:
|
||||
|
||||

|
||||
|
||||
然后对于所有的支持向量,使他们到超平面  的距离最大,也就是
|
||||
|
||||

|
||||
|
||||
因为对于所有支持向量,他们  的值都是一定的,我们假设恒等于 1 ,那么上式变成了  ,并且对于所有的样本点,满足  的约束,因此,可以利用拉格朗日乘数法计算出它的极值。也就是求出这个超平面。
|
||||
|
||||
推导过程略为复杂,详细了解可以参考凸二次规划知识,结合 SMO 算法理解 SVM 计算超平面的详细过程。
|
||||
|
||||
总之,在计算的过程中,我们不需要了解支持向量以外的其他样本点,只需要利用相对于所有样本点来说为数不多的支持向量,就可以求出分类超平面,计算复杂度大为降低。
|
||||
|
||||
### 4、引用知乎 [@靠靠靠谱](https://www.zhihu.com/people/kao-kao-kao-pu/answers) 大佬的理解(这个需要的数学知识更加厉害一点):
|
||||
|
||||
先看思维导图:
|
||||
|
||||
* 左边是求解基本的SVM问题
|
||||
* 右边是相关扩展
|
||||
|
||||

|
||||
|
||||
<b>什么是 SVM ?</b>
|
||||
|
||||
Support Vector Machine, 一个普通的 SVM 就是一条直线罢了,用来完美划分 linearly separable 的两类。但这又不是一条普通的直线,这是无数条可以分类的直线当中最完美的,因为它恰好在两个类的中间,距离两个类的点都一样远。而所谓的 Support vector 就是这些离分界线最近的『点』。如果去掉这些点,直线多半是要改变位置的。可以说是这些 vectors (主,点点) support (谓,定义)了 machine (宾,分类器)...
|
||||
|
||||

|
||||
|
||||
所以谜底就在谜面上啊朋友们,只要找到了这些最靠近的点不就找到了 SVM 了嘛。
|
||||
|
||||
如果是高维的点,SVM 的分界线就是平面或者超平面。其实没有差,都是一刀切两块,我就统统叫直线了。
|
||||
|
||||
<b>怎么求解 SVM ?</b>
|
||||
|
||||
关于这条直线,我们知道
|
||||
|
||||
(1)它离两边一样远,(2)最近距离就是到support vector的距离,其他距离只能更远。
|
||||
|
||||
于是自然而然可以得到重要表达 <b>I. direct representation</b>
|
||||
|
||||

|
||||
|
||||
(可以把 margin 看作是 boundary 的函数,并且想要找到使得是使得 margin 最大化的boundary,而 margin(*) 这个函数是:输入一个 boundary ,计算(正确分类的)所有苹果和香蕉中,到 boundary 的最小距离。)
|
||||
|
||||
又有最大又有最小看起来好矛盾。实际上『最大』是对这个整体使用不同 boundary 层面的最大,『最小』是在比较『点』的层面上的最小。外层在比较 boundary 找最大的 margin ,内层在比较点点找最小的距离。
|
||||
|
||||
其中距离,说白了就是点到直线的距离;只要定义带正负号的距离,是 {苹果+1} 面为正 {香蕉-1} 面为负的距离,互相乘上各自的 label  ,就和谐统一民主富强了。
|
||||
|
||||

|
||||
|
||||
到这里为止已经说完了所有关于SVM的直观了解,如果不想看求解,可以跳过下面一大段直接到 objective function 。
|
||||
|
||||
直接表达虽然清楚但是求解无从下手。做一些简单地等价变换(分母倒上来)可以得到 <b>II. canonical representation </b> (敲黑板)
|
||||
|
||||

|
||||
|
||||
要得到 <b>III. dual representation</b> 之前需要大概知道一下拉格朗日乘子法 (method of lagrange multiplier),它是用在有各种约束条件(各种 "subject to" )下的目标函数,也就是直接可以求导可以引出 dual representation(怎么还没完摔)
|
||||
|
||||

|
||||
|
||||
稍微借用刚刚数学表达里面的内容看个有趣的东西:
|
||||
|
||||
还记得我们怎么预测一个新的水果是苹果还是香蕉吗?我们代入到分界的直线里,然后通过符号来判断。
|
||||
|
||||
刚刚w已经被表达出来了也就是说这个直线现在变成了: 
|
||||
|
||||
看似仿佛用到了所有的训练水果,但是其中  的水果都没有起到作用,剩下的就是小部分靠边边的 Support vectors 呀。
|
||||
|
||||
<b>III. dual representation</b>
|
||||
|
||||

|
||||
|
||||
<b>如果香蕉和苹果不能用直线分割呢?</b>
|
||||
|
||||

|
||||
|
||||
Kernel trick.
|
||||
|
||||
其实用直线分割的时候我们已经使用了 kernel ,那就是线性 kernel , 
|
||||
|
||||
如果要替换 kernel 那么把目标函数里面的内积全部替换成新的 kernel function 就好了,就是这么简单。
|
||||
|
||||
第一个武侠大师的比喻已经说得很直观了,低维非线性的分界线其实在高维是可以线性分割的,可以理解为——『你们是虫子!』分得开个p...(大雾)
|
||||
|
||||
<b>如果香蕉和苹果有交集呢?</b>
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
<b>如果还有梨呢?</b>
|
||||
|
||||

|
||||
|
||||
可以每个类别做一次 SVM:是苹果还是不是苹果?是香蕉还是不是香蕉?是梨子还是不是梨子?从中选出可能性最大的。这是 one-versus-the-rest approach。
|
||||
|
||||
也可以两两做一次 SVM:是苹果还是香蕉?是香蕉还是梨子?是梨子还是苹果?最后三个分类器投票决定。这是 one-versus-one approace。
|
||||
|
||||
但这其实都多多少少有问题,比如苹果特别多,香蕉特别少,我就无脑判断为苹果也不会错太多;多个分类器要放到一个台面上,万一他们的 scale 没有在一个台面上也未可知。
|
||||
|
||||
课后题:
|
||||
1、vector 不愿意 support 怎么办?
|
||||
2、苹果好吃还是香蕉好吃?
|
||||
|
||||
<p>最后送一张图我好爱哈哈哈 (Credit: Burr Settles)</p>
|
||||
|
||||

|
||||
|
||||
<p>[1] Bishop C M. Pattern recognition[J]. Machine Learning, 2006, 128.</p>
|
||||
<p>[2] Friedman J, Hastie T, Tibshirani R. The elements of statistical learning[M]. Springer, Berlin: Springer series in statistics, 2001.</p>
|
||||
<p>[3] James G, Witten D, Hastie T, et al. An introduction to statistical learning[M]. New York: springer, 2013.</p>
|
||||
|
||||
|
||||
## 理解和应用
|
||||
|
||||
### 1、DataMining (数据挖掘)
|
||||
做数据挖掘应用的一种重要算法,也是效果最好的分类算法之一。
|
||||
|
||||
举个例子,就是尽量把样本中的从更高纬度看起来在一起的样本合在一起,比如在一维(直线)空间里的样本从二维平面上可以分成不同类别,而在二维平面上分散的样本如果从第三维空间上来看就可以对他们做分类。
|
||||
|
||||
支持向量机算法目的是找出最优超平面,使分类间隔最大,要求不但正确分开,而且使分类间隔最大,在两类样本中离分类平面最近且位于平行于最优超平面的超平面上的点就是支持向量,为找到最优超平面只要找到所有支持向量即可。
|
||||
|
||||
对于非线性支持向量机,通常做法是把线性不可分转化成线性可分,通过一个非线性映射将输入到低维空间中的数据特性映射到高维线性特征空间中,在高维空间中求线性最优分类超平面。
|
||||
|
||||
### 2、scikit-learn (sklearn)
|
||||
|
||||
SVM 的基本原理基本上已经说的差不多了,下面咱们就来看看 SVM 在实际应用该如何使用了。幸运的是,在 python 下面,sklearn 提供了一个非常好用的机器学习算法,我们调用相关的包就好啦。
|
||||
|
||||

|
||||
|
||||
|
||||
## 小结
|
||||
|
||||
学习 SVM 需要有耐心,当初研究这个部分的时候,炼哥(github [jiangzhonglian](https://github.com/jiangzhonglian)),法超大佬(github [geekidentity](https://github.com/geekidentity)),羊三大佬(github [sheepmen](https://github.com/sheepmen)),庭哥(github [wangyangting](https://github.com/wangyangting))都花费了好长时间,我只能躲在角落发抖....
|
||||
|
|
@ -0,0 +1,568 @@
|
|||
# 第6章 支持向量机
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## 支持向量机 概述
|
||||
|
||||
支持向量机(Support Vector Machines, SVM):是一种监督学习算法。
|
||||
* 支持向量(Support Vector)就是离分隔超平面最近的那些点。
|
||||
* 机(Machine)就是表示一种算法,而不是表示机器。
|
||||
|
||||
## 支持向量机 场景
|
||||
|
||||
* 要给左右两边的点进行分类
|
||||
* 明显发现:选择D会比B、C分隔的效果要好很多。
|
||||
|
||||
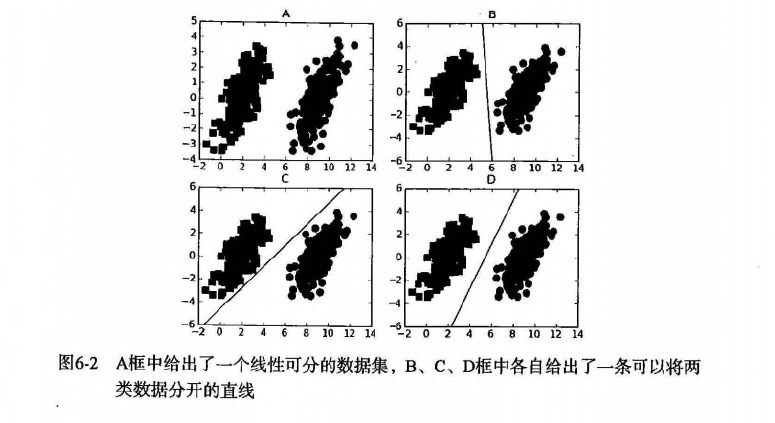
|
||||
|
||||
|
||||
## 支持向量机 原理
|
||||
|
||||
### SVM 工作原理
|
||||
|
||||

|
||||
|
||||
对于上述的苹果和香蕉,我们想象为2种水果类型的炸弹。(保证距离最近的炸弹,距离它们最远)
|
||||
|
||||
1. 寻找最大分类间距
|
||||
2. 转而通过拉格朗日函数求优化的问题
|
||||
|
||||
|
||||
* 数据可以通过画一条直线就可以将它们完全分开,这组数据叫`线性可分(linearly separable)`数据,而这条分隔直线称为`分隔超平面(separating hyperplane)`。
|
||||
* 如果数据集上升到1024维呢?那么需要1023维来分隔数据集,也就说需要N-1维的对象来分隔,这个对象叫做`超平面(hyperlane)`,也就是分类的决策边界。
|
||||
|
||||
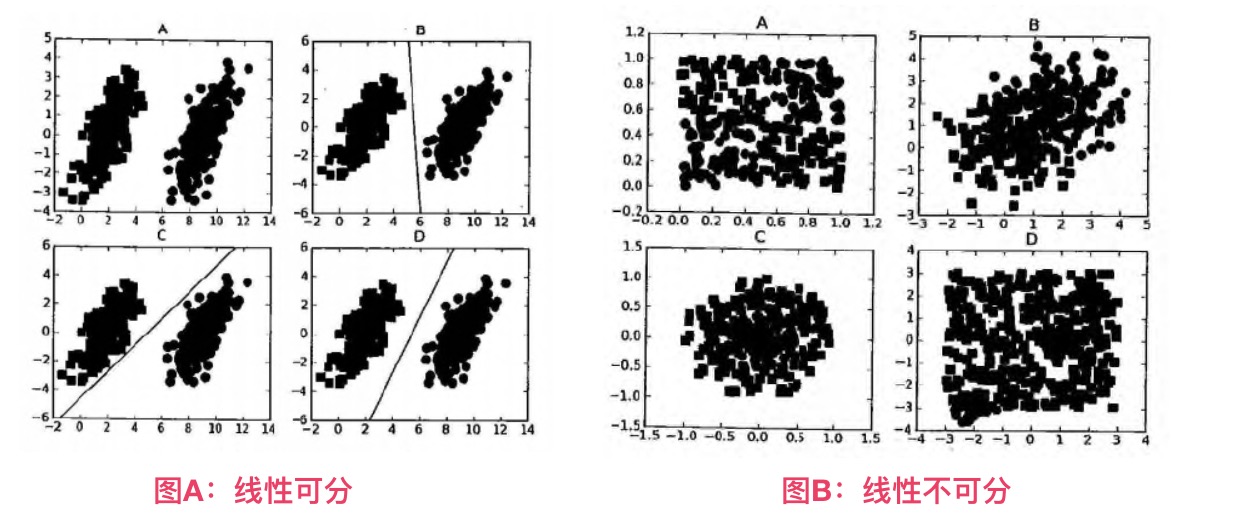
|
||||
|
||||
### 寻找最大间隔
|
||||
|
||||
#### 为什么寻找最大间隔
|
||||
|
||||
```
|
||||
摘录地址:http://slideplayer.com/slide/8610144 (第12条信息)
|
||||
Support Vector Machines: Slide 12 Copyright © 2001, 2003, Andrew W. Moore Why Maximum Margin?
|
||||
|
||||
1.Intuitively this feels safest.
|
||||
2.If we’ve made a small error in the location of the boundary (it’s been jolted in its perpendicular direction) this gives us least chance of causing a misclassification.
|
||||
3.CV is easy since the model is immune to removal of any non-support-vector datapoints.
|
||||
4.There’s some theory that this is a good thing.
|
||||
5.Empirically it works very very well.
|
||||
|
||||
* * *
|
||||
|
||||
1. 直觉上是最安全的
|
||||
2. 如果我们在边界的位置发生了一个小错误(它在垂直方向上被颠倒),这给我们最小的可能导致错误分类。
|
||||
3. CV(cross validation 交叉验证)很容易,因为该模型对任何非支持向量数据点的去除是免疫的。
|
||||
4. 有一些理论表明这是一件好东西。
|
||||
5. 从经验角度上说它的效果非常非常好。
|
||||
```
|
||||
|
||||
#### 怎么寻找最大间隔
|
||||
|
||||
> 点到超平面的距离
|
||||
|
||||
* 分隔超平面`函数间距`: \\(y(x)=w^Tx+b\\)
|
||||
* 分类的结果: \\(f(x)=sign(w^Tx+b)\\) (sign表示>0为1,<0为-1,=0为0)
|
||||
* 点到超平面的`几何间距`: \\(d(x)=(w^Tx+b)/||w||\\) (||w||表示w矩阵的二范数=> \\(\sqrt{w^T*w}\\), 点到超平面的距离也是类似的)
|
||||
|
||||

|
||||
|
||||
> 拉格朗日乘子法
|
||||
|
||||
* 类别标签用-1、1,是为了后期方便 \\(label*(w^Tx+b)\\) 的标识和距离计算;如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,否则预测错误。
|
||||
* 现在目标很明确,就是要找到`w`和`b`,因此我们必须要找到最小间隔的数据点,也就是前面所说的`支持向量`。
|
||||
* 也就说,让最小的距离取最大.(最小的距离:就是最小间隔的数据点;最大:就是最大间距,为了找出最优超平面--最终就是支持向量)
|
||||
* 目标函数:\\(arg: max_{关于w, b} \left( min[label*(w^Tx+b)]*\frac{1}{||w||} \right) \\)
|
||||
1. 如果 \\(label*(w^Tx+b)>0\\) 表示预测正确,也称`函数间隔`,\\(||w||\\) 可以理解为归一化,也称`几何间隔`。
|
||||
2. 令 \\(label*(w^Tx+b)>=1\\), 因为0~1之间,得到的点是存在误判的可能性,所以要保障 \\(min[label*(w^Tx+b)]=1\\),才能更好降低噪音数据影响。
|
||||
3. 所以本质上是求 \\(arg: max_{关于w, b} \frac{1}{||w||} \\);也就说,我们约束(前提)条件是: \\(label*(w^Tx+b)=1\\)
|
||||
* 新的目标函数求解: \\(arg: max_{关于w, b} \frac{1}{||w||} \\)
|
||||
* => 就是求: \\(arg: min_{关于w, b} ||w|| \\) (求矩阵会比较麻烦,如果x只是 \\(\frac{1}{2}*x^2\\) 的偏导数,那么。。同样是求最小值)
|
||||
* => 就是求: \\(arg: min_{关于w, b} (\frac{1}{2}*||w||^2)\\) (二次函数求导,求极值,平方也方便计算)
|
||||
* 本质上就是求线性不等式的二次优化问题(求分隔超平面,等价于求解相应的凸二次规划问题)
|
||||
* 通过拉格朗日乘子法,求二次优化问题
|
||||
* 假设需要求极值的目标函数 (objective function) 为 f(x,y),限制条件为 φ(x,y)=M # M=1
|
||||
* 设g(x,y)=M-φ(x,y) # 临时φ(x,y)表示下文中 \\(label*(w^Tx+b)\\)
|
||||
* 定义一个新函数: F(x,y,λ)=f(x,y)+λg(x,y)
|
||||
* a为λ(a>=0),代表要引入的拉格朗日乘子(Lagrange multiplier)
|
||||
* 那么: \\(L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 因为:\\(label*(w^Tx+b)>=1, \alpha>=0\\) , 所以 \\(\alpha*[1-label*(w^Tx+b)]<=0\\) , \\(\sum_{i=1}^{n} \alpha_i * [1-label*(w^Tx+b)]<=0\\)
|
||||
* 当 \\(label*(w^Tx+b)>1\\) 则 \\(\alpha=0\\) ,表示该点为<font color=red>非支持向量</font>
|
||||
* 相当于求解: \\(max_{关于\alpha} L(w,b,\alpha) = \frac{1}{2} *||w||^2\\)
|
||||
* 如果求: \\(min_{关于w, b} \frac{1}{2} *||w||^2\\) , 也就是要求: \\(min_{关于w, b} \left( max_{关于\alpha} L(w,b,\alpha)\right)\\)
|
||||
* 现在转化到对偶问题的求解
|
||||
* \\(min_{关于w, b} \left(max_{关于\alpha} L(w,b,\alpha) \right) \\) >= \\(max_{关于\alpha} \left(min_{关于w, b}\ L(w,b,\alpha) \right) \\)
|
||||
* 现在分2步
|
||||
* 先求: \\(min_{关于w, b} L(w,b,\alpha)=\frac{1}{2} * ||w||^2 + \sum_{i=1}^{n} \alpha_i * [1 - label * (w^Tx+b)]\\)
|
||||
* 就是求`L(w,b,a)`关于[w, b]的偏导数, 得到`w和b的值`,并化简为:`L和a的方程`。
|
||||
* 参考: 如果公式推导还是不懂,也可以参考《统计学习方法》李航-P103<学习的对偶算法>
|
||||

|
||||
* 终于得到课本上的公式: \\(max_{关于\alpha} \left( \sum_{i=1}^{m} \alpha_i - \frac{1}{2} \sum_{i, j=1}^{m} label_i·label_j·\alpha_i·\alpha_j·<x_i, x_j> \right) \\)
|
||||
* 约束条件: \\(a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
|
||||
> 松弛变量(slack variable)
|
||||
|
||||
参考地址:http://blog.csdn.net/wusecaiyun/article/details/49659183
|
||||
|
||||
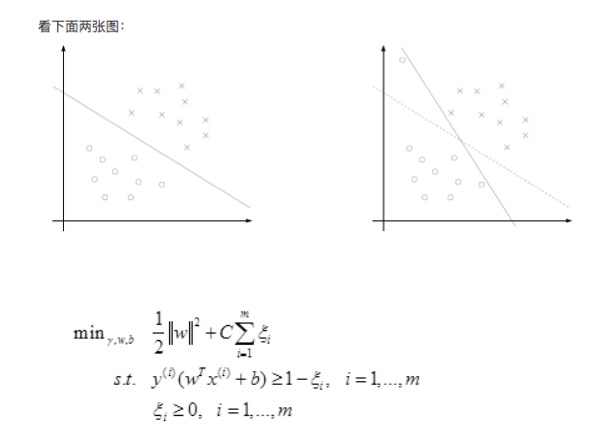
|
||||
|
||||
* 我们知道几乎所有的数据都不那么干净, 通过引入松弛变量来 `允许数据点可以处于分隔面错误的一侧`。
|
||||
* 约束条件: \\(C>=a>=0\\) 并且 \\(\sum_{i=1}^{m} a_i·label_i=0\\)
|
||||
* 总的来说:
|
||||
*  表示 `松弛变量`
|
||||
* 常量C是 `惩罚因子`, 表示离群点的权重(用于控制“最大化间隔”和“保证大部分点的函数间隔小于1.0” )
|
||||
* \\(label*(w^Tx+b) > 1\\) and alpha = 0 (在边界外,就是非支持向量)
|
||||
* \\(label*(w^Tx+b) = 1\\) and 0< alpha < C (在分割超平面上,就支持向量)
|
||||
* \\(label*(w^Tx+b) < 1\\) and alpha = C (在分割超平面内,是误差点 -> C表示它该受到的惩罚因子程度)
|
||||
* 参考地址:https://www.zhihu.com/question/48351234/answer/110486455
|
||||
* C值越大,表示离群点影响越大,就越容易过度拟合;反之有可能欠拟合。
|
||||
* 我们看到,目标函数控制了离群点的数目和程度,使大部分样本点仍然遵守限制条件。
|
||||
* 例如:正类有10000个样本,而负类只给了100个(C越大表示100个负样本的影响越大,就会出现过度拟合,所以C决定了负样本对模型拟合程度的影响!,C就是一个非常关键的优化点!)
|
||||
* 这一结论十分直接,SVM中的主要工作就是要求解 alpha.
|
||||
|
||||
### SMO 高效优化算法
|
||||
|
||||
* SVM有很多种实现,最流行的一种实现是: `序列最小优化(Sequential Minimal Optimization, SMO)算法`。
|
||||
* 下面还会介绍一种称为 `核函数(kernel)` 的方式将SVM扩展到更多数据集上。
|
||||
* 注意:`SVM几何含义比较直观,但其算法实现较复杂,牵扯大量数学公式的推导。`
|
||||
|
||||
> 序列最小优化(Sequential Minimal Optimization, SMO)
|
||||
|
||||
* 创建作者:John Platt
|
||||
* 创建时间:1996年
|
||||
* SMO用途:用于训练 SVM
|
||||
* SMO目标:求出一系列 alpha 和 b,一旦求出 alpha,就很容易计算出权重向量 w 并得到分隔超平面。
|
||||
* SMO思想:是将大优化问题分解为多个小优化问题来求解的。
|
||||
* SMO原理:每次循环选择两个 alpha 进行优化处理,一旦找出一对合适的 alpha,那么就增大一个同时减少一个。
|
||||
* 这里指的合适必须要符合一定的条件
|
||||
1. 这两个 alpha 必须要在间隔边界之外
|
||||
2. 这两个 alpha 还没有进行过区间化处理或者不在边界上。
|
||||
* 之所以要同时改变2个 alpha;原因是我们有一个约束条件: \\(\sum_{i=1}^{m} a_i·label_i=0\\);如果只是修改一个 alpha,很可能导致约束条件失效。
|
||||
|
||||
> SMO 伪代码大致如下:
|
||||
|
||||
```
|
||||
创建一个 alpha 向量并将其初始化为0向量
|
||||
当迭代次数小于最大迭代次数时(外循环)
|
||||
对数据集中的每个数据向量(内循环):
|
||||
如果该数据向量可以被优化
|
||||
随机选择另外一个数据向量
|
||||
同时优化这两个向量
|
||||
如果两个向量都不能被优化,退出内循环
|
||||
如果所有向量都没被优化,增加迭代数目,继续下一次循环
|
||||
```
|
||||
|
||||
### SVM 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任意方法。
|
||||
准备数据:需要数值型数据。
|
||||
分析数据:有助于可视化分隔超平面。
|
||||
训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优。
|
||||
测试算法:十分简单的计算过程就可以实现。
|
||||
使用算法:几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二类分类器,对多类问题应用SVM需要对代码做一些修改。
|
||||
```
|
||||
|
||||
### SVM 算法特点
|
||||
|
||||
```
|
||||
优点:泛化(由具体的、个别的扩大为一般的,就是说:模型训练完后的新样本)错误率低,计算开销不大,结果易理解。
|
||||
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适合于处理二分类问题。
|
||||
使用数据类型:数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 课本案例(无核函数)
|
||||
|
||||
#### 项目概述
|
||||
|
||||
对小规模数据点进行分类
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集数据
|
||||
|
||||
文本文件格式:
|
||||
|
||||
```python
|
||||
3.542485 1.977398 -1
|
||||
3.018896 2.556416 -1
|
||||
7.551510 -1.580030 1
|
||||
2.114999 -0.004466 -1
|
||||
8.127113 1.274372 1
|
||||
```
|
||||
|
||||
> 准备数据
|
||||
|
||||
```python
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
对文件进行逐行解析,从而得到第行的类标签和整个特征矩阵
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 特征矩阵
|
||||
labelMat 类标签
|
||||
"""
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
```
|
||||
|
||||
> 分析数据: 无
|
||||
|
||||
> 训练算法
|
||||
|
||||
```python
|
||||
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
"""smoSimple
|
||||
|
||||
Args:
|
||||
dataMatIn 特征集合
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率(是指在某个体系中能减小一些因素或选择对某个系统产生不稳定的概率。)
|
||||
maxIter 退出前最大的循环次数
|
||||
Returns:
|
||||
b 模型的常量值
|
||||
alphas 拉格朗日乘子
|
||||
"""
|
||||
dataMatrix = mat(dataMatIn)
|
||||
# 矩阵转置 和 .T 一样的功能
|
||||
labelMat = mat(classLabels).transpose()
|
||||
m, n = shape(dataMatrix)
|
||||
|
||||
# 初始化 b和alphas(alpha有点类似权重值。)
|
||||
b = 0
|
||||
alphas = mat(zeros((m, 1)))
|
||||
|
||||
# 没有任何alpha改变的情况下遍历数据的次数
|
||||
iter = 0
|
||||
while (iter < maxIter):
|
||||
# w = calcWs(alphas, dataMatIn, classLabels)
|
||||
# print("w:", w)
|
||||
|
||||
# 记录alpha是否已经进行优化,每次循环时设为0,然后再对整个集合顺序遍历
|
||||
alphaPairsChanged = 0
|
||||
for i in range(m):
|
||||
# print 'alphas=', alphas
|
||||
# print 'labelMat=', labelMat
|
||||
# print 'multiply(alphas, labelMat)=', multiply(alphas, labelMat)
|
||||
# 我们预测的类别 y[i] = w^Tx[i]+b; 其中因为 w = Σ(1~n) a[n]*label[n]*x[n]
|
||||
fXi = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[i, :].T)) + b
|
||||
# 预测结果与真实结果比对,计算误差Ei
|
||||
Ei = fXi - float(labelMat[i])
|
||||
|
||||
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
|
||||
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
|
||||
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
'''
|
||||
# 检验训练样本(xi, yi)是否满足KKT条件
|
||||
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
|
||||
yi*f(i) == 1 and 0<alpha< C (on the boundary)
|
||||
yi*f(i) <= 1 and alpha = C (between the boundary)
|
||||
'''
|
||||
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
|
||||
|
||||
# 如果满足优化的条件,我们就随机选取非i的一个点,进行优化比较
|
||||
j = selectJrand(i, m)
|
||||
# 预测j的结果
|
||||
fXj = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[j, :].T)) + b
|
||||
Ej = fXj - float(labelMat[j])
|
||||
alphaIold = alphas[i].copy()
|
||||
alphaJold = alphas[j].copy()
|
||||
|
||||
# L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接执行continue语句
|
||||
# labelMat[i] != labelMat[j] 表示异侧,就相减,否则是同侧,就相加。
|
||||
if (labelMat[i] != labelMat[j]):
|
||||
L = max(0, alphas[j] - alphas[i])
|
||||
H = min(C, C + alphas[j] - alphas[i])
|
||||
else:
|
||||
L = max(0, alphas[j] + alphas[i] - C)
|
||||
H = min(C, alphas[j] + alphas[i])
|
||||
# 如果相同,就没法优化了
|
||||
if L == H:
|
||||
print("L==H")
|
||||
continue
|
||||
|
||||
# eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
|
||||
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
|
||||
eta = 2.0 * dataMatrix[i, :]*dataMatrix[j, :].T - dataMatrix[i, :]*dataMatrix[i, :].T - dataMatrix[j, :]*dataMatrix[j, :].T
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
continue
|
||||
|
||||
# 计算出一个新的alphas[j]值
|
||||
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
|
||||
# 并使用辅助函数,以及L和H对其进行调整
|
||||
alphas[j] = clipAlpha(alphas[j], H, L)
|
||||
# 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
|
||||
if (abs(alphas[j] - alphaJold) < 0.00001):
|
||||
print("j not moving enough")
|
||||
continue
|
||||
# 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
|
||||
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
|
||||
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
|
||||
# w= Σ[1~n] ai*yi*xi => b = yj- Σ[1~n] ai*yi(xi*xj)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
|
||||
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[i, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i, :]*dataMatrix[j, :].T
|
||||
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[j, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j, :]*dataMatrix[j, :].T
|
||||
if (0 < alphas[i]) and (C > alphas[i]):
|
||||
b = b1
|
||||
elif (0 < alphas[j]) and (C > alphas[j]):
|
||||
b = b2
|
||||
else:
|
||||
b = (b1 + b2)/2.0
|
||||
alphaPairsChanged += 1
|
||||
print("iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
# 在for循环外,检查alpha值是否做了更新,如果更新则将iter设为0后继续运行程序
|
||||
# 直到更新完毕后,iter次循环无变化,才退出循环。
|
||||
if (alphaPairsChanged == 0):
|
||||
iter += 1
|
||||
else:
|
||||
iter = 0
|
||||
print("iteration number: %d" % iter)
|
||||
return b, alphas
|
||||
```
|
||||
|
||||
[完整代码地址:SVM简化版,应用简化版SMO算法处理小规模数据集](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-simple.py>
|
||||
|
||||
[完整代码地址:SVM完整版,使用完整 Platt SMO算法加速优化,优化点:选择alpha的方式不同](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete_Non-Kernel.py>
|
||||
|
||||
## 核函数(kernel) 使用
|
||||
|
||||
* 对于线性可分的情况,效果明显
|
||||
* 对于非线性的情况也一样,此时需要用到一种叫`核函数(kernel)`的工具将数据转化为分类器易于理解的形式。
|
||||
|
||||
> 利用核函数将数据映射到高维空间
|
||||
|
||||
* 使用核函数:可以将数据从某个特征空间到另一个特征空间的映射。(通常情况下:这种映射会将低维特征空间映射到高维空间。)
|
||||
* 如果觉得特征空间很装逼、很难理解。
|
||||
* 可以把核函数想象成一个包装器(wrapper)或者是接口(interface),它能将数据从某个很难处理的形式转换成为另一个较容易处理的形式。
|
||||
* 经过空间转换后:低维需要解决的非线性问题,就变成了高维需要解决的线性问题。
|
||||
* SVM 优化特别好的地方,在于所有的运算都可以写成内积(inner product: 是指2个向量相乘,得到单个标量 或者 数值);内积替换成核函数的方式被称为`核技巧(kernel trick)`或者`核"变电"(kernel substation)`
|
||||
* 核函数并不仅仅应用于支持向量机,很多其他的机器学习算法也都用到核函数。最流行的核函数:径向基函数(radial basis function)
|
||||
* 径向基函数的高斯版本,其具体的公式为:
|
||||
|
||||

|
||||
|
||||
### 项目案例: 手写数字识别的优化(有核函数)
|
||||
|
||||
#### 项目概述
|
||||
|
||||
```python
|
||||
你的老板要求:你写的那个手写识别程序非常好,但是它占用内存太大。顾客无法通过无线的方式下载我们的应用。
|
||||
所以:我们可以考虑使用支持向量机,保留支持向量就行(knn需要保留所有的向量),就可以获得非常好的效果。
|
||||
```
|
||||
|
||||
#### 开发流程
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
|
||||
```python
|
||||
00000000000000001111000000000000
|
||||
00000000000000011111111000000000
|
||||
00000000000000011111111100000000
|
||||
00000000000000011111111110000000
|
||||
00000000000000011111111110000000
|
||||
00000000000000111111111100000000
|
||||
00000000000000111111111100000000
|
||||
00000000000001111111111100000000
|
||||
00000000000000111111111100000000
|
||||
00000000000000111111111100000000
|
||||
00000000000000111111111000000000
|
||||
00000000000001111111111000000000
|
||||
00000000000011111111111000000000
|
||||
00000000000111111111110000000000
|
||||
00000000001111111111111000000000
|
||||
00000001111111111111111000000000
|
||||
00000011111111111111110000000000
|
||||
00000111111111111111110000000000
|
||||
00000111111111111111110000000000
|
||||
00000001111111111111110000000000
|
||||
00000001111111011111110000000000
|
||||
00000000111100011111110000000000
|
||||
00000000000000011111110000000000
|
||||
00000000000000011111100000000000
|
||||
00000000000000111111110000000000
|
||||
00000000000000011111110000000000
|
||||
00000000000000011111110000000000
|
||||
00000000000000011111111000000000
|
||||
00000000000000011111111000000000
|
||||
00000000000000011111111000000000
|
||||
00000000000000000111111110000000
|
||||
00000000000000000111111100000000
|
||||
|
||||
```
|
||||
|
||||
> 准备数据:基于二值图像构造向量
|
||||
|
||||
`将 32*32的文本转化为 1*1024的矩阵`
|
||||
|
||||
```python
|
||||
def img2vector(filename):
|
||||
returnVect = zeros((1, 1024))
|
||||
fr = open(filename)
|
||||
for i in range(32):
|
||||
lineStr = fr.readline()
|
||||
for j in range(32):
|
||||
returnVect[0, 32 * i + j] = int(lineStr[j])
|
||||
return returnVect
|
||||
|
||||
def loadImages(dirName):
|
||||
from os import listdir
|
||||
hwLabels = []
|
||||
print(dirName)
|
||||
trainingFileList = listdir(dirName) # load the training set
|
||||
m = len(trainingFileList)
|
||||
trainingMat = zeros((m, 1024))
|
||||
for i in range(m):
|
||||
fileNameStr = trainingFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
if classNumStr == 9:
|
||||
hwLabels.append(-1)
|
||||
else:
|
||||
hwLabels.append(1)
|
||||
trainingMat[i, :] = img2vector('%s/%s' % (dirName, fileNameStr))
|
||||
return trainingMat, hwLabels
|
||||
```
|
||||
|
||||
> 分析数据:对图像向量进行目测
|
||||
|
||||
> 训练算法:采用两种不同的核函数,并对径向基核函数采用不同的设置来运行SMO算法
|
||||
|
||||
```python
|
||||
def kernelTrans(X, A, kTup): # calc the kernel or transform data to a higher dimensional space
|
||||
"""
|
||||
核转换函数
|
||||
Args:
|
||||
X dataMatIn数据集
|
||||
A dataMatIn数据集的第i行的数据
|
||||
kTup 核函数的信息
|
||||
|
||||
Returns:
|
||||
|
||||
"""
|
||||
m, n = shape(X)
|
||||
K = mat(zeros((m, 1)))
|
||||
if kTup[0] == 'lin':
|
||||
# linear kernel: m*n * n*1 = m*1
|
||||
K = X * A.T
|
||||
elif kTup[0] == 'rbf':
|
||||
for j in range(m):
|
||||
deltaRow = X[j, :] - A
|
||||
K[j] = deltaRow * deltaRow.T
|
||||
# 径向基函数的高斯版本
|
||||
K = exp(K / (-1 * kTup[1] ** 2)) # divide in NumPy is element-wise not matrix like Matlab
|
||||
else:
|
||||
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
|
||||
return K
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
|
||||
"""
|
||||
完整SMO算法外循环,与smoSimple有些类似,但这里的循环退出条件更多一些
|
||||
Args:
|
||||
dataMatIn 数据集
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率
|
||||
maxIter 退出前最大的循环次数
|
||||
kTup 包含核函数信息的元组
|
||||
Returns:
|
||||
b 模型的常量值
|
||||
alphas 拉格朗日乘子
|
||||
"""
|
||||
|
||||
# 创建一个 optStruct 对象
|
||||
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler, kTup)
|
||||
iter = 0
|
||||
entireSet = True
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 循环遍历:循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 当entireSet=true or 非边界alpha对没有了;就开始寻找 alpha对,然后决定是否要进行else。
|
||||
if entireSet:
|
||||
# 在数据集上遍历所有可能的alpha
|
||||
for i in range(oS.m):
|
||||
# 是否存在alpha对,存在就+1
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
# print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
|
||||
# 对已存在 alpha对,选出非边界的alpha值,进行优化。
|
||||
else:
|
||||
# 遍历所有的非边界alpha值,也就是不在边界0或C上的值。
|
||||
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
# print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
|
||||
# 如果找到alpha对,就优化非边界alpha值,否则,就重新进行寻找,如果寻找一遍 遍历所有的行还是没找到,就退出循环。
|
||||
if entireSet:
|
||||
entireSet = False # toggle entire set loop
|
||||
elif (alphaPairsChanged == 0):
|
||||
entireSet = True
|
||||
print("iteration number: %d" % iter)
|
||||
return oS.b, oS.alphas
|
||||
```
|
||||
|
||||
> 测试算法:便携一个函数来测试不同的和函数并计算错误率
|
||||
|
||||
```python
|
||||
def testDigits(kTup=('rbf', 10)):
|
||||
|
||||
# 1. 导入训练数据
|
||||
dataArr, labelArr = loadImages('data/6.SVM/trainingDigits')
|
||||
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
svInd = nonzero(alphas.A > 0)[0]
|
||||
sVs = datMat[svInd]
|
||||
labelSV = labelMat[svInd]
|
||||
# print("there are %d Support Vectors" % shape(sVs)[0])
|
||||
m, n = shape(datMat)
|
||||
errorCount = 0
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
|
||||
# 1*m * m*1 = 1*1 单个预测结果
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]): errorCount += 1
|
||||
print("the training error rate is: %f" % (float(errorCount) / m))
|
||||
|
||||
# 2. 导入测试数据
|
||||
dataArr, labelArr = loadImages('data/6.SVM/testDigits')
|
||||
errorCount = 0
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
m, n = shape(datMat)
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
|
||||
# 1*m * m*1 = 1*1 单个预测结果
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]): errorCount += 1
|
||||
print("the test error rate is: %f" % (float(errorCount) / m))
|
||||
```
|
||||
|
||||
> 使用算法:一个图像识别的完整应用还需要一些图像处理的知识,这里并不打算深入介绍
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/6.SVM/svm-complete.py>
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](http://cwiki.apachecn.org/display/~jiangzhonglian) [geekidentity](http://cwiki.apachecn.org/display/~houfachao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,660 @@
|
|||
# 第7章 集成方法 ensemble method
|
||||
|
||||

|
||||
|
||||
## 集成方法: ensemble method(元算法: meta algorithm) 概述
|
||||
|
||||
* 概念:是对其他算法进行组合的一种形式。
|
||||
* 通俗来说: 当做重要决定时,大家可能都会考虑吸取多个专家而不只是一个人的意见。
|
||||
机器学习处理问题时又何尝不是如此? 这就是集成方法背后的思想。
|
||||
|
||||
* 集成方法:
|
||||
1. 投票选举(bagging: 自举汇聚法 bootstrap aggregating): 是基于数据随机重抽样分类器构造的方法
|
||||
2. 再学习(boosting): 是基于所有分类器的加权求和的方法
|
||||
|
||||
|
||||
## 集成方法 场景
|
||||
|
||||
目前 bagging 方法最流行的版本是: 随机森林(random forest)<br/>
|
||||
选男友:美女选择择偶对象的时候,会问几个闺蜜的建议,最后选择一个综合得分最高的一个作为男朋友
|
||||
|
||||
目前 boosting 方法最流行的版本是: AdaBoost<br/>
|
||||
追女友:3个帅哥追同一个美女,第1个帅哥失败->(传授经验:姓名、家庭情况) 第2个帅哥失败->(传授经验:兴趣爱好、性格特点) 第3个帅哥成功
|
||||
|
||||
> bagging 和 boosting 区别是什么?
|
||||
|
||||
1. bagging 是一种与 boosting 很类似的技术, 所使用的多个分类器的类型(数据量和特征量)都是一致的。
|
||||
2. bagging 是由不同的分类器(1.数据随机化 2.特征随机化)经过训练,综合得出的出现最多分类结果;boosting 是通过调整已有分类器错分的那些数据来获得新的分类器,得出目前最优的结果。
|
||||
3. bagging 中的分类器权重是相等的;而 boosting 中的分类器加权求和,所以权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
|
||||
|
||||
|
||||
## 随机森林
|
||||
|
||||
### 随机森林 概述
|
||||
|
||||
* 随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。
|
||||
* 决策树相当于一个大师,通过自己在数据集中学到的知识用于新数据的分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
|
||||
|
||||
### 随机森林 原理
|
||||
|
||||
那随机森林具体如何构建呢?<br/>
|
||||
有两个方面:<br/>
|
||||
1. 数据的随机性化<br/>
|
||||
2. 待选特征的随机化<br/>
|
||||
|
||||
使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
|
||||
|
||||
> 数据的随机化:使得随机森林中的决策树更普遍化一点,适合更多的场景。
|
||||
|
||||
(有放回的准确率在:70% 以上, 无放回的准确率在:60% 以上)
|
||||
1. 采取有放回的抽样方式 构造子数据集,保证不同子集之间的数量级一样(不同子集/同一子集 之间的元素可以重复)
|
||||
2. 利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。
|
||||
3. 然后统计子决策树的投票结果,得到最终的分类 就是 随机森林的输出结果。
|
||||
4. 如下图,假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
|
||||
|
||||
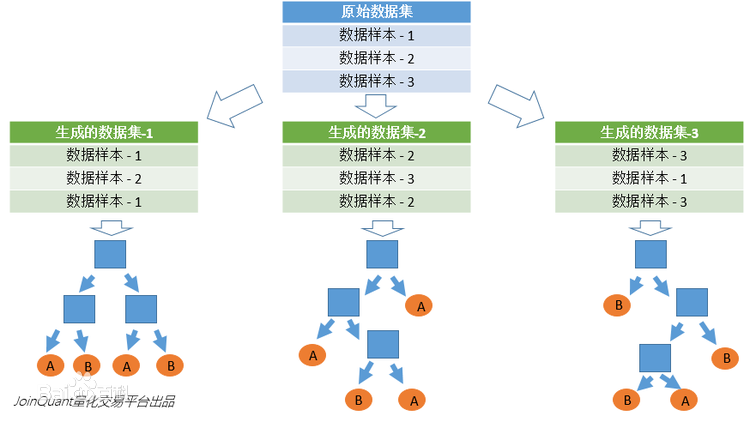
|
||||
|
||||
> 待选特征的随机化
|
||||
|
||||
1. 子树从所有的待选特征中随机选取一定的特征。
|
||||
2. 在选取的特征中选取最优的特征。
|
||||
|
||||
下图中,蓝色的方块代表所有可以被选择的特征,也就是目前的待选特征;黄色的方块是分裂特征。<br/>
|
||||
左边是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征(别忘了前文提到的ID3算法,C4.5算法,CART算法等等),完成分裂。<br/>
|
||||
右边是一个随机森林中的子树的特征选取过程。<br/>
|
||||
|
||||
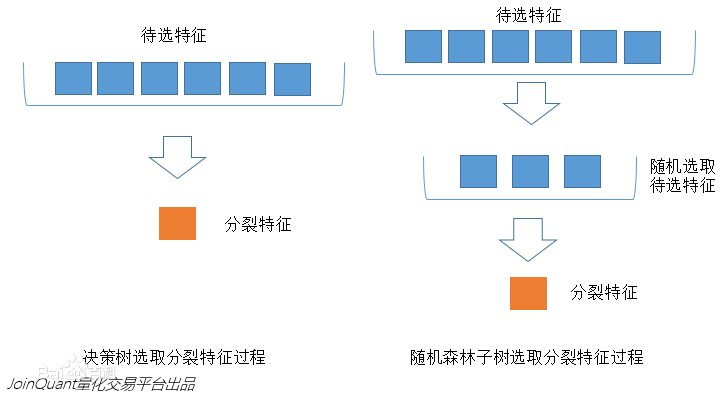
|
||||
|
||||
> 随机森林 开发流程
|
||||
|
||||
```
|
||||
收集数据:任何方法
|
||||
准备数据:转换样本集
|
||||
分析数据:任何方法
|
||||
训练算法:通过数据随机化和特征随机化,进行多实例的分类评估
|
||||
测试算法:计算错误率
|
||||
使用算法:输入样本数据,然后运行 随机森林 算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
|
||||
```
|
||||
|
||||
> 随机森林 算法特点
|
||||
|
||||
```
|
||||
优点:几乎不需要输入准备、可实现隐式特征选择、训练速度非常快、其他模型很难超越、很难建立一个糟糕的随机森林模型、大量优秀、免费以及开源的实现。
|
||||
缺点:劣势在于模型大小、是个很难去解释的黑盒子。
|
||||
适用数据范围:数值型和标称型
|
||||
```
|
||||
|
||||
### 项目案例: 声纳信号分类
|
||||
|
||||
#### 项目概述
|
||||
|
||||
这是 Gorman 和 Sejnowski 在研究使用神经网络的声纳信号分类中使用的数据集。任务是训练一个模型来区分声纳信号。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供的文本文件
|
||||
准备数据:转换样本集
|
||||
分析数据:手工检查数据
|
||||
训练算法:在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
测试算法:在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分
|
||||
使用算法:若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
```
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
|
||||
样本数据:sonar-all-data.txt
|
||||
|
||||
```
|
||||
0.02,0.0371,0.0428,0.0207,0.0954,0.0986,0.1539,0.1601,0.3109,0.2111,0.1609,0.1582,0.2238,0.0645,0.066,0.2273,0.31,0.2999,0.5078,0.4797,0.5783,0.5071,0.4328,0.555,0.6711,0.6415,0.7104,0.808,0.6791,0.3857,0.1307,0.2604,0.5121,0.7547,0.8537,0.8507,0.6692,0.6097,0.4943,0.2744,0.051,0.2834,0.2825,0.4256,0.2641,0.1386,0.1051,0.1343,0.0383,0.0324,0.0232,0.0027,0.0065,0.0159,0.0072,0.0167,0.018,0.0084,0.009,0.0032,R
|
||||
0.0453,0.0523,0.0843,0.0689,0.1183,0.2583,0.2156,0.3481,0.3337,0.2872,0.4918,0.6552,0.6919,0.7797,0.7464,0.9444,1,0.8874,0.8024,0.7818,0.5212,0.4052,0.3957,0.3914,0.325,0.32,0.3271,0.2767,0.4423,0.2028,0.3788,0.2947,0.1984,0.2341,0.1306,0.4182,0.3835,0.1057,0.184,0.197,0.1674,0.0583,0.1401,0.1628,0.0621,0.0203,0.053,0.0742,0.0409,0.0061,0.0125,0.0084,0.0089,0.0048,0.0094,0.0191,0.014,0.0049,0.0052,0.0044,R
|
||||
0.0262,0.0582,0.1099,0.1083,0.0974,0.228,0.2431,0.3771,0.5598,0.6194,0.6333,0.706,0.5544,0.532,0.6479,0.6931,0.6759,0.7551,0.8929,0.8619,0.7974,0.6737,0.4293,0.3648,0.5331,0.2413,0.507,0.8533,0.6036,0.8514,0.8512,0.5045,0.1862,0.2709,0.4232,0.3043,0.6116,0.6756,0.5375,0.4719,0.4647,0.2587,0.2129,0.2222,0.2111,0.0176,0.1348,0.0744,0.013,0.0106,0.0033,0.0232,0.0166,0.0095,0.018,0.0244,0.0316,0.0164,0.0095,0.0078,R
|
||||
```
|
||||
|
||||
> 准备数据:转换样本集
|
||||
|
||||
```python
|
||||
# 导入csv文件
|
||||
def loadDataSet(filename):
|
||||
dataset = []
|
||||
with open(filename, 'r') as fr:
|
||||
for line in fr.readlines():
|
||||
if not line:
|
||||
continue
|
||||
lineArr = []
|
||||
for featrue in line.split(','):
|
||||
# strip()返回移除字符串头尾指定的字符生成的新字符串
|
||||
str_f = featrue.strip()
|
||||
if str_f.isdigit(): # 判断是否是数字
|
||||
# 将数据集的第column列转换成float形式
|
||||
lineArr.append(float(str_f))
|
||||
else:
|
||||
# 添加分类标签
|
||||
lineArr.append(str_f)
|
||||
dataset.append(lineArr)
|
||||
return dataset
|
||||
```
|
||||
|
||||
> 分析数据:手工检查数据
|
||||
|
||||
> 训练算法:在数据上,利用 random_forest() 函数进行优化评估,返回模型的综合分类结果
|
||||
|
||||
* 样本数据随机无放回抽样-用于交叉验证
|
||||
|
||||
```python
|
||||
def cross_validation_split(dataset, n_folds):
|
||||
"""cross_validation_split(将数据集进行抽重抽样 n_folds 份,数据可以重复抽取)
|
||||
|
||||
Args:
|
||||
dataset 原始数据集
|
||||
n_folds 数据集dataset分成n_flods份
|
||||
Returns:
|
||||
dataset_split list集合,存放的是:将数据集进行抽重抽样 n_folds 份,数据可以重复抽取
|
||||
"""
|
||||
dataset_split = list()
|
||||
dataset_copy = list(dataset) # 复制一份 dataset,防止 dataset 的内容改变
|
||||
fold_size = len(dataset) / n_folds
|
||||
for i in range(n_folds):
|
||||
fold = list() # 每次循环 fold 清零,防止重复导入 dataset_split
|
||||
while len(fold) < fold_size: # 这里不能用 if,if 只是在第一次判断时起作用,while 执行循环,直到条件不成立
|
||||
# 有放回的随机采样,有一些样本被重复采样,从而在训练集中多次出现,有的则从未在训练集中出现,此为自助采样法。从而保证每棵决策树训练集的差异性
|
||||
index = randrange(len(dataset_copy))
|
||||
# 将对应索引 index 的内容从 dataset_copy 中导出,并将该内容从 dataset_copy 中删除。
|
||||
# pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
|
||||
fold.append(dataset_copy.pop(index)) # 无放回的方式
|
||||
# fold.append(dataset_copy[index]) # 有放回的方式
|
||||
dataset_split.append(fold)
|
||||
# 由dataset分割出的n_folds个数据构成的列表,为了用于交叉验证
|
||||
return dataset_split
|
||||
```
|
||||
|
||||
* 训练数据集随机化
|
||||
|
||||
```python
|
||||
# Create a random subsample from the dataset with replacement
|
||||
def subsample(dataset, ratio): # 创建数据集的随机子样本
|
||||
"""random_forest(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
dataset 训练数据集
|
||||
ratio 训练数据集的样本比例
|
||||
Returns:
|
||||
sample 随机抽样的训练样本
|
||||
"""
|
||||
|
||||
sample = list()
|
||||
# 训练样本的按比例抽样。
|
||||
# round() 方法返回浮点数x的四舍五入值。
|
||||
n_sample = round(len(dataset) * ratio)
|
||||
while len(sample) < n_sample:
|
||||
# 有放回的随机采样,有一些样本被重复采样,从而在训练集中多次出现,有的则从未在训练集中出现,此为自助采样法。从而保证每棵决策树训练集的差异性
|
||||
index = randrange(len(dataset))
|
||||
sample.append(dataset[index])
|
||||
return sample
|
||||
```
|
||||
|
||||
* 特征随机化
|
||||
|
||||
```python
|
||||
# 找出分割数据集的最优特征,得到最优的特征 index,特征值 row[index],以及分割完的数据 groups(left, right)
|
||||
def get_split(dataset, n_features):
|
||||
class_values = list(set(row[-1] for row in dataset)) # class_values =[0, 1]
|
||||
b_index, b_value, b_score, b_groups = 999, 999, 999, None
|
||||
features = list()
|
||||
while len(features) < n_features:
|
||||
index = randrange(len(dataset[0])-1) # 往 features 添加 n_features 个特征( n_feature 等于特征数的个数),特征索引从 dataset 中随机取
|
||||
if index not in features:
|
||||
features.append(index)
|
||||
for index in features: # 在 n_features 个特征中选出最优的特征索引,并没有遍历所有特征,从而保证了每课决策树的差异性
|
||||
for row in dataset:
|
||||
groups = test_split(index, row[index], dataset) # groups=(left, right), row[index] 遍历每一行 index 索引下的特征值作为分类值 value, 找出最优的分类特征和特征值
|
||||
gini = gini_index(groups, class_values)
|
||||
# 左右两边的数量越一样,说明数据区分度不高,gini系数越大
|
||||
if gini < b_score:
|
||||
b_index, b_value, b_score, b_groups = index, row[index], gini, groups # 最后得到最优的分类特征 b_index,分类特征值 b_value,分类结果 b_groups。b_value 为分错的代价成本
|
||||
# print b_score
|
||||
return {'index': b_index, 'value': b_value, 'groups': b_groups}
|
||||
```
|
||||
|
||||
* 随机森林
|
||||
|
||||
```python
|
||||
# Random Forest Algorithm
|
||||
def random_forest(train, test, max_depth, min_size, sample_size, n_trees, n_features):
|
||||
"""random_forest(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
train 训练数据集
|
||||
test 测试数据集
|
||||
max_depth 决策树深度不能太深,不然容易导致过拟合
|
||||
min_size 叶子节点的大小
|
||||
sample_size 训练数据集的样本比例
|
||||
n_trees 决策树的个数
|
||||
n_features 选取的特征的个数
|
||||
Returns:
|
||||
predictions 每一行的预测结果,bagging 预测最后的分类结果
|
||||
"""
|
||||
|
||||
trees = list()
|
||||
# n_trees 表示决策树的数量
|
||||
for i in range(n_trees):
|
||||
# 随机抽样的训练样本, 随机采样保证了每棵决策树训练集的差异性
|
||||
sample = subsample(train, sample_size)
|
||||
# 创建一个决策树
|
||||
tree = build_tree(sample, max_depth, min_size, n_features)
|
||||
trees.append(tree)
|
||||
|
||||
# 每一行的预测结果,bagging 预测最后的分类结果
|
||||
predictions = [bagging_predict(trees, row) for row in test]
|
||||
return predictions
|
||||
```
|
||||
|
||||
> 测试算法:在采用自定义 n_folds 份随机重抽样 进行测试评估,得出综合的预测评分。
|
||||
|
||||
* 计算随机森林的预测结果的正确率
|
||||
|
||||
```python
|
||||
# 评估算法性能,返回模型得分
|
||||
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
"""evaluate_algorithm(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
dataset 原始数据集
|
||||
algorithm 使用的算法
|
||||
n_folds 数据的份数
|
||||
*args 其他的参数
|
||||
Returns:
|
||||
scores 模型得分
|
||||
"""
|
||||
|
||||
# 将数据集进行随机抽样,分成 n_folds 份,数据无重复的抽取
|
||||
folds = cross_validation_split(dataset, n_folds)
|
||||
scores = list()
|
||||
# 每次循环从 folds 从取出一个 fold 作为测试集,其余作为训练集,遍历整个 folds ,实现交叉验证
|
||||
for fold in folds:
|
||||
train_set = list(folds)
|
||||
train_set.remove(fold)
|
||||
# 将多个 fold 列表组合成一个 train_set 列表, 类似 union all
|
||||
"""
|
||||
In [20]: l1=[[1, 2, 'a'], [11, 22, 'b']]
|
||||
In [21]: l2=[[3, 4, 'c'], [33, 44, 'd']]
|
||||
In [22]: l=[]
|
||||
In [23]: l.append(l1)
|
||||
In [24]: l.append(l2)
|
||||
In [25]: l
|
||||
Out[25]: [[[1, 2, 'a'], [11, 22, 'b']], [[3, 4, 'c'], [33, 44, 'd']]]
|
||||
In [26]: sum(l, [])
|
||||
Out[26]: [[1, 2, 'a'], [11, 22, 'b'], [3, 4, 'c'], [33, 44, 'd']]
|
||||
"""
|
||||
train_set = sum(train_set, [])
|
||||
test_set = list()
|
||||
# fold 表示从原始数据集 dataset 提取出来的测试集
|
||||
for row in fold:
|
||||
row_copy = list(row)
|
||||
row_copy[-1] = None
|
||||
test_set.append(row_copy)
|
||||
predicted = algorithm(train_set, test_set, *args)
|
||||
actual = [row[-1] for row in fold]
|
||||
|
||||
# 计算随机森林的预测结果的正确率
|
||||
accuracy = accuracy_metric(actual, predicted)
|
||||
scores.append(accuracy)
|
||||
return scores
|
||||
```
|
||||
|
||||
> 使用算法:若你感兴趣可以构建完整的应用程序,从案例进行封装,也可以参考我们的代码
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.RandomForest/randomForest.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.RandomForest/randomForest.py>
|
||||
|
||||
|
||||
## AdaBoost
|
||||
|
||||
### AdaBoost (adaptive boosting: 自适应 boosting) 概述
|
||||
|
||||
`能否使用弱分类器和多个实例来构建一个强分类器? 这是一个非常有趣的理论问题。`
|
||||
|
||||
### AdaBoost 原理
|
||||
|
||||
> AdaBoost 工作原理
|
||||
|
||||

|
||||
|
||||
> AdaBoost 开发流程
|
||||
|
||||
```
|
||||
收集数据:可以使用任意方法
|
||||
准备数据:依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以处理任何数据类型。
|
||||
当然也可以使用任意分类器作为弱分类器,第2章到第6章中的任一分类器都可以充当弱分类器。
|
||||
作为弱分类器,简单分类器的效果更好。
|
||||
分析数据:可以使用任意方法。
|
||||
训练算法:AdaBoost 的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器。
|
||||
测试算法:计算分类的错误率。
|
||||
使用算法:通SVM一样,AdaBoost 预测两个类别中的一个。如果想把它应用到多个类别的场景,那么就要像多类 SVM 中的做法一样对 AdaBoost 进行修改。
|
||||
```
|
||||
|
||||
> AdaBoost 算法特点
|
||||
|
||||
```
|
||||
* 优点:泛化(由具体的、个别的扩大为一般的)错误率低,易编码,可以应用在大部分分类器上,无参数调节。
|
||||
* 缺点:对离群点敏感。
|
||||
* 适用数据类型:数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 项目案例: 马疝病的预测
|
||||
|
||||
> 项目流程图
|
||||
|
||||

|
||||
|
||||
基于单层决策树构建弱分类器
|
||||
* 单层决策树(decision stump, 也称决策树桩)是一种简单的决策树。
|
||||
|
||||
#### 项目概述
|
||||
|
||||
预测患有疝气病的马的存活问题,这里的数据包括368个样本和28个特征,疝气病是描述马胃肠痛的术语,然而,这种病并不一定源自马的胃肠问题,其他问题也可能引发疝气病,该数据集中包含了医院检测马疝气病的一些指标,有的指标比较主观,有的指标难以测量,例如马的疼痛级别。另外,除了部分指标主观和难以测量之外,该数据还存在一个问题,数据集中有30%的值是缺失的。
|
||||
|
||||
#### 开发流程
|
||||
|
||||
```
|
||||
收集数据:提供的文本文件
|
||||
准备数据:确保类别标签是+1和-1,而非1和0
|
||||
分析数据:统计分析
|
||||
训练算法:在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
测试算法:我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较
|
||||
使用算法:观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去
|
||||
```
|
||||
|
||||
> 收集数据:提供的文本文件
|
||||
|
||||
训练数据:horseColicTraining.txt<br/>
|
||||
测试数据:horseColicTest.txt
|
||||
|
||||
```
|
||||
2.000000 1.000000 38.500000 66.000000 28.000000 3.000000 3.000000 0.000000 2.000000 5.000000 4.000000 4.000000 0.000000 0.000000 0.000000 3.000000 5.000000 45.000000 8.400000 0.000000 0.000000 -1.000000
|
||||
1.000000 1.000000 39.200000 88.000000 20.000000 0.000000 0.000000 4.000000 1.000000 3.000000 4.000000 2.000000 0.000000 0.000000 0.000000 4.000000 2.000000 50.000000 85.000000 2.000000 2.000000 -1.000000
|
||||
2.000000 1.000000 38.300000 40.000000 24.000000 1.000000 1.000000 3.000000 1.000000 3.000000 3.000000 1.000000 0.000000 0.000000 0.000000 1.000000 1.000000 33.000000 6.700000 0.000000 0.000000 1.000000
|
||||
```
|
||||
|
||||
> 准备数据:确保类别标签是+1和-1,而非1和0
|
||||
|
||||
```python
|
||||
def loadDataSet(fileName):
|
||||
# 获取 feature 的数量, 便于获取
|
||||
numFeat = len(open(fileName).readline().split('\t'))
|
||||
dataArr = []
|
||||
labelArr = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = []
|
||||
curLine = line.strip().split('\t')
|
||||
for i in range(numFeat-1):
|
||||
lineArr.append(float(curLine[i]))
|
||||
dataArr.append(lineArr)
|
||||
labelArr.append(float(curLine[-1]))
|
||||
return dataArr, labelArr
|
||||
```
|
||||
|
||||
> 分析数据:统计分析
|
||||
|
||||
过拟合(overfitting, 也称为过学习)
|
||||
* 发现测试错误率在达到一个最小值之后有开始上升,这种现象称为过拟合。
|
||||
|
||||
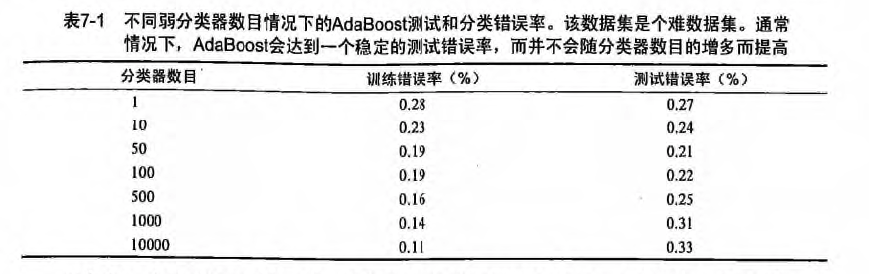
|
||||
|
||||
* 通俗来说:就是把一些噪音数据也拟合进去的,如下图。
|
||||
|
||||
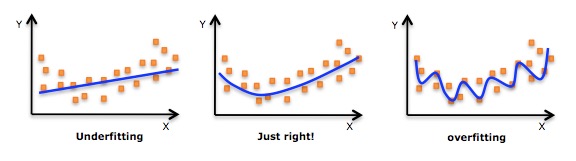
|
||||
|
||||
> 训练算法:在数据上,利用 adaBoostTrainDS() 函数训练出一系列的分类器
|
||||
|
||||
```python
|
||||
def adaBoostTrainDS(dataArr, labelArr, numIt=40):
|
||||
"""adaBoostTrainDS(adaBoost训练过程放大)
|
||||
Args:
|
||||
dataArr 特征标签集合
|
||||
labelArr 分类标签集合
|
||||
numIt 实例数
|
||||
Returns:
|
||||
weakClassArr 弱分类器的集合
|
||||
aggClassEst 预测的分类结果值
|
||||
"""
|
||||
weakClassArr = []
|
||||
m = shape(dataArr)[0]
|
||||
# 初始化 D,设置每个样本的权重值,平均分为m份
|
||||
D = mat(ones((m, 1))/m)
|
||||
aggClassEst = mat(zeros((m, 1)))
|
||||
for i in range(numIt):
|
||||
# 得到决策树的模型
|
||||
bestStump, error, classEst = buildStump(dataArr, labelArr, D)
|
||||
|
||||
# alpha目的主要是计算每一个分类器实例的权重(组合就是分类结果)
|
||||
# 计算每个分类器的alpha权重值
|
||||
alpha = float(0.5*log((1.0-error)/max(error, 1e-16)))
|
||||
bestStump['alpha'] = alpha
|
||||
# store Stump Params in Array
|
||||
weakClassArr.append(bestStump)
|
||||
|
||||
print "alpha=%s, classEst=%s, bestStump=%s, error=%s " % (alpha, classEst.T, bestStump, error)
|
||||
# 分类正确:乘积为1,不会影响结果,-1主要是下面求e的-alpha次方
|
||||
# 分类错误:乘积为 -1,结果会受影响,所以也乘以 -1
|
||||
expon = multiply(-1*alpha*mat(labelArr).T, classEst)
|
||||
print '(-1取反)预测值expon=', expon.T
|
||||
# 计算e的expon次方,然后计算得到一个综合的概率的值
|
||||
# 结果发现: 判断错误的样本,D中相对应的样本权重值会变大。
|
||||
D = multiply(D, exp(expon))
|
||||
D = D/D.sum()
|
||||
|
||||
# 预测的分类结果值,在上一轮结果的基础上,进行加和操作
|
||||
print '当前的分类结果:', alpha*classEst.T
|
||||
aggClassEst += alpha*classEst
|
||||
print "叠加后的分类结果aggClassEst: ", aggClassEst.T
|
||||
# sign 判断正为1, 0为0, 负为-1,通过最终加和的权重值,判断符号。
|
||||
# 结果为:错误的样本标签集合,因为是 !=,那么结果就是0 正, 1 负
|
||||
aggErrors = multiply(sign(aggClassEst) != mat(labelArr).T, ones((m, 1)))
|
||||
errorRate = aggErrors.sum()/m
|
||||
# print "total error=%s " % (errorRate)
|
||||
if errorRate == 0.0:
|
||||
break
|
||||
return weakClassArr, aggClassEst
|
||||
```
|
||||
|
||||
```
|
||||
发现:
|
||||
alpha (模型权重)目的主要是计算每一个分类器实例的权重(加和就是分类结果)
|
||||
分类的权重值:最大的值= alpha 的加和,最小值=-最大值
|
||||
D (样本权重)的目的是为了计算错误概率: weightedError = D.T*errArr,求最佳分类器
|
||||
样本的权重值:如果一个值误判的几率越小,那么 D 的样本权重越小
|
||||
```
|
||||
|
||||

|
||||
|
||||
> 测试算法:我们拥有两个数据集。在不采用随机抽样的方法下,我们就会对 AdaBoost 和 Logistic 回归的结果进行完全对等的比较。
|
||||
|
||||
```python
|
||||
def adaClassify(datToClass, classifierArr):
|
||||
"""adaClassify(ada分类测试)
|
||||
Args:
|
||||
datToClass 多个待分类的样例
|
||||
classifierArr 弱分类器的集合
|
||||
Returns:
|
||||
sign(aggClassEst) 分类结果
|
||||
"""
|
||||
# do stuff similar to last aggClassEst in adaBoostTrainDS
|
||||
dataMat = mat(datToClass)
|
||||
m = shape(dataMat)[0]
|
||||
aggClassEst = mat(zeros((m, 1)))
|
||||
|
||||
# 循环 多个分类器
|
||||
for i in range(len(classifierArr)):
|
||||
# 前提: 我们已经知道了最佳的分类器的实例
|
||||
# 通过分类器来核算每一次的分类结果,然后通过alpha*每一次的结果 得到最后的权重加和的值。
|
||||
classEst = stumpClassify(dataMat, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
|
||||
aggClassEst += classifierArr[i]['alpha']*classEst
|
||||
return sign(aggClassEst)
|
||||
```
|
||||
|
||||
> 使用算法:观察该例子上的错误率。不过,也可以构建一个 Web 网站,让驯马师输入马的症状然后预测马是否会死去。
|
||||
|
||||
```python
|
||||
# 马疝病数据集
|
||||
# 训练集合
|
||||
dataArr, labelArr = loadDataSet("data/7.AdaBoost/horseColicTraining2.txt")
|
||||
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, labelArr, 40)
|
||||
print weakClassArr, '\n-----\n', aggClassEst.T
|
||||
# 计算ROC下面的AUC的面积大小
|
||||
plotROC(aggClassEst.T, labelArr)
|
||||
# 测试集合
|
||||
dataArrTest, labelArrTest = loadDataSet("data/7.AdaBoost/horseColicTest2.txt")
|
||||
m = shape(dataArrTest)[0]
|
||||
predicting10 = adaClassify(dataArrTest, weakClassArr)
|
||||
errArr = mat(ones((m, 1)))
|
||||
# 测试:计算总样本数,错误样本数,错误率
|
||||
print m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10 != mat(labelArrTest).T].sum()/m
|
||||
```
|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.AdaBoost/adaboost.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.AdaBoost/adaboost.py>
|
||||
|
||||
#### 要点补充
|
||||
|
||||
> 非均衡现象:
|
||||
|
||||
`在分类器训练时,正例数目和反例数目不相等(相差很大)。或者发生在正负例分类错误的成本不同的时候。`
|
||||
|
||||
* 判断马是否能继续生存(不可误杀)
|
||||
* 过滤垃圾邮件(不可漏判)
|
||||
* 不能放过传染病的人
|
||||
* 不能随便认为别人犯罪
|
||||
|
||||
我们有多种方法来处理这个问题: 具体可参考[此链接](https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/)
|
||||
|
||||
再结合书中的方法,可以归为八大类:
|
||||
|
||||
##### 1.能否收集到更多的数据?
|
||||
|
||||
这个措施往往被人们所忽略,被认为很蠢。但是更大的数据集更能体现样本的分布,多样性。
|
||||
|
||||
##### 2.尝试使用其他的评价指标
|
||||
|
||||
|
||||
Accuracy 或者error rate 不能用于非均衡的数据集。这会误导人。这时候可以尝试其他的评价指标。
|
||||
|
||||
Confusion Matrix 混淆矩阵:使用一个表格对分类器所预测的类别与其真实的类别的样本统计,分别为:TP、FN、FP与TN。
|
||||
|
||||
Precision:精确度
|
||||
|
||||
Recall: 召回率
|
||||
|
||||
F1 Score (or F-Score): 精确度和召回率的加权平均
|
||||
|
||||
或者使用
|
||||
|
||||
Kappa (Cohen's kappa)
|
||||
|
||||
ROC Curves
|
||||
|
||||
> ROC 评估方法
|
||||
|
||||
* ROC 曲线: 最佳的分类器应该尽可能地处于左上角
|
||||
|
||||
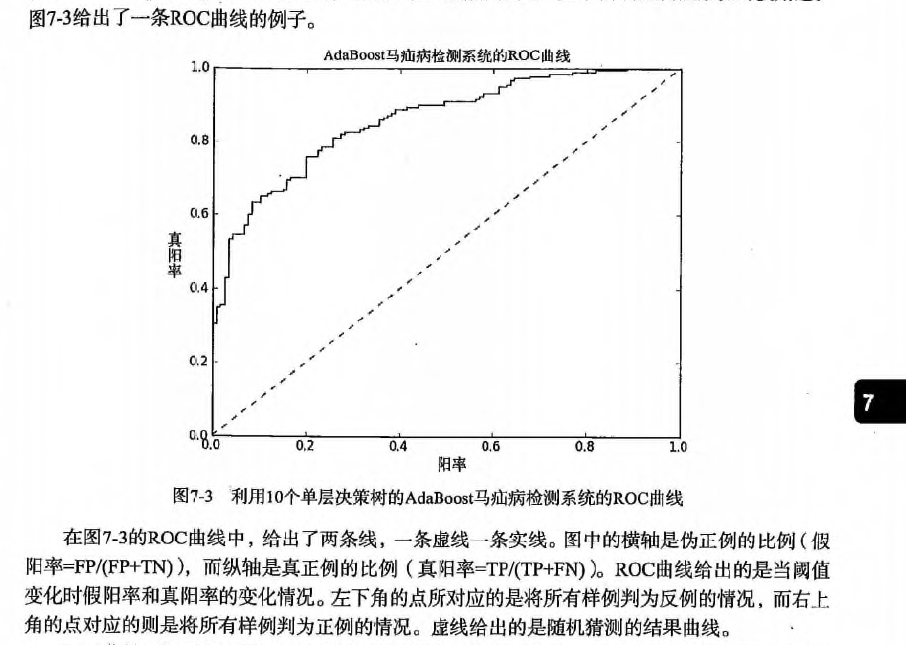
|
||||
|
||||
* 对不同的 ROC 曲线进行比较的一个指标是曲线下的面积(Area Unser the Curve, AUC).
|
||||
|
||||
* AUC 给出的是分类器的平均性能值,当然它并不能完全代替对整条曲线的观察。
|
||||
|
||||
* 一个完美分类器的 AUC 为1,而随机猜测的 AUC 则为0.5。
|
||||
|
||||
##### 3.尝试对样本重抽样
|
||||
|
||||
欠抽样(undersampling)或者过抽样(oversampling)
|
||||
|
||||
- 欠抽样: 意味着删除样例
|
||||
- 过抽样: 意味着复制样例(重复使用)
|
||||
|
||||
对大类进行欠抽样
|
||||
|
||||
对小类进行过抽样
|
||||
|
||||
或者结合上述两种方法进行抽样
|
||||
|
||||
一些经验法则:
|
||||
|
||||
* 考虑样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
|
||||
|
||||
* 考虑样本(不足1为甚至更少)进行过采样,即添加部分样本的副本;
|
||||
|
||||
* 考虑尝试随机采样与非随机采样两种采样方法;
|
||||
|
||||
* 考虑对各类别尝试不同的采样比例,不一定是1:1
|
||||
|
||||
* 考虑同时使用过采样与欠采样
|
||||
|
||||
##### 4.尝试产生人工生成的样本
|
||||
|
||||
一种简单的方法就是随机抽样小类样本的属性(特征)来组成新的样本即属性值随机采样。你可以根据经验进行抽样,可以使用其他方式比如朴素贝叶斯方法假设各属性之间互相独立进行采样,这样便可得到更多的数据,但是无法保证属性之间的非线性关系。
|
||||
|
||||
当然也有系统性的算法。最常用的SMOTE(Synthetic Minority Over-Sampling Technique)。 顾名思义,这是一种over sampling(过抽样)的方式。它是产生人为的样本而不是制造样本副本。这个算法是选取2个或者2个以上相似的样本(根据距离度量 distance measure),然后每次选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声(每次只处理一个属性)。这样就构造了更多的新生数据。具体可以参见[原始论文](http://www.jair.org/papers/paper953.html)。
|
||||
|
||||
python实现可以查阅[UnbalancedDataset](https://github.com/scikit-learn-contrib/imbalanced-learn)
|
||||
|
||||
##### 5.尝试不同的算法
|
||||
|
||||
强烈建议不要在每个问题上使用你最喜欢的算法。虽然这个算法带来较好的效果,但是它也会蒙蔽你观察数据内蕴含的其他的信息。至少你得在同一个问题上试试各种算法。具体可以参阅[Why you should be Spot-Checking Algorithms on your Machine Learning Problems](https://machinelearningmastery.com/why-you-should-be-spot-checking-algorithms-on-your-machine-learning-problems/)
|
||||
|
||||
比如说,决策树经常在非均衡数据集上表现良好。创建分类树时候使用基于类变量的划分规则强制使类别表达出来。如果有疑惑,可以尝试一些流行的决策树,比如, C4.5, C5.0, CART 和 Random Forrest。
|
||||
|
||||
##### 6.尝试使用惩罚的模型
|
||||
|
||||
你可以使用同种算法但是以不同的角度对待这个问题。
|
||||
|
||||
惩罚的模型就是对于不同的分类错误给予不同的代价(惩罚)。比如对于错分的小类给予更高的代价。这种方式会使模型偏差,更加关注小类。
|
||||
|
||||
通常来说这种代价/惩罚或者比重在学习中算法是特定的。比如使用代价函数来实现:
|
||||
|
||||
> 代价函数
|
||||
|
||||
* 基于代价函数的分类器决策控制:`TP*(-5)+FN*1+FP*50+TN*0`
|
||||
|
||||
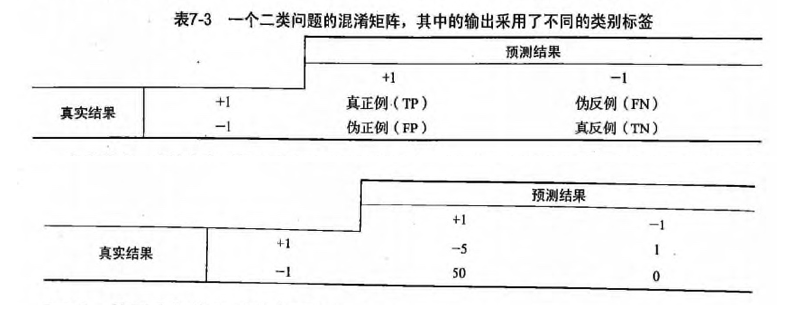
|
||||
|
||||
这种方式叫做 cost sensitive learning,Weka 中相应的框架可以实现叫[CostSensitiveClassifier](http://weka.sourceforge.net/doc.dev/weka/classifiers/meta/CostSensitiveClassifier.html)
|
||||
|
||||
如果当你只能使用特定算法而且无法重抽样,或者模型效果不行,这时候使用惩罚(penalization)是可行的方法。这提供另外一种方式来“平衡”类别。但是设定惩罚函数/代价函数是比较复杂的。最好还是尝试不同的代价函数组合来得到最优效果。
|
||||
|
||||
##### 7.尝试使用不同的角度
|
||||
|
||||
其实有很多研究关于非均衡数据。他们有自己的算法,度量,术语。
|
||||
|
||||
从它们的角度看看你的问题,思考你的问题,说不定会有新的想法。
|
||||
|
||||
两个领域您可以考虑: anomaly detection(异常值检测) 和 change detection(变化趋势检测)。
|
||||
|
||||
Anomaly dectection 就是检测稀有事件。 比如通过机器震动来识别机器谷中或者根据一系列系统的调用来检测恶意操作。与常规操作相比,这些事件是罕见的。
|
||||
|
||||
把小类想成异常类这种转变可能会帮助你想到新办法来分类数据样本。
|
||||
|
||||
change detection 变化趋势检测类似于异常值检测。但是他不是寻找异常值而是寻找变化或区别。比如通过使用模式或者银行交易记录来观察用户行为转变。
|
||||
|
||||
这些两种转变可能会给你新的方式去思考你的问题和新的技术去尝试。
|
||||
|
||||
##### 8.尝试去创新
|
||||
|
||||
仔细思考你的问题然后想想看如何将这问题细分为几个更切实际的小问题。
|
||||
|
||||
比如:
|
||||
|
||||
将你的大类分解成多个较小的类;
|
||||
|
||||
使用One Class分类器(看待成异常点检测);
|
||||
|
||||
对数据集进行抽样成多个数据集,使用集成方式,训练多个分类器,然后联合这些分类器进行分类;
|
||||
|
||||
这只是一个例子。更多的可以参阅[In classification, how do you handle an unbalanced training set?](http://www.quora.com/In-classification-how-do-you-handle-an-unbalanced-training-set) 和[Classification when 80% of my training set is of one class](https://www.reddit.com/r/MachineLearning/comments/12evgi/classification_when_80_of_my_training_set_is_of/)
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,848 @@
|
|||
# 第8章 预测数值型数据:回归
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## 回归(Regression) 概述
|
||||
|
||||
`我们前边提到的分类的目标变量是标称型数据,而回归则是对连续型的数据做出处理,回归的目的是预测数值型数据的目标值。`
|
||||
|
||||
## 回归 场景
|
||||
|
||||
回归的目的是预测数值型的目标值。最直接的办法是依据输入写出一个目标值的计算公式。
|
||||
|
||||
假如你想要预测兰博基尼跑车的功率大小,可能会这样计算:
|
||||
|
||||
HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
|
||||
|
||||
这就是所谓的 `回归方程(regression equation)`,其中的 0.0015 和 -0.99 称作 `回归系数(regression weights)`,求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。我们这里所说的,回归系数是一个向量,输入也是向量,这些运算也就是求出二者的内积。
|
||||
|
||||
说到回归,一般都是指 `线性回归(linear regression)`。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。
|
||||
|
||||
补充:
|
||||
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以由前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
|
||||
|
||||
## 回归 原理
|
||||
|
||||
### 1、线性回归
|
||||
|
||||
我们应该怎样从一大堆数据里求出回归方程呢? 假定输入数据存放在矩阵 x 中,而回归系数存放在向量 w 中。那么对于给定的数据 X1,预测结果将会通过 Y = X1^T w 给出。现在的问题是,手里有一些 X 和对应的 y,怎样才能找到 w 呢?一个常用的方法就是找出使误差最小的 w 。这里的误差是指预测 y 值和真实 y 值之间的差值,使用该误差的简单累加将使得正差值和负差值相互抵消,所以我们采用平方误差(实际上就是我们通常所说的最小二乘法)。
|
||||
|
||||
平方误差可以写做(其实我们是使用这个函数作为 loss function):
|
||||
|
||||
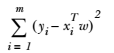
|
||||
|
||||
用矩阵表示还可以写做 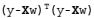 。如果对 w 求导,得到 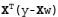 ,令其等于零,解出 w 如下(具体求导过程为: http://blog.csdn.net/nomadlx53/article/details/50849941 ):
|
||||
|
||||
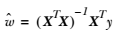
|
||||
|
||||
#### 1.1、线性回归 须知概念
|
||||
|
||||
##### 1.1.1、矩阵求逆
|
||||
|
||||
因为我们在计算回归方程的回归系数时,用到的计算公式如下:
|
||||
|
||||
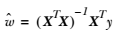
|
||||
|
||||
需要对矩阵求逆,因此这个方程只在逆矩阵存在的时候适用,我们在程序代码中对此作出判断。
|
||||
判断矩阵是否可逆的一个可选方案是:
|
||||
|
||||
判断矩阵的行列式是否为 0,若为 0 ,矩阵就不存在逆矩阵,不为 0 的话,矩阵才存在逆矩阵。
|
||||
|
||||
##### 1.1.2、最小二乘法
|
||||
|
||||
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。
|
||||
|
||||
#### 1.2、线性回归 工作原理
|
||||
|
||||
```
|
||||
读入数据,将数据特征x、特征标签y存储在矩阵x、y中
|
||||
验证 x^Tx 矩阵是否可逆
|
||||
使用最小二乘法求得 回归系数 w 的最佳估计
|
||||
```
|
||||
|
||||
#### 1.3、线性回归 开发流程
|
||||
|
||||
```
|
||||
收集数据: 采用任意方法收集数据
|
||||
准备数据: 回归需要数值型数据,标称型数据将被转换成二值型数据
|
||||
分析数据: 绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后,可以将新拟合线绘在图上作为对比
|
||||
训练算法: 找到回归系数
|
||||
测试算法: 使用 R^2 或者预测值和数据的拟合度,来分析模型的效果
|
||||
使用算法: 使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签
|
||||
```
|
||||
|
||||
#### 1.4、线性回归 算法特点
|
||||
|
||||
```
|
||||
优点:结果易于理解,计算上不复杂。
|
||||
缺点:对非线性的数据拟合不好。
|
||||
适用于数据类型:数值型和标称型数据。
|
||||
```
|
||||
|
||||
#### 1.5、线性回归 项目案例
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
##### 1.5.1、线性回归 项目概述
|
||||
|
||||
根据下图中的点,找出该数据的最佳拟合直线。
|
||||
|
||||

|
||||
|
||||
数据格式为:
|
||||
|
||||
```
|
||||
x0 x1 y
|
||||
1.000000 0.067732 3.176513
|
||||
1.000000 0.427810 3.816464
|
||||
1.000000 0.995731 4.550095
|
||||
1.000000 0.738336 4.256571
|
||||
```
|
||||
|
||||
##### 1.5.2、线性回归 编写代码
|
||||
|
||||
```python
|
||||
def loadDataSet(fileName):
|
||||
""" 加载数据
|
||||
解析以tab键分隔的文件中的浮点数
|
||||
Returns:
|
||||
dataMat : feature 对应的数据集
|
||||
labelMat : feature 对应的分类标签,即类别标签
|
||||
|
||||
"""
|
||||
# 获取样本特征的总数,不算最后的目标变量
|
||||
numFeat = len(open(fileName).readline().split('\t')) - 1
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
# 读取每一行
|
||||
lineArr =[]
|
||||
# 删除一行中以tab分隔的数据前后的空白符号
|
||||
curLine = line.strip().split('\t')
|
||||
# i 从0到2,不包括2
|
||||
for i in range(numFeat):
|
||||
# 将数据添加到lineArr List中,每一行数据测试数据组成一个行向量
|
||||
lineArr.append(float(curLine[i]))
|
||||
# 将测试数据的输入数据部分存储到dataMat 的List中
|
||||
dataMat.append(lineArr)
|
||||
# 将每一行的最后一个数据,即类别,或者叫目标变量存储到labelMat List中
|
||||
labelMat.append(float(curLine[-1]))
|
||||
return dataMat,labelMat
|
||||
|
||||
|
||||
def standRegres(xArr,yArr):
|
||||
'''
|
||||
Description:
|
||||
线性回归
|
||||
Args:
|
||||
xArr :输入的样本数据,包含每个样本数据的 feature
|
||||
yArr :对应于输入数据的类别标签,也就是每个样本对应的目标变量
|
||||
Returns:
|
||||
ws:回归系数
|
||||
'''
|
||||
|
||||
# mat()函数将xArr,yArr转换为矩阵 mat().T 代表的是对矩阵进行转置操作
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
# 矩阵乘法的条件是左矩阵的列数等于右矩阵的行数
|
||||
xTx = xMat.T*xMat
|
||||
# 因为要用到xTx的逆矩阵,所以事先需要确定计算得到的xTx是否可逆,条件是矩阵的行列式不为0
|
||||
# linalg.det() 函数是用来求得矩阵的行列式的,如果矩阵的行列式为0,则这个矩阵是不可逆的,就无法进行接下来的运算
|
||||
if linalg.det(xTx) == 0.0:
|
||||
print "This matrix is singular, cannot do inverse"
|
||||
return
|
||||
# 最小二乘法
|
||||
# http://cwiki.apachecn.org/pages/viewpage.action?pageId=5505133
|
||||
# 书中的公式,求得w的最优解
|
||||
ws = xTx.I * (xMat.T*yMat)
|
||||
return ws
|
||||
|
||||
|
||||
def regression1():
|
||||
xArr, yArr = loadDataSet("data/8.Regression/data.txt")
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr)
|
||||
ws = standRegres(xArr, yArr)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111) #add_subplot(349)函数的参数的意思是,将画布分成3行4列图像画在从左到右从上到下第9块
|
||||
ax.scatter(xMat[:, 1].flatten(), yMat.T[:, 0].flatten().A[0]) #scatter 的x是xMat中的第二列,y是yMat的第一列
|
||||
xCopy = xMat.copy()
|
||||
xCopy.sort(0)
|
||||
yHat = xCopy * ws
|
||||
ax.plot(xCopy[:, 1], yHat)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
##### 1.5.3、线性回归 拟合效果
|
||||
|
||||

|
||||
|
||||
|
||||
### 2、局部加权线性回归
|
||||
|
||||
线性回归的一个问题是有可能出现欠拟合现象,因为它求的是具有最小均方差的无偏估计。显而易见,如果模型欠拟合将不能取得最好的预测效果。所以有些方法允许在估计中引入一些偏差,从而降低预测的均方误差。
|
||||
|
||||
一个方法是局部加权线性回归(Locally Weighted Linear Regression,LWLR)。在这个算法中,我们给预测点附近的每个点赋予一定的权重,然后与 线性回归 类似,在这个子集上基于最小均方误差来进行普通的回归。我们需要最小化的目标函数大致为:
|
||||
|
||||
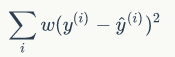
|
||||
|
||||
目标函数中 w 为权重,不是回归系数。与 kNN 一样,这种算法每次预测均需要事先选取出对应的数据子集。该算法解出回归系数 w 的形式如下:
|
||||
|
||||
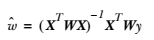
|
||||
|
||||
其中 W 是一个矩阵,用来给每个数据点赋予权重。$\hat{w}$ 则为回归系数。 这两个是不同的概念,请勿混用。
|
||||
|
||||
LWLR 使用 “核”(与支持向量机中的核类似)来对附近的点赋予更高的权重。核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:
|
||||
|
||||
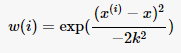
|
||||
|
||||
这样就构建了一个只含对角元素的权重矩阵 **w**,并且点 x 与 x(i) 越近,w(i) 将会越大。上述公式中包含一个需要用户指定的参数 k ,它决定了对附近的点赋予多大的权重,这也是使用 LWLR 时唯一需要考虑的参数,下面的图给出了参数 k 与权重的关系。
|
||||
|
||||
|
||||
|
||||
上面的图是 每个点的权重图(假定我们正预测的点是 x = 0.5),最上面的图是原始数据集,第二个图显示了当 k = 0.5 时,大部分的数据都用于训练回归模型;而最下面的图显示当 k=0.01 时,仅有很少的局部点被用于训练回归模型。
|
||||
|
||||
#### 2.1、局部加权线性回归 工作原理
|
||||
|
||||
```
|
||||
读入数据,将数据特征x、特征标签y存储在矩阵x、y中
|
||||
利用高斯核构造一个权重矩阵 W,对预测点附近的点施加权重
|
||||
验证 X^TWX 矩阵是否可逆
|
||||
使用最小二乘法求得 回归系数 w 的最佳估计
|
||||
```
|
||||
|
||||
#### 2.2、局部加权线性回归 项目案例
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
##### 2.2.1、局部加权线性回归 项目概述
|
||||
|
||||
我们仍然使用上面 线性回归 的数据集,对这些点进行一个 局部加权线性回归 的拟合。
|
||||
|
||||
|
||||
|
||||
数据格式为:
|
||||
|
||||
```
|
||||
1.000000 0.067732 3.176513
|
||||
1.000000 0.427810 3.816464
|
||||
1.000000 0.995731 4.550095
|
||||
1.000000 0.738336 4.256571
|
||||
```
|
||||
|
||||
##### 2.2.2、局部加权线性回归 编写代码
|
||||
|
||||
```python
|
||||
# 局部加权线性回归
|
||||
def lwlr(testPoint,xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
局部加权线性回归,在待预测点附近的每个点赋予一定的权重,在子集上基于最小均方差来进行普通的回归。
|
||||
Args:
|
||||
testPoint:样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
k:关于赋予权重矩阵的核的一个参数,与权重的衰减速率有关
|
||||
Returns:
|
||||
testPoint * ws:数据点与具有权重的系数相乘得到的预测点
|
||||
Notes:
|
||||
这其中会用到计算权重的公式,w = e^((x^((i))-x) / -2k^2)
|
||||
理解:x为某个预测点,x^((i))为样本点,样本点距离预测点越近,贡献的误差越大(权值越大),越远则贡献的误差越小(权值越小)。
|
||||
关于预测点的选取,在我的代码中取的是样本点。其中k是带宽参数,控制w(钟形函数)的宽窄程度,类似于高斯函数的标准差。
|
||||
算法思路:假设预测点取样本点中的第i个样本点(共m个样本点),遍历1到m个样本点(含第i个),算出每一个样本点与预测点的距离,
|
||||
也就可以计算出每个样本贡献误差的权值,可以看出w是一个有m个元素的向量(写成对角阵形式)。
|
||||
'''
|
||||
# mat() 函数是将array转换为矩阵的函数, mat().T 是转换为矩阵之后,再进行转置操作
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
# 获得xMat矩阵的行数
|
||||
m = shape(xMat)[0]
|
||||
# eye()返回一个对角线元素为1,其他元素为0的二维数组,创建权重矩阵weights,该矩阵为每个样本点初始化了一个权重
|
||||
weights = mat(eye((m)))
|
||||
for j in range(m):
|
||||
# testPoint 的形式是 一个行向量的形式
|
||||
# 计算 testPoint 与输入样本点之间的距离,然后下面计算出每个样本贡献误差的权值
|
||||
diffMat = testPoint - xMat[j,:]
|
||||
# k控制衰减的速度
|
||||
weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2))
|
||||
# 根据矩阵乘法计算 xTx ,其中的 weights 矩阵是样本点对应的权重矩阵
|
||||
xTx = xMat.T * (weights * xMat)
|
||||
if linalg.det(xTx) == 0.0:
|
||||
print ("This matrix is singular, cannot do inverse")
|
||||
return
|
||||
# 计算出回归系数的一个估计
|
||||
ws = xTx.I * (xMat.T * (weights * yMat))
|
||||
return testPoint * ws
|
||||
|
||||
def lwlrTest(testArr,xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
测试局部加权线性回归,对数据集中每个点调用 lwlr() 函数
|
||||
Args:
|
||||
testArr:测试所用的所有样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
k:控制核函数的衰减速率
|
||||
Returns:
|
||||
yHat:预测点的估计值
|
||||
'''
|
||||
# 得到样本点的总数
|
||||
m = shape(testArr)[0]
|
||||
# 构建一个全部都是 0 的 1 * m 的矩阵
|
||||
yHat = zeros(m)
|
||||
# 循环所有的数据点,并将lwlr运用于所有的数据点
|
||||
for i in range(m):
|
||||
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
|
||||
# 返回估计值
|
||||
return yHat
|
||||
|
||||
def lwlrTestPlot(xArr,yArr,k=1.0):
|
||||
'''
|
||||
Description:
|
||||
首先将 X 排序,其余的都与lwlrTest相同,这样更容易绘图
|
||||
Args:
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量,实际值
|
||||
k:控制核函数的衰减速率的有关参数,这里设定的是常量值 1
|
||||
Return:
|
||||
yHat:样本点的估计值
|
||||
xCopy:xArr的复制
|
||||
'''
|
||||
# 生成一个与目标变量数目相同的 0 向量
|
||||
yHat = zeros(shape(yArr))
|
||||
# 将 xArr 转换为 矩阵形式
|
||||
xCopy = mat(xArr)
|
||||
# 排序
|
||||
xCopy.sort(0)
|
||||
# 开始循环,为每个样本点进行局部加权线性回归,得到最终的目标变量估计值
|
||||
for i in range(shape(xArr)[0]):
|
||||
yHat[i] = lwlr(xCopy[i],xArr,yArr,k)
|
||||
return yHat,xCopy
|
||||
|
||||
|
||||
#test for LWLR
|
||||
def regression2():
|
||||
xArr, yArr = loadDataSet("data/8.Regression/data.txt")
|
||||
yHat = lwlrTest(xArr, xArr, yArr, 0.003)
|
||||
xMat = mat(xArr)
|
||||
srtInd = xMat[:,1].argsort(0) # argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出
|
||||
xSort=xMat[srtInd][:,0,:]
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(xSort[:,1], yHat[srtInd])
|
||||
ax.scatter(xMat[:,1].flatten().A[0], mat(yArr).T.flatten().A[0] , s=2, c='red')
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
##### 2.2.3、局部加权线性回归 拟合效果
|
||||
|
||||
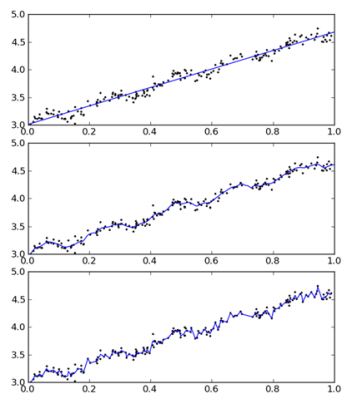
|
||||
|
||||
上图使用了 3 种不同平滑值绘出的局部加权线性回归的结果。上图中的平滑系数 k =1.0,中图 k = 0.01,下图 k = 0.003 。可以看到,k = 1.0 时的使所有数据等比重,其模型效果与基本的线性回归相同,k=0.01时该模型可以挖出数据的潜在规律,而 k=0.003时则考虑了太多的噪声,进而导致了过拟合现象。
|
||||
|
||||
#### 2.3、局部加权线性回归 注意事项
|
||||
|
||||
局部加权线性回归也存在一个问题,即增加了计算量,因为它对每个点做预测时都必须使用整个数据集。
|
||||
|
||||
|
||||
### 3、线性回归 & 局部加权线性回归 项目案例
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
到此为止,我们已经介绍了找出最佳拟合直线的两种方法,下面我们用这些技术来预测鲍鱼的年龄。
|
||||
|
||||
#### 3.1、项目概述
|
||||
|
||||
我们有一份来自 UCI 的数据集合的数据,记录了鲍鱼(一种介壳类水生动物)的年龄。鲍鱼年龄可以从鲍鱼壳的层数推算得到。
|
||||
|
||||
#### 3.2、开发流程
|
||||
|
||||
```
|
||||
收集数据: 采用任意方法收集数据
|
||||
准备数据: 回归需要数值型数据,标称型数据将被转换成二值型数据
|
||||
分析数据: 绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后,可以将新拟合线绘在图上作为对比
|
||||
训练算法: 找到回归系数
|
||||
测试算法: 使用 rssError()函数 计算预测误差的大小,来分析模型的效果
|
||||
使用算法: 使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签
|
||||
```
|
||||
|
||||
> 收集数据: 采用任意方法收集数据
|
||||
|
||||
> 准备数据: 回归需要数值型数据,标称型数据将被转换成二值型数据
|
||||
|
||||
数据存储格式:
|
||||
|
||||
```
|
||||
1 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 15
|
||||
1 0.35 0.265 0.09 0.2255 0.0995 0.0485 0.07 7
|
||||
-1 0.53 0.42 0.135 0.677 0.2565 0.1415 0.21 9
|
||||
1 0.44 0.365 0.125 0.516 0.2155 0.114 0.155 10
|
||||
0 0.33 0.255 0.08 0.205 0.0895 0.0395 0.055 7
|
||||
```
|
||||
|
||||
> 分析数据: 绘出数据的可视化二维图将有助于对数据做出理解和分析,在采用缩减法求得新回归系数之后,可以将新拟合线绘在图上作为对比
|
||||
|
||||
> 训练算法: 找到回归系数
|
||||
|
||||
使用上面我们讲到的 局部加权线性回归 训练算法,求出回归系数
|
||||
|
||||
> 测试算法: 使用 rssError()函数 计算预测误差的大小,来分析模型的效果
|
||||
|
||||
```python
|
||||
def rssError(yArr,yHatArr):
|
||||
'''
|
||||
Desc:
|
||||
返回真实值与预测值误差大小
|
||||
Args:
|
||||
yArr:样本的真实值
|
||||
yHatArr:样本的预测值
|
||||
Returns:
|
||||
一个数字,代表误差
|
||||
'''
|
||||
return ((yArr-yHatArr)**2).sum()
|
||||
```
|
||||
|
||||
```python
|
||||
# test for abloneDataSet
|
||||
def abaloneTest():
|
||||
'''
|
||||
Desc:
|
||||
预测鲍鱼的年龄
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 加载数据
|
||||
abX, abY = loadDataSet("data/8.Regression/abalone.txt")
|
||||
# 使用不同的核进行预测
|
||||
oldyHat01 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 0.1)
|
||||
oldyHat1 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 1)
|
||||
oldyHat10 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 10)
|
||||
# 打印出不同的核预测值与训练数据集上的真实值之间的误差大小
|
||||
print "old yHat01 error Size is :" , rssError(abY[0:99], oldyHat01.T)
|
||||
print "old yHat1 error Size is :" , rssError(abY[0:99], oldyHat1.T)
|
||||
print "old yHat10 error Size is :" , rssError(abY[0:99], oldyHat10.T)
|
||||
|
||||
# 打印出 不同的核预测值 与 新数据集(测试数据集)上的真实值之间的误差大小
|
||||
newyHat01 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 0.1)
|
||||
print "new yHat01 error Size is :" , rssError(abY[0:99], newyHat01.T)
|
||||
newyHat1 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 1)
|
||||
print "new yHat1 error Size is :" , rssError(abY[0:99], newyHat1.T)
|
||||
newyHat10 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 10)
|
||||
print "new yHat10 error Size is :" , rssError(abY[0:99], newyHat10.T)
|
||||
|
||||
# 使用简单的 线性回归 进行预测,与上面的计算进行比较
|
||||
standWs = standRegres(abX[0:99], abY[0:99])
|
||||
standyHat = mat(abX[100:199]) * standWs
|
||||
print "standRegress error Size is:", rssError(abY[100:199], standyHat.T.A)
|
||||
```
|
||||
|
||||
|
||||
根据我们上边的测试,可以看出:
|
||||
|
||||
简单线性回归达到了与局部加权现行回归类似的效果。这也说明了一点,必须在未知数据上比较效果才能选取到最佳模型。那么最佳的核大小是 10 吗?或许是,但如果想得到更好的效果,可以尝试用 10 个不同的样本集做 10 次测试来比较结果。
|
||||
|
||||
> 使用算法: 使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签
|
||||
|
||||
|
||||
### 4、缩减系数来 “理解” 数据
|
||||
|
||||
如果数据的特征比样本点还多应该怎么办?是否还可以使用线性回归和之前的方法来做预测?答案是否定的,即我们不能再使用前面介绍的方法。这是因为在计算 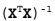 的时候会出错。
|
||||
|
||||
如果特征比样本点还多(n > m),也就是说输入数据的矩阵 x 不是满秩矩阵。非满秩矩阵求逆时会出现问题。
|
||||
|
||||
为了解决这个问题,我们引入了 `岭回归(ridge regression)` 这种缩减方法。接着是 `lasso法`,最后介绍 `前向逐步回归`。
|
||||
|
||||
#### 4.1、岭回归
|
||||
|
||||
简单来说,岭回归就是在矩阵 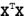 上加一个 λI 从而使得矩阵非奇异,进而能对 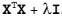 求逆。其中矩阵I是一个 n * n (等于列数) 的单位矩阵,
|
||||
对角线上元素全为1,其他元素全为0。而λ是一个用户定义的数值,后面会做介绍。在这种情况下,回归系数的计算公式将变成:
|
||||
|
||||
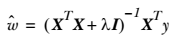
|
||||
|
||||
岭回归最先用来处理特征数多于样本数的情况,现在也用于在估计中加入偏差,从而得到更好的估计。这里通过引入 λ 来限制了所有 w 之和,通过引入该惩罚项,能够减少不重要的参数,这个技术在统计学中也叫作 `缩减(shrinkage)`。
|
||||
|
||||

|
||||
|
||||
缩减方法可以去掉不重要的参数,因此能更好地理解数据。此外,与简单的线性回归相比,缩减法能取得更好的预测效果。
|
||||
|
||||
这里通过预测误差最小化得到 λ: 数据获取之后,首先抽一部分数据用于测试,剩余的作为训练集用于训练参数 w。训练完毕后在测试集上测试预测性能。通过选取不同的 λ 来重复上述测试过程,最终得到一个使预测误差最小的 λ 。
|
||||
|
||||
##### 4.1.1、岭回归 原始代码
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
```python
|
||||
def ridgeRegres(xMat,yMat,lam=0.2):
|
||||
'''
|
||||
Desc:
|
||||
这个函数实现了给定 lambda 下的岭回归求解。
|
||||
如果数据的特征比样本点还多,就不能再使用上面介绍的的线性回归和局部线性回归了,因为计算 (xTx)^(-1)会出现错误。
|
||||
如果特征比样本点还多(n > m),也就是说,输入数据的矩阵x不是满秩矩阵。非满秩矩阵在求逆时会出现问题。
|
||||
为了解决这个问题,我们下边讲一下:岭回归,这是我们要讲的第一种缩减方法。
|
||||
Args:
|
||||
xMat:样本的特征数据,即 feature
|
||||
yMat:每个样本对应的类别标签,即目标变量,实际值
|
||||
lam:引入的一个λ值,使得矩阵非奇异
|
||||
Returns:
|
||||
经过岭回归公式计算得到的回归系数
|
||||
'''
|
||||
|
||||
xTx = xMat.T*xMat
|
||||
# 岭回归就是在矩阵 xTx 上加一个 λI 从而使得矩阵非奇异,进而能对 xTx + λI 求逆
|
||||
denom = xTx + eye(shape(xMat)[1])*lam
|
||||
# 检查行列式是否为零,即矩阵是否可逆,行列式为0的话就不可逆,不为0的话就是可逆。
|
||||
if linalg.det(denom) == 0.0:
|
||||
print ("This matrix is singular, cannot do inverse")
|
||||
return
|
||||
ws = denom.I * (xMat.T*yMat)
|
||||
return ws
|
||||
|
||||
|
||||
def ridgeTest(xArr,yArr):
|
||||
'''
|
||||
Desc:
|
||||
函数 ridgeTest() 用于在一组 λ 上测试结果
|
||||
Args:
|
||||
xArr:样本数据的特征,即 feature
|
||||
yArr:样本数据的类别标签,即真实数据
|
||||
Returns:
|
||||
wMat:将所有的回归系数输出到一个矩阵并返回
|
||||
'''
|
||||
|
||||
xMat = mat(xArr)
|
||||
yMat=mat(yArr).T
|
||||
# 计算Y的均值
|
||||
yMean = mean(yMat,0)
|
||||
# Y的所有的特征减去均值
|
||||
yMat = yMat - yMean
|
||||
# 标准化 x,计算 xMat 平均值
|
||||
xMeans = mean(xMat,0)
|
||||
# 然后计算 X的方差
|
||||
xVar = var(xMat,0)
|
||||
# 所有特征都减去各自的均值并除以方差
|
||||
xMat = (xMat - xMeans)/xVar
|
||||
# 可以在 30 个不同的 lambda 下调用 ridgeRegres() 函数。
|
||||
numTestPts = 30
|
||||
# 创建30 * m 的全部数据为0 的矩阵
|
||||
wMat = zeros((numTestPts,shape(xMat)[1]))
|
||||
for i in range(numTestPts):
|
||||
# exp() 返回 e^x
|
||||
ws = ridgeRegres(xMat,yMat,exp(i-10))
|
||||
wMat[i,:]=ws.T
|
||||
return wMat
|
||||
|
||||
|
||||
#test for ridgeRegression
|
||||
def regression3():
|
||||
abX,abY = loadDataSet("data/8.Regression/abalone.txt")
|
||||
ridgeWeights = ridgeTest(abX, abY)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(ridgeWeights)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
##### 4.1.2、岭回归在鲍鱼数据集上的运行效果
|
||||
|
||||
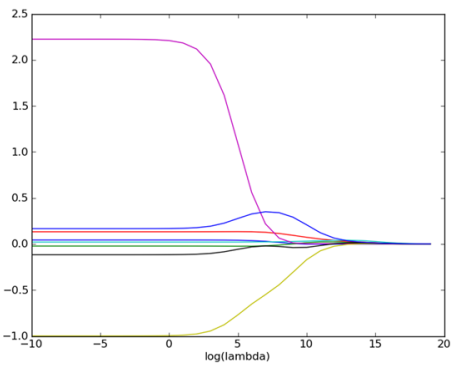
|
||||
|
||||
上图绘制出了回归系数与 log(λ) 的关系。在最左边,即 λ 最小时,可以得到所有系数的原始值(与线性回归一致);而在右边,系数全部缩减为0;在中间部分的某值将可以取得最好的预测效果。为了定量地找到最佳参数值,还需要进行交叉验证。另外,要判断哪些变量对结果预测最具有影响力,在上图中观察它们对应的系数大小就可以了。
|
||||
|
||||
|
||||
#### 4.2、套索方法(Lasso,The Least Absolute Shrinkage and Selection Operator)
|
||||
|
||||
在增加如下约束时,普通的最小二乘法回归会得到与岭回归一样的公式:
|
||||
|
||||
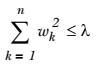
|
||||
|
||||
上式限定了所有回归系数的平方和不能大于 λ 。使用普通的最小二乘法回归在当两个或更多的特征相关时,可能会得到一个很大的正系数和一个很大的负系数。正是因为上述限制条件的存在,使用岭回归可以避免这个问题。
|
||||
|
||||
与岭回归类似,另一个缩减方法lasso也对回归系数做了限定,对应的约束条件如下:
|
||||
|
||||
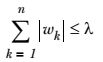
|
||||
|
||||
唯一的不同点在于,这个约束条件使用绝对值取代了平方和。虽然约束形式只是稍作变化,结果却大相径庭: 在 λ 足够小的时候,一些系数会因此被迫缩减到 0.这个特性可以帮助我们更好地理解数据。
|
||||
|
||||
#### 4.3、前向逐步回归
|
||||
|
||||
前向逐步回归算法可以得到与 lasso 差不多的效果,但更加简单。它属于一种贪心算法,即每一步都尽可能减少误差。一开始,所有权重都设置为 0,然后每一步所做的决策是对某个权重增加或减少一个很小的值。
|
||||
|
||||
伪代码如下:
|
||||
|
||||
```
|
||||
数据标准化,使其分布满足 0 均值 和单位方差
|
||||
在每轮迭代过程中:
|
||||
设置当前最小误差 lowestError 为正无穷
|
||||
对每个特征:
|
||||
增大或缩小:
|
||||
改变一个系数得到一个新的 w
|
||||
计算新 w 下的误差
|
||||
如果误差 Error 小于当前最小误差 lowestError: 设置 Wbest 等于当前的 W
|
||||
将 W 设置为新的 Wbest
|
||||
```
|
||||
|
||||
##### 4.3.1、前向逐步回归 原始代码
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
```python
|
||||
def stageWise(xArr,yArr,eps=0.01,numIt=100):
|
||||
xMat = mat(xArr); yMat=mat(yArr).T
|
||||
yMean = mean(yMat,0)
|
||||
yMat = yMat - yMean # 也可以规则化ys但会得到更小的coef
|
||||
xMat = regularize(xMat)
|
||||
m,n=shape(xMat)
|
||||
#returnMat = zeros((numIt,n)) # 测试代码删除
|
||||
ws = zeros((n,1)); wsTest = ws.copy(); wsMax = ws.copy()
|
||||
for i in range(numIt):
|
||||
print (ws.T)
|
||||
lowestError = inf;
|
||||
for j in range(n):
|
||||
for sign in [-1,1]:
|
||||
wsTest = ws.copy()
|
||||
wsTest[j] += eps*sign
|
||||
yTest = xMat*wsTest
|
||||
rssE = rssError(yMat.A,yTest.A)
|
||||
if rssE < lowestError:
|
||||
lowestError = rssE
|
||||
wsMax = wsTest
|
||||
ws = wsMax.copy()
|
||||
returnMat[i,:]=ws.T
|
||||
return returnMat
|
||||
|
||||
|
||||
#test for stageWise
|
||||
def regression4():
|
||||
xArr,yArr=loadDataSet("data/8.Regression/abalone.txt")
|
||||
print(stageWise(xArr,yArr,0.01,200))
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
xMat = regularize(xMat)
|
||||
yM = mean(yMat,0)
|
||||
yMat = yMat - yM
|
||||
weights = standRegres(xMat, yMat.T)
|
||||
print (weights.T)
|
||||
```
|
||||
|
||||
|
||||
##### 4.3.2、逐步线性回归在鲍鱼数据集上的运行效果
|
||||
|
||||
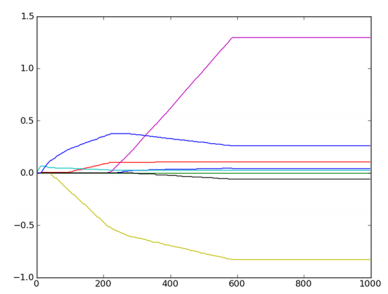
|
||||
|
||||
逐步线性回归算法的主要优点在于它可以帮助人们理解现有的模型并作出改进。当构建了一个模型后,可以运行该算法找出重要的特征,这样就有可能及时停止对那些不重要特征的收集。最后,如果用于测试,该算法每100次迭代后就可以构建出一个模型,可以使用类似于10折交叉验证的方法比较这些模型,最终选择使误差最小的模型。
|
||||
|
||||
#### 4.4、小结
|
||||
|
||||
当应用缩减方法(如逐步线性回归或岭回归)时,模型也就增加了偏差(bias),与此同时却减小了模型的方差。
|
||||
|
||||
|
||||
### 5、权衡偏差和方差
|
||||
|
||||
任何时候,一旦发现模型和测量值之间存在差异,就说出现了误差。当考虑模型中的 “噪声” 或者说误差时,必须考虑其来源。你可能会对复杂的过程进行简化,这将导致在模型和测量值之间出现 “噪声” 或误差,若无法理解数据的真实生成过程,也会导致差异的产生。另外,测量过程本身也可能产生 “噪声” 或者问题。下面我们举一个例子,我们使用 `线性回归` 和 `局部加权线性回归` 处理过一个从文件导入的二维数据。
|
||||
|
||||

|
||||
|
||||
其中的 N(0, 1) 是一个均值为 0、方差为 1 的正态分布。我们尝试过仅用一条直线来拟合上述数据。不难想到,直线所能得到的最佳拟合应该是 3.0+1.7x 这一部分。这样的话,误差部分就是 0.1sin(30x)+0.06N(0, 1) 。在上面,我们使用了局部加权线性回归来试图捕捉数据背后的结构。该结构拟合起来有一定的难度,因此我们测试了多组不同的局部权重来找到具有最小测试误差的解。
|
||||
|
||||
下图给出了训练误差和测试误差的曲线图,上面的曲面就是测试误差,下面的曲线是训练误差。我们根据 预测鲍鱼年龄 的实验知道: 如果降低核的大小,那么训练误差将变小。从下图开看,从左到右就表示了核逐渐减小的过程。
|
||||
|
||||
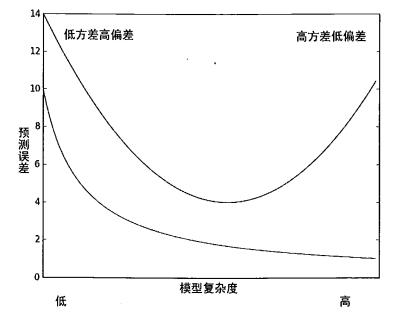
|
||||
|
||||
一般认为,上述两种误差由三个部分组成: 偏差、测量误差和随机噪声。局部加权线性回归 和 预测鲍鱼年龄 中,我们通过引入了三个越来越小的核来不断增大模型的方差。
|
||||
|
||||
在缩减系数来“理解”数据这一节中,我们介绍了缩减法,可以将一些系数缩减成很小的值或直接缩减为 0 ,这是一个增大模型偏差的例子。通过把一些特征的回归系数缩减到 0 ,同时也就减小了模型的复杂度。例子中有 8 个特征,消除其中两个后不仅使模型更易理解,同时还降低了预测误差。对照上图,左侧是参数缩减过于严厉的结果,而右侧是无缩减的效果。
|
||||
|
||||
方差是可以度量的。如果从鲍鱼数据中取一个随机样本集(例如取其中 100 个数据)并用线性模型拟合,将会得到一组回归系数。同理,再取出另一组随机样本集并拟合,将会得到另一组回归系数。这些系数间的差异大小也就是模型方差的反映。
|
||||
|
||||
|
||||
### 6、回归 项目案例
|
||||
|
||||
#### 项目案例1: 预测乐高玩具套装的价格
|
||||
|
||||
[完整代码地址](/src/py2.x/ml/8.Regression/regression.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/8.Regression/regression.py>
|
||||
|
||||
##### 项目概述
|
||||
|
||||
Dangler 喜欢为乐高套装估价,我们用回归技术来帮助他建立一个预测模型。
|
||||
|
||||
##### 开发流程
|
||||
|
||||
```
|
||||
(1) 收集数据:用 Google Shopping 的API收集数据。
|
||||
(2) 准备数据:从返回的JSON数据中抽取价格。
|
||||
(3) 分析数据:可视化并观察数据。
|
||||
(4) 训练算法:构建不同的模型,采用逐步线性回归和直接的线性回归模型。
|
||||
(5) 测试算法:使用交叉验证来测试不同的模型,分析哪个效果最好。
|
||||
(6) 使用算法:这次练习的目标就是生成数据模型。
|
||||
```
|
||||
|
||||
> 收集数据: 使用 Google 购物的 API
|
||||
|
||||
由于 Google 提供的 api 失效,我们只能自己下载咯,将数据存储在了 input 文件夹下的 setHtml 文件夹下
|
||||
|
||||
> 准备数据: 从返回的 JSON 数据中抽取价格
|
||||
|
||||
因为我们这里不是在线的,就不再是 JSON 了,我们直接解析线下的网页,得到我们想要的数据。
|
||||
|
||||
> 分析数据: 可视化并观察数据
|
||||
|
||||
这里我们将解析得到的数据打印出来,然后观察数据。
|
||||
|
||||
> 训练算法: 构建不同的模型
|
||||
|
||||
```python
|
||||
from numpy import *
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
# 从页面读取数据,生成retX和retY列表
|
||||
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
|
||||
|
||||
# 打开并读取HTML文件
|
||||
fr = open(inFile)
|
||||
soup = BeautifulSoup(fr.read())
|
||||
i=1
|
||||
|
||||
# 根据HTML页面结构进行解析
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
while(len(currentRow)!=0):
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
title = currentRow[0].findAll('a')[1].text
|
||||
lwrTitle = title.lower()
|
||||
|
||||
# 查找是否有全新标签
|
||||
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
|
||||
newFlag = 1.0
|
||||
else:
|
||||
newFlag = 0.0
|
||||
|
||||
# 查找是否已经标志出售,我们只收集已出售的数据
|
||||
soldUnicde = currentRow[0].findAll('td')[3].findAll('span')
|
||||
if len(soldUnicde)==0:
|
||||
print "item #%d did not sell" % i
|
||||
else:
|
||||
# 解析页面获取当前价格
|
||||
soldPrice = currentRow[0].findAll('td')[4]
|
||||
priceStr = soldPrice.text
|
||||
priceStr = priceStr.replace('$','') #strips out $
|
||||
priceStr = priceStr.replace(',','') #strips out ,
|
||||
if len(soldPrice)>1:
|
||||
priceStr = priceStr.replace('Free shipping', '')
|
||||
sellingPrice = float(priceStr)
|
||||
|
||||
# 去掉不完整的套装价格
|
||||
if sellingPrice > origPrc * 0.5:
|
||||
print "%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice)
|
||||
retX.append([yr, numPce, newFlag, origPrc])
|
||||
retY.append(sellingPrice)
|
||||
i += 1
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
|
||||
# 依次读取六种乐高套装的数据,并生成数据矩阵
|
||||
def setDataCollect(retX, retY):
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego8288.html', 2006, 800, 49.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10030.html', 2002, 3096, 269.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10179.html', 2007, 5195, 499.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10181.html', 2007, 3428, 199.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10189.html', 2008, 5922, 299.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10196.html', 2009, 3263, 249.99)
|
||||
```
|
||||
|
||||
> 测试算法:使用交叉验证来测试不同的模型,分析哪个效果最好
|
||||
|
||||
```python
|
||||
# 交叉验证测试岭回归
|
||||
def crossValidation(xArr,yArr,numVal=10):
|
||||
# 获得数据点个数,xArr和yArr具有相同长度
|
||||
m = len(yArr)
|
||||
indexList = range(m)
|
||||
errorMat = zeros((numVal,30))
|
||||
|
||||
# 主循环 交叉验证循环
|
||||
for i in range(numVal):
|
||||
# 随机拆分数据,将数据分为训练集(90%)和测试集(10%)
|
||||
trainX=[]; trainY=[]
|
||||
testX = []; testY = []
|
||||
|
||||
# 对数据进行混洗操作
|
||||
random.shuffle(indexList)
|
||||
|
||||
# 切分训练集和测试集
|
||||
for j in range(m):
|
||||
if j < m*0.9:
|
||||
trainX.append(xArr[indexList[j]])
|
||||
trainY.append(yArr[indexList[j]])
|
||||
else:
|
||||
testX.append(xArr[indexList[j]])
|
||||
testY.append(yArr[indexList[j]])
|
||||
|
||||
# 获得回归系数矩阵
|
||||
wMat = ridgeTest(trainX,trainY)
|
||||
|
||||
# 循环遍历矩阵中的30组回归系数
|
||||
for k in range(30):
|
||||
# 读取训练集和数据集
|
||||
matTestX = mat(testX); matTrainX=mat(trainX)
|
||||
# 对数据进行标准化
|
||||
meanTrain = mean(matTrainX,0)
|
||||
varTrain = var(matTrainX,0)
|
||||
matTestX = (matTestX-meanTrain)/varTrain
|
||||
|
||||
# 测试回归效果并存储
|
||||
yEst = matTestX * mat(wMat[k,:]).T + mean(trainY)
|
||||
|
||||
# 计算误差
|
||||
errorMat[i,k] = ((yEst.T.A-array(testY))**2).sum()
|
||||
|
||||
# 计算误差估计值的均值
|
||||
meanErrors = mean(errorMat,0)
|
||||
minMean = float(min(meanErrors))
|
||||
bestWeights = wMat[nonzero(meanErrors==minMean)]
|
||||
|
||||
# 不要使用标准化的数据,需要对数据进行还原来得到输出结果
|
||||
xMat = mat(xArr); yMat=mat(yArr).T
|
||||
meanX = mean(xMat,0); varX = var(xMat,0)
|
||||
unReg = bestWeights/varX
|
||||
|
||||
# 输出构建的模型
|
||||
print "the best model from Ridge Regression is:\n",unReg
|
||||
print "with constant term: ",-1*sum(multiply(meanX,unReg)) + mean(yMat)
|
||||
|
||||
|
||||
# predict for lego's price
|
||||
def regression5():
|
||||
lgX = []
|
||||
lgY = []
|
||||
|
||||
setDataCollect(lgX, lgY)
|
||||
crossValidation(lgX, lgY, 10)
|
||||
```
|
||||
|
||||
> 使用算法:这次练习的目标就是生成数据模型
|
||||
|
||||
## 7、选读内容
|
||||
|
||||
求解线性回归可以有很多种方式,除了上述的方法(正规方程 normal equation)解决之外,还有可以对Cost function 求导,其中最简单的方法就是梯度下降法。
|
||||
|
||||
那么正规方程就可以直接得出真实值。而梯度下降法只能给出近似值。
|
||||
|
||||
以下是梯度下降法和正规方程的比较:
|
||||
|
||||
| 梯度下降法 | 正规方程 |
|
||||
| ------------- |:-------------:|
|
||||
| 结果为真实值的近似值 | 结果为真实值 |
|
||||
| 需要循环多次 | 无需循环 |
|
||||
| 样本数量大的时候也ok | 样本数量特别大的时候会很慢(n>10000) |
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[小瑶](http://cwiki.apachecn.org/display/~chenyao) [片刻](https://github.com/jiangzhonglian)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,633 @@
|
|||
# 第9章 树回归
|
||||
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
|
||||
|
||||

|
||||
|
||||
## 树回归 概述
|
||||
|
||||
`我们本章介绍 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。`
|
||||
|
||||
## 树回归 场景
|
||||
|
||||
我们在第 8 章中介绍了线性回归的一些强大的方法,但这些方法创建的模型需要拟合所有的样本点(局部加权线性回归除外)。当数据拥有众多特征并且特征之间关系十分复杂时,构建全局模型的想法就显得太难了,也略显笨拙。而且,实际生活中很多问题都是非线性的,不可能使用全局线性模型来拟合任何数据。
|
||||
|
||||
一种可行的方法是将数据集切分成很多份易建模的数据,然后利用我们的线性回归技术来建模。如果首次切分后仍然难以拟合线性模型就继续切分。在这种切分方式下,树回归和回归法就相当有用。
|
||||
|
||||
除了我们在 第3章 中介绍的 决策树算法,我们介绍一个新的叫做 CART(Classification And Regression Trees, 分类回归树) 的树构建算法。该算法既可以用于分类还可以用于回归。
|
||||
|
||||
## 1、树回归 原理
|
||||
|
||||
### 1.1、树回归 原理概述
|
||||
|
||||
为成功构建以分段常数为叶节点的树,需要度量出数据的一致性。第3章使用树进行分类,会在给定节点时计算数据的混乱度。那么如何计算连续型数值的混乱度呢?
|
||||
|
||||
在这里,计算连续型数值的混乱度是非常简单的。首先计算所有数据的均值,然后计算每条数据的值到均值的差值。为了对正负差值同等看待,一般使用绝对值或平方值来代替上述差值。
|
||||
|
||||
上述做法有点类似于前面介绍过的统计学中常用的方差计算。唯一不同就是,方差是平方误差的均值(均方差),而这里需要的是平方误差的总值(总方差)。总方差可以通过均方差乘以数据集中样本点的个数来得到。
|
||||
|
||||
### 1.2、树构建算法 比较
|
||||
|
||||
我们在 第3章 中使用的树构建算法是 ID3 。ID3 的做法是每次选取当前最佳的特征来分割数据,并按照该特征的所有可能取值来切分。也就是说,如果一个特征有 4 种取值,那么数据将被切分成 4 份。一旦按照某特征切分后,该特征在之后的算法执行过程中将不会再起作用,所以有观点认为这种切分方式过于迅速。另外一种方法是二元切分法,即每次把数据集切分成两份。如果数据的某特征值等于切分所要求的值,那么这些数据就进入树的左子树,反之则进入树的右子树。
|
||||
|
||||
除了切分过于迅速外, ID3 算法还存在另一个问题,它不能直接处理连续型特征。只有事先将连续型特征转换成离散型,才能在 ID3 算法中使用。但这种转换过程会破坏连续型变量的内在性质。而使用二元切分法则易于对树构造过程进行调整以处理连续型特征。具体的处理方法是: 如果特征值大于给定值就走左子树,否则就走右子树。另外,二元切分法也节省了树的构建时间,但这点意义也不是特别大,因为这些树构建一般是离线完成,时间并非需要重点关注的因素。
|
||||
|
||||
CART 是十分著名且广泛记载的树构建算法,它使用二元切分来处理连续型变量。对 CART 稍作修改就可以处理回归问题。第 3 章中使用香农熵来度量集合的无组织程度。如果选用其他方法来代替香农熵,就可以使用树构建算法来完成回归。
|
||||
|
||||
回归树与分类树的思路类似,但是叶节点的数据类型不是离散型,而是连续型。
|
||||
|
||||
#### 1.2.1、附加 各常见树构造算法的划分分支方式
|
||||
|
||||
还有一点要说明,构建决策树算法,常用到的是三个方法: ID3, C4.5, CART.
|
||||
三种方法区别是划分树的分支的方式:
|
||||
1. ID3 是信息增益分支
|
||||
2. C4.5 是信息增益率分支
|
||||
3. CART 做分类工作时,采用 GINI 值作为节点分裂的依据;回归时,采用样本的最小方差作为节点的分裂依据。
|
||||
|
||||
工程上总的来说:
|
||||
|
||||
CART 和 C4.5 之间主要差异在于分类结果上,CART 可以回归分析也可以分类,C4.5 只能做分类;C4.5 子节点是可以多分的,而 CART 是无数个二叉子节点;
|
||||
|
||||
以此拓展出以 CART 为基础的 “树群” Random forest , 以 回归树 为基础的 “树群” GBDT 。
|
||||
|
||||
### 1.3、树回归 工作原理
|
||||
|
||||
1、找到数据集切分的最佳位置,函数 chooseBestSplit() 伪代码大致如下:
|
||||
|
||||
```
|
||||
对每个特征:
|
||||
对每个特征值:
|
||||
将数据集切分成两份(小于该特征值的数据样本放在左子树,否则放在右子树)
|
||||
计算切分的误差
|
||||
如果当前误差小于当前最小误差,那么将当前切分设定为最佳切分并更新最小误差
|
||||
返回最佳切分的特征和阈值
|
||||
```
|
||||
2、树构建算法,函数 createTree() 伪代码大致如下:
|
||||
|
||||
```
|
||||
找到最佳的待切分特征:
|
||||
如果该节点不能再分,将该节点存为叶节点
|
||||
执行二元切分
|
||||
在右子树调用 createTree() 方法
|
||||
在左子树调用 createTree() 方法
|
||||
```
|
||||
|
||||
### 1.4、树回归 开发流程
|
||||
|
||||
```
|
||||
(1) 收集数据:采用任意方法收集数据。
|
||||
(2) 准备数据:需要数值型数据,标称型数据应该映射成二值型数据。
|
||||
(3) 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树。
|
||||
(4) 训练算法:大部分时间都花费在叶节点树模型的构建上。
|
||||
(5) 测试算法:使用测试数据上的R^2值来分析模型的效果。
|
||||
(6) 使用算法:使用训练处的树做预测,预测结果还可以用来做很多事情。
|
||||
```
|
||||
|
||||
### 1.5、树回归 算法特点
|
||||
|
||||
```
|
||||
优点:可以对复杂和非线性的数据建模。
|
||||
缺点:结果不易理解。
|
||||
适用数据类型:数值型和标称型数据。
|
||||
```
|
||||
|
||||
### 1.6、回归树 项目案例
|
||||
|
||||
#### 1.6.1、项目概述
|
||||
|
||||
在简单数据集上生成一棵回归树。
|
||||
|
||||
#### 1.6.2、开发流程
|
||||
|
||||
```
|
||||
收集数据:采用任意方法收集数据
|
||||
准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法:大部分时间都花费在叶节点树模型的构建上
|
||||
测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
```
|
||||
|
||||
> 收集数据:采用任意方法收集数据
|
||||
|
||||
data1.txt 文件中存储的数据格式如下:
|
||||
|
||||
```
|
||||
0.036098 0.155096
|
||||
0.993349 1.077553
|
||||
0.530897 0.893462
|
||||
0.712386 0.564858
|
||||
0.343554 -0.371700
|
||||
0.098016 -0.332760
|
||||
```
|
||||
> 准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
|
||||
> 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
|
||||
基于 CART 算法构建回归树的简单数据集
|
||||
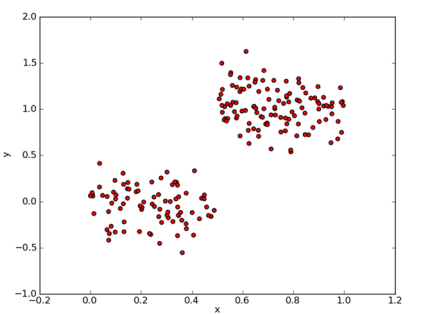
|
||||
|
||||
用于测试回归树的分段常数数据集
|
||||
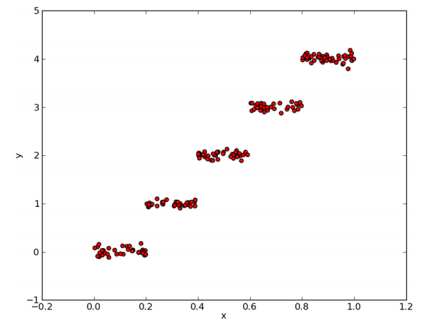
|
||||
|
||||
|
||||
> 训练算法: 构造树的数据结构
|
||||
|
||||
```python
|
||||
def binSplitDataSet(dataSet, feature, value):
|
||||
"""binSplitDataSet(将数据集,按照feature列的value进行 二元切分)
|
||||
Description:在给定特征和特征值的情况下,该函数通过数组过滤方式将上述数据集合切分得到两个子集并返回。
|
||||
Args:
|
||||
dataMat 数据集
|
||||
feature 待切分的特征列
|
||||
value 特征列要比较的值
|
||||
Returns:
|
||||
mat0 小于等于 value 的数据集在左边
|
||||
mat1 大于 value 的数据集在右边
|
||||
Raises:
|
||||
"""
|
||||
# # 测试案例
|
||||
# print 'dataSet[:, feature]=', dataSet[:, feature]
|
||||
# print 'nonzero(dataSet[:, feature] > value)[0]=', nonzero(dataSet[:, feature] > value)[0]
|
||||
# print 'nonzero(dataSet[:, feature] <= value)[0]=', nonzero(dataSet[:, feature] <= value)[0]
|
||||
|
||||
# dataSet[:, feature] 取去每一行中,第1列的值(从0开始算)
|
||||
# nonzero(dataSet[:, feature] > value) 返回结果为true行的index下标
|
||||
mat0 = dataSet[nonzero(dataSet[:, feature] <= value)[0], :]
|
||||
mat1 = dataSet[nonzero(dataSet[:, feature] > value)[0], :]
|
||||
return mat0, mat1
|
||||
|
||||
|
||||
# 1.用最佳方式切分数据集
|
||||
# 2.生成相应的叶节点
|
||||
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
"""chooseBestSplit(用最佳方式切分数据集 和 生成相应的叶节点)
|
||||
|
||||
Args:
|
||||
dataSet 加载的原始数据集
|
||||
leafType 建立叶子点的函数
|
||||
errType 误差计算函数(求总方差)
|
||||
ops [容许误差下降值,切分的最少样本数]。
|
||||
Returns:
|
||||
bestIndex feature的index坐标
|
||||
bestValue 切分的最优值
|
||||
Raises:
|
||||
"""
|
||||
|
||||
# ops=(1,4),非常重要,因为它决定了决策树划分停止的threshold值,被称为预剪枝(prepruning),其实也就是用于控制函数的停止时机。
|
||||
# 之所以这样说,是因为它防止决策树的过拟合,所以当误差的下降值小于tolS,或划分后的集合size小于tolN时,选择停止继续划分。
|
||||
# 最小误差下降值,划分后的误差减小小于这个差值,就不用继续划分
|
||||
tolS = ops[0]
|
||||
# 划分最小 size 小于,就不继续划分了
|
||||
tolN = ops[1]
|
||||
# 如果结果集(最后一列为1个变量),就返回退出
|
||||
# .T 对数据集进行转置
|
||||
# .tolist()[0] 转化为数组并取第0列
|
||||
if len(set(dataSet[:, -1].T.tolist()[0])) == 1: # 如果集合size为1,不用继续划分。
|
||||
# exit cond 1
|
||||
return None, leafType(dataSet)
|
||||
# 计算行列值
|
||||
m, n = shape(dataSet)
|
||||
# 无分类误差的总方差和
|
||||
# the choice of the best feature is driven by Reduction in RSS error from mean
|
||||
S = errType(dataSet)
|
||||
# inf 正无穷大
|
||||
bestS, bestIndex, bestValue = inf, 0, 0
|
||||
# 循环处理每一列对应的feature值
|
||||
for featIndex in range(n-1): # 对于每个特征
|
||||
# [0]表示这一列的[所有行],不要[0]就是一个array[[所有行]]
|
||||
for splitVal in set(dataSet[:, featIndex].T.tolist()[0]):
|
||||
# 对该列进行分组,然后组内的成员的val值进行 二元切分
|
||||
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
|
||||
# 判断二元切分的方式的元素数量是否符合预期
|
||||
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
|
||||
continue
|
||||
newS = errType(mat0) + errType(mat1)
|
||||
# 如果二元切分,算出来的误差在可接受范围内,那么就记录切分点,并记录最小误差
|
||||
# 如果划分后误差小于 bestS,则说明找到了新的bestS
|
||||
if newS < bestS:
|
||||
bestIndex = featIndex
|
||||
bestValue = splitVal
|
||||
bestS = newS
|
||||
# 判断二元切分的方式的元素误差是否符合预期
|
||||
# if the decrease (S-bestS) is less than a threshold don't do the split
|
||||
if (S - bestS) < tolS:
|
||||
return None, leafType(dataSet)
|
||||
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
|
||||
# 对整体的成员进行判断,是否符合预期
|
||||
# 如果集合的 size 小于 tolN
|
||||
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 当最佳划分后,集合过小,也不划分,产生叶节点
|
||||
return None, leafType(dataSet)
|
||||
return bestIndex, bestValue
|
||||
|
||||
|
||||
# assume dataSet is NumPy Mat so we can array filtering
|
||||
# 假设 dataSet 是 NumPy Mat 类型的,那么我们可以进行 array 过滤
|
||||
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
"""createTree(获取回归树)
|
||||
Description:递归函数:如果构建的是回归树,该模型是一个常数,如果是模型树,其模型师一个线性方程。
|
||||
Args:
|
||||
dataSet 加载的原始数据集
|
||||
leafType 建立叶子点的函数
|
||||
errType 误差计算函数
|
||||
ops=(1, 4) [容许误差下降值,切分的最少样本数]
|
||||
Returns:
|
||||
retTree 决策树最后的结果
|
||||
"""
|
||||
# 选择最好的切分方式: feature索引值,最优切分值
|
||||
# choose the best split
|
||||
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
|
||||
# if the splitting hit a stop condition return val
|
||||
# 如果 splitting 达到一个停止条件,那么返回 val
|
||||
if feat is None:
|
||||
return val
|
||||
retTree = {}
|
||||
retTree['spInd'] = feat
|
||||
retTree['spVal'] = val
|
||||
# 大于在右边,小于在左边,分为2个数据集
|
||||
lSet, rSet = binSplitDataSet(dataSet, feat, val)
|
||||
# 递归的进行调用,在左右子树中继续递归生成树
|
||||
retTree['left'] = createTree(lSet, leafType, errType, ops)
|
||||
retTree['right'] = createTree(rSet, leafType, errType, ops)
|
||||
return retTree
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
> 测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
|
||||
> 使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
|
||||
## 2、树剪枝
|
||||
|
||||
一棵树如果节点过多,表明该模型可能对数据进行了 “过拟合”。
|
||||
|
||||
通过降低决策树的复杂度来避免过拟合的过程称为 `剪枝(pruning)`。在函数 chooseBestSplit() 中提前终止条件,实际上是在进行一种所谓的 `预剪枝(prepruning)`操作。另一个形式的剪枝需要使用测试集和训练集,称作 `后剪枝(postpruning)`。
|
||||
|
||||
### 2.1、预剪枝(prepruning)
|
||||
|
||||
顾名思义,预剪枝就是及早的停止树增长,在构造决策树的同时进行剪枝。
|
||||
|
||||
所有决策树的构建方法,都是在无法进一步降低熵的情况下才会停止创建分支的过程,为了避免过拟合,可以设定一个阈值,熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。但是这种方法实际中的效果并不好。
|
||||
|
||||
### 2.2、后剪枝(postpruning)
|
||||
|
||||
决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。合并也被称作 `塌陷处理` ,在回归树中一般采用取需要合并的所有子树的平均值。后剪枝是目前最普遍的做法。
|
||||
|
||||
后剪枝 prune() 的伪代码如下:
|
||||
|
||||
```
|
||||
基于已有的树切分测试数据:
|
||||
如果存在任一子集是一棵树,则在该子集递归剪枝过程
|
||||
计算将当前两个叶节点合并后的误差
|
||||
计算不合并的误差
|
||||
如果合并会降低误差的话,就将叶节点合并
|
||||
```
|
||||
|
||||
### 2.3、剪枝 代码
|
||||
|
||||
回归树剪枝函数
|
||||
|
||||
```python
|
||||
# 判断节点是否是一个字典
|
||||
def isTree(obj):
|
||||
"""
|
||||
Desc:
|
||||
测试输入变量是否是一棵树,即是否是一个字典
|
||||
Args:
|
||||
obj -- 输入变量
|
||||
Returns:
|
||||
返回布尔类型的结果。如果 obj 是一个字典,返回true,否则返回 false
|
||||
"""
|
||||
return (type(obj).__name__ == 'dict')
|
||||
|
||||
|
||||
# 计算左右枝丫的均值
|
||||
def getMean(tree):
|
||||
"""
|
||||
Desc:
|
||||
从上往下遍历树直到叶节点为止,如果找到两个叶节点则计算它们的平均值。
|
||||
对 tree 进行塌陷处理,即返回树平均值。
|
||||
Args:
|
||||
tree -- 输入的树
|
||||
Returns:
|
||||
返回 tree 节点的平均值
|
||||
"""
|
||||
if isTree(tree['right']):
|
||||
tree['right'] = getMean(tree['right'])
|
||||
if isTree(tree['left']):
|
||||
tree['left'] = getMean(tree['left'])
|
||||
return (tree['left']+tree['right'])/2.0
|
||||
|
||||
|
||||
# 检查是否适合合并分枝
|
||||
def prune(tree, testData):
|
||||
"""
|
||||
Desc:
|
||||
从上而下找到叶节点,用测试数据集来判断将这些叶节点合并是否能降低测试误差
|
||||
Args:
|
||||
tree -- 待剪枝的树
|
||||
testData -- 剪枝所需要的测试数据 testData
|
||||
Returns:
|
||||
tree -- 剪枝完成的树
|
||||
"""
|
||||
# 判断是否测试数据集没有数据,如果没有,就直接返回tree本身的均值
|
||||
if shape(testData)[0] == 0:
|
||||
return getMean(tree)
|
||||
|
||||
# 判断分枝是否是dict字典,如果是就将测试数据集进行切分
|
||||
if (isTree(tree['right']) or isTree(tree['left'])):
|
||||
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
|
||||
# 如果是左边分枝是字典,就传入左边的数据集和左边的分枝,进行递归
|
||||
if isTree(tree['left']):
|
||||
tree['left'] = prune(tree['left'], lSet)
|
||||
# 如果是右边分枝是字典,就传入左边的数据集和左边的分枝,进行递归
|
||||
if isTree(tree['right']):
|
||||
tree['right'] = prune(tree['right'], rSet)
|
||||
|
||||
# 上面的一系列操作本质上就是将测试数据集按照训练完成的树拆分好,对应的值放到对应的节点
|
||||
|
||||
# 如果左右两边同时都不是dict字典,也就是左右两边都是叶节点,而不是子树了,那么分割测试数据集。
|
||||
# 1. 如果正确
|
||||
# * 那么计算一下总方差 和 该结果集的本身不分枝的总方差比较
|
||||
# * 如果 合并的总方差 < 不合并的总方差,那么就进行合并
|
||||
# 注意返回的结果: 如果可以合并,原来的dict就变为了 数值
|
||||
if not isTree(tree['left']) and not isTree(tree['right']):
|
||||
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
|
||||
# power(x, y)表示x的y次方
|
||||
errorNoMerge = sum(power(lSet[:, -1] - tree['left'], 2)) + sum(power(rSet[:, -1] - tree['right'], 2))
|
||||
treeMean = (tree['left'] + tree['right'])/2.0
|
||||
errorMerge = sum(power(testData[:, -1] - treeMean, 2))
|
||||
# 如果 合并的总方差 < 不合并的总方差,那么就进行合并
|
||||
if errorMerge < errorNoMerge:
|
||||
print "merging"
|
||||
return treeMean
|
||||
else:
|
||||
return tree
|
||||
else:
|
||||
return tree
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
## 3、模型树
|
||||
|
||||
### 3.1、模型树 简介
|
||||
用树来对数据建模,除了把叶节点简单地设定为常数值之外,还有一种方法是把叶节点设定为分段线性函数,这里所谓的 `分段线性(piecewise linear)` 是指模型由多个线性片段组成。
|
||||
|
||||
我们看一下图 9-4 中的数据,如果使用两条直线拟合是否比使用一组常数来建模好呢?答案显而易见。可以设计两条分别从 0.0~0.3、从 0.3~1.0 的直线,于是就可以得到两个线性模型。因为数据集里的一部分数据(0.0~0.3)以某个线性模型建模,而另一部分数据(0.3~1.0)则以另一个线性模型建模,因此我们说采用了所谓的分段线性模型。
|
||||
|
||||
决策树相比于其他机器学习算法的优势之一在于结果更易理解。很显然,两条直线比很多节点组成一棵大树更容易解释。模型树的可解释性是它优于回归树的特点之一。另外,模型树也具有更高的预测准确度。
|
||||
|
||||
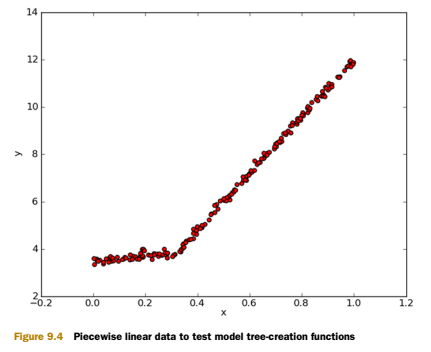
|
||||
|
||||
将之前的回归树的代码稍作修改,就可以在叶节点生成线性模型而不是常数值。下面将利用树生成算法对数据进行划分,且每份切分数据都能很容易被线性模型所表示。这个算法的关键在于误差的计算。
|
||||
|
||||
那么为了找到最佳切分,应该怎样计算误差呢?前面用于回归树的误差计算方法这里不能再用。稍加变化,对于给定的数据集,应该先用模型来对它进行拟合,然后计算真实的目标值与模型预测值间的差值。最后将这些差值的平方求和就得到了所需的误差。
|
||||
|
||||
### 3.2、模型树 代码
|
||||
|
||||
模型树的叶节点生成函数
|
||||
|
||||
```python
|
||||
# 得到模型的ws系数:f(x) = x0 + x1*featrue1+ x3*featrue2 ...
|
||||
# create linear model and return coeficients
|
||||
def modelLeaf(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
当数据不再需要切分的时候,生成叶节点的模型。
|
||||
Args:
|
||||
dataSet -- 输入数据集
|
||||
Returns:
|
||||
调用 linearSolve 函数,返回得到的 回归系数ws
|
||||
"""
|
||||
ws, X, Y = linearSolve(dataSet)
|
||||
return ws
|
||||
|
||||
|
||||
# 计算线性模型的误差值
|
||||
def modelErr(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
在给定数据集上计算误差。
|
||||
Args:
|
||||
dataSet -- 输入数据集
|
||||
Returns:
|
||||
调用 linearSolve 函数,返回 yHat 和 Y 之间的平方误差。
|
||||
"""
|
||||
ws, X, Y = linearSolve(dataSet)
|
||||
yHat = X * ws
|
||||
# print corrcoef(yHat, Y, rowvar=0)
|
||||
return sum(power(Y - yHat, 2))
|
||||
|
||||
|
||||
# helper function used in two places
|
||||
def linearSolve(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
将数据集格式化成目标变量Y和自变量X,执行简单的线性回归,得到ws
|
||||
Args:
|
||||
dataSet -- 输入数据
|
||||
Returns:
|
||||
ws -- 执行线性回归的回归系数
|
||||
X -- 格式化自变量X
|
||||
Y -- 格式化目标变量Y
|
||||
"""
|
||||
m, n = shape(dataSet)
|
||||
# 产生一个关于1的矩阵
|
||||
X = mat(ones((m, n)))
|
||||
Y = mat(ones((m, 1)))
|
||||
# X的0列为1,常数项,用于计算平衡误差
|
||||
X[:, 1: n] = dataSet[:, 0: n-1]
|
||||
Y = dataSet[:, -1]
|
||||
|
||||
# 转置矩阵*矩阵
|
||||
xTx = X.T * X
|
||||
# 如果矩阵的逆不存在,会造成程序异常
|
||||
if linalg.det(xTx) == 0.0:
|
||||
raise NameError('This matrix is singular, cannot do inverse,\ntry increasing the second value of ops')
|
||||
# 最小二乘法求最优解: w0*1+w1*x1=y
|
||||
ws = xTx.I * (X.T * Y)
|
||||
return ws, X, Y
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
### 3.3、模型树 运行结果
|
||||
|
||||
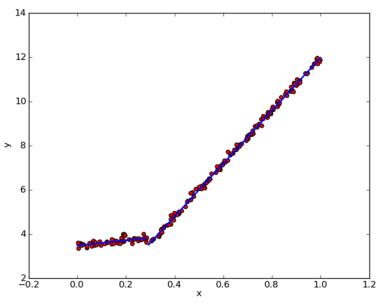
|
||||
|
||||
|
||||
## 4、树回归 项目案例
|
||||
|
||||
### 4.1、项目案例1: 树回归与标准回归的比较
|
||||
|
||||
#### 4.1.1、项目概述
|
||||
|
||||
前面介绍了模型树、回归树和一般的回归方法,下面测试一下哪个模型最好。
|
||||
|
||||
这些模型将在某个数据上进行测试,该数据涉及人的智力水平和自行车的速度的关系。当然,数据是假的。
|
||||
|
||||
#### 4.1.2、开发流程
|
||||
|
||||
```
|
||||
收集数据:采用任意方法收集数据
|
||||
准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
训练算法:模型树的构建
|
||||
测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
```
|
||||
|
||||
> 收集数据: 采用任意方法收集数据
|
||||
|
||||
> 准备数据:需要数值型数据,标称型数据应该映射成二值型数据
|
||||
|
||||
数据存储格式:
|
||||
```
|
||||
3.000000 46.852122
|
||||
23.000000 178.676107
|
||||
0.000000 86.154024
|
||||
6.000000 68.707614
|
||||
15.000000 139.737693
|
||||
```
|
||||
|
||||
> 分析数据:绘出数据的二维可视化显示结果,以字典方式生成树
|
||||
|
||||
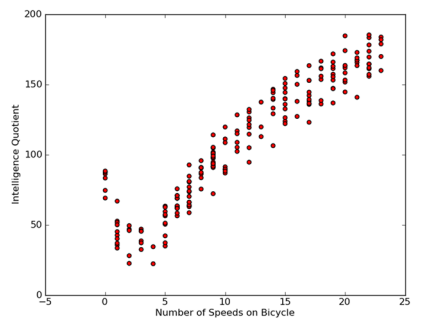
|
||||
|
||||
> 训练算法:模型树的构建
|
||||
|
||||
用树回归进行预测的代码
|
||||
```python
|
||||
# 回归树测试案例
|
||||
# 为了和 modelTreeEval() 保持一致,保留两个输入参数
|
||||
def regTreeEval(model, inDat):
|
||||
"""
|
||||
Desc:
|
||||
对 回归树 进行预测
|
||||
Args:
|
||||
model -- 指定模型,可选值为 回归树模型 或者 模型树模型,这里为回归树
|
||||
inDat -- 输入的测试数据
|
||||
Returns:
|
||||
float(model) -- 将输入的模型数据转换为 浮点数 返回
|
||||
"""
|
||||
return float(model)
|
||||
|
||||
|
||||
# 模型树测试案例
|
||||
# 对输入数据进行格式化处理,在原数据矩阵上增加第0列,元素的值都是1,
|
||||
# 也就是增加偏移值,和我们之前的简单线性回归是一个套路,增加一个偏移量
|
||||
def modelTreeEval(model, inDat):
|
||||
"""
|
||||
Desc:
|
||||
对 模型树 进行预测
|
||||
Args:
|
||||
model -- 输入模型,可选值为 回归树模型 或者 模型树模型,这里为模型树模型
|
||||
inDat -- 输入的测试数据
|
||||
Returns:
|
||||
float(X * model) -- 将测试数据乘以 回归系数 得到一个预测值 ,转化为 浮点数 返回
|
||||
"""
|
||||
n = shape(inDat)[1]
|
||||
X = mat(ones((1, n+1)))
|
||||
X[:, 1: n+1] = inDat
|
||||
# print X, model
|
||||
return float(X * model)
|
||||
|
||||
|
||||
# 计算预测的结果
|
||||
# 在给定树结构的情况下,对于单个数据点,该函数会给出一个预测值。
|
||||
# modelEval是对叶节点进行预测的函数引用,指定树的类型,以便在叶节点上调用合适的模型。
|
||||
# 此函数自顶向下遍历整棵树,直到命中叶节点为止,一旦到达叶节点,它就会在输入数据上
|
||||
# 调用modelEval()函数,该函数的默认值为regTreeEval()
|
||||
def treeForeCast(tree, inData, modelEval=regTreeEval):
|
||||
"""
|
||||
Desc:
|
||||
对特定模型的树进行预测,可以是 回归树 也可以是 模型树
|
||||
Args:
|
||||
tree -- 已经训练好的树的模型
|
||||
inData -- 输入的测试数据
|
||||
modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树
|
||||
Returns:
|
||||
返回预测值
|
||||
"""
|
||||
if not isTree(tree):
|
||||
return modelEval(tree, inData)
|
||||
if inData[tree['spInd']] <= tree['spVal']:
|
||||
if isTree(tree['left']):
|
||||
return treeForeCast(tree['left'], inData, modelEval)
|
||||
else:
|
||||
return modelEval(tree['left'], inData)
|
||||
else:
|
||||
if isTree(tree['right']):
|
||||
return treeForeCast(tree['right'], inData, modelEval)
|
||||
else:
|
||||
return modelEval(tree['right'], inData)
|
||||
|
||||
|
||||
# 预测结果
|
||||
def createForeCast(tree, testData, modelEval=regTreeEval):
|
||||
"""
|
||||
Desc:
|
||||
调用 treeForeCast ,对特定模型的树进行预测,可以是 回归树 也可以是 模型树
|
||||
Args:
|
||||
tree -- 已经训练好的树的模型
|
||||
inData -- 输入的测试数据
|
||||
modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树
|
||||
Returns:
|
||||
返回预测值矩阵
|
||||
"""
|
||||
m = len(testData)
|
||||
yHat = mat(zeros((m, 1)))
|
||||
# print yHat
|
||||
for i in range(m):
|
||||
yHat[i, 0] = treeForeCast(tree, mat(testData[i]), modelEval)
|
||||
# print "yHat==>", yHat[i, 0]
|
||||
return yHat
|
||||
```
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/regTrees.py>
|
||||
|
||||
> 测试算法:使用测试数据上的R^2值来分析模型的效果
|
||||
|
||||
R^2 判定系数就是拟合优度判定系数,它体现了回归模型中自变量的变异在因变量的变异中所占的比例。如 R^2=0.99999 表示在因变量 y 的变异中有 99.999% 是由于变量 x 引起。当 R^2=1 时表示,所有观测点都落在拟合的直线或曲线上;当 R^2=0 时,表示自变量与因变量不存在直线或曲线关系。
|
||||
|
||||
所以我们看出, R^2 的值越接近 1.0 越好。
|
||||
|
||||
> 使用算法:使用训练出的树做预测,预测结果还可以用来做很多事情
|
||||
|
||||
|
||||
## 5、附加 Python 中 GUI 的使用
|
||||
|
||||
### 5.1、使用 Python 的 Tkinter 库创建 GUI
|
||||
|
||||
如果能让用户不需要任何指令就可以按照他们自己的方式来分析数据,就不需要对数据做出过多解释。其中一个能同时支持数据呈现和用户交互的方式就是构建一个图形用户界面(GUI,Graphical User Interface),如图9-7所示。
|
||||
|
||||

|
||||
|
||||
### 5.2、用 Tkinter 创建 GUI
|
||||
|
||||
Python 有很多 GUI 框架,其中一个易于使用的 Tkinter,是随 Python 的标准版编译版本发布的。Tkinter 可以在 Windows、Mac OS和大多数的 Linux 平台上使用。
|
||||
|
||||
|
||||
### 5.3、集成 Matplotlib 和 Tkinter
|
||||
|
||||
MatPlotlib 的构建程序包含一个前端,也就是面向用户的一些代码,如 plot() 和 scatter() 方法等。事实上,它同时创建了一个后端,用于实现绘图和不同应用之间接口。
|
||||
|
||||
通过改变后端可以将图像绘制在PNG、PDF、SVG等格式的文件上。下面将设置后端为 TkAgg (Agg 是一个 C++ 的库,可以从图像创建光栅图)。TkAgg可以在所选GUI框架上调用Agg,把 Agg 呈现在画布上。我们可以在Tk的GUI上放置一个画布,并用 .grid()来调整布局。
|
||||
|
||||
### 5.4、用treeExplore 的GUI构建的模型树示例图
|
||||
|
||||

|
||||
|
||||
[完整代码地址](https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/treeExplore.py): <https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/9.RegTrees/treeExplore.py>
|
||||
|
||||
|
||||
## 6、树回归 小结
|
||||
|
||||
数据集中经常包含一些复杂的相关关系,使得输入数据和目标变量之间呈现非线性关系。对这些复杂的关系建模,一种可行的方式是使用树来对预测值分段,包括分段常数或分段直线。一般采用树结构来对这种数据建模。相应地,若叶节点使用的模型是分段常数则称为回归树,若叶节点使用的模型师线性回归方程则称为模型树。
|
||||
|
||||
CART 算法可以用于构建二元树并处理离散型或连续型数据的切分。若使用不同的误差准则,就可以通过CART 算法构建模型树和回归树。该算法构建出的树会倾向于对数据过拟合。一棵过拟合的树常常十分复杂,剪枝技术的出现就是为了解决这个问题。两种剪枝方法分别是预剪枝(在树的构建过程中就进行剪枝)和后剪枝(当树构建完毕再进行剪枝),预剪枝更有效但需要用户定义一些参数。
|
||||
|
||||
Tkinter 是 Python 的一个 GUI 工具包。虽然并不是唯一的包,但它最常用。利用 Tkinter ,我们可以轻轻松松绘制各种部件并安排它们的位置。另外,可以为 Tkinter 构造一个特殊的部件来显示 Matplotlib 绘出的图。所以,Matplotlib 和 Tkinter 的集成可以构建出更强大的 GUI ,用户可以以更自然的方式来探索机器学习算法的奥妙。
|
||||
|
||||
* * *
|
||||
|
||||
* **作者:[片刻](https://github.com/jiangzhonglian) [小瑶](http://cwiki.apachecn.org/display/~chenyao)**
|
||||
* [GitHub地址](https://github.com/apachecn/AiLearning): <https://github.com/apachecn/AiLearning>
|
||||
* **版权声明:欢迎转载学习 => 请标注信息来源于 [ApacheCN](http://www.apachecn.org/)**
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
|
||||
## 朴素贝叶斯讨论
|
||||
|
||||
> [@Time渐行渐远](https://github.com/Timehsw) [@那伊抹微笑](https://github.com/wangyangting) [@小瑶](https://github.com/chenyyx) [@如果迎着风就飞](https://github.com/orgs/apachecn/people/mikechengwei)
|
||||
|
||||
朴素贝叶斯就是用来求逆向概率的(已知)。
|
||||
|
||||
1. 根据训练数据集求(正向)概率。
|
||||
2. 根据测试数据集求(逆向)概率(根据 贝叶斯公式)。
|
||||
3. 求出的逆向概率,哪个大,就属于哪个类别。
|
||||
|
||||
### 疑问 1
|
||||
通过训练集求出了各个特征的概率, 然后测试集的特征和之前求出来的概率相乘, 这个就代表这个测试集的特征的概率了.
|
||||
有了这个基础后, 通过贝叶斯公式, 就可以得到这个测试集的特征属于哪个类别了, 他们相乘的依据是什么?
|
||||
|
||||
```
|
||||
朴素贝叶斯?
|
||||
条件独立性啊
|
||||
朴素贝叶斯不是基于两个定理吗
|
||||
一个是假设 条件独立性
|
||||
一个是 贝叶斯定理
|
||||
条件独立性 所以每个特征相乘得到的概率 就是这个数据的概率
|
||||
```
|
||||
|
||||
### 疑问 2
|
||||
凭啥测试集的特征乘以训练集的概率就是测试集的概率了.这么做的理论依据是什么?
|
||||
|
||||
```
|
||||
朴素贝叶斯就是利用先验知识来解决后验概率,因为训练集中我们已经知道了每个单词在类别0和1中的概率,即p(w|c).
|
||||
我们就是要利用这个知识去解决在出现这些单词的组合情况下,类别更可能是0还是1,即p(c|w).
|
||||
如果说之前的训练样本少, 那么这个 p(w|c) 就更可能不准确, 所以样本越多我们会觉得这个 p(w|c) 越可信.
|
||||
```
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
# 自然语言处理介绍
|
||||
|
||||
* 语言是知识和思维的载体
|
||||
* 自然语言处理 (Natural Language Processing, NLP) 是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
|
||||
|
||||
## NLP相关的技术
|
||||
|
||||
| 中文 | 英文 | 描述 |
|
||||
| --- | --- | --- |
|
||||
| 分词 | Word Segmentation | 将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列 |
|
||||
| 命名实体识别 | Named Entity Recognition | 识别自然语言文本中具有特定意义的实体(人、地、机构、时间、作品等) |
|
||||
| 词性标注 | Part-Speech Tagging | 为自然语言文本中的每个词汇赋予一个词性(名词、动词、形容词等) |
|
||||
| 依存句法分析 | Dependency Parsing | 自动分析句子中的句法成分(主语、谓语、宾语、定语、状语和补语等成分) |
|
||||
| 词向量与语义相似度 | Word Embedding & Semantic Similarity | 依托全网海量数据和深度神经网络技术,实现了对词汇的向量化表示,并据此实现了词汇的语义相似度计算 |
|
||||
| 文本语义相似度 | Text Semantic Similarity | 依托全网海量数据和深度神经网络技术,实现文本间的语义相似度计算的能力 |
|
||||
| 篇章分析 | Document Analysis | 分析篇章级文本的内在结构,进而分析文本情感倾向,提取评论性观点,并生成反映文本关键信息的标签与摘要 |
|
||||
| 机器翻译技术 | Machine Translating | 基于互联网大数据,融合深度神经网络、统计、规则多种翻译方法,帮助用户跨越语言鸿沟,与世界自由沟通 |
|
||||
|
||||
## 场景案例
|
||||
|
||||
### 案例1(解决交叉歧义)
|
||||
|
||||
**分词(Word Segmentation)** :将连续的自然语言文本,切分成具有语义合理性和完整性的词汇序列
|
||||
|
||||
例句:致毕业和尚未毕业的同学。
|
||||
|
||||
分词:
|
||||
1. `致` `毕业` `和` `尚未` `毕业` `的` `同学`
|
||||
2. `致` `毕业` `和尚` `未` `毕业` `的` `同学`
|
||||
|
||||
推荐:
|
||||
1. 校友 和 老师 给 尚未 毕业 同学 的 一 封 信
|
||||
2. 本科 未 毕业 可以 当 和尚 吗
|
||||
|
||||
### 案例2(从粒度整合未登录体词)
|
||||
|
||||
**命名实体识别(Named Entity Recognition)**:识别自然语言文本中具有特定意义的实体(人、地、机构、时间、作品等)
|
||||
|
||||
例句:天使爱美丽在线观看
|
||||
|
||||
分词:`天使` `爱` `美丽` `在线` `观看`
|
||||
|
||||
实体: 天使爱美丽 -> 电影
|
||||
|
||||
推荐:
|
||||
1. 网页:天使爱美丽 土豆 高清视频
|
||||
2. 网页:在线直播爱美丽的天使
|
||||
|
||||
### 案例3(结构歧义问题)
|
||||
|
||||
**词性标注(Part-Speech Tagging)**: 为自然语言文本中的每个词汇赋予一个词性(名词、动词、形容词等)
|
||||
**依存句法分析(Dependency Parsing)**:自动分析句子中的句法成分(主语、谓语、宾语、定语、状语和补语等成分)
|
||||
|
||||
评论:房间里还可以欣赏日出
|
||||
|
||||
歧义:
|
||||
1. 房间还可以
|
||||
2. 可以欣赏日出
|
||||
|
||||
词性:(???)
|
||||
房间里:主语
|
||||
还可以:谓语
|
||||
欣赏日出: 动宾短语
|
||||
|
||||
### 案例4(词汇语言相似度)
|
||||
|
||||
**词向量与语义相似度(Word Embedding & Semantic Similarity)**:对词汇进行向量化表示,并据此实现词汇的语义相似度计算。
|
||||
|
||||
例如:西瓜 与 (呆瓜/草莓),哪个更接近?
|
||||
|
||||
向量化表示: 西瓜(0.1222, 0.22333, .. )
|
||||
相似度计算: 呆瓜(0.115) 草莓(0.325)
|
||||
向量化表示:(-0.333, 0.1223 .. ) (0.333, 0.3333, .. )
|
||||
|
||||
### 案例5(文本语义相似度)
|
||||
|
||||
**文本语义相似度(Text Semantic Similarity)**:依托全网海量数据和深度神经网络技术,实现文本间的语义相似度计算的能力
|
||||
|
||||
例如:车头如何防止车牌 与 (前牌照怎么装/如何办理北京牌照),哪个更接近?
|
||||
|
||||
向量化表示: 车头如何防止车牌(0.1222, 0.22333, .. )
|
||||
相似度计算: 前牌照怎么装(0.762) 如何办理北京牌照(0.486)
|
||||
向量化表示: (-0.333, 0.1223 .. ) (0.333, 0.3333, .. )
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
# 篇章分析-内容概述
|
||||
|
||||
## 篇章分析变迁
|
||||
|
||||
1. 内容生态: 新浪 -> 百家号、今日头条(自媒体)
|
||||
2. 用户成为信息的生产中心: web 1.0 -> 百度贴吧、新浪微博、团购网站(用户评论,富有个人情感和用户观点的信息)
|
||||
3. 移动、无屏: 显示屏 -> 手机、Siri(展示的终端)
|
||||
|
||||
## 篇章分析场景
|
||||
|
||||
篇章分析重要性:让人们最平等`便捷`地`获取信息`,`找到所求`。
|
||||
|
||||
1. 个性化信息获取(搜索引擎的理解和推荐):从搜索的角度来看,通过对内容的深入理解,我们能够精准地对内容进行分析,然后将内容推荐给需要的用户,达到不搜即得。
|
||||
2. 便捷咨询阅读(头条的热门推荐):从资讯阅读的角度来看,我们通过对内容进行概括总结、形成摘要,就能搞让用户更快捷地浏览信息、获取知识。
|
||||
3. 信息直接满足:更进一步说,对用户的问题,我们可以基于内容理解,直接给出答案,从而满足用户的需求。
|
||||
|
||||
`总之`:通过篇章分析,我们能够进行内容理解,从而更好地服务用户。
|
||||
|
||||
## 篇章分析概述
|
||||
|
||||
`篇章是形式上互相衔接、语义上前后连贯的句子序列。`
|
||||
|
||||
有以下3种:
|
||||
* 1.文章:新闻稿、博客、微博
|
||||
* 2.评论:O2O服务的用户评论、豆瓣的影评、微博上的动态
|
||||
* 3.对话:话题上是相互衔接的、语义上也是连贯的一个对话序列
|
||||
|
||||
## 篇章分析任务
|
||||
|
||||
整理的nlp全面知识体系: <https://liuhuanyong.github.io>
|
||||
|
||||
## nlp 学习书籍和工具:
|
||||
|
||||
* 百度搜索:Python自然语言处理
|
||||
* 读书笔记:https://wnma3mz.github.io/hexo_blog/2018/05/13/《Python自然语言处理》阅读笔记(一)
|
||||
* Python自然语言处理工具汇总: <https://blog.csdn.net/sa14023053/article/details/51823122>
|
||||
|
||||
## nlp 全局介绍视频:(简单做了解就行)
|
||||
|
||||
地址链接: http://bit.baidu.com/Course/detail/id/56.html
|
||||
|
||||
1. 自然语言处理知识入门
|
||||
2. 百度机器翻译
|
||||
3. 篇章分析
|
||||
4. UNIT:语言理解与交互技术
|
||||
|
||||
## 中文 NLP
|
||||
|
||||
> 开源 - 词向量库集合
|
||||
|
||||
* <https://github.com/Embedding/Chinese-Word-Vectors>
|
||||
* <https://github.com/brightmart/nlp_chinese_corpus>
|
||||
* <https://github.com/codemayq/chinese_chatbot_corpus>
|
||||
* <https://github.com/candlewill/Dialog_Corpus>
|
||||
|
||||
> 深度学习必学
|
||||
|
||||
1. [反向传递](/docs/dl/反向传递.md): https://www.cnblogs.com/charlotte77/p/5629865.html
|
||||
2. [CNN原理](/docs/dl/CNN原理.md): http://www.cnblogs.com/charlotte77/p/7759802.html
|
||||
3. [RNN原理](/docs/dl/RNN原理.md): https://blog.csdn.net/qq_39422642/article/details/78676567
|
||||
4. [LSTM原理](/docs/dl/LSTM原理.md): https://blog.csdn.net/weixin_42111770/article/details/80900575
|
||||
|
||||
> [Word2Vec 原理](/docs/nlp/Word2Vec.md):
|
||||
|
||||
1. 负采样
|
||||
|
||||
介绍:
|
||||
自然语言处理领域中,判断两个单词是不是一对上下文词(context)与目标词(target),如果是一对,则是正样本,如果不是一对,则是负样本。
|
||||
采样得到一个上下文词和一个目标词,生成一个正样本(positive example),生成一个负样本(negative example),则是用与正样本相同的上下文词,再在字典中随机选择一个单词,这就是负采样(negative sampling)。
|
||||
|
||||
案例:
|
||||
比如给定一句话“这是去上学的班车”,则对这句话进行正采样,得到上下文“上”和目标词“学”,则这两个字就是正样本。
|
||||
负样本的采样需要选定同样的“上”,然后在训练的字典中任意取另一个字,如“我”、“梦”、“目”,这一对就构成负样本。
|
||||
训练需要正样本和负样本同时存在。
|
||||
|
||||
优势:
|
||||
负采样的本质:每次让一个训练样本只更新部分权重,其他权重全部固定;减少计算量;(一定程度上还可以增加随机性)
|
||||
|
||||
## nlp 操作流程
|
||||
|
||||
[本项目](https://pytorch.apachecn.org/docs/1.0/#/char_rnn_classification_tutorial) 试图通过名字分类问题给大家描述一个基础的深度学习中自然语言处理模型,同时也向大家展示了Pytorch的基本玩法。 其实对于大部分基础的NLP工作,都是类似的套路:
|
||||
|
||||
1. 收集数据
|
||||
2. 清洗数据
|
||||
3. 为数据建立字母表或词表(vocabulary或者叫look-up table)
|
||||
4. 根据字母表或者词表把数据向量化
|
||||
5. 搭建神经网络,深度学习中一般以LSTM或者GRU为主,按照需求结合各种其他的工具,包括embedding,注意力机制,双向RNN等等常见算法。
|
||||
6. 输入数据,按需求得到输出,比如分类模型根据类别数来得到输出,生成模型根据指定的长度或者结束标志符来得到输出等等。
|
||||
7. 把输出的结果进行处理,得到最终想要的数据。常需要把向量化的结果根据字母表或者词表变回文本数据。
|
||||
8. 评估模型。
|
||||
|
||||
如果真的想要对自然语言处理或者序列模型有更加全面的了解,建议大家去网易云课堂看一看吴恩达深度学习微专业中的序列模型这一板块,可以说是讲的非常清楚了。 此外极力推荐两个blog:
|
||||
|
||||
1. 讲述RNN循环神经网络在深度学习中的各种应用场景。http://karpathy.github.io/2015/05/21/rnn-effectiveness/
|
||||
2. 讲述LSTM的来龙去脉。http://colah.github.io/posts/2015-08-Understanding-LSTMs/
|
||||
|
||||
最后,本文参考整合了:
|
||||
|
||||
* Pytorch中文文档:https://pytorch.apachecn.org
|
||||
* Pytorch官方文档:http://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html
|
||||
* Ngarneau小哥的博文:https://github.com/ngarneau/understanding-pytorch-batching-lstm
|
||||
* 另外,本项目搭配Sung Kim的Pytorch Zero To All的第13讲rnn_classification会更加方便食用喔,视频可以在油管和b站中找到。
|
||||
|
||||
## nlp - 比赛链接
|
||||
|
||||
* https://competitions.codalab.org/competitions/12731
|
||||
* https://sites.ualberta.ca/%7Emiyoung2/COLIEE2018/
|
||||
* https://visualdialog.org/challenge/2018
|
||||
+ 人机对话 NLP
|
||||
- http://jddc.jd.com
|
||||
+ 司法数据文本的 NLP
|
||||
- http://cail.cipsc.org.cn
|
||||
+ “达观杯” 文本智能处理挑战赛
|
||||
- http://www.dcjingsai.com/common/cmpt/“达观杯”文本智能处理挑战赛_竞赛信息.html
|
||||
+ 中文论文摘要数据
|
||||
- https://biendata.com/competition/smpetst2018
|
||||
+ 中文问答任务
|
||||
- https://biendata.com/competition/CCKS2018_4/
|
||||
+ 第二届讯飞杯中文机器阅读理解评测
|
||||
- http://www.hfl-tek.com/cmrc2018
|
||||
+ 2018机器阅读理解技术竞赛 这也是结束了的 NLP
|
||||
- http://mrc2018.cipsc.org.cn
|
||||
+ 句子文本相似度计算
|
||||
- https://www.kaggle.com/c/quora-question-pairs
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
【比赛收集平台】: https://github.com/iphysresearch/DataSciComp
|
||||
|
|
@ -0,0 +1,48 @@
|
|||
# Word2Vec 讲解
|
||||
|
||||
## 介绍
|
||||
|
||||
**需要复习** 手写 Word2Vec 源码:https://blog.csdn.net/u014595019/article/details/51943428
|
||||
|
||||
* 2013年,Google开源了一款用于词向量计算的工具—— `word2vec`,引起了工业界和学术界的关注。
|
||||
* `word2vec` 算法或模型的时候,其实指的是其背后用于计算 **word vector** 的 `CBoW` 模型和 `Skip-gram` 模型
|
||||
* 很多人以为 `word2vec` 指的是一个算法或模型,这也是一种谬误。
|
||||
* 因此通过 Word2Vec 技术 输出的词向量可以被用来做很多NLP相关的工作,比如聚类、找同义词、词性分析等等.
|
||||
|
||||
> 适用场景
|
||||
|
||||
1. cbow适用于小规模,或者主题比较散的语料,毕竟他的向量产生只跟临近的字有关系,更远的语料并没有被采用。
|
||||
2. 而相反的skip-gram可以处理基于相同语义,义群的一大批语料。
|
||||
|
||||
## CBoW 模型(Continuous Bag-of-Words Model)
|
||||
|
||||
* 连续词袋模型(CBOW)常用于NLP深度学习。
|
||||
* 这是一种模式,它试图根据目标词 `之前` 和 `之后` 几个单词的背景来预测单词(CBOW不是顺序)。
|
||||
* CBOW 模型: 能够根据输入周围n-1个词来预测出这个词本身.
|
||||
* 也就是说,CBOW模型的输入是某个词A周围的n个单词的词向量之和,输出是词A本身的词向量.
|
||||
|
||||

|
||||
|
||||
## 前言
|
||||
无意间,2017 年马上又要结束了,时间过得真快啊,又要老一岁了 。。。
|
||||
|
||||

|
||||
|
||||
在 2016 年 4 月份的时候,有一个想法,就是一个人想翻译下官方文档,感觉这样做的话,学习东西的话也会快很多,对自己也是一个提升,同时还可以帮助到其他的朋友,何乐而不为呢???
|
||||
有了这个想法之后,就跟一些朋友聊了一下,看一下可行性怎么样,大家都觉得有搞头,可以操作一波。(好可惜呀,跟好多人说了这个想法,真正想做并能坚持的朋友,貌似没有几个了,坚持着不该坚持的坚持,执着着不该执着的执着 。。。)
|
||||
|
||||
在 2016 年 7 月份的时候,才真正的打算做这件事情,那时候年少轻狂,写了一篇文章 [伟大的航道,前往新世界](http://www.apachecn.org/newworld/11.html)(**注: 了解 ApacheCN 必读**) 文章,简单的说了下自己的经历和想法,一些想做的事情,想找更多的朋友一起来翻译下官方文档。
|
||||
|
||||
由于当时做的是大数据方面的,所以更多的是翻译 Spark,Storm,Kudu,Zeepelin,Kibana,Elasticsearch 。。。等等和大数据相关的官方文档了,中间有很多故事由于篇幅原因,就先不细说了。至今为止,以上技术相关的文档,基本上都算是翻译好了,算是能看了,虽然还需要更进一步的完善,至少聊胜于无啊!~
|
||||
|
||||
最开始用的域名是 [le.wiki](http://www.le.wiki)(为啥用这个域名,原因很简单,因为那时候在乐视搬砖嘛!←_← 说到乐视,可能大家会说他哪里哪里不好什么的,开始各种黑了。我不想表达什么,我想说的是,至少对于我来说,能有东西学,能让自己成长,能有工资拿,就不错了,至少我很感谢 [乐视](http://www.le.com))。
|
||||
|
||||
[le.wiki](http://www.le.wiki) 域名太局限了,不够体现我们大家的情怀,所以不得不换一个域名了。
|
||||
|
||||
[apache.wiki](http://cwiki.apachecn.org) 域名的切换。由于我们这些成员大多数都是做大数据的,对 [Apache](http://www.apache.org) 是很有情怀的,非常感谢的,比如我们现在用的 Hadoop,Hive,Spark,Flink 等等的一些框架,都是 [Apache](http://www.apache.org) 开源出来的。所以经过大家的一致讨论后,准备使用 [apache.wiki](http://cwiki.apachecn.org) 使用这个域名了,据说看着还挺有情怀(逼格)的 。。。
|
||||
|
||||
在这期间,做了一些准备工作,和大家讨论一些事情等等,大家各自的尝试,然后就拖到 10 月份了。
|
||||
|
||||
|
||||
在 2016 年 10 月份的时候,准确来说是国庆后吧,正式开始翻译文档的搞事之际,邀请大家来操作一波,也为了让大家了解下我们是干嘛的,还特意在 [apache.wiki](http://cwiki.apachecn.org) 上写了写了一篇 [关于我们](http://cwiki.apachecn.org/pages/viewpage.action?pageId=2887240)(**注: 了解 ApacheCN 必读**),我差点把自己都感动了 。。。
|
||||
|
||||
在 2016 年年末试了下 Spark,Elasticsearch 文档的翻译,虽然内容很多,但还算是 OK 吧!~ 大家还是坚持了下来,非常感谢大家,我记得我调格式都调的要死了,忧桑 。。。
|
||||
|
||||
在 2017 年春节过后,大家又开始上班了,也许上班上了 3 年觉得太无聊了吧,或者说是想搞点事情出来,这样比较刺激点了。考虑了好久,刚好也有志同道合的伙伴 [小瑶](),[片刻](),干脆一起出来装逼吧。
|
||||
|
||||
就这样,在 2017 年 6 月底,踏上了装逼不归路,再不疯狂一把,我们就真的老了。。。
|
||||
|
||||

|
||||
|
||||
## 装逼的不归路
|
||||
自从走上了装逼的不归路之后,腰不酸了,腿不疼了,一口气装完逼脸不红,心也不跳了。。。
|
||||
|
||||
其实会有很多人问我,在这期间你们的收入来源怎么办呢???
|
||||
这特么就非常尴尬了,我能说根本没有收入来源么,自己选择的路,跪着也要走完吧!~
|
||||
|
||||
大不了再出去找工作呗,慌个毛呀,俗话说得好,人生苦短,及时行乐呀,趁着年轻,把自己想做的事情都做了,不要留下遗憾 。。。
|
||||
|
||||
这件事情,依然要坚持下去 。。。
|
||||
|
||||

|
||||
|
||||
## 组织趋势
|
||||
前言说了辣么多,也简单的介绍下组织的一个趋势吧:
|
||||
1. 资源: 组织的资源变得多了起来,光官方文档来说,前前后后一共翻译了差不多 10 个官方文档了,还在持续增加中。具体详情请看 [apachecn.org](http://www.apachecn.org) 中的中文文档。
|
||||
2. 影响力: 慢慢有人知道了 ApacheCN 这个开源组织的存在了,或者是接触到我们的资源了。
|
||||
3. UV: UV 从刚开始的每天 20,估计也就是我们自己点一下了,涨到了现在的 1K+,不容易呀,大家一把辛酸一把泪 - - 、
|
||||
4. GitHub: github.com/apachecn 也算是有我们自己的 github 了。
|
||||
5. 慢慢开始着手弄更多的东西了,比如优酷,B站,A站,知乎,悟空问答,网易云课堂,YouTube 等等之类的,不像以前辣么单调了。
|
||||
|
||||
随着流量的增加,影响力的扩大,辣么我们所需要做的事情就更多了,这时候的话,当然需要更多志同道合的朋友来一起来参与,一起来装逼了,23333333 。。。
|
||||
|
||||
## 组织目标
|
||||
第一目标: 国内第一装逼组织,大家去哪里装逼的时候,都能遇到组织成员就刺激了。
|
||||
第二目标: 等你来定义 。。。
|
||||

|
||||
|
||||
## 组织是做什么的
|
||||
请看 [apachecn.org](http://www.apachecn.org) 组织首页的介绍,专注于优秀项目维护的开源组织,不止于权威的文档视频技术支持。
|
||||
这里需要说一下的是,翻译文档不是我们这个组织唯一的事情。翻译文档只是该组织职能下的一个分支。
|
||||
比如,你想要解决技术问题,我们可以看一看,瞧一瞧。
|
||||
比如,你想要咨询个人问题,比如学习路线,职业规划等等,我们可以提供帮助。
|
||||
比如,你想要组织内的某些资源,我们也可以看情况提供。
|
||||
比如,你有好的想法,要来搞事情,我们可以一起装逼。
|
||||
比如,你想要装逼???那么来对地方了,欢迎 。。。
|
||||
比如,。。。等等。
|
||||
|
||||
## 加入好处
|
||||
1. 如果你喜欢装逼,从此你装逼的时候不是夜深人静的时候一个人。
|
||||
2. 如果你喜欢学习,在这里可以学习更多装逼的知识,更快的提升自己的个人技能。
|
||||
3. 如果你喜欢交友,在这里可以扩大自己的人脉圈,认识各种各样的大佬(小白),交更多的朋友 。
|
||||
4. 如果你是小白,可以跟我我们一起学习,有更多的人帮助你,比如在线咨询,学习路线规划,职业生涯规划,如何泡妹纸 。。。等等。
|
||||
5. 如果你是大佬 。。。好像我们都是小白,这特么就非常尴尬了。欢迎大佬!~
|
||||
6. 如果你喜欢搞事情,那么真的是来对地方了,组织欢迎你。
|
||||
7. 如果你喜欢搞基,那么欢迎来到搞基的天堂,如果不是为了搞基,那么人生还有什么意义。
|
||||
8. 如果你是伸手党 。。。这 。。。大哥你怕是走错地方了 - - !
|
||||
|
||||
特喵的,技术没学到什么,图片倒是收藏了很多张 。。。
|
||||
|
||||

|
||||
|
||||
## 组织架构
|
||||
为何要完善组织架构???
|
||||
1. 让成员更有参与感,提升成员的体验,万一出名了,以后可以自豪的说,我是组织里面的一员。
|
||||
2. 组织成员职能的划分,参与各种决策,不会像以前那样,挂个号就完了,既然想装逼,就得把逼装好了。
|
||||
3. 利于组织的发展扩大,外部成员的加入。一个好的组织架构,是组织发展更为壮大的重要一步,虽然只是我们组织的一小步,确是整个互联网的一大步 。。。(这牛逼吹的,我差点就信了 - - 、)
|
||||
4. 具体的组织架构,不在这里细说了。
|
||||
5. 。。。等等。
|
||||
6. 竟然还有小伙伴问,能不能兑换翔 。。。我也是无话可说。
|
||||
|
||||

|
||||
|
||||
## 组织积分制
|
||||
正在完善组织积分制,简单来说就是参与组织的一些活动,比如参与翻译,参与反馈,参与宣传活动等等啥的,都会获得相应的积分。
|
||||
那么积分可以干嘛呢,可以兑换什么呢?
|
||||
1. 云梯服务,遨游世界。
|
||||
2. 话费,积分可以直接折合成话费,充值到你的手机号中去。
|
||||
3. 百度网盘,爱奇艺,迅雷,迅游,优酷 。。。等等会员。
|
||||
4. 与积分等价的物品,比如可能你需要 `1080ti显卡` 。(只要你积分够,显卡组织当场兑换,不解释 。。。)
|
||||
5. 。。。等等。
|
||||
|
||||
## 组织规划
|
||||
在往机器学习,深度学习的道路方向前行,虽然过程很痛苦,但是前行的过程中有大家的欢声笑语觉得很快乐,在装逼的道路上渐行渐远 。。。
|
||||
|
||||
### 现阶段活动
|
||||
前端时间,组织根据书籍《机器学习实战》录制了一期公益性的视频,放到 A站,B站,优酷 等视频网站上了,相应的视频,文档,源码,注释,数据集可以在我们的 GitHub: <https://github.com/apachecn/AiLearning/> 中找到。
|
||||
|
||||
最近组织的 [scikit-learn 0.19 中文文档翻译校验活动]() 即将结束,sklearn 0.19.0 中文文档: <http://sklearn.apachecn.org/cn/0.19.0/> 马上可以正式的上线了。
|
||||
在此感谢参与活动的贡献者们: <https://github.com/apachecn/scikit-learn-doc-zh#%E8%B4%A1%E7%8C%AE%E8%80%85>
|
||||
|
||||
### 近期计划
|
||||
1. 准备马上开始组织一期《机器学习实战复习活动》,针对该书籍,自己复习的同时,提升大家的技术水平(针对新手小白)。
|
||||
2. 组织一起刷 kaggle 的活动,以此来熟悉 sklearn 套路的同时,也可以了解 kaggle 的套路。
|
||||
|
||||
## 加入要求
|
||||
没有什么要求,只要你愿意为组织出一份力,想要一起走的更快,一起走的更远即可。
|
||||
1. 如果你是小白: 非常欢迎小白,我们可以帮助你走更少的弯路,一起成长,可能你会想着说,你技术不够好,要先修炼修炼再加入我们,那么我只能说这个想法真的有问题。。。不要等到你足够优秀的时候,才去跟女神表白。。。因为等到你足够优秀的时候,机会已经错过了 。。。
|
||||
2. 如果你是大佬: 非常欢迎大佬们,来一起装逼。
|
||||
3. 如果你单纯的只是想找大佬来带你,怕是你又来错地方了 。。。- - 、
|
||||
|
||||

|
||||
|
||||
## 了解我们
|
||||
以前写的一些文章,如果想了解我们更多一点的话,必看的哟!~
|
||||
1. [伟大的航道,前往新世界](http://www.apachecn.org/newworld/11.html)
|
||||
2. [关于我们](http://cwiki.apachecn.org/pages/viewpage.action?pageId=2887240)
|
||||
|
||||
## 支持我们
|
||||
如果大佬们想要支持下我们,觉得我们的资源还不错,麻烦去 github: <https://github.com/apachecn> 给我们点几个 star 我们就满足了,谢谢!~
|
||||
|
||||
## 加入方式
|
||||
|
||||
* 机器学习企鹅群: 629470233(MachineLearning)
|
||||
|
||||
ps: 又特喵的收获了一些图片 。。。
|
||||
|
|
@ -0,0 +1,81 @@
|
|||
# 第1章 机器学习实战-复习版(问题汇总)
|
||||
|
||||
## 1.VSCode的安装使用
|
||||
|
||||
参考文档:http://cwiki.apachecn.org/pages/viewpage.action?pageId=7373315
|
||||
|
||||
## 2.GitHub的使用说明
|
||||
|
||||
参考文档:https://github.com/apachecn/kaggle/blob/master/docs/github-quickstart.md
|
||||
|
||||
注意: https://github.com/apachecn/AiLearning (这是本项目的地址,记得修改链接。。)
|
||||
|
||||
## 3.问题汇总
|
||||
|
||||
> 1.样本数据的来源:
|
||||
|
||||
1. 日志文件
|
||||
2. 数据库
|
||||
3. HDFS
|
||||
4. 数据流
|
||||
|
||||
> 2.样本数据按照一定比例来划分:训练数据集 + 测试数据集
|
||||
|
||||
1. 根据业务场景来分析,得到对应的比例
|
||||
2. 一般设置是按照 训练数据集:测试数据集 = 8:2
|
||||
|
||||
> 3.训练数据集包括: 特征(也就是数据的纬度 or 属性) + 目标变量(分类结果 or 回归值)
|
||||
|
||||
> 4.测试数据用来干嘛?
|
||||
|
||||
如下图:用于评估模型的效果。(测试样本的预测类别 和 测试样本的实际类别 的diff,就是我们的错误率)
|
||||
|
||||

|
||||
|
||||
> 5.监督学习和无监督学习的区别:是否有目标变量(也就是:是否存在分类结果)
|
||||
|
||||
> 6.电子书的下载位置:
|
||||
|
||||
* 下载书籍: https://github.com/apachecn/AiLearning/tree/python-2.7/books
|
||||
|
||||
> 7.性能不好是什么意思?
|
||||
|
||||
* 就是对比其他语言来说:资源的使用效率受限、处理速度慢。
|
||||
|
||||
> 8.学习原理后,如果成为调包侠?调包侠是否很丑?
|
||||
|
||||
1. 学习原理后,就看看 [sklearn中文文档](http://sklearn.apachecn.org/): http://sklearn.apachecn.org, 转型做调包侠
|
||||
2. 调包侠一点都不丑,为什么呢?
|
||||
* 便于分析业务,快速发现问题
|
||||
* 开发速度快,便于优化和维护
|
||||
|
||||
> 9.python讲解的版本 2.7.X
|
||||
|
||||
* 2.7.X版本测试比较稳定,没有Bug
|
||||
* 3.X 的朋友刚好可以上手去熟悉 API 并 锻炼自我解决问题的能力,算是自我学习的一个方式吧
|
||||
* 对于使用 3.X的朋友,可以提交 Pull Requests 到 3.X 分支,成为开源的贡献者,方便更多的人学习你的代码
|
||||
|
||||
## 4.复习的时间和资料
|
||||
|
||||
* 形式:直播+讨论组
|
||||
* 周期:周一 ~ 周五
|
||||
* 时间:20:30 ~ 21:30
|
||||
* 学习文档:https://github.com/apachecn/AiLearning
|
||||
* 下载书籍: https://github.com/apachecn/AiLearning/tree/python-2.7/books
|
||||
* 活动日期:2017-11-20 ~ 2017-12-08(共15天,1章1天)
|
||||
* 活动详情:http://www.apachecn.org/machinelearning/279.html
|
||||
|
||||
## 5.直播方式
|
||||
|
||||
* QQ:在讨论组共享屏幕(实时)
|
||||
* 视频会在 讨论组中进行分享
|
||||
* B站的直播地址(延迟)
|
||||
* 直播地址: http://live.bilibili.com/5427054
|
||||
|
||||
## 6.机器学习QQ群
|
||||
|
||||
* ApacheCN - 学习机器学习群【629470233】
|
||||
|
||||
***
|
||||
|
||||
`装逼不装逼,我们还是老地方见! | ApacheCN`
|
||||
|
|
@ -0,0 +1,366 @@
|
|||
# 直播问题汇总
|
||||
|
||||
标签(空格分隔): 机器学习 直播问题
|
||||
|
||||
---
|
||||
|
||||
## 1、机器学习基础(片刻)
|
||||
|
||||
1. 谷德 2017-11-20 20:45:09
|
||||
问:关于 github ,如果是管理员的话,那只能在 web 页面上做查看和审批吗?不能用 vscode 等编辑器进行吗?
|
||||
|
||||
答:管理员啥权限都有的,删除和创建项目的权限都有,但是都是在网页上进行, vscode 还不可以。github 的 桌面客户端应该也可以,但是相对用的较少。
|
||||
|
||||
2. HY Serendipity 2017-11-20 20:58:39
|
||||
问:回归和函数拟合的区别在哪儿?
|
||||
|
||||
答:回归是预测结果,而函数拟合是预测结果的一个步骤。
|
||||
|
||||
3. Michael❦ 2017-11-20 21:31:26
|
||||
问:话说 sklearn是啥 三方库么 听说好多次啦
|
||||
|
||||
答:scikit-learn 简称 sklearn 。是机器学习中一个常用的 python 第三方模块,英文官网:http://scikit-learn.org/stable/ 。中文官网(^_^):http://sklearn.apachecn.org/ 。里面对一些常用的机器学习方法进行了封装,在进行机器学习任务时,并不需要每个人都实现所有的算法,只需要简单的调用 sklearn 里面的模块就可以实现大多数机器学习任务。
|
||||
|
||||
4. HY Serendipity 2017-11-20 21:33:38
|
||||
问:em,我想问,之后学习算法是调包实现还是自己写代码实现?
|
||||
|
||||
答:最正确的做法,就是先了解原理之后,再做调包侠,因为咱们谁上来都不想做单纯的调包侠,那样显得咱们也比较 low 。
|
||||
|
||||
5. HY Serendipity 2017-11-20 22:22:19
|
||||
问:那个我想问一下,比如我从apachecn上fork了一个项目,并且自己clone到了本地,之后apachecn的项目有了更新,我直接在本地pull了apachecn的远程仓库的项目,但是我push是只能push到自己的仓库的,那么我自己的origin仓库的更新操作是怎么实现的呢?
|
||||
|
||||
答:是这样实现的,这算是一个基本的操作吧。下面我以第一人称来介绍啊。我先从 apachecn 上 fork 了ML项目到了我自己的 github 中,比如我的 github 用户名叫做 chenyyx ,我的项目中就有了一个叫做 ML 的项目,如 chenyyx/ML 。这样,我接下来,使用 git clone https://github.com/chenyyx/MachineLearning.git 命令,就将这个项目 克隆到我自己的本地计算机了。接下来就是我们的重头戏了。
|
||||
有一点需要知道:我的 git 默认创建的是本地与远程自己的 github (也就是 chenyyx)之间的关联。即,我在本地输入命令 git remote -v 看到的分支,只有一个 origin 分支,并且这个分支指向的是我自己的 github (也就是: https://github.com/chenyyx/MachineLearning),现在可能你会发现一个问题,我现在本地的文件与远程关联,只是与远程的我自己的 github 项目关联,并没有与 apachecn 的项目关联(也就是https://github.com/apachecn/AiLearning),所以我们还需要创建一个管道来连接我的本地文件与apachecn的项目。创建的命令是(每个单词之间用空格隔开):git remote add origin_ml(分支名称) https://github.com/apachecn/AiLearning.git(apachecn的远程分支) 。这样就在我本地文件与 apachecn 的远程分支建立了一个管道,可以用来同步 apachecn 的远程更新。使用命令如下:git pull origin_ml 或者麻烦点,使用:git fetch origin_ml 然后再使用 git merge origin_ml/master 这个命令,将远程的 master 分支上的更新与本地合并。(即达到了我的本地与 apachecn 的远程分支同步),然后再输入命令: git push 就可以将我同步提交到 我们自己的 github 上(实际上,就达到了我们的目的,将apachecn 的远程更新与我自己的github同步)。
|
||||
|
||||
6. 风风 2017-11-21 00:05:22
|
||||
问:各位大佬,我装了anconda3,那vscode还需要安装Python3吗?
|
||||
|
||||
答:不需要了,实际上 anaconda3 就是一个 python 的集成环境,它本身集成了很多常用的库,当然里面已经有了 python3 了,就不需要安装了。
|
||||
|
||||
## 2、k-近邻算法(KNN)(小瑶)
|
||||
|
||||
1. 谷德 2017-11-21 20:39:38
|
||||
问:求距离还有其他的算法吗?
|
||||
|
||||
答:k 近邻模型的特征空间一般是 n 维实数向量空间 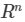 ,使用的距离是欧式距离。当然,我们还可以选择其他距离,比如更加一般的 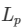 距离(Lp distance),或者 Minkowski 距离(Minkowski distance),曼哈顿距离(Manhattan Distance),切比雪夫距离(Chebyshev Distance)。
|
||||
|
||||
更多参见链接:http://liyonghui160com.iteye.com/blog/2084557
|
||||
|
||||
2. ~~ 2017-11-21 20:41:07
|
||||
问:用来求电影距离的 x y 具体含义是指什么?
|
||||
|
||||
答:如果大佬你说的是下面这种:
|
||||
|
||||

|
||||
|
||||
那么求电影距离的 x 是对应的电影中的 打斗镜头数 ,而 y 对应的是接吻镜头数,都是指的数据的特征,可能这里写的不清楚,你可以把这里的 y 当成 x2 属性,而把之前的 x 当成 x1 属性,这样就容易理解多了。都是特征,只不过是对应的不同的特征。注意,这里的 y 代表的不是相应的分类。
|
||||
|
||||
如果不是上面的这种,那么 x 代表的就是特征,y 代表的是目标变量,也就是相应的分类。
|
||||
|
||||
3. 蓝色之旅 2017-11-21 20:41:22
|
||||
问:可以讲pearson计算相似评价值度量吗?
|
||||
|
||||
答:Pearson 相关系数可以参考下面两个链接:
|
||||
* http://www.codeweblog.com/%E7%9B%B8%E4%BC%BC%E6%80%A7%E5%BA%A6%E9%87%8F-pearson%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0/
|
||||
* https://www.cnblogs.com/yulinfeng/p/4508930.html
|
||||
|
||||
4. QQ 2017-11-21 20:44:15
|
||||
问:那这个算法优化点在 k 和 距离上?
|
||||
|
||||
答:对,但不全对。三个因素上都可以进行优化。
|
||||
* 比如 k 值的选择上,我们可以选择一个近似误差和估计误差都较好的一个 k 值。
|
||||
* 距离度量上,我们上面说有很多种的距离度量方式,具体问题具体对待,根据不同的数据我们选择不同的距离度量方式,也可以达到优化的效果。
|
||||
* 分类决策规则这方面,我们也可以根据自己的经验选择适合的分类决策规则,KNN 最常用的就是多数表决。
|
||||
* 补充一点,还可以进行优化的部分。可以给训练数据集中的数据点加上适合的权重,距离新数据点相对较近的,权重较大,较远的,权重相应减小。这样也可以算是一种优化吧。
|
||||
|
||||
5. 谷德 2017-11-21 21:01:52
|
||||
问:如果数据的维度很多(列有很多)的话,这个靠内存计算是不是就很快就爆了?
|
||||
|
||||
答:是的啊,也可能不会爆炸,但是会很慢。当然大佬问的时候说到,那 KNN 在实际应用中的意义何在?之前的巨人们也做了一些相应的优化,比如 kd-tree 和 ball-tree 这些,详细内容可以参见链接:https://www.zhihu.com/question/30957691 。如果你感觉仍然达不到你的需求,对最初的数据进行预处理,也是可以的,比如降维等,在实用算法之前进行一些必要的处理,这样也可以使 KNN 的效率提升。当然,如果还是不如你的预期,那就考虑一下换一个算法试试。
|
||||
|
||||
6. QQ 2017-11-21 21:03:05
|
||||
问:归一化算法的选取标准是什么?
|
||||
|
||||
答:归一化算法的选取标准可以参考下面两个链接:
|
||||
* https://www.zhihu.com/question/20455227
|
||||
* https://www.zhihu.com/question/26546711/answer/62085061
|
||||
|
||||
7. HY Serendipity 2017-11-21 21:25:18
|
||||
问:手写数字识别的时候,img2vector 所以是看成了32·32个特征么?
|
||||
|
||||
答:这么理解稍微有一些偏颇。并不是将图片文件看成 32*32 个特征,而是将之前 32 行 32 列的数据转换成为一行数据,也就是 1 * 1024 的形式,把它当成一条数据来处理,一个图片代表一个样本数据,这样更便于我们接下来的欧式距离的计算。
|
||||
|
||||
## 3、决策树(Decision Tree)(小瑶)
|
||||
|
||||
1. QQ 2017-11-22 20:38:06
|
||||
问:叶节点是提前分好的吗?
|
||||
|
||||
答:其实,不能这么说吧,叶节点是根据我们训练数据集中所有数据的分类来得到的,是我们训练出来的。训练数据集中有什么分类,我们就会得到什么叶节点。
|
||||
|
||||
2. HY Serendipity 2017-11-22 20:42:12
|
||||
问:信息增益是信息熵的差么?
|
||||
|
||||
答:是的,是数据集划分之前的信息熵 减去 数据集划分之后的信息熵 的差值,得到的这个差值我们就称之为信息增益。
|
||||
|
||||
3. HY Serendipity 2017-11-22 20:45:46
|
||||
问:什么是划分后熵最小?
|
||||
|
||||
答:因为我们在构造决策树的过程中,是遍历数据集中所有的数据特征(N个特征,全部都遍历一次),在每一次会依据一个特征划分数据集之后,会计算一下划分后得到的子数据集的新的信息熵。我们从这些得到的新的信息熵中找到那个最小的信息熵,也就是划分数据集之前的信息熵与划分数据集之后的信息熵的差值是最大的。也就是咱们说的信息增益是最大的。
|
||||
|
||||
4. 谷德 2017-11-22 20:48:45
|
||||
问:那树的深度是多少呢?
|
||||
|
||||
答:在没有设置树的深度,或者没有设置树的停止条件下,树的深度是N,也就是训练数据集的 N 个特征数。
|
||||
|
||||
当然树的深度可以自己设置,比如,我们在使用信息增益划分数据集的情况下,我们可以设置信息增益的最小值(作为阈值),只要大于我们设置的最小值就划分数据集,如果小于这个阈值的话,我们就不再划分数据集了。这其实就是一个剪枝的概念(预剪枝)。而既然有这种考虑的话,那我们就要想到,不再划分数据
|
||||
|
||||
还有就是在我们已经将树构建完成后,认为树的节点或者深度过多的话,可以通过一定的算法减少树的节点和深度,这样就得到了自定义的树的深度和节点。这也是另一种层面上的剪枝(后剪枝)。
|
||||
|
||||
5. HY Serendipity 2017-11-22 20:55:28
|
||||
问:这个示例里的特征的概率具体是怎么计算的?还有详细的信息熵计算。
|
||||
|
||||
答:首先我们看一下计算香农熵的公式,然后下面看计算给定数据集的香农熵的函数。
|
||||
|
||||
其中的 $p(x_i)$ 是选择该分类的概率。
|
||||
|
||||
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
|
||||
$$H = -\sum_{i=1}^{n}p(x_i)log_2p(x_i)$$
|
||||
|
||||
```python
|
||||
def calcShannonEnt(dataSet):
|
||||
# 求list的长度,表示计算参与训练的数据量
|
||||
numEntries = len(dataSet)
|
||||
# 计算分类标签label出现的次数
|
||||
labelCounts = {}
|
||||
# the the number of unique elements and their occurance
|
||||
for featVec in dataSet:
|
||||
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
|
||||
currentLabel = featVec[-1]
|
||||
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
|
||||
if currentLabel not in labelCounts.keys():
|
||||
labelCounts[currentLabel] = 0
|
||||
labelCounts[currentLabel] += 1
|
||||
|
||||
# 对于 label 标签的占比,求出 label 标签的香农熵
|
||||
shannonEnt = 0.0
|
||||
for key in labelCounts:
|
||||
# 使用所有类标签的发生频率计算类别出现的概率。
|
||||
prob = float(labelCounts[key])/numEntries
|
||||
# 计算香农熵,以 2 为底求对数
|
||||
shannonEnt -= prob * log(prob, 2)
|
||||
return shannonEnt
|
||||
```
|
||||
|
||||
可以看到,我们这里计算概率纯属就是为计算数据集的香农熵做准备的。
|
||||
接下来,这里是这样来计算相应概率的:
|
||||
1、首先统计 dataSet 中全部数据的条数,作为总数据量(也就是我们要计算概率的时候的除数或者说是分母)。
|
||||
2、然后遍历数据集中的所有数据,统计数据集中的分类,生成一个字典,形式如:{"A(我是分类A)":2(数据集中所有A类数据的条数), "B(我是分类B)":3(数据集中所有B类数据的条数)....}。
|
||||
3、最后遍历这个字典,使用字典中每一项对应的条数除以总的数据量,就计算出相应的概率了。emmm,就这样我们集计算了相应的概率。
|
||||
4、接下来就是计算香农熵,以 2 为底的对数计算。按照我们上面的信息熵计算公式。shannonEnt -= prob * log(prob, 2) 就得到了香农熵了。
|
||||
|
||||
|
||||
不知道讲没讲清楚,也不知道讲没讲错误,还请大家看一下,有什么问题直接联系我(小瑶)。(╯‵□′)╯︵┻━┻
|
||||
|
||||
## 4、朴素贝叶斯算法(Naive Bayes)(如果迎着风就飞)
|
||||
|
||||
1. 小瑶 2017-11-23 20:45:05
|
||||
问:先验概率和后验概率都是什么意思?
|
||||
|
||||
答:先验概率是在缺乏某个事实的情况下描述一个变量; 而后验概率是在考虑了一个事实之后的条件概率。所以后验概率也可以叫做条件概率。
|
||||
|
||||
2. HY Serendipity 2017-11-23 20:52:56
|
||||
问:朴素是指条件独立吗?
|
||||
|
||||
答:是的,朴素贝叶斯就是假设条件完全独立。
|
||||
|
||||
3. 那伊抹微笑 2017-11-23 21:16:45
|
||||
问:为什么概率最大是我们想要的结果?
|
||||
|
||||
答:代价最小/风险最小(需要详细写一下吧)
|
||||
|
||||
4. 超萌小宝贝 2017-11-23 21:20:18
|
||||
问:两种估计就差一个参数?
|
||||
|
||||
答:最大似然估计和贝叶斯估计,分母和分子是相差一个参数的,是为了避免概率值为0的情况。但是目的都是为了计算概率。
|
||||
|
||||
5. HY Serendipity 2017-11-23 21:21:01
|
||||
问:分母为什么要加上分子的 s 倍?
|
||||
|
||||
答:s倍取决于特征数,因为我要保证所有特征数属于某个类别的概率和为1。
|
||||
|
||||
6. 灵魂 2017-11-23 21:30:48
|
||||
问:拉普拉斯平滑是为了解决什么问题?
|
||||
|
||||
答:有时候因为训练量不足,会令分类器质量大大降低。为了解决这个问题,我们引入Laplace校准(这就引出了我们的拉普拉斯平滑),它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。(不知道回答的对不对)
|
||||
|
||||
## 5、Logistic 回归(逻辑斯蒂回归)(如果迎着风就飞)
|
||||
|
||||
1. HY Serendipity 2017-11-24 21:06:22
|
||||
问:我不清楚的是这里怎么引出梯度上升的?
|
||||
|
||||
答:因为逻辑回归在使用sigmoid函数的时候要找到每个特征是某个类别的权重,所以通过梯度上升来找到最优的权重比。
|
||||
|
||||
2. HY Serendipity 2017-11-24 21:19:25
|
||||
问:为什么要使用梯度上升求极值呢?
|
||||
|
||||
答:梯度上升和梯度下降都可以用来求极值,我们这里用梯度上升来求某条数据是某个类别的最大的可能性。最大的可能性肯定就是求最大值呀。所以求极大值上升,极小值下降。
|
||||
|
||||
3. ls 2017-11-24 21:26:32
|
||||
问:什么时候使用梯度上升,什么时候使用梯度下降?
|
||||
|
||||
答:主要看你的数学问题,和二次方程一样,-x^2肯定有最大值,x^2肯定是最小值啊。
|
||||
|
||||
4. HY Serendipity 2017-11-24 21:35:11
|
||||
问:我其实更想知道似然函数,因为这里用到了梯度上升
|
||||
|
||||
答:似然函数就一种条件概率,某个数据是某个类别的概率。
|
||||
|
||||
5. 为什么 LR 模型要使用 sigmoid 函数,背后的数学原理是什么?
|
||||
答:https://www.zhihu.com/question/35322351
|
||||
|
||||
|
||||
## 6、Support Vector Machine(支持向量机 SVM)(片刻)
|
||||
|
||||
1. HY Serendipity 2017-11-27 20:36:47
|
||||
问:这几个边界点是怎么选的?
|
||||
|
||||
答:
|
||||
|
||||
2. ls 2017-11-27 20:43:18
|
||||
问:函数间距怎么个意思啊?
|
||||
|
||||
答:函数距离是人为定义的,可以通过缩放w和b任意改变,所以不能用函数间距代表这个点到超平面的距离,用几何距离是一定的。
|
||||
|
||||
3. 怎么找最大间隔?
|
||||
答:
|
||||
|
||||
4. 分子等于 1,怎么解释?
|
||||
答:
|
||||
|
||||
5. 我在网站上看到的公式是乱码? A:github 没加载js,不会显示 LaTex?
|
||||
答:
|
||||
|
||||
6. 若果 w 之前没做平方的话,那这里求偏导不就没了?
|
||||
答:不做平方的话,就不是凸二次规划问题,就不能用拉格朗日替换了。
|
||||
|
||||
7. alpha是指什么?
|
||||
答:拉格朗日乘子
|
||||
|
||||
8. 这里的C是干嘛的,怎么选择的?
|
||||
答:
|
||||
|
||||
9. 不同的核函数,怎么使用?我的意思是什么情况下用什么核函数?
|
||||
答:
|
||||
|
||||
## 7、集成方法(ensemble method)(片刻)
|
||||
|
||||
1. HY Serendipity 2017-11-28 20:46:03
|
||||
问:这里的分裂特征是什么?
|
||||
|
||||
答:
|
||||
|
||||
2. 风风 2017-11-28 20:55:44
|
||||
问:我有个问题,如果都是随机化,那是不是每次运行算法都会不一样?
|
||||
|
||||
答:
|
||||
|
||||
3. 有放回 和无放回区别是什么哦?标准是:是否可以重复取样?
|
||||
答:
|
||||
|
||||
4. 怎么使用这些已有代码呢?用于理解这些算法理论?
|
||||
答:
|
||||
|
||||
## 8、预测数值型数据:回归(regression)(小瑶)
|
||||
|
||||
1. HY Serendipity 2017-11-29 20:42:04
|
||||
问:最后的表达特征与结果的非线性是什么意思?
|
||||
|
||||
答:就是说,我们得到数据特征之后,这些特征可能与最终的结果没有关系(或者说有关系,但是是非线性关系),但是我们通过加一些权重,就可以使得特征与我们最终的结果之间有一个线性关系了,这就是我们说的,使用线性数据(特征)来表达非线性关系的意思了。
|
||||
|
||||
2. 介绍一下k折交叉验证。
|
||||
|
||||
答:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
|
||||
|
||||
3. Cold 2017-11-29 21:43:42
|
||||
问:这个回归 应用场景 主要是预测么?
|
||||
|
||||
答:是的,主要是做预测,根据我们现在已有的一些数据,对接下来我们想要知道(而还未知道)的一些数值型数据做预测的。
|
||||
|
||||
|
||||
## 9、树回归(小瑶)
|
||||
|
||||
1. 片刻 2017-11-30 21:07:31
|
||||
问:决策树和模型树的区别在哪里?还没听明白
|
||||
|
||||
答:其实这个问题不能这么说吧。模型树本质上就是决策树的一种。大佬你想问的应该是分类树,回归树,模型树之间的一个区别在哪儿。
|
||||
- 分类树:在找划分数据集的最佳特征的时候,判断标准是等于不等于(是不是),而不是比较数值之间的大小,并且划分数据集(切分子数据集)的依据是信息增益(划分数据集之前的信息熵减去划分数据集之后的信息熵),测试数据根据我们构建完成的树结构走到最终的叶节点的时候,得到的是我们对测试数据的一个预测分类。
|
||||
- 回归树:在划分数据集的最佳特征的时候,判断标准是数值之间的大小比较,比如小于等于 value 值的进入左子树,而大于的进入右子树,并且,测试数据根据我们构建完成的树结构走到最终的叶节点的时候,得到的是我们对测试数据的一个预测值(预测值我们使用同一叶节点的均值)。
|
||||
- 模型树:对数据进行分段预测,只不过存储的子树中,是存储的线性回归模型的回归系数,这样从每个子树中我们就能够得到一个线性回归模型。通俗来说,就是决策树和线性回归的一个结合。
|
||||
|
||||
2. HY Serendipity 2017-11-30 21:22:42
|
||||
问:后剪枝是将两个叶子变成一个叶子?
|
||||
|
||||
答:后剪枝是从根节点遍历,一直找到最后的叶节点,然后计算,合并之后的两个叶子节点得到的误差值,与合并之前的两个叶子节点的误差值,做一个差值,看看是否小于我们设定的一个阈值,小于的话,我们就认为可以合并,然后,将两个叶子节点合并成一个叶子节点,并且使用两个叶子节点的所有数据的均值来代表这个叶子节点。
|
||||
|
||||
3. 诺 2017-11-30 21:24:11
|
||||
问:后剪枝需要遍历每个节点吗?
|
||||
|
||||
答:是的,需要遍历每个节点,从根节点起,一步一步遍历到不是树的节点,也就是最后的叶子节点。然后考虑合并还是不合并。
|
||||
|
||||
## 10、K-Means(K-均值)聚类算法(那伊抹微笑)
|
||||
|
||||
1. 小瑶 2017-12-01 20:46:29
|
||||
问:kMeans 会不会陷入局部最优?
|
||||
|
||||
答:会陷入局部最优,咱们这里介绍了一个方法来解决这个问题,二分 kmeans 。
|
||||
|
||||
## 11、Apriori 算法关联分析(那伊抹微笑)
|
||||
|
||||
2017-12-04 暂时无问题。
|
||||
|
||||
## 12、FP-growth算法发现频繁项集(如果迎着风就飞)
|
||||
|
||||
1. HY Serendipity 2017-12-05 20:41:38
|
||||
问:感觉这里的支持度有点问题啊,应该是出现次数比较妥当?
|
||||
|
||||
答:是的,这里我们省略分母,因为我们算支持度=出现次数/总的数目。 分母其实都是一样,所以我们省略了。
|
||||
|
||||
2. HY Serendipity 2017-12-05 21:09:45
|
||||
问:就是想问一下怎么一步步递归得到最后的t的所有频繁项集?
|
||||
|
||||
答:就是递归的去构造FP树,然后从FP树中挖掘频繁项集,当FP树节点为空,当前根递归才算结束。
|
||||
|
||||
## 13、PCA 简化数据(片刻)
|
||||
|
||||
1. 、 2017-12-06 20:44:01
|
||||
问:为什么主成分的方向,就是数据方差最大的方向?
|
||||
|
||||
答:
|
||||
|
||||
2. mushroom 2017-12-06 20:58:54
|
||||
问:降维之后会损失有效数据,怎么理解?
|
||||
|
||||
答:
|
||||
|
||||
3. cpp 2017-12-06 20:59:35
|
||||
问:为什么会正交?
|
||||
|
||||
答:正交的一个原因是特征值的特征向量是正交的。(还需要详细说一下)
|
||||
|
||||
## 14、SVD 简化数据(片刻)
|
||||
|
||||
1. 风风 2017-12-07 21:19:22
|
||||
问:为什么分解后还要还原?或者说,压缩的目的是什么?
|
||||
|
||||
答:
|
||||
|
||||
|
||||
## 15、大数据与 MapReduce(片刻)
|
||||
|
||||
1. HY Serendipity 2017-12-08 20:45:21
|
||||
问:mrjob 和 hadoop 区别是什么?
|
||||
|
||||
答:hadoop = HDFS + YARN + MapReduce
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
<!-- index.html -->
|
||||
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
|
||||
<meta name="viewport" content="width=device-width,initial-scale=1">
|
||||
<meta charset="UTF-8">
|
||||
<link rel="stylesheet" href="//unpkg.com/docsify/themes/vue.css">
|
||||
|
||||
<!-- google ads -->
|
||||
<script async src="//pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"></script>
|
||||
|
||||
<!-- baidu stats -->
|
||||
<script>
|
||||
var _hmt = _hmt || [];
|
||||
(function() {
|
||||
var hm = document.createElement("script");
|
||||
hm.src = "https://hm.baidu.com/hm.js?33149aa6702022b1203201da06e23d81";
|
||||
var s = document.getElementsByTagName("script")[0];
|
||||
s.parentNode.insertBefore(hm, s);
|
||||
})();
|
||||
</script>
|
||||
|
||||
<!-- google webmaster -->
|
||||
<meta name="google-site-verification" content="pyo9N70ZWyh8JB43bIu633mhxesJ1IcwWCZlM3jUfFo" />
|
||||
</head>
|
||||
<body>
|
||||
<div id="app">now loading...</div>
|
||||
<script id="footer" type="text/xml">
|
||||
<hr/>
|
||||
<div align="center">
|
||||
<p><a href="http://www.apachecn.org/" target="_blank"><font face="KaiTi" size="6" color="red">我们一直在努力</font></a><p>
|
||||
<p><a href="https://github.com/apachecn/ailearning/" target="_blank">apachecn/ailearning</a></p>
|
||||
<p><iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=ailearning&type=watch&count=true&v=2" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>
|
||||
<iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=ailearning&type=star&count=true" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>
|
||||
<iframe align="middle" src="https://ghbtns.com/github-btn.html?user=apachecn&repo=ailearning&type=fork&count=true" frameborder="0" scrolling="0" width="100px" height="25px"></iframe>
|
||||
<a target="_blank" href="//shang.qq.com/wpa/qunwpa?idkey=bcee938030cc9e1552deb3bd9617bbbf62d3ec1647e4b60d9cd6b6e8f78ddc03"><img border="0" src="//pub.idqqimg.com/wpa/images/group.png" alt="ML | ApacheCN" title="ML | ApacheCN"></a></p>
|
||||
<div style="text-align:center;margin:0 0 10.5px;">
|
||||
<ins class="adsbygoogle"
|
||||
style="display:inline-block;width:728px;height:90px"
|
||||
data-ad-client="ca-pub-3565452474788507"
|
||||
data-ad-slot="2543897000"></ins>
|
||||
</div>
|
||||
</div>
|
||||
</script>
|
||||
<script>
|
||||
window.docsPlugin = function(hook) {
|
||||
var footer = document.querySelector('#footer').innerHTML
|
||||
hook.afterEach(function(html) {
|
||||
return html + footer
|
||||
})
|
||||
hook.doneEach(function() {
|
||||
(adsbygoogle = window.adsbygoogle || []).push({})
|
||||
})
|
||||
}
|
||||
|
||||
window.$docsify = {
|
||||
loadSidebar: 'SUMMARY.md',
|
||||
name: '机器学习实战',
|
||||
auto2top: true,
|
||||
themeColor: '#03a9f4',
|
||||
repo: 'apachecn/ailearning',
|
||||
plugins: [window.docsPlugin],
|
||||
}
|
||||
</script>
|
||||
<script src="//unpkg.com/docsify/lib/docsify.min.js"></script>
|
||||
<script src="//unpkg.com/prismjs/components/prism-python.min.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
|
|
@ -0,0 +1,15 @@
|
|||
# 2017-04-08 第一期的总结
|
||||
|
||||

|
||||

|
||||
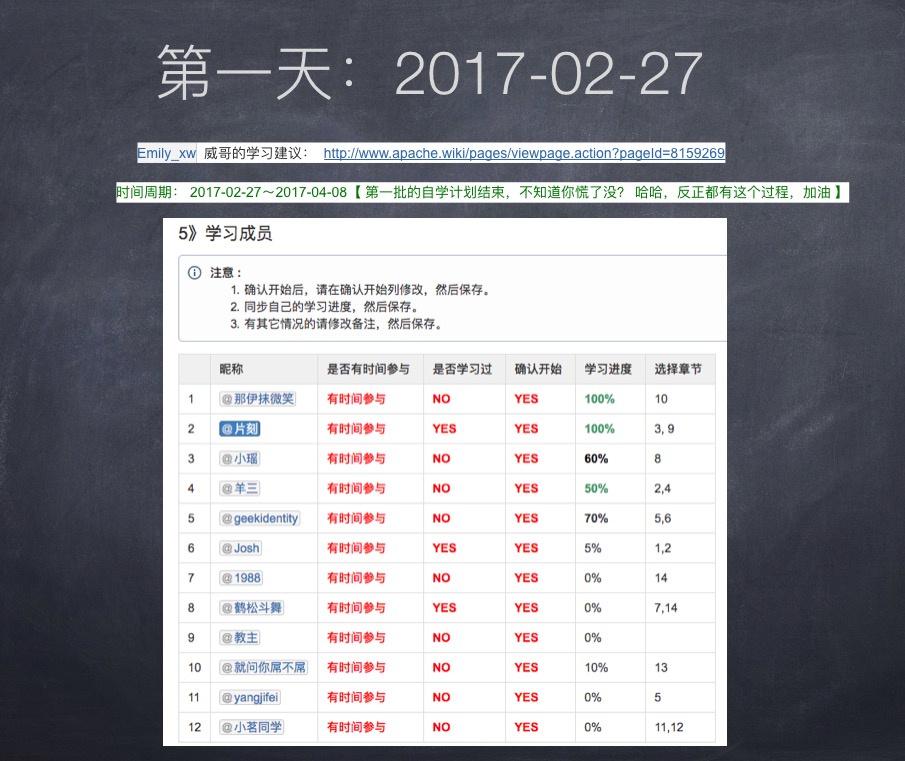
|
||||
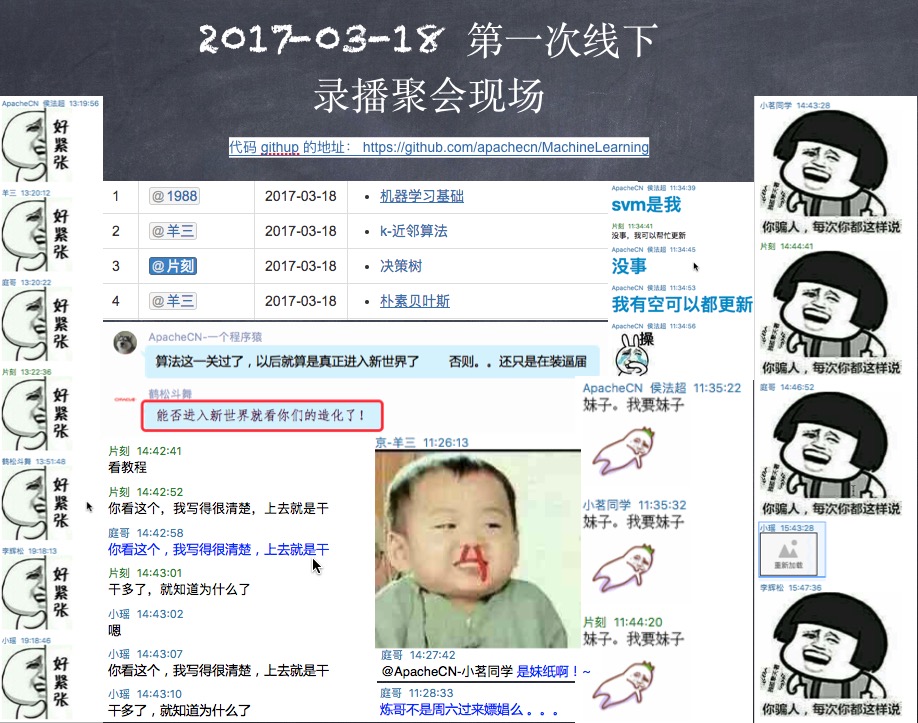
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
|
|
@ -0,0 +1,38 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
import numpy as np
|
||||
|
||||
|
||||
class ReluActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
#return weighted_input
|
||||
return max(0, weighted_input)
|
||||
|
||||
def backward(self, output):
|
||||
return 1 if output > 0 else 0
|
||||
|
||||
|
||||
class IdentityActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return weighted_input
|
||||
|
||||
def backward(self, output):
|
||||
return 1
|
||||
|
||||
|
||||
class SigmoidActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return 1.0 / (1.0 + np.exp(-weighted_input))
|
||||
|
||||
def backward(self, output):
|
||||
return output * (1 - output)
|
||||
|
||||
|
||||
class TanhActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return 2.0 / (1.0 + np.exp(-2 * weighted_input)) - 1.0
|
||||
|
||||
def backward(self, output):
|
||||
return 1 - output * output
|
||||
|
|
@ -0,0 +1,863 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from __future__ import print_function
|
||||
import random
|
||||
from numpy import *
|
||||
|
||||
# sigmoid 函数
|
||||
def sigmoid(inX):
|
||||
'''
|
||||
Desc:
|
||||
sigmoid 函数实现
|
||||
Args:
|
||||
inX --- 输入向量
|
||||
Returns:
|
||||
对输入向量作用 sigmoid 函数之后得到的输出
|
||||
'''
|
||||
return 1.0 / (1 + exp(-inX))
|
||||
|
||||
|
||||
# 定义神经网络的节点类
|
||||
class Node(object):
|
||||
'''
|
||||
Desc:
|
||||
神经网络的节点类
|
||||
'''
|
||||
def __init__(self, layer_index, node_index):
|
||||
'''
|
||||
Desc:
|
||||
初始化一个节点
|
||||
Args:
|
||||
layer_index --- 层的索引,也就是表示第几层
|
||||
node_index --- 节点的索引,也就是表示节点的索引
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 设置节点所在的层的位置
|
||||
self.layer_index = layer_index
|
||||
# 设置层中的节点的索引
|
||||
self.node_index = node_index
|
||||
# 设置此节点的下游节点,也就是这个节点与下一层的哪个节点相连
|
||||
self.downstream = []
|
||||
# 设置此节点的上游节点,也就是哪几个节点的下游节点与此节点相连
|
||||
self.upstream = []
|
||||
# 此节点的输出
|
||||
self.output = 0
|
||||
# 此节点真实值与计算值之间的差值
|
||||
self.delta = 0
|
||||
|
||||
def set_output(self, output):
|
||||
'''
|
||||
Desc:
|
||||
设置节点的 output
|
||||
Args:
|
||||
output --- 节点的 output
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
self.output = output
|
||||
|
||||
def append_downstream_connection(self, conn):
|
||||
'''
|
||||
Desc:
|
||||
添加此节点的下游节点的连接
|
||||
Args:
|
||||
conn --- 当前节点的下游节点的连接的 list
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 使用 list 的 append 方法来将 conn 中的节点添加到 downstream 中
|
||||
self.downstream.append(conn)
|
||||
|
||||
def append_upstream_connection(self, conn):
|
||||
'''
|
||||
Desc:
|
||||
添加此节点的上游节点的连接
|
||||
Args:
|
||||
conn ---- 当前节点的上游节点的连接的 list
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 使用 list 的 append 方法来将 conn 中的节点添加到 upstream 中
|
||||
self.upstream.append(conn)
|
||||
|
||||
def calc_output(self):
|
||||
'''
|
||||
Desc:
|
||||
计算节点的输出,依据 output = sigmoid(wTx)
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 使用 reduce() 函数对其中的因素求和
|
||||
output = reduce(lambda ret, conn: ret + conn.upstream_node.output * conn.weight, self.upstream, 0)
|
||||
# 对上游节点的 output 乘 weights 之后求和得到的结果应用 sigmoid 函数,得到当前节点的 output
|
||||
self.output = sigmoid(output)
|
||||
|
||||
def calc_hidden_layer_delta(self):
|
||||
'''
|
||||
Desc:
|
||||
计算隐藏层的节点的 delta
|
||||
Args:
|
||||
output --- 节点的 output
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 根据 https://www.zybuluo.com/hanbingtao/note/476663 的 式4 计算隐藏层的delta
|
||||
downstream_delta = reduce(lambda ret, conn: ret + conn.downstream_node.delta * conn.weight, self.downstream, 0.0)
|
||||
# 计算此节点的 delta
|
||||
self.delta = self.output * (1 - self.output) * downstream_delta
|
||||
|
||||
def calc_output_layer_delta(self, label):
|
||||
'''
|
||||
Desc:
|
||||
计算输出层的 delta
|
||||
Args:
|
||||
label --- 输入向量对应的真实标签,不是计算得到的结果
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 就是那输出层的 delta
|
||||
self.delta = self.output * (1 - self.output) * (label - self.output)
|
||||
|
||||
def __str__(self):
|
||||
'''
|
||||
Desc:
|
||||
将节点的信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 打印格式:第几层 - 第几个节点,output 是多少,delta 是多少
|
||||
node_str = '%u-%u: output: %f delta: %f' % (self.layer_index, self.node_index, self.output, self.delta)
|
||||
# 下游节点
|
||||
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
|
||||
# 上游节点
|
||||
upstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.upstream, '')
|
||||
# 将本节点 + 下游节点 + 上游节点 的信息打印出来
|
||||
return node_str + '\n\tdownstream:' + downstream_str + '\n\tupstream:' + upstream_str
|
||||
|
||||
|
||||
# ConstNode 对象,为了实现一个输出恒为 1 的节点(计算偏置项 wb 时需要)
|
||||
class ConstNode(object):
|
||||
'''
|
||||
Desc:
|
||||
常数项对象,即相当于计算的时候的偏置项
|
||||
'''
|
||||
def __init__(self, layer_index, node_index):
|
||||
'''
|
||||
Desc:
|
||||
初始化节点对象
|
||||
Args:
|
||||
layer_index --- 节点所属的层的编号
|
||||
node_index --- 节点的编号
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
self.layer_index = layer_index
|
||||
self.node_index = node_index
|
||||
self.downstream = []
|
||||
self.output = 1
|
||||
|
||||
|
||||
def append_downstream_connection(self, conn):
|
||||
'''
|
||||
Desc:
|
||||
添加一个到下游节点的连接
|
||||
Args:
|
||||
conn --- 到下游节点的连接
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 使用 list 的 append 方法将包含下游节点的 conn 添加到 downstream 中
|
||||
self.downstream.append(conn)
|
||||
|
||||
|
||||
def calc_hidden_layer_delta(self):
|
||||
'''
|
||||
Desc:
|
||||
计算隐藏层的 delta
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 使用我们的 公式 4 来计算下游节点的 delta,求和
|
||||
downstream_delta = reduce(lambda ret, conn: ret + conn.downstream_node.delta * conn.weight, self.downstream, 0.0)
|
||||
# 计算隐藏层的本节点的 delta
|
||||
self.delta = self.output * (1 - self.output) * downstream_delta
|
||||
|
||||
|
||||
def __str__(self):
|
||||
'''
|
||||
Desc:
|
||||
将节点信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 将节点的信息打印出来
|
||||
# 格式 第几层-第几个节点的 output
|
||||
node_str = '%u-%u: output: 1' % (self.layer_index, self.node_index)
|
||||
# 此节点的下游节点的信息
|
||||
downstream_str = reduce(lambda ret, conn: ret + '\n\t' + str(conn), self.downstream, '')
|
||||
# 将此节点与下游节点的信息组合,一起打印出来
|
||||
return node_str + '\n\tdownstream:' + downstream_str
|
||||
|
||||
|
||||
# 神经网络的层对象,负责初始化一层。此外,作为 Node 的集合对象,提供对 Node 集合的操作
|
||||
class Layer(object):
|
||||
'''
|
||||
Desc:
|
||||
神经网络的 Layer 类
|
||||
'''
|
||||
|
||||
def __init__(self, layer_index, node_count):
|
||||
'''
|
||||
Desc:
|
||||
神经网络的层对象的初始化
|
||||
Args:
|
||||
layer_index --- 层的索引
|
||||
node_count --- 节点的个数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 设置 层的索引
|
||||
self.layer_index = layer_index
|
||||
# 设置层中的节点的 list
|
||||
self.nodes = []
|
||||
# 将 Node 节点添加到 nodes 中
|
||||
for i in range(node_count):
|
||||
self.nodes.append(Node(layer_index, i))
|
||||
# 将 ConstNode 节点也添加到 nodes 中
|
||||
self.nodes.append(ConstNode(layer_index, node_count))
|
||||
|
||||
def set_output(self, data):
|
||||
'''
|
||||
Desc:
|
||||
设置层的输出,当层是输入层时会用到
|
||||
Args:
|
||||
data --- 输出的值的 list
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 设置输入层中各个节点的 output
|
||||
for i in range(len(data)):
|
||||
self.nodes[i].set_output(data[i])
|
||||
|
||||
def calc_output(self):
|
||||
'''
|
||||
Desc:
|
||||
计算层的输出向量
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 遍历本层的所有节点(除去最后一个节点,因为它是恒为常数的偏置项b)
|
||||
# 调用节点的 calc_output 方法来计算输出向量
|
||||
for node in self.nodes[:-1]:
|
||||
node.calc_output()
|
||||
|
||||
def dump(self):
|
||||
'''
|
||||
Desc:
|
||||
将层信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 遍历层的所有的节点 nodes,将节点信息打印出来
|
||||
for node in self.nodes:
|
||||
print(node)
|
||||
|
||||
|
||||
# Connection 对象类,主要负责记录连接的权重,以及这个连接所关联的上下游的节点
|
||||
class Connection(object):
|
||||
'''
|
||||
Desc:
|
||||
Connection 对象,记录连接权重和连接所关联的上下游节点,注意,这里的 connection 没有 s ,不是复数
|
||||
'''
|
||||
def __init__(self, upstream_node, downstream_node):
|
||||
'''
|
||||
Desc:
|
||||
初始化 Connection 对象
|
||||
Args:
|
||||
upstream_node --- 上游节点
|
||||
downstream_node --- 下游节点
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 设置上游节点
|
||||
self.upstream_node = upstream_node
|
||||
# 设置下游节点
|
||||
self.downstream_node = downstream_node
|
||||
# 设置权重,这里设置的权重是 -0.1 到 0.1 之间的任何数
|
||||
self.weight = random.uniform(-0.1, 0.1)
|
||||
# 设置梯度 为 0.0
|
||||
self.gradient = 0.0
|
||||
|
||||
def calc_gradient(self):
|
||||
'''
|
||||
Desc:
|
||||
计算梯度
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 下游节点的 delta * 上游节点的 output 计算得到梯度
|
||||
self.gradient = self.downstream_node.delta * self.upstream_node.output
|
||||
|
||||
def update_weight(self, rate):
|
||||
'''
|
||||
Desc:
|
||||
根据梯度下降算法更新权重
|
||||
Args:
|
||||
rate --- 学习率 / 或者成为步长
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 调用计算梯度的函数来将梯度计算出来
|
||||
self.calc_gradient()
|
||||
# 使用梯度下降算法来更新权重
|
||||
self.weight += rate * self.gradient
|
||||
|
||||
def get_gradient(self):
|
||||
'''
|
||||
Desc:
|
||||
获取当前的梯度
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
当前的梯度 gradient
|
||||
'''
|
||||
return self.gradient
|
||||
|
||||
def __str__(self):
|
||||
'''
|
||||
Desc:
|
||||
将连接信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
连接信息进行返回
|
||||
'''
|
||||
# 格式为:上游节点的层的索引+上游节点的节点索引 ---> 下游节点的层的索引+下游节点的节点索引,最后一个数是权重
|
||||
return '(%u-%u) -> (%u-%u) = %f' % (
|
||||
self.upstream_node.layer_index,
|
||||
self.upstream_node.node_index,
|
||||
self.downstream_node.layer_index,
|
||||
self.downstream_node.node_index,
|
||||
self.weight)
|
||||
|
||||
|
||||
|
||||
# Connections 对象,提供 Connection 集合操作。
|
||||
class Connections(object):
|
||||
'''
|
||||
Desc:
|
||||
Connections 对象,提供 Connection 集合的操作,看清楚后面有没有 s ,不要看错
|
||||
'''
|
||||
def __init__(self):
|
||||
'''
|
||||
Desc:
|
||||
初始化 Connections 对象
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 初始化一个列表 list
|
||||
self.connections = []
|
||||
|
||||
def add_connection(self, connection):
|
||||
'''
|
||||
Desc:
|
||||
将 connection 中的节点信息 append 到 connections 中
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
self.connections.append(connection)
|
||||
|
||||
def dump(self):
|
||||
'''
|
||||
Desc:
|
||||
将 Connections 的节点信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
for conn in self.connections:
|
||||
print(conn)
|
||||
|
||||
|
||||
# Network 对象,提供相应 API
|
||||
class Network(object):
|
||||
'''
|
||||
Desc:
|
||||
Network 类
|
||||
'''
|
||||
def __init__(self, layers):
|
||||
'''
|
||||
Desc:
|
||||
初始化一个全连接神经网络
|
||||
Args:
|
||||
layers --- 二维数组,描述神经网络的每层节点数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 初始化 connections,使用的是 Connections 对象
|
||||
self.connections = Connections()
|
||||
# 初始化 layers
|
||||
self.layers = []
|
||||
# 我们的神经网络的层数
|
||||
layer_count = len(layers)
|
||||
# 节点数
|
||||
node_count = 0
|
||||
# 遍历所有的层,将每层信息添加到 layers 中去
|
||||
for i in range(layer_count):
|
||||
self.layers.append(Layer(i, layers[i]))
|
||||
# 遍历除去输出层之外的所有层,将连接信息添加到 connections 对象中
|
||||
for layer in range(layer_count - 1):
|
||||
connections = [Connection(upstream_node, downstream_node) for upstream_node in self.layers[layer].nodes for downstream_node in self.layers[layer + 1].nodes[:-1]]
|
||||
# 遍历 connections,将 conn 添加到 connections 中
|
||||
for conn in connections:
|
||||
self.connections.add_connection(conn)
|
||||
# 为下游节点添加上游节点为 conn
|
||||
conn.downstream_node.append_upstream_connection(conn)
|
||||
# 为上游节点添加下游节点为 conn
|
||||
conn.upstream_node.append_downstream_connection(conn)
|
||||
|
||||
|
||||
def train(self, labels, data_set, rate, epoch):
|
||||
'''
|
||||
Desc:
|
||||
训练神经网络
|
||||
Args:
|
||||
labels --- 数组,训练样本标签,每个元素是一个样本的标签
|
||||
data_set --- 二维数组,训练样本的特征数据。每行数据是一个样本的特征
|
||||
rate --- 学习率
|
||||
epoch --- 迭代次数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 循环迭代 epoch 次
|
||||
for i in range(epoch):
|
||||
# 遍历每个训练样本
|
||||
for d in range(len(data_set)):
|
||||
# 使用此样本进行训练(一条样本进行训练)
|
||||
self.train_one_sample(labels[d], data_set[d], rate)
|
||||
# print 'sample %d training finished' % d
|
||||
|
||||
def train_one_sample(self, label, sample, rate):
|
||||
'''
|
||||
Desc:
|
||||
内部函数,使用一个样本对网络进行训练
|
||||
Args:
|
||||
label --- 样本的标签
|
||||
sample --- 样本的特征
|
||||
rate --- 学习率
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 调用 Network 的 predict 方法,对这个样本进行预测
|
||||
self.predict(sample)
|
||||
# 计算根据此样本得到的结果的 delta
|
||||
self.calc_delta(label)
|
||||
# 更新权重
|
||||
self.update_weight(rate)
|
||||
|
||||
def calc_delta(self, label):
|
||||
'''
|
||||
Desc:
|
||||
计算每个节点的 delta
|
||||
Args:
|
||||
label --- 样本的真实值,也就是样本的标签
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 获取输出层的所有节点
|
||||
output_nodes = self.layers[-1].nodes
|
||||
# 遍历所有的 label
|
||||
for i in range(len(label)):
|
||||
# 计算输出层节点的 delta
|
||||
output_nodes[i].calc_output_layer_delta(label[i])
|
||||
# 这个用法就是切片的用法, [-2::-1] 就是将 layers 这个数组倒过来,从没倒过来的时候的倒数第二个元素开始,到翻转过来的倒数第一个数,比如这样:aaa = [1,2,3,4,5,6,7,8,9],bbb = aaa[-2::-1] ==> bbb = [8, 7, 6, 5, 4, 3, 2, 1]
|
||||
# 实际上就是除掉输出层之外的所有层按照相反的顺序进行遍历
|
||||
for layer in self.layers[-2::-1]:
|
||||
# 遍历每层的所有节点
|
||||
for node in layer.nodes:
|
||||
# 计算隐藏层的 delta
|
||||
node.calc_hidden_layer_delta()
|
||||
|
||||
def update_weight(self, rate):
|
||||
'''
|
||||
Desc:
|
||||
更新每个连接的权重
|
||||
Args:
|
||||
rate --- 学习率
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 按照正常顺序遍历除了输出层的层
|
||||
for layer in self.layers[:-1]:
|
||||
# 遍历每层的所有节点
|
||||
for node in layer.nodes:
|
||||
# 遍历节点的下游节点
|
||||
for conn in node.downstream:
|
||||
# 根据下游节点来更新连接的权重
|
||||
conn.update_weight(rate)
|
||||
|
||||
def calc_gradient(self):
|
||||
'''
|
||||
Desc:
|
||||
计算每个连接的梯度
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 按照正常顺序遍历除了输出层之外的层
|
||||
for layer in self.layers[:-1]:
|
||||
# 遍历层中的所有节点
|
||||
for node in layer.nodes:
|
||||
# 遍历节点的下游节点
|
||||
for conn in node.downstream:
|
||||
# 计算梯度
|
||||
conn.calc_gradient()
|
||||
|
||||
def get_gradient(self, label, sample):
|
||||
'''
|
||||
Desc:
|
||||
获得网络在一个样本下,每个连接上的梯度
|
||||
Args:
|
||||
label --- 样本标签
|
||||
sample --- 样本特征
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 调用 predict() 方法,利用样本的特征数据对样本进行预测
|
||||
self.predict(sample)
|
||||
# 计算 delta
|
||||
self.calc_delta(label)
|
||||
# 计算梯度
|
||||
self.calc_gradient()
|
||||
|
||||
def predict(self, sample):
|
||||
'''
|
||||
Desc:
|
||||
根据输入的样本预测输出值
|
||||
Args:
|
||||
sample --- 数组,样本的特征,也就是网络的输入向量
|
||||
Returns:
|
||||
使用我们的感知器规则计算网络的输出
|
||||
'''
|
||||
# 首先为输入层设置输出值output为样本的输入向量,即不发生任何变化
|
||||
self.layers[0].set_output(sample)
|
||||
# 遍历除去输入层开始到最后一层
|
||||
for i in range(1, len(self.layers)):
|
||||
# 计算 output
|
||||
self.layers[i].calc_output()
|
||||
# 将计算得到的输出,也就是我们的预测值返回
|
||||
return map(lambda node: node.output, self.layers[-1].nodes[:-1])
|
||||
|
||||
def dump(self):
|
||||
'''
|
||||
Desc:
|
||||
打印出我们的网络信息
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 遍历所有的 layers
|
||||
for layer in self.layers:
|
||||
# 将所有的层的信息打印出来
|
||||
layer.dump()
|
||||
|
||||
|
||||
# # ------------------------- 至此,基本上我们把 我们的神经网络实现完成,下面还会介绍一下对应的梯度检查相关的算法,现在我们首先回顾一下我们上面写道的类及他们的作用 ------------------------
|
||||
'''
|
||||
1、节点类的实现 Node :负责记录和维护节点自身信息以及这个节点相关的上下游连接,实现输出值和误差项的计算。如下:
|
||||
layer_index --- 节点所属的层的编号
|
||||
node_index --- 节点的编号
|
||||
downstream --- 下游节点
|
||||
upstream ---- 上游节点
|
||||
output ---- 节点的输出值
|
||||
delta ------ 节点的误差项
|
||||
|
||||
2、ConstNode 类,偏置项类的实现:实现一个输出恒为 1 的节点(计算偏置项的时候会用到),如下:
|
||||
layer_index --- 节点所属层的编号
|
||||
node_index ---- 节点的编号
|
||||
downstream ---- 下游节点
|
||||
没有记录上游节点,因为一个偏置项的输出与上游节点的输出无关
|
||||
output ----- 偏置项的输出
|
||||
|
||||
3、layer 类,负责初始化一层。作为的是 Node 节点的集合对象,提供对 Node 集合的操作。也就是说,layer 包含的是 Node 的集合。
|
||||
layer_index ---- 层的编号
|
||||
node_count ----- 层所包含的节点的个数
|
||||
def set_ouput() -- 设置层的输出,当层是输入层时会用到
|
||||
def calc_output -- 计算层的输出向量,调用的 Node 类的 计算输出 方法
|
||||
|
||||
4、Connection 类:负责记录连接的权重,以及这个连接所关联的上下游节点,如下:
|
||||
upstream_node --- 连接的上游节点
|
||||
downstream_node -- 连接的下游节点
|
||||
weight -------- random.uniform(-0.1, 0.1) 初始化为一个很小的随机数
|
||||
gradient -------- 0.0 梯度,初始化为 0.0
|
||||
def calc_gradient() --- 计算梯度,使用的是下游节点的 delta 与上游节点的 output 相乘计算得到
|
||||
def get_gradient() ---- 获取当前的梯度
|
||||
def update_weight() --- 根据梯度下降算法更新权重
|
||||
|
||||
5、Connections 类:提供对 Connection 集合操作,如下:
|
||||
def add_connection() --- 添加一个 connection
|
||||
|
||||
6、Network 类:提供相应的 API,如下:
|
||||
connections --- Connections 对象
|
||||
layers -------- 神经网络的层
|
||||
layer_count --- 神经网络的层数
|
||||
node_count --- 节点个数
|
||||
def train() --- 训练神经网络
|
||||
def train_one_sample() --- 用一个样本训练网络
|
||||
def calc_delta() --- 计算误差项
|
||||
def update_weight() --- 更新每个连接权重
|
||||
def calc_gradient() --- 计算每个连接的梯度
|
||||
def get_gradient() --- 获得网络在一个样本下,每个连接上的梯度
|
||||
def predict() --- 根据输入的样本预测输出值
|
||||
'''
|
||||
|
||||
# #--------------------------------------回顾完成了,有些问题可能还是没有弄懂,没事,我们接着看下面---------------------------------------------
|
||||
|
||||
class Normalizer(object):
|
||||
'''
|
||||
Desc:
|
||||
归一化工具类
|
||||
Args:
|
||||
object --- 对象
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
def __init__(self):
|
||||
'''
|
||||
Desc:
|
||||
初始化
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 初始化 16 进制的数,用来判断位的,分别是
|
||||
# 0x1 ---- 00000001
|
||||
# 0x2 ---- 00000010
|
||||
# 0x4 ---- 00000100
|
||||
# 0x8 ---- 00001000
|
||||
# 0x10 --- 00010000
|
||||
# 0x20 --- 00100000
|
||||
# 0x40 --- 01000000
|
||||
# 0x80 --- 10000000
|
||||
self.mask = [0x1, 0x2, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80]
|
||||
|
||||
def norm(self, number):
|
||||
'''
|
||||
Desc:
|
||||
对 number 进行规范化
|
||||
Args:
|
||||
number --- 要规范化的数据
|
||||
Returns:
|
||||
规范化之后的数据
|
||||
'''
|
||||
# 此方法就相当于判断一个 8 位的向量,哪一位上有数字,如果有就将这个数设置为 0.9 ,否则,设置为 0.1,通俗比较来说,就是我们这里用 0.9 表示 1,用 0.1 表示 0
|
||||
return map(lambda m: 0.9 if number & m else 0.1, self.mask)
|
||||
|
||||
def denorm(self, vec):
|
||||
'''
|
||||
Desc:
|
||||
对我们得到的向量进行反规范化
|
||||
Args:
|
||||
vec --- 得到的向量
|
||||
Returns:
|
||||
最终的预测结果
|
||||
'''
|
||||
# 进行二分类,大于 0.5 就设置为 1,小于 0.5 就设置为 0
|
||||
binary = map(lambda i: 1 if i > 0.5 else 0, vec)
|
||||
# 遍历 mask
|
||||
for i in range(len(self.mask)):
|
||||
binary[i] = binary[i] * self.mask[i]
|
||||
# 将结果相加得到最终的预测结果
|
||||
return reduce(lambda x,y: x + y, binary)
|
||||
|
||||
|
||||
def mean_square_error(vec1, vec2):
|
||||
'''
|
||||
Desc:
|
||||
计算平均平方误差
|
||||
Args:
|
||||
vec1 --- 第一个数
|
||||
vec2 --- 第二个数
|
||||
Returns:
|
||||
返回 1/2 * (x-y)^2 计算得到的值
|
||||
'''
|
||||
return 0.5 * reduce(lambda a, b: a + b, map(lambda v: (v[0] - v[1]) * (v[0] - v[1]), zip(vec1, vec2)))
|
||||
|
||||
|
||||
|
||||
def gradient_check(network, sample_feature, sample_label):
|
||||
'''
|
||||
Desc:
|
||||
梯度检查
|
||||
Args:
|
||||
network --- 神经网络对象
|
||||
sample_feature --- 样本的特征
|
||||
sample_label --- 样本的标签
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 计算网络误差
|
||||
network_error = lambda vec1, vec2: 0.5 * reduce(lambda a, b: a + b, map(lambda v: (v[0] - v[1]) * (v[0] - v[1]), zip(vec1, vec2)))
|
||||
|
||||
# 获取网络在当前样本下每个连接的梯度
|
||||
network.get_gradient(sample_feature, sample_label)
|
||||
|
||||
# 对每个权重做梯度检查
|
||||
for conn in network.connections.connections:
|
||||
# 获取指定连接的梯度
|
||||
actual_gradient = conn.get_gradient()
|
||||
|
||||
# 增加一个很小的值,计算网络的误差
|
||||
epsilon = 0.0001
|
||||
conn.weight += epsilon
|
||||
error1 = network_error(network.predict(sample_feature), sample_label)
|
||||
|
||||
# 减去一个很小的值,计算网络的误差
|
||||
conn.weight -= 2 * epsilon # 刚才加过了一次,因此这里需要减去2倍
|
||||
error2 = network_error(network.predict(sample_feature), sample_label)
|
||||
|
||||
# 根据式6计算期望的梯度值
|
||||
expected_gradient = (error2 - error1) / (2 * epsilon)
|
||||
|
||||
# 打印
|
||||
print('expected gradient: \t%f\nactual gradient: \t%f' % (expected_gradient, actual_gradient))
|
||||
|
||||
|
||||
def train_data_set():
|
||||
'''
|
||||
Desc:
|
||||
获取训练数据集
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
labels --- 训练数据集每条数据对应的标签
|
||||
'''
|
||||
# 调用 Normalizer() 类
|
||||
normalizer = Normalizer()
|
||||
# 初始化一个 list,用来存储后面的数据
|
||||
data_set = []
|
||||
labels = []
|
||||
# 0 到 256 ,其中以 8 为步长
|
||||
for i in range(0, 256, 8):
|
||||
# 调用 normalizer 对象的 norm 方法
|
||||
n = normalizer.norm(int(random.uniform(0, 256)))
|
||||
# 在 data_set 中 append n
|
||||
data_set.append(n)
|
||||
# 在 labels 中 append n
|
||||
labels.append(n)
|
||||
# 将它们返回
|
||||
return labels, data_set
|
||||
|
||||
|
||||
def train(network):
|
||||
'''
|
||||
Desc:
|
||||
使用我们的神经网络进行训练
|
||||
Args:
|
||||
network --- 神经网络对象
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 获取训练数据集
|
||||
labels, data_set = train_data_set()
|
||||
# 调用 network 中的 train方法来训练我们的神经网络
|
||||
network.train(labels, data_set, 0.3, 50)
|
||||
|
||||
|
||||
def test(network, data):
|
||||
'''
|
||||
Desc:
|
||||
对我们的全连接神经网络进行测试
|
||||
Args:
|
||||
network --- 神经网络对象
|
||||
data ------ 测试数据集
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 调用 Normalizer() 类
|
||||
normalizer = Normalizer()
|
||||
# 调用 norm 方法,对数据进行规范化
|
||||
norm_data = normalizer.norm(data)
|
||||
# 对测试数据进行预测
|
||||
predict_data = network.predict(norm_data)
|
||||
# 将结果打印出来
|
||||
print('\ttestdata(%u)\tpredict(%u)' % (data, normalizer.denorm(predict_data)))
|
||||
|
||||
|
||||
def correct_ratio(network):
|
||||
'''
|
||||
Desc:
|
||||
计算我们的神经网络的正确率
|
||||
Args:
|
||||
network --- 神经网络对象
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
normalizer = Normalizer()
|
||||
correct = 0.0
|
||||
for i in range(256):
|
||||
if normalizer.denorm(network.predict(normalizer.norm(i))) == i:
|
||||
correct += 1.0
|
||||
print('correct_ratio: %.2f%%' % (correct / 256 * 100))
|
||||
|
||||
|
||||
def gradient_check_test():
|
||||
'''
|
||||
Desc:
|
||||
梯度检查测试
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 创建一个有 3 层的网络,每层有 2 个节点
|
||||
net = Network([2, 2, 2])
|
||||
# 样本的特征
|
||||
sample_feature = [0.9, 0.1]
|
||||
# 样本对应的标签
|
||||
sample_label = [0.9, 0.1]
|
||||
# 使用梯度检查来查看是否正确
|
||||
gradient_check(net, sample_feature, sample_label)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
'''
|
||||
Desc:
|
||||
主函数
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 初始化一个神经网络,输入层 8 个节点,隐藏层 3 个节点,输出层 8 个节点
|
||||
net = Network([8, 3, 8])
|
||||
# 训练我们的神经网络
|
||||
train(net)
|
||||
# 将我们的神经网络的信息打印出来
|
||||
net.dump()
|
||||
# 打印出神经网络的正确率
|
||||
correct_ratio(net)
|
||||
|
|
@ -0,0 +1,466 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
from __future__ import print_function
|
||||
import numpy as np
|
||||
from activators import ReluActivator, IdentityActivator
|
||||
|
||||
|
||||
# 获取卷积区域
|
||||
def get_patch(input_array, i, j, filter_width,
|
||||
filter_height, stride):
|
||||
'''
|
||||
从输入数组中获取本次卷积的区域,
|
||||
自动适配输入为2D和3D的情况
|
||||
'''
|
||||
start_i = i * stride
|
||||
start_j = j * stride
|
||||
if input_array.ndim == 2:
|
||||
return input_array[
|
||||
start_i : start_i + filter_height,
|
||||
start_j : start_j + filter_width]
|
||||
elif input_array.ndim == 3:
|
||||
return input_array[:,
|
||||
start_i : start_i + filter_height,
|
||||
start_j : start_j + filter_width]
|
||||
|
||||
|
||||
# 获取一个2D区域的最大值所在的索引
|
||||
def get_max_index(array):
|
||||
max_i = 0
|
||||
max_j = 0
|
||||
max_value = array[0,0]
|
||||
for i in range(array.shape[0]):
|
||||
for j in range(array.shape[1]):
|
||||
if array[i,j] > max_value:
|
||||
max_value = array[i,j]
|
||||
max_i, max_j = i, j
|
||||
return max_i, max_j
|
||||
|
||||
|
||||
# 计算卷积
|
||||
def conv(input_array,
|
||||
kernel_array,
|
||||
output_array,
|
||||
stride, bias):
|
||||
'''
|
||||
计算卷积,自动适配输入为2D和3D的情况
|
||||
conv函数实现了2维和3维数组的卷积
|
||||
'''
|
||||
channel_number = input_array.ndim
|
||||
output_width = output_array.shape[1]
|
||||
output_height = output_array.shape[0]
|
||||
kernel_width = kernel_array.shape[-1]
|
||||
kernel_height = kernel_array.shape[-2]
|
||||
for i in range(output_height):
|
||||
for j in range(output_width):
|
||||
output_array[i][j] = (
|
||||
get_patch(input_array, i, j, kernel_width,
|
||||
kernel_height, stride) * kernel_array
|
||||
).sum() + bias
|
||||
|
||||
|
||||
# 为数组增加Zero padding
|
||||
def padding(input_array, zp):
|
||||
'''
|
||||
为数组增加Zero padding,自动适配输入为2D和3D的情况
|
||||
'''
|
||||
if zp == 0:
|
||||
return input_array
|
||||
else:
|
||||
if input_array.ndim == 3:
|
||||
input_width = input_array.shape[2]
|
||||
input_height = input_array.shape[1]
|
||||
input_depth = input_array.shape[0]
|
||||
padded_array = np.zeros((
|
||||
input_depth,
|
||||
input_height + 2 * zp,
|
||||
input_width + 2 * zp))
|
||||
padded_array[:,
|
||||
zp : zp + input_height,
|
||||
zp : zp + input_width] = input_array
|
||||
return padded_array
|
||||
elif input_array.ndim == 2:
|
||||
input_width = input_array.shape[1]
|
||||
input_height = input_array.shape[0]
|
||||
padded_array = np.zeros((
|
||||
input_height + 2 * zp,
|
||||
input_width + 2 * zp))
|
||||
padded_array[zp : zp + input_height,
|
||||
zp : zp + input_width] = input_array
|
||||
return padded_array
|
||||
|
||||
|
||||
# 对numpy数组进行element wise操作
|
||||
def element_wise_op(array, op):
|
||||
'''
|
||||
Desc:
|
||||
element_wise_op函数实现了对numpy数组进行按元素操作,并将返回值写回到数组中
|
||||
'''
|
||||
for i in np.nditer(array,
|
||||
op_flags=['readwrite']):
|
||||
i[...] = op(i)
|
||||
|
||||
|
||||
class Filter(object):
|
||||
'''
|
||||
Desc:
|
||||
Filter类保存了卷积层的参数以及梯度,并且实现了用梯度下降算法来更新参数。
|
||||
我们对参数的初始化采用了常用的策略,即:权重随机初始化为一个很小的值,而偏置项初始化为0。
|
||||
'''
|
||||
def __init__(self, width, height, depth):
|
||||
self.weights = np.random.uniform(-1e-4, 1e-4,
|
||||
(depth, height, width))
|
||||
self.bias = 0
|
||||
self.weights_grad = np.zeros(
|
||||
self.weights.shape)
|
||||
self.bias_grad = 0
|
||||
|
||||
def __repr__(self):
|
||||
return 'filter weights:\n%s\nbias:\n%s' % (
|
||||
repr(self.weights), repr(self.bias))
|
||||
|
||||
def get_weights(self):
|
||||
return self.weights
|
||||
|
||||
def get_bias(self):
|
||||
return self.bias
|
||||
|
||||
def update(self, learning_rate):
|
||||
self.weights -= learning_rate * self.weights_grad
|
||||
self.bias -= learning_rate * self.bias_grad
|
||||
|
||||
|
||||
class ConvLayer(object):
|
||||
'''
|
||||
Desc:
|
||||
用ConvLayer类来实现一个卷积层。下面的代码是初始化一个卷积层,可以在构造函数中设置卷积层的超参数。
|
||||
'''
|
||||
def __init__(self, input_width, input_height,
|
||||
channel_number, filter_width,
|
||||
filter_height, filter_number,
|
||||
zero_padding, stride, activator,
|
||||
learning_rate):
|
||||
self.input_width = input_width
|
||||
self.input_height = input_height
|
||||
self.channel_number = channel_number
|
||||
self.filter_width = filter_width
|
||||
self.filter_height = filter_height
|
||||
self.filter_number = filter_number
|
||||
self.zero_padding = zero_padding
|
||||
self.stride = stride
|
||||
self.output_width = \
|
||||
ConvLayer.calculate_output_size(
|
||||
self.input_width, filter_width, zero_padding,
|
||||
stride)
|
||||
self.output_height = \
|
||||
ConvLayer.calculate_output_size(
|
||||
self.input_height, filter_height, zero_padding,
|
||||
stride)
|
||||
self.output_array = np.zeros((self.filter_number,
|
||||
self.output_height, self.output_width))
|
||||
self.filters = []
|
||||
for i in range(filter_number):
|
||||
self.filters.append(Filter(filter_width,
|
||||
filter_height, self.channel_number))
|
||||
self.activator = activator
|
||||
self.learning_rate = learning_rate
|
||||
|
||||
def forward(self, input_array):
|
||||
'''
|
||||
Desc:
|
||||
计算卷积层的输出,输出结果保存在 self.output_array
|
||||
ConvLayer 类的 forward 方法实现了卷积层的前向计算(即计算根据输入来计算卷积层的输出)
|
||||
'''
|
||||
self.input_array = input_array
|
||||
self.padded_input_array = padding(input_array,
|
||||
self.zero_padding)
|
||||
for f in range(self.filter_number):
|
||||
filter = self.filters[f]
|
||||
conv(self.padded_input_array,
|
||||
filter.get_weights(), self.output_array[f],
|
||||
self.stride, filter.get_bias())
|
||||
element_wise_op(self.output_array,
|
||||
self.activator.forward)
|
||||
|
||||
def backward(self, input_array, sensitivity_array,
|
||||
activator):
|
||||
'''
|
||||
计算传递给前一层的误差项,以及计算每个权重的梯度
|
||||
前一层的误差项保存在self.delta_array
|
||||
梯度保存在Filter对象的weights_grad
|
||||
'''
|
||||
self.forward(input_array)
|
||||
self.bp_sensitivity_map(sensitivity_array,
|
||||
activator)
|
||||
self.bp_gradient(sensitivity_array)
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
按照梯度下降,更新权重
|
||||
'''
|
||||
for filter in self.filters:
|
||||
filter.update(self.learning_rate)
|
||||
|
||||
def bp_sensitivity_map(self, sensitivity_array,
|
||||
activator):
|
||||
'''
|
||||
计算传递到上一层的sensitivity map
|
||||
sensitivity_array: 本层的sensitivity map
|
||||
activator: 上一层的激活函数
|
||||
'''
|
||||
# 处理卷积步长,对原始sensitivity map进行扩展
|
||||
expanded_array = self.expand_sensitivity_map(
|
||||
sensitivity_array)
|
||||
# full卷积,对sensitivitiy map进行zero padding
|
||||
# 虽然原始输入的zero padding单元也会获得残差
|
||||
# 但这个残差不需要继续向上传递,因此就不计算了
|
||||
expanded_width = expanded_array.shape[2]
|
||||
zp = (self.input_width +
|
||||
self.filter_width - 1 - expanded_width) / 2
|
||||
padded_array = padding(expanded_array, zp)
|
||||
# 初始化delta_array,用于保存传递到上一层的
|
||||
# sensitivity map
|
||||
self.delta_array = self.create_delta_array()
|
||||
# 对于具有多个filter的卷积层来说,最终传递到上一层的
|
||||
# sensitivity map相当于所有的filter的
|
||||
# sensitivity map之和
|
||||
for f in range(self.filter_number):
|
||||
filter = self.filters[f]
|
||||
# 将filter权重翻转180度
|
||||
flipped_weights = np.array(map(
|
||||
lambda i: np.rot90(i, 2),
|
||||
filter.get_weights()))
|
||||
# 计算与一个filter对应的delta_array
|
||||
delta_array = self.create_delta_array()
|
||||
for d in range(delta_array.shape[0]):
|
||||
conv(padded_array[f], flipped_weights[d],
|
||||
delta_array[d], 1, 0)
|
||||
self.delta_array += delta_array
|
||||
# 将计算结果与激活函数的偏导数做element-wise乘法操作
|
||||
derivative_array = np.array(self.input_array)
|
||||
element_wise_op(derivative_array,
|
||||
activator.backward)
|
||||
self.delta_array *= derivative_array
|
||||
|
||||
def bp_gradient(self, sensitivity_array):
|
||||
# 处理卷积步长,对原始sensitivity map进行扩展
|
||||
expanded_array = self.expand_sensitivity_map(
|
||||
sensitivity_array)
|
||||
for f in range(self.filter_number):
|
||||
# 计算每个权重的梯度
|
||||
filter = self.filters[f]
|
||||
for d in range(filter.weights.shape[0]):
|
||||
conv(self.padded_input_array[d],
|
||||
expanded_array[f],
|
||||
filter.weights_grad[d], 1, 0)
|
||||
# 计算偏置项的梯度
|
||||
filter.bias_grad = expanded_array[f].sum()
|
||||
|
||||
def expand_sensitivity_map(self, sensitivity_array):
|
||||
depth = sensitivity_array.shape[0]
|
||||
# 确定扩展后sensitivity map的大小
|
||||
# 计算stride为1时sensitivity map的大小
|
||||
expanded_width = (self.input_width -
|
||||
self.filter_width + 2 * self.zero_padding + 1)
|
||||
expanded_height = (self.input_height -
|
||||
self.filter_height + 2 * self.zero_padding + 1)
|
||||
# 构建新的sensitivity_map
|
||||
expand_array = np.zeros((depth, expanded_height,
|
||||
expanded_width))
|
||||
# 从原始sensitivity map拷贝误差值
|
||||
for i in range(self.output_height):
|
||||
for j in range(self.output_width):
|
||||
i_pos = i * self.stride
|
||||
j_pos = j * self.stride
|
||||
expand_array[:,i_pos,j_pos] = \
|
||||
sensitivity_array[:,i,j]
|
||||
return expand_array
|
||||
|
||||
def create_delta_array(self):
|
||||
return np.zeros((self.channel_number,
|
||||
self.input_height, self.input_width))
|
||||
|
||||
@staticmethod
|
||||
def calculate_output_size(input_size, filter_size, zero_padding, stride):
|
||||
'''
|
||||
Desc:
|
||||
用来确定卷积层输出的大小
|
||||
'''
|
||||
return (input_size - filter_size +
|
||||
2 * zero_padding) / stride + 1
|
||||
|
||||
|
||||
class MaxPoolingLayer(object):
|
||||
def __init__(self, input_width, input_height,
|
||||
channel_number, filter_width,
|
||||
filter_height, stride):
|
||||
self.input_width = input_width
|
||||
self.input_height = input_height
|
||||
self.channel_number = channel_number
|
||||
self.filter_width = filter_width
|
||||
self.filter_height = filter_height
|
||||
self.stride = stride
|
||||
self.output_width = (input_width -
|
||||
filter_width) / self.stride + 1
|
||||
self.output_height = (input_height -
|
||||
filter_height) / self.stride + 1
|
||||
self.output_array = np.zeros((self.channel_number,
|
||||
self.output_height, self.output_width))
|
||||
|
||||
def forward(self, input_array):
|
||||
for d in range(self.channel_number):
|
||||
for i in range(self.output_height):
|
||||
for j in range(self.output_width):
|
||||
self.output_array[d,i,j] = (
|
||||
get_patch(input_array[d], i, j,
|
||||
self.filter_width,
|
||||
self.filter_height,
|
||||
self.stride).max())
|
||||
|
||||
def backward(self, input_array, sensitivity_array):
|
||||
self.delta_array = np.zeros(input_array.shape)
|
||||
for d in range(self.channel_number):
|
||||
for i in range(self.output_height):
|
||||
for j in range(self.output_width):
|
||||
patch_array = get_patch(
|
||||
input_array[d], i, j,
|
||||
self.filter_width,
|
||||
self.filter_height,
|
||||
self.stride)
|
||||
k, l = get_max_index(patch_array)
|
||||
self.delta_array[d,
|
||||
i * self.stride + k,
|
||||
j * self.stride + l] = \
|
||||
sensitivity_array[d,i,j]
|
||||
|
||||
|
||||
def init_test():
|
||||
a = np.array(
|
||||
[[[0,1,1,0,2],
|
||||
[2,2,2,2,1],
|
||||
[1,0,0,2,0],
|
||||
[0,1,1,0,0],
|
||||
[1,2,0,0,2]],
|
||||
[[1,0,2,2,0],
|
||||
[0,0,0,2,0],
|
||||
[1,2,1,2,1],
|
||||
[1,0,0,0,0],
|
||||
[1,2,1,1,1]],
|
||||
[[2,1,2,0,0],
|
||||
[1,0,0,1,0],
|
||||
[0,2,1,0,1],
|
||||
[0,1,2,2,2],
|
||||
[2,1,0,0,1]]])
|
||||
b = np.array(
|
||||
[[[0,1,1],
|
||||
[2,2,2],
|
||||
[1,0,0]],
|
||||
[[1,0,2],
|
||||
[0,0,0],
|
||||
[1,2,1]]])
|
||||
cl = ConvLayer(5,5,3,3,3,2,1,2,IdentityActivator(),0.001)
|
||||
cl.filters[0].weights = np.array(
|
||||
[[[-1,1,0],
|
||||
[0,1,0],
|
||||
[0,1,1]],
|
||||
[[-1,-1,0],
|
||||
[0,0,0],
|
||||
[0,-1,0]],
|
||||
[[0,0,-1],
|
||||
[0,1,0],
|
||||
[1,-1,-1]]], dtype=np.float64)
|
||||
cl.filters[0].bias=1
|
||||
cl.filters[1].weights = np.array(
|
||||
[[[1,1,-1],
|
||||
[-1,-1,1],
|
||||
[0,-1,1]],
|
||||
[[0,1,0],
|
||||
[-1,0,-1],
|
||||
[-1,1,0]],
|
||||
[[-1,0,0],
|
||||
[-1,0,1],
|
||||
[-1,0,0]]], dtype=np.float64)
|
||||
return a, b, cl
|
||||
|
||||
|
||||
def test():
|
||||
a, b, cl = init_test()
|
||||
cl.forward(a)
|
||||
print(cl.output_array)
|
||||
|
||||
def test_bp():
|
||||
a, b, cl = init_test()
|
||||
cl.backward(a, b, IdentityActivator())
|
||||
cl.update()
|
||||
print(cl.filters[0])
|
||||
print(cl.filters[1])
|
||||
|
||||
|
||||
def gradient_check():
|
||||
'''
|
||||
梯度检查
|
||||
'''
|
||||
# 设计一个误差函数,取所有节点输出项之和
|
||||
error_function = lambda o: o.sum()
|
||||
|
||||
# 计算forward值
|
||||
a, b, cl = init_test()
|
||||
cl.forward(a)
|
||||
|
||||
# 求取sensitivity map
|
||||
sensitivity_array = np.ones(cl.output_array.shape,
|
||||
dtype=np.float64)
|
||||
# 计算梯度
|
||||
cl.backward(a, sensitivity_array,
|
||||
IdentityActivator())
|
||||
# 检查梯度
|
||||
epsilon = 10e-4
|
||||
for d in range(cl.filters[0].weights_grad.shape[0]):
|
||||
for i in range(cl.filters[0].weights_grad.shape[1]):
|
||||
for j in range(cl.filters[0].weights_grad.shape[2]):
|
||||
cl.filters[0].weights[d,i,j] += epsilon
|
||||
cl.forward(a)
|
||||
err1 = error_function(cl.output_array)
|
||||
cl.filters[0].weights[d,i,j] -= 2*epsilon
|
||||
cl.forward(a)
|
||||
err2 = error_function(cl.output_array)
|
||||
expect_grad = (err1 - err2) / (2 * epsilon)
|
||||
cl.filters[0].weights[d,i,j] += epsilon
|
||||
print('weights(%d,%d,%d): expected - actural %f - %f' % (
|
||||
d, i, j, expect_grad, cl.filters[0].weights_grad[d,i,j]))
|
||||
|
||||
|
||||
def init_pool_test():
|
||||
a = np.array(
|
||||
[[[1,1,2,4],
|
||||
[5,6,7,8],
|
||||
[3,2,1,0],
|
||||
[1,2,3,4]],
|
||||
[[0,1,2,3],
|
||||
[4,5,6,7],
|
||||
[8,9,0,1],
|
||||
[3,4,5,6]]], dtype=np.float64)
|
||||
|
||||
b = np.array(
|
||||
[[[1,2],
|
||||
[2,4]],
|
||||
[[3,5],
|
||||
[8,2]]], dtype=np.float64)
|
||||
|
||||
mpl = MaxPoolingLayer(4,4,2,2,2,2)
|
||||
|
||||
return a, b, mpl
|
||||
|
||||
|
||||
def test_pool():
|
||||
a, b, mpl = init_pool_test()
|
||||
mpl.forward(a)
|
||||
print('input array:\n%s\noutput array:\n%s' % (a, mpl.output_array))
|
||||
|
||||
|
||||
def test_pool_bp():
|
||||
a, b, mpl = init_pool_test()
|
||||
mpl.backward(a, b)
|
||||
print('input array:\n%s\nsensitivity array:\n%s\ndelta array:\n%s' % (a, b, mpl.delta_array))
|
||||
|
|
@ -0,0 +1,232 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
from __future__ import print_function
|
||||
import random
|
||||
import numpy as np
|
||||
from activators import SigmoidActivator, IdentityActivator
|
||||
|
||||
try:
|
||||
reduce # Python 2
|
||||
except NameError: # Python 3
|
||||
from functools import reduce
|
||||
|
||||
|
||||
# 全连接层实现类
|
||||
class FullConnectedLayer(object):
|
||||
def __init__(self, input_size, output_size,
|
||||
activator):
|
||||
'''
|
||||
构造函数
|
||||
input_size: 本层输入向量的维度
|
||||
output_size: 本层输出向量的维度
|
||||
activator: 激活函数
|
||||
'''
|
||||
self.input_size = input_size
|
||||
self.output_size = output_size
|
||||
self.activator = activator
|
||||
# 权重数组W
|
||||
self.W = np.random.uniform(-0.1, 0.1,
|
||||
(output_size, input_size))
|
||||
# 偏置项b
|
||||
self.b = np.zeros((output_size, 1))
|
||||
# 输出向量
|
||||
self.output = np.zeros((output_size, 1))
|
||||
|
||||
def forward(self, input_array):
|
||||
'''
|
||||
前向计算
|
||||
input_array: 输入向量,维度必须等于input_size
|
||||
'''
|
||||
# 式2
|
||||
self.input = input_array
|
||||
self.output = self.activator.forward(
|
||||
np.dot(self.W, input_array) + self.b)
|
||||
|
||||
def backward(self, delta_array):
|
||||
'''
|
||||
反向计算W和b的梯度
|
||||
delta_array: 从上一层传递过来的误差项
|
||||
'''
|
||||
# 式8
|
||||
self.delta = self.activator.backward(self.input) * np.dot(
|
||||
self.W.T, delta_array)
|
||||
self.W_grad = np.dot(delta_array, self.input.T)
|
||||
self.b_grad = delta_array
|
||||
|
||||
def update(self, learning_rate):
|
||||
'''
|
||||
使用梯度下降算法更新权重
|
||||
'''
|
||||
self.W += learning_rate * self.W_grad
|
||||
self.b += learning_rate * self.b_grad
|
||||
|
||||
def dump(self):
|
||||
print('W: %s\nb:%s' % (self.W, self.b))
|
||||
|
||||
|
||||
# 神经网络类
|
||||
class Network(object):
|
||||
def __init__(self, layers):
|
||||
'''
|
||||
构造函数
|
||||
'''
|
||||
self.layers = []
|
||||
for i in range(len(layers) - 1):
|
||||
self.layers.append(
|
||||
FullConnectedLayer(
|
||||
layers[i], layers[i+1],
|
||||
SigmoidActivator()
|
||||
)
|
||||
)
|
||||
|
||||
def predict(self, sample):
|
||||
'''
|
||||
使用神经网络实现预测
|
||||
sample: 输入样本
|
||||
'''
|
||||
output = sample
|
||||
for layer in self.layers:
|
||||
layer.forward(output)
|
||||
output = layer.output
|
||||
return output
|
||||
|
||||
def train(self, labels, data_set, rate, epoch):
|
||||
'''
|
||||
训练函数
|
||||
labels: 样本标签
|
||||
data_set: 输入样本
|
||||
rate: 学习速率
|
||||
epoch: 训练轮数
|
||||
'''
|
||||
for i in range(epoch):
|
||||
for d in range(len(data_set)):
|
||||
self.train_one_sample(labels[d],
|
||||
data_set[d], rate)
|
||||
|
||||
def train_one_sample(self, label, sample, rate):
|
||||
self.predict(sample)
|
||||
self.calc_gradient(label)
|
||||
self.update_weight(rate)
|
||||
|
||||
def calc_gradient(self, label):
|
||||
delta = self.layers[-1].activator.backward(
|
||||
self.layers[-1].output
|
||||
) * (label - self.layers[-1].output)
|
||||
for layer in self.layers[::-1]:
|
||||
layer.backward(delta)
|
||||
delta = layer.delta
|
||||
return delta
|
||||
|
||||
def update_weight(self, rate):
|
||||
for layer in self.layers:
|
||||
layer.update(rate)
|
||||
|
||||
def dump(self):
|
||||
for layer in self.layers:
|
||||
layer.dump()
|
||||
|
||||
def loss(self, output, label):
|
||||
return 0.5 * ((label - output) * (label - output)).sum()
|
||||
|
||||
def gradient_check(self, sample_feature, sample_label):
|
||||
'''
|
||||
梯度检查
|
||||
network: 神经网络对象
|
||||
sample_feature: 样本的特征
|
||||
sample_label: 样本的标签
|
||||
'''
|
||||
|
||||
# 获取网络在当前样本下每个连接的梯度
|
||||
self.predict(sample_feature)
|
||||
self.calc_gradient(sample_label)
|
||||
|
||||
# 检查梯度
|
||||
epsilon = 10e-4
|
||||
for fc in self.layers:
|
||||
for i in range(fc.W.shape[0]):
|
||||
for j in range(fc.W.shape[1]):
|
||||
fc.W[i,j] += epsilon
|
||||
output = self.predict(sample_feature)
|
||||
err1 = self.loss(sample_label, output)
|
||||
fc.W[i,j] -= 2*epsilon
|
||||
output = self.predict(sample_feature)
|
||||
err2 = self.loss(sample_label, output)
|
||||
expect_grad = (err1 - err2) / (2 * epsilon)
|
||||
fc.W[i,j] += epsilon
|
||||
print('weights(%d,%d): expected - actural %.4e - %.4e' % (
|
||||
i, j, expect_grad, fc.W_grad[i,j]))
|
||||
|
||||
|
||||
from bp import train_data_set
|
||||
|
||||
|
||||
def transpose(args):
|
||||
return map(
|
||||
lambda arg: map(
|
||||
lambda line: np.array(line).reshape(len(line), 1)
|
||||
, arg)
|
||||
, args
|
||||
)
|
||||
|
||||
|
||||
class Normalizer(object):
|
||||
def __init__(self):
|
||||
self.mask = [
|
||||
0x1, 0x2, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80
|
||||
]
|
||||
|
||||
def norm(self, number):
|
||||
data = map(lambda m: 0.9 if number & m else 0.1, self.mask)
|
||||
return np.array(data).reshape(8, 1)
|
||||
|
||||
def denorm(self, vec):
|
||||
binary = map(lambda i: 1 if i > 0.5 else 0, vec[:,0])
|
||||
for i in range(len(self.mask)):
|
||||
binary[i] = binary[i] * self.mask[i]
|
||||
return reduce(lambda x,y: x + y, binary)
|
||||
|
||||
def train_data_set():
|
||||
normalizer = Normalizer()
|
||||
data_set = []
|
||||
labels = []
|
||||
for i in range(0, 256):
|
||||
n = normalizer.norm(i)
|
||||
data_set.append(n)
|
||||
labels.append(n)
|
||||
return labels, data_set
|
||||
|
||||
def correct_ratio(network):
|
||||
normalizer = Normalizer()
|
||||
correct = 0.0;
|
||||
for i in range(256):
|
||||
if normalizer.denorm(network.predict(normalizer.norm(i))) == i:
|
||||
correct += 1.0
|
||||
print('correct_ratio: %.2f%%' % (correct / 256 * 100))
|
||||
|
||||
|
||||
def test():
|
||||
labels, data_set = transpose(train_data_set())
|
||||
net = Network([8, 3, 8])
|
||||
rate = 0.5
|
||||
mini_batch = 20
|
||||
epoch = 10
|
||||
for i in range(epoch):
|
||||
net.train(labels, data_set, rate, mini_batch)
|
||||
print('after epoch %d loss: %f' % (
|
||||
(i + 1),
|
||||
net.loss(labels[-1], net.predict(data_set[-1]))
|
||||
))
|
||||
rate /= 2
|
||||
correct_ratio(net)
|
||||
|
||||
|
||||
def gradient_check():
|
||||
'''
|
||||
梯度检查
|
||||
'''
|
||||
labels, data_set = transpose(train_data_set())
|
||||
net = Network([8, 3, 8])
|
||||
net.gradient_check(data_set[0], labels[0])
|
||||
return net
|
||||
|
|
@ -0,0 +1,122 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
# 引入 Perceptron 类
|
||||
from __future__ import print_function
|
||||
from perceptron import Perceptron
|
||||
|
||||
# 定义激活函数 f
|
||||
f = lambda x: x
|
||||
|
||||
class LinearUnit(Perceptron):
|
||||
'''
|
||||
Desc:
|
||||
线性单元类
|
||||
Args:
|
||||
Perceptron —— 感知器
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
def __init__(self, input_num):
|
||||
'''
|
||||
Desc:
|
||||
初始化线性单元,设置输入参数的个数
|
||||
Args:
|
||||
input_num —— 输入参数的个数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 初始化我们的感知器类,设置输入参数的个数 input_num 和 激活函数 f
|
||||
Perceptron.__init__(self, input_num, f)
|
||||
|
||||
# 构造简单的数据集
|
||||
def get_training_dataset():
|
||||
'''
|
||||
Desc:
|
||||
构建一个简单的训练数据集
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
input_vecs —— 训练数据集的特征部分
|
||||
labels —— 训练数据集的数据对应的标签,是一一对应的
|
||||
'''
|
||||
# 构建数据集,输入向量列表,每一项是工作年限
|
||||
input_vecs = [[5], [3], [8], [1.4], [10.1]]
|
||||
# 期望的输出列表,也就是输入向量的对应的标签,与工作年限对应的收入年薪
|
||||
labels = [5500, 2300, 7600, 1800, 11400]
|
||||
return input_vecs, labels
|
||||
|
||||
|
||||
# 使用我们的训练数据集对线性单元进行训练
|
||||
def train_linear_unit():
|
||||
'''
|
||||
Desc:
|
||||
使用训练数据集对我们的线性单元进行训练
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
lu —— 返回训练好的线性单元
|
||||
'''
|
||||
# 创建感知器对象,输入参数的个数也就是特征数为 1(工作年限)
|
||||
lu = LinearUnit(1)
|
||||
# 获取构建的数据集
|
||||
input_vecs, labels = get_training_dataset()
|
||||
# 训练感知器,迭代 10 轮,学习率为 0.01
|
||||
lu.train(input_vecs, labels, 10, 0.01)
|
||||
# 返回训练好的线性单元
|
||||
return lu
|
||||
|
||||
|
||||
# 将图像画出来
|
||||
def plot(linear_unit):
|
||||
'''
|
||||
Desc:
|
||||
将我们训练好的线性单元对数据的分类情况作图画出来
|
||||
Args:
|
||||
linear_unit —— 训练好的线性单元
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 引入绘图的库
|
||||
import matplotlib.pyplot as plt
|
||||
# 获取训练数据:特征 input_vecs 与 对应的标签 labels
|
||||
input_vecs, labels = get_training_dataset()
|
||||
# figure() 创建一个 Figure 对象,与用户交互的整个窗口,这个 figure 中容纳着 subplots
|
||||
fig = plt.figure()
|
||||
# 在 figure 对象中创建 1行1列中的第一个图
|
||||
ax = fig.add_subplot(111)
|
||||
# scatter(x, y) 绘制散点图,其中的 x,y 是相同长度的数组序列
|
||||
ax.scatter(map(lambda x: x[0], input_vecs), labels)
|
||||
# 设置权重
|
||||
weights = linear_unit.weights
|
||||
# 设置偏置项
|
||||
bias = linear_unit.bias
|
||||
# range(start, stop, step) 从 start 开始,到 stop 结束,步长为 step
|
||||
x = range(0, 12, 1)
|
||||
# 计算感知器对输入计算得到的值
|
||||
y = map(lambda x: weights[0] * x + bias, x)
|
||||
# 将图画出来
|
||||
ax.plot(x, y)
|
||||
# 将最终的图展示出来
|
||||
plt.show()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
'''
|
||||
Desc:
|
||||
main 函数,训练我们的线性单元,并进行预测
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 首先训练我们的线性单元
|
||||
linear_unit = train_linear_unit()
|
||||
# 打印训练获得的权重 和 偏置
|
||||
print(linear_unit)
|
||||
# 测试
|
||||
print('Work 3.4 years, monthly salary = %.2f' % linear_unit.predict([3.4]))
|
||||
print('Work 15 years, monthly salary = %.2f' % linear_unit.predict([15]))
|
||||
print('Work 1.5 years, monthly salary = %.2f' % linear_unit.predict([1.5]))
|
||||
print('Work 6.3 years, monthly salary = %.2f' % linear_unit.predict([6.3]))
|
||||
plot(linear_unit)
|
||||
|
|
@ -0,0 +1,334 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
from __future__ import print_function
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from cnn import element_wise_op
|
||||
from activators import SigmoidActivator, TanhActivator, IdentityActivator
|
||||
|
||||
|
||||
class LstmLayer(object):
|
||||
def __init__(self, input_width, state_width,
|
||||
learning_rate):
|
||||
self.input_width = input_width
|
||||
self.state_width = state_width
|
||||
self.learning_rate = learning_rate
|
||||
# 门的激活函数
|
||||
self.gate_activator = SigmoidActivator()
|
||||
# 输出的激活函数
|
||||
self.output_activator = TanhActivator()
|
||||
# 当前时刻初始化为t0
|
||||
self.times = 0
|
||||
# 各个时刻的单元状态向量c
|
||||
self.c_list = self.init_state_vec()
|
||||
# 各个时刻的输出向量h
|
||||
self.h_list = self.init_state_vec()
|
||||
# 各个时刻的遗忘门f
|
||||
self.f_list = self.init_state_vec()
|
||||
# 各个时刻的输入门i
|
||||
self.i_list = self.init_state_vec()
|
||||
# 各个时刻的输出门o
|
||||
self.o_list = self.init_state_vec()
|
||||
# 各个时刻的即时状态c~
|
||||
self.ct_list = self.init_state_vec()
|
||||
# 遗忘门权重矩阵Wfh, Wfx, 偏置项bf
|
||||
self.Wfh, self.Wfx, self.bf = (
|
||||
self.init_weight_mat())
|
||||
# 输入门权重矩阵Wfh, Wfx, 偏置项bf
|
||||
self.Wih, self.Wix, self.bi = (
|
||||
self.init_weight_mat())
|
||||
# 输出门权重矩阵Wfh, Wfx, 偏置项bf
|
||||
self.Woh, self.Wox, self.bo = (
|
||||
self.init_weight_mat())
|
||||
# 单元状态权重矩阵Wfh, Wfx, 偏置项bf
|
||||
self.Wch, self.Wcx, self.bc = (
|
||||
self.init_weight_mat())
|
||||
|
||||
def init_state_vec(self):
|
||||
'''
|
||||
初始化保存状态的向量
|
||||
'''
|
||||
state_vec_list = []
|
||||
state_vec_list.append(np.zeros(
|
||||
(self.state_width, 1)))
|
||||
return state_vec_list
|
||||
|
||||
def init_weight_mat(self):
|
||||
'''
|
||||
初始化权重矩阵
|
||||
'''
|
||||
Wh = np.random.uniform(-1e-4, 1e-4,
|
||||
(self.state_width, self.state_width))
|
||||
Wx = np.random.uniform(-1e-4, 1e-4,
|
||||
(self.state_width, self.input_width))
|
||||
b = np.zeros((self.state_width, 1))
|
||||
return Wh, Wx, b
|
||||
|
||||
def forward(self, x):
|
||||
'''
|
||||
根据式1-式6进行前向计算
|
||||
'''
|
||||
self.times += 1
|
||||
# 遗忘门
|
||||
fg = self.calc_gate(x, self.Wfx, self.Wfh,
|
||||
self.bf, self.gate_activator)
|
||||
self.f_list.append(fg)
|
||||
# 输入门
|
||||
ig = self.calc_gate(x, self.Wix, self.Wih,
|
||||
self.bi, self.gate_activator)
|
||||
self.i_list.append(ig)
|
||||
# 输出门
|
||||
og = self.calc_gate(x, self.Wox, self.Woh,
|
||||
self.bo, self.gate_activator)
|
||||
self.o_list.append(og)
|
||||
# 即时状态
|
||||
ct = self.calc_gate(x, self.Wcx, self.Wch,
|
||||
self.bc, self.output_activator)
|
||||
self.ct_list.append(ct)
|
||||
# 单元状态
|
||||
c = fg * self.c_list[self.times - 1] + ig * ct
|
||||
self.c_list.append(c)
|
||||
# 输出
|
||||
h = og * self.output_activator.forward(c)
|
||||
self.h_list.append(h)
|
||||
|
||||
def calc_gate(self, x, Wx, Wh, b, activator):
|
||||
'''
|
||||
计算门
|
||||
'''
|
||||
h = self.h_list[self.times - 1] # 上次的LSTM输出
|
||||
net = np.dot(Wh, h) + np.dot(Wx, x) + b
|
||||
gate = activator.forward(net)
|
||||
return gate
|
||||
|
||||
|
||||
def backward(self, x, delta_h, activator):
|
||||
'''
|
||||
实现LSTM训练算法
|
||||
'''
|
||||
self.calc_delta(delta_h, activator)
|
||||
self.calc_gradient(x)
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
按照梯度下降,更新权重
|
||||
'''
|
||||
self.Wfh -= self.learning_rate * self.Whf_grad
|
||||
self.Wfx -= self.learning_rate * self.Whx_grad
|
||||
self.bf -= self.learning_rate * self.bf_grad
|
||||
self.Wih -= self.learning_rate * self.Whi_grad
|
||||
self.Wix -= self.learning_rate * self.Whi_grad
|
||||
self.bi -= self.learning_rate * self.bi_grad
|
||||
self.Woh -= self.learning_rate * self.Wof_grad
|
||||
self.Wox -= self.learning_rate * self.Wox_grad
|
||||
self.bo -= self.learning_rate * self.bo_grad
|
||||
self.Wch -= self.learning_rate * self.Wcf_grad
|
||||
self.Wcx -= self.learning_rate * self.Wcx_grad
|
||||
self.bc -= self.learning_rate * self.bc_grad
|
||||
|
||||
def calc_delta(self, delta_h, activator):
|
||||
# 初始化各个时刻的误差项
|
||||
self.delta_h_list = self.init_delta() # 输出误差项
|
||||
self.delta_o_list = self.init_delta() # 输出门误差项
|
||||
self.delta_i_list = self.init_delta() # 输入门误差项
|
||||
self.delta_f_list = self.init_delta() # 遗忘门误差项
|
||||
self.delta_ct_list = self.init_delta() # 即时输出误差项
|
||||
|
||||
# 保存从上一层传递下来的当前时刻的误差项
|
||||
self.delta_h_list[-1] = delta_h
|
||||
|
||||
# 迭代计算每个时刻的误差项
|
||||
for k in range(self.times, 0, -1):
|
||||
self.calc_delta_k(k)
|
||||
|
||||
def init_delta(self):
|
||||
'''
|
||||
初始化误差项
|
||||
'''
|
||||
delta_list = []
|
||||
for i in range(self.times + 1):
|
||||
delta_list.append(np.zeros(
|
||||
(self.state_width, 1)))
|
||||
return delta_list
|
||||
|
||||
def calc_delta_k(self, k):
|
||||
'''
|
||||
根据k时刻的delta_h,计算k时刻的delta_f、
|
||||
delta_i、delta_o、delta_ct,以及k-1时刻的delta_h
|
||||
'''
|
||||
# 获得k时刻前向计算的值
|
||||
ig = self.i_list[k]
|
||||
og = self.o_list[k]
|
||||
fg = self.f_list[k]
|
||||
ct = self.ct_list[k]
|
||||
c = self.c_list[k]
|
||||
c_prev = self.c_list[k-1]
|
||||
tanh_c = self.output_activator.forward(c)
|
||||
delta_k = self.delta_h_list[k]
|
||||
|
||||
# 根据式9计算delta_o
|
||||
delta_o = (delta_k * tanh_c *
|
||||
self.gate_activator.backward(og))
|
||||
delta_f = (delta_k * og *
|
||||
(1 - tanh_c * tanh_c) * c_prev *
|
||||
self.gate_activator.backward(fg))
|
||||
delta_i = (delta_k * og *
|
||||
(1 - tanh_c * tanh_c) * ct *
|
||||
self.gate_activator.backward(ig))
|
||||
delta_ct = (delta_k * og *
|
||||
(1 - tanh_c * tanh_c) * ig *
|
||||
self.output_activator.backward(ct))
|
||||
delta_h_prev = (
|
||||
np.dot(delta_o.transpose(), self.Woh) +
|
||||
np.dot(delta_i.transpose(), self.Wih) +
|
||||
np.dot(delta_f.transpose(), self.Wfh) +
|
||||
np.dot(delta_ct.transpose(), self.Wch)
|
||||
).transpose()
|
||||
|
||||
# 保存全部delta值
|
||||
self.delta_h_list[k-1] = delta_h_prev
|
||||
self.delta_f_list[k] = delta_f
|
||||
self.delta_i_list[k] = delta_i
|
||||
self.delta_o_list[k] = delta_o
|
||||
self.delta_ct_list[k] = delta_ct
|
||||
|
||||
def calc_gradient(self, x):
|
||||
# 初始化遗忘门权重梯度矩阵和偏置项
|
||||
self.Wfh_grad, self.Wfx_grad, self.bf_grad = (
|
||||
self.init_weight_gradient_mat())
|
||||
# 初始化输入门权重梯度矩阵和偏置项
|
||||
self.Wih_grad, self.Wix_grad, self.bi_grad = (
|
||||
self.init_weight_gradient_mat())
|
||||
# 初始化输出门权重梯度矩阵和偏置项
|
||||
self.Woh_grad, self.Wox_grad, self.bo_grad = (
|
||||
self.init_weight_gradient_mat())
|
||||
# 初始化单元状态权重梯度矩阵和偏置项
|
||||
self.Wch_grad, self.Wcx_grad, self.bc_grad = (
|
||||
self.init_weight_gradient_mat())
|
||||
|
||||
# 计算对上一次输出h的权重梯度
|
||||
for t in range(self.times, 0, -1):
|
||||
# 计算各个时刻的梯度
|
||||
(Wfh_grad, bf_grad,
|
||||
Wih_grad, bi_grad,
|
||||
Woh_grad, bo_grad,
|
||||
Wch_grad, bc_grad) = (
|
||||
self.calc_gradient_t(t))
|
||||
# 实际梯度是各时刻梯度之和
|
||||
self.Wfh_grad += Wfh_grad
|
||||
self.bf_grad += bf_grad
|
||||
self.Wih_grad += Wih_grad
|
||||
self.bi_grad += bi_grad
|
||||
self.Woh_grad += Woh_grad
|
||||
self.bo_grad += bo_grad
|
||||
self.Wch_grad += Wch_grad
|
||||
self.bc_grad += bc_grad
|
||||
|
||||
# 计算对本次输入x的权重梯度
|
||||
xt = x.transpose()
|
||||
self.Wfx_grad = np.dot(self.delta_f_list[-1], xt)
|
||||
self.Wix_grad = np.dot(self.delta_i_list[-1], xt)
|
||||
self.Wox_grad = np.dot(self.delta_o_list[-1], xt)
|
||||
self.Wcx_grad = np.dot(self.delta_ct_list[-1], xt)
|
||||
|
||||
def init_weight_gradient_mat(self):
|
||||
'''
|
||||
初始化权重矩阵
|
||||
'''
|
||||
Wh_grad = np.zeros((self.state_width,
|
||||
self.state_width))
|
||||
Wx_grad = np.zeros((self.state_width,
|
||||
self.input_width))
|
||||
b_grad = np.zeros((self.state_width, 1))
|
||||
return Wh_grad, Wx_grad, b_grad
|
||||
|
||||
def calc_gradient_t(self, t):
|
||||
'''
|
||||
计算每个时刻t权重的梯度
|
||||
'''
|
||||
h_prev = self.h_list[t-1].transpose()
|
||||
Wfh_grad = np.dot(self.delta_f_list[t], h_prev)
|
||||
bf_grad = self.delta_f_list[t]
|
||||
Wih_grad = np.dot(self.delta_i_list[t], h_prev)
|
||||
bi_grad = self.delta_f_list[t]
|
||||
Woh_grad = np.dot(self.delta_o_list[t], h_prev)
|
||||
bo_grad = self.delta_f_list[t]
|
||||
Wch_grad = np.dot(self.delta_ct_list[t], h_prev)
|
||||
bc_grad = self.delta_ct_list[t]
|
||||
return Wfh_grad, bf_grad, Wih_grad, bi_grad, \
|
||||
Woh_grad, bo_grad, Wch_grad, bc_grad
|
||||
|
||||
def reset_state(self):
|
||||
# 当前时刻初始化为t0
|
||||
self.times = 0
|
||||
# 各个时刻的单元状态向量c
|
||||
self.c_list = self.init_state_vec()
|
||||
# 各个时刻的输出向量h
|
||||
self.h_list = self.init_state_vec()
|
||||
# 各个时刻的遗忘门f
|
||||
self.f_list = self.init_state_vec()
|
||||
# 各个时刻的输入门i
|
||||
self.i_list = self.init_state_vec()
|
||||
# 各个时刻的输出门o
|
||||
self.o_list = self.init_state_vec()
|
||||
# 各个时刻的即时状态c~
|
||||
self.ct_list = self.init_state_vec()
|
||||
|
||||
|
||||
def data_set():
|
||||
x = [np.array([[1], [2], [3]]),
|
||||
np.array([[2], [3], [4]])]
|
||||
d = np.array([[1], [2]])
|
||||
return x, d
|
||||
|
||||
|
||||
def gradient_check():
|
||||
'''
|
||||
梯度检查
|
||||
'''
|
||||
# 设计一个误差函数,取所有节点输出项之和
|
||||
error_function = lambda o: o.sum()
|
||||
|
||||
lstm = LstmLayer(3, 2, 1e-3)
|
||||
|
||||
# 计算forward值
|
||||
x, d = data_set()
|
||||
lstm.forward(x[0])
|
||||
lstm.forward(x[1])
|
||||
|
||||
# 求取sensitivity map
|
||||
sensitivity_array = np.ones(lstm.h_list[-1].shape,
|
||||
dtype=np.float64)
|
||||
# 计算梯度
|
||||
lstm.backward(x[1], sensitivity_array, IdentityActivator())
|
||||
|
||||
# 检查梯度
|
||||
epsilon = 10e-4
|
||||
for i in range(lstm.Wfh.shape[0]):
|
||||
for j in range(lstm.Wfh.shape[1]):
|
||||
lstm.Wfh[i,j] += epsilon
|
||||
lstm.reset_state()
|
||||
lstm.forward(x[0])
|
||||
lstm.forward(x[1])
|
||||
err1 = error_function(lstm.h_list[-1])
|
||||
lstm.Wfh[i,j] -= 2*epsilon
|
||||
lstm.reset_state()
|
||||
lstm.forward(x[0])
|
||||
lstm.forward(x[1])
|
||||
err2 = error_function(lstm.h_list[-1])
|
||||
expect_grad = (err1 - err2) / (2 * epsilon)
|
||||
lstm.Wfh[i,j] += epsilon
|
||||
print('weights(%d,%d): expected - actural %.4e - %.4e' % (
|
||||
i, j, expect_grad, lstm.Wfh_grad[i,j]))
|
||||
return lstm
|
||||
|
||||
|
||||
def test():
|
||||
l = LstmLayer(3, 2, 1e-3)
|
||||
x, d = data_set()
|
||||
l.forward(x[0])
|
||||
l.forward(x[1])
|
||||
l.backward(x[1], d, IdentityActivator())
|
||||
return l
|
||||
|
|
@ -0,0 +1,177 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from __future__ import print_function
|
||||
import struct
|
||||
from fc import *
|
||||
from datetime import datetime
|
||||
|
||||
|
||||
# 数据加载器基类
|
||||
class Loader(object):
|
||||
def __init__(self, path, count):
|
||||
'''
|
||||
初始化加载器
|
||||
path: 数据文件路径
|
||||
count: 文件中的样本个数
|
||||
'''
|
||||
self.path = path
|
||||
self.count = count
|
||||
|
||||
def get_file_content(self):
|
||||
'''
|
||||
读取文件内容
|
||||
'''
|
||||
f = open(self.path, 'rb')
|
||||
content = f.read()
|
||||
f.close()
|
||||
return content
|
||||
|
||||
def to_int(self, byte):
|
||||
'''
|
||||
将unsigned byte字符转换为整数
|
||||
'''
|
||||
return struct.unpack('B', byte)[0]
|
||||
|
||||
|
||||
# 图像数据加载器
|
||||
class ImageLoader(Loader):
|
||||
def get_picture(self, content, index):
|
||||
'''
|
||||
内部函数,从文件中获取图像
|
||||
'''
|
||||
start = index * 28 * 28 + 16
|
||||
picture = []
|
||||
for i in range(28):
|
||||
picture.append([])
|
||||
for j in range(28):
|
||||
picture[i].append(
|
||||
self.to_int(content[start + i * 28 + j]))
|
||||
return picture
|
||||
|
||||
def get_one_sample(self, picture):
|
||||
'''
|
||||
内部函数,将图像转化为样本的输入向量
|
||||
'''
|
||||
sample = []
|
||||
for i in range(28):
|
||||
for j in range(28):
|
||||
sample.append(picture[i][j])
|
||||
return sample
|
||||
|
||||
def load(self):
|
||||
'''
|
||||
加载数据文件,获得全部样本的输入向量
|
||||
'''
|
||||
content = self.get_file_content()
|
||||
data_set = []
|
||||
for index in range(self.count):
|
||||
data_set.append(
|
||||
self.get_one_sample(
|
||||
self.get_picture(content, index)))
|
||||
return data_set
|
||||
|
||||
|
||||
# 标签数据加载器
|
||||
class LabelLoader(Loader):
|
||||
def load(self):
|
||||
'''
|
||||
加载数据文件,获得全部样本的标签向量
|
||||
'''
|
||||
content = self.get_file_content()
|
||||
labels = []
|
||||
for index in range(self.count):
|
||||
labels.append(self.norm(content[index + 8]))
|
||||
return labels
|
||||
|
||||
def norm(self, label):
|
||||
'''
|
||||
内部函数,将一个值转换为10维标签向量
|
||||
'''
|
||||
label_vec = []
|
||||
label_value = self.to_int(label)
|
||||
for i in range(10):
|
||||
if i == label_value:
|
||||
label_vec.append(0.9)
|
||||
else:
|
||||
label_vec.append(0.1)
|
||||
return label_vec
|
||||
|
||||
|
||||
def get_training_data_set():
|
||||
'''
|
||||
获得训练数据集
|
||||
'''
|
||||
image_loader = ImageLoader('train-images-idx3-ubyte', 60000)
|
||||
label_loader = LabelLoader('train-labels-idx1-ubyte', 60000)
|
||||
return image_loader.load(), label_loader.load()
|
||||
|
||||
|
||||
def get_test_data_set():
|
||||
'''
|
||||
获得测试数据集
|
||||
'''
|
||||
image_loader = ImageLoader('t10k-images-idx3-ubyte', 10000)
|
||||
label_loader = LabelLoader('t10k-labels-idx1-ubyte', 10000)
|
||||
return image_loader.load(), label_loader.load()
|
||||
|
||||
|
||||
def show(sample):
|
||||
str = ''
|
||||
for i in range(28):
|
||||
for j in range(28):
|
||||
if sample[i*28+j] != 0:
|
||||
str += '*'
|
||||
else:
|
||||
str += ' '
|
||||
str += '\n'
|
||||
print(str)
|
||||
|
||||
|
||||
def get_result(vec):
|
||||
max_value_index = 0
|
||||
max_value = 0
|
||||
for i in range(len(vec)):
|
||||
if vec[i] > max_value:
|
||||
max_value = vec[i]
|
||||
max_value_index = i
|
||||
return max_value_index
|
||||
|
||||
|
||||
def evaluate(network, test_data_set, test_labels):
|
||||
error = 0
|
||||
total = len(test_data_set)
|
||||
|
||||
for i in range(total):
|
||||
label = get_result(test_labels[i])
|
||||
predict = get_result(network.predict(test_data_set[i]))
|
||||
if label != predict:
|
||||
error += 1
|
||||
return float(error) / float(total)
|
||||
|
||||
|
||||
def now():
|
||||
return datetime.now().strftime('%c')
|
||||
|
||||
|
||||
def train_and_evaluate():
|
||||
last_error_ratio = 1.0
|
||||
epoch = 0
|
||||
train_data_set, train_labels = transpose(get_training_data_set())
|
||||
test_data_set, test_labels = transpose(get_test_data_set())
|
||||
network = Network([784, 100, 10])
|
||||
while True:
|
||||
epoch += 1
|
||||
network.train(train_labels, train_data_set, 0.01, 1)
|
||||
print('%s epoch %d finished, loss %f' % (now(), epoch,
|
||||
network.loss(train_labels[-1], network.predict(train_data_set[-1]))))
|
||||
if epoch % 2 == 0:
|
||||
error_ratio = evaluate(network, test_data_set, test_labels)
|
||||
print('%s after epoch %d, error ratio is %f' % (now(), epoch, error_ratio))
|
||||
if error_ratio > last_error_ratio:
|
||||
break
|
||||
else:
|
||||
last_error_ratio = error_ratio
|
||||
|
||||
if __name__ == '__main__':
|
||||
train_and_evaluate()
|
||||
|
|
@ -0,0 +1,187 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
# 神经元 / 感知器
|
||||
|
||||
from __future__ import print_function
|
||||
class Perceptron():
|
||||
'''
|
||||
Desc:
|
||||
感知器类
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
|
||||
def __init__(self, input_num, activator):
|
||||
'''
|
||||
Desc:
|
||||
初始化感知器
|
||||
Args:
|
||||
input_num —— 输入参数的个数
|
||||
activator —— 激活函数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 设置的激活函数
|
||||
self.activator = activator
|
||||
# 权重向量初始化为 0
|
||||
self.weights = [0.0 for _ in range(input_num)]
|
||||
# 偏置项初始化为 0
|
||||
self.bias = 0.0
|
||||
|
||||
|
||||
def __str__(self):
|
||||
'''
|
||||
Desc:
|
||||
将感知器信息打印出来
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
return('weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias))
|
||||
|
||||
|
||||
def predict(self, input_vec):
|
||||
'''
|
||||
Desc:
|
||||
输入向量,输出感知器的计算结果
|
||||
Args:
|
||||
input_vec —— 输入向量
|
||||
Returns:
|
||||
感知器的计算结果
|
||||
'''
|
||||
# 将输入向量的计算结果返回
|
||||
# 调用 激活函数 activator ,将输入向量输入,计算感知器的结果
|
||||
# reduce() 函数是 python 2 的内置函数,从 python 3 开始移到了 functools 模块
|
||||
# reduce() 从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值,例如 reduce(lambda x,y: x+y, [1,2,3,4,5]) 计算的就是 ((((1+2)+3)+4)+5)
|
||||
# map() 接收一个函数 f 和一个 list ,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 返回。比如我们的 f 函数是计算平方, map(f, [1,2,3,4,5]) ===> 返回 [1,4,9,16,25]
|
||||
# zip() 接收任意多个(包括 0 个和 1个)序列作为参数,返回一个 tuple 列表。例:x = [1,2,3] y = [4,5,6] z = [7,8,9] xyz = zip(x, y, z) ===> [(1,4,7), (2,5,8), (3,6,9)]
|
||||
return self.activator(reduce(lambda a, b: a + b,map(lambda (x, w): x * w, zip(input_vec, self.weights)), 0.0) + self.bias)
|
||||
|
||||
|
||||
def train(self, input_vecs, labels, iteration, rate):
|
||||
'''
|
||||
Desc:
|
||||
输入训练数据:一组向量、与每个向量对应的 label; 以及训练轮数、学习率
|
||||
Args:
|
||||
input_vec —— 输入向量
|
||||
labels —— 数据对应的标签
|
||||
iteration —— 训练的迭代轮数
|
||||
rate —— 学习率
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
for i in range(iteration):
|
||||
self._one_iteration(input_vecs, labels, rate)
|
||||
|
||||
|
||||
def _one_iteration(self, input_vecs, labels, rate):
|
||||
'''
|
||||
Desc:
|
||||
训练过程的一次迭代过程
|
||||
Args:
|
||||
input_vecs —— 输入向量
|
||||
labels —— 数据对应的标签
|
||||
rate —— 学习率
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# zip() 接收任意多个(包括 0 个和 1个)序列作为参数,返回一个 tuple 列表。例:x = [1,2,3] y = [4,5,6] z = [7,8,9] xyz = zip(x, y, z) ===> [(1,4,7), (2,5,8), (3,6,9)]
|
||||
samples = zip(input_vecs, labels)
|
||||
# 对每个样本,按照感知器规则更新权重
|
||||
for (input_vec, label) in samples:
|
||||
# 计算感知器在当前权重下的输出
|
||||
output = self.predict(input_vec)
|
||||
# 更新权重
|
||||
output = self._update_weights(input_vec, output, label, rate)
|
||||
|
||||
def _update_weights(self, input_vec, output, label, rate):
|
||||
'''
|
||||
Desc:
|
||||
按照感知器规则更新权重
|
||||
Args:
|
||||
input_vec —— 输入向量
|
||||
output —— 经过感知器规则计算得到的输出
|
||||
label —— 输入向量对应的标签
|
||||
rate —— 学习率
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 利用感知器规则更新权重
|
||||
delta = label - output
|
||||
# map() 接收一个函数 f 和一个 list ,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 返回。比如我们的 f 函数是计算平方, map(f, [1,2,3,4,5]) ===> 返回 [1,4,9,16,25]
|
||||
# zip() 接收任意多个(包括 0 个和 1个)序列作为参数,返回一个 tuple 列表。例:x = [1,2,3] y = [4,5,6] z = [7,8,9] xyz = zip(x, y, z) ===> [(1,4,7), (2,5,8), (3,6,9)]
|
||||
self.weights = map(lambda (x, w): w + rate * delta * x, zip(input_vec, self.weights))
|
||||
# 更新 bias
|
||||
self.bias += rate * delta
|
||||
|
||||
|
||||
|
||||
def f(x):
|
||||
'''
|
||||
Desc:
|
||||
定义激活函数 f
|
||||
Args:
|
||||
x —— 输入向量
|
||||
Returns:
|
||||
(实现阶跃函数)大于 0 返回 1,否则返回 0
|
||||
'''
|
||||
return 1 if x > 0 else 0
|
||||
|
||||
|
||||
def get_training_dataset():
|
||||
'''
|
||||
Desc:
|
||||
基于 and 真值表来构建/获取训练数据集
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
input_vecs —— 输入向量
|
||||
labels —— 输入向量对应的标签
|
||||
'''
|
||||
# 构建训练数据,输入向量的列表
|
||||
input_vecs = [[1,1],[0,0],[1,0],[0,1]]
|
||||
# 期望的输出列表,也就是上面的输入向量的列表中数据对应的标签,是一一对应的
|
||||
labels = [1, 0, 0, 0]
|
||||
return input_vecs, labels
|
||||
|
||||
|
||||
def train_and_perceptron():
|
||||
'''
|
||||
Desc:
|
||||
使用 and 真值表来训练我们的感知器
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
p —— 返回训练好的感知器
|
||||
'''
|
||||
# 创建感知器,输入参数的个数是 2 个(因为 and 是个二元函数),激活函数为 f
|
||||
p = Perceptron(2, f)
|
||||
# 进行训练,迭代 10 轮,学习速率是我们设定的 rate ,为 0.1
|
||||
input_vecs, labels = get_training_dataset()
|
||||
p.train(input_vecs, labels, 10, 0.1)
|
||||
# 返回训练好的感知器
|
||||
return p
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
'''
|
||||
Desc:
|
||||
主函数,调用上面返回的训练好的感知器进行预测
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 训练 and 感知器
|
||||
and_perceptron = train_and_perceptron()
|
||||
# 打印训练获得的权重
|
||||
print(and_perceptron)
|
||||
# 测试
|
||||
print('1 and 1 = %d' % and_perceptron.predict([1, 1]))
|
||||
print('0 and 0 = %d' % and_perceptron.predict([0, 0]))
|
||||
print('1 and 0 = %d' % and_perceptron.predict([1, 0]))
|
||||
print('0 and 1 = %d' % and_perceptron.predict([0, 1]))
|
||||
|
|
@ -0,0 +1,185 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
from __future__ import print_function
|
||||
import numpy as np
|
||||
from activators import IdentityActivator
|
||||
|
||||
|
||||
class TreeNode(object):
|
||||
def __init__(self, data, children=[], children_data=[]):
|
||||
self.parent = None
|
||||
self.children = children
|
||||
self.children_data = children_data
|
||||
self.data = data
|
||||
for child in children:
|
||||
child.parent = self
|
||||
|
||||
# 递归神经网络实现
|
||||
class RecursiveLayer(object):
|
||||
def __init__(self, node_width, child_count,
|
||||
activator, learning_rate):
|
||||
'''
|
||||
递归神经网络构造函数
|
||||
node_width: 表示每个节点的向量的维度
|
||||
child_count: 每个父节点有几个子节点
|
||||
activator: 激活函数对象
|
||||
learning_rate: 梯度下降算法学习率
|
||||
'''
|
||||
self.node_width = node_width
|
||||
self.child_count = child_count
|
||||
self.activator = activator
|
||||
self.learning_rate = learning_rate
|
||||
# 权重数组W
|
||||
self.W = np.random.uniform(-1e-4, 1e-4,
|
||||
(node_width, node_width * child_count))
|
||||
# 偏置项b
|
||||
self.b = np.zeros((node_width, 1))
|
||||
# 递归神经网络生成的树的根节点
|
||||
self.root = None
|
||||
|
||||
def forward(self, *children):
|
||||
'''
|
||||
前向计算
|
||||
'''
|
||||
children_data = self.concatenate(children)
|
||||
parent_data = self.activator.forward(
|
||||
np.dot(self.W, children_data) + self.b
|
||||
)
|
||||
self.root = TreeNode(parent_data, children
|
||||
, children_data)
|
||||
|
||||
def backward(self, parent_delta):
|
||||
'''
|
||||
BPTS反向传播算法
|
||||
'''
|
||||
self.calc_delta(parent_delta, self.root)
|
||||
self.W_grad, self.b_grad = self.calc_gradient(self.root)
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
使用SGD算法更新权重
|
||||
'''
|
||||
self.W -= self.learning_rate * self.W_grad
|
||||
self.b -= self.learning_rate * self.b_grad
|
||||
|
||||
def reset_state(self):
|
||||
self.root = None
|
||||
|
||||
def concatenate(self, tree_nodes):
|
||||
'''
|
||||
将各个树节点中的数据拼接成一个长向量
|
||||
'''
|
||||
concat = np.zeros((0,1))
|
||||
for node in tree_nodes:
|
||||
concat = np.concatenate((concat, node.data))
|
||||
return concat
|
||||
|
||||
def calc_delta(self, parent_delta, parent):
|
||||
'''
|
||||
计算每个节点的delta
|
||||
'''
|
||||
parent.delta = parent_delta
|
||||
if parent.children:
|
||||
# 根据式2计算每个子节点的delta
|
||||
children_delta = np.dot(self.W.T, parent_delta) * (
|
||||
self.activator.backward(parent.children_data)
|
||||
)
|
||||
# slices = [(子节点编号,子节点delta起始位置,子节点delta结束位置)]
|
||||
slices = [(i, i * self.node_width,
|
||||
(i + 1) * self.node_width)
|
||||
for i in range(self.child_count)]
|
||||
# 针对每个子节点,递归调用calc_delta函数
|
||||
for s in slices:
|
||||
self.calc_delta(children_delta[s[1]:s[2]],
|
||||
parent.children[s[0]])
|
||||
|
||||
def calc_gradient(self, parent):
|
||||
'''
|
||||
计算每个节点权重的梯度,并将它们求和,得到最终的梯度
|
||||
'''
|
||||
W_grad = np.zeros((self.node_width,
|
||||
self.node_width * self.child_count))
|
||||
b_grad = np.zeros((self.node_width, 1))
|
||||
if not parent.children:
|
||||
return W_grad, b_grad
|
||||
parent.W_grad = np.dot(parent.delta, parent.children_data.T)
|
||||
parent.b_grad = parent.delta
|
||||
W_grad += parent.W_grad
|
||||
b_grad += parent.b_grad
|
||||
for child in parent.children:
|
||||
W, b = self.calc_gradient(child)
|
||||
W_grad += W
|
||||
b_grad += b
|
||||
return W_grad, b_grad
|
||||
|
||||
def dump(self, **kwArgs):
|
||||
print('root.data: %s' % self.root.data)
|
||||
print('root.children_data: %s' % self.root.children_data)
|
||||
if kwArgs.has_key('dump_grad'):
|
||||
print('W_grad: %s' % self.W_grad)
|
||||
print('b_grad: %s' % self.b_grad)
|
||||
|
||||
|
||||
def data_set():
|
||||
children = [
|
||||
TreeNode(np.array([[1],[2]])),
|
||||
TreeNode(np.array([[3],[4]])),
|
||||
TreeNode(np.array([[5],[6]]))
|
||||
]
|
||||
d = np.array([[0.5],[0.8]])
|
||||
return children, d
|
||||
|
||||
|
||||
def gradient_check():
|
||||
'''
|
||||
梯度检查
|
||||
'''
|
||||
# 设计一个误差函数,取所有节点输出项之和
|
||||
error_function = lambda o: o.sum()
|
||||
|
||||
rnn = RecursiveLayer(2, 2, IdentityActivator(), 1e-3)
|
||||
|
||||
# 计算forward值
|
||||
x, d = data_set()
|
||||
rnn.forward(x[0], x[1])
|
||||
rnn.forward(rnn.root, x[2])
|
||||
|
||||
# 求取sensitivity map
|
||||
sensitivity_array = np.ones((rnn.node_width, 1),
|
||||
dtype=np.float64)
|
||||
# 计算梯度
|
||||
rnn.backward(sensitivity_array)
|
||||
|
||||
# 检查梯度
|
||||
epsilon = 10e-4
|
||||
for i in range(rnn.W.shape[0]):
|
||||
for j in range(rnn.W.shape[1]):
|
||||
rnn.W[i,j] += epsilon
|
||||
rnn.reset_state()
|
||||
rnn.forward(x[0], x[1])
|
||||
rnn.forward(rnn.root, x[2])
|
||||
err1 = error_function(rnn.root.data)
|
||||
rnn.W[i,j] -= 2*epsilon
|
||||
rnn.reset_state()
|
||||
rnn.forward(x[0], x[1])
|
||||
rnn.forward(rnn.root, x[2])
|
||||
err2 = error_function(rnn.root.data)
|
||||
expect_grad = (err1 - err2) / (2 * epsilon)
|
||||
rnn.W[i,j] += epsilon
|
||||
print('weights(%d,%d): expected - actural %.4e - %.4e' % (
|
||||
i, j, expect_grad, rnn.W_grad[i,j]))
|
||||
return rnn
|
||||
|
||||
|
||||
def test():
|
||||
children, d = data_set()
|
||||
rnn = RecursiveLayer(2, 2, IdentityActivator(), 1e-3)
|
||||
rnn.forward(children[0], children[1])
|
||||
rnn.dump()
|
||||
rnn.forward(rnn.root, children[2])
|
||||
rnn.dump()
|
||||
rnn.backward(d)
|
||||
rnn.dump(dump_grad='true')
|
||||
return rnn
|
||||
|
|
@ -0,0 +1,161 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
from __future__ import print_function
|
||||
import numpy as np
|
||||
from cnn import element_wise_op
|
||||
from activators import ReluActivator, IdentityActivator
|
||||
|
||||
try:
|
||||
reduce # Python 2
|
||||
except NameError: # Python 3
|
||||
from functools import reduce
|
||||
|
||||
|
||||
class RecurrentLayer(object):
|
||||
'''
|
||||
Desc:
|
||||
用 RecurrentLayer 类来实现一个循环层。下面的代码是初始化一个循环层,可以在构造函数中设置卷积层的超参数。我们注意到,循环层有两个权重数组,U和W
|
||||
'''
|
||||
def __init__(self, input_width, state_width,
|
||||
activator, learning_rate):
|
||||
self.input_width = input_width
|
||||
self.state_width = state_width
|
||||
self.activator = activator
|
||||
self.learning_rate = learning_rate
|
||||
self.times = 0 # 当前时刻初始化为t0
|
||||
self.state_list = [] # 保存各个时刻的state
|
||||
self.state_list.append(np.zeros(
|
||||
(state_width, 1))) # 初始化s0
|
||||
self.U = np.random.uniform(-1e-4, 1e-4,
|
||||
(state_width, input_width)) # 初始化U
|
||||
self.W = np.random.uniform(-1e-4, 1e-4,
|
||||
(state_width, state_width)) # 初始化W
|
||||
|
||||
def forward(self, input_array):
|
||||
'''
|
||||
Desc:
|
||||
实现循环层的前向计算
|
||||
'''
|
||||
self.times += 1
|
||||
state = (np.dot(self.U, input_array) +
|
||||
np.dot(self.W, self.state_list[-1]))
|
||||
element_wise_op(state, self.activator.forward)
|
||||
self.state_list.append(state)
|
||||
|
||||
def backward(self, sensitivity_array,
|
||||
activator):
|
||||
'''
|
||||
实现BPTT算法
|
||||
'''
|
||||
self.calc_delta(sensitivity_array, activator)
|
||||
self.calc_gradient()
|
||||
|
||||
def update(self):
|
||||
'''
|
||||
按照梯度下降,更新权重
|
||||
'''
|
||||
self.W -= self.learning_rate * self.gradient
|
||||
|
||||
def calc_delta(self, sensitivity_array, activator):
|
||||
self.delta_list = [] # 用来保存各个时刻的误差项
|
||||
for i in range(self.times):
|
||||
self.delta_list.append(np.zeros(
|
||||
(self.state_width, 1)))
|
||||
self.delta_list.append(sensitivity_array)
|
||||
# 迭代计算每个时刻的误差项
|
||||
for k in range(self.times - 1, 0, -1):
|
||||
self.calc_delta_k(k, activator)
|
||||
|
||||
def calc_delta_k(self, k, activator):
|
||||
'''
|
||||
根据k+1时刻的delta计算k时刻的delta
|
||||
'''
|
||||
state = self.state_list[k+1].copy()
|
||||
element_wise_op(self.state_list[k+1],
|
||||
activator.backward)
|
||||
self.delta_list[k] = np.dot(
|
||||
np.dot(self.delta_list[k+1].T, self.W),
|
||||
np.diag(state[:,0])).T
|
||||
|
||||
def calc_gradient(self):
|
||||
self.gradient_list = [] # 保存各个时刻的权重梯度
|
||||
for t in range(self.times + 1):
|
||||
self.gradient_list.append(np.zeros(
|
||||
(self.state_width, self.state_width)))
|
||||
for t in range(self.times, 0, -1):
|
||||
self.calc_gradient_t(t)
|
||||
# 实际的梯度是各个时刻梯度之和
|
||||
self.gradient = reduce(
|
||||
lambda a, b: a + b, self.gradient_list,
|
||||
self.gradient_list[0]) # [0]被初始化为0且没有被修改过
|
||||
|
||||
def calc_gradient_t(self, t):
|
||||
'''
|
||||
计算每个时刻t权重的梯度
|
||||
'''
|
||||
gradient = np.dot(self.delta_list[t],
|
||||
self.state_list[t-1].T)
|
||||
self.gradient_list[t] = gradient
|
||||
|
||||
def reset_state(self):
|
||||
self.times = 0 # 当前时刻初始化为t0
|
||||
self.state_list = [] # 保存各个时刻的state
|
||||
self.state_list.append(np.zeros(
|
||||
(self.state_width, 1))) # 初始化s0
|
||||
|
||||
|
||||
def data_set():
|
||||
x = [np.array([[1], [2], [3]]),
|
||||
np.array([[2], [3], [4]])]
|
||||
d = np.array([[1], [2]])
|
||||
return x, d
|
||||
|
||||
|
||||
def gradient_check():
|
||||
'''
|
||||
梯度检查
|
||||
'''
|
||||
# 设计一个误差函数,取所有节点输出项之和
|
||||
error_function = lambda o: o.sum()
|
||||
|
||||
rl = RecurrentLayer(3, 2, IdentityActivator(), 1e-3)
|
||||
|
||||
# 计算forward值
|
||||
x, d = data_set()
|
||||
rl.forward(x[0])
|
||||
rl.forward(x[1])
|
||||
|
||||
# 求取sensitivity map
|
||||
sensitivity_array = np.ones(rl.state_list[-1].shape,
|
||||
dtype=np.float64)
|
||||
# 计算梯度
|
||||
rl.backward(sensitivity_array, IdentityActivator())
|
||||
|
||||
# 检查梯度
|
||||
epsilon = 10e-4
|
||||
for i in range(rl.W.shape[0]):
|
||||
for j in range(rl.W.shape[1]):
|
||||
rl.W[i,j] += epsilon
|
||||
rl.reset_state()
|
||||
rl.forward(x[0])
|
||||
rl.forward(x[1])
|
||||
err1 = error_function(rl.state_list[-1])
|
||||
rl.W[i,j] -= 2*epsilon
|
||||
rl.reset_state()
|
||||
rl.forward(x[0])
|
||||
rl.forward(x[1])
|
||||
err2 = error_function(rl.state_list[-1])
|
||||
expect_grad = (err1 - err2) / (2 * epsilon)
|
||||
rl.W[i,j] += epsilon
|
||||
print('weights(%d,%d): expected - actural %f - %f' % (
|
||||
i, j, expect_grad, rl.gradient[i,j]))
|
||||
|
||||
|
||||
def test():
|
||||
l = RecurrentLayer(3, 2, ReluActivator(), 1e-3)
|
||||
x, d = data_set()
|
||||
l.forward(x[0])
|
||||
l.forward(x[1])
|
||||
l.backward(d, ReluActivator())
|
||||
return l
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf-8
|
||||
|
||||
'''
|
||||
Created on 2017-05-18
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/1988/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
|
||||
from numpy import random, mat, eye
|
||||
|
||||
'''
|
||||
# NumPy 矩阵和数组的区别
|
||||
NumPy存在2中不同的数据类型:
|
||||
1. 矩阵 matrix
|
||||
2. 数组 array
|
||||
相似点:
|
||||
都可以处理行列表示的数字元素
|
||||
不同点:
|
||||
1. 2个数据类型上执行相同的数据运算可能得到不同的结果。
|
||||
2. NumPy函数库中的 matrix 与 MATLAB中 matrices 等价。
|
||||
'''
|
||||
|
||||
# 生成一个 4*4 的随机数组
|
||||
randArray = random.rand(4, 4)
|
||||
|
||||
# 转化关系, 数组转化为矩阵
|
||||
randMat = mat(randArray)
|
||||
'''
|
||||
.I 表示对矩阵求逆(可以利用矩阵的初等变换)
|
||||
意义:逆矩阵是一个判断相似性的工具。逆矩阵A与列向量p相乘后,将得到列向量q,q的第i个分量表示p与A的第i个列向量的相似度。
|
||||
参考案例链接:
|
||||
https://www.zhihu.com/question/33258489
|
||||
http://blog.csdn.net/vernice/article/details/48506027
|
||||
.T 表示对矩阵转置(行列颠倒)
|
||||
* 等同于: .transpose()
|
||||
.A 返回矩阵基于的数组
|
||||
参考案例链接:
|
||||
http://blog.csdn.net/qq403977698/article/details/47254539
|
||||
'''
|
||||
invRandMat = randMat.I
|
||||
TraRandMat = randMat.T
|
||||
ArrRandMat = randMat.A
|
||||
# 输出结果
|
||||
print('randArray=(%s) \n' % type(randArray), randArray)
|
||||
print('randMat=(%s) \n' % type(randMat), randMat)
|
||||
print('invRandMat=(%s) \n' % type(invRandMat), invRandMat)
|
||||
print('TraRandMat=(%s) \n' % type(TraRandMat), TraRandMat)
|
||||
print('ArrRandMat=(%s) \n' % type(ArrRandMat), ArrRandMat)
|
||||
# 矩阵和逆矩阵 进行求积 (单位矩阵,对角线都为1嘛,理论上4*4的矩阵其他的都为0)
|
||||
myEye = randMat*invRandMat
|
||||
# 误差
|
||||
print(myEye - eye(4))
|
||||
|
||||
'''
|
||||
如果上面的代码运行没有问题,说明numpy安装没有问题
|
||||
'''
|
||||
|
|
@ -0,0 +1,165 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on Feb 16, 2011
|
||||
Update on 2017-05-18
|
||||
k Means Clustering for Ch10 of Machine Learning in Action
|
||||
Author: Peter Harrington/那伊抹微笑
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
|
||||
|
||||
# 从文本中构建矩阵,加载文本文件,然后处理
|
||||
def loadDataSet(fileName): # 通用函数,用来解析以 tab 键分隔的 floats(浮点数)
|
||||
dataSet = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
curLine = line.strip().split('\t')
|
||||
fltLine = map(float, curLine) # 映射所有的元素为 float(浮点数)类型
|
||||
dataSet.append(fltLine)
|
||||
return dataSet
|
||||
|
||||
|
||||
# 计算两个向量的欧式距离(可根据场景选择)
|
||||
def distEclud(vecA, vecB):
|
||||
return sqrt(sum(power(vecA - vecB, 2))) # la.norm(vecA-vecB)
|
||||
|
||||
|
||||
# 为给定数据集构建一个包含 k 个随机质心的集合。随机质心必须要在整个数据集的边界之内,这可以通过找到数据集每一维的最小和最大值来完成。然后生成 0~1.0 之间的随机数并通过取值范围和最小值,以便确保随机点在数据的边界之内。
|
||||
def randCent(dataMat, k):
|
||||
n = shape(dataMat)[1] # 列的数量
|
||||
centroids = mat(zeros((k, n))) # 创建k个质心矩阵
|
||||
for j in range(n): # 创建随机簇质心,并且在每一维的边界内
|
||||
minJ = min(dataMat[:, j]) # 最小值
|
||||
rangeJ = float(max(dataMat[:, j]) - minJ) # 范围 = 最大值 - 最小值
|
||||
centroids[:, j] = mat(minJ + rangeJ * random.rand(k, 1)) # 随机生成
|
||||
return centroids
|
||||
|
||||
|
||||
# k-means 聚类算法
|
||||
# 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
|
||||
# 这个过程重复数次,知道数据点的簇分配结果不再改变位置。
|
||||
# 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似,也可能会陷入局部最小值)
|
||||
def kMeans(dataMat, k, distMeas=distEclud, createCent=randCent):
|
||||
m = shape(dataMat)[0] # 行数
|
||||
clusterAssment = mat(zeros(
|
||||
(m, 2))) # 创建一个与 dataMat 行数一样,但是有两列的矩阵,用来保存簇分配结果
|
||||
centroids = createCent(dataMat, k) # 创建质心,随机k个质心
|
||||
clusterChanged = True
|
||||
while clusterChanged:
|
||||
clusterChanged = False
|
||||
for i in range(m): # 循环每一个数据点并分配到最近的质心中去
|
||||
minDist = inf
|
||||
minIndex = -1
|
||||
for j in range(k):
|
||||
distJI = distMeas(centroids[j, :],
|
||||
dataMat[i, :]) # 计算数据点到质心的距离
|
||||
if distJI < minDist: # 如果距离比 minDist(最小距离)还小,更新 minDist(最小距离)和最小质心的 index(索引)
|
||||
minDist = distJI
|
||||
minIndex = j
|
||||
if clusterAssment[i, 0] != minIndex: # 簇分配结果改变
|
||||
clusterChanged = True # 簇改变
|
||||
clusterAssment[
|
||||
i, :] = minIndex, minDist**2 # 更新簇分配结果为最小质心的 index(索引),minDist(最小距离)的平方
|
||||
print(centroids)
|
||||
for cent in range(k): # 更新质心
|
||||
ptsInClust = dataMat[nonzero(
|
||||
clusterAssment[:, 0].A == cent)[0]] # 获取该簇中的所有点
|
||||
centroids[cent, :] = mean(
|
||||
ptsInClust, axis=0) # 将质心修改为簇中所有点的平均值,mean 就是求平均值的
|
||||
return centroids, clusterAssment
|
||||
|
||||
|
||||
# 二分 KMeans 聚类算法, 基于 kMeans 基础之上的优化,以避免陷入局部最小值
|
||||
def biKMeans(dataMat, k, distMeas=distEclud):
|
||||
m = shape(dataMat)[0]
|
||||
clusterAssment = mat(zeros((m, 2))) # 保存每个数据点的簇分配结果和平方误差
|
||||
centroid0 = mean(dataMat, axis=0).tolist()[0] # 质心初始化为所有数据点的均值
|
||||
centList = [centroid0] # 初始化只有 1 个质心的 list
|
||||
for j in range(m): # 计算所有数据点到初始质心的距离平方误差
|
||||
clusterAssment[j, 1] = distMeas(mat(centroid0), dataMat[j, :])**2
|
||||
while (len(centList) < k): # 当质心数量小于 k 时
|
||||
lowestSSE = inf
|
||||
for i in range(len(centList)): # 对每一个质心
|
||||
ptsInCurrCluster = dataMat[nonzero(
|
||||
clusterAssment[:, 0].A == i)[0], :] # 获取当前簇 i 下的所有数据点
|
||||
centroidMat, splitClustAss = kMeans(
|
||||
ptsInCurrCluster, 2, distMeas) # 将当前簇 i 进行二分 kMeans 处理
|
||||
sseSplit = sum(splitClustAss[:, 1]) # 将二分 kMeans 结果中的平方和的距离进行求和
|
||||
sseNotSplit = sum(
|
||||
clusterAssment[nonzero(clusterAssment[:, 0].A != i)[0],
|
||||
1]) # 将未参与二分 kMeans 分配结果中的平方和的距离进行求和
|
||||
print("sseSplit, and notSplit: ", sseSplit, sseNotSplit)
|
||||
if (sseSplit + sseNotSplit) < lowestSSE:
|
||||
bestCentToSplit = i
|
||||
bestNewCents = centroidMat
|
||||
bestClustAss = splitClustAss.copy()
|
||||
lowestSSE = sseSplit + sseNotSplit
|
||||
# 找出最好的簇分配结果
|
||||
bestClustAss[nonzero(bestClustAss[:, 0].A == 1)[0], 0] = len(
|
||||
centList) # 调用二分 kMeans 的结果,默认簇是 0,1. 当然也可以改成其它的数字
|
||||
bestClustAss[nonzero(bestClustAss[:, 0].A == 0)[0],
|
||||
0] = bestCentToSplit # 更新为最佳质心
|
||||
print('the bestCentToSplit is: ', bestCentToSplit)
|
||||
print('the len of bestClustAss is: ', len(bestClustAss))
|
||||
# 更新质心列表
|
||||
centList[bestCentToSplit] = bestNewCents[0, :].tolist()[
|
||||
0] # 更新原质心 list 中的第 i 个质心为使用二分 kMeans 后 bestNewCents 的第一个质心
|
||||
centList.append(
|
||||
bestNewCents[1, :].tolist()[0]) # 添加 bestNewCents 的第二个质心
|
||||
clusterAssment[nonzero(clusterAssment[:, 0].A == bestCentToSplit)[
|
||||
0], :] = bestClustAss # 重新分配最好簇下的数据(质心)以及SSE
|
||||
return mat(centList), clusterAssment
|
||||
|
||||
|
||||
def testBasicFunc():
|
||||
# 加载测试数据集
|
||||
dataMat = mat(loadDataSet('data/10.KMeans/testSet.txt'))
|
||||
|
||||
# 测试 randCent() 函数是否正常运行。
|
||||
# 首先,先看一下矩阵中的最大值与最小值
|
||||
print('min(dataMat[:, 0])=', min(dataMat[:, 0]))
|
||||
print('min(dataMat[:, 1])=', min(dataMat[:, 1]))
|
||||
print('max(dataMat[:, 1])=', max(dataMat[:, 1]))
|
||||
print('max(dataMat[:, 0])=', max(dataMat[:, 0]))
|
||||
|
||||
# 然后看看 randCent() 函数能否生成 min 到 max 之间的值
|
||||
print('randCent(dataMat, 2)=', randCent(dataMat, 2))
|
||||
|
||||
# 最后测试一下距离计算方法
|
||||
print(' distEclud(dataMat[0], dataMat[1])=', distEclud(dataMat[0], dataMat[1]))
|
||||
|
||||
|
||||
def testKMeans():
|
||||
# 加载测试数据集
|
||||
dataMat = mat(loadDataSet('data/10.KMeans/testSet.txt'))
|
||||
|
||||
# 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
|
||||
# 这个过程重复数次,知道数据点的簇分配结果不再改变位置。
|
||||
# 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似)
|
||||
myCentroids, clustAssing = kMeans(dataMat, 4)
|
||||
|
||||
print('centroids=', myCentroids)
|
||||
|
||||
|
||||
def testBiKMeans():
|
||||
# 加载测试数据集
|
||||
dataMat = mat(loadDataSet('data/10.KMeans/testSet2.txt'))
|
||||
|
||||
centList, myNewAssments = biKMeans(dataMat, 3)
|
||||
|
||||
print('centList=', centList)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# 测试基础的函数
|
||||
# testBasicFunc()
|
||||
|
||||
# 测试 kMeans 函数
|
||||
# testKMeans()
|
||||
|
||||
# 测试二分 biKMeans 函数
|
||||
testBiKMeans()
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
# -*- coding:UTF-8 -*-
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from sklearn.cluster import KMeans
|
||||
|
||||
# 加载数据集
|
||||
dataMat = []
|
||||
fr = open("data/10.KMeans/testSet.txt") # 注意,这个是相对路径,请保证是在 MachineLearning 这个目录下执行。
|
||||
for line in fr.readlines():
|
||||
curLine = line.strip().split('\t')
|
||||
fltLine = map(float,curLine) # 映射所有的元素为 float(浮点数)类型
|
||||
dataMat.append(fltLine)
|
||||
|
||||
# 训练模型
|
||||
km = KMeans(n_clusters=4) # 初始化
|
||||
km.fit(dataMat) # 拟合
|
||||
km_pred = km.predict(dataMat) # 预测
|
||||
centers = km.cluster_centers_ # 质心
|
||||
|
||||
# 可视化结果
|
||||
plt.scatter(np.array(dataMat)[:, 1], np.array(dataMat)[:, 0], c=km_pred)
|
||||
plt.scatter(centers[:, 1], centers[:, 0], c="r")
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
# import
|
||||
>>> import kMeans
|
||||
>>> from numpy import *
|
||||
|
||||
# 从文本中构建矩阵,加载测试数据集
|
||||
>>> datMat=mat(kMeans.loadDataSet('testSet.txt'))
|
||||
|
||||
# 测试 randCent() 函数是否正常运行。
|
||||
# 首先,先看一下矩阵中的最大值与最小值
|
||||
>>> min(datMat[:,0])
|
||||
matrix([[-5.379713]])
|
||||
>>> min(datMat[:,1])
|
||||
matrix([[-4.232586]])
|
||||
>>> max(datMat[:,1])
|
||||
matrix([[ 5.1904]])
|
||||
>>> max(datMat[:,0])
|
||||
matrix([[ 4.838138]])
|
||||
|
||||
# 然后看看 randCent() 函数能否生成 min 到 max 之间的值
|
||||
>>> kMeans.randCent(datMat, 2)
|
||||
matrix([[-3.59997714, -1.43558065],
|
||||
[-3.03744979, 4.35541488]])
|
||||
|
||||
# 最后测试一下距离计算方法
|
||||
>>> kMeans.distEclud(datMat[0], datMat[1])
|
||||
5.184632816681332
|
||||
|
||||
# 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。
|
||||
# 这个过程重复数次,知道数据点的簇分配结果不再改变位置。
|
||||
# 运行结果(多次运行结果可能会不一样,可以试试,原因为随机质心的影响,但总的结果是对的, 因为数据足够相似)
|
||||
>>> myCentroids, clustAssing = kMeans.kMeans(datMat, 4)
|
||||
[[ 0.15357605 -0.94962877]
|
||||
[ 3.3593825 1.05965957]
|
||||
[-2.41900657 3.30513371]
|
||||
[-2.80505526 -3.73280289]]
|
||||
[[ 2.35622556 -3.02056425]
|
||||
[ 2.95373358 2.32801413]
|
||||
[-2.46154315 2.78737555]
|
||||
[-3.38237045 -2.9473363 ]]
|
||||
[[ 2.65077367 -2.79019029]
|
||||
[ 2.6265299 3.10868015]
|
||||
[-2.46154315 2.78737555]
|
||||
[-3.53973889 -2.89384326]]
|
||||
|
|
@ -0,0 +1,371 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf8
|
||||
|
||||
'''
|
||||
Created on Mar 24, 2011
|
||||
Update on 2017-05-18
|
||||
Ch 11 code
|
||||
Author: Peter/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
from numpy import *
|
||||
|
||||
# 加载数据集
|
||||
def loadDataSet():
|
||||
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
|
||||
|
||||
# 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
|
||||
def createC1(dataSet):
|
||||
"""createC1(创建集合 C1)
|
||||
|
||||
Args:
|
||||
dataSet 原始数据集
|
||||
Returns:
|
||||
frozenset 返回一个 frozenset 格式的 list
|
||||
"""
|
||||
|
||||
C1 = []
|
||||
for transaction in dataSet:
|
||||
for item in transaction:
|
||||
if not [item] in C1:
|
||||
# 遍历所有的元素,如果不在 C1 出现过,那么就 append
|
||||
C1.append([item])
|
||||
# 对数组进行 `从小到大` 的排序
|
||||
# print 'sort 前=', C1
|
||||
C1.sort()
|
||||
# frozenset 表示冻结的 set 集合,元素无改变;可以把它当字典的 key 来使用
|
||||
# print 'sort 后=', C1
|
||||
# print 'frozenset=', map(frozenset, C1)
|
||||
return map(frozenset, C1)
|
||||
|
||||
# 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度(minSupport)的数据
|
||||
def scanD(D, Ck, minSupport):
|
||||
"""scanD(计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度 minSupport 的数据)
|
||||
|
||||
Args:
|
||||
D 数据集
|
||||
Ck 候选项集列表
|
||||
minSupport 最小支持度
|
||||
Returns:
|
||||
retList 支持度大于 minSupport 的集合
|
||||
supportData 候选项集支持度数据
|
||||
"""
|
||||
|
||||
# ssCnt 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8
|
||||
ssCnt = {}
|
||||
for tid in D:
|
||||
for can in Ck:
|
||||
# s.issubset(t) 测试是否 s 中的每一个元素都在 t 中
|
||||
if can.issubset(tid):
|
||||
if not ssCnt.has_key(can):
|
||||
ssCnt[can] = 1
|
||||
else:
|
||||
ssCnt[can] += 1
|
||||
numItems = float(len(D)) # 数据集 D 的数量
|
||||
retList = []
|
||||
supportData = {}
|
||||
for key in ssCnt:
|
||||
# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量
|
||||
support = ssCnt[key]/numItems
|
||||
if support >= minSupport:
|
||||
# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值
|
||||
retList.insert(0, key)
|
||||
# 存储所有的候选项(key)和对应的支持度(support)
|
||||
supportData[key] = support
|
||||
return retList, supportData
|
||||
|
||||
# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
|
||||
def aprioriGen(Lk, k):
|
||||
"""aprioriGen(输入频繁项集列表 Lk 与返回的元素个数 k,然后输出候选项集 Ck。
|
||||
例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
|
||||
仅需要计算一次,不需要将所有的结果计算出来,然后进行去重操作
|
||||
这是一个更高效的算法)
|
||||
|
||||
Args:
|
||||
Lk 频繁项集列表
|
||||
k 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)
|
||||
Returns:
|
||||
retList 元素两两合并的数据集
|
||||
"""
|
||||
|
||||
retList = []
|
||||
lenLk = len(Lk)
|
||||
for i in range(lenLk):
|
||||
for j in range(i+1, lenLk):
|
||||
L1 = list(Lk[i])[: k-2]
|
||||
L2 = list(Lk[j])[: k-2]
|
||||
# print '-----i=', i, k-2, Lk, Lk[i], list(Lk[i])[: k-2]
|
||||
# print '-----j=', j, k-2, Lk, Lk[j], list(Lk[j])[: k-2]
|
||||
L1.sort()
|
||||
L2.sort()
|
||||
# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集
|
||||
# if first k-2 elements are equal
|
||||
if L1 == L2:
|
||||
# set union
|
||||
# print 'union=', Lk[i] | Lk[j], Lk[i], Lk[j]
|
||||
retList.append(Lk[i] | Lk[j])
|
||||
return retList
|
||||
|
||||
# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
|
||||
def apriori(dataSet, minSupport=0.5):
|
||||
"""apriori(首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)
|
||||
|
||||
Args:
|
||||
dataSet 原始数据集
|
||||
minSupport 支持度的阈值
|
||||
Returns:
|
||||
L 频繁项集的全集
|
||||
supportData 所有元素和支持度的全集
|
||||
"""
|
||||
# C1 即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
|
||||
C1 = createC1(dataSet)
|
||||
# print 'C1: ', C1
|
||||
# 对每一行进行 set 转换,然后存放到集合中
|
||||
D = map(set, dataSet)
|
||||
# print 'D=', D
|
||||
# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
|
||||
L1, supportData = scanD(D, C1, minSupport)
|
||||
# print "L1=", L1, "\n", "outcome: ", supportData
|
||||
|
||||
# L 加了一层 list, L 一共 2 层 list
|
||||
L = [L1]
|
||||
k = 2
|
||||
# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1
|
||||
while (len(L[k-2]) > 0):
|
||||
# print 'k=', k, L, L[k-2]
|
||||
Ck = aprioriGen(L[k-2], k) # 例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
|
||||
# print 'Ck', Ck
|
||||
|
||||
Lk, supK = scanD(D, Ck, minSupport) # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
|
||||
# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
|
||||
supportData.update(supK)
|
||||
if len(Lk) == 0:
|
||||
break
|
||||
# Lk 表示满足频繁子项的集合,L 元素在增加,例如:
|
||||
# l=[[set(1), set(2), set(3)]]
|
||||
# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]
|
||||
L.append(Lk)
|
||||
k += 1
|
||||
# print 'k=', k, len(L[k-2])
|
||||
return L, supportData
|
||||
|
||||
# 计算可信度(confidence)
|
||||
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
|
||||
"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
|
||||
|
||||
Args:
|
||||
freqSet 频繁项集中的元素,例如: frozenset([1, 3])
|
||||
H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
|
||||
supportData 所有元素的支持度的字典
|
||||
brl 关联规则列表的空数组
|
||||
minConf 最小可信度
|
||||
Returns:
|
||||
prunedH 记录 可信度大于阈值的集合
|
||||
"""
|
||||
# 记录可信度大于最小可信度(minConf)的集合
|
||||
prunedH = []
|
||||
for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度
|
||||
|
||||
# print 'confData=', freqSet, H, conseq, freqSet-conseq
|
||||
conf = supportData[freqSet]/supportData[freqSet-conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]
|
||||
if conf >= minConf:
|
||||
# 只要买了 freqSet-conseq 集合,一定会买 conseq 集合(freqSet-conseq 集合和 conseq集合 是全集)
|
||||
print(freqSet-conseq, '-->', conseq, 'conf:', conf)
|
||||
brl.append((freqSet-conseq, conseq, conf))
|
||||
prunedH.append(conseq)
|
||||
return prunedH
|
||||
|
||||
# 递归计算频繁项集的规则
|
||||
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
|
||||
"""rulesFromConseq
|
||||
|
||||
Args:
|
||||
freqSet 频繁项集中的元素,例如: frozenset([2, 3, 5])
|
||||
H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
supportData 所有元素的支持度的字典
|
||||
brl 关联规则列表的数组
|
||||
minConf 最小可信度
|
||||
"""
|
||||
# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制
|
||||
# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...
|
||||
# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
# 那么 m = len(H[0]) 的递归的值依次为 1 2
|
||||
# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。
|
||||
m = len(H[0])
|
||||
if (len(freqSet) > (m + 1)):
|
||||
# print 'freqSet******************', len(freqSet), m + 1, freqSet, H, H[0]
|
||||
# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]
|
||||
# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]
|
||||
# 第二次 。。。没有第二次,递归条件判断时已经退出了
|
||||
Hmp1 = aprioriGen(H, m+1)
|
||||
# 返回可信度大于最小可信度的集合
|
||||
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
|
||||
print('Hmp1=', Hmp1)
|
||||
print('len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freqSet))
|
||||
# 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
|
||||
if (len(Hmp1) > 1):
|
||||
# print '----------------------', Hmp1
|
||||
# print len(freqSet), len(Hmp1[0]) + 1
|
||||
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
|
||||
|
||||
# 生成关联规则
|
||||
def generateRules(L, supportData, minConf=0.7):
|
||||
"""generateRules
|
||||
|
||||
Args:
|
||||
L 频繁项集列表
|
||||
supportData 频繁项集支持度的字典
|
||||
minConf 最小置信度
|
||||
Returns:
|
||||
bigRuleList 可信度规则列表(关于 (A->B+置信度) 3个字段的组合)
|
||||
"""
|
||||
bigRuleList = []
|
||||
# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]
|
||||
for i in range(1, len(L)):
|
||||
# 获取频繁项集中每个组合的所有元素
|
||||
for freqSet in L[i]:
|
||||
# 假设:freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]
|
||||
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
|
||||
H1 = [frozenset([item]) for item in freqSet]
|
||||
# 2 个的组合,走 else, 2 个以上的组合,走 if
|
||||
if (i > 1):
|
||||
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
|
||||
else:
|
||||
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
|
||||
return bigRuleList
|
||||
|
||||
|
||||
def getActionIds():
|
||||
from time import sleep
|
||||
from votesmart import votesmart
|
||||
# votesmart.apikey = 'get your api key first'
|
||||
votesmart.apikey = 'a7fa40adec6f4a77178799fae4441030'
|
||||
actionIdList = []
|
||||
billTitleList = []
|
||||
fr = open('data/11.Apriori/recent20bills.txt')
|
||||
for line in fr.readlines():
|
||||
billNum = int(line.split('\t')[0])
|
||||
try:
|
||||
billDetail = votesmart.votes.getBill(billNum) # api call
|
||||
for action in billDetail.actions:
|
||||
if action.level == 'House' and (action.stage == 'Passage' or action.stage == 'Amendment Vote'):
|
||||
actionId = int(action.actionId)
|
||||
print('bill: %d has actionId: %d' % (billNum, actionId))
|
||||
actionIdList.append(actionId)
|
||||
billTitleList.append(line.strip().split('\t')[1])
|
||||
except:
|
||||
print("problem getting bill %d" % billNum)
|
||||
sleep(1) # delay to be polite
|
||||
return actionIdList, billTitleList
|
||||
|
||||
|
||||
def getTransList(actionIdList, billTitleList): #this will return a list of lists containing ints
|
||||
itemMeaning = ['Republican', 'Democratic']#list of what each item stands for
|
||||
for billTitle in billTitleList:#fill up itemMeaning list
|
||||
itemMeaning.append('%s -- Nay' % billTitle)
|
||||
itemMeaning.append('%s -- Yea' % billTitle)
|
||||
transDict = {}#list of items in each transaction (politician)
|
||||
voteCount = 2
|
||||
for actionId in actionIdList:
|
||||
sleep(3)
|
||||
print('getting votes for actionId: %d' % actionId)
|
||||
try:
|
||||
voteList = votesmart.votes.getBillActionVotes(actionId)
|
||||
for vote in voteList:
|
||||
if not transDict.has_key(vote.candidateName):
|
||||
transDict[vote.candidateName] = []
|
||||
if vote.officeParties == 'Democratic':
|
||||
transDict[vote.candidateName].append(1)
|
||||
elif vote.officeParties == 'Republican':
|
||||
transDict[vote.candidateName].append(0)
|
||||
if vote.action == 'Nay':
|
||||
transDict[vote.candidateName].append(voteCount)
|
||||
elif vote.action == 'Yea':
|
||||
transDict[vote.candidateName].append(voteCount + 1)
|
||||
except:
|
||||
print("problem getting actionId: %d" % actionId)
|
||||
voteCount += 2
|
||||
return transDict, itemMeaning
|
||||
|
||||
|
||||
# 暂时没用上
|
||||
# def pntRules(ruleList, itemMeaning):
|
||||
# for ruleTup in ruleList:
|
||||
# for item in ruleTup[0]:
|
||||
# print itemMeaning[item]
|
||||
# print " -------->"
|
||||
# for item in ruleTup[1]:
|
||||
# print itemMeaning[item]
|
||||
# print "confidence: %f" % ruleTup[2]
|
||||
# print #print a blank line
|
||||
|
||||
def testApriori():
|
||||
# 加载测试数据集
|
||||
dataSet = loadDataSet()
|
||||
print('dataSet: ', dataSet)
|
||||
|
||||
# Apriori 算法生成频繁项集以及它们的支持度
|
||||
L1, supportData1 = apriori(dataSet, minSupport=0.7)
|
||||
print('L(0.7): ', L1)
|
||||
print('supportData(0.7): ', supportData1)
|
||||
|
||||
print('->->->->->->->->->->->->->->->->->->->->->->->->->->->->')
|
||||
|
||||
# Apriori 算法生成频繁项集以及它们的支持度
|
||||
L2, supportData2 = apriori(dataSet, minSupport=0.5)
|
||||
print('L(0.5): ', L2)
|
||||
print('supportData(0.5): ', supportData2)
|
||||
|
||||
def testGenerateRules():
|
||||
# 加载测试数据集
|
||||
dataSet = loadDataSet()
|
||||
print('dataSet: ', dataSet)
|
||||
|
||||
# Apriori 算法生成频繁项集以及它们的支持度
|
||||
L1, supportData1 = apriori(dataSet, minSupport=0.5)
|
||||
print('L(0.7): ', L1)
|
||||
print('supportData(0.7): ', supportData1)
|
||||
|
||||
# 生成关联规则
|
||||
rules = generateRules(L1, supportData1, minConf=0.5)
|
||||
print('rules: ', rules)
|
||||
|
||||
def main():
|
||||
# 测试 Apriori 算法
|
||||
testApriori()
|
||||
|
||||
# 生成关联规则
|
||||
# testGenerateRules()
|
||||
|
||||
# # 项目案例
|
||||
# # 构建美国国会投票记录的事务数据集
|
||||
# actionIdList, billTitleList = getActionIds()
|
||||
# # 测试前2个
|
||||
# # transDict, itemMeaning = getTransList(actionIdList[: 2], billTitleList[: 2])
|
||||
# # transDict 表示 action_id的集合,transDict[key]这个就是action_id对应的选项,例如 [1, 2, 3]
|
||||
# transDict, itemMeaning = getTransList(actionIdList, billTitleList)
|
||||
# # 得到全集的数据
|
||||
# dataSet = [transDict[key] for key in transDict.keys()]
|
||||
# L, supportData = apriori(dataSet, minSupport=0.3)
|
||||
# rules = generateRules(L, supportData, minConf=0.95)
|
||||
# print rules
|
||||
|
||||
# # 项目案例
|
||||
# # 发现毒蘑菇的相似特性
|
||||
# # 得到全集的数据
|
||||
# dataSet = [line.split() for line in open("data/11.Apriori/mushroom.dat").readlines()]
|
||||
# L, supportData = apriori(dataSet, minSupport=0.3)
|
||||
# # 2表示毒蘑菇,1表示可食用的蘑菇
|
||||
# # 找出关于2的频繁子项出来,就知道如果是毒蘑菇,那么出现频繁的也可能是毒蘑菇
|
||||
# for item in L[1]:
|
||||
# if item.intersection('2'):
|
||||
# print item
|
||||
|
||||
# for item in L[2]:
|
||||
# if item.intersection('2'):
|
||||
# print item
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -0,0 +1,344 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on Jun 14, 2011
|
||||
Update on 2017-05-18
|
||||
FP-Growth FP means frequent pattern
|
||||
the FP-Growth algorithm needs:
|
||||
1. FP-tree (class treeNode)
|
||||
2. header table (use dict)
|
||||
This finds frequent itemsets similar to apriori but does not find association rules.
|
||||
Author: Peter/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
|
||||
|
||||
class treeNode:
|
||||
def __init__(self, nameValue, numOccur, parentNode):
|
||||
self.name = nameValue
|
||||
self.count = numOccur
|
||||
self.nodeLink = None
|
||||
# needs to be updated
|
||||
self.parent = parentNode
|
||||
self.children = {}
|
||||
|
||||
def inc(self, numOccur):
|
||||
"""inc(对count变量增加给定值)
|
||||
"""
|
||||
self.count += numOccur
|
||||
|
||||
def disp(self, ind=1):
|
||||
"""disp(用于将树以文本形式显示)
|
||||
|
||||
"""
|
||||
print(' '*ind, self.name, ' ', self.count)
|
||||
for child in self.children.values():
|
||||
child.disp(ind+1)
|
||||
|
||||
|
||||
def loadSimpDat():
|
||||
simpDat = [['r', 'z', 'h', 'j', 'p'],
|
||||
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
|
||||
['z'],
|
||||
['r', 'x', 'n', 'o', 's'],
|
||||
# ['r', 'x', 'n', 'o', 's'],
|
||||
['y', 'r', 'x', 'z', 'q', 't', 'p'],
|
||||
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
|
||||
return simpDat
|
||||
|
||||
|
||||
def createInitSet(dataSet):
|
||||
retDict = {}
|
||||
for trans in dataSet:
|
||||
if not retDict.has_key(frozenset(trans)):
|
||||
retDict[frozenset(trans)] = 1
|
||||
else:
|
||||
retDict[frozenset(trans)] += 1
|
||||
return retDict
|
||||
|
||||
|
||||
# this version does not use recursion
|
||||
def updateHeader(nodeToTest, targetNode):
|
||||
"""updateHeader(更新头指针,建立相同元素之间的关系,例如: 左边的r指向右边的r值,就是后出现的相同元素 指向 已经出现的元素)
|
||||
|
||||
从头指针的nodeLink开始,一直沿着nodeLink直到到达链表末尾。这就是链表。
|
||||
性能:如果链表很长可能会遇到迭代调用的次数限制。
|
||||
|
||||
Args:
|
||||
nodeToTest 满足minSup {所有的元素+(value, treeNode)}
|
||||
targetNode Tree对象的子节点
|
||||
"""
|
||||
# 建立相同元素之间的关系,例如: 左边的r指向右边的r值
|
||||
while (nodeToTest.nodeLink is not None):
|
||||
nodeToTest = nodeToTest.nodeLink
|
||||
nodeToTest.nodeLink = targetNode
|
||||
|
||||
|
||||
def updateTree(items, inTree, headerTable, count):
|
||||
"""updateTree(更新FP-tree,第二次遍历)
|
||||
|
||||
# 针对每一行的数据
|
||||
# 最大的key, 添加
|
||||
Args:
|
||||
items 满足minSup 排序后的元素key的数组(大到小的排序)
|
||||
inTree 空的Tree对象
|
||||
headerTable 满足minSup {所有的元素+(value, treeNode)}
|
||||
count 原数据集中每一组Kay出现的次数
|
||||
"""
|
||||
# 取出 元素 出现次数最高的
|
||||
# 如果该元素在 inTree.children 这个字典中,就进行累加
|
||||
# 如果该元素不存在 就 inTree.children 字典中新增key,value为初始化的 treeNode 对象
|
||||
if items[0] in inTree.children:
|
||||
# 更新 最大元素,对应的 treeNode 对象的count进行叠加
|
||||
inTree.children[items[0]].inc(count)
|
||||
else:
|
||||
# 如果不存在子节点,我们为该inTree添加子节点
|
||||
inTree.children[items[0]] = treeNode(items[0], count, inTree)
|
||||
# 如果满足minSup的dist字典的value值第二位为null, 我们就设置该元素为 本节点对应的tree节点
|
||||
# 如果元素第二位不为null,我们就更新header节点
|
||||
if headerTable[items[0]][1] is None:
|
||||
# headerTable只记录第一次节点出现的位置
|
||||
headerTable[items[0]][1] = inTree.children[items[0]]
|
||||
else:
|
||||
# 本质上是修改headerTable的key对应的Tree,的nodeLink值
|
||||
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
|
||||
if len(items) > 1:
|
||||
# 递归的调用,在items[0]的基础上,添加item0[1]做子节点, count只要循环的进行累计加和而已,统计出节点的最后的统计值。
|
||||
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
|
||||
|
||||
|
||||
def createTree(dataSet, minSup=1):
|
||||
"""createTree(生成FP-tree)
|
||||
|
||||
Args:
|
||||
dataSet dist{行:出现次数}的样本数据
|
||||
minSup 最小的支持度
|
||||
Returns:
|
||||
retTree FP-tree
|
||||
headerTable 满足minSup {所有的元素+(value, treeNode)}
|
||||
"""
|
||||
# 支持度>=minSup的dist{所有元素:出现的次数}
|
||||
headerTable = {}
|
||||
# 循环 dist{行:出现次数}的样本数据
|
||||
for trans in dataSet:
|
||||
# 对所有的行进行循环,得到行里面的所有元素
|
||||
# 统计每一行中,每个元素出现的总次数
|
||||
for item in trans:
|
||||
# 例如: {'ababa': 3} count(a)=3+3+3=9 count(b)=3+3=6
|
||||
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
|
||||
# 删除 headerTable中,元素次数<最小支持度的元素
|
||||
for k in headerTable.keys():
|
||||
if headerTable[k] < minSup:
|
||||
del(headerTable[k])
|
||||
|
||||
# 满足minSup: set(各元素集合)
|
||||
freqItemSet = set(headerTable.keys())
|
||||
# 如果不存在,直接返回None
|
||||
if len(freqItemSet) == 0:
|
||||
return None, None
|
||||
for k in headerTable:
|
||||
# 格式化: dist{元素key: [元素次数, None]}
|
||||
headerTable[k] = [headerTable[k], None]
|
||||
|
||||
# create tree
|
||||
retTree = treeNode('Null Set', 1, None)
|
||||
# 循环 dist{行:出现次数}的样本数据
|
||||
for tranSet, count in dataSet.items():
|
||||
# print 'tranSet, count=', tranSet, count
|
||||
# localD = dist{元素key: 元素总出现次数}
|
||||
localD = {}
|
||||
for item in tranSet:
|
||||
# 判断是否在满足minSup的集合中
|
||||
if item in freqItemSet:
|
||||
# print 'headerTable[item][0]=', headerTable[item][0], headerTable[item]
|
||||
localD[item] = headerTable[item][0]
|
||||
# print 'localD=', localD
|
||||
if len(localD) > 0:
|
||||
# p=key,value; 所以是通过value值的大小,进行从大到小进行排序
|
||||
# orderedItems 表示取出元组的key值,也就是字母本身,但是字母本身是大到小的顺序
|
||||
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
|
||||
# print 'orderedItems=', orderedItems, 'headerTable', headerTable, '\n\n\n'
|
||||
# 填充树,通过有序的orderedItems的第一位,进行顺序填充 第一层的子节点。
|
||||
updateTree(orderedItems, retTree, headerTable, count)
|
||||
|
||||
return retTree, headerTable
|
||||
|
||||
|
||||
def ascendTree(leafNode, prefixPath):
|
||||
"""ascendTree(如果存在父节点,就记录当前节点的name值)
|
||||
|
||||
Args:
|
||||
leafNode 查询的节点对于的nodeTree
|
||||
prefixPath 要查询的节点值
|
||||
"""
|
||||
if leafNode.parent is not None:
|
||||
prefixPath.append(leafNode.name)
|
||||
ascendTree(leafNode.parent, prefixPath)
|
||||
|
||||
|
||||
def findPrefixPath(basePat, treeNode):
|
||||
"""findPrefixPath 基础数据集
|
||||
|
||||
Args:
|
||||
basePat 要查询的节点值
|
||||
treeNode 查询的节点所在的当前nodeTree
|
||||
Returns:
|
||||
condPats 对非basePat的倒叙值作为key,赋值为count数
|
||||
"""
|
||||
condPats = {}
|
||||
# 对 treeNode的link进行循环
|
||||
while treeNode is not None:
|
||||
prefixPath = []
|
||||
# 寻找改节点的父节点,相当于找到了该节点的频繁项集
|
||||
ascendTree(treeNode, prefixPath)
|
||||
# 避免 单独`Z`一个元素,添加了空节点
|
||||
if len(prefixPath) > 1:
|
||||
# 对非basePat的倒叙值作为key,赋值为count数
|
||||
# prefixPath[1:] 变frozenset后,字母就变无序了
|
||||
# condPats[frozenset(prefixPath)] = treeNode.count
|
||||
condPats[frozenset(prefixPath[1:])] = treeNode.count
|
||||
# 递归,寻找改节点的下一个 相同值的链接节点
|
||||
treeNode = treeNode.nodeLink
|
||||
# print treeNode
|
||||
return condPats
|
||||
|
||||
|
||||
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
|
||||
"""mineTree(创建条件FP树)
|
||||
|
||||
Args:
|
||||
inTree myFPtree
|
||||
headerTable 满足minSup {所有的元素+(value, treeNode)}
|
||||
minSup 最小支持项集
|
||||
preFix preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
|
||||
freqItemList 用来存储频繁子项的列表
|
||||
"""
|
||||
# 通过value进行从小到大的排序, 得到频繁项集的key
|
||||
# 最小支持项集的key的list集合
|
||||
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]
|
||||
print('-----', sorted(headerTable.items(), key=lambda p: p[1]))
|
||||
print('bigL=', bigL)
|
||||
# 循环遍历 最频繁项集的key,从小到大的递归寻找对应的频繁项集
|
||||
for basePat in bigL:
|
||||
# preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
|
||||
newFreqSet = preFix.copy()
|
||||
newFreqSet.add(basePat)
|
||||
print('newFreqSet=', newFreqSet, preFix)
|
||||
|
||||
freqItemList.append(newFreqSet)
|
||||
print('freqItemList=', freqItemList)
|
||||
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
|
||||
print('condPattBases=', basePat, condPattBases)
|
||||
|
||||
# 构建FP-tree
|
||||
myCondTree, myHead = createTree(condPattBases, minSup)
|
||||
print('myHead=', myHead)
|
||||
# 挖掘条件 FP-tree, 如果myHead不为空,表示满足minSup {所有的元素+(value, treeNode)}
|
||||
if myHead is not None:
|
||||
myCondTree.disp(1)
|
||||
print('\n\n\n')
|
||||
# 递归 myHead 找出频繁项集
|
||||
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
|
||||
print('\n\n\n')
|
||||
|
||||
|
||||
# import twitter
|
||||
# from time import sleep
|
||||
# import re
|
||||
|
||||
|
||||
# def getLotsOfTweets(searchStr):
|
||||
# """
|
||||
# 获取 100个搜索结果页面
|
||||
# """
|
||||
# CONSUMER_KEY = ''
|
||||
# CONSUMER_SECRET = ''
|
||||
# ACCESS_TOKEN_KEY = ''
|
||||
# ACCESS_TOKEN_SECRET = ''
|
||||
# api = twitter.Api(consumer_key=CONSUMER_KEY, consumer_secret=CONSUMER_SECRET, access_token_key=ACCESS_TOKEN_KEY, access_token_secret=ACCESS_TOKEN_SECRET)
|
||||
|
||||
# # you can get 1500 results 15 pages * 100 per page
|
||||
# resultsPages = []
|
||||
# for i in range(1, 15):
|
||||
# print "fetching page %d" % i
|
||||
# searchResults = api.GetSearch(searchStr, per_page=100, page=i)
|
||||
# resultsPages.append(searchResults)
|
||||
# sleep(6)
|
||||
# return resultsPages
|
||||
|
||||
|
||||
# def textParse(bigString):
|
||||
# """
|
||||
# 解析页面内容
|
||||
# """
|
||||
# urlsRemoved = re.sub('(http:[/][/]|www.)([a-z]|[A-Z]|[0-9]|[/.]|[~])*', '', bigString)
|
||||
# listOfTokens = re.split(r'\W*', urlsRemoved)
|
||||
# return [tok.lower() for tok in listOfTokens if len(tok) > 2]
|
||||
|
||||
|
||||
# def mineTweets(tweetArr, minSup=5):
|
||||
# """
|
||||
# 获取频繁项集
|
||||
# """
|
||||
# parsedList = []
|
||||
# for i in range(14):
|
||||
# for j in range(100):
|
||||
# parsedList.append(textParse(tweetArr[i][j].text))
|
||||
# initSet = createInitSet(parsedList)
|
||||
# myFPtree, myHeaderTab = createTree(initSet, minSup)
|
||||
# myFreqList = []
|
||||
# mineTree(myFPtree, myHeaderTab, minSup, set([]), myFreqList)
|
||||
# return myFreqList
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# rootNode = treeNode('pyramid', 9, None)
|
||||
# rootNode.children['eye'] = treeNode('eye', 13, None)
|
||||
# rootNode.children['phoenix'] = treeNode('phoenix', 3, None)
|
||||
# # 将树以文本形式显示
|
||||
# # print rootNode.disp()
|
||||
|
||||
# load样本数据
|
||||
simpDat = loadSimpDat()
|
||||
# print simpDat, '\n'
|
||||
# frozen set 格式化 并 重新装载 样本数据,对所有的行进行统计求和,格式: {行:出现次数}
|
||||
initSet = createInitSet(simpDat)
|
||||
print(initSet)
|
||||
|
||||
# 创建FP树
|
||||
# 输入:dist{行:出现次数}的样本数据 和 最小的支持度
|
||||
# 输出:最终的PF-tree,通过循环获取第一层的节点,然后每一层的节点进行递归的获取每一行的字节点,也就是分支。然后所谓的指针,就是后来的指向已存在的
|
||||
myFPtree, myHeaderTab = createTree(initSet, 3)
|
||||
myFPtree.disp()
|
||||
|
||||
# 抽取条件模式基
|
||||
# 查询树节点的,频繁子项
|
||||
print('x --->', findPrefixPath('x', myHeaderTab['x'][1]))
|
||||
print('z --->', findPrefixPath('z', myHeaderTab['z'][1]))
|
||||
print('r --->', findPrefixPath('r', myHeaderTab['r'][1]))
|
||||
|
||||
# 创建条件模式基
|
||||
freqItemList = []
|
||||
mineTree(myFPtree, myHeaderTab, 3, set([]), freqItemList)
|
||||
print(freqItemList)
|
||||
|
||||
# # 项目实战
|
||||
# # 1.twitter项目案例
|
||||
# # 无法运行,因为没发链接twitter
|
||||
# lotsOtweets = getLotsOfTweets('RIMM')
|
||||
# listOfTerms = mineTweets(lotsOtweets, 20)
|
||||
# print len(listOfTerms)
|
||||
# for t in listOfTerms:
|
||||
# print t
|
||||
|
||||
# # 2.新闻网站点击流中挖掘,例如:文章1阅读过的人,还阅读过什么?
|
||||
# parsedDat = [line.split() for line in open('data/12.FPGrowth/kosarak.dat').readlines()]
|
||||
# initSet = createInitSet(parsedDat)
|
||||
# myFPtree, myHeaderTab = createTree(initSet, 100000)
|
||||
|
||||
# myFreList = []
|
||||
# mineTree(myFPtree, myHeaderTab, 100000, set([]), myFreList)
|
||||
# print myFreList
|
||||
|
|
@ -0,0 +1,153 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf-8
|
||||
|
||||
'''
|
||||
Created on Jun 1, 2011
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/片刻
|
||||
GitHub:https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
import matplotlib.pyplot as plt
|
||||
print(__doc__)
|
||||
|
||||
|
||||
def loadDataSet(fileName, delim='\t'):
|
||||
fr = open(fileName)
|
||||
stringArr = [line.strip().split(delim) for line in fr.readlines()]
|
||||
datArr = [map(float, line) for line in stringArr]
|
||||
return mat(datArr)
|
||||
|
||||
|
||||
def pca(dataMat, topNfeat=9999999):
|
||||
"""pca
|
||||
|
||||
Args:
|
||||
dataMat 原数据集矩阵
|
||||
topNfeat 应用的N个特征
|
||||
Returns:
|
||||
lowDDataMat 降维后数据集
|
||||
reconMat 新的数据集空间
|
||||
"""
|
||||
|
||||
# 计算每一列的均值
|
||||
meanVals = mean(dataMat, axis=0)
|
||||
# print 'meanVals', meanVals
|
||||
|
||||
# 每个向量同时都减去 均值
|
||||
meanRemoved = dataMat - meanVals
|
||||
# print 'meanRemoved=', meanRemoved
|
||||
|
||||
# cov协方差=[(x1-x均值)*(y1-y均值)+(x2-x均值)*(y2-y均值)+...+(xn-x均值)*(yn-y均值)+]/(n-1)
|
||||
'''
|
||||
方差:(一维)度量两个随机变量关系的统计量
|
||||
协方差: (二维)度量各个维度偏离其均值的程度
|
||||
协方差矩阵:(多维)度量各个维度偏离其均值的程度
|
||||
|
||||
当 cov(X, Y)>0时,表明X与Y正相关;(X越大,Y也越大;X越小Y,也越小。这种情况,我们称为“正相关”。)
|
||||
当 cov(X, Y)<0时,表明X与Y负相关;
|
||||
当 cov(X, Y)=0时,表明X与Y不相关。
|
||||
'''
|
||||
covMat = cov(meanRemoved, rowvar=0)
|
||||
|
||||
# eigVals为特征值, eigVects为特征向量
|
||||
eigVals, eigVects = linalg.eig(mat(covMat))
|
||||
# print 'eigVals=', eigVals
|
||||
# print 'eigVects=', eigVects
|
||||
# 对特征值,进行从小到大的排序,返回从小到大的index序号
|
||||
# 特征值的逆序就可以得到topNfeat个最大的特征向量
|
||||
'''
|
||||
>>> x = np.array([3, 1, 2])
|
||||
>>> np.argsort(x)
|
||||
array([1, 2, 0]) # index,1 = 1; index,2 = 2; index,0 = 3
|
||||
>>> y = np.argsort(x)
|
||||
>>> y[::-1]
|
||||
array([0, 2, 1])
|
||||
>>> y[:-3:-1]
|
||||
array([0, 2]) # 取出 -1, -2
|
||||
>>> y[:-6:-1]
|
||||
array([0, 2, 1])
|
||||
'''
|
||||
eigValInd = argsort(eigVals)
|
||||
# print 'eigValInd1=', eigValInd
|
||||
|
||||
# -1表示倒序,返回topN的特征值[-1 到 -(topNfeat+1) 但是不包括-(topNfeat+1)本身的倒叙]
|
||||
eigValInd = eigValInd[:-(topNfeat+1):-1]
|
||||
# print 'eigValInd2=', eigValInd
|
||||
# 重组 eigVects 最大到最小
|
||||
redEigVects = eigVects[:, eigValInd]
|
||||
# print 'redEigVects=', redEigVects.T
|
||||
# 将数据转换到新空间
|
||||
# print "---", shape(meanRemoved), shape(redEigVects)
|
||||
lowDDataMat = meanRemoved * redEigVects
|
||||
reconMat = (lowDDataMat * redEigVects.T) + meanVals
|
||||
# print 'lowDDataMat=', lowDDataMat
|
||||
# print 'reconMat=', reconMat
|
||||
return lowDDataMat, reconMat
|
||||
|
||||
|
||||
def replaceNanWithMean():
|
||||
datMat = loadDataSet('data/13.PCA/secom.data', ' ')
|
||||
numFeat = shape(datMat)[1]
|
||||
for i in range(numFeat):
|
||||
# 对value不为NaN的求均值
|
||||
# .A 返回矩阵基于的数组
|
||||
meanVal = mean(datMat[nonzero(~isnan(datMat[:, i].A))[0], i])
|
||||
# 将value为NaN的值赋值为均值
|
||||
datMat[nonzero(isnan(datMat[:, i].A))[0],i] = meanVal
|
||||
return datMat
|
||||
|
||||
|
||||
def show_picture(dataMat, reconMat):
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.scatter(dataMat[:, 0].flatten().A[0], dataMat[:, 1].flatten().A[0], marker='^', s=90)
|
||||
ax.scatter(reconMat[:, 0].flatten().A[0], reconMat[:, 1].flatten().A[0], marker='o', s=50, c='red')
|
||||
plt.show()
|
||||
|
||||
|
||||
def analyse_data(dataMat):
|
||||
meanVals = mean(dataMat, axis=0)
|
||||
meanRemoved = dataMat-meanVals
|
||||
covMat = cov(meanRemoved, rowvar=0)
|
||||
eigvals, eigVects = linalg.eig(mat(covMat))
|
||||
eigValInd = argsort(eigvals)
|
||||
|
||||
topNfeat = 20
|
||||
eigValInd = eigValInd[:-(topNfeat+1):-1]
|
||||
cov_all_score = float(sum(eigvals))
|
||||
sum_cov_score = 0
|
||||
for i in range(0, len(eigValInd)):
|
||||
line_cov_score = float(eigvals[eigValInd[i]])
|
||||
sum_cov_score += line_cov_score
|
||||
'''
|
||||
我们发现其中有超过20%的特征值都是0。
|
||||
这就意味着这些特征都是其他特征的副本,也就是说,它们可以通过其他特征来表示,而本身并没有提供额外的信息。
|
||||
|
||||
最前面15个值的数量级大于10^5,实际上那以后的值都变得非常小。
|
||||
这就相当于告诉我们只有部分重要特征,重要特征的数目也很快就会下降。
|
||||
|
||||
最后,我们可能会注意到有一些小的负值,他们主要源自数值误差应该四舍五入成0.
|
||||
'''
|
||||
print('主成分:%s, 方差占比:%s%%, 累积方差占比:%s%%' % (format(i+1, '2.0f'), format(line_cov_score/cov_all_score*100, '4.2f'), format(sum_cov_score/cov_all_score*100, '4.1f')))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# # 加载数据,并转化数据类型为float
|
||||
# dataMat = loadDataSet('data/13.PCA/testSet.txt')
|
||||
# # 只需要1个特征向量
|
||||
# lowDmat, reconMat = pca(dataMat, 1)
|
||||
# # 只需要2个特征向量,和原始数据一致,没任何变化
|
||||
# # lowDmat, reconMat = pca(dataMat, 2)
|
||||
# # print shape(lowDmat)
|
||||
# show_picture(dataMat, reconMat)
|
||||
|
||||
# 利用PCA对半导体制造数据降维
|
||||
dataMat = replaceNanWithMean()
|
||||
print(shape(dataMat))
|
||||
# 分析数据
|
||||
analyse_data(dataMat)
|
||||
# lowDmat, reconMat = pca(dataMat, 20)
|
||||
# print shape(lowDmat)
|
||||
# show_picture(dataMat, reconMat)
|
||||
|
|
@ -0,0 +1,363 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf-8
|
||||
|
||||
'''
|
||||
Created on Mar 8, 2011
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/山上有课树/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import linalg as la
|
||||
from numpy import *
|
||||
|
||||
|
||||
def loadExData3():
|
||||
# 利用SVD提高推荐效果,菜肴矩阵
|
||||
return[[2, 0, 0, 4, 4, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
|
||||
[0, 0, 0, 0, 0, 0, 0, 1, 0, 4, 0],
|
||||
[3, 3, 4, 0, 3, 0, 0, 2, 2, 0, 0],
|
||||
[5, 5, 5, 0, 0, 0, 0, 0, 0, 0, 0],
|
||||
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
|
||||
[4, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5],
|
||||
[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 4],
|
||||
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
|
||||
[0, 0, 0, 3, 0, 0, 0, 0, 4, 5, 0],
|
||||
[1, 1, 2, 1, 1, 2, 1, 0, 4, 5, 0]]
|
||||
|
||||
|
||||
def loadExData2():
|
||||
# 书上代码给的示例矩阵
|
||||
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
|
||||
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
|
||||
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
|
||||
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
|
||||
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
|
||||
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
|
||||
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
|
||||
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
|
||||
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
|
||||
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
|
||||
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
|
||||
|
||||
|
||||
def loadExData():
|
||||
"""
|
||||
# 推荐引擎示例矩阵
|
||||
return[[4, 4, 0, 2, 2],
|
||||
[4, 0, 0, 3, 3],
|
||||
[4, 0, 0, 1, 1],
|
||||
[1, 1, 1, 2, 0],
|
||||
[2, 2, 2, 0, 0],
|
||||
[1, 1, 1, 0, 0],
|
||||
[5, 5, 5, 0, 0]]
|
||||
"""
|
||||
# # 原矩阵
|
||||
# return[[1, 1, 1, 0, 0],
|
||||
# [2, 2, 2, 0, 0],
|
||||
# [1, 1, 1, 0, 0],
|
||||
# [5, 5, 5, 0, 0],
|
||||
# [1, 1, 0, 2, 2],
|
||||
# [0, 0, 0, 3, 3],
|
||||
# [0, 0, 0, 1, 1]]
|
||||
|
||||
# 原矩阵
|
||||
return[[0, -1.6, 0.6],
|
||||
[0, 1.2, 0.8],
|
||||
[0, 0, 0],
|
||||
[0, 0, 0]]
|
||||
|
||||
|
||||
# 相似度计算,假定inA和inB 都是列向量
|
||||
# 基于欧氏距离
|
||||
def ecludSim(inA, inB):
|
||||
return 1.0/(1.0 + la.norm(inA - inB))
|
||||
|
||||
|
||||
# pearsSim()函数会检查是否存在3个或更多的点。
|
||||
# corrcoef直接计算皮尔逊相关系数,范围[-1, 1],归一化后[0, 1]
|
||||
def pearsSim(inA, inB):
|
||||
# 如果不存在,该函数返回1.0,此时两个向量完全相关。
|
||||
if len(inA) < 3:
|
||||
return 1.0
|
||||
return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1]
|
||||
|
||||
|
||||
# 计算余弦相似度,如果夹角为90度,相似度为0;如果两个向量的方向相同,相似度为1.0
|
||||
def cosSim(inA, inB):
|
||||
num = float(inA.T*inB)
|
||||
denom = la.norm(inA)*la.norm(inB)
|
||||
return 0.5 + 0.5*(num/denom)
|
||||
|
||||
|
||||
# 基于物品相似度的推荐引擎
|
||||
def standEst(dataMat, user, simMeas, item):
|
||||
"""standEst(计算某用户未评分物品中,以对该物品和其他物品评分的用户的物品相似度,然后进行综合评分)
|
||||
|
||||
Args:
|
||||
dataMat 训练数据集
|
||||
user 用户编号
|
||||
simMeas 相似度计算方法
|
||||
item 未评分的物品编号
|
||||
Returns:
|
||||
ratSimTotal/simTotal 评分(0~5之间的值)
|
||||
"""
|
||||
# 得到数据集中的物品数目
|
||||
n = shape(dataMat)[1]
|
||||
# 初始化两个评分值
|
||||
simTotal = 0.0
|
||||
ratSimTotal = 0.0
|
||||
# 遍历行中的每个物品(对用户评过分的物品进行遍历,并将它与其他物品进行比较)
|
||||
for j in range(n):
|
||||
userRating = dataMat[user, j]
|
||||
# 如果某个物品的评分值为0,则跳过这个物品
|
||||
if userRating == 0:
|
||||
continue
|
||||
# 寻找两个用户都评级的物品
|
||||
# 变量 overLap 给出的是两个物品当中已经被评分的那个元素的索引ID
|
||||
# logical_and 计算x1和x2元素的真值。
|
||||
overLap = nonzero(logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0]
|
||||
# 如果相似度为0,则两着没有任何重合元素,终止本次循环
|
||||
if len(overLap) == 0:
|
||||
similarity = 0
|
||||
# 如果存在重合的物品,则基于这些重合物重新计算相似度。
|
||||
else:
|
||||
similarity = simMeas(dataMat[overLap, item], dataMat[overLap, j])
|
||||
# print 'the %d and %d similarity is : %f'(iten,j,similarity)
|
||||
# 相似度会不断累加,每次计算时还考虑相似度和当前用户评分的乘积
|
||||
# similarity 用户相似度, userRating 用户评分
|
||||
simTotal += similarity
|
||||
ratSimTotal += similarity * userRating
|
||||
if simTotal == 0:
|
||||
return 0
|
||||
# 通过除以所有的评分总和,对上述相似度评分的乘积进行归一化,使得最后评分在0~5之间,这些评分用来对预测值进行排序
|
||||
else:
|
||||
return ratSimTotal/simTotal
|
||||
|
||||
|
||||
# 基于SVD的评分估计
|
||||
# 在recommend() 中,这个函数用于替换对standEst()的调用,该函数对给定用户给定物品构建了一个评分估计值
|
||||
def svdEst(dataMat, user, simMeas, item):
|
||||
"""svdEst( )
|
||||
|
||||
Args:
|
||||
dataMat 训练数据集
|
||||
user 用户编号
|
||||
simMeas 相似度计算方法
|
||||
item 未评分的物品编号
|
||||
Returns:
|
||||
ratSimTotal/simTotal 评分(0~5之间的值)
|
||||
"""
|
||||
# 物品数目
|
||||
n = shape(dataMat)[1]
|
||||
# 对数据集进行SVD分解
|
||||
simTotal = 0.0
|
||||
ratSimTotal = 0.0
|
||||
# 奇异值分解
|
||||
# 在SVD分解之后,我们只利用包含了90%能量值的奇异值,这些奇异值会以NumPy数组的形式得以保存
|
||||
U, Sigma, VT = la.svd(dataMat)
|
||||
|
||||
# # 分析 Sigma 的长度取值
|
||||
# analyse_data(Sigma, 20)
|
||||
|
||||
# 如果要进行矩阵运算,就必须要用这些奇异值构建出一个对角矩阵
|
||||
Sig4 = mat(eye(4) * Sigma[: 4])
|
||||
|
||||
# 利用U矩阵将物品转换到低维空间中,构建转换后的物品(物品+4个主要的特征)
|
||||
xformedItems = dataMat.T * U[:, :4] * Sig4.I
|
||||
print('dataMat', shape(dataMat))
|
||||
print('U[:, :4]', shape(U[:, :4]))
|
||||
print('Sig4.I', shape(Sig4.I))
|
||||
print('VT[:4, :]', shape(VT[:4, :]))
|
||||
print('xformedItems', shape(xformedItems))
|
||||
|
||||
# 对于给定的用户,for循环在用户对应行的元素上进行遍历
|
||||
# 这和standEst()函数中的for循环的目的一样,只不过这里的相似度计算时在低维空间下进行的。
|
||||
for j in range(n):
|
||||
userRating = dataMat[user, j]
|
||||
if userRating == 0 or j == item:
|
||||
continue
|
||||
# 相似度的计算方法也会作为一个参数传递给该函数
|
||||
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
|
||||
# for 循环中加入了一条print语句,以便了解相似度计算的进展情况。如果觉得累赘,可以去掉
|
||||
print('the %d and %d similarity is: %f' % (item, j, similarity))
|
||||
# 对相似度不断累加求和
|
||||
simTotal += similarity
|
||||
# 对相似度及对应评分值的乘积求和
|
||||
ratSimTotal += similarity * userRating
|
||||
if simTotal == 0:
|
||||
return 0
|
||||
else:
|
||||
# 计算估计评分
|
||||
return ratSimTotal/simTotal
|
||||
|
||||
|
||||
# recommend()函数,就是推荐引擎,它默认调用standEst()函数,产生了最高的N个推荐结果。
|
||||
# 如果不指定N的大小,则默认值为3。该函数另外的参数还包括相似度计算方法和估计方法
|
||||
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
|
||||
"""svdEst( )
|
||||
|
||||
Args:
|
||||
dataMat 训练数据集
|
||||
user 用户编号
|
||||
simMeas 相似度计算方法
|
||||
estMethod 使用的推荐算法
|
||||
Returns:
|
||||
返回最终 N 个推荐结果
|
||||
"""
|
||||
# 寻找未评级的物品
|
||||
# 对给定的用户建立一个未评分的物品列表
|
||||
unratedItems = nonzero(dataMat[user, :].A == 0)[1]
|
||||
# 如果不存在未评分物品,那么就退出函数
|
||||
if len(unratedItems) == 0:
|
||||
return 'you rated everything'
|
||||
# 物品的编号和评分值
|
||||
itemScores = []
|
||||
# 在未评分物品上进行循环
|
||||
for item in unratedItems:
|
||||
# 获取 item 该物品的评分
|
||||
estimatedScore = estMethod(dataMat, user, simMeas, item)
|
||||
itemScores.append((item, estimatedScore))
|
||||
# 按照评分得分 进行逆排序,获取前N个未评级物品进行推荐
|
||||
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[: N]
|
||||
|
||||
|
||||
def analyse_data(Sigma, loopNum=20):
|
||||
"""analyse_data(分析 Sigma 的长度取值)
|
||||
|
||||
Args:
|
||||
Sigma Sigma的值
|
||||
loopNum 循环次数
|
||||
"""
|
||||
# 总方差的集合(总能量值)
|
||||
Sig2 = Sigma**2
|
||||
SigmaSum = sum(Sig2)
|
||||
for i in range(loopNum):
|
||||
SigmaI = sum(Sig2[:i+1])
|
||||
'''
|
||||
根据自己的业务情况,就行处理,设置对应的 Singma 次数
|
||||
|
||||
通常保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并取出噪声。
|
||||
'''
|
||||
print('主成分:%s, 方差占比:%s%%' % (format(i+1, '2.0f'), format(SigmaI/SigmaSum*100, '4.2f')))
|
||||
|
||||
|
||||
# 图像压缩函数
|
||||
# 加载并转换数据
|
||||
def imgLoadData(filename):
|
||||
myl = []
|
||||
# 打开文本文件,并从文件以数组方式读入字符
|
||||
for line in open(filename).readlines():
|
||||
newRow = []
|
||||
for i in range(32):
|
||||
newRow.append(int(line[i]))
|
||||
myl.append(newRow)
|
||||
# 矩阵调入后,就可以在屏幕上输出该矩阵
|
||||
myMat = mat(myl)
|
||||
return myMat
|
||||
|
||||
|
||||
# 打印矩阵
|
||||
def printMat(inMat, thresh=0.8):
|
||||
# 由于矩阵保护了浮点数,因此定义浅色和深色,遍历所有矩阵元素,当元素大于阀值时打印1,否则打印0
|
||||
for i in range(32):
|
||||
for k in range(32):
|
||||
if float(inMat[i, k]) > thresh:
|
||||
print(1, end=' ')
|
||||
else:
|
||||
print(0, end=' ')
|
||||
print('')
|
||||
|
||||
|
||||
# 实现图像压缩,允许基于任意给定的奇异值数目来重构图像
|
||||
def imgCompress(numSV=3, thresh=0.8):
|
||||
"""imgCompress( )
|
||||
|
||||
Args:
|
||||
numSV Sigma长度
|
||||
thresh 判断的阈值
|
||||
"""
|
||||
# 构建一个列表
|
||||
myMat = imgLoadData('data/14.SVD/0_5.txt')
|
||||
|
||||
print("****original matrix****")
|
||||
# 对原始图像进行SVD分解并重构图像e
|
||||
printMat(myMat, thresh)
|
||||
|
||||
# 通过Sigma 重新构成SigRecom来实现
|
||||
# Sigma是一个对角矩阵,因此需要建立一个全0矩阵,然后将前面的那些奇异值填充到对角线上。
|
||||
U, Sigma, VT = la.svd(myMat)
|
||||
# SigRecon = mat(zeros((numSV, numSV)))
|
||||
# for k in range(numSV):
|
||||
# SigRecon[k, k] = Sigma[k]
|
||||
|
||||
# 分析插入的 Sigma 长度
|
||||
analyse_data(Sigma, 20)
|
||||
|
||||
SigRecon = mat(eye(numSV) * Sigma[: numSV])
|
||||
reconMat = U[:, :numSV] * SigRecon * VT[:numSV, :]
|
||||
print("****reconstructed matrix using %d singular values *****" % numSV)
|
||||
printMat(reconMat, thresh)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# # 对矩阵进行SVD分解(用python实现SVD)
|
||||
# Data = loadExData()
|
||||
# print 'Data:', Data
|
||||
# U, Sigma, VT = linalg.svd(Data)
|
||||
# # 打印Sigma的结果,因为前3个数值比其他的值大了很多,为9.72140007e+00,5.29397912e+00,6.84226362e-01
|
||||
# # 后两个值比较小,每台机器输出结果可能有不同可以将这两个值去掉
|
||||
# print 'U:', U
|
||||
# print 'Sigma', Sigma
|
||||
# print 'VT:', VT
|
||||
# print 'VT:', VT.T
|
||||
|
||||
# # 重构一个3x3的矩阵Sig3
|
||||
# Sig3 = mat([[Sigma[0], 0, 0], [0, Sigma[1], 0], [0, 0, Sigma[2]]])
|
||||
# print U[:, :3] * Sig3 * VT[:3, :]
|
||||
|
||||
"""
|
||||
# 计算欧氏距离
|
||||
myMat = mat(loadExData())
|
||||
# print myMat
|
||||
print ecludSim(myMat[:, 0], myMat[:, 4])
|
||||
print ecludSim(myMat[:, 0], myMat[:, 0])
|
||||
|
||||
# 计算余弦相似度
|
||||
print cosSim(myMat[:, 0], myMat[:, 4])
|
||||
print cosSim(myMat[:, 0], myMat[:, 0])
|
||||
|
||||
# 计算皮尔逊相关系数
|
||||
print pearsSim(myMat[:, 0], myMat[:, 4])
|
||||
print pearsSim(myMat[:, 0], myMat[:, 0])
|
||||
|
||||
"""
|
||||
|
||||
# 计算相似度的方法
|
||||
myMat = mat(loadExData3())
|
||||
# print myMat
|
||||
# 计算相似度的第一种方式
|
||||
print(recommend(myMat, 1, estMethod=svdEst))
|
||||
# 计算相似度的第二种方式
|
||||
print(recommend(myMat, 1, estMethod=svdEst, simMeas=pearsSim))
|
||||
|
||||
# 默认推荐(菜馆菜肴推荐示例)
|
||||
print(recommend(myMat, 2))
|
||||
|
||||
"""
|
||||
# 利用SVD提高推荐效果
|
||||
U, Sigma, VT = la.svd(mat(loadExData2()))
|
||||
print Sigma # 计算矩阵的SVD来了解其需要多少维的特征
|
||||
Sig2 = Sigma**2 # 计算需要多少个奇异值能达到总能量的90%
|
||||
print sum(Sig2) # 计算总能量
|
||||
print sum(Sig2) * 0.9 # 计算总能量的90%
|
||||
print sum(Sig2[: 2]) # 计算前两个元素所包含的能量
|
||||
print sum(Sig2[: 3]) # 两个元素的能量值小于总能量的90%,于是计算前三个元素所包含的能量
|
||||
# 该值高于总能量的90%,这就可以了
|
||||
|
||||
"""
|
||||
|
||||
# 压缩图片
|
||||
# imgCompress(2)
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on 2017-04-07
|
||||
Update on 2017-06-20
|
||||
Author: Peter/ApacheCN-xy/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from mrjob.job import MRJob
|
||||
|
||||
|
||||
class MRmean(MRJob):
|
||||
def __init__(self, *args, **kwargs): # 对数据初始化
|
||||
super(MRmean, self).__init__(*args, **kwargs)
|
||||
self.inCount = 0
|
||||
self.inSum = 0
|
||||
self.inSqSum = 0
|
||||
|
||||
# 接受输入数据流
|
||||
def map(self, key, val): # 需要 2 个参数,求数据的和与平方和
|
||||
if False:
|
||||
yield
|
||||
inVal = float(val)
|
||||
self.inCount += 1
|
||||
self.inSum += inVal
|
||||
self.inSqSum += inVal*inVal
|
||||
|
||||
# 所有输入到达后开始处理
|
||||
def map_final(self): # 计算数据的平均值,平方的均值,并返回
|
||||
mn = self.inSum/self.inCount
|
||||
mnSq = self.inSqSum/self.inCount
|
||||
yield (1, [self.inCount, mn, mnSq])
|
||||
|
||||
def reduce(self, key, packedValues):
|
||||
cumN, cumVal, cumSumSq = 0.0, 0.0, 0.0
|
||||
for valArr in packedValues: # 从输入流中获取值
|
||||
nj = float(valArr[0])
|
||||
cumN += nj
|
||||
cumVal += nj*float(valArr[1])
|
||||
cumSumSq += nj*float(valArr[2])
|
||||
mean = cumVal/cumN
|
||||
var = (cumSumSq - 2*mean*cumVal + cumN*mean*mean)/cumN
|
||||
yield (mean, var) # 发出平均值和方差
|
||||
|
||||
def steps(self):
|
||||
"""
|
||||
step方法定义执行的步骤。
|
||||
执行顺序不必完全遵循map-reduce模式。
|
||||
例如:
|
||||
1. map-reduce-reduce-reduce
|
||||
2. map-reduce-map-reduce-map-reduce
|
||||
在step方法里,需要为mrjob指定mapper和reducer的名称。如果没有,它将默认调用mapper和reducer方法。
|
||||
|
||||
在mapper 和 mapper_final中还可以共享状态,mapper 或 mapper_final 不能 reducer之间共享状态。
|
||||
"""
|
||||
return ([self.mr(mapper=self.map, mapper_final=self.map_final, reducer=self.reduce,)])
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
MRmean.run()
|
||||
|
|
@ -0,0 +1,41 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on 2017-04-06
|
||||
Update on 2017-06-20
|
||||
Machine Learning in Action Chapter 18
|
||||
Map Reduce Job for Hadoop Streaming
|
||||
Author: Peter/ApacheCN-xy/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
import sys
|
||||
from numpy import mat, mean, power
|
||||
|
||||
'''
|
||||
这个mapper文件按行读取所有的输入并创建一组对应的浮点数,然后得到数组的长度并创建NumPy矩阵。
|
||||
再对所有的值进行平方,最后将均值和平方后的均值发送出去。这些值将用来计算全局的均值和方差。
|
||||
|
||||
Args:
|
||||
file 输入数据
|
||||
Return:
|
||||
'''
|
||||
|
||||
|
||||
def read_input(file):
|
||||
for line in file:
|
||||
yield line.rstrip() # 返回一个 yield 迭代器,每次获取下一个值,节约内存。
|
||||
|
||||
|
||||
input = read_input(sys.stdin) # 创建一个输入的数据行的列表list
|
||||
input = [float(line) for line in input] # 将得到的数据转化为 float 类型
|
||||
numInputs = len(input) # 获取数据的个数,即输入文件的数据的行数
|
||||
input = mat(input) # 将 List 转换为矩阵
|
||||
sqInput = power(input, 2) # 将矩阵的数据分别求 平方,即 2次方
|
||||
|
||||
# 输出 数据的个数,n个数据的均值,n个数据平方之后的均值
|
||||
# 第一行是标准输出,也就是reducer的输出
|
||||
# 第二行识标准错误输出,即对主节点作出的响应报告,表明本节点工作正常。
|
||||
# 【这不就是面试的装逼重点吗?如何设计监听架构细节】注意:一个好的习惯是想标准错误输出发送报告。如果某任务10分钟内没有报告输出,则将被Hadoop中止。
|
||||
print("%d\t%f\t%f" % (numInputs, mean(input), mean(sqInput))) # 计算均值
|
||||
print("map report: still alive", file=sys.stderr)
|
||||
|
|
@ -0,0 +1,47 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on 2017-04-06
|
||||
Update on 2017-06-20
|
||||
Machine Learning in Action Chapter 18
|
||||
Map Reduce Job for Hadoop Streaming
|
||||
Author: Peter/ApacheCN-xy/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
import sys
|
||||
|
||||
'''
|
||||
mapper 接受原始的输入并产生中间值传递给 reducer。
|
||||
很多的mapper是并行执行的,所以需要将这些mapper的输出合并成一个值。
|
||||
即:将中间的 key/value 对进行组合。
|
||||
'''
|
||||
|
||||
|
||||
def read_input(file):
|
||||
for line in file:
|
||||
yield line.rstrip() # 返回值中包含输入文件的每一行的数据的一个大的List
|
||||
|
||||
|
||||
input = read_input(sys.stdin) # 创建一个输入的数据行的列表list
|
||||
|
||||
# 将输入行分割成单独的项目并存储在列表的列表中
|
||||
mapperOut = [line.split('\t') for line in input]
|
||||
# 输入 数据的个数,n个数据的均值,n个数据平方之后的均值
|
||||
print (mapperOut)
|
||||
|
||||
# 累计样本总和,总和 和 平分和的总和
|
||||
cumN, cumVal, cumSumSq = 0.0, 0.0, 0.0
|
||||
for instance in mapperOut:
|
||||
nj = float(instance[0])
|
||||
cumN += nj
|
||||
cumVal += nj*float(instance[1])
|
||||
cumSumSq += nj*float(instance[2])
|
||||
|
||||
# 计算均值( varSum是计算方差的展开形式 )
|
||||
mean_ = cumVal/cumN
|
||||
varSum = (cumSumSq - 2*mean_*cumVal + cumN*mean_*mean_)/cumN
|
||||
# 输出 数据总量,均值,平方的均值(方差)
|
||||
print ("数据总量:%d\t均值:%f\t方差:%f" % (cumN, mean_, varSum))
|
||||
print("reduce report: still alive", file=sys.stderr)
|
||||
|
|
@ -0,0 +1,95 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on 2017-04-07
|
||||
Update on 2017-06-20
|
||||
MapReduce version of Pegasos SVM
|
||||
Using mrjob to automate job flow
|
||||
Author: Peter/ApacheCN-xy/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from mrjob.job import MRJob
|
||||
|
||||
import pickle
|
||||
from numpy import *
|
||||
|
||||
|
||||
class MRsvm(MRJob):
|
||||
DEFAULT_INPUT_PROTOCOL = 'json_value'
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super(MRsvm, self).__init__(*args, **kwargs)
|
||||
self.data = pickle.load(open('/opt/git/MachineLearnidata/15.BigData_MapReduce/svmDat27'))
|
||||
self.w = 0
|
||||
self.eta = 0.69
|
||||
self.dataList = []
|
||||
self.k = self.options.batchsize
|
||||
self.numMappers = 1
|
||||
self.t = 1 # iteration number
|
||||
|
||||
def configure_options(self):
|
||||
super(MRsvm, self).configure_options()
|
||||
self.add_passthrough_option(
|
||||
'--iterations', dest='iterations', default=2, type='int',
|
||||
help='T: number of iterations to run')
|
||||
self.add_passthrough_option(
|
||||
'--batchsize', dest='batchsize', default=100, type='int',
|
||||
help='k: number of data points in a batch')
|
||||
|
||||
def map(self, mapperId, inVals): # 需要 2 个参数
|
||||
# input: nodeId, ('w', w-vector) OR nodeId, ('x', int)
|
||||
if False:
|
||||
yield
|
||||
if inVals[0] == 'w': # 积累 w向量
|
||||
self.w = inVals[1]
|
||||
elif inVals[0] == 'x':
|
||||
self.dataList.append(inVals[1]) # 累积数据点计算
|
||||
elif inVals[0] == 't': # 迭代次数
|
||||
self.t = inVals[1]
|
||||
else:
|
||||
self.eta = inVals # 这用于 debug, eta未在map中使用
|
||||
|
||||
def map_fin(self):
|
||||
labels = self.data[:, -1]
|
||||
X = self.data[:, :-1] # 将数据重新形成 X 和 Y
|
||||
if self.w == 0:
|
||||
self.w = [0.001] * shape(X)[1] # 在第一次迭代时,初始化 w
|
||||
for index in self.dataList:
|
||||
p = mat(self.w)*X[index, :].T # calc p=w*dataSet[key].T
|
||||
if labels[index]*p < 1.0:
|
||||
yield (1, ['u', index]) # 确保一切数据包含相同的key
|
||||
yield (1, ['w', self.w]) # 它们将在同一个 reducer
|
||||
yield (1, ['t', self.t])
|
||||
|
||||
def reduce(self, _, packedVals):
|
||||
for valArr in packedVals: # 从流输入获取值
|
||||
if valArr[0] == 'u':
|
||||
self.dataList.append(valArr[1])
|
||||
elif valArr[0] == 'w':
|
||||
self.w = valArr[1]
|
||||
elif valArr[0] == 't':
|
||||
self.t = valArr[1]
|
||||
|
||||
labels = self.data[:, -1]
|
||||
X = self.data[:, 0:-1]
|
||||
wMat = mat(self.w)
|
||||
wDelta = mat(zeros(len(self.w)))
|
||||
|
||||
for index in self.dataList:
|
||||
wDelta += float(labels[index]) * X[index, :] # wDelta += label*dataSet
|
||||
eta = 1.0/(2.0*self.t) # calc new: eta
|
||||
# calc new: w = (1.0 - 1/t)*w + (eta/k)*wDelta
|
||||
wMat = (1.0 - 1.0/self.t)*wMat + (eta/self.k)*wDelta
|
||||
for mapperNum in range(1, self.numMappers+1):
|
||||
yield (mapperNum, ['w', wMat.tolist()[0]]) # 发出 w
|
||||
if self.t < self.options.iterations:
|
||||
yield (mapperNum, ['t', self.t+1]) # 增量 T
|
||||
for j in range(self.k/self.numMappers): # emit random ints for mappers iid
|
||||
yield (mapperNum, ['x', random.randint(shape(self.data)[0])])
|
||||
|
||||
def steps(self):
|
||||
return ([self.mr(mapper=self.map, reducer=self.reduce, mapper_final=self.map_fin)] * self.options.iterations)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
MRsvm.run()
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
'''
|
||||
Created on Feb 27, 2011
|
||||
|
||||
Author: Peter
|
||||
'''
|
||||
from mrjob.protocol import JSONProtocol
|
||||
from numpy import *
|
||||
|
||||
fw=open('kickStart2.txt', 'w')
|
||||
for i in [1]:
|
||||
for j in range(100):
|
||||
fw.write('["x", %d]\n' % random.randint(200))
|
||||
fw.close()
|
||||
|
|
@ -0,0 +1,112 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on 2017-04-07
|
||||
Sequential Pegasos
|
||||
the input T is k*T in Batch Pegasos
|
||||
Author: Peter/ApacheCN-xy
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
# dataMat.append([float(lineArr[0]), float(lineArr[1]), float(lineArr[2])])
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
def seqPegasos(dataSet, labels, lam, T):
|
||||
m, n = shape(dataSet)
|
||||
w = zeros(n)
|
||||
for t in range(1, T+1):
|
||||
i = random.randint(m)
|
||||
eta = 1.0/(lam*t)
|
||||
p = predict(w, dataSet[i, :])
|
||||
if labels[i]*p < 1:
|
||||
w = (1.0 - 1/t)*w + eta*labels[i]*dataSet[i, :]
|
||||
else:
|
||||
w = (1.0 - 1/t)*w
|
||||
print(w)
|
||||
return w
|
||||
|
||||
|
||||
def predict(w, x):
|
||||
return w*x.T # 就是预测 y 的值
|
||||
|
||||
|
||||
def batchPegasos(dataSet, labels, lam, T, k):
|
||||
"""batchPegasos()
|
||||
|
||||
Args:
|
||||
dataMat 特征集合
|
||||
labels 分类结果集合
|
||||
lam 固定值
|
||||
T 迭代次数
|
||||
k 待处理列表大小
|
||||
Returns:
|
||||
w 回归系数
|
||||
"""
|
||||
m, n = shape(dataSet)
|
||||
w = zeros(n) # 回归系数
|
||||
dataIndex = range(m)
|
||||
for t in range(1, T+1):
|
||||
wDelta = mat(zeros(n)) # 重置 wDelta
|
||||
|
||||
# 它是学习率,代表了权重调整幅度的大小。(也可以理解为随机梯度的步长,使它不断减小,便于拟合)
|
||||
# 输入T和K分别设定了迭代次数和待处理列表的大小。在T次迭代过程中,每次需要重新计算eta
|
||||
eta = 1.0/(lam*t)
|
||||
random.shuffle(dataIndex)
|
||||
for j in range(k): # 全部的训练集 内循环中执行批处理,将分类错误的值全部做累加后更新权重向量
|
||||
i = dataIndex[j]
|
||||
p = predict(w, dataSet[i, :]) # mapper 代码
|
||||
|
||||
# 如果预测正确,并且预测结果的绝对值>=1,因为最大间隔为1, 认为没问题。
|
||||
# 否则算是预测错误, 通过预测错误的结果,来累计更新w.
|
||||
if labels[i]*p < 1: # mapper 代码
|
||||
wDelta += labels[i]*dataSet[i, :].A # 累积变化
|
||||
# w通过不断的随机梯度的方式来优化
|
||||
w = (1.0 - 1/t)*w + (eta/k)*wDelta # 在每个 T上应用更改
|
||||
# print '-----', w
|
||||
# print '++++++', w
|
||||
return w
|
||||
|
||||
|
||||
datArr, labelList = loadDataSet('data/15.BigData_MapReduce/testSet.txt')
|
||||
datMat = mat(datArr)
|
||||
# finalWs = seqPegasos(datMat, labelList, 2, 5000)
|
||||
finalWs = batchPegasos(datMat, labelList, 2, 50, 100)
|
||||
print(finalWs)
|
||||
|
||||
import matplotlib
|
||||
import matplotlib.pyplot as plt
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
x1 = []
|
||||
y1 = []
|
||||
xm1 = []
|
||||
ym1 = []
|
||||
for i in range(len(labelList)):
|
||||
if labelList[i] == 1.0:
|
||||
x1.append(datMat[i, 0])
|
||||
y1.append(datMat[i, 1])
|
||||
else:
|
||||
xm1.append(datMat[i, 0])
|
||||
ym1.append(datMat[i, 1])
|
||||
ax.scatter(x1, y1, marker='s', s=90)
|
||||
ax.scatter(xm1, ym1, marker='o', s=50, c='red')
|
||||
x = arange(-6.0, 8.0, 0.1)
|
||||
y = (-finalWs[0, 0]*x - 0)/finalWs[0, 1]
|
||||
# y2 = (0.43799*x)/0.12316
|
||||
y2 = (0.498442*x)/0.092387 # 2 iterations
|
||||
ax.plot(x, y)
|
||||
ax.plot(x, y2, 'g-.')
|
||||
ax.axis([-6, 8, -4, 5])
|
||||
ax.legend(('50 Iterations', '2 Iterations'))
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on 2011-02-25
|
||||
Update on 2017-06-20
|
||||
Author: Peter/ApacheCN-xy/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
import base64
|
||||
import pickle
|
||||
|
||||
import numpy
|
||||
|
||||
|
||||
def map(key, value):
|
||||
# input key= class for one training example, e.g. "-1.0"
|
||||
classes = [float(item) for item in key.split(",")] # e.g. [-1.0]
|
||||
D = numpy.diag(classes)
|
||||
|
||||
# input value = feature vector for one training example, e.g. "3.0, 7.0, 2.0"
|
||||
featurematrix = [float(item) for item in value.split(",")]
|
||||
A = numpy.matrix(featurematrix)
|
||||
|
||||
# create matrix E and vector e
|
||||
e = numpy.matrix(numpy.ones(len(A)).reshape(len(A), 1))
|
||||
E = numpy.matrix(numpy.append(A, -e, axis=1))
|
||||
|
||||
# create a tuple with the values to be used by reducer
|
||||
# and encode it with base64 to avoid potential trouble with '\t' and '\n' used
|
||||
# as default separators in Hadoop Streaming
|
||||
producedvalue = base64.b64encode(pickle.dumps((E.T*E, E.T*D*e)))
|
||||
|
||||
# note: a single constant key "producedkey" sends to only one reducer
|
||||
# somewhat "atypical" due to low degree of parallism on reducer side
|
||||
print("producedkey\t%s" % (producedvalue))
|
||||
|
||||
def reduce(key, values, mu=0.1):
|
||||
sumETE = None
|
||||
sumETDe = None
|
||||
|
||||
# key isn't used, so ignoring it with _ (underscore).
|
||||
for _, value in values:
|
||||
# unpickle values
|
||||
ETE, ETDe = pickle.loads(base64.b64decode(value))
|
||||
if sumETE == None:
|
||||
# create the I/mu with correct dimensions
|
||||
sumETE = numpy.matrix(numpy.eye(ETE.shape[1])/mu)
|
||||
sumETE += ETE
|
||||
|
||||
if sumETDe == None:
|
||||
# create sumETDe with correct dimensions
|
||||
sumETDe = ETDe
|
||||
else:
|
||||
sumETDe += ETDe
|
||||
|
||||
# note: omega = result[:-1] and gamma = result[-1]
|
||||
# but printing entire vector as output
|
||||
result = sumETE.I*sumETDe
|
||||
print("%s\t%s" % (key, str(result.tolist())))
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
'''
|
||||
Created on Feb 27, 2011
|
||||
MapReduce version of Pegasos SVM
|
||||
Using mrjob to automate job flow
|
||||
Author: Peter
|
||||
'''
|
||||
from mrjob.job import MRJob
|
||||
|
||||
import pickle
|
||||
from numpy import *
|
||||
|
||||
class MRsvm(MRJob):
|
||||
|
||||
def map(self, mapperId, inVals): #needs exactly 2 arguments
|
||||
if False: yield
|
||||
yield (1, 22)
|
||||
|
||||
def reduce(self, _, packedVals):
|
||||
yield "fuck ass"
|
||||
|
||||
def steps(self):
|
||||
return ([self.mr(mapper=self.map, reducer=self.reduce)])
|
||||
|
||||
if __name__ == '__main__':
|
||||
MRsvm.run()
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
from mrjob.job import MRJob
|
||||
|
||||
|
||||
class MRWordCountUtility(MRJob):
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super(MRWordCountUtility, self).__init__(*args, **kwargs)
|
||||
self.chars = 0
|
||||
self.words = 0
|
||||
self.lines = 0
|
||||
|
||||
def mapper(self, _, line):
|
||||
if False:
|
||||
yield # I'm a generator!
|
||||
|
||||
self.chars += len(line) + 1 # +1 for newline
|
||||
self.words += sum(1 for word in line.split() if word.strip())
|
||||
self.lines += 1
|
||||
|
||||
def mapper_final(self):
|
||||
yield('chars', self.chars)
|
||||
yield('words', self.words)
|
||||
yield('lines', self.lines)
|
||||
|
||||
def reducer(self, key, values):
|
||||
yield(key, sum(values))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
MRWordCountUtility.run()
|
||||
|
|
@ -0,0 +1,298 @@
|
|||
#!/usr/bin/env python
|
||||
# coding: utf-8
|
||||
'''
|
||||
Created on Sep 16, 2010
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/羊三/小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
# 导入科学计算包numpy和运算符模块operator
|
||||
import operator
|
||||
from os import listdir
|
||||
from collections import Counter
|
||||
|
||||
|
||||
def createDataSet():
|
||||
"""
|
||||
创建数据集和标签
|
||||
|
||||
调用方式
|
||||
import kNN
|
||||
group, labels = kNN.createDataSet()
|
||||
"""
|
||||
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
|
||||
labels = ['A', 'A', 'B', 'B']
|
||||
return group, labels
|
||||
|
||||
|
||||
def classify0(inX, dataSet, labels, k):
|
||||
"""
|
||||
inx[1,2,3]
|
||||
DS=[[1,2,3],[1,2,0]]
|
||||
inX: 用于分类的输入向量
|
||||
dataSet: 输入的训练样本集
|
||||
labels: 标签向量
|
||||
k: 选择最近邻居的数目
|
||||
注意:labels元素数目和dataSet行数相同;程序使用欧式距离公式.
|
||||
|
||||
预测数据所在分类可在输入下列命令
|
||||
kNN.classify0([0,0], group, labels, 3)
|
||||
"""
|
||||
|
||||
# -----------实现 classify0() 方法的第一种方式----------------------------------------------------------------------------------------------------------------------------
|
||||
# 1. 距离计算
|
||||
dataSetSize = dataSet.shape[0]
|
||||
# tile生成和训练样本对应的矩阵,并与训练样本求差
|
||||
"""
|
||||
tile: 列-3表示复制的行数, 行-1/2表示对inx的重复的次数
|
||||
|
||||
In [8]: tile(inx, (3, 1))
|
||||
Out[8]:
|
||||
array([[1, 2, 3],
|
||||
[1, 2, 3],
|
||||
[1, 2, 3]])
|
||||
|
||||
In [9]: tile(inx, (3, 2))
|
||||
Out[9]:
|
||||
array([[1, 2, 3, 1, 2, 3],
|
||||
[1, 2, 3, 1, 2, 3],
|
||||
[1, 2, 3, 1, 2, 3]])
|
||||
"""
|
||||
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
|
||||
"""
|
||||
欧氏距离: 点到点之间的距离
|
||||
第一行: 同一个点 到 dataSet的第一个点的距离。
|
||||
第二行: 同一个点 到 dataSet的第二个点的距离。
|
||||
...
|
||||
第N行: 同一个点 到 dataSet的第N个点的距离。
|
||||
|
||||
[[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]]
|
||||
(A1-A2)^2+(B1-B2)^2+(c1-c2)^2
|
||||
"""
|
||||
# 取平方
|
||||
sqDiffMat = diffMat ** 2
|
||||
# 将矩阵的每一行相加
|
||||
sqDistances = sqDiffMat.sum(axis=1)
|
||||
# 开方
|
||||
distances = sqDistances ** 0.5
|
||||
# 根据距离排序从小到大的排序,返回对应的索引位置
|
||||
# argsort() 是将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。
|
||||
# 例如:y=array([3,0,2,1,4,5]) 则,x[3]=-1最小,所以y[0]=3;x[5]=9最大,所以y[5]=5。
|
||||
# print 'distances=', distances
|
||||
sortedDistIndicies = distances.argsort()
|
||||
# print 'distances.argsort()=', sortedDistIndicies
|
||||
|
||||
# 2. 选择距离最小的k个点
|
||||
classCount = {}
|
||||
for i in range(k):
|
||||
# 找到该样本的类型
|
||||
voteIlabel = labels[sortedDistIndicies[i]]
|
||||
# 在字典中将该类型加一
|
||||
# 字典的get方法
|
||||
# 如:list.get(k,d) 其中 get相当于一条if...else...语句,参数k在字典中,字典将返回list[k];如果参数k不在字典中则返回参数d,如果K在字典中则返回k对应的value值
|
||||
# l = {5:2,3:4}
|
||||
# print l.get(3,0)返回的值是4;
|
||||
# Print l.get(1,0)返回值是0;
|
||||
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
|
||||
# 3. 排序并返回出现最多的那个类型
|
||||
# 字典的 items() 方法,以列表返回可遍历的(键,值)元组数组。
|
||||
# 例如:dict = {'Name': 'Zara', 'Age': 7} print "Value : %s" % dict.items() Value : [('Age', 7), ('Name', 'Zara')]
|
||||
# sorted 中的第2个参数 key=operator.itemgetter(1) 这个参数的意思是先比较第几个元素
|
||||
# 例如:a=[('b',2),('a',1),('c',0)] b=sorted(a,key=operator.itemgetter(1)) >>>b=[('c',0),('a',1),('b',2)] 可以看到排序是按照后边的0,1,2进行排序的,而不是a,b,c
|
||||
# b=sorted(a,key=operator.itemgetter(0)) >>>b=[('a',1),('b',2),('c',0)] 这次比较的是前边的a,b,c而不是0,1,2
|
||||
# b=sorted(a,key=opertator.itemgetter(1,0)) >>>b=[('c',0),('a',1),('b',2)] 这个是先比较第2个元素,然后对第一个元素进行排序,形成多级排序。
|
||||
# sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
|
||||
# return sortedClassCount[0][0]
|
||||
# 3.利用max函数直接返回字典中value最大的key
|
||||
maxClassCount = max(classCount, key=classCount.get)
|
||||
return maxClassCount
|
||||
|
||||
# ------------------------------------------------------------------------------------------------------------------------------------------
|
||||
# 实现 classify0() 方法的第二种方式
|
||||
|
||||
# """
|
||||
# 1. 计算距离
|
||||
|
||||
# 欧氏距离: 点到点之间的距离
|
||||
# 第一行: 同一个点 到 dataSet的第一个点的距离。
|
||||
# 第二行: 同一个点 到 dataSet的第二个点的距离。
|
||||
# ...
|
||||
# 第N行: 同一个点 到 dataSet的第N个点的距离。
|
||||
|
||||
# [[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]]
|
||||
# (A1-A2)^2+(B1-B2)^2+(c1-c2)^2
|
||||
|
||||
# inx - dataset 使用了numpy broadcasting,见 https://docs.scipy.org/doc/numpy-1.13.0/user/basics.broadcasting.html
|
||||
# np.sum() 函数的使用见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sum.html
|
||||
# """
|
||||
# dist = np.sum((inx - dataset)**2, axis=1)**0.5
|
||||
|
||||
# """
|
||||
# 2. k个最近的标签
|
||||
|
||||
# 对距离排序使用numpy中的argsort函数, 见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sort.html#numpy.sort
|
||||
# 函数返回的是索引,因此取前k个索引使用[0 : k]
|
||||
# 将这k个标签存在列表k_labels中
|
||||
# """
|
||||
# k_labels = [labels[index] for index in dist.argsort()[0 : k]]
|
||||
# """
|
||||
# 3. 出现次数最多的标签即为最终类别
|
||||
|
||||
# 使用collections.Counter可以统计各个标签的出现次数,most_common返回出现次数最多的标签tuple,例如[('lable1', 2)],因此[0][0]可以取出标签值
|
||||
# """
|
||||
# label = Counter(k_labels).most_common(1)[0][0]
|
||||
# return label
|
||||
|
||||
# ------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
|
||||
def test1():
|
||||
"""
|
||||
第一个例子演示
|
||||
"""
|
||||
group, labels = createDataSet()
|
||||
print(str(group))
|
||||
print(str(labels))
|
||||
print(classify0([0.1, 0.1], group, labels, 3))
|
||||
|
||||
|
||||
# ----------------------------------------------------------------------------------------
|
||||
def file2matrix(filename):
|
||||
"""
|
||||
导入训练数据
|
||||
:param filename: 数据文件路径
|
||||
:return: 数据矩阵returnMat和对应的类别classLabelVector
|
||||
"""
|
||||
fr = open(filename)
|
||||
# 获得文件中的数据行的行数
|
||||
numberOfLines = len(fr.readlines())
|
||||
# 生成对应的空矩阵
|
||||
# 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
|
||||
returnMat = zeros((numberOfLines, 3)) # prepare matrix to return
|
||||
classLabelVector = [] # prepare labels return
|
||||
fr = open(filename)
|
||||
index = 0
|
||||
for line in fr.readlines():
|
||||
# str.strip([chars]) --返回移除字符串头尾指定的字符生成的新字符串
|
||||
line = line.strip()
|
||||
# 以 '\t' 切割字符串
|
||||
listFromLine = line.split('\t')
|
||||
# 每列的属性数据
|
||||
returnMat[index, :] = listFromLine[0:3]
|
||||
# 每列的类别数据,就是 label 标签数据
|
||||
classLabelVector.append(int(listFromLine[-1]))
|
||||
index += 1
|
||||
# 返回数据矩阵returnMat和对应的类别classLabelVector
|
||||
return returnMat, classLabelVector
|
||||
|
||||
|
||||
def autoNorm(dataSet):
|
||||
"""
|
||||
归一化特征值,消除属性之间量级不同导致的影响
|
||||
:param dataSet: 数据集
|
||||
:return: 归一化后的数据集normDataSet,ranges和minVals即最小值与范围,并没有用到
|
||||
|
||||
归一化公式:
|
||||
Y = (X-Xmin)/(Xmax-Xmin)
|
||||
其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。
|
||||
"""
|
||||
# 计算每种属性的最大值、最小值、范围
|
||||
minVals = dataSet.min(0)
|
||||
maxVals = dataSet.max(0)
|
||||
# 极差
|
||||
ranges = maxVals - minVals
|
||||
# -------第一种实现方式---start-------------------------
|
||||
normDataSet = zeros(shape(dataSet))
|
||||
m = dataSet.shape[0]
|
||||
# 生成与最小值之差组成的矩阵
|
||||
normDataSet = dataSet - tile(minVals, (m, 1))
|
||||
# 将最小值之差除以范围组成矩阵
|
||||
normDataSet = normDataSet / tile(ranges, (m, 1)) # element wise divide
|
||||
# -------第一种实现方式---end---------------------------------------------
|
||||
|
||||
# # -------第二种实现方式---start---------------------------------------
|
||||
# norm_dataset = (dataset - minvalue) / ranges
|
||||
# # -------第二种实现方式---end---------------------------------------------
|
||||
return normDataSet, ranges, minVals
|
||||
|
||||
|
||||
def datingClassTest():
|
||||
"""
|
||||
对约会网站的测试方法
|
||||
:return: 错误数
|
||||
"""
|
||||
# 设置测试数据的的一个比例(训练数据集比例=1-hoRatio)
|
||||
hoRatio = 0.1 # 测试范围,一部分测试一部分作为样本
|
||||
# 从文件中加载数据
|
||||
datingDataMat, datingLabels = file2matrix('data/2.KNN/datingTestSet2.txt') # load data setfrom file
|
||||
# 归一化数据
|
||||
normMat, ranges, minVals = autoNorm(datingDataMat)
|
||||
# m 表示数据的行数,即矩阵的第一维
|
||||
m = normMat.shape[0]
|
||||
# 设置测试的样本数量, numTestVecs:m表示训练样本的数量
|
||||
numTestVecs = int(m * hoRatio)
|
||||
print('numTestVecs=', numTestVecs)
|
||||
errorCount = 0.0
|
||||
for i in range(numTestVecs):
|
||||
# 对数据测试
|
||||
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
|
||||
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
|
||||
if (classifierResult != datingLabels[i]): errorCount += 1.0
|
||||
print("the total error rate is: %f" % (errorCount / float(numTestVecs)))
|
||||
print(errorCount)
|
||||
|
||||
|
||||
def img2vector(filename):
|
||||
"""
|
||||
将图像数据转换为向量
|
||||
:param filename: 图片文件 因为我们的输入数据的图片格式是 32 * 32的
|
||||
:return: 一维矩阵
|
||||
该函数将图像转换为向量:该函数创建 1 * 1024 的NumPy数组,然后打开给定的文件,
|
||||
循环读出文件的前32行,并将每行的头32个字符值存储在NumPy数组中,最后返回数组。
|
||||
"""
|
||||
returnVect = zeros((1, 1024))
|
||||
fr = open(filename)
|
||||
for i in range(32):
|
||||
lineStr = fr.readline()
|
||||
for j in range(32):
|
||||
returnVect[0, 32 * i + j] = int(lineStr[j])
|
||||
return returnVect
|
||||
|
||||
|
||||
def handwritingClassTest():
|
||||
# 1. 导入数据
|
||||
hwLabels = []
|
||||
trainingFileList = listdir('data/2.KNN/trainingDigits') # load the training set
|
||||
m = len(trainingFileList)
|
||||
trainingMat = zeros((m, 1024))
|
||||
# hwLabels存储0~9对应的index位置, trainingMat存放的每个位置对应的图片向量
|
||||
for i in range(m):
|
||||
fileNameStr = trainingFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
hwLabels.append(classNumStr)
|
||||
# 将 32*32的矩阵->1*1024的矩阵
|
||||
trainingMat[i, :] = img2vector('data/2.KNN/trainingDigits/%s' % fileNameStr)
|
||||
|
||||
# 2. 导入测试数据
|
||||
testFileList = listdir('data/2.KNN/testDigits') # iterate through the test set
|
||||
errorCount = 0.0
|
||||
mTest = len(testFileList)
|
||||
for i in range(mTest):
|
||||
fileNameStr = testFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
vectorUnderTest = img2vector('data/2.KNN/testDigits/%s' % fileNameStr)
|
||||
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
|
||||
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
|
||||
if (classifierResult != classNumStr): errorCount += 1.0
|
||||
print("\nthe total number of errors is: %d" % errorCount)
|
||||
print("\nthe total error rate is: %f" % (errorCount / float(mTest)))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
# test1()
|
||||
# datingClassTest()
|
||||
handwritingClassTest()
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on 2017-06-28
|
||||
Updated on 2017-06-28
|
||||
KNN:k近邻算法
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from numpy import *
|
||||
from matplotlib.colors import ListedColormap
|
||||
from sklearn import neighbors, datasets
|
||||
|
||||
n_neighbors = 3
|
||||
|
||||
# 导入一些要玩的数据
|
||||
# iris = datasets.load_iris()
|
||||
# X = iris.data[:, :2] # 我们只采用前两个feature. 我们可以使用二维数据集避免这个丑陋的切片
|
||||
# y = iris.target
|
||||
|
||||
# print 'X=', type(X), X
|
||||
# print 'y=', type(y), y
|
||||
|
||||
X = array([[-1.0, -1.1], [-1.0, -1.0], [0, 0], [1.0, 1.1], [2.0, 2.0], [2.0, 2.1]])
|
||||
y = array([0, 0, 0, 1, 1, 1])
|
||||
|
||||
# print 'X=', type(X), X
|
||||
# print 'y=', type(y), y
|
||||
|
||||
h = .02 # 网格中的步长
|
||||
|
||||
# 创建彩色的地图
|
||||
# cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
|
||||
# cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
|
||||
|
||||
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA'])
|
||||
cmap_bold = ListedColormap(['#FF0000', '#00FF00'])
|
||||
|
||||
for weights in ['uniform', 'distance']:
|
||||
# 我们创建了一个knn分类器的实例,并适合数据。
|
||||
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
|
||||
clf.fit(X, y)
|
||||
|
||||
# 绘制决策边界。为此,我们将为每个分配一个颜色
|
||||
# 来绘制网格中的点 [x_min, x_max]x[y_min, y_max].
|
||||
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
|
||||
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
|
||||
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
|
||||
np.arange(y_min, y_max, h))
|
||||
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
|
||||
|
||||
# 将结果放入一个彩色图中
|
||||
Z = Z.reshape(xx.shape)
|
||||
plt.figure()
|
||||
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
|
||||
|
||||
# 绘制训练点
|
||||
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold)
|
||||
plt.xlim(xx.min(), xx.max())
|
||||
plt.ylim(yy.min(), yy.max())
|
||||
plt.title("3-Class classification (k = %i, weights = '%s')"
|
||||
% (n_neighbors, weights))
|
||||
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,118 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf8
|
||||
# 原始链接: http://blog.csdn.net/lsldd/article/details/41223147
|
||||
# GitHub: https://github.com/apachecn/AiLearning
|
||||
from __future__ import print_function
|
||||
import numpy as np
|
||||
from sklearn import tree
|
||||
from sklearn.metrics import precision_recall_curve
|
||||
from sklearn.metrics import classification_report
|
||||
from sklearn.cross_validation import train_test_split
|
||||
|
||||
|
||||
def createDataSet():
|
||||
''' 数据读入 '''
|
||||
data = []
|
||||
labels = []
|
||||
with open("data/3.DecisionTree/data.txt") as ifile:
|
||||
for line in ifile:
|
||||
# 特征: 身高 体重 label: 胖瘦
|
||||
tokens = line.strip().split(' ')
|
||||
data.append([float(tk) for tk in tokens[:-1]])
|
||||
labels.append(tokens[-1])
|
||||
# 特征数据
|
||||
x = np.array(data)
|
||||
# label分类的标签数据
|
||||
labels = np.array(labels)
|
||||
# 预估结果的标签数据
|
||||
y = np.zeros(labels.shape)
|
||||
|
||||
''' 标签转换为0/1 '''
|
||||
y[labels == 'fat'] = 1
|
||||
print(data, '-------', x, '-------', labels, '-------', y)
|
||||
return x, y
|
||||
|
||||
|
||||
def predict_train(x_train, y_train):
|
||||
'''
|
||||
使用信息熵作为划分标准,对决策树进行训练
|
||||
参考链接: http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
|
||||
'''
|
||||
clf = tree.DecisionTreeClassifier(criterion='entropy')
|
||||
# print(clf)
|
||||
clf.fit(x_train, y_train)
|
||||
''' 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
|
||||
print('feature_importances_: %s' % clf.feature_importances_)
|
||||
|
||||
'''测试结果的打印'''
|
||||
y_pre = clf.predict(x_train)
|
||||
# print(x_train)
|
||||
print(y_pre)
|
||||
print(y_train)
|
||||
print(np.mean(y_pre == y_train))
|
||||
return y_pre, clf
|
||||
|
||||
|
||||
def show_precision_recall(x, y, clf, y_train, y_pre):
|
||||
'''
|
||||
准确率与召回率
|
||||
参考链接: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_recall_curve.html#sklearn.metrics.precision_recall_curve
|
||||
'''
|
||||
precision, recall, thresholds = precision_recall_curve(y_train, y_pre)
|
||||
# 计算全量的预估结果
|
||||
answer = clf.predict_proba(x)[:, 1]
|
||||
|
||||
'''
|
||||
展现 准确率与召回率
|
||||
precision 准确率
|
||||
recall 召回率
|
||||
f1-score 准确率和召回率的一个综合得分
|
||||
support 参与比较的数量
|
||||
参考链接:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html#sklearn.metrics.classification_report
|
||||
'''
|
||||
# target_names 以 y的label分类为准
|
||||
target_names = ['thin', 'fat']
|
||||
print(classification_report(y, answer, target_names=target_names))
|
||||
print(answer)
|
||||
print(y)
|
||||
|
||||
|
||||
def show_pdf(clf):
|
||||
'''
|
||||
可视化输出
|
||||
把决策树结构写入文件: http://sklearn.lzjqsdd.com/modules/tree.html
|
||||
|
||||
Mac报错:pydotplus.graphviz.InvocationException: GraphViz's executables not found
|
||||
解决方案:sudo brew install graphviz
|
||||
参考写入: http://www.jianshu.com/p/59b510bafb4d
|
||||
'''
|
||||
# with open("testResult/tree.dot", 'w') as f:
|
||||
# from sklearn.externals.six import StringIO
|
||||
# tree.export_graphviz(clf, out_file=f)
|
||||
|
||||
import pydotplus
|
||||
from sklearn.externals.six import StringIO
|
||||
dot_data = StringIO()
|
||||
tree.export_graphviz(clf, out_file=dot_data)
|
||||
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
|
||||
graph.write_pdf("output/3.DecisionTree/tree.pdf")
|
||||
|
||||
# from IPython.display import Image
|
||||
# Image(graph.create_png())
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
x, y = createDataSet()
|
||||
|
||||
''' 拆分训练数据与测试数据, 80%做训练 20%做测试 '''
|
||||
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
|
||||
print('拆分数据:', x_train, x_test, y_train, y_test)
|
||||
|
||||
# 得到训练的预测结果集
|
||||
y_pre, clf = predict_train(x_train, y_train)
|
||||
|
||||
# 展现 准确率与召回率
|
||||
show_precision_recall(x, y, clf, y_train, y_pre)
|
||||
|
||||
# 可视化输出
|
||||
show_pdf(clf)
|
||||
|
|
@ -0,0 +1,390 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf-8
|
||||
'''
|
||||
Created on Oct 12, 2010
|
||||
Update on 2017-05-18
|
||||
Decision Tree Source Code for Machine Learning in Action Ch. 3
|
||||
Author: Peter Harrington/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
import operator
|
||||
from math import log
|
||||
import decisionTreePlot as dtPlot
|
||||
from collections import Counter
|
||||
|
||||
|
||||
def createDataSet():
|
||||
"""DateSet 基础数据集
|
||||
|
||||
Args:
|
||||
无需传入参数
|
||||
Returns:
|
||||
返回数据集和对应的label标签
|
||||
"""
|
||||
dataSet = [[1, 1, 'yes'],
|
||||
[1, 1, 'yes'],
|
||||
[1, 0, 'no'],
|
||||
[0, 1, 'no'],
|
||||
[0, 1, 'no']]
|
||||
# dataSet = [['yes'],
|
||||
# ['yes'],
|
||||
# ['no'],
|
||||
# ['no'],
|
||||
# ['no']]
|
||||
# labels 露出水面 脚蹼
|
||||
labels = ['no surfacing', 'flippers']
|
||||
# change to discrete values
|
||||
return dataSet, labels
|
||||
|
||||
|
||||
def calcShannonEnt(dataSet):
|
||||
"""calcShannonEnt(calculate Shannon entropy 计算给定数据集的香农熵)
|
||||
|
||||
Args:
|
||||
dataSet 数据集
|
||||
Returns:
|
||||
返回 每一组feature下的某个分类下,香农熵的信息期望
|
||||
"""
|
||||
# -----------计算香农熵的第一种实现方式start--------------------------------------------------------------------------------
|
||||
# 求list的长度,表示计算参与训练的数据量
|
||||
numEntries = len(dataSet)
|
||||
# 下面输出我们测试的数据集的一些信息
|
||||
# 例如:<type 'list'> numEntries: 5 是下面的代码的输出
|
||||
# print type(dataSet), 'numEntries: ', numEntries
|
||||
|
||||
# 计算分类标签label出现的次数
|
||||
labelCounts = {}
|
||||
# the the number of unique elements and their occurance
|
||||
for featVec in dataSet:
|
||||
# 将当前实例的标签存储,即每一行数据的最后一个数据代表的是标签
|
||||
currentLabel = featVec[-1]
|
||||
# 为所有可能的分类创建字典,如果当前的键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。
|
||||
if currentLabel not in labelCounts.keys():
|
||||
labelCounts[currentLabel] = 0
|
||||
labelCounts[currentLabel] += 1
|
||||
# print '-----', featVec, labelCounts
|
||||
|
||||
# 对于label标签的占比,求出label标签的香农熵
|
||||
shannonEnt = 0.0
|
||||
for key in labelCounts:
|
||||
# 使用所有类标签的发生频率计算类别出现的概率。
|
||||
prob = float(labelCounts[key])/numEntries
|
||||
# log base 2
|
||||
# 计算香农熵,以 2 为底求对数
|
||||
shannonEnt -= prob * log(prob, 2)
|
||||
# print '---', prob, prob * log(prob, 2), shannonEnt
|
||||
# -----------计算香农熵的第一种实现方式end--------------------------------------------------------------------------------
|
||||
|
||||
# # -----------计算香农熵的第二种实现方式start--------------------------------------------------------------------------------
|
||||
# # 统计标签出现的次数
|
||||
# label_count = Counter(data[-1] for data in dataSet)
|
||||
# # 计算概率
|
||||
# probs = [p[1] / len(dataSet) for p in label_count.items()]
|
||||
# # 计算香农熵
|
||||
# shannonEnt = sum([-p * log(p, 2) for p in probs])
|
||||
# # -----------计算香农熵的第二种实现方式end--------------------------------------------------------------------------------
|
||||
return shannonEnt
|
||||
|
||||
|
||||
def splitDataSet(dataSet, index, value):
|
||||
"""splitDataSet(通过遍历dataSet数据集,求出index对应的colnum列的值为value的行)
|
||||
就是依据index列进行分类,如果index列的数据等于 value的时候,就要将 index 划分到我们创建的新的数据集中
|
||||
Args:
|
||||
dataSet 数据集 待划分的数据集
|
||||
index 表示每一行的index列 划分数据集的特征
|
||||
value 表示index列对应的value值 需要返回的特征的值。
|
||||
Returns:
|
||||
index列为value的数据集【该数据集需要排除index列】
|
||||
"""
|
||||
# -----------切分数据集的第一种方式 start------------------------------------
|
||||
retDataSet = []
|
||||
for featVec in dataSet:
|
||||
# index列为value的数据集【该数据集需要排除index列】
|
||||
# 判断index列的值是否为value
|
||||
if featVec[index] == value:
|
||||
# chop out index used for splitting
|
||||
# [:index]表示前index行,即若 index 为2,就是取 featVec 的前 index 行
|
||||
reducedFeatVec = featVec[:index]
|
||||
'''
|
||||
请百度查询一下: extend和append的区别
|
||||
list.append(object) 向列表中添加一个对象object
|
||||
list.extend(sequence) 把一个序列seq的内容添加到列表中
|
||||
1、使用append的时候,是将new_media看作一个对象,整体打包添加到music_media对象中。
|
||||
2、使用extend的时候,是将new_media看作一个序列,将这个序列和music_media序列合并,并放在其后面。
|
||||
result = []
|
||||
result.extend([1,2,3])
|
||||
print result
|
||||
result.append([4,5,6])
|
||||
print result
|
||||
result.extend([7,8,9])
|
||||
print result
|
||||
结果:
|
||||
[1, 2, 3]
|
||||
[1, 2, 3, [4, 5, 6]]
|
||||
[1, 2, 3, [4, 5, 6], 7, 8, 9]
|
||||
'''
|
||||
reducedFeatVec.extend(featVec[index+1:])
|
||||
# [index+1:]表示从跳过 index 的 index+1行,取接下来的数据
|
||||
# 收集结果值 index列为value的行【该行需要排除index列】
|
||||
retDataSet.append(reducedFeatVec)
|
||||
# -----------切分数据集的第一种方式 end------------------------------------
|
||||
|
||||
# # -----------切分数据集的第二种方式 start------------------------------------
|
||||
# retDataSet = [data for data in dataSet for i, v in enumerate(data) if i == axis and v == value]
|
||||
# # -----------切分数据集的第二种方式 end------------------------------------
|
||||
return retDataSet
|
||||
|
||||
|
||||
def chooseBestFeatureToSplit(dataSet):
|
||||
"""chooseBestFeatureToSplit(选择最好的特征)
|
||||
|
||||
Args:
|
||||
dataSet 数据集
|
||||
Returns:
|
||||
bestFeature 最优的特征列
|
||||
"""
|
||||
|
||||
# -----------选择最优特征的第一种方式 start------------------------------------
|
||||
# 求第一行有多少列的 Feature, 最后一列是label列嘛
|
||||
numFeatures = len(dataSet[0]) - 1
|
||||
# label的信息熵
|
||||
baseEntropy = calcShannonEnt(dataSet)
|
||||
# 最优的信息增益值, 和最优的Featurn编号
|
||||
bestInfoGain, bestFeature = 0.0, -1
|
||||
# iterate over all the features
|
||||
for i in range(numFeatures):
|
||||
# create a list of all the examples of this feature
|
||||
# 获取每一个实例的第i+1个feature,组成list集合
|
||||
featList = [example[i] for example in dataSet]
|
||||
# get a set of unique values
|
||||
# 获取剔重后的集合,使用set对list数据进行去重
|
||||
uniqueVals = set(featList)
|
||||
# 创建一个临时的信息熵
|
||||
newEntropy = 0.0
|
||||
# 遍历某一列的value集合,计算该列的信息熵
|
||||
# 遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,计算数据集的新熵值,并对所有唯一特征值得到的熵求和。
|
||||
for value in uniqueVals:
|
||||
subDataSet = splitDataSet(dataSet, i, value)
|
||||
prob = len(subDataSet)/float(len(dataSet))
|
||||
newEntropy += prob * calcShannonEnt(subDataSet)
|
||||
# gain[信息增益]: 划分数据集前后的信息变化, 获取信息熵最大的值
|
||||
# 信息增益是熵的减少或者是数据无序度的减少。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
|
||||
infoGain = baseEntropy - newEntropy
|
||||
print('infoGain=', infoGain, 'bestFeature=', i, baseEntropy, newEntropy)
|
||||
if (infoGain > bestInfoGain):
|
||||
bestInfoGain = infoGain
|
||||
bestFeature = i
|
||||
return bestFeature
|
||||
# -----------选择最优特征的第一种方式 end------------------------------------
|
||||
|
||||
# # -----------选择最优特征的第二种方式 start------------------------------------
|
||||
# # 计算初始香农熵
|
||||
# base_entropy = calcShannonEnt(dataSet)
|
||||
# best_info_gain = 0
|
||||
# best_feature = -1
|
||||
# # 遍历每一个特征
|
||||
# for i in range(len(dataSet[0]) - 1):
|
||||
# # 对当前特征进行统计
|
||||
# feature_count = Counter([data[i] for data in dataSet])
|
||||
# # 计算分割后的香农熵
|
||||
# new_entropy = sum(feature[1] / float(len(dataSet)) * calcShannonEnt(splitDataSet(dataSet, i, feature[0])) \
|
||||
# for feature in feature_count.items())
|
||||
# # 更新值
|
||||
# info_gain = base_entropy - new_entropy
|
||||
# print('No. {0} feature info gain is {1:.3f}'.format(i, info_gain))
|
||||
# if info_gain > best_info_gain:
|
||||
# best_info_gain = info_gain
|
||||
# best_feature = i
|
||||
# return best_feature
|
||||
# # -----------选择最优特征的第二种方式 end------------------------------------
|
||||
|
||||
|
||||
def majorityCnt(classList):
|
||||
"""majorityCnt(选择出现次数最多的一个结果)
|
||||
|
||||
Args:
|
||||
classList label列的集合
|
||||
Returns:
|
||||
bestFeature 最优的特征列
|
||||
"""
|
||||
# -----------majorityCnt的第一种方式 start------------------------------------
|
||||
classCount = {}
|
||||
for vote in classList:
|
||||
if vote not in classCount.keys():
|
||||
classCount[vote] = 0
|
||||
classCount[vote] += 1
|
||||
# 倒叙排列classCount得到一个字典集合,然后取出第一个就是结果(yes/no),即出现次数最多的结果
|
||||
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
|
||||
# print 'sortedClassCount:', sortedClassCount
|
||||
return sortedClassCount[0][0]
|
||||
# -----------majorityCnt的第一种方式 end------------------------------------
|
||||
|
||||
# # -----------majorityCnt的第二种方式 start------------------------------------
|
||||
# major_label = Counter(classList).most_common(1)[0]
|
||||
# return major_label
|
||||
# # -----------majorityCnt的第二种方式 end------------------------------------
|
||||
|
||||
|
||||
def createTree(dataSet, labels):
|
||||
classList = [example[-1] for example in dataSet]
|
||||
# 如果数据集的最后一列的第一个值出现的次数=整个集合的数量,也就说只有一个类别,就只直接返回结果就行
|
||||
# 第一个停止条件:所有的类标签完全相同,则直接返回该类标签。
|
||||
# count() 函数是统计括号中的值在list中出现的次数
|
||||
if classList.count(classList[0]) == len(classList):
|
||||
return classList[0]
|
||||
# 如果数据集只有1列,那么最初出现label次数最多的一类,作为结果
|
||||
# 第二个停止条件:使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。
|
||||
if len(dataSet[0]) == 1:
|
||||
return majorityCnt(classList)
|
||||
|
||||
# 选择最优的列,得到最优列对应的label含义
|
||||
bestFeat = chooseBestFeatureToSplit(dataSet)
|
||||
# 获取label的名称
|
||||
bestFeatLabel = labels[bestFeat]
|
||||
# 初始化myTree
|
||||
myTree = {bestFeatLabel: {}}
|
||||
# 注:labels列表是可变对象,在PYTHON函数中作为参数时传址引用,能够被全局修改
|
||||
# 所以这行代码导致函数外的同名变量被删除了元素,造成例句无法执行,提示'no surfacing' is not in list
|
||||
del(labels[bestFeat])
|
||||
# 取出最优列,然后它的branch做分类
|
||||
featValues = [example[bestFeat] for example in dataSet]
|
||||
uniqueVals = set(featValues)
|
||||
for value in uniqueVals:
|
||||
# 求出剩余的标签label
|
||||
subLabels = labels[:]
|
||||
# 遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree()
|
||||
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
|
||||
# print 'myTree', value, myTree
|
||||
return myTree
|
||||
|
||||
|
||||
def classify(inputTree, featLabels, testVec):
|
||||
"""classify(给输入的节点,进行分类)
|
||||
|
||||
Args:
|
||||
inputTree 决策树模型
|
||||
featLabels Feature标签对应的名称
|
||||
testVec 测试输入的数据
|
||||
Returns:
|
||||
classLabel 分类的结果值,需要映射label才能知道名称
|
||||
"""
|
||||
# 获取tree的根节点对于的key值
|
||||
firstStr = inputTree.keys()[0]
|
||||
# 通过key得到根节点对应的value
|
||||
secondDict = inputTree[firstStr]
|
||||
# 判断根节点名称获取根节点在label中的先后顺序,这样就知道输入的testVec怎么开始对照树来做分类
|
||||
featIndex = featLabels.index(firstStr)
|
||||
# 测试数据,找到根节点对应的label位置,也就知道从输入的数据的第几位来开始分类
|
||||
key = testVec[featIndex]
|
||||
valueOfFeat = secondDict[key]
|
||||
print('+++', firstStr, 'xxx', secondDict, '---', key, '>>>', valueOfFeat)
|
||||
# 判断分枝是否结束: 判断valueOfFeat是否是dict类型
|
||||
if isinstance(valueOfFeat, dict):
|
||||
classLabel = classify(valueOfFeat, featLabels, testVec)
|
||||
else:
|
||||
classLabel = valueOfFeat
|
||||
return classLabel
|
||||
|
||||
|
||||
def storeTree(inputTree, filename):
|
||||
import pickle
|
||||
# -------------- 第一种方法 start --------------
|
||||
fw = open(filename, 'wb')
|
||||
pickle.dump(inputTree, fw)
|
||||
fw.close()
|
||||
# -------------- 第一种方法 end --------------
|
||||
|
||||
# -------------- 第二种方法 start --------------
|
||||
with open(filename, 'wb') as fw:
|
||||
pickle.dump(inputTree, fw)
|
||||
# -------------- 第二种方法 start --------------
|
||||
|
||||
|
||||
def grabTree(filename):
|
||||
import pickle
|
||||
fr = open(filename,'rb')
|
||||
return pickle.load(fr)
|
||||
|
||||
|
||||
def fishTest():
|
||||
# 1.创建数据和结果标签
|
||||
myDat, labels = createDataSet()
|
||||
# print myDat, labels
|
||||
|
||||
# 计算label分类标签的香农熵
|
||||
# calcShannonEnt(myDat)
|
||||
|
||||
# # 求第0列 为 1/0的列的数据集【排除第0列】
|
||||
# print '1---', splitDataSet(myDat, 0, 1)
|
||||
# print '0---', splitDataSet(myDat, 0, 0)
|
||||
|
||||
# # 计算最好的信息增益的列
|
||||
# print chooseBestFeatureToSplit(myDat)
|
||||
|
||||
import copy
|
||||
myTree = createTree(myDat, copy.deepcopy(labels))
|
||||
print(myTree)
|
||||
# [1, 1]表示要取的分支上的节点位置,对应的结果值
|
||||
print(classify(myTree, labels, [1, 1]))
|
||||
|
||||
# 获得树的高度
|
||||
print(get_tree_height(myTree))
|
||||
|
||||
# 画图可视化展现
|
||||
dtPlot.createPlot(myTree)
|
||||
|
||||
|
||||
def ContactLensesTest():
|
||||
"""
|
||||
Desc:
|
||||
预测隐形眼镜的测试代码
|
||||
Args:
|
||||
none
|
||||
Returns:
|
||||
none
|
||||
"""
|
||||
|
||||
# 加载隐形眼镜相关的 文本文件 数据
|
||||
fr = open('data/3.DecisionTree/lenses.txt')
|
||||
# 解析数据,获得 features 数据
|
||||
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
|
||||
# 得到数据的对应的 Labels
|
||||
lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
|
||||
# 使用上面的创建决策树的代码,构造预测隐形眼镜的决策树
|
||||
lensesTree = createTree(lenses, lensesLabels)
|
||||
print(lensesTree)
|
||||
# 画图可视化展现
|
||||
dtPlot.createPlot(lensesTree)
|
||||
|
||||
|
||||
def get_tree_height(tree):
|
||||
"""
|
||||
Desc:
|
||||
递归获得决策树的高度
|
||||
Args:
|
||||
tree
|
||||
Returns:
|
||||
树高
|
||||
"""
|
||||
|
||||
if not isinstance(tree, dict):
|
||||
return 1
|
||||
|
||||
child_trees = tree.values()[0].values()
|
||||
|
||||
# 遍历子树, 获得子树的最大高度
|
||||
max_height = 0
|
||||
for child_tree in child_trees:
|
||||
child_tree_height = get_tree_height(child_tree)
|
||||
|
||||
if child_tree_height > max_height:
|
||||
max_height = child_tree_height
|
||||
|
||||
return max_height + 1
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
fishTest()
|
||||
# ContactLensesTest()
|
||||
|
|
@ -0,0 +1,138 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on Oct 14, 2010
|
||||
Update on 2018-01-04
|
||||
Decision Tree Source Code for Machine Learning in Action Ch. 3
|
||||
Author: Peter Harrington/jiangzhonglian/zh0ng
|
||||
'''
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# 定义文本框 和 箭头格式 【 sawtooth 波浪方框, round4 矩形方框 , fc表示字体颜色的深浅 0.1~0.9 依次变浅,没错是变浅】
|
||||
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
|
||||
leafNode = dict(boxstyle="round4", fc="0.8")
|
||||
arrow_args = dict(arrowstyle="<-")
|
||||
|
||||
|
||||
def getNumLeafs(myTree):
|
||||
numLeafs = 0
|
||||
firstStr = myTree.keys()[0]
|
||||
secondDict = myTree[firstStr]
|
||||
# 根节点开始遍历
|
||||
for key in secondDict.keys():
|
||||
# 判断子节点是否为dict, 不是+1
|
||||
if type(secondDict[key]) is dict:
|
||||
numLeafs += getNumLeafs(secondDict[key])
|
||||
else:
|
||||
numLeafs += 1
|
||||
return numLeafs
|
||||
|
||||
|
||||
def getTreeDepth(myTree):
|
||||
maxDepth = 0
|
||||
firstStr = myTree.keys()[0]
|
||||
secondDict = myTree[firstStr]
|
||||
# 根节点开始遍历
|
||||
for key in secondDict.keys():
|
||||
# 判断子节点是不是dict, 求分枝的深度
|
||||
if type(secondDict[key]) is dict:
|
||||
thisDepth = 1 + getTreeDepth(secondDict[key])
|
||||
else:
|
||||
thisDepth = 1
|
||||
# 记录最大的分支深度
|
||||
if thisDepth > maxDepth:
|
||||
maxDepth = thisDepth
|
||||
return maxDepth
|
||||
|
||||
|
||||
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
|
||||
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt,
|
||||
textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
|
||||
|
||||
|
||||
def plotMidText(cntrPt, parentPt, txtString):
|
||||
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
|
||||
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
|
||||
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
|
||||
|
||||
|
||||
def plotTree(myTree, parentPt, nodeTxt):
|
||||
# 获取叶子节点的数量
|
||||
numLeafs = getNumLeafs(myTree)
|
||||
# 获取树的深度
|
||||
# depth = getTreeDepth(myTree)
|
||||
|
||||
# 找出第1个中心点的位置,然后与 parentPt定点进行划线
|
||||
# x坐标为 (numLeafs-1.)/plotTree.totalW/2+1./plotTree.totalW,化简如下
|
||||
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
|
||||
# print cntrPt
|
||||
# 并打印输入对应的文字
|
||||
plotMidText(cntrPt, parentPt, nodeTxt)
|
||||
|
||||
firstStr = myTree.keys()[0]
|
||||
# 可视化Node分支点;第一次调用plotTree时,cntrPt与parentPt相同
|
||||
plotNode(firstStr, cntrPt, parentPt, decisionNode)
|
||||
# 根节点的值
|
||||
secondDict = myTree[firstStr]
|
||||
# y值 = 最高点-层数的高度[第二个节点位置];1.0相当于树的高度
|
||||
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
|
||||
for key in secondDict.keys():
|
||||
# 判断该节点是否是Node节点
|
||||
if type(secondDict[key]) is dict:
|
||||
# 如果是就递归调用[recursion]
|
||||
plotTree(secondDict[key], cntrPt, str(key))
|
||||
else:
|
||||
# 如果不是,就在原来节点一半的地方找到节点的坐标
|
||||
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
|
||||
# 可视化该节点位置
|
||||
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
|
||||
# 并打印输入对应的文字
|
||||
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
|
||||
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
|
||||
|
||||
|
||||
def createPlot(inTree):
|
||||
# 创建一个figure的模版
|
||||
fig = plt.figure(1, facecolor='green')
|
||||
fig.clf()
|
||||
|
||||
axprops = dict(xticks=[], yticks=[])
|
||||
# 表示创建一个1行,1列的图,createPlot.ax1 为第 1 个子图,
|
||||
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
|
||||
|
||||
plotTree.totalW = float(getNumLeafs(inTree))
|
||||
plotTree.totalD = float(getTreeDepth(inTree))
|
||||
# 半个节点的长度;xOff表示当前plotTree未遍历到的最左的叶节点的左边一个叶节点的x坐标
|
||||
# 所有叶节点中,最左的叶节点的x坐标是0.5/plotTree.totalW(因为totalW个叶节点在x轴方向是平均分布在[0, 1]区间上的)
|
||||
# 因此,xOff的初始值应该是 0.5/plotTree.totalW-相邻两个叶节点的x轴方向距离
|
||||
plotTree.xOff = -0.5 / plotTree.totalW
|
||||
# 根节点的y坐标为1.0,树的最低点y坐标为0
|
||||
plotTree.yOff = 1.0
|
||||
# 第二个参数是根节点的坐标
|
||||
plotTree(inTree, (0.5, 1.0), '')
|
||||
plt.show()
|
||||
|
||||
|
||||
# # 测试画图
|
||||
# def createPlot():
|
||||
# fig = plt.figure(1, facecolor='white')
|
||||
# fig.clf()
|
||||
# # ticks for demo puropses
|
||||
# createPlot.ax1 = plt.subplot(111, frameon=False)
|
||||
# plotNode('a decision node', (0.5, 0.1), (0.1, 0.5), decisionNode)
|
||||
# plotNode('a leaf node', (0.8, 0.1), (0.3, 0.8), leafNode)
|
||||
# plt.show()
|
||||
|
||||
|
||||
# 测试数据集
|
||||
def retrieveTree(i):
|
||||
listOfTrees = [
|
||||
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}},
|
||||
{'no surfacing': {0: 'no', 1: {'flippers': {0: {'head': {0: 'no', 1: 'yes'}}, 1: 'no'}}}}
|
||||
]
|
||||
return listOfTrees[i]
|
||||
|
||||
# 用测试数据绘制树
|
||||
# myTree = retrieveTree(1)
|
||||
# createPlot(myTree)
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on 2017-06-29
|
||||
Updated on 2017-06-29
|
||||
DecisionTree:决策树
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
|
||||
print(__doc__)
|
||||
|
||||
# 引入必要的模型和库
|
||||
import numpy as np
|
||||
from sklearn.tree import DecisionTreeRegressor
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# 创建一个随机的数据集
|
||||
# 参考 https://docs.scipy.org/doc/numpy-1.6.0/reference/generated/numpy.random.mtrand.RandomState.html
|
||||
rng = np.random.RandomState(1)
|
||||
# print 'lalalalala===', rng
|
||||
# rand() 是给定形状的随机值,rng.rand(80, 1)即矩阵的形状是 80行,1列
|
||||
# sort()
|
||||
X = np.sort(5 * rng.rand(80, 1), axis=0)
|
||||
# print 'X=', X
|
||||
y = np.sin(X).ravel()
|
||||
# print 'y=', y
|
||||
y[::5] += 3 * (0.5 - rng.rand(16))
|
||||
# print 'yyy=', y
|
||||
|
||||
# 拟合回归模型
|
||||
# regr_1 = DecisionTreeRegressor(max_depth=2)
|
||||
# 保持 max_depth=5 不变,增加 min_samples_leaf=6 的参数,效果进一步提升了
|
||||
regr_2 = DecisionTreeRegressor(max_depth=5)
|
||||
regr_2 = DecisionTreeRegressor(min_samples_leaf=6)
|
||||
# regr_3 = DecisionTreeRegressor(max_depth=4)
|
||||
# regr_1.fit(X, y)
|
||||
regr_2.fit(X, y)
|
||||
# regr_3.fit(X, y)
|
||||
|
||||
# 预测
|
||||
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
|
||||
# y_1 = regr_1.predict(X_test)
|
||||
y_2 = regr_2.predict(X_test)
|
||||
# y_3 = regr_3.predict(X_test)
|
||||
|
||||
# 绘制结果
|
||||
plt.figure()
|
||||
plt.scatter(X, y, c="darkorange", label="data")
|
||||
# plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
|
||||
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
|
||||
# plt.plot(X_test, y_3, color="red", label="max_depth=3", linewidth=2)
|
||||
plt.xlabel("data")
|
||||
plt.ylabel("target")
|
||||
plt.title("Decision Tree Regression")
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf-8
|
||||
|
||||
"""
|
||||
Created on 2017-06-29
|
||||
Updated on 2017-06-29
|
||||
DecisionTree:决策树
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
from sklearn.datasets import load_iris
|
||||
from sklearn.tree import DecisionTreeClassifier
|
||||
|
||||
# 参数
|
||||
n_classes = 3
|
||||
plot_colors = "bry"
|
||||
plot_step = 0.02
|
||||
|
||||
# 加载数据
|
||||
iris = load_iris()
|
||||
|
||||
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3], [1, 2], [1, 3], [2, 3]]):
|
||||
# 我们只用两个相应的features
|
||||
X = iris.data[:, pair]
|
||||
y = iris.target
|
||||
|
||||
# 训练
|
||||
clf = DecisionTreeClassifier().fit(X, y)
|
||||
|
||||
# 绘制决策边界
|
||||
plt.subplot(2, 3, pairidx + 1)
|
||||
|
||||
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
|
||||
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
|
||||
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
|
||||
np.arange(y_min, y_max, plot_step))
|
||||
|
||||
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
|
||||
Z = Z.reshape(xx.shape)
|
||||
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
|
||||
|
||||
plt.xlabel(iris.feature_names[pair[0]])
|
||||
plt.ylabel(iris.feature_names[pair[1]])
|
||||
plt.axis("tight")
|
||||
|
||||
# 绘制训练点
|
||||
for i, color in zip(range(n_classes), plot_colors):
|
||||
idx = np.where(y == i)
|
||||
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
|
||||
cmap=plt.cm.Paired)
|
||||
|
||||
plt.axis("tight")
|
||||
|
||||
plt.suptitle("Decision surface of a decision tree using paired features")
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,356 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding:utf-8 -*-
|
||||
'''
|
||||
Created on Oct 19, 2010
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/羊三/小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
"""
|
||||
p(xy)=p(x|y)p(y)=p(y|x)p(x)
|
||||
p(x|y)=p(y|x)p(x)/p(y)
|
||||
"""
|
||||
|
||||
|
||||
# 项目案例1: 屏蔽社区留言板的侮辱性言论
|
||||
|
||||
def loadDataSet():
|
||||
"""
|
||||
创建数据集
|
||||
:return: 单词列表postingList, 所属类别classVec
|
||||
"""
|
||||
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #[0,0,1,1,1......]
|
||||
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
|
||||
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
|
||||
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
|
||||
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
|
||||
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
|
||||
classVec = [0, 1, 0, 1, 0, 1] # 1 is abusive, 0 not
|
||||
return postingList, classVec
|
||||
|
||||
|
||||
def createVocabList(dataSet):
|
||||
"""
|
||||
获取所有单词的集合
|
||||
:param dataSet: 数据集
|
||||
:return: 所有单词的集合(即不含重复元素的单词列表)
|
||||
"""
|
||||
vocabSet = set([]) # create empty set
|
||||
for document in dataSet:
|
||||
# 操作符 | 用于求两个集合的并集
|
||||
vocabSet = vocabSet | set(document) # union of the two sets
|
||||
return list(vocabSet)
|
||||
|
||||
|
||||
def setOfWords2Vec(vocabList, inputSet):
|
||||
"""
|
||||
遍历查看该单词是否出现,出现该单词则将该单词置1
|
||||
:param vocabList: 所有单词集合列表
|
||||
:param inputSet: 输入数据集
|
||||
:return: 匹配列表[0,1,0,1...],其中 1与0 表示词汇表中的单词是否出现在输入的数据集中
|
||||
"""
|
||||
# 创建一个和词汇表等长的向量,并将其元素都设置为0
|
||||
returnVec = [0] * len(vocabList)# [0,0......]
|
||||
# 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
|
||||
for word in inputSet:
|
||||
if word in vocabList:
|
||||
returnVec[vocabList.index(word)] = 1
|
||||
else:
|
||||
print("the word: %s is not in my Vocabulary!" % word)
|
||||
return returnVec
|
||||
|
||||
|
||||
def _trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据原版
|
||||
:param trainMatrix: 文件单词矩阵 [[1,0,1,1,1....],[],[]...]
|
||||
:param trainCategory: 文件对应的类别[0,1,1,0....],列表长度等于单词矩阵数,其中的1代表对应的文件是侮辱性文件,0代表不是侮辱性矩阵
|
||||
:return:
|
||||
"""
|
||||
# 文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率,即trainCategory中所有的1的个数,
|
||||
# 代表的就是多少个侮辱性文件,与文件的总数相除就得到了侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
p0Num = zeros(numWords) # [0,0,0,.....]
|
||||
p1Num = zeros(numWords) # [0,0,0,.....]
|
||||
|
||||
# 整个数据集单词出现总数
|
||||
p0Denom = 0.0
|
||||
p1Denom = 0.0
|
||||
for i in range(numTrainDocs):
|
||||
# 遍历所有的文件,如果是侮辱性文件,就计算此侮辱性文件中出现的侮辱性单词的个数
|
||||
if trainCategory[i] == 1:
|
||||
p1Num += trainMatrix[i] #[0,1,1,....]->[0,1,1,...]
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
# 如果不是侮辱性文件,则计算非侮辱性文件中出现的侮辱性单词的个数
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[P(F1|C1),P(F2|C1),P(F3|C1),P(F4|C1),P(F5|C1)....]列表
|
||||
# 即 在1类别下,每个单词出现次数的占比
|
||||
p1Vect = p1Num / p1Denom# [1,2,3,5]/90->[1/90,...]
|
||||
# 类别0,即正常文档的[P(F1|C0),P(F2|C0),P(F3|C0),P(F4|C0),P(F5|C0)....]列表
|
||||
# 即 在0类别下,每个单词出现次数的占比
|
||||
p0Vect = p0Num / p0Denom
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
|
||||
|
||||
def trainNB0(trainMatrix, trainCategory):
|
||||
"""
|
||||
训练数据优化版本
|
||||
:param trainMatrix: 文件单词矩阵
|
||||
:param trainCategory: 文件对应的类别
|
||||
:return:
|
||||
"""
|
||||
# 总文件数
|
||||
numTrainDocs = len(trainMatrix)
|
||||
# 总单词数
|
||||
numWords = len(trainMatrix[0])
|
||||
# 侮辱性文件的出现概率
|
||||
pAbusive = sum(trainCategory) / float(numTrainDocs)
|
||||
# 构造单词出现次数列表
|
||||
# p0Num 正常的统计
|
||||
# p1Num 侮辱的统计
|
||||
# 避免单词列表中的任何一个单词为0,而导致最后的乘积为0,所以将每个单词的出现次数初始化为 1
|
||||
p0Num = ones(numWords)#[0,0......]->[1,1,1,1,1.....]
|
||||
p1Num = ones(numWords)
|
||||
|
||||
# 整个数据集单词出现总数,2.0根据样本/实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整)
|
||||
# p0Denom 正常的统计
|
||||
# p1Denom 侮辱的统计
|
||||
p0Denom = 2.0
|
||||
p1Denom = 2.0
|
||||
for i in range(numTrainDocs):
|
||||
if trainCategory[i] == 1:
|
||||
# 累加辱骂词的频次
|
||||
p1Num += trainMatrix[i]
|
||||
# 对每篇文章的辱骂的频次 进行统计汇总
|
||||
p1Denom += sum(trainMatrix[i])
|
||||
else:
|
||||
p0Num += trainMatrix[i]
|
||||
p0Denom += sum(trainMatrix[i])
|
||||
# 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
p1Vect = log(p1Num / p1Denom)
|
||||
# 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
p0Vect = log(p0Num / p0Denom)
|
||||
return p0Vect, p1Vect, pAbusive
|
||||
|
||||
|
||||
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
|
||||
"""
|
||||
使用算法:
|
||||
# 将乘法转换为加法
|
||||
乘法:P(C|F1F2...Fn) = P(F1F2...Fn|C)P(C)/P(F1F2...Fn)
|
||||
加法:P(F1|C)*P(F2|C)....P(Fn|C)P(C) -> log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
:param vec2Classify: 待测数据[0,1,1,1,1...],即要分类的向量
|
||||
:param p0Vec: 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表
|
||||
:param p1Vec: 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表
|
||||
:param pClass1: 类别1,侮辱性文件的出现概率
|
||||
:return: 类别1 or 0
|
||||
"""
|
||||
# 计算公式 log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C))
|
||||
# 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。
|
||||
# 我的理解是:这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来
|
||||
# 可以理解为 1.单词在词汇表中的条件下,文件是good 类别的概率 也可以理解为 2.在整个空间下,文件既在词汇表中又是good类别的概率
|
||||
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
|
||||
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
|
||||
if p1 > p0:
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def bagOfWords2VecMN(vocabList, inputSet):
|
||||
returnVec = [0] * len(vocabList)
|
||||
for word in inputSet:
|
||||
if word in vocabList:
|
||||
returnVec[vocabList.index(word)] += 1
|
||||
return returnVec
|
||||
|
||||
|
||||
def testingNB():
|
||||
"""
|
||||
测试朴素贝叶斯算法
|
||||
"""
|
||||
# 1. 加载数据集
|
||||
listOPosts, listClasses = loadDataSet()
|
||||
# 2. 创建单词集合
|
||||
myVocabList = createVocabList(listOPosts)
|
||||
# 3. 计算单词是否出现并创建数据矩阵
|
||||
trainMat = []
|
||||
for postinDoc in listOPosts:
|
||||
# 返回m*len(myVocabList)的矩阵, 记录的都是0,1信息
|
||||
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
|
||||
# 4. 训练数据
|
||||
p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses))
|
||||
# 5. 测试数据
|
||||
testEntry = ['love', 'my', 'dalmation']
|
||||
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
|
||||
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
|
||||
testEntry = ['stupid', 'garbage']
|
||||
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
|
||||
print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
|
||||
|
||||
|
||||
# ------------------------------------------------------------------------------------------
|
||||
# 项目案例2: 使用朴素贝叶斯过滤垃圾邮件
|
||||
|
||||
# 切分文本
|
||||
def textParse(bigString):
|
||||
'''
|
||||
Desc:
|
||||
接收一个大字符串并将其解析为字符串列表
|
||||
Args:
|
||||
bigString -- 大字符串
|
||||
Returns:
|
||||
去掉少于 2 个字符的字符串,并将所有字符串转换为小写,返回字符串列表
|
||||
'''
|
||||
import re
|
||||
# 使用正则表达式来切分句子,其中分隔符是除单词、数字外的任意字符串
|
||||
listOfTokens = re.split(r'\W*', bigString)
|
||||
return [tok.lower() for tok in listOfTokens if len(tok) > 2]
|
||||
|
||||
|
||||
def spamTest():
|
||||
'''
|
||||
Desc:
|
||||
对贝叶斯垃圾邮件分类器进行自动化处理。
|
||||
Args:
|
||||
none
|
||||
Returns:
|
||||
对测试集中的每封邮件进行分类,若邮件分类错误,则错误数加 1,最后返回总的错误百分比。
|
||||
'''
|
||||
docList = []
|
||||
classList = []
|
||||
fullText = []
|
||||
for i in range(1, 26):
|
||||
# 切分,解析数据,并归类为 1 类别
|
||||
wordList = textParse(open('data/4.NaiveBayes/email/spam/%d.txt' % i).read())
|
||||
docList.append(wordList)
|
||||
classList.append(1)
|
||||
# 切分,解析数据,并归类为 0 类别
|
||||
wordList = textParse(open('data/4.NaiveBayes/email/ham/%d.txt' % i).read())
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(0)
|
||||
# 创建词汇表
|
||||
vocabList = createVocabList(docList)
|
||||
trainingSet = range(50)
|
||||
testSet = []
|
||||
# 随机取 10 个邮件用来测试
|
||||
for i in range(10):
|
||||
# random.uniform(x, y) 随机生成一个范围为 x - y 的实数
|
||||
randIndex = int(random.uniform(0, len(trainingSet)))
|
||||
testSet.append(trainingSet[randIndex])
|
||||
del(trainingSet[randIndex])
|
||||
trainMat = []
|
||||
trainClasses = []
|
||||
for docIndex in trainingSet:
|
||||
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
|
||||
trainClasses.append(classList[docIndex])
|
||||
p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
|
||||
errorCount = 0
|
||||
for docIndex in testSet:
|
||||
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
|
||||
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
|
||||
errorCount += 1
|
||||
print('the errorCount is: ', errorCount)
|
||||
print('the testSet length is :', len(testSet))
|
||||
print('the error rate is :', float(errorCount)/len(testSet))
|
||||
|
||||
|
||||
def testParseTest():
|
||||
print(textParse(open('data/4.NaiveBayes/email/ham/1.txt').read()))
|
||||
|
||||
|
||||
# -----------------------------------------------------------------------------------
|
||||
# 项目案例3: 使用朴素贝叶斯从个人广告中获取区域倾向
|
||||
|
||||
# 将文本文件解析成 词条向量
|
||||
def setOfWords2VecMN(vocabList,inputSet):
|
||||
returnVec=[0]*len(vocabList) # 创建一个其中所含元素都为0的向量
|
||||
for word in inputSet:
|
||||
if word in vocabList:
|
||||
returnVec[vocabList.index(word)]+=1
|
||||
return returnVec
|
||||
|
||||
|
||||
#文件解析
|
||||
def textParse(bigString):
|
||||
import re
|
||||
listOfTokens=re.split(r'\W*', bigString)
|
||||
return [tok.lower() for tok in listOfTokens if len(tok)>2]
|
||||
|
||||
|
||||
#RSS源分类器及高频词去除函数
|
||||
def calcMostFreq(vocabList,fullText):
|
||||
import operator
|
||||
freqDict={}
|
||||
for token in vocabList: #遍历词汇表中的每个词
|
||||
freqDict[token]=fullText.count(token) #统计每个词在文本中出现的次数
|
||||
sortedFreq=sorted(freqDict.iteritems(),key=operator.itemgetter(1),reverse=True) #根据每个词出现的次数从高到底对字典进行排序
|
||||
return sortedFreq[:30] #返回出现次数最高的30个单词
|
||||
def localWords(feed1,feed0):
|
||||
import feedparser
|
||||
docList=[];classList=[];fullText=[]
|
||||
minLen=min(len(feed1['entries']),len(feed0['entries']))
|
||||
for i in range(minLen):
|
||||
wordList=textParse(feed1['entries'][i]['summary']) #每次访问一条RSS源
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(1)
|
||||
wordList=textParse(feed0['entries'][i]['summary'])
|
||||
docList.append(wordList)
|
||||
fullText.extend(wordList)
|
||||
classList.append(0)
|
||||
vocabList=createVocabList(docList)
|
||||
top30Words=calcMostFreq(vocabList,fullText)
|
||||
for pairW in top30Words:
|
||||
if pairW[0] in vocabList:vocabList.remove(pairW[0]) #去掉出现次数最高的那些词
|
||||
trainingSet=range(2*minLen);testSet=[]
|
||||
for i in range(20):
|
||||
randIndex=int(random.uniform(0,len(trainingSet)))
|
||||
testSet.append(trainingSet[randIndex])
|
||||
del(trainingSet[randIndex])
|
||||
trainMat=[];trainClasses=[]
|
||||
for docIndex in trainingSet:
|
||||
trainMat.append(bagOfWords2VecMN(vocabList,docList[docIndex]))
|
||||
trainClasses.append(classList[docIndex])
|
||||
p0V,p1V,pSpam=trainNB0(array(trainMat),array(trainClasses))
|
||||
errorCount=0
|
||||
for docIndex in testSet:
|
||||
wordVector=bagOfWords2VecMN(vocabList,docList[docIndex])
|
||||
if classifyNB(array(wordVector),p0V,p1V,pSpam)!=classList[docIndex]:
|
||||
errorCount+=1
|
||||
print('the error rate is:',float(errorCount)/len(testSet))
|
||||
return vocabList,p0V,p1V
|
||||
|
||||
|
||||
# 最具表征性的词汇显示函数
|
||||
def getTopWords(ny,sf):
|
||||
import operator
|
||||
vocabList,p0V,p1V=localWords(ny,sf)
|
||||
topNY=[];topSF=[]
|
||||
for i in range(len(p0V)):
|
||||
if p0V[i]>-6.0:topSF.append((vocabList[i],p0V[i]))
|
||||
if p1V[i]>-6.0:topNY.append((vocabList[i],p1V[i]))
|
||||
sortedSF=sorted(topSF,key=lambda pair:pair[1],reverse=True)
|
||||
print("SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**")
|
||||
for item in sortedSF:
|
||||
print(item[0])
|
||||
sortedNY=sorted(topNY,key=lambda pair:pair[1],reverse=True)
|
||||
print("NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**")
|
||||
for item in sortedNY:
|
||||
print(item[0])
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# testingNB()
|
||||
spamTest()
|
||||
# laTest()
|
||||
|
|
@ -0,0 +1,46 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on 2017-06-28
|
||||
Updated on 2017-06-28
|
||||
NaiveBayes:朴素贝叶斯
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
|
||||
|
||||
# GaussianNB_高斯朴素贝叶斯
|
||||
import numpy as np
|
||||
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
|
||||
Y = np.array([1, 1, 1, 2, 2, 2])
|
||||
from sklearn.naive_bayes import GaussianNB
|
||||
clf = GaussianNB()
|
||||
clf.fit(X, Y)
|
||||
print(clf.predict([[-0.8, -1]]))
|
||||
clf_pf = GaussianNB()
|
||||
clf_pf.partial_fit(X, Y, np.unique(Y))
|
||||
print(clf_pf.predict([[-0.8, -1]]))
|
||||
|
||||
# MultinomialNB_多项朴素贝叶斯
|
||||
'''
|
||||
import numpy as np
|
||||
X = np.random.randint(5, size=(6, 100))
|
||||
y = np.array([1, 2, 3, 4, 5, 6])
|
||||
from sklearn.naive_bayes import MultinomialNB
|
||||
clf = MultinomialNB()
|
||||
clf.fit(X, y)
|
||||
print clf.predict(X[2:3])
|
||||
'''
|
||||
|
||||
# BernoulliNB_伯努利朴素贝叶斯
|
||||
'''
|
||||
import numpy as np
|
||||
X = np.random.randint(2, size=(6, 100))
|
||||
Y = np.array([1, 2, 3, 4, 4, 5])
|
||||
from sklearn.naive_bayes import BernoulliNB
|
||||
clf = BernoulliNB()
|
||||
clf.fit(X, Y)
|
||||
print clf.predict(X[2:3])
|
||||
'''
|
||||
|
|
@ -0,0 +1,298 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf8
|
||||
'''
|
||||
Created on Oct 27, 2010
|
||||
Update on 2017-05-18
|
||||
Logistic Regression Working Module
|
||||
Author: Peter Harrington/羊三/小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# ---------------------------------------------------------------------------
|
||||
# 使用 Logistic 回归在简单数据集上的分类
|
||||
|
||||
|
||||
# 解析数据
|
||||
def loadDataSet(file_name):
|
||||
'''
|
||||
Desc:
|
||||
加载并解析数据
|
||||
Args:
|
||||
file_name -- 文件名称,要解析的文件所在磁盘位置
|
||||
Returns:
|
||||
dataMat -- 原始数据的特征
|
||||
labelMat -- 原始数据的标签,也就是每条样本对应的类别
|
||||
'''
|
||||
# dataMat为原始数据, labelMat为原始数据的标签
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(file_name)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split()
|
||||
if len(lineArr) == 1:
|
||||
continue # 这里如果就一个空的元素,则跳过本次循环
|
||||
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(int(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
# sigmoid跳跃函数
|
||||
def sigmoid(inX):
|
||||
# return 1.0 / (1 + exp(-inX))
|
||||
|
||||
# Tanh是Sigmoid的变形,与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好。
|
||||
return 2 * 1.0/(1+exp(-2*inX)) - 1
|
||||
|
||||
|
||||
# 正常的处理方案
|
||||
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
|
||||
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
|
||||
def gradAscent(dataMatIn, classLabels):
|
||||
'''
|
||||
Desc:
|
||||
正常的梯度上升法
|
||||
Args:
|
||||
dataMatIn -- 输入的 数据的特征 List
|
||||
classLabels -- 输入的数据的类别标签
|
||||
Returns:
|
||||
array(weights) -- 得到的最佳回归系数
|
||||
'''
|
||||
|
||||
# 转化为矩阵[[1,1,2],[1,1,2]....]
|
||||
dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
|
||||
# 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
|
||||
# transpose() 行列转置函数
|
||||
# 将行向量转化为列向量 => 矩阵的转置
|
||||
labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
|
||||
# m->数据量,样本数 n->特征数
|
||||
m, n = shape(dataMatrix)
|
||||
# print m, n, '__'*10, shape(dataMatrix.transpose()), '__'*100
|
||||
# alpha代表向目标移动的步长
|
||||
alpha = 0.001
|
||||
# 迭代次数
|
||||
maxCycles = 500
|
||||
# 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
|
||||
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
|
||||
weights = ones((n, 1))
|
||||
for k in range(maxCycles): # heavy on matrix operations
|
||||
# m*3 的矩阵 * 3*1 的单位矩阵 = m*1的矩阵
|
||||
# 那么乘上单位矩阵的意义,就代表:通过公式得到的理论值
|
||||
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
|
||||
# print 'dataMatrix====', dataMatrix
|
||||
# print 'weights====', weights
|
||||
# n*3 * 3*1 = n*1
|
||||
h = sigmoid(dataMatrix * weights) # 矩阵乘法
|
||||
# print 'hhhhhhh====', h
|
||||
# labelMat是实际值
|
||||
error = (labelMat - h) # 向量相减
|
||||
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
|
||||
weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
|
||||
return array(weights)
|
||||
|
||||
|
||||
# 随机梯度下降
|
||||
# 梯度下降优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
|
||||
# 随机梯度下降一次只用一个样本点来更新回归系数
|
||||
def stocGradAscent0(dataMatrix, classLabels):
|
||||
'''
|
||||
Desc:
|
||||
随机梯度下降,只使用一个样本点来更新回归系数
|
||||
Args:
|
||||
dataMatrix -- 输入数据的数据特征(除去最后一列)
|
||||
classLabels -- 输入数据的类别标签(最后一列数据)
|
||||
Returns:
|
||||
weights -- 得到的最佳回归系数
|
||||
'''
|
||||
m, n = shape(dataMatrix)
|
||||
alpha = 0.01
|
||||
# n*1的矩阵
|
||||
# 函数ones创建一个全1的数组
|
||||
weights = ones(n) # 初始化长度为n的数组,元素全部为 1
|
||||
for i in range(m):
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
|
||||
h = sigmoid(sum(dataMatrix[i] * weights))
|
||||
# print 'dataMatrix[i]===', dataMatrix[i]
|
||||
# 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
|
||||
error = classLabels[i] - h
|
||||
# 0.01*(1*1)*(1*n)
|
||||
# print weights, "*" * 10, dataMatrix[i], "*" * 10, error
|
||||
weights = weights + alpha * error * dataMatrix[i]
|
||||
return weights
|
||||
|
||||
|
||||
# 随机梯度下降算法(随机化)
|
||||
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
|
||||
'''
|
||||
Desc:
|
||||
改进版的随机梯度下降,使用随机的一个样本来更新回归系数
|
||||
Args:
|
||||
dataMatrix -- 输入数据的数据特征(除去最后一列数据)
|
||||
classLabels -- 输入数据的类别标签(最后一列数据)
|
||||
numIter=150 -- 迭代次数
|
||||
Returns:
|
||||
weights -- 得到的最佳回归系数
|
||||
'''
|
||||
m, n = shape(dataMatrix)
|
||||
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
|
||||
# 随机梯度, 循环150,观察是否收敛
|
||||
for j in range(numIter):
|
||||
# [0, 1, 2 .. m-1]
|
||||
dataIndex = range(m)
|
||||
for i in range(m):
|
||||
# i和j的不断增大,导致alpha的值不断减少,但是不为0
|
||||
alpha = 4 / (
|
||||
1.0 + j + i
|
||||
) + 0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
|
||||
# 随机产生一个 0~len()之间的一个值
|
||||
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
|
||||
randIndex = int(random.uniform(0, len(dataIndex)))
|
||||
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
|
||||
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights))
|
||||
error = classLabels[dataIndex[randIndex]] - h
|
||||
# print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
|
||||
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
|
||||
del (dataIndex[randIndex])
|
||||
return weights
|
||||
|
||||
|
||||
# 可视化展示
|
||||
def plotBestFit(dataArr, labelMat, weights):
|
||||
'''
|
||||
Desc:
|
||||
将我们得到的数据可视化展示出来
|
||||
Args:
|
||||
dataArr:样本数据的特征
|
||||
labelMat:样本数据的类别标签,即目标变量
|
||||
weights:回归系数
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
|
||||
n = shape(dataArr)[0]
|
||||
xcord1 = []
|
||||
ycord1 = []
|
||||
xcord2 = []
|
||||
ycord2 = []
|
||||
for i in range(n):
|
||||
if int(labelMat[i]) == 1:
|
||||
xcord1.append(dataArr[i, 1])
|
||||
ycord1.append(dataArr[i, 2])
|
||||
else:
|
||||
xcord2.append(dataArr[i, 1])
|
||||
ycord2.append(dataArr[i, 2])
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
|
||||
ax.scatter(xcord2, ycord2, s=30, c='green')
|
||||
x = arange(-3.0, 3.0, 0.1)
|
||||
"""
|
||||
y的由来,卧槽,是不是没看懂?
|
||||
首先理论上是这个样子的。
|
||||
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
|
||||
w0*x0+w1*x1+w2*x2=f(x)
|
||||
x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
|
||||
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
|
||||
"""
|
||||
y = (-weights[0] - weights[1] * x) / weights[2]
|
||||
ax.plot(x, y)
|
||||
plt.xlabel('X')
|
||||
plt.ylabel('Y')
|
||||
plt.show()
|
||||
|
||||
|
||||
def simpleTest():
|
||||
# 1.收集并准备数据
|
||||
dataMat, labelMat = loadDataSet("data/5.Logistic/TestSet.txt")
|
||||
|
||||
# print dataMat, '---\n', labelMat
|
||||
# 2.训练模型, f(x)=a1*x1+b2*x2+..+nn*xn中 (a1,b2, .., nn).T的矩阵值
|
||||
# 因为数组没有是复制n份, array的乘法就是乘法
|
||||
dataArr = array(dataMat)
|
||||
# print dataArr
|
||||
# weights = gradAscent(dataArr, labelMat)
|
||||
# weights = stocGradAscent0(dataArr, labelMat)
|
||||
weights = stocGradAscent1(dataArr, labelMat)
|
||||
# print '*'*30, weights
|
||||
|
||||
# 数据可视化
|
||||
plotBestFit(dataArr, labelMat, weights)
|
||||
|
||||
|
||||
# --------------------------------------------------------------------------------
|
||||
# 从疝气病症预测病马的死亡率
|
||||
# 分类函数,根据回归系数和特征向量来计算 Sigmoid的值
|
||||
def classifyVector(inX, weights):
|
||||
'''
|
||||
Desc:
|
||||
最终的分类函数,根据回归系数和特征向量来计算 Sigmoid 的值,大于0.5函数返回1,否则返回0
|
||||
Args:
|
||||
inX -- 特征向量,features
|
||||
weights -- 根据梯度下降/随机梯度下降 计算得到的回归系数
|
||||
Returns:
|
||||
如果 prob 计算大于 0.5 函数返回 1
|
||||
否则返回 0
|
||||
'''
|
||||
prob = sigmoid(sum(inX * weights))
|
||||
if prob > 0.5: return 1.0
|
||||
else: return 0.0
|
||||
|
||||
|
||||
# 打开测试集和训练集,并对数据进行格式化处理
|
||||
def colicTest():
|
||||
'''
|
||||
Desc:
|
||||
打开测试集和训练集,并对数据进行格式化处理
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
errorRate -- 分类错误率
|
||||
'''
|
||||
frTrain = open('data/5.Logistic/horseColicTraining.txt')
|
||||
frTest = open('data/5.Logistic/horseColicTest.txt')
|
||||
trainingSet = []
|
||||
trainingLabels = []
|
||||
# 解析训练数据集中的数据特征和Labels
|
||||
# trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签
|
||||
for line in frTrain.readlines():
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(21):
|
||||
lineArr.append(float(currLine[i]))
|
||||
trainingSet.append(lineArr)
|
||||
trainingLabels.append(float(currLine[21]))
|
||||
# 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights
|
||||
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 500)
|
||||
# trainWeights = stocGradAscent0(array(trainingSet), trainingLabels)
|
||||
errorCount = 0
|
||||
numTestVec = 0.0
|
||||
# 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率
|
||||
for line in frTest.readlines():
|
||||
numTestVec += 1.0
|
||||
currLine = line.strip().split('\t')
|
||||
lineArr = []
|
||||
for i in range(21):
|
||||
lineArr.append(float(currLine[i]))
|
||||
if int(classifyVector(array(lineArr), trainWeights)) != int(
|
||||
currLine[21]):
|
||||
errorCount += 1
|
||||
errorRate = (float(errorCount) / numTestVec)
|
||||
print("the error rate of this test is: %f" % errorRate)
|
||||
return errorRate
|
||||
|
||||
|
||||
# 调用 colicTest() 10次并求结果的平均值
|
||||
def multiTest():
|
||||
numTests = 10
|
||||
errorSum = 0.0
|
||||
for k in range(numTests):
|
||||
errorSum += colicTest()
|
||||
print("after %d iterations the average error rate is: %f" % (numTests, errorSum / float(numTests)))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
simpleTest()
|
||||
# multiTest()
|
||||
|
|
@ -0,0 +1,282 @@
|
|||
#!/usr/bin/python
|
||||
# coding: utf8
|
||||
|
||||
'''
|
||||
Created on Oct 27, 2010
|
||||
Update on 2017-05-18
|
||||
Logistic Regression Working Module
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
scikit-learn的例子地址:http://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
|
||||
'''
|
||||
|
||||
# 逻辑回归中的 L1 惩罚和稀缺性 L1 Penalty and Sparsity in Logistic Regression
|
||||
'''
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
from sklearn import datasets
|
||||
from sklearn.preprocessing import StandardScaler
|
||||
|
||||
digits = datasets.load_digits()
|
||||
|
||||
X, y = digits.data, digits.target
|
||||
X = StandardScaler().fit_transform(X)
|
||||
|
||||
# 将大小数字分类为小
|
||||
y = (y > 4).astype(np.int)
|
||||
|
||||
|
||||
# 设置正则化参数
|
||||
for i, C in enumerate((100, 1, 0.01)):
|
||||
# 减少训练时间短的容忍度
|
||||
clf_l1_LR = LogisticRegression(C=C, penalty='l1', tol=0.01)
|
||||
clf_l2_LR = LogisticRegression(C=C, penalty='l2', tol=0.01)
|
||||
clf_l1_LR.fit(X, y)
|
||||
clf_l2_LR.fit(X, y)
|
||||
|
||||
coef_l1_LR = clf_l1_LR.coef_.ravel()
|
||||
coef_l2_LR = clf_l2_LR.coef_.ravel()
|
||||
|
||||
# coef_l1_LR contains zeros due to the
|
||||
# L1 sparsity inducing norm
|
||||
# 由于 L1 稀疏诱导规范,coef_l1_LR 包含零
|
||||
|
||||
sparsity_l1_LR = np.mean(coef_l1_LR == 0) * 100
|
||||
sparsity_l2_LR = np.mean(coef_l2_LR == 0) * 100
|
||||
|
||||
print("C=%.2f" % C)
|
||||
print("Sparsity with L1 penalty: %.2f%%" % sparsity_l1_LR)
|
||||
print("score with L1 penalty: %.4f" % clf_l1_LR.score(X, y))
|
||||
print("Sparsity with L2 penalty: %.2f%%" % sparsity_l2_LR)
|
||||
print("score with L2 penalty: %.4f" % clf_l2_LR.score(X, y))
|
||||
|
||||
l1_plot = plt.subplot(3, 2, 2 * i + 1)
|
||||
l2_plot = plt.subplot(3, 2, 2 * (i + 1))
|
||||
if i == 0:
|
||||
l1_plot.set_title("L1 penalty")
|
||||
l2_plot.set_title("L2 penalty")
|
||||
|
||||
l1_plot.imshow(np.abs(coef_l1_LR.reshape(8, 8)), interpolation='nearest',
|
||||
cmap='binary', vmax=1, vmin=0)
|
||||
l2_plot.imshow(np.abs(coef_l2_LR.reshape(8, 8)), interpolation='nearest',
|
||||
cmap='binary', vmax=1, vmin=0)
|
||||
plt.text(-8, 3, "C = %.2f" % C)
|
||||
|
||||
l1_plot.set_xticks(())
|
||||
l1_plot.set_yticks(())
|
||||
l2_plot.set_xticks(())
|
||||
l2_plot.set_yticks(())
|
||||
|
||||
plt.show()
|
||||
'''
|
||||
|
||||
# 具有 L1-逻辑回归的路径
|
||||
'''
|
||||
print(__doc__)
|
||||
|
||||
from datetime import datetime
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
from sklearn import linear_model
|
||||
from sklearn import datasets
|
||||
from sklearn.svm import l1_min_c
|
||||
|
||||
iris = datasets.load_iris()
|
||||
X = iris.data
|
||||
y = iris.target
|
||||
|
||||
X = X[y != 2]
|
||||
y = y[y != 2]
|
||||
|
||||
X -= np.mean(X, 0)
|
||||
|
||||
cs = l1_min_c(X, y, loss='log') * np.logspace(0, 3)
|
||||
|
||||
|
||||
print("Computing regularization path ...")
|
||||
start = datetime.now()
|
||||
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
|
||||
coefs_ = []
|
||||
for c in cs:
|
||||
clf.set_params(C=c)
|
||||
clf.fit(X, y)
|
||||
coefs_.append(clf.coef_.ravel().copy())
|
||||
print("This took ", datetime.now() - start)
|
||||
|
||||
coefs_ = np.array(coefs_)
|
||||
plt.plot(np.log10(cs), coefs_)
|
||||
ymin, ymax = plt.ylim()
|
||||
plt.xlabel('log(C)')
|
||||
plt.ylabel('Coefficients')
|
||||
plt.title('Logistic Regression Path')
|
||||
plt.axis('tight')
|
||||
plt.show()
|
||||
'''
|
||||
|
||||
# 绘制多项式和一对二的逻辑回归 Plot multinomial and One-vs-Rest Logistic Regression
|
||||
'''
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from sklearn.datasets import make_blobs
|
||||
from sklearn.linear_model import LogisticRegression
|
||||
|
||||
# 制作 3 类数据集进行分类
|
||||
centers = [[-5, 0], [0, 1.5], [5, -1]]
|
||||
X, y = make_blobs(n_samples=1000, centers=centers, random_state=40)
|
||||
transformation = [[0.4, 0.2], [-0.4, 1.2]]
|
||||
X = np.dot(X, transformation)
|
||||
|
||||
for multi_class in ('multinomial', 'ovr'):
|
||||
clf = LogisticRegression(solver='sag', max_iter=100, random_state=42,
|
||||
multi_class=multi_class).fit(X, y)
|
||||
|
||||
# 打印训练分数
|
||||
print("training score : %.3f (%s)" % (clf.score(X, y), multi_class))
|
||||
|
||||
# 创建一个网格来绘制
|
||||
h = .02 # 网格中的步长
|
||||
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
|
||||
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
|
||||
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
|
||||
np.arange(y_min, y_max, h))
|
||||
|
||||
# 绘制决策边界。为此,我们将为网格 [x_min, x_max]x[y_min, y_max]中的每个点分配一个颜色。
|
||||
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
|
||||
# 将结果放入彩色图
|
||||
Z = Z.reshape(xx.shape)
|
||||
plt.figure()
|
||||
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
|
||||
plt.title("Decision surface of LogisticRegression (%s)" % multi_class)
|
||||
plt.axis('tight')
|
||||
|
||||
# 将训练点也绘制进入
|
||||
colors = "bry"
|
||||
for i, color in zip(clf.classes_, colors):
|
||||
idx = np.where(y == i)
|
||||
plt.scatter(X[idx, 0], X[idx, 1], c=color, cmap=plt.cm.Paired)
|
||||
|
||||
# 绘制三个一对数分类器
|
||||
xmin, xmax = plt.xlim()
|
||||
ymin, ymax = plt.ylim()
|
||||
coef = clf.coef_
|
||||
intercept = clf.intercept_
|
||||
|
||||
def plot_hyperplane(c, color):
|
||||
def line(x0):
|
||||
return (-(x0 * coef[c, 0]) - intercept[c]) / coef[c, 1]
|
||||
plt.plot([xmin, xmax], [line(xmin), line(xmax)],
|
||||
ls="--", color=color)
|
||||
|
||||
for i, color in zip(clf.classes_, colors):
|
||||
plot_hyperplane(i, color)
|
||||
|
||||
plt.show()
|
||||
'''
|
||||
from __future__ import print_function
|
||||
|
||||
# Logistic Regression 3-class Classifier 逻辑回归 3-类 分类器
|
||||
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from sklearn import linear_model, datasets
|
||||
|
||||
# 引入一些数据来玩
|
||||
iris = datasets.load_iris()
|
||||
# 我们只采用样本数据的前两个feature
|
||||
X = iris.data[:, :2]
|
||||
Y = iris.target
|
||||
|
||||
h = .02 # 网格中的步长
|
||||
|
||||
logreg = linear_model.LogisticRegression(C=1e5)
|
||||
|
||||
# 我们创建了一个 Neighbours Classifier 的实例,并拟合数据。
|
||||
logreg.fit(X, Y)
|
||||
|
||||
# 绘制决策边界。为此我们将为网格 [x_min, x_max]x[y_min, y_max] 中的每个点分配一个颜色。
|
||||
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
|
||||
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
|
||||
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
|
||||
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
|
||||
|
||||
# 将结果放入彩色图中
|
||||
Z = Z.reshape(xx.shape)
|
||||
plt.figure(1, figsize=(4, 3))
|
||||
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
|
||||
|
||||
# 将训练点也同样放入彩色图中
|
||||
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired)
|
||||
plt.xlabel('Sepal length')
|
||||
plt.ylabel('Sepal width')
|
||||
|
||||
plt.xlim(xx.min(), xx.max())
|
||||
plt.ylim(yy.min(), yy.max())
|
||||
plt.xticks(())
|
||||
plt.yticks(())
|
||||
|
||||
plt.show()
|
||||
|
||||
# Logistic function 逻辑回归函数
|
||||
# 这个类似于咱们之前讲解 logistic 回归的 Sigmoid 函数,模拟的阶跃函数
|
||||
|
||||
'''
|
||||
print(__doc__)
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
from sklearn import linear_model
|
||||
|
||||
# 这是我们的测试集,它只是一条直线,带有一些高斯噪声。
|
||||
xmin, xmax = -5, 5
|
||||
n_samples = 100
|
||||
np.random.seed(0)
|
||||
X = np.random.normal(size=n_samples)
|
||||
y = (X > 0).astype(np.float)
|
||||
X[X > 0] *= 4
|
||||
X += .3 * np.random.normal(size=n_samples)
|
||||
|
||||
X = X[:, np.newaxis]
|
||||
# 运行分类器
|
||||
clf = linear_model.LogisticRegression(C=1e5)
|
||||
clf.fit(X, y)
|
||||
|
||||
# 并且画出我们的结果
|
||||
plt.figure(1, figsize=(4, 3))
|
||||
plt.clf()
|
||||
plt.scatter(X.ravel(), y, color='black', zorder=20)
|
||||
X_test = np.linspace(-5, 10, 300)
|
||||
|
||||
|
||||
def model(x):
|
||||
return 1 / (1 + np.exp(-x))
|
||||
loss = model(X_test * clf.coef_ + clf.intercept_).ravel()
|
||||
plt.plot(X_test, loss, color='red', linewidth=3)
|
||||
|
||||
ols = linear_model.LinearRegression()
|
||||
ols.fit(X, y)
|
||||
plt.plot(X_test, ols.coef_ * X_test + ols.intercept_, linewidth=1)
|
||||
plt.axhline(.5, color='.5')
|
||||
|
||||
plt.ylabel('y')
|
||||
plt.xlabel('X')
|
||||
plt.xticks(range(-5, 10))
|
||||
plt.yticks([0, 0.5, 1])
|
||||
plt.ylim(-.25, 1.25)
|
||||
plt.xlim(-4, 10)
|
||||
plt.legend(('Logistic Regression Model', 'Linear Regression Model'),
|
||||
loc="lower right", fontsize='small')
|
||||
plt.show()
|
||||
'''
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on 2017-06-28
|
||||
Updated on 2017-06-28
|
||||
SVM:最大边距分离超平面
|
||||
Author: 片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
sklearn-SVM译文链接: http://cwiki.apachecn.org/pages/viewpage.action?pageId=10031359
|
||||
"""
|
||||
from __future__ import print_function
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
from sklearn import svm
|
||||
|
||||
print(__doc__)
|
||||
|
||||
|
||||
# 创建40个分离点
|
||||
np.random.seed(0)
|
||||
# X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
|
||||
# Y = [0] * 20 + [1] * 20
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
对文件进行逐行解析,从而得到第行的类标签和整个数据矩阵
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 数据矩阵
|
||||
labelMat 类标签
|
||||
"""
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
X, Y = loadDataSet('data/6.SVM/testSet.txt')
|
||||
X = np.mat(X)
|
||||
|
||||
print(("X=", X))
|
||||
print(("Y=", Y))
|
||||
|
||||
# 拟合一个SVM模型
|
||||
clf = svm.SVC(kernel='linear')
|
||||
clf.fit(X, Y)
|
||||
|
||||
# 获取分割超平面
|
||||
w = clf.coef_[0]
|
||||
# 斜率
|
||||
a = -w[0]/w[1]
|
||||
# 从-5到5,顺序间隔采样50个样本,默认是num=50
|
||||
# xx = np.linspace(-5, 5) # , num=50)
|
||||
xx = np.linspace(-2, 10) # , num=50)
|
||||
# 二维的直线方程
|
||||
yy = a * xx - (clf.intercept_[0]) / w[1]
|
||||
print(("yy=", yy))
|
||||
|
||||
# plot the parallels to the separating hyperplane that pass through the support vectors
|
||||
# 通过支持向量绘制分割超平面
|
||||
print(("support_vectors_=", clf.support_vectors_))
|
||||
b = clf.support_vectors_[0]
|
||||
yy_down = a * xx + (b[1] - a * b[0])
|
||||
b = clf.support_vectors_[-1]
|
||||
yy_up = a * xx + (b[1] - a * b[0])
|
||||
|
||||
# plot the line, the points, and the nearest vectors to the plane
|
||||
plt.plot(xx, yy, 'k-')
|
||||
plt.plot(xx, yy_down, 'k--')
|
||||
plt.plot(xx, yy_up, 'k--')
|
||||
|
||||
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=80, facecolors='none')
|
||||
plt.scatter([X[:, 0]], [X[:, 1]], c=Y, cmap=plt.cm.Paired)
|
||||
|
||||
plt.axis('tight')
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,536 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on Nov 4, 2010
|
||||
Update on 2017-05-18
|
||||
Chapter 5 source file for Machine Learing in Action
|
||||
Author: Peter/geekidentity/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
class optStruct:
|
||||
"""
|
||||
建立的数据结构来保存所有的重要值
|
||||
"""
|
||||
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
|
||||
"""
|
||||
Args:
|
||||
dataMatIn 数据集
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率
|
||||
kTup 包含核函数信息的元组
|
||||
"""
|
||||
|
||||
self.X = dataMatIn
|
||||
self.labelMat = classLabels
|
||||
self.C = C
|
||||
self.tol = toler
|
||||
|
||||
# 数据的行数
|
||||
self.m = shape(dataMatIn)[0]
|
||||
self.alphas = mat(zeros((self.m, 1)))
|
||||
self.b = 0
|
||||
|
||||
# 误差缓存,第一列给出的是eCache是否有效的标志位,第二列给出的是实际的E值。
|
||||
self.eCache = mat(zeros((self.m, 2)))
|
||||
|
||||
# m行m列的矩阵
|
||||
self.K = mat(zeros((self.m, self.m)))
|
||||
for i in range(self.m):
|
||||
self.K[:, i] = kernelTrans(self.X, self.X[i, :], kTup)
|
||||
|
||||
|
||||
def kernelTrans(X, A, kTup): # calc the kernel or transform data to a higher dimensional space
|
||||
"""
|
||||
核转换函数
|
||||
Args:
|
||||
X dataMatIn数据集
|
||||
A dataMatIn数据集的第i行的数据
|
||||
kTup 核函数的信息
|
||||
|
||||
Returns:
|
||||
|
||||
"""
|
||||
m, n = shape(X)
|
||||
K = mat(zeros((m, 1)))
|
||||
if kTup[0] == 'lin':
|
||||
# linear kernel: m*n * n*1 = m*1
|
||||
K = X * A.T
|
||||
elif kTup[0] == 'rbf':
|
||||
for j in range(m):
|
||||
deltaRow = X[j, :] - A
|
||||
K[j] = deltaRow * deltaRow.T
|
||||
# 径向基函数的高斯版本
|
||||
K = exp(K / (-1 * kTup[1] ** 2)) # divide in NumPy is element-wise not matrix like Matlab
|
||||
else:
|
||||
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
|
||||
return K
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""loadDataSet(对文件进行逐行解析,从而得到第行的类标签和整个数据矩阵)
|
||||
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 数据矩阵
|
||||
labelMat 类标签
|
||||
"""
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
def calcEk(oS, k):
|
||||
"""calcEk(求 Ek误差:预测值-真实值的差)
|
||||
|
||||
该过程在完整版的SMO算法中陪出现次数较多,因此将其单独作为一个方法
|
||||
Args:
|
||||
oS optStruct对象
|
||||
k 具体的某一行
|
||||
|
||||
Returns:
|
||||
Ek 预测结果与真实结果比对,计算误差Ek
|
||||
"""
|
||||
fXk = float(multiply(oS.alphas, oS.labelMat).T * oS.K[:, k] + oS.b)
|
||||
Ek = fXk - float(oS.labelMat[k])
|
||||
return Ek
|
||||
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
随机选择一个整数
|
||||
Args:
|
||||
i 第一个alpha的下标
|
||||
m 所有alpha的数目
|
||||
Returns:
|
||||
j 返回一个不为i的随机数,在0~m之间的整数值
|
||||
"""
|
||||
j = i
|
||||
while j == i:
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
|
||||
def selectJ(i, oS, Ei): # this is the second choice -heurstic, and calcs Ej
|
||||
"""selectJ(返回最优的j和Ej)
|
||||
|
||||
内循环的启发式方法。
|
||||
选择第二个(内循环)alpha的alpha值
|
||||
这里的目标是选择合适的第二个alpha值以保证每次优化中采用最大步长。
|
||||
该函数的误差与第一个alpha值Ei和下标i有关。
|
||||
Args:
|
||||
i 具体的第i一行
|
||||
oS optStruct对象
|
||||
Ei 预测结果与真实结果比对,计算误差Ei
|
||||
|
||||
Returns:
|
||||
j 随机选出的第j一行
|
||||
Ej 预测结果与真实结果比对,计算误差Ej
|
||||
"""
|
||||
maxK = -1
|
||||
maxDeltaE = 0
|
||||
Ej = 0
|
||||
# 首先将输入值Ei在缓存中设置成为有效的。这里的有效意味着它已经计算好了。
|
||||
oS.eCache[i] = [1, Ei]
|
||||
|
||||
# print 'oS.eCache[%s]=%s' % (i, oS.eCache[i])
|
||||
# print 'oS.eCache[:, 0].A=%s' % oS.eCache[:, 0].A.T
|
||||
# """
|
||||
# # 返回非0的:行列值
|
||||
# nonzero(oS.eCache[:, 0].A)= (
|
||||
# 行: array([ 0, 2, 4, 5, 8, 10, 17, 18, 20, 21, 23, 25, 26, 29, 30, 39, 46,52, 54, 55, 62, 69, 70, 76, 79, 82, 94, 97]),
|
||||
# 列: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0])
|
||||
# )
|
||||
# """
|
||||
# print 'nonzero(oS.eCache[:, 0].A)=', nonzero(oS.eCache[:, 0].A)
|
||||
# # 取行的list
|
||||
# print 'nonzero(oS.eCache[:, 0].A)[0]=', nonzero(oS.eCache[:, 0].A)[0]
|
||||
# 非零E值的行的list列表,所对应的alpha值
|
||||
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
|
||||
if (len(validEcacheList)) > 1:
|
||||
for k in validEcacheList: # 在所有的值上进行循环,并选择其中使得改变最大的那个值
|
||||
if k == i:
|
||||
continue # don't calc for i, waste of time
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ek = calcEk(oS, k)
|
||||
deltaE = abs(Ei - Ek)
|
||||
if (deltaE > maxDeltaE):
|
||||
# 选择具有最大步长的j
|
||||
maxK = k
|
||||
maxDeltaE = deltaE
|
||||
Ej = Ek
|
||||
return maxK, Ej
|
||||
else: # 如果是第一次循环,则随机选择一个alpha值
|
||||
j = selectJrand(i, oS.m)
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ej = calcEk(oS, j)
|
||||
return j, Ej
|
||||
|
||||
|
||||
def updateEk(oS, k):
|
||||
"""updateEk(计算误差值并存入缓存中。)
|
||||
|
||||
在对alpha值进行优化之后会用到这个值。
|
||||
Args:
|
||||
oS optStruct对象
|
||||
k 某一列的行号
|
||||
"""
|
||||
|
||||
# 求 误差:预测值-真实值的差
|
||||
Ek = calcEk(oS, k)
|
||||
oS.eCache[k] = [1, Ek]
|
||||
|
||||
|
||||
def clipAlpha(aj, H, L):
|
||||
"""clipAlpha(调整aj的值,使aj处于 L<=aj<=H)
|
||||
Args:
|
||||
aj 目标值
|
||||
H 最大值
|
||||
L 最小值
|
||||
Returns:
|
||||
aj 目标值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
|
||||
def innerL(i, oS):
|
||||
"""innerL
|
||||
内循环代码
|
||||
Args:
|
||||
i 具体的某一行
|
||||
oS optStruct对象
|
||||
|
||||
Returns:
|
||||
0 找不到最优的值
|
||||
1 找到了最优的值,并且oS.Cache到缓存中
|
||||
"""
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ei = calcEk(oS, i)
|
||||
|
||||
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
|
||||
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
|
||||
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
'''
|
||||
# 检验训练样本(xi, yi)是否满足KKT条件
|
||||
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
|
||||
yi*f(i) == 1 and 0<alpha< C (on the boundary)
|
||||
yi*f(i) <= 1 and alpha = C (between the boundary)
|
||||
'''
|
||||
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
|
||||
# 选择最大的误差对应的j进行优化。效果更明显
|
||||
j, Ej = selectJ(i, oS, Ei)
|
||||
alphaIold = oS.alphas[i].copy()
|
||||
alphaJold = oS.alphas[j].copy()
|
||||
|
||||
# L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接return 0
|
||||
if (oS.labelMat[i] != oS.labelMat[j]):
|
||||
L = max(0, oS.alphas[j] - oS.alphas[i])
|
||||
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
|
||||
else:
|
||||
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
|
||||
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
|
||||
if L == H:
|
||||
# print("L==H")
|
||||
return 0
|
||||
|
||||
# eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
|
||||
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
|
||||
eta = 2.0 * oS.K[i, j] - oS.K[i, i] - oS.K[j, j] # changed for kernel
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
return 0
|
||||
|
||||
# 计算出一个新的alphas[j]值
|
||||
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
|
||||
# 并使用辅助函数,以及L和H对其进行调整
|
||||
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
|
||||
# 更新误差缓存
|
||||
updateEk(oS, j)
|
||||
|
||||
# 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
|
||||
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
|
||||
# print("j not moving enough")
|
||||
return 0
|
||||
|
||||
# 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
|
||||
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
|
||||
# 更新误差缓存
|
||||
updateEk(oS, i)
|
||||
|
||||
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
|
||||
# w= Σ[1~n] ai*yi*xi => b = yi- Σ[1~n] ai*yi(xi*xj)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
|
||||
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, i] - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.K[i, j]
|
||||
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, j] - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.K[j, j]
|
||||
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
|
||||
oS.b = b1
|
||||
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
|
||||
oS.b = b2
|
||||
else:
|
||||
oS.b = (b1 + b2) / 2.0
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup=('lin', 0)):
|
||||
"""
|
||||
完整SMO算法外循环,与smoSimple有些类似,但这里的循环退出条件更多一些
|
||||
Args:
|
||||
dataMatIn 数据集
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率
|
||||
maxIter 退出前最大的循环次数
|
||||
kTup 包含核函数信息的元组
|
||||
Returns:
|
||||
b 模型的常量值
|
||||
alphas 拉格朗日乘子
|
||||
"""
|
||||
|
||||
# 创建一个 optStruct 对象
|
||||
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler, kTup)
|
||||
iter = 0
|
||||
entireSet = True
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 循环遍历:循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 当entireSet=true or 非边界alpha对没有了;就开始寻找 alpha对,然后决定是否要进行else。
|
||||
if entireSet:
|
||||
# 在数据集上遍历所有可能的alpha
|
||||
for i in range(oS.m):
|
||||
# 是否存在alpha对,存在就+1
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
# print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
|
||||
# 对已存在 alpha对,选出非边界的alpha值,进行优化。
|
||||
else:
|
||||
# 遍历所有的非边界alpha值,也就是不在边界0或C上的值。
|
||||
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
# print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
|
||||
# 如果找到alpha对,就优化非边界alpha值,否则,就重新进行寻找,如果寻找一遍 遍历所有的行还是没找到,就退出循环。
|
||||
if entireSet:
|
||||
entireSet = False # toggle entire set loop
|
||||
elif (alphaPairsChanged == 0):
|
||||
entireSet = True
|
||||
print("iteration number: %d" % iter)
|
||||
return oS.b, oS.alphas
|
||||
|
||||
|
||||
def calcWs(alphas, dataArr, classLabels):
|
||||
"""
|
||||
基于alpha计算w值
|
||||
Args:
|
||||
alphas 拉格朗日乘子
|
||||
dataArr feature数据集
|
||||
classLabels 目标变量数据集
|
||||
|
||||
Returns:
|
||||
wc 回归系数
|
||||
"""
|
||||
X = mat(dataArr)
|
||||
labelMat = mat(classLabels).transpose()
|
||||
m, n = shape(X)
|
||||
w = zeros((n, 1))
|
||||
for i in range(m):
|
||||
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
|
||||
return w
|
||||
|
||||
|
||||
def testRbf(k1=1.3):
|
||||
dataArr, labelArr = loadDataSet('data/6.SVM/testSetRBF.txt')
|
||||
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) # C=200 important
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
svInd = nonzero(alphas.A > 0)[0]
|
||||
sVs = datMat[svInd] # get matrix of only support vectors
|
||||
labelSV = labelMat[svInd]
|
||||
print("there are %d Support Vectors" % shape(sVs)[0])
|
||||
m, n = shape(datMat)
|
||||
errorCount = 0
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
|
||||
|
||||
# 和这个svm-simple类似: fXi = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[i, :].T)) + b
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]):
|
||||
errorCount += 1
|
||||
print("the training error rate is: %f" % (float(errorCount) / m))
|
||||
|
||||
dataArr, labelArr = loadDataSet('data/6.SVM/testSetRBF2.txt')
|
||||
errorCount = 0
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
m, n = shape(datMat)
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]):
|
||||
errorCount += 1
|
||||
print("the test error rate is: %f" % (float(errorCount) / m))
|
||||
|
||||
|
||||
def img2vector(filename):
|
||||
returnVect = zeros((1, 1024))
|
||||
fr = open(filename)
|
||||
for i in range(32):
|
||||
lineStr = fr.readline()
|
||||
for j in range(32):
|
||||
returnVect[0, 32 * i + j] = int(lineStr[j])
|
||||
return returnVect
|
||||
|
||||
|
||||
def loadImages(dirName):
|
||||
from os import listdir
|
||||
hwLabels = []
|
||||
print(dirName)
|
||||
trainingFileList = listdir(dirName) # load the training set
|
||||
m = len(trainingFileList)
|
||||
trainingMat = zeros((m, 1024))
|
||||
for i in range(m):
|
||||
fileNameStr = trainingFileList[i]
|
||||
fileStr = fileNameStr.split('.')[0] # take off .txt
|
||||
classNumStr = int(fileStr.split('_')[0])
|
||||
if classNumStr == 9:
|
||||
hwLabels.append(-1)
|
||||
else:
|
||||
hwLabels.append(1)
|
||||
trainingMat[i, :] = img2vector('%s/%s' % (dirName, fileNameStr))
|
||||
return trainingMat, hwLabels
|
||||
|
||||
|
||||
def testDigits(kTup=('rbf', 10)):
|
||||
|
||||
# 1. 导入训练数据
|
||||
dataArr, labelArr = loadImages('data/6.SVM/trainingDigits')
|
||||
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
svInd = nonzero(alphas.A > 0)[0]
|
||||
sVs = datMat[svInd]
|
||||
labelSV = labelMat[svInd]
|
||||
# print("there are %d Support Vectors" % shape(sVs)[0])
|
||||
m, n = shape(datMat)
|
||||
errorCount = 0
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
|
||||
# 1*m * m*1 = 1*1 单个预测结果
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]): errorCount += 1
|
||||
print("the training error rate is: %f" % (float(errorCount) / m))
|
||||
|
||||
# 2. 导入测试数据
|
||||
dataArr, labelArr = loadImages('data/6.SVM/testDigits')
|
||||
errorCount = 0
|
||||
datMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).transpose()
|
||||
m, n = shape(datMat)
|
||||
for i in range(m):
|
||||
kernelEval = kernelTrans(sVs, datMat[i, :], kTup)
|
||||
predict = kernelEval.T * multiply(labelSV, alphas[svInd]) + b
|
||||
if sign(predict) != sign(labelArr[i]): errorCount += 1
|
||||
print("the test error rate is: %f" % (float(errorCount) / m))
|
||||
|
||||
|
||||
def plotfig_SVM(xArr, yArr, ws, b, alphas):
|
||||
"""
|
||||
参考地址:
|
||||
http://blog.csdn.net/maoersong/article/details/24315633
|
||||
http://www.cnblogs.com/JustForCS/p/5283489.html
|
||||
http://blog.csdn.net/kkxgx/article/details/6951959
|
||||
"""
|
||||
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr)
|
||||
|
||||
# b原来是矩阵,先转为数组类型后其数组大小为(1,1),所以后面加[0],变为(1,)
|
||||
b = array(b)[0]
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
|
||||
# 注意flatten的用法
|
||||
ax.scatter(xMat[:, 0].flatten().A[0], xMat[:, 1].flatten().A[0])
|
||||
|
||||
# x最大值,最小值根据原数据集dataArr[:, 0]的大小而定
|
||||
x = arange(-1.0, 10.0, 0.1)
|
||||
|
||||
# 根据x.w + b = 0 得到,其式子展开为w0.x1 + w1.x2 + b = 0, x2就是y值
|
||||
y = (-b-ws[0, 0]*x)/ws[1, 0]
|
||||
ax.plot(x, y)
|
||||
|
||||
for i in range(shape(yMat[0, :])[1]):
|
||||
if yMat[0, i] > 0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'cx')
|
||||
else:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'kp')
|
||||
|
||||
# 找到支持向量,并在图中标红
|
||||
for i in range(100):
|
||||
if alphas[i] > 0.0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'ro')
|
||||
plt.show()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# 无核函数的测试
|
||||
# 获取特征和目标变量
|
||||
dataArr, labelArr = loadDataSet('data/6.SVM/testSet.txt')
|
||||
# print labelArr
|
||||
|
||||
# b是常量值, alphas是拉格朗日乘子
|
||||
b, alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40)
|
||||
print('/n/n/n')
|
||||
print('b=', b)
|
||||
print('alphas[alphas>0]=', alphas[alphas > 0])
|
||||
print('shape(alphas[alphas > 0])=', shape(alphas[alphas > 0]))
|
||||
for i in range(100):
|
||||
if alphas[i] > 0:
|
||||
print(dataArr[i], labelArr[i])
|
||||
# 画图
|
||||
ws = calcWs(alphas, dataArr, labelArr)
|
||||
plotfig_SVM(dataArr, labelArr, ws, b, alphas)
|
||||
|
||||
# 有核函数的测试
|
||||
testRbf(0.8)
|
||||
|
||||
# # 项目实战
|
||||
# # 示例:手写识别问题回顾
|
||||
# testDigits(('rbf', 0.1))
|
||||
# testDigits(('rbf', 5))
|
||||
# testDigits(('rbf', 10))
|
||||
# testDigits(('rbf', 50))
|
||||
# testDigits(('rbf', 100))
|
||||
# testDigits(('lin'))
|
||||
|
|
@ -0,0 +1,375 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on Nov 4, 2010
|
||||
Update on 2017-05-18
|
||||
Chapter 5 source file for Machine Learing in Action
|
||||
Author: Peter/geekidentity/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
class optStruct:
|
||||
def __init__(self, dataMatIn, classLabels, C, toler): # Initialize the structure with the parameters
|
||||
self.X = dataMatIn
|
||||
self.labelMat = classLabels
|
||||
self.C = C
|
||||
self.tol = toler
|
||||
self.m = shape(dataMatIn)[0]
|
||||
self.alphas = mat(zeros((self.m, 1)))
|
||||
self.b = 0
|
||||
self.eCache = mat(zeros((self.m, 2))) # first column is valid flag
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""loadDataSet(对文件进行逐行解析,从而得到第行的类标签和整个数据矩阵)
|
||||
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 数据矩阵
|
||||
labelMat 类标签
|
||||
"""
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
随机选择一个整数
|
||||
Args:
|
||||
i 第一个alpha的下标
|
||||
m 所有alpha的数目
|
||||
Returns:
|
||||
j 返回一个不为i的随机数,在0~m之间的整数值
|
||||
"""
|
||||
j = i
|
||||
while j == i:
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
|
||||
def clipAlpha(aj, H, L):
|
||||
"""clipAlpha(调整aj的值,使aj处于 L<=aj<=H)
|
||||
Args:
|
||||
aj 目标值
|
||||
H 最大值
|
||||
L 最小值
|
||||
Returns:
|
||||
aj 目标值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
|
||||
def calcEk(oS, k):
|
||||
"""calcEk(求 Ek误差:预测值-真实值的差)
|
||||
|
||||
该过程在完整版的SMO算法中陪出现次数较多,因此将其单独作为一个方法
|
||||
Args:
|
||||
oS optStruct对象
|
||||
k 具体的某一行
|
||||
|
||||
Returns:
|
||||
Ek 预测结果与真实结果比对,计算误差Ek
|
||||
"""
|
||||
fXk = float(multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T)) + oS.b
|
||||
Ek = fXk - float(oS.labelMat[k])
|
||||
return Ek
|
||||
|
||||
|
||||
def selectJ(i, oS, Ei): # this is the second choice -heurstic, and calcs Ej
|
||||
"""selectJ(返回最优的j和Ej)
|
||||
|
||||
内循环的启发式方法。
|
||||
选择第二个(内循环)alpha的alpha值
|
||||
这里的目标是选择合适的第二个alpha值以保证每次优化中采用最大步长。
|
||||
该函数的误差与第一个alpha值Ei和下标i有关。
|
||||
Args:
|
||||
i 具体的第i一行
|
||||
oS optStruct对象
|
||||
Ei 预测结果与真实结果比对,计算误差Ei
|
||||
|
||||
Returns:
|
||||
j 随机选出的第j一行
|
||||
Ej 预测结果与真实结果比对,计算误差Ej
|
||||
"""
|
||||
maxK = -1
|
||||
maxDeltaE = 0
|
||||
Ej = 0
|
||||
# 首先将输入值Ei在缓存中设置成为有效的。这里的有效意味着它已经计算好了。
|
||||
oS.eCache[i] = [1, Ei]
|
||||
|
||||
# print 'oS.eCache[%s]=%s' % (i, oS.eCache[i])
|
||||
# print 'oS.eCache[:, 0].A=%s' % oS.eCache[:, 0].A.T
|
||||
# """
|
||||
# # 返回非0的:行列值
|
||||
# nonzero(oS.eCache[:, 0].A)= (
|
||||
# 行: array([ 0, 2, 4, 5, 8, 10, 17, 18, 20, 21, 23, 25, 26, 29, 30, 39, 46,52, 54, 55, 62, 69, 70, 76, 79, 82, 94, 97]),
|
||||
# 列: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0])
|
||||
# )
|
||||
# """
|
||||
# print 'nonzero(oS.eCache[:, 0].A)=', nonzero(oS.eCache[:, 0].A)
|
||||
# # 取行的list
|
||||
# print 'nonzero(oS.eCache[:, 0].A)[0]=', nonzero(oS.eCache[:, 0].A)[0]
|
||||
# 非零E值的行的list列表,所对应的alpha值
|
||||
validEcacheList = nonzero(oS.eCache[:, 0].A)[0]
|
||||
if (len(validEcacheList)) > 1:
|
||||
for k in validEcacheList: # 在所有的值上进行循环,并选择其中使得改变最大的那个值
|
||||
if k == i:
|
||||
continue # don't calc for i, waste of time
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ek = calcEk(oS, k)
|
||||
deltaE = abs(Ei - Ek)
|
||||
if (deltaE > maxDeltaE):
|
||||
maxK = k
|
||||
maxDeltaE = deltaE
|
||||
Ej = Ek
|
||||
return maxK, Ej
|
||||
else: # 如果是第一次循环,则随机选择一个alpha值
|
||||
j = selectJrand(i, oS.m)
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ej = calcEk(oS, j)
|
||||
return j, Ej
|
||||
|
||||
|
||||
def updateEk(oS, k): # after any alpha has changed update the new value in the cache
|
||||
"""updateEk(计算误差值并存入缓存中。)
|
||||
|
||||
在对alpha值进行优化之后会用到这个值。
|
||||
Args:
|
||||
oS optStruct对象
|
||||
k 某一列的行号
|
||||
"""
|
||||
|
||||
# 求 误差:预测值-真实值的差
|
||||
Ek = calcEk(oS, k)
|
||||
oS.eCache[k] = [1, Ek]
|
||||
|
||||
|
||||
def innerL(i, oS):
|
||||
"""innerL
|
||||
内循环代码
|
||||
Args:
|
||||
i 具体的某一行
|
||||
oS optStruct对象
|
||||
|
||||
Returns:
|
||||
0 找不到最优的值
|
||||
1 找到了最优的值,并且oS.Cache到缓存中
|
||||
"""
|
||||
|
||||
# 求 Ek误差:预测值-真实值的差
|
||||
Ei = calcEk(oS, i)
|
||||
|
||||
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
|
||||
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
|
||||
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
'''
|
||||
# 检验训练样本(xi, yi)是否满足KKT条件
|
||||
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
|
||||
yi*f(i) == 1 and 0<alpha< C (on the boundary)
|
||||
yi*f(i) <= 1 and alpha = C (between the boundary)
|
||||
'''
|
||||
if ((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
|
||||
# 选择最大的误差对应的j进行优化。效果更明显
|
||||
j, Ej = selectJ(i, oS, Ei)
|
||||
alphaIold = oS.alphas[i].copy()
|
||||
alphaJold = oS.alphas[j].copy()
|
||||
|
||||
# L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接return 0
|
||||
if (oS.labelMat[i] != oS.labelMat[j]):
|
||||
L = max(0, oS.alphas[j] - oS.alphas[i])
|
||||
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
|
||||
else:
|
||||
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
|
||||
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
|
||||
if L == H:
|
||||
print("L==H")
|
||||
return 0
|
||||
|
||||
# eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
|
||||
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
|
||||
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
return 0
|
||||
|
||||
# 计算出一个新的alphas[j]值
|
||||
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
|
||||
# 并使用辅助函数,以及L和H对其进行调整
|
||||
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
|
||||
# 更新误差缓存
|
||||
updateEk(oS, j)
|
||||
|
||||
# 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
|
||||
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
|
||||
print("j not moving enough")
|
||||
return 0
|
||||
|
||||
# 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
|
||||
oS.alphas[i] += oS.labelMat[j] * oS.labelMat[i] * (alphaJold - oS.alphas[j])
|
||||
# 更新误差缓存
|
||||
updateEk(oS, i)
|
||||
|
||||
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
|
||||
# w= Σ[1~n] ai*yi*xi => b = yj Σ[1~n] ai*yi(xi*xj)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
|
||||
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[i, :] * oS.X[j, :].T
|
||||
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
|
||||
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]):
|
||||
oS.b = b1
|
||||
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]):
|
||||
oS.b = b2
|
||||
else:
|
||||
oS.b = (b1 + b2) / 2.0
|
||||
return 1
|
||||
else:
|
||||
return 0
|
||||
|
||||
|
||||
def smoP(dataMatIn, classLabels, C, toler, maxIter):
|
||||
"""
|
||||
完整SMO算法外循环,与smoSimple有些类似,但这里的循环退出条件更多一些
|
||||
Args:
|
||||
dataMatIn 数据集
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率
|
||||
maxIter 退出前最大的循环次数
|
||||
Returns:
|
||||
b 模型的常量值
|
||||
alphas 拉格朗日乘子
|
||||
"""
|
||||
|
||||
# 创建一个 optStruct 对象
|
||||
oS = optStruct(mat(dataMatIn), mat(classLabels).transpose(), C, toler)
|
||||
iter = 0
|
||||
entireSet = True
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 循环遍历:循环maxIter次 并且 (alphaPairsChanged存在可以改变 or 所有行遍历一遍)
|
||||
# 循环迭代结束 或者 循环遍历所有alpha后,alphaPairs还是没变化
|
||||
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
|
||||
alphaPairsChanged = 0
|
||||
|
||||
# 当entireSet=true or 非边界alpha对没有了;就开始寻找 alpha对,然后决定是否要进行else。
|
||||
if entireSet:
|
||||
# 在数据集上遍历所有可能的alpha
|
||||
for i in range(oS.m):
|
||||
# 是否存在alpha对,存在就+1
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
# 对已存在 alpha对,选出非边界的alpha值,进行优化。
|
||||
else:
|
||||
# 遍历所有的非边界alpha值,也就是不在边界0或C上的值。
|
||||
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
|
||||
for i in nonBoundIs:
|
||||
alphaPairsChanged += innerL(i, oS)
|
||||
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
iter += 1
|
||||
|
||||
# 如果找到alpha对,就优化非边界alpha值,否则,就重新进行寻找,如果寻找一遍 遍历所有的行还是没找到,就退出循环。
|
||||
if entireSet:
|
||||
entireSet = False # toggle entire set loop
|
||||
elif (alphaPairsChanged == 0):
|
||||
entireSet = True
|
||||
print("iteration number: %d" % iter)
|
||||
return oS.b, oS.alphas
|
||||
|
||||
|
||||
def calcWs(alphas, dataArr, classLabels):
|
||||
"""
|
||||
基于alpha计算w值
|
||||
Args:
|
||||
alphas 拉格朗日乘子
|
||||
dataArr feature数据集
|
||||
classLabels 目标变量数据集
|
||||
|
||||
Returns:
|
||||
wc 回归系数
|
||||
"""
|
||||
X = mat(dataArr)
|
||||
labelMat = mat(classLabels).transpose()
|
||||
m, n = shape(X)
|
||||
w = zeros((n, 1))
|
||||
for i in range(m):
|
||||
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
|
||||
return w
|
||||
|
||||
|
||||
def plotfig_SVM(xArr, yArr, ws, b, alphas):
|
||||
"""
|
||||
参考地址:
|
||||
http://blog.csdn.net/maoersong/article/details/24315633
|
||||
http://www.cnblogs.com/JustForCS/p/5283489.html
|
||||
http://blog.csdn.net/kkxgx/article/details/6951959
|
||||
"""
|
||||
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr)
|
||||
|
||||
# b原来是矩阵,先转为数组类型后其数组大小为(1,1),所以后面加[0],变为(1,)
|
||||
b = array(b)[0]
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
|
||||
# 注意flatten的用法
|
||||
ax.scatter(xMat[:, 0].flatten().A[0], xMat[:, 1].flatten().A[0])
|
||||
|
||||
# x最大值,最小值根据原数据集dataArr[:, 0]的大小而定
|
||||
x = arange(-1.0, 10.0, 0.1)
|
||||
|
||||
# 根据x.w + b = 0 得到,其式子展开为w0.x1 + w1.x2 + b = 0, x2就是y值
|
||||
y = (-b-ws[0, 0]*x)/ws[1, 0]
|
||||
ax.plot(x, y)
|
||||
|
||||
for i in range(shape(yMat[0, :])[1]):
|
||||
if yMat[0, i] > 0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'cx')
|
||||
else:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'kp')
|
||||
|
||||
# 找到支持向量,并在图中标红
|
||||
for i in range(100):
|
||||
if alphas[i] > 0.0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'ro')
|
||||
plt.show()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 获取特征和目标变量
|
||||
dataArr, labelArr = loadDataSet('data/6.SVM/testSet.txt')
|
||||
# print labelArr
|
||||
|
||||
# b是常量值, alphas是拉格朗日乘子
|
||||
b, alphas = smoP(dataArr, labelArr, 0.6, 0.001, 40)
|
||||
print('/n/n/n')
|
||||
print('b=', b)
|
||||
print('alphas[alphas>0]=', alphas[alphas > 0])
|
||||
print('shape(alphas[alphas > 0])=', shape(alphas[alphas > 0]))
|
||||
for i in range(100):
|
||||
if alphas[i] > 0:
|
||||
print(dataArr[i], labelArr[i])
|
||||
# 画图
|
||||
ws = calcWs(alphas, dataArr, labelArr)
|
||||
plotfig_SVM(dataArr, labelArr, ws, b, alphas)
|
||||
|
|
@ -0,0 +1,255 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on Nov 4, 2010
|
||||
Update on 2017-05-18
|
||||
Chapter 5 source file for Machine Learing in Action
|
||||
Author: Peter/geekidentity/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
"""
|
||||
对文件进行逐行解析,从而得到第行的类标签和整个特征矩阵
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 特征矩阵
|
||||
labelMat 类标签
|
||||
"""
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = line.strip().split('\t')
|
||||
dataMat.append([float(lineArr[0]), float(lineArr[1])])
|
||||
labelMat.append(float(lineArr[2]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
def selectJrand(i, m):
|
||||
"""
|
||||
随机选择一个整数
|
||||
Args:
|
||||
i 第一个alpha的下标
|
||||
m 所有alpha的数目
|
||||
Returns:
|
||||
j 返回一个不为i的随机数,在0~m之间的整数值
|
||||
"""
|
||||
j = i
|
||||
while j == i:
|
||||
j = int(random.uniform(0, m))
|
||||
return j
|
||||
|
||||
|
||||
def clipAlpha(aj, H, L):
|
||||
"""clipAlpha(调整aj的值,使aj处于 L<=aj<=H)
|
||||
Args:
|
||||
aj 目标值
|
||||
H 最大值
|
||||
L 最小值
|
||||
Returns:
|
||||
aj 目标值
|
||||
"""
|
||||
if aj > H:
|
||||
aj = H
|
||||
if L > aj:
|
||||
aj = L
|
||||
return aj
|
||||
|
||||
|
||||
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
|
||||
"""smoSimple
|
||||
|
||||
Args:
|
||||
dataMatIn 数据集
|
||||
classLabels 类别标签
|
||||
C 松弛变量(常量值),允许有些数据点可以处于分隔面的错误一侧。
|
||||
控制最大化间隔和保证大部分的函数间隔小于1.0这两个目标的权重。
|
||||
可以通过调节该参数达到不同的结果。
|
||||
toler 容错率(是指在某个体系中能减小一些因素或选择对某个系统产生不稳定的概率。)
|
||||
maxIter 退出前最大的循环次数
|
||||
Returns:
|
||||
b 模型的常量值
|
||||
alphas 拉格朗日乘子
|
||||
"""
|
||||
dataMatrix = mat(dataMatIn)
|
||||
# 矩阵转置 和 .T 一样的功能
|
||||
labelMat = mat(classLabels).transpose()
|
||||
m, n = shape(dataMatrix)
|
||||
|
||||
# 初始化 b和alphas(alpha有点类似权重值。)
|
||||
b = 0
|
||||
alphas = mat(zeros((m, 1)))
|
||||
|
||||
# 没有任何alpha改变的情况下遍历数据的次数
|
||||
iter = 0
|
||||
while (iter < maxIter):
|
||||
# w = calcWs(alphas, dataMatIn, classLabels)
|
||||
# print("w:", w)
|
||||
|
||||
# 记录alpha是否已经进行优化,每次循环时设为0,然后再对整个集合顺序遍历
|
||||
alphaPairsChanged = 0
|
||||
for i in range(m):
|
||||
# print 'alphas=', alphas
|
||||
# print 'labelMat=', labelMat
|
||||
# print 'multiply(alphas, labelMat)=', multiply(alphas, labelMat)
|
||||
# 我们预测的类别 y = w^Tx[i]+b; 其中因为 w = Σ(1~n) a[n]*lable[n]*x[n]
|
||||
fXi = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[i, :].T)) + b
|
||||
# 预测结果与真实结果比对,计算误差Ei
|
||||
Ei = fXi - float(labelMat[i])
|
||||
|
||||
# 约束条件 (KKT条件是解决最优化问题的时用到的一种方法。我们这里提到的最优化问题通常是指对于给定的某一函数,求其在指定作用域上的全局最小值)
|
||||
# 0<=alphas[i]<=C,但由于0和C是边界值,我们无法进行优化,因为需要增加一个alphas和降低一个alphas。
|
||||
# 表示发生错误的概率:labelMat[i]*Ei 如果超出了 toler, 才需要优化。至于正负号,我们考虑绝对值就对了。
|
||||
'''
|
||||
# 检验训练样本(xi, yi)是否满足KKT条件
|
||||
yi*f(i) >= 1 and alpha = 0 (outside the boundary)
|
||||
yi*f(i) == 1 and 0<alpha< C (on the boundary)
|
||||
yi*f(i) <= 1 and alpha = C (between the boundary)
|
||||
'''
|
||||
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
|
||||
|
||||
# 如果满足优化的条件,我们就随机选取非i的一个点,进行优化比较
|
||||
j = selectJrand(i, m)
|
||||
# 预测j的结果
|
||||
fXj = float(multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[j, :].T)) + b
|
||||
Ej = fXj - float(labelMat[j])
|
||||
alphaIold = alphas[i].copy()
|
||||
alphaJold = alphas[j].copy()
|
||||
|
||||
# L和H用于将alphas[j]调整到0-C之间。如果L==H,就不做任何改变,直接执行continue语句
|
||||
# labelMat[i] != labelMat[j] 表示异侧,就相减,否则是同侧,就相加。
|
||||
if (labelMat[i] != labelMat[j]):
|
||||
L = max(0, alphas[j] - alphas[i])
|
||||
H = min(C, C + alphas[j] - alphas[i])
|
||||
else:
|
||||
L = max(0, alphas[j] + alphas[i] - C)
|
||||
H = min(C, alphas[j] + alphas[i])
|
||||
# 如果相同,就没发优化了
|
||||
if L == H:
|
||||
print("L==H")
|
||||
continue
|
||||
|
||||
# eta是alphas[j]的最优修改量,如果eta==0,需要退出for循环的当前迭代过程
|
||||
# 参考《统计学习方法》李航-P125~P128<序列最小最优化算法>
|
||||
eta = 2.0 * dataMatrix[i, :]*dataMatrix[j, :].T - dataMatrix[i, :]*dataMatrix[i, :].T - dataMatrix[j, :]*dataMatrix[j, :].T
|
||||
if eta >= 0:
|
||||
print("eta>=0")
|
||||
continue
|
||||
|
||||
# 计算出一个新的alphas[j]值
|
||||
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
|
||||
# 并使用辅助函数,以及L和H对其进行调整
|
||||
alphas[j] = clipAlpha(alphas[j], H, L)
|
||||
# 检查alpha[j]是否只是轻微的改变,如果是的话,就退出for循环。
|
||||
if (abs(alphas[j] - alphaJold) < 0.00001):
|
||||
print("j not moving enough")
|
||||
continue
|
||||
# 然后alphas[i]和alphas[j]同样进行改变,虽然改变的大小一样,但是改变的方向正好相反
|
||||
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
|
||||
# 在对alpha[i], alpha[j] 进行优化之后,给这两个alpha值设置一个常数b。
|
||||
# w= Σ[1~n] ai*yi*xi => b = yj- Σ[1~n] ai*yi(xi*xj)
|
||||
# 所以: b1 - b = (y1-y) - Σ[1~n] yi*(a1-a)*(xi*x1)
|
||||
# 为什么减2遍? 因为是 减去Σ[1~n],正好2个变量i和j,所以减2遍
|
||||
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[i, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i, :]*dataMatrix[j, :].T
|
||||
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i, :]*dataMatrix[j, :].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j, :]*dataMatrix[j, :].T
|
||||
if (0 < alphas[i]) and (C > alphas[i]):
|
||||
b = b1
|
||||
elif (0 < alphas[j]) and (C > alphas[j]):
|
||||
b = b2
|
||||
else:
|
||||
b = (b1 + b2)/2.0
|
||||
alphaPairsChanged += 1
|
||||
print("iter: %d i:%d, pairs changed %d" % (iter, i, alphaPairsChanged))
|
||||
# 在for循环外,检查alpha值是否做了更新,如果在更新则将iter设为0后继续运行程序
|
||||
# 知道更新完毕后,iter次循环无变化,才推出循环。
|
||||
if (alphaPairsChanged == 0):
|
||||
iter += 1
|
||||
else:
|
||||
iter = 0
|
||||
print("iteration number: %d" % iter)
|
||||
return b, alphas
|
||||
|
||||
|
||||
def calcWs(alphas, dataArr, classLabels):
|
||||
"""
|
||||
基于alpha计算w值
|
||||
Args:
|
||||
alphas 拉格朗日乘子
|
||||
dataArr feature数据集
|
||||
classLabels 目标变量数据集
|
||||
|
||||
Returns:
|
||||
wc 回归系数
|
||||
"""
|
||||
X = mat(dataArr)
|
||||
labelMat = mat(classLabels).transpose()
|
||||
m, n = shape(X)
|
||||
w = zeros((n, 1))
|
||||
for i in range(m):
|
||||
w += multiply(alphas[i] * labelMat[i], X[i, :].T)
|
||||
return w
|
||||
|
||||
|
||||
def plotfig_SVM(xMat, yMat, ws, b, alphas):
|
||||
"""
|
||||
参考地址:
|
||||
http://blog.csdn.net/maoersong/article/details/24315633
|
||||
http://www.cnblogs.com/JustForCS/p/5283489.html
|
||||
http://blog.csdn.net/kkxgx/article/details/6951959
|
||||
"""
|
||||
|
||||
xMat = mat(xMat)
|
||||
yMat = mat(yMat)
|
||||
|
||||
# b原来是矩阵,先转为数组类型后其数组大小为(1,1),所以后面加[0],变为(1,)
|
||||
b = array(b)[0]
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
|
||||
# 注意flatten的用法
|
||||
ax.scatter(xMat[:, 0].flatten().A[0], xMat[:, 1].flatten().A[0])
|
||||
|
||||
# x最大值,最小值根据原数据集dataArr[:, 0]的大小而定
|
||||
x = arange(-1.0, 10.0, 0.1)
|
||||
|
||||
# 根据x.w + b = 0 得到,其式子展开为w0.x1 + w1.x2 + b = 0, x2就是y值
|
||||
y = (-b-ws[0, 0]*x)/ws[1, 0]
|
||||
ax.plot(x, y)
|
||||
|
||||
for i in range(shape(yMat[0, :])[1]):
|
||||
if yMat[0, i] > 0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'cx')
|
||||
else:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'kp')
|
||||
|
||||
# 找到支持向量,并在图中标红
|
||||
for i in range(100):
|
||||
if alphas[i] > 0.0:
|
||||
ax.plot(xMat[i, 0], xMat[i, 1], 'ro')
|
||||
plt.show()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 获取特征和目标变量
|
||||
dataArr, labelArr = loadDataSet('data/6.SVM/testSet.txt')
|
||||
# print labelArr
|
||||
|
||||
# b是常量值, alphas是拉格朗日乘子
|
||||
b, alphas = smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
|
||||
print('/n/n/n')
|
||||
print('b=', b)
|
||||
print('alphas[alphas>0]=', alphas[alphas > 0])
|
||||
print('shape(alphas[alphas > 0])=', shape(alphas[alphas > 0]))
|
||||
for i in range(100):
|
||||
if alphas[i] > 0:
|
||||
print(dataArr[i], labelArr[i])
|
||||
# 画图
|
||||
ws = calcWs(alphas, dataArr, labelArr)
|
||||
plotfig_SVM(dataArr, labelArr, ws, b, alphas)
|
||||
|
|
@ -0,0 +1,312 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on Nov 28, 2010
|
||||
Update on 2017-05-18
|
||||
Adaboost is short for Adaptive Boosting
|
||||
Author: Peter/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from numpy import *
|
||||
|
||||
|
||||
def loadSimpData():
|
||||
""" 测试数据
|
||||
Returns:
|
||||
dataArr feature对应的数据集
|
||||
labelArr feature对应的分类标签
|
||||
"""
|
||||
dataArr = array([[1., 2.1], [2., 1.1], [1.3, 1.], [1., 1.], [2., 1.]])
|
||||
labelArr = [1.0, 1.0, -1.0, -1.0, 1.0]
|
||||
return dataArr, labelArr
|
||||
|
||||
|
||||
# general function to parse tab -delimited floats
|
||||
def loadDataSet(fileName):
|
||||
# get number of fields
|
||||
numFeat = len(open(fileName).readline().split('\t'))
|
||||
dataArr = []
|
||||
labelArr = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
lineArr = []
|
||||
curLine = line.strip().split('\t')
|
||||
for i in range(numFeat-1):
|
||||
lineArr.append(float(curLine[i]))
|
||||
dataArr.append(lineArr)
|
||||
labelArr.append(float(curLine[-1]))
|
||||
return dataArr, labelArr
|
||||
|
||||
|
||||
def stumpClassify(dataMat, dimen, threshVal, threshIneq):
|
||||
"""stumpClassify(将数据集,按照feature列的value进行 二分法切分比较来赋值分类)
|
||||
|
||||
Args:
|
||||
dataMat Matrix数据集
|
||||
dimen 特征列
|
||||
threshVal 特征列要比较的值
|
||||
Returns:
|
||||
retArray 结果集
|
||||
"""
|
||||
# 默认都是1
|
||||
retArray = ones((shape(dataMat)[0], 1))
|
||||
# dataMat[:, dimen] 表示数据集中第dimen列的所有值
|
||||
# threshIneq == 'lt'表示修改左边的值,gt表示修改右边的值
|
||||
# print '-----', threshIneq, dataMat[:, dimen], threshVal
|
||||
if threshIneq == 'lt':
|
||||
retArray[dataMat[:, dimen] <= threshVal] = -1.0
|
||||
else:
|
||||
retArray[dataMat[:, dimen] > threshVal] = -1.0
|
||||
return retArray
|
||||
|
||||
|
||||
def buildStump(dataArr, labelArr, D):
|
||||
"""buildStump(得到决策树的模型)
|
||||
|
||||
Args:
|
||||
dataArr 特征标签集合
|
||||
labelArr 分类标签集合
|
||||
D 最初的样本的所有特征权重集合
|
||||
Returns:
|
||||
bestStump 最优的分类器模型
|
||||
minError 错误率
|
||||
bestClasEst 训练后的结果集
|
||||
"""
|
||||
# 转换数据
|
||||
dataMat = mat(dataArr)
|
||||
labelMat = mat(labelArr).T
|
||||
# m行 n列
|
||||
m, n = shape(dataMat)
|
||||
|
||||
# 初始化数据
|
||||
numSteps = 10.0
|
||||
bestStump = {}
|
||||
bestClasEst = mat(zeros((m, 1)))
|
||||
# 初始化的最小误差为无穷大
|
||||
minError = inf
|
||||
|
||||
# 循环所有的feature列,将列切分成 若干份,每一段以最左边的点作为分类节点
|
||||
for i in range(n):
|
||||
rangeMin = dataMat[:, i].min()
|
||||
rangeMax = dataMat[:, i].max()
|
||||
# print 'rangeMin=%s, rangeMax=%s' % (rangeMin, rangeMax)
|
||||
# 计算每一份的元素个数
|
||||
stepSize = (rangeMax-rangeMin)/numSteps
|
||||
# 例如: 4=(10-1)/2 那么 1-4(-1次) 1(0次) 1+1*4(1次) 1+2*4(2次)
|
||||
# 所以: 循环 -1/0/1/2
|
||||
for j in range(-1, int(numSteps)+1):
|
||||
# go over less than and greater than
|
||||
for inequal in ['lt', 'gt']:
|
||||
# 如果是-1,那么得到rangeMin-stepSize; 如果是numSteps,那么得到rangeMax
|
||||
threshVal = (rangeMin + float(j) * stepSize)
|
||||
# 对单层决策树进行简单分类,得到预测的分类值
|
||||
predictedVals = stumpClassify(dataMat, i, threshVal, inequal)
|
||||
# print predictedVals
|
||||
errArr = mat(ones((m, 1)))
|
||||
# 正确为0,错误为1
|
||||
errArr[predictedVals == labelMat] = 0
|
||||
# 计算 平均每个特征的概率0.2*错误概率的总和为多少,就知道错误率多高
|
||||
# 例如: 一个都没错,那么错误率= 0.2*0=0 , 5个都错,那么错误率= 0.2*5=1, 只错3个,那么错误率= 0.2*3=0.6
|
||||
weightedError = D.T*errArr
|
||||
'''
|
||||
dim 表示 feature列
|
||||
threshVal 表示树的分界值
|
||||
inequal 表示计算树左右颠倒的错误率的情况
|
||||
weightedError 表示整体结果的错误率
|
||||
bestClasEst 预测的最优结果
|
||||
'''
|
||||
# print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
|
||||
if weightedError < minError:
|
||||
minError = weightedError
|
||||
bestClasEst = predictedVals.copy()
|
||||
bestStump['dim'] = i
|
||||
bestStump['thresh'] = threshVal
|
||||
bestStump['ineq'] = inequal
|
||||
|
||||
# bestStump 表示分类器的结果,在第几个列上,用大于/小于比较,阈值是多少
|
||||
return bestStump, minError, bestClasEst
|
||||
|
||||
|
||||
def adaBoostTrainDS(dataArr, labelArr, numIt=40):
|
||||
"""adaBoostTrainDS(adaBoost训练过程放大)
|
||||
|
||||
Args:
|
||||
dataArr 特征标签集合
|
||||
labelArr 分类标签集合
|
||||
numIt 实例数
|
||||
Returns:
|
||||
weakClassArr 弱分类器的集合
|
||||
aggClassEst 预测的分类结果值
|
||||
"""
|
||||
weakClassArr = []
|
||||
m = shape(dataArr)[0]
|
||||
# 初始化 D,设置每行数据的样本的所有特征权重集合,平均分为m份
|
||||
D = mat(ones((m, 1))/m)
|
||||
aggClassEst = mat(zeros((m, 1)))
|
||||
for i in range(numIt):
|
||||
# 得到决策树的模型
|
||||
bestStump, error, classEst = buildStump(dataArr, labelArr, D)
|
||||
|
||||
# alpha 目的主要是计算每一个分类器实例的权重(加和就是分类结果)
|
||||
# 计算每个分类器的 alpha 权重值
|
||||
alpha = float(0.5*log((1.0-error)/max(error, 1e-16)))
|
||||
bestStump['alpha'] = alpha
|
||||
# store Stump Params in Array
|
||||
weakClassArr.append(bestStump)
|
||||
|
||||
# print "alpha=%s, classEst=%s, bestStump=%s, error=%s " % (alpha, classEst.T, bestStump, error)
|
||||
# 分类正确:乘积为1,不会影响结果,-1主要是下面求e的-alpha次方
|
||||
# 分类错误:乘积为 -1,结果会受影响,所以也乘以 -1
|
||||
expon = multiply(-1*alpha*mat(labelArr).T, classEst)
|
||||
# print '\n'
|
||||
# print 'labelArr=', labelArr
|
||||
# print 'classEst=', classEst.T
|
||||
# print '\n'
|
||||
# print '乘积: ', multiply(mat(labelArr).T, classEst).T
|
||||
# 判断正确的,就乘以-1,否则就乘以1, 为什么? 书上的公式。
|
||||
# print '(-1取反)预测值expon=', expon.T
|
||||
# 计算e的expon次方,然后计算得到一个综合的概率的值
|
||||
# 结果发现: 判断错误的样本,D对于的样本权重值会变大。
|
||||
D = multiply(D, exp(expon))
|
||||
D = D/D.sum()
|
||||
# print "D: ", D.T
|
||||
# print '\n'
|
||||
|
||||
# 预测的分类结果值,在上一轮结果的基础上,进行加和操作
|
||||
# print '当前的分类结果:', alpha*classEst.T
|
||||
aggClassEst += alpha*classEst
|
||||
# print "叠加后的分类结果aggClassEst: ", aggClassEst.T
|
||||
# sign 判断正为1, 0为0, 负为-1,通过最终加和的权重值,判断符号。
|
||||
# 结果为:错误的样本标签集合,因为是 !=,那么结果就是0 正, 1 负
|
||||
aggErrors = multiply(sign(aggClassEst) != mat(labelArr).T, ones((m, 1)))
|
||||
errorRate = aggErrors.sum()/m
|
||||
# print "total error=%s " % (errorRate)
|
||||
if errorRate == 0.0:
|
||||
break
|
||||
return weakClassArr, aggClassEst
|
||||
|
||||
|
||||
def adaClassify(datToClass, classifierArr):
|
||||
# do stuff similar to last aggClassEst in adaBoostTrainDS
|
||||
dataMat = mat(datToClass)
|
||||
m = shape(dataMat)[0]
|
||||
aggClassEst = mat(zeros((m, 1)))
|
||||
|
||||
# 循环 多个分类器
|
||||
for i in range(len(classifierArr)):
|
||||
# 前提: 我们已经知道了最佳的分类器的实例
|
||||
# 通过分类器来核算每一次的分类结果,然后通过alpha*每一次的结果 得到最后的权重加和的值。
|
||||
classEst = stumpClassify(dataMat, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
|
||||
aggClassEst += classifierArr[i]['alpha']*classEst
|
||||
# print aggClassEst
|
||||
return sign(aggClassEst)
|
||||
|
||||
|
||||
def plotROC(predStrengths, classLabels):
|
||||
"""plotROC(打印ROC曲线,并计算AUC的面积大小)
|
||||
|
||||
Args:
|
||||
predStrengths 最终预测结果的权重值
|
||||
classLabels 原始数据的分类结果集
|
||||
"""
|
||||
print('predStrengths=', predStrengths)
|
||||
print('classLabels=', classLabels)
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
# variable to calculate AUC
|
||||
ySum = 0.0
|
||||
# 对正样本的进行求和
|
||||
numPosClas = sum(array(classLabels)==1.0)
|
||||
# 正样本的概率
|
||||
yStep = 1/float(numPosClas)
|
||||
# 负样本的概率
|
||||
xStep = 1/float(len(classLabels)-numPosClas)
|
||||
# argsort函数返回的是数组值从小到大的索引值
|
||||
# get sorted index, it's reverse
|
||||
sortedIndicies = predStrengths.argsort()
|
||||
# 测试结果是否是从小到大排列
|
||||
print('sortedIndicies=', sortedIndicies, predStrengths[0, 176], predStrengths.min(), predStrengths[0, 293], predStrengths.max())
|
||||
|
||||
# 开始创建模版对象
|
||||
fig = plt.figure()
|
||||
fig.clf()
|
||||
ax = plt.subplot(111)
|
||||
# cursor光标值
|
||||
cur = (1.0, 1.0)
|
||||
# loop through all the values, drawing a line segment at each point
|
||||
for index in sortedIndicies.tolist()[0]:
|
||||
if classLabels[index] == 1.0:
|
||||
delX = 0
|
||||
delY = yStep
|
||||
else:
|
||||
delX = xStep
|
||||
delY = 0
|
||||
ySum += cur[1]
|
||||
# draw line from cur to (cur[0]-delX, cur[1]-delY)
|
||||
# 画点连线 (x1, x2, y1, y2)
|
||||
print(cur[0], cur[0]-delX, cur[1], cur[1]-delY)
|
||||
ax.plot([cur[0], cur[0]-delX], [cur[1], cur[1]-delY], c='b')
|
||||
cur = (cur[0]-delX, cur[1]-delY)
|
||||
# 画对角的虚线线
|
||||
ax.plot([0, 1], [0, 1], 'b--')
|
||||
plt.xlabel('False positive rate')
|
||||
plt.ylabel('True positive rate')
|
||||
plt.title('ROC curve for AdaBoost horse colic detection system')
|
||||
# 设置画图的范围区间 (x1, x2, y1, y2)
|
||||
ax.axis([0, 1, 0, 1])
|
||||
plt.show()
|
||||
'''
|
||||
参考说明:http://blog.csdn.net/wenyusuran/article/details/39056013
|
||||
为了计算 AUC ,我们需要对多个小矩形的面积进行累加。
|
||||
这些小矩形的宽度是xStep,因此可以先对所有矩形的高度进行累加,最后再乘以xStep得到其总面积。
|
||||
所有高度的和(ySum)随着x轴的每次移动而渐次增加。
|
||||
'''
|
||||
print("the Area Under the Curve is: ", ySum*xStep)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# # 我们要将5个点进行分类
|
||||
# dataArr, labelArr = loadSimpData()
|
||||
# print 'dataArr', dataArr, 'labelArr', labelArr
|
||||
|
||||
# # D表示最初值,对1进行均分为5份,平均每一个初始的概率都为0.2
|
||||
# # D的目的是为了计算错误概率: weightedError = D.T*errArr
|
||||
# D = mat(ones((5, 1))/5)
|
||||
# print 'D=', D.T
|
||||
|
||||
# # bestStump, minError, bestClasEst = buildStump(dataArr, labelArr, D)
|
||||
# # print 'bestStump=', bestStump
|
||||
# # print 'minError=', minError
|
||||
# # print 'bestClasEst=', bestClasEst.T
|
||||
|
||||
# # 分类器:weakClassArr
|
||||
# # 历史累计的分类结果集
|
||||
# weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, labelArr, 9)
|
||||
# print '\nweakClassArr=', weakClassArr, '\naggClassEst=', aggClassEst.T
|
||||
|
||||
# """
|
||||
# 发现:
|
||||
# 分类的权重值:最大的值,为alpha的加和,最小值为-最大值
|
||||
# 特征的权重值:如果一个值误判的几率越小,那么D的特征权重越少
|
||||
# """
|
||||
|
||||
# # 测试数据的分类结果, 观测:aggClassEst分类的最终权重
|
||||
# print adaClassify([0, 0], weakClassArr).T
|
||||
# print adaClassify([[5, 5], [0, 0]], weakClassArr).T
|
||||
|
||||
# 马疝病数据集
|
||||
# 训练集合
|
||||
dataArr, labelArr = loadDataSet("data/7.AdaBoost/horseColicTraining2.txt")
|
||||
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, labelArr, 40)
|
||||
print(weakClassArr, '\n-----\n', aggClassEst.T)
|
||||
# 计算ROC下面的AUC的面积大小
|
||||
plotROC(aggClassEst.T, labelArr)
|
||||
# 测试集合
|
||||
dataArrTest, labelArrTest = loadDataSet("data/7.AdaBoost/horseColicTest2.txt")
|
||||
m = shape(dataArrTest)[0]
|
||||
predicting10 = adaClassify(dataArrTest, weakClassArr)
|
||||
errArr = mat(ones((m, 1)))
|
||||
# 测试:计算总样本数,错误样本数,错误率
|
||||
print(m, errArr[predicting10 != mat(labelArrTest).T].sum(), errArr[predicting10 != mat(labelArrTest).T].sum()/m)
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
"""
|
||||
Created on 2017-07-10
|
||||
Updated on 2017-07-10
|
||||
Author: 片刻/Noel Dawe
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
sklearn-AdaBoost译文链接: http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813457
|
||||
"""
|
||||
from __future__ import print_function
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
# importing necessary libraries
|
||||
import numpy as np
|
||||
from sklearn import metrics
|
||||
from sklearn.ensemble import AdaBoostRegressor
|
||||
from sklearn.tree import DecisionTreeRegressor
|
||||
|
||||
print(__doc__)
|
||||
|
||||
|
||||
# Create the dataset
|
||||
rng = np.random.RandomState(1)
|
||||
X = np.linspace(0, 6, 100)[:, np.newaxis]
|
||||
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
|
||||
# dataArr, labelArr = loadDataSet("data/7.AdaBoost/horseColicTraining2.txt")
|
||||
|
||||
|
||||
# Fit regression model
|
||||
regr_1 = DecisionTreeRegressor(max_depth=4)
|
||||
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=300, random_state=rng)
|
||||
|
||||
regr_1.fit(X, y)
|
||||
regr_2.fit(X, y)
|
||||
|
||||
# Predict
|
||||
y_1 = regr_1.predict(X)
|
||||
y_2 = regr_2.predict(X)
|
||||
|
||||
# Plot the results
|
||||
plt.figure()
|
||||
plt.scatter(X, y, c="k", label="training samples")
|
||||
plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2)
|
||||
plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2)
|
||||
plt.xlabel("data")
|
||||
plt.ylabel("target")
|
||||
plt.title("Boosted Decision Tree Regression")
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
||||
print('y---', type(y[0]), len(y), y[:4])
|
||||
print('y_1---', type(y_1[0]), len(y_1), y_1[:4])
|
||||
print('y_2---', type(y_2[0]), len(y_2), y_2[:4])
|
||||
|
||||
# 适合2分类
|
||||
y_true = np.array([0, 0, 1, 1])
|
||||
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
|
||||
print('y_scores---', type(y_scores[0]), len(y_scores), y_scores)
|
||||
print(metrics.roc_auc_score(y_true, y_scores))
|
||||
|
||||
# print "-" * 100
|
||||
# print metrics.roc_auc_score(y[:1], y_2[:1])
|
||||
|
|
@ -0,0 +1,347 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created 2017-04-25
|
||||
Update on 2017-05-18
|
||||
Random Forest Algorithm on Sonar Dataset
|
||||
Author: Flying_sfeng/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
---
|
||||
源代码网址:http://www.tuicool.com/articles/iiUfeim
|
||||
Flying_sfeng博客地址:http://blog.csdn.net/flying_sfeng/article/details/64133822 (感谢作者贡献)
|
||||
'''
|
||||
from __future__ import print_function
|
||||
from random import seed, randrange, random
|
||||
|
||||
|
||||
# 导入csv文件
|
||||
def loadDataSet(filename):
|
||||
dataset = []
|
||||
with open(filename, 'r') as fr:
|
||||
for line in fr.readlines():
|
||||
if not line:
|
||||
continue
|
||||
lineArr = []
|
||||
for featrue in line.split(','):
|
||||
# strip()返回移除字符串头尾指定的字符生成的新字符串
|
||||
str_f = featrue.strip()
|
||||
|
||||
# isdigit 如果是浮点型数值,就是 false,所以换成 isalpha() 函数
|
||||
# if str_f.isdigit(): # 判断是否是数字
|
||||
if str_f.isalpha(): # 如果是字母,说明是标签
|
||||
# 添加分类标签
|
||||
lineArr.append(str_f)
|
||||
else:
|
||||
# 将数据集的第column列转换成float形式
|
||||
lineArr.append(float(str_f))
|
||||
dataset.append(lineArr)
|
||||
return dataset
|
||||
|
||||
|
||||
def cross_validation_split(dataset, n_folds):
|
||||
"""cross_validation_split(将数据集进行抽重抽样 n_folds 份,数据可以重复重复抽取,每一次list的元素是无重复的)
|
||||
|
||||
Args:
|
||||
dataset 原始数据集
|
||||
n_folds 数据集dataset分成n_flods份
|
||||
Returns:
|
||||
dataset_split list集合,存放的是:将数据集进行抽重抽样 n_folds 份,数据可以重复重复抽取,每一次list的元素是无重复的
|
||||
"""
|
||||
dataset_split = list()
|
||||
dataset_copy = list(dataset) # 复制一份 dataset,防止 dataset 的内容改变
|
||||
fold_size = len(dataset) / n_folds
|
||||
for i in range(n_folds):
|
||||
fold = list() # 每次循环 fold 清零,防止重复导入 dataset_split
|
||||
while len(fold) < fold_size: # 这里不能用 if,if 只是在第一次判断时起作用,while 执行循环,直到条件不成立
|
||||
# 有放回的随机采样,有一些样本被重复采样,从而在训练集中多次出现,有的则从未在训练集中出现,此则自助采样法。从而保证每棵决策树训练集的差异性
|
||||
index = randrange(len(dataset_copy))
|
||||
# 将对应索引 index 的内容从 dataset_copy 中导出,并将该内容从 dataset_copy 中删除。
|
||||
# pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
|
||||
# fold.append(dataset_copy.pop(index)) # 无放回的方式
|
||||
fold.append(dataset_copy[index]) # 有放回的方式
|
||||
dataset_split.append(fold)
|
||||
# 由dataset分割出的n_folds个数据构成的列表,为了用于交叉验证
|
||||
return dataset_split
|
||||
|
||||
|
||||
# Split a dataset based on an attribute and an attribute value # 根据特征和特征值分割数据集
|
||||
def test_split(index, value, dataset):
|
||||
left, right = list(), list()
|
||||
for row in dataset:
|
||||
if row[index] < value:
|
||||
left.append(row)
|
||||
else:
|
||||
right.append(row)
|
||||
return left, right
|
||||
|
||||
|
||||
'''
|
||||
Gini指数的计算问题,假如将原始数据集D切割两部分,分别为D1和D2,则
|
||||
Gini(D|切割) = (|D1|/|D| ) * Gini(D1) + (|D2|/|D|) * Gini(D2)
|
||||
学习地址:
|
||||
http://bbs.pinggu.org/thread-5986969-1-1.html
|
||||
http://www.cnblogs.com/pinard/p/6053344.html
|
||||
而原文中 计算方式为:
|
||||
Gini(D|切割) = Gini(D1) + Gini(D2)
|
||||
|
||||
# Calculate the Gini index for a split dataset
|
||||
def gini_index(groups, class_values): # 个人理解:计算代价,分类越准确,则 gini 越小
|
||||
gini = 0.0
|
||||
for class_value in class_values: # class_values = [0, 1]
|
||||
for group in groups: # groups = (left, right)
|
||||
size = len(group)
|
||||
if size == 0:
|
||||
continue
|
||||
proportion = [row[-1] for row in group].count(class_value) / float(size)
|
||||
gini += (proportion * (1.0 - proportion)) # 个人理解:计算代价,分类越准确,则 gini 越小
|
||||
return gini
|
||||
'''
|
||||
|
||||
|
||||
def gini_index(groups, class_values): # 个人理解:计算代价,分类越准确,则 gini 越小
|
||||
gini = 0.0
|
||||
D = len(groups[0]) + len(groups[1])
|
||||
for class_value in class_values: # class_values = [0, 1]
|
||||
for group in groups: # groups = (left, right)
|
||||
size = len(group)
|
||||
if size == 0:
|
||||
continue
|
||||
proportion = [row[-1] for row in group].count(class_value) / float(size)
|
||||
gini += float(size)/D * (proportion * (1.0 - proportion)) # 个人理解:计算代价,分类越准确,则 gini 越小
|
||||
return gini
|
||||
|
||||
|
||||
# 找出分割数据集的最优特征,得到最优的特征 index,特征值 row[index],以及分割完的数据 groups(left, right)
|
||||
def get_split(dataset, n_features):
|
||||
class_values = list(set(row[-1] for row in dataset)) # class_values =[0, 1]
|
||||
b_index, b_value, b_score, b_groups = 999, 999, 999, None
|
||||
features = list()
|
||||
while len(features) < n_features:
|
||||
index = randrange(len(dataset[0])-1) # 往 features 添加 n_features 个特征( n_feature 等于特征数的根号),特征索引从 dataset 中随机取
|
||||
if index not in features:
|
||||
features.append(index)
|
||||
for index in features: # 在 n_features 个特征中选出最优的特征索引,并没有遍历所有特征,从而保证了每课决策树的差异性
|
||||
for row in dataset:
|
||||
groups = test_split(index, row[index], dataset) # groups=(left, right), row[index] 遍历每一行 index 索引下的特征值作为分类值 value, 找出最优的分类特征和特征值
|
||||
gini = gini_index(groups, class_values)
|
||||
# 左右两边的数量越一样,说明数据区分度不高,gini系数越大
|
||||
if gini < b_score:
|
||||
b_index, b_value, b_score, b_groups = index, row[index], gini, groups # 最后得到最优的分类特征 b_index,分类特征值 b_value,分类结果 b_groups。b_value 为分错的代价成本
|
||||
# print b_score
|
||||
return {'index': b_index, 'value': b_value, 'groups': b_groups}
|
||||
|
||||
|
||||
# Create a terminal node value # 输出group中出现次数较多的标签
|
||||
def to_terminal(group):
|
||||
outcomes = [row[-1] for row in group] # max() 函数中,当 key 参数不为空时,就以 key 的函数对象为判断的标准
|
||||
return max(set(outcomes), key=outcomes.count) # 输出 group 中出现次数较多的标签
|
||||
|
||||
|
||||
# Create child splits for a node or make terminal # 创建子分割器,递归分类,直到分类结束
|
||||
def split(node, max_depth, min_size, n_features, depth): # max_depth = 10, min_size = 1, n_features=int(sqrt((len(dataset[0])-1)
|
||||
left, right = node['groups']
|
||||
del(node['groups'])
|
||||
# check for a no split
|
||||
if not left or not right:
|
||||
node['left'] = node['right'] = to_terminal(left + right)
|
||||
return
|
||||
# check for max depth
|
||||
if depth >= max_depth: # max_depth=10 表示递归十次,若分类还未结束,则选取数据中分类标签较多的作为结果,使分类提前结束,防止过拟合
|
||||
node['left'], node['right'] = to_terminal(left), to_terminal(right)
|
||||
return
|
||||
# process left child
|
||||
if len(left) <= min_size:
|
||||
node['left'] = to_terminal(left)
|
||||
else:
|
||||
node['left'] = get_split(left, n_features) # node['left']是一个字典,形式为{'index':b_index, 'value':b_value, 'groups':b_groups},所以node是一个多层字典
|
||||
split(node['left'], max_depth, min_size, n_features, depth+1) # 递归,depth+1计算递归层数
|
||||
# process right child
|
||||
if len(right) <= min_size:
|
||||
node['right'] = to_terminal(right)
|
||||
else:
|
||||
node['right'] = get_split(right, n_features)
|
||||
split(node['right'], max_depth, min_size, n_features, depth+1)
|
||||
|
||||
|
||||
# Build a decision tree
|
||||
def build_tree(train, max_depth, min_size, n_features):
|
||||
"""build_tree(创建一个决策树)
|
||||
|
||||
Args:
|
||||
train 训练数据集
|
||||
max_depth 决策树深度不能太深,不然容易导致过拟合
|
||||
min_size 叶子节点的大小
|
||||
n_features 选取的特征的个数
|
||||
Returns:
|
||||
root 返回决策树
|
||||
"""
|
||||
|
||||
# 返回最优列和相关的信息
|
||||
root = get_split(train, n_features)
|
||||
|
||||
# 对左右2边的数据 进行递归的调用,由于最优特征使用过,所以在后面进行使用的时候,就没有意义了
|
||||
# 例如: 性别-男女,对男使用这一特征就没任何意义了
|
||||
split(root, max_depth, min_size, n_features, 1)
|
||||
return root
|
||||
|
||||
|
||||
# Make a prediction with a decision tree
|
||||
def predict(node, row): # 预测模型分类结果
|
||||
if row[node['index']] < node['value']:
|
||||
if isinstance(node['left'], dict): # isinstance 是 Python 中的一个内建函数。是用来判断一个对象是否是一个已知的类型。
|
||||
return predict(node['left'], row)
|
||||
else:
|
||||
return node['left']
|
||||
else:
|
||||
if isinstance(node['right'], dict):
|
||||
return predict(node['right'], row)
|
||||
else:
|
||||
return node['right']
|
||||
|
||||
|
||||
# Make a prediction with a list of bagged trees
|
||||
def bagging_predict(trees, row):
|
||||
"""bagging_predict(bagging预测)
|
||||
|
||||
Args:
|
||||
trees 决策树的集合
|
||||
row 测试数据集的每一行数据
|
||||
Returns:
|
||||
返回随机森林中,决策树结果出现次数做大的
|
||||
"""
|
||||
|
||||
# 使用多个决策树trees对测试集test的第row行进行预测,再使用简单投票法判断出该行所属分类
|
||||
predictions = [predict(tree, row) for tree in trees]
|
||||
return max(set(predictions), key=predictions.count)
|
||||
|
||||
|
||||
# Create a random subsample from the dataset with replacement
|
||||
def subsample(dataset, ratio): # 创建数据集的随机子样本
|
||||
"""random_forest(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
dataset 训练数据集
|
||||
ratio 训练数据集的样本比例
|
||||
Returns:
|
||||
sample 随机抽样的训练样本
|
||||
"""
|
||||
|
||||
sample = list()
|
||||
# 训练样本的按比例抽样。
|
||||
# round() 方法返回浮点数x的四舍五入值。
|
||||
n_sample = round(len(dataset) * ratio)
|
||||
while len(sample) < n_sample:
|
||||
# 有放回的随机采样,有一些样本被重复采样,从而在训练集中多次出现,有的则从未在训练集中出现,此则自助采样法。从而保证每棵决策树训练集的差异性
|
||||
index = randrange(len(dataset))
|
||||
sample.append(dataset[index])
|
||||
return sample
|
||||
|
||||
|
||||
# Random Forest Algorithm
|
||||
def random_forest(train, test, max_depth, min_size, sample_size, n_trees, n_features):
|
||||
"""random_forest(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
train 训练数据集
|
||||
test 测试数据集
|
||||
max_depth 决策树深度不能太深,不然容易导致过拟合
|
||||
min_size 叶子节点的大小
|
||||
sample_size 训练数据集的样本比例
|
||||
n_trees 决策树的个数
|
||||
n_features 选取的特征的个数
|
||||
Returns:
|
||||
predictions 每一行的预测结果,bagging 预测最后的分类结果
|
||||
"""
|
||||
|
||||
trees = list()
|
||||
# n_trees 表示决策树的数量
|
||||
for i in range(n_trees):
|
||||
# 随机抽样的训练样本, 随机采样保证了每棵决策树训练集的差异性
|
||||
sample = subsample(train, sample_size)
|
||||
# 创建一个决策树
|
||||
tree = build_tree(sample, max_depth, min_size, n_features)
|
||||
trees.append(tree)
|
||||
|
||||
# 每一行的预测结果,bagging 预测最后的分类结果
|
||||
predictions = [bagging_predict(trees, row) for row in test]
|
||||
return predictions
|
||||
|
||||
|
||||
# Calculate accuracy percentage
|
||||
def accuracy_metric(actual, predicted): # 导入实际值和预测值,计算精确度
|
||||
correct = 0
|
||||
for i in range(len(actual)):
|
||||
if actual[i] == predicted[i]:
|
||||
correct += 1
|
||||
return correct / float(len(actual)) * 100.0
|
||||
|
||||
|
||||
# 评估算法性能,返回模型得分
|
||||
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
|
||||
"""evaluate_algorithm(评估算法性能,返回模型得分)
|
||||
|
||||
Args:
|
||||
dataset 原始数据集
|
||||
algorithm 使用的算法
|
||||
n_folds 数据的份数
|
||||
*args 其他的参数
|
||||
Returns:
|
||||
scores 模型得分
|
||||
"""
|
||||
|
||||
# 将数据集进行抽重抽样 n_folds 份,数据可以重复重复抽取,每一次 list 的元素是无重复的
|
||||
folds = cross_validation_split(dataset, n_folds)
|
||||
scores = list()
|
||||
# 每次循环从 folds 从取出一个 fold 作为测试集,其余作为训练集,遍历整个 folds ,实现交叉验证
|
||||
for fold in folds:
|
||||
train_set = list(folds)
|
||||
train_set.remove(fold)
|
||||
# 将多个 fold 列表组合成一个 train_set 列表, 类似 union all
|
||||
"""
|
||||
In [20]: l1=[[1, 2, 'a'], [11, 22, 'b']]
|
||||
In [21]: l2=[[3, 4, 'c'], [33, 44, 'd']]
|
||||
In [22]: l=[]
|
||||
In [23]: l.append(l1)
|
||||
In [24]: l.append(l2)
|
||||
In [25]: l
|
||||
Out[25]: [[[1, 2, 'a'], [11, 22, 'b']], [[3, 4, 'c'], [33, 44, 'd']]]
|
||||
In [26]: sum(l, [])
|
||||
Out[26]: [[1, 2, 'a'], [11, 22, 'b'], [3, 4, 'c'], [33, 44, 'd']]
|
||||
"""
|
||||
train_set = sum(train_set, [])
|
||||
test_set = list()
|
||||
# fold 表示从原始数据集 dataset 提取出来的测试集
|
||||
for row in fold:
|
||||
row_copy = list(row)
|
||||
row_copy[-1] = None
|
||||
test_set.append(row_copy)
|
||||
predicted = algorithm(train_set, test_set, *args)
|
||||
actual = [row[-1] for row in fold]
|
||||
|
||||
# 计算随机森林的预测结果的正确率
|
||||
accuracy = accuracy_metric(actual, predicted)
|
||||
scores.append(accuracy)
|
||||
return scores
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
# 加载数据
|
||||
dataset = loadDataSet('data/7.RandomForest/sonar-all-data.txt')
|
||||
# print dataset
|
||||
|
||||
n_folds = 5 # 分成5份数据,进行交叉验证
|
||||
max_depth = 20 # 调参(自己修改) #决策树深度不能太深,不然容易导致过拟合
|
||||
min_size = 1 # 决策树的叶子节点最少的元素数量
|
||||
sample_size = 1.0 # 做决策树时候的样本的比例
|
||||
# n_features = int((len(dataset[0])-1))
|
||||
n_features = 15 # 调参(自己修改) #准确性与多样性之间的权衡
|
||||
for n_trees in [1, 10, 20, 30, 40, 50]: # 理论上树是越多越好
|
||||
scores = evaluate_algorithm(dataset, random_forest, n_folds, max_depth, min_size, sample_size, n_trees, n_features)
|
||||
# 每一次执行本文件时都能产生同一个随机数
|
||||
seed(1)
|
||||
print('random=', random())
|
||||
print('Trees: %d' % n_trees)
|
||||
print('Scores: %s' % scores)
|
||||
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
|
||||
|
|
@ -0,0 +1,606 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on Jan 8, 2011
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
|
||||
from numpy import *
|
||||
import matplotlib.pylab as plt
|
||||
|
||||
|
||||
def loadDataSet(fileName):
|
||||
""" 加载数据
|
||||
解析以tab键分隔的文件中的浮点数
|
||||
Returns:
|
||||
dataMat : feature 对应的数据集
|
||||
labelMat : feature 对应的分类标签,即类别标签
|
||||
"""
|
||||
# 获取样本特征的总数,不算最后的目标变量
|
||||
numFeat = len(open(fileName).readline().split('\t')) - 1
|
||||
dataMat = []
|
||||
labelMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
# 读取每一行
|
||||
lineArr = []
|
||||
# 删除一行中以tab分隔的数据前后的空白符号
|
||||
curLine = line.strip().split('\t')
|
||||
# i 从0到2,不包括2
|
||||
for i in range(numFeat):
|
||||
# 将数据添加到lineArr List中,每一行数据测试数据组成一个行向量
|
||||
lineArr.append(float(curLine[i]))
|
||||
# 将测试数据的输入数据部分存储到dataMat 的List中
|
||||
dataMat.append(lineArr)
|
||||
# 将每一行的最后一个数据,即类别,或者叫目标变量存储到labelMat List中
|
||||
labelMat.append(float(curLine[-1]))
|
||||
return dataMat, labelMat
|
||||
|
||||
|
||||
def standRegres(xArr, yArr):
|
||||
'''
|
||||
Description:
|
||||
线性回归
|
||||
Args:
|
||||
xArr :输入的样本数据,包含每个样本数据的 feature
|
||||
yArr :对应于输入数据的类别标签,也就是每个样本对应的目标变量
|
||||
Returns:
|
||||
ws:回归系数
|
||||
'''
|
||||
|
||||
# mat()函数将xArr,yArr转换为矩阵 mat().T 代表的是对矩阵进行转置操作
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
# 矩阵乘法的条件是左矩阵的列数等于右矩阵的行数
|
||||
xTx = xMat.T * xMat
|
||||
# 因为要用到xTx的逆矩阵,所以事先需要确定计算得到的xTx是否可逆,条件是矩阵的行列式不为0
|
||||
# linalg.det() 函数是用来求得矩阵的行列式的,如果矩阵的行列式为0,则这个矩阵是不可逆的,就无法进行接下来的运算
|
||||
if linalg.det(xTx) == 0.0:
|
||||
print("This matrix is singular, cannot do inverse")
|
||||
return
|
||||
# 最小二乘法
|
||||
# http://cwiki.apachecn.org/pages/viewpage.action?pageId=5505133
|
||||
# 书中的公式,求得w的最优解
|
||||
ws = xTx.I * (xMat.T * yMat)
|
||||
return ws
|
||||
|
||||
|
||||
# 局部加权线性回归
|
||||
def lwlr(testPoint, xArr, yArr, k=1.0):
|
||||
'''
|
||||
Description:
|
||||
局部加权线性回归,在待预测点附近的每个点赋予一定的权重,在子集上基于最小均方差来进行普通的回归。
|
||||
Args:
|
||||
testPoint:样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
k:关于赋予权重矩阵的核的一个参数,与权重的衰减速率有关
|
||||
Returns:
|
||||
testPoint * ws:数据点与具有权重的系数相乘得到的预测点
|
||||
Notes:
|
||||
这其中会用到计算权重的公式,w = e^((x^((i))-x) / -2k^2)
|
||||
理解:x为某个预测点,x^((i))为样本点,样本点距离预测点越近,贡献的误差越大(权值越大),越远则贡献的误差越小(权值越小)。
|
||||
关于预测点的选取,在我的代码中取的是样本点。其中k是带宽参数,控制w(钟形函数)的宽窄程度,类似于高斯函数的标准差。
|
||||
算法思路:假设预测点取样本点中的第i个样本点(共m个样本点),遍历1到m个样本点(含第i个),算出每一个样本点与预测点的距离,
|
||||
也就可以计算出每个样本贡献误差的权值,可以看出w是一个有m个元素的向量(写成对角阵形式)。
|
||||
'''
|
||||
# mat() 函数是将array转换为矩阵的函数, mat().T 是转换为矩阵之后,再进行转置操作
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
# 获得xMat矩阵的行数
|
||||
m = shape(xMat)[0]
|
||||
# eye()返回一个对角线元素为1,其他元素为0的二维数组,创建权重矩阵weights,该矩阵为每个样本点初始化了一个权重
|
||||
weights = mat(eye((m)))
|
||||
for j in range(m):
|
||||
# testPoint 的形式是 一个行向量的形式
|
||||
# 计算 testPoint 与输入样本点之间的距离,然后下面计算出每个样本贡献误差的权值
|
||||
diffMat = testPoint - xMat[j, :]
|
||||
# k控制衰减的速度
|
||||
weights[j, j] = exp(diffMat * diffMat.T / (-2.0 * k**2))
|
||||
# 根据矩阵乘法计算 xTx ,其中的 weights 矩阵是样本点对应的权重矩阵
|
||||
xTx = xMat.T * (weights * xMat)
|
||||
if linalg.det(xTx) == 0.0:
|
||||
print("This matrix is singular, cannot do inverse")
|
||||
return
|
||||
# 计算出回归系数的一个估计
|
||||
ws = xTx.I * (xMat.T * (weights * yMat))
|
||||
return testPoint * ws
|
||||
|
||||
|
||||
def lwlrTest(testArr, xArr, yArr, k=1.0):
|
||||
'''
|
||||
Description:
|
||||
测试局部加权线性回归,对数据集中每个点调用 lwlr() 函数
|
||||
Args:
|
||||
testArr:测试所用的所有样本点
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量
|
||||
k:控制核函数的衰减速率
|
||||
Returns:
|
||||
yHat:预测点的估计值
|
||||
'''
|
||||
# 得到样本点的总数
|
||||
m = shape(testArr)[0]
|
||||
# 构建一个全部都是 0 的 1 * m 的矩阵
|
||||
yHat = zeros(m)
|
||||
# 循环所有的数据点,并将lwlr运用于所有的数据点
|
||||
for i in range(m):
|
||||
yHat[i] = lwlr(testArr[i], xArr, yArr, k)
|
||||
# 返回估计值
|
||||
return yHat
|
||||
|
||||
|
||||
def lwlrTestPlot(xArr, yArr, k=1.0):
|
||||
'''
|
||||
Description:
|
||||
首先将 X 排序,其余的都与lwlrTest相同,这样更容易绘图
|
||||
Args:
|
||||
xArr:样本的特征数据,即 feature
|
||||
yArr:每个样本对应的类别标签,即目标变量,实际值
|
||||
k:控制核函数的衰减速率的有关参数,这里设定的是常量值 1
|
||||
Return:
|
||||
yHat:样本点的估计值
|
||||
xCopy:xArr的复制
|
||||
'''
|
||||
# 生成一个与目标变量数目相同的 0 向量
|
||||
yHat = zeros(shape(yArr))
|
||||
# 将 xArr 转换为 矩阵形式
|
||||
xCopy = mat(xArr)
|
||||
# 排序
|
||||
xCopy.sort(0)
|
||||
# 开始循环,为每个样本点进行局部加权线性回归,得到最终的目标变量估计值
|
||||
for i in range(shape(xArr)[0]):
|
||||
yHat[i] = lwlr(xCopy[i], xArr, yArr, k)
|
||||
return yHat, xCopy
|
||||
|
||||
|
||||
def rssError(yArr, yHatArr):
|
||||
'''
|
||||
Desc:
|
||||
计算分析预测误差的大小
|
||||
Args:
|
||||
yArr:真实的目标变量
|
||||
yHatArr:预测得到的估计值
|
||||
Returns:
|
||||
计算真实值和估计值得到的值的平方和作为最后的返回值
|
||||
'''
|
||||
return ((yArr - yHatArr)**2).sum()
|
||||
|
||||
|
||||
def ridgeRegres(xMat, yMat, lam=0.2):
|
||||
'''
|
||||
Desc:
|
||||
这个函数实现了给定 lambda 下的岭回归求解。
|
||||
如果数据的特征比样本点还多,就不能再使用上面介绍的的线性回归和局部线性回归了,因为计算 (xTx)^(-1)会出现错误。
|
||||
如果特征比样本点还多(n > m),也就是说,输入数据的矩阵x不是满秩矩阵。非满秩矩阵在求逆时会出现问题。
|
||||
为了解决这个问题,我们下边讲一下:岭回归,这是我们要讲的第一种缩减方法。
|
||||
Args:
|
||||
xMat:样本的特征数据,即 feature
|
||||
yMat:每个样本对应的类别标签,即目标变量,实际值
|
||||
lam:引入的一个λ值,使得矩阵非奇异
|
||||
Returns:
|
||||
经过岭回归公式计算得到的回归系数
|
||||
'''
|
||||
|
||||
xTx = xMat.T * xMat
|
||||
# 岭回归就是在矩阵 xTx 上加一个 λI 从而使得矩阵非奇异,进而能对 xTx + λI 求逆
|
||||
denom = xTx + eye(shape(xMat)[1]) * lam
|
||||
# 检查行列式是否为零,即矩阵是否可逆,行列式为0的话就不可逆,不为0的话就是可逆。
|
||||
if linalg.det(denom) == 0.0:
|
||||
print("This matrix is singular, cannot do inverse")
|
||||
return
|
||||
ws = denom.I * (xMat.T * yMat)
|
||||
return ws
|
||||
|
||||
|
||||
def ridgeTest(xArr, yArr):
|
||||
'''
|
||||
Desc:
|
||||
函数 ridgeTest() 用于在一组 λ 上测试结果
|
||||
Args:
|
||||
xArr:样本数据的特征,即 feature
|
||||
yArr:样本数据的类别标签,即真实数据
|
||||
Returns:
|
||||
wMat:将所有的回归系数输出到一个矩阵并返回
|
||||
'''
|
||||
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
# 计算Y的均值
|
||||
yMean = mean(yMat, 0)
|
||||
# Y的所有的特征减去均值
|
||||
yMat = yMat - yMean
|
||||
# 标准化 x,计算 xMat 平均值
|
||||
xMeans = mean(xMat, 0)
|
||||
# 然后计算 X的方差
|
||||
xVar = var(xMat, 0)
|
||||
# 所有特征都减去各自的均值并除以方差
|
||||
xMat = (xMat - xMeans) / xVar
|
||||
# 可以在 30 个不同的 lambda 下调用 ridgeRegres() 函数。
|
||||
numTestPts = 30
|
||||
# 创建30 * m 的全部数据为0 的矩阵
|
||||
wMat = zeros((numTestPts, shape(xMat)[1]))
|
||||
for i in range(numTestPts):
|
||||
# exp() 返回 e^x
|
||||
ws = ridgeRegres(xMat, yMat, exp(i - 10))
|
||||
wMat[i, :] = ws.T
|
||||
return wMat
|
||||
|
||||
|
||||
def regularize(xMat): # 按列进行规范化
|
||||
inMat = xMat.copy()
|
||||
inMeans = mean(inMat, 0) # 计算平均值然后减去它
|
||||
inVar = var(inMat, 0) # 计算除以Xi的方差
|
||||
inMat = (inMat - inMeans) / inVar
|
||||
return inMat
|
||||
|
||||
|
||||
def stageWise(xArr, yArr, eps=0.01, numIt=100):
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
yMean = mean(yMat, 0)
|
||||
yMat = yMat - yMean # 也可以规则化ys但会得到更小的coef
|
||||
xMat = regularize(xMat)
|
||||
m, n = shape(xMat)
|
||||
# returnMat = zeros((numIt,n)) # 测试代码删除
|
||||
ws = zeros((n, 1))
|
||||
wsTest = ws.copy()
|
||||
wsMax = ws.copy()
|
||||
for i in range(numIt):
|
||||
print(ws.T)
|
||||
lowestError = inf
|
||||
for j in range(n):
|
||||
for sign in [-1, 1]:
|
||||
wsTest = ws.copy()
|
||||
wsTest[j] += eps * sign
|
||||
yTest = xMat * wsTest
|
||||
rssE = rssError(yMat.A, yTest.A)
|
||||
if rssE < lowestError:
|
||||
lowestError = rssE
|
||||
wsMax = wsTest
|
||||
ws = wsMax.copy()
|
||||
# returnMat[i,:]=ws.T
|
||||
# return returnMat
|
||||
|
||||
# def scrapePage(inFile,outFile,yr,numPce,origPrc):
|
||||
# from BeautifulSoup import BeautifulSoup
|
||||
# fr = open(inFile); fw=open(outFile,'a') #a is append mode writing
|
||||
# soup = BeautifulSoup(fr.read())
|
||||
# i=1
|
||||
# currentRow = soup.findAll('table', r="%d" % i)
|
||||
# while(len(currentRow)!=0):
|
||||
# title = currentRow[0].findAll('a')[1].text
|
||||
# lwrTitle = title.lower()
|
||||
# if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
|
||||
# newFlag = 1.0
|
||||
# else:
|
||||
# newFlag = 0.0
|
||||
# soldUnicde = currentRow[0].findAll('td')[3].findAll('span')
|
||||
# if len(soldUnicde)==0:
|
||||
# print "item #%d did not sell" % i
|
||||
# else:
|
||||
# soldPrice = currentRow[0].findAll('td')[4]
|
||||
# priceStr = soldPrice.text
|
||||
# priceStr = priceStr.replace('$','') #strips out $
|
||||
# priceStr = priceStr.replace(',','') #strips out ,
|
||||
# if len(soldPrice)>1:
|
||||
# priceStr = priceStr.replace('Free shipping', '') #strips out Free Shipping
|
||||
# print "%s\t%d\t%s" % (priceStr,newFlag,title)
|
||||
# fw.write("%d\t%d\t%d\t%f\t%s\n" % (yr,numPce,newFlag,origPrc,priceStr))
|
||||
# i += 1
|
||||
# currentRow = soup.findAll('table', r="%d" % i)
|
||||
# fw.close()
|
||||
|
||||
# --------------------------------------------------------------
|
||||
# 预测乐高玩具套装的价格 ------ 最初的版本,因为现在 google 的 api 变化,无法获取数据
|
||||
# 故改为了下边的样子,但是需要安装一个 beautifulSoup 这个第三方爬虫库,安装很简单,见下边
|
||||
|
||||
|
||||
'''
|
||||
from time import sleep
|
||||
import json
|
||||
import urllib2
|
||||
def searchForSet(retX, retY, setNum, yr, numPce, origPrc):
|
||||
sleep(10)
|
||||
myAPIstr = 'AIzaSyD2cR2KFyx12hXu6PFU-wrWot3NXvko8vY'
|
||||
searchURL = 'https://www.googleapis.com/shopping/search/v1/public/products?key=%s&country=US&q=lego+%d&alt=json' % (myAPIstr, setNum)
|
||||
pg = urllib2.urlopen(searchURL)
|
||||
retDict = json.loads(pg.read())
|
||||
for i in range(len(retDict['items'])):
|
||||
try:
|
||||
currItem = retDict['items'][i]
|
||||
if currItem['product']['condition'] == 'new':
|
||||
newFlag = 1
|
||||
else: newFlag = 0
|
||||
listOfInv = currItem['product']['inventories']
|
||||
for item in listOfInv:
|
||||
sellingPrice = item['price']
|
||||
if sellingPrice > origPrc * 0.5:
|
||||
print ("%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice))
|
||||
retX.append([yr, numPce, newFlag, origPrc])
|
||||
retY.append(sellingPrice)
|
||||
except: print ('problem with item %d' % i)
|
||||
|
||||
def setDataCollect(retX, retY):
|
||||
searchForSet(retX, retY, 8288, 2006, 800, 49.99)
|
||||
searchForSet(retX, retY, 10030, 2002, 3096, 269.99)
|
||||
searchForSet(retX, retY, 10179, 2007, 5195, 499.99)
|
||||
searchForSet(retX, retY, 10181, 2007, 3428, 199.99)
|
||||
searchForSet(retX, retY, 10189, 2008, 5922, 299.99)
|
||||
searchForSet(retX, retY, 10196, 2009, 3263, 249.99)
|
||||
|
||||
def crossValidation(xArr,yArr,numVal=10):
|
||||
m = len(yArr)
|
||||
indexList = range(m)
|
||||
errorMat = zeros((numVal,30))#create error mat 30columns numVal rows创建error mat 30columns numVal 行
|
||||
for i in range(numVal):
|
||||
trainX=[]; trainY=[]
|
||||
testX = []; testY = []
|
||||
random.shuffle(indexList)
|
||||
for j in range(m):#create training set based on first 90% of values in indexList
|
||||
#基于indexList中的前90%的值创建训练集
|
||||
if j < m*0.9:
|
||||
trainX.append(xArr[indexList[j]])
|
||||
gt56 trainY.append(yArr[indexList[j]])
|
||||
else:
|
||||
testX.append(xArr[indexList[j]])
|
||||
testY.append(yArr[indexList[j]])
|
||||
wMat = ridgeTest(trainX,trainY) #get 30 weight vectors from ridge
|
||||
for k in range(30):#loop over all of the ridge estimates
|
||||
matTestX = mat(testX); matTrainX=mat(trainX)
|
||||
meanTrain = mean(matTrainX,0)
|
||||
varTrain = var(matTrainX,0)
|
||||
matTestX = (matTestX-meanTrain)/varTrain #regularize test with training params
|
||||
yEst = matTestX * mat(wMat[k,:]).T + mean(trainY)#test ridge results and store
|
||||
errorMat[i,k]=rssError(yEst.T.A,array(testY))
|
||||
#print errorMat[i,k]
|
||||
meanErrors = mean(errorMat,0)#calc avg performance of the different ridge weight vectors
|
||||
minMean = float(min(meanErrors))
|
||||
bestWeights = wMat[nonzero(meanErrors==minMean)]
|
||||
#can unregularize to get model
|
||||
#when we regularized we wrote Xreg = (x-meanX)/var(x)
|
||||
#we can now write in terms of x not Xreg: x*w/var(x) - meanX/var(x) +meanY
|
||||
xMat = mat(xArr); yMat=mat(yArr).T
|
||||
meanX = mean(xMat,0); varX = var(xMat,0)
|
||||
unReg = bestWeights/varX
|
||||
print ("the best model from Ridge Regression is:\n",unReg)
|
||||
print ("with constant term: ",-1*sum(multiply(meanX,unReg)) + mean(yMat))
|
||||
'''
|
||||
|
||||
# ----------------------------------------------------------------------------
|
||||
# 预测乐高玩具套装的价格 可运行版本,我们把乐高数据存储到了我们的 input 文件夹下,使用 beautifulSoup 爬去一下内容
|
||||
# 前提:安装 BeautifulSoup 第三方爬虫库,步骤如下
|
||||
# 在这个页面 https://www.crummy.com/software/BeautifulSoup/bs4/download/4.4/ 下载,beautifulsoup4-4.4.1.tar.gz
|
||||
# 将下载文件解压,使用 windows 版本的 cmd 命令行,进入解压的包,输入以下两行命令即可完成安装
|
||||
# python setup.py build
|
||||
# python setup.py install
|
||||
'''
|
||||
from numpy import *
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
# 从页面读取数据,生成retX和retY列表
|
||||
def scrapePage(retX, retY, inFile, yr, numPce, origPrc):
|
||||
|
||||
# 打开并读取HTML文件
|
||||
fr = open(inFile)
|
||||
soup = BeautifulSoup(fr.read())
|
||||
i=1
|
||||
|
||||
# 根据HTML页面结构进行解析
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
while(len(currentRow)!=0):
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
title = currentRow[0].findAll('a')[1].text
|
||||
lwrTitle = title.lower()
|
||||
|
||||
# 查找是否有全新标签
|
||||
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
|
||||
newFlag = 1.0
|
||||
else:
|
||||
newFlag = 0.0
|
||||
|
||||
# 查找是否已经标志出售,我们只收集已出售的数据
|
||||
soldUnicde = currentRow[0].findAll('td')[3].findAll('span')
|
||||
if len(soldUnicde)==0:
|
||||
print "item #%d did not sell" % i
|
||||
else:
|
||||
# 解析页面获取当前价格
|
||||
soldPrice = currentRow[0].findAll('td')[4]
|
||||
priceStr = soldPrice.text
|
||||
priceStr = priceStr.replace('$','') #strips out $
|
||||
priceStr = priceStr.replace(',','') #strips out ,
|
||||
if len(soldPrice)>1:
|
||||
priceStr = priceStr.replace('Free shipping', '')
|
||||
sellingPrice = float(priceStr)
|
||||
|
||||
# 去掉不完整的套装价格
|
||||
if sellingPrice > origPrc * 0.5:
|
||||
print "%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice)
|
||||
retX.append([yr, numPce, newFlag, origPrc])
|
||||
retY.append(sellingPrice)
|
||||
i += 1
|
||||
currentRow = soup.findAll('table', r="%d" % i)
|
||||
|
||||
# 依次读取六种乐高套装的数据,并生成数据矩阵
|
||||
def setDataCollect(retX, retY):
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego8288.html', 2006, 800, 49.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10030.html', 2002, 3096, 269.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10179.html', 2007, 5195, 499.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10181.html', 2007, 3428, 199.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10189.html', 2008, 5922, 299.99)
|
||||
scrapePage(retX, retY, 'data/8.Regression/setHtml/lego10196.html', 2009, 3263, 249.99)
|
||||
|
||||
|
||||
# 交叉验证测试岭回归
|
||||
def crossValidation(xArr,yArr,numVal=10):
|
||||
# 获得数据点个数,xArr和yArr具有相同长度
|
||||
m = len(yArr)
|
||||
indexList = range(m)
|
||||
errorMat = zeros((numVal,30))
|
||||
|
||||
# 主循环 交叉验证循环
|
||||
for i in range(numVal):
|
||||
# 随机拆分数据,将数据分为训练集(90%)和测试集(10%)
|
||||
trainX=[]; trainY=[]
|
||||
testX = []; testY = []
|
||||
|
||||
# 对数据进行混洗操作
|
||||
random.shuffle(indexList)
|
||||
|
||||
# 切分训练集和测试集
|
||||
for j in range(m):
|
||||
if j < m*0.9:
|
||||
trainX.append(xArr[indexList[j]])
|
||||
trainY.append(yArr[indexList[j]])
|
||||
else:
|
||||
testX.append(xArr[indexList[j]])
|
||||
testY.append(yArr[indexList[j]])
|
||||
|
||||
# 获得回归系数矩阵
|
||||
wMat = ridgeTest(trainX,trainY)
|
||||
|
||||
# 循环遍历矩阵中的30组回归系数
|
||||
for k in range(30):
|
||||
# 读取训练集和数据集
|
||||
matTestX = mat(testX); matTrainX=mat(trainX)
|
||||
# 对数据进行标准化
|
||||
meanTrain = mean(matTrainX,0)
|
||||
varTrain = var(matTrainX,0)
|
||||
matTestX = (matTestX-meanTrain)/varTrain
|
||||
|
||||
# 测试回归效果并存储
|
||||
yEst = matTestX * mat(wMat[k,:]).T + mean(trainY)
|
||||
|
||||
# 计算误差
|
||||
errorMat[i,k] = ((yEst.T.A-array(testY))**2).sum()
|
||||
|
||||
# 计算误差估计值的均值
|
||||
meanErrors = mean(errorMat,0)
|
||||
minMean = float(min(meanErrors))
|
||||
bestWeights = wMat[nonzero(meanErrors==minMean)]
|
||||
|
||||
# 不要使用标准化的数据,需要对数据进行还原来得到输出结果
|
||||
xMat = mat(xArr); yMat=mat(yArr).T
|
||||
meanX = mean(xMat,0); varX = var(xMat,0)
|
||||
unReg = bestWeights/varX
|
||||
|
||||
# 输出构建的模型
|
||||
print "the best model from Ridge Regression is:\n",unReg
|
||||
print "with constant term: ",-1*sum(multiply(meanX,unReg)) + mean(yMat)
|
||||
'''
|
||||
|
||||
|
||||
# test for standRegression
|
||||
def regression1():
|
||||
xArr, yArr = loadDataSet("data/8.Regression/data.txt")
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr)
|
||||
ws = standRegres(xArr, yArr)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(
|
||||
111) # add_subplot(349)函数的参数的意思是,将画布分成3行4列图像画在从左到右从上到下第9块
|
||||
ax.scatter(
|
||||
[xMat[:, 1].flatten()],
|
||||
[yMat.T[:, 0].flatten().A[0]]) # scatter 的x是xMat中的第二列,y是yMat的第一列
|
||||
xCopy = xMat.copy()
|
||||
xCopy.sort(0)
|
||||
yHat = xCopy * ws
|
||||
ax.plot(xCopy[:, 1], yHat)
|
||||
plt.show()
|
||||
|
||||
|
||||
# test for LWLR
|
||||
def regression2():
|
||||
xArr, yArr = loadDataSet("data/8.Regression/data.txt")
|
||||
yHat = lwlrTest(xArr, xArr, yArr, 0.003)
|
||||
xMat = mat(xArr)
|
||||
srtInd = xMat[:, 1].argsort(
|
||||
0) #argsort()函数是将x中的元素从小到大排列,提取其对应的index(索引),然后输出
|
||||
xSort = xMat[srtInd][:, 0, :]
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(xSort[:, 1], yHat[srtInd])
|
||||
ax.scatter(
|
||||
[xMat[:, 1].flatten().A[0]], [mat(yArr).T.flatten().A[0]],
|
||||
s=2,
|
||||
c='red')
|
||||
plt.show()
|
||||
|
||||
|
||||
# test for abloneDataSet
|
||||
def abaloneTest():
|
||||
'''
|
||||
Desc:
|
||||
预测鲍鱼的年龄
|
||||
Args:
|
||||
None
|
||||
Returns:
|
||||
None
|
||||
'''
|
||||
# 加载数据
|
||||
abX, abY = loadDataSet("data/8.Regression/abalone.txt")
|
||||
# 使用不同的核进行预测
|
||||
oldyHat01 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 0.1)
|
||||
oldyHat1 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 1)
|
||||
oldyHat10 = lwlrTest(abX[0:99], abX[0:99], abY[0:99], 10)
|
||||
# 打印出不同的核预测值与训练数据集上的真实值之间的误差大小
|
||||
print(("old yHat01 error Size is :", rssError(abY[0:99], oldyHat01.T)))
|
||||
print(("old yHat1 error Size is :", rssError(abY[0:99], oldyHat1.T)))
|
||||
print(("old yHat10 error Size is :", rssError(abY[0:99], oldyHat10.T)))
|
||||
|
||||
# 打印出 不同的核预测值 与 新数据集(测试数据集)上的真实值之间的误差大小
|
||||
newyHat01 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 0.1)
|
||||
print(("new yHat01 error Size is :", rssError(abY[0:99], newyHat01.T)))
|
||||
newyHat1 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 1)
|
||||
print(("new yHat1 error Size is :", rssError(abY[0:99], newyHat1.T)))
|
||||
newyHat10 = lwlrTest(abX[100:199], abX[0:99], abY[0:99], 10)
|
||||
print(("new yHat10 error Size is :", rssError(abY[0:99], newyHat10.T)))
|
||||
|
||||
# 使用简单的 线性回归 进行预测,与上面的计算进行比较
|
||||
standWs = standRegres(abX[0:99], abY[0:99])
|
||||
standyHat = mat(abX[100:199]) * standWs
|
||||
print(("standRegress error Size is:", rssError(abY[100:199], standyHat.T.A)))
|
||||
|
||||
|
||||
# test for ridgeRegression
|
||||
def regression3():
|
||||
abX, abY = loadDataSet("data/8.Regression/abalone.txt")
|
||||
ridgeWeights = ridgeTest(abX, abY)
|
||||
fig = plt.figure()
|
||||
ax = fig.add_subplot(111)
|
||||
ax.plot(ridgeWeights)
|
||||
plt.show()
|
||||
|
||||
|
||||
# test for stageWise
|
||||
def regression4():
|
||||
xArr, yArr = loadDataSet("data/8.Regression/abalone.txt")
|
||||
stageWise(xArr, yArr, 0.01, 200)
|
||||
xMat = mat(xArr)
|
||||
yMat = mat(yArr).T
|
||||
xMat = regularize(xMat)
|
||||
yM = mean(yMat, 0)
|
||||
yMat = yMat - yM
|
||||
weights = standRegres(xMat, yMat.T)
|
||||
print(weights.T)
|
||||
|
||||
|
||||
# predict for lego's price
|
||||
def regression5():
|
||||
lgX = []
|
||||
lgY = []
|
||||
|
||||
setDataCollect(lgX, lgY)
|
||||
crossValidation(lgX, lgY, 10)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
regression1()
|
||||
# regression2()
|
||||
# abaloneTest()
|
||||
# regression3()
|
||||
# regression4()
|
||||
# regression5()
|
||||
|
|
@ -0,0 +1,192 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on Jan 8, 2011
|
||||
Update on 2017-05-18
|
||||
Author: Peter Harrington/小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
|
||||
|
||||
# Isotonic Regression 等式回归
|
||||
print(__doc__)
|
||||
|
||||
# Author: Nelle Varoquaux <nelle.varoquaux@gmail.com>
|
||||
# Alexandre Gramfort <alexandre.gramfort@inria.fr>
|
||||
# License: BSD
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from matplotlib.collections import LineCollection
|
||||
|
||||
from sklearn.linear_model import LinearRegression
|
||||
from sklearn.isotonic import IsotonicRegression
|
||||
from sklearn.utils import check_random_state
|
||||
|
||||
n = 100
|
||||
x = np.arange(n)
|
||||
rs = check_random_state(0)
|
||||
y = rs.randint(-50, 50, size=(n,)) + 50. * np.log(1 + np.arange(n))
|
||||
|
||||
ir = IsotonicRegression()
|
||||
|
||||
y_ = ir.fit_transform(x, y)
|
||||
|
||||
lr = LinearRegression()
|
||||
lr.fit(x[:, np.newaxis], y) # 线性回归的 x 需要为 2d
|
||||
|
||||
segments = [[[i, y[i]], [i, y_[i]]] for i in range(n)]
|
||||
lc = LineCollection(segments, zorder=0)
|
||||
lc.set_array(np.ones(len(y)))
|
||||
lc.set_linewidths(0.5 * np.ones(n))
|
||||
|
||||
fig = plt.figure()
|
||||
plt.plot(x, y, 'r.', markersize=12)
|
||||
plt.plot(x, y_, 'g.-', markersize=12)
|
||||
plt.plot(x, lr.predict(x[:, np.newaxis]), 'b-')
|
||||
plt.gca().add_collection(lc)
|
||||
plt.legend(('Data', 'Isotonic Fit', 'Linear Fit'), loc='lower right')
|
||||
plt.title('Isotonic regression')
|
||||
plt.show()
|
||||
|
||||
# Kernel ridge regression ( 内核岭回归 )
|
||||
|
||||
# 2.1 Comparison of kernel ridge regression and SVR ( 内核岭回归与 SVR 的比较 )
|
||||
|
||||
# Authors: Jan Hendrik Metzen <jhm@informatik.uni-bremen.de>
|
||||
# License: BSD 3 clause
|
||||
|
||||
'''
|
||||
from __future__ import division
|
||||
import time
|
||||
|
||||
import numpy as np
|
||||
|
||||
from sklearn.svm import SVR
|
||||
from sklearn.model_selection import GridSearchCV
|
||||
from sklearn.model_selection import learning_curve
|
||||
from sklearn.kernel_ridge import KernelRidge
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
rng = np.random.RandomState(0)
|
||||
|
||||
# 生成样本数据
|
||||
X = 5 * rng.rand(10000, 1)
|
||||
y = np.sin(X).ravel()
|
||||
|
||||
# 给目标增加噪音
|
||||
y[::5] += 3 * (0.5 - rng.rand(X.shape[0] // 5))
|
||||
|
||||
X_plot = np.linspace(0, 5, 100000)[:, None]
|
||||
|
||||
# Fit regression model ( 拟合 回归 模型 )
|
||||
train_size = 100
|
||||
svr = GridSearchCV(SVR(kernel='rbf', gamma=0.1), cv=5,
|
||||
param_grid={"C": [1e0, 1e1, 1e2, 1e3],
|
||||
"gamma": np.logspace(-2, 2, 5)})
|
||||
|
||||
kr = GridSearchCV(KernelRidge(kernel='rbf', gamma=0.1), cv=5,
|
||||
param_grid={"alpha": [1e0, 0.1, 1e-2, 1e-3],
|
||||
"gamma": np.logspace(-2, 2, 5)})
|
||||
|
||||
t0 = time.time()
|
||||
svr.fit(X[:train_size], y[:train_size])
|
||||
svr_fit = time.time() - t0
|
||||
print("SVR complexity and bandwidth selected and model fitted in %.3f s"
|
||||
% svr_fit)
|
||||
|
||||
t0 = time.time()
|
||||
kr.fit(X[:train_size], y[:train_size])
|
||||
kr_fit = time.time() - t0
|
||||
print("KRR complexity and bandwidth selected and model fitted in %.3f s"
|
||||
% kr_fit)
|
||||
|
||||
sv_ratio = svr.best_estimator_.support_.shape[0] / train_size
|
||||
print("Support vector ratio: %.3f" % sv_ratio)
|
||||
|
||||
t0 = time.time()
|
||||
y_svr = svr.predict(X_plot)
|
||||
svr_predict = time.time() - t0
|
||||
print("SVR prediction for %d inputs in %.3f s"
|
||||
% (X_plot.shape[0], svr_predict))
|
||||
|
||||
t0 = time.time()
|
||||
y_kr = kr.predict(X_plot)
|
||||
kr_predict = time.time() - t0
|
||||
print("KRR prediction for %d inputs in %.3f s"
|
||||
% (X_plot.shape[0], kr_predict))
|
||||
|
||||
# 查看结果
|
||||
sv_ind = svr.best_estimator_.support_
|
||||
plt.scatter(X[sv_ind], y[sv_ind], c='r', s=50, label='SVR support vectors',
|
||||
zorder=2)
|
||||
plt.scatter(X[:100], y[:100], c='k', label='data', zorder=1)
|
||||
plt.hold('on')
|
||||
plt.plot(X_plot, y_svr, c='r',
|
||||
label='SVR (fit: %.3fs, predict: %.3fs)' % (svr_fit, svr_predict))
|
||||
plt.plot(X_plot, y_kr, c='g',
|
||||
label='KRR (fit: %.3fs, predict: %.3fs)' % (kr_fit, kr_predict))
|
||||
plt.xlabel('data')
|
||||
plt.ylabel('target')
|
||||
plt.title('SVR versus Kernel Ridge')
|
||||
plt.legend()
|
||||
|
||||
# 可视化训练和预测时间
|
||||
plt.figure()
|
||||
|
||||
# 生成样本数据
|
||||
X = 5 * rng.rand(10000, 1)
|
||||
y = np.sin(X).ravel()
|
||||
y[::5] += 3 * (0.5 - rng.rand(X.shape[0] // 5))
|
||||
sizes = np.logspace(1, 4, 7, dtype=np.int)
|
||||
for name, estimator in {"KRR": KernelRidge(kernel='rbf', alpha=0.1,
|
||||
gamma=10),
|
||||
"SVR": SVR(kernel='rbf', C=1e1, gamma=10)}.items():
|
||||
train_time = []
|
||||
test_time = []
|
||||
for train_test_size in sizes:
|
||||
t0 = time.time()
|
||||
estimator.fit(X[:train_test_size], y[:train_test_size])
|
||||
train_time.append(time.time() - t0)
|
||||
|
||||
t0 = time.time()
|
||||
estimator.predict(X_plot[:1000])
|
||||
test_time.append(time.time() - t0)
|
||||
|
||||
plt.plot(sizes, train_time, 'o-', color="r" if name == "SVR" else "g",
|
||||
label="%s (train)" % name)
|
||||
plt.plot(sizes, test_time, 'o--', color="r" if name == "SVR" else "g",
|
||||
label="%s (test)" % name)
|
||||
|
||||
plt.xscale("log")
|
||||
plt.yscale("log")
|
||||
plt.xlabel("Train size")
|
||||
plt.ylabel("Time (seconds)")
|
||||
plt.title('Execution Time')
|
||||
plt.legend(loc="best")
|
||||
|
||||
# 可视化学习曲线
|
||||
plt.figure()
|
||||
|
||||
svr = SVR(kernel='rbf', C=1e1, gamma=0.1)
|
||||
kr = KernelRidge(kernel='rbf', alpha=0.1, gamma=0.1)
|
||||
train_sizes, train_scores_svr, test_scores_svr = \
|
||||
learning_curve(svr, X[:100], y[:100], train_sizes=np.linspace(0.1, 1, 10),
|
||||
scoring="neg_mean_squared_error", cv=10)
|
||||
train_sizes_abs, train_scores_kr, test_scores_kr = \
|
||||
learning_curve(kr, X[:100], y[:100], train_sizes=np.linspace(0.1, 1, 10),
|
||||
scoring="neg_mean_squared_error", cv=10)
|
||||
|
||||
plt.plot(train_sizes, -test_scores_svr.mean(1), 'o-', color="r",
|
||||
label="SVR")
|
||||
plt.plot(train_sizes, -test_scores_kr.mean(1), 'o-', color="g",
|
||||
label="KRR")
|
||||
plt.xlabel("Train size")
|
||||
plt.ylabel("Mean Squared Error")
|
||||
plt.title('Learning curves')
|
||||
plt.legend(loc="best")
|
||||
|
||||
plt.show()
|
||||
'''
|
||||
|
|
@ -0,0 +1,106 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
# '''
|
||||
# Created on 2017-03-10
|
||||
# Update on 2017-03-10
|
||||
# author: jiangzhonglian
|
||||
# content: 回归树
|
||||
# '''
|
||||
|
||||
# print(__doc__)
|
||||
|
||||
|
||||
# # Import the necessary modules and libraries
|
||||
# import numpy as np
|
||||
# from sklearn.tree import DecisionTreeRegressor
|
||||
# import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
# # Create a random dataset
|
||||
# rng = np.random.RandomState(1)
|
||||
# X = np.sort(5 * rng.rand(80, 1), axis=0)
|
||||
# y = np.sin(X).ravel()
|
||||
# print X, '\n\n\n-----------\n\n\n', y
|
||||
# y[::5] += 3 * (0.5 - rng.rand(16))
|
||||
|
||||
|
||||
# # Fit regression model
|
||||
# regr_1 = DecisionTreeRegressor(max_depth=2, min_samples_leaf=5)
|
||||
# regr_2 = DecisionTreeRegressor(max_depth=5, min_samples_leaf=5)
|
||||
# regr_1.fit(X, y)
|
||||
# regr_2.fit(X, y)
|
||||
|
||||
|
||||
# # Predict
|
||||
# X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
|
||||
# y_1 = regr_1.predict(X_test)
|
||||
# y_2 = regr_2.predict(X_test)
|
||||
|
||||
|
||||
# # Plot the results
|
||||
# plt.figure()
|
||||
# plt.scatter(X, y, c="darkorange", label="data")
|
||||
# plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
|
||||
# plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
|
||||
# plt.xlabel("data")
|
||||
# plt.ylabel("target")
|
||||
# plt.title("Decision Tree Regression")
|
||||
# plt.legend()
|
||||
# plt.show()
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
'''
|
||||
Created on 2017-03-10
|
||||
Update on 2017-03-10
|
||||
author: jiangzhonglian
|
||||
content: 模型树
|
||||
'''
|
||||
from __future__ import print_function
|
||||
|
||||
print(__doc__)
|
||||
|
||||
# Author: Noel Dawe <noel.dawe@gmail.com>
|
||||
#
|
||||
# License: BSD 3 clause
|
||||
|
||||
# importing necessary libraries
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from sklearn.tree import DecisionTreeRegressor
|
||||
from sklearn.ensemble import AdaBoostRegressor
|
||||
|
||||
# Create the dataset
|
||||
rng = np.random.RandomState(1)
|
||||
X = np.linspace(0, 6, 100)[:, np.newaxis]
|
||||
y = np.sin(X).ravel() + np.sin(6 * X).ravel() + rng.normal(0, 0.1, X.shape[0])
|
||||
|
||||
# Fit regression model
|
||||
regr_1 = DecisionTreeRegressor(max_depth=4)
|
||||
|
||||
regr_2 = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4),
|
||||
n_estimators=300, random_state=rng)
|
||||
|
||||
regr_1.fit(X, y)
|
||||
regr_2.fit(X, y)
|
||||
|
||||
# Predict
|
||||
y_1 = regr_1.predict(X)
|
||||
y_2 = regr_2.predict(X)
|
||||
|
||||
# Plot the results
|
||||
plt.figure()
|
||||
plt.scatter(X, y, c="k", label="training samples")
|
||||
plt.plot(X, y_1, c="g", label="n_estimators=1", linewidth=2)
|
||||
plt.plot(X, y_2, c="r", label="n_estimators=300", linewidth=2)
|
||||
plt.xlabel("data")
|
||||
plt.ylabel("target")
|
||||
plt.title("Boosted Decision Tree Regression")
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,468 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
'''
|
||||
Created on Feb 4, 2011
|
||||
Update on 2017-12-20
|
||||
Tree-Based Regression Methods Source Code for Machine Learning in Action Ch. 9
|
||||
Author: Peter Harrington/片刻/小瑶/zh0ng
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
print(__doc__)
|
||||
from numpy import *
|
||||
|
||||
|
||||
# 默认解析的数据是用tab分隔,并且是数值类型
|
||||
# general function to parse tab -delimited floats
|
||||
def loadDataSet(fileName):
|
||||
"""loadDataSet(解析每一行,并转化为float类型)
|
||||
Desc:该函数读取一个以 tab 键为分隔符的文件,然后将每行的内容保存成一组浮点数
|
||||
Args:
|
||||
fileName 文件名
|
||||
Returns:
|
||||
dataMat 每一行的数据集array类型
|
||||
Raises:
|
||||
"""
|
||||
# 假定最后一列是结果值
|
||||
# assume last column is target value
|
||||
dataMat = []
|
||||
fr = open(fileName)
|
||||
for line in fr.readlines():
|
||||
curLine = line.strip().split('\t')
|
||||
# 将所有的元素转化为float类型
|
||||
# map all elements to float()
|
||||
# map() 函数具体的含义,可见 https://my.oschina.net/zyzzy/blog/115096
|
||||
fltLine = map(float, curLine)
|
||||
dataMat.append(fltLine)
|
||||
return dataMat
|
||||
|
||||
|
||||
def binSplitDataSet(dataSet, feature, value):
|
||||
"""binSplitDataSet(将数据集,按照feature列的value进行 二元切分)
|
||||
Description:在给定特征和特征值的情况下,该函数通过数组过滤方式将上述数据集合切分得到两个子集并返回。
|
||||
Args:
|
||||
dataMat 数据集
|
||||
feature 待切分的特征列
|
||||
value 特征列要比较的值
|
||||
Returns:
|
||||
mat0 小于等于 value 的数据集在左边
|
||||
mat1 大于 value 的数据集在右边
|
||||
Raises:
|
||||
"""
|
||||
# # 测试案例
|
||||
# print 'dataSet[:, feature]=', dataSet[:, feature]
|
||||
# print 'nonzero(dataSet[:, feature] > value)[0]=', nonzero(dataSet[:, feature] > value)[0]
|
||||
# print 'nonzero(dataSet[:, feature] <= value)[0]=', nonzero(dataSet[:, feature] <= value)[0]
|
||||
|
||||
# dataSet[:, feature] 取去每一行中,第1列的值(从0开始算)
|
||||
# nonzero(dataSet[:, feature] > value) 返回结果为true行的index下标
|
||||
mat0 = dataSet[nonzero(dataSet[:, feature] <= value)[0], :]
|
||||
mat1 = dataSet[nonzero(dataSet[:, feature] > value)[0], :]
|
||||
return mat0, mat1
|
||||
|
||||
|
||||
# 返回每一个叶子结点的均值
|
||||
# returns the value used for each leaf
|
||||
# 我的理解是:regLeaf 是产生叶节点的函数,就是求均值,即用聚类中心点来代表这类数据
|
||||
def regLeaf(dataSet):
|
||||
return mean(dataSet[:, -1])
|
||||
|
||||
|
||||
# 计算总方差=方差*样本数
|
||||
# 我的理解是:求这组数据的方差,即通过决策树划分,可以让靠近的数据分到同一类中去
|
||||
def regErr(dataSet):
|
||||
# shape(dataSet)[0] 表示行数
|
||||
return var(dataSet[:, -1]) * shape(dataSet)[0]
|
||||
|
||||
|
||||
# 1.用最佳方式切分数据集
|
||||
# 2.生成相应的叶节点
|
||||
def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
"""chooseBestSplit(用最佳方式切分数据集 和 生成相应的叶节点)
|
||||
|
||||
Args:
|
||||
dataSet 加载的原始数据集
|
||||
leafType 建立叶子点的函数
|
||||
errType 误差计算函数(求总方差)
|
||||
ops [容许误差下降值,切分的最少样本数]。
|
||||
Returns:
|
||||
bestIndex feature的index坐标
|
||||
bestValue 切分的最优值
|
||||
Raises:
|
||||
"""
|
||||
|
||||
# ops=(1,4),非常重要,因为它决定了决策树划分停止的threshold值,被称为预剪枝(prepruning),其实也就是用于控制函数的停止时机。
|
||||
# 之所以这样说,是因为它防止决策树的过拟合,所以当误差的下降值小于tolS,或划分后的集合size小于tolN时,选择停止继续划分。
|
||||
# 最小误差下降值,划分后的误差减小小于这个差值,就不用继续划分
|
||||
tolS = ops[0]
|
||||
# 划分最小 size 小于,就不继续划分了
|
||||
tolN = ops[1]
|
||||
# 如果结果集(最后一列为1个变量),就返回退出
|
||||
# .T 对数据集进行转置
|
||||
# .tolist()[0] 转化为数组并取第0列
|
||||
if len(set(dataSet[:, -1].T.tolist()[0])) == 1: # 如果集合size为1,也就是说全部的数据都是同一个类别,不用继续划分。
|
||||
# exit cond 1
|
||||
return None, leafType(dataSet)
|
||||
# 计算行列值
|
||||
m, n = shape(dataSet)
|
||||
# 无分类误差的总方差和
|
||||
# the choice of the best feature is driven by Reduction in RSS error from mean
|
||||
S = errType(dataSet)
|
||||
# inf 正无穷大
|
||||
bestS, bestIndex, bestValue = inf, 0, 0
|
||||
# 循环处理每一列对应的feature值
|
||||
for featIndex in range(n-1): # 对于每个特征
|
||||
# [0]表示这一列的[所有行],不要[0]就是一个array[[所有行]],下面的一行表示的是将某一列全部的数据转换为行,然后设置为list形式
|
||||
for splitVal in set(dataSet[:, featIndex].T.tolist()[0]):
|
||||
# 对该列进行分组,然后组内的成员的val值进行 二元切分
|
||||
mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal)
|
||||
# 判断二元切分的方式的元素数量是否符合预期
|
||||
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN):
|
||||
continue
|
||||
newS = errType(mat0) + errType(mat1)
|
||||
# 如果二元切分,算出来的误差在可接受范围内,那么就记录切分点,并记录最小误差
|
||||
# 如果划分后误差小于 bestS,则说明找到了新的bestS
|
||||
if newS < bestS:
|
||||
bestIndex = featIndex
|
||||
bestValue = splitVal
|
||||
bestS = newS
|
||||
# 判断二元切分的方式的元素误差是否符合预期
|
||||
# if the decrease (S-bestS) is less than a threshold don't do the split
|
||||
if (S - bestS) < tolS:
|
||||
return None, leafType(dataSet)
|
||||
mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue)
|
||||
# 对整体的成员进行判断,是否符合预期
|
||||
# 如果集合的 size 小于 tolN
|
||||
if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): # 当最佳划分后,集合过小,也不划分,产生叶节点
|
||||
return None, leafType(dataSet)
|
||||
return bestIndex, bestValue
|
||||
|
||||
|
||||
# assume dataSet is NumPy Mat so we can array filtering
|
||||
# 假设 dataSet 是 NumPy Mat 类型的,那么我们可以进行 array 过滤
|
||||
def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1, 4)):
|
||||
"""createTree(获取回归树)
|
||||
Description:递归函数:如果构建的是回归树,该模型是一个常数,如果是模型树,其模型师一个线性方程。
|
||||
Args:
|
||||
dataSet 加载的原始数据集
|
||||
leafType 建立叶子点的函数
|
||||
errType 误差计算函数
|
||||
ops=(1, 4) [容许误差下降值,切分的最少样本数]
|
||||
Returns:
|
||||
retTree 决策树最后的结果
|
||||
"""
|
||||
# 选择最好的切分方式: feature索引值,最优切分值
|
||||
# choose the best split
|
||||
feat, val = chooseBestSplit(dataSet, leafType, errType, ops)
|
||||
# if the splitting hit a stop condition return val
|
||||
# 如果 splitting 达到一个停止条件,那么返回 val
|
||||
'''
|
||||
*** 最后的返回结果是最后剩下的 val,也就是len小于topN的集合
|
||||
'''
|
||||
if feat is None:
|
||||
return val
|
||||
retTree = {}
|
||||
retTree['spInd'] = feat
|
||||
retTree['spVal'] = val
|
||||
# 大于在右边,小于在左边,分为2个数据集
|
||||
lSet, rSet = binSplitDataSet(dataSet, feat, val)
|
||||
# 递归的进行调用,在左右子树中继续递归生成树
|
||||
retTree['left'] = createTree(lSet, leafType, errType, ops)
|
||||
retTree['right'] = createTree(rSet, leafType, errType, ops)
|
||||
return retTree
|
||||
|
||||
|
||||
# 判断节点是否是一个字典
|
||||
def isTree(obj):
|
||||
"""
|
||||
Desc:
|
||||
测试输入变量是否是一棵树,即是否是一个字典
|
||||
Args:
|
||||
obj -- 输入变量
|
||||
Returns:
|
||||
返回布尔类型的结果。如果 obj 是一个字典,返回true,否则返回 false
|
||||
"""
|
||||
return (type(obj).__name__ == 'dict')
|
||||
|
||||
|
||||
# 计算左右枝丫的均值
|
||||
def getMean(tree):
|
||||
"""
|
||||
Desc:
|
||||
从上往下遍历树直到叶节点为止,如果找到两个叶节点则计算它们的平均值。
|
||||
对 tree 进行塌陷处理,即返回树平均值。
|
||||
Args:
|
||||
tree -- 输入的树
|
||||
Returns:
|
||||
返回 tree 节点的平均值
|
||||
"""
|
||||
if isTree(tree['right']):
|
||||
tree['right'] = getMean(tree['right'])
|
||||
if isTree(tree['left']):
|
||||
tree['left'] = getMean(tree['left'])
|
||||
return (tree['left']+tree['right'])/2.0
|
||||
|
||||
|
||||
# 检查是否适合合并分枝
|
||||
def prune(tree, testData):
|
||||
"""
|
||||
Desc:
|
||||
从上而下找到叶节点,用测试数据集来判断将这些叶节点合并是否能降低测试误差
|
||||
Args:
|
||||
tree -- 待剪枝的树
|
||||
testData -- 剪枝所需要的测试数据 testData
|
||||
Returns:
|
||||
tree -- 剪枝完成的树
|
||||
"""
|
||||
# 判断是否测试数据集没有数据,如果没有,就直接返回tree本身的均值
|
||||
if shape(testData)[0] == 0:
|
||||
return getMean(tree)
|
||||
|
||||
# 判断分枝是否是dict字典,如果是就将测试数据集进行切分
|
||||
if (isTree(tree['right']) or isTree(tree['left'])):
|
||||
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
|
||||
# 如果是左边分枝是字典,就传入左边的数据集和左边的分枝,进行递归
|
||||
if isTree(tree['left']):
|
||||
tree['left'] = prune(tree['left'], lSet)
|
||||
# 如果是右边分枝是字典,就传入左边的数据集和左边的分枝,进行递归
|
||||
if isTree(tree['right']):
|
||||
tree['right'] = prune(tree['right'], rSet)
|
||||
|
||||
# 上面的一系列操作本质上就是将测试数据集按照训练完成的树拆分好,对应的值放到对应的节点
|
||||
|
||||
# 如果左右两边同时都不是dict字典,也就是左右两边都是叶节点,而不是子树了,那么分割测试数据集。
|
||||
# 1. 如果正确
|
||||
# * 那么计算一下总方差 和 该结果集的本身不分枝的总方差比较
|
||||
# * 如果 合并的总方差 < 不合并的总方差,那么就进行合并
|
||||
# 注意返回的结果: 如果可以合并,原来的dict就变为了 数值
|
||||
if not isTree(tree['left']) and not isTree(tree['right']):
|
||||
lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal'])
|
||||
# power(x, y)表示x的y次方;这时tree['left']和tree['right']都是具体数值
|
||||
errorNoMerge = sum(power(lSet[:, -1] - tree['left'], 2)) + sum(power(rSet[:, -1] - tree['right'], 2))
|
||||
treeMean = (tree['left'] + tree['right'])/2.0
|
||||
errorMerge = sum(power(testData[:, -1] - treeMean, 2))
|
||||
# 如果 合并的总方差 < 不合并的总方差,那么就进行合并
|
||||
if errorMerge < errorNoMerge:
|
||||
print("merging")
|
||||
return treeMean
|
||||
# 两个return可以简化成一个
|
||||
else:
|
||||
return tree
|
||||
else:
|
||||
return tree
|
||||
|
||||
|
||||
# 得到模型的ws系数:f(x) = x0 + x1*featrue1+ x2*featrue2 ...
|
||||
# create linear model and return coeficients
|
||||
def modelLeaf(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
当数据不再需要切分的时候,生成叶节点的模型。
|
||||
Args:
|
||||
dataSet -- 输入数据集
|
||||
Returns:
|
||||
调用 linearSolve 函数,返回得到的 回归系数ws
|
||||
"""
|
||||
ws, X, Y = linearSolve(dataSet)
|
||||
return ws
|
||||
|
||||
|
||||
# 计算线性模型的误差值
|
||||
def modelErr(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
在给定数据集上计算误差。
|
||||
Args:
|
||||
dataSet -- 输入数据集
|
||||
Returns:
|
||||
调用 linearSolve 函数,返回 yHat 和 Y 之间的平方误差。
|
||||
"""
|
||||
ws, X, Y = linearSolve(dataSet)
|
||||
yHat = X * ws
|
||||
# print corrcoef(yHat, Y, rowvar=0)
|
||||
return sum(power(Y - yHat, 2))
|
||||
|
||||
|
||||
# helper function used in two places
|
||||
def linearSolve(dataSet):
|
||||
"""
|
||||
Desc:
|
||||
将数据集格式化成目标变量Y和自变量X,执行简单的线性回归,得到ws
|
||||
Args:
|
||||
dataSet -- 输入数据
|
||||
Returns:
|
||||
ws -- 执行线性回归的回归系数
|
||||
X -- 格式化自变量X
|
||||
Y -- 格式化目标变量Y
|
||||
"""
|
||||
m, n = shape(dataSet)
|
||||
# 产生一个关于1的矩阵
|
||||
X = mat(ones((m, n)))
|
||||
Y = mat(ones((m, 1)))
|
||||
# X的0列为1,常数项,用于计算平衡误差
|
||||
X[:, 1: n] = dataSet[:, 0: n-1]
|
||||
Y = dataSet[:, -1]
|
||||
|
||||
# 转置矩阵*矩阵
|
||||
xTx = X.T * X
|
||||
# 如果矩阵的逆不存在,会造成程序异常
|
||||
if linalg.det(xTx) == 0.0:
|
||||
raise NameError('This matrix is singular, cannot do inverse,\ntry increasing the second value of ops')
|
||||
# 最小二乘法求最优解: w0*1+w1*x1=y
|
||||
ws = xTx.I * (X.T * Y)
|
||||
return ws, X, Y
|
||||
|
||||
|
||||
# 回归树测试案例
|
||||
# 为了和 modelTreeEval() 保持一致,保留两个输入参数
|
||||
def regTreeEval(model, inDat):
|
||||
"""
|
||||
Desc:
|
||||
对 回归树 进行预测
|
||||
Args:
|
||||
model -- 指定模型,可选值为 回归树模型 或者 模型树模型,这里为回归树
|
||||
inDat -- 输入的测试数据
|
||||
Returns:
|
||||
float(model) -- 将输入的模型数据转换为 浮点数 返回
|
||||
"""
|
||||
return float(model)
|
||||
|
||||
|
||||
# 模型树测试案例
|
||||
# 对输入数据进行格式化处理,在原数据矩阵上增加第0列,元素的值都是1,
|
||||
# 也就是增加偏移值,和我们之前的简单线性回归是一个套路,增加一个偏移量
|
||||
def modelTreeEval(model, inDat):
|
||||
"""
|
||||
Desc:
|
||||
对 模型树 进行预测
|
||||
Args:
|
||||
model -- 输入模型,可选值为 回归树模型 或者 模型树模型,这里为模型树模型,实则为 回归系数
|
||||
inDat -- 输入的测试数据
|
||||
Returns:
|
||||
float(X * model) -- 将测试数据乘以 回归系数 得到一个预测值 ,转化为 浮点数 返回
|
||||
"""
|
||||
n = shape(inDat)[1]
|
||||
X = mat(ones((1, n+1)))
|
||||
X[:, 1: n+1] = inDat
|
||||
# print X, model
|
||||
return float(X * model)
|
||||
|
||||
|
||||
# 计算预测的结果
|
||||
# 在给定树结构的情况下,对于单个数据点,该函数会给出一个预测值。
|
||||
# modelEval是对叶节点进行预测的函数引用,指定树的类型,以便在叶节点上调用合适的模型。
|
||||
# 此函数自顶向下遍历整棵树,直到命中叶节点为止,一旦到达叶节点,它就会在输入数据上
|
||||
# 调用modelEval()函数,该函数的默认值为regTreeEval()
|
||||
def treeForeCast(tree, inData, modelEval=regTreeEval):
|
||||
"""
|
||||
Desc:
|
||||
对特定模型的树进行预测,可以是 回归树 也可以是 模型树
|
||||
Args:
|
||||
tree -- 已经训练好的树的模型
|
||||
inData -- 输入的测试数据,只有一行
|
||||
modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树
|
||||
Returns:
|
||||
返回预测值
|
||||
"""
|
||||
if not isTree(tree):
|
||||
return modelEval(tree, inData)
|
||||
# 书中写的是inData[tree['spInd']],只适合inData只有一列的情况,否则会产生异常
|
||||
if inData[0, tree['spInd']] <= tree['spVal']:
|
||||
# 可以把if-else去掉,只留if里面的分支
|
||||
if isTree(tree['left']):
|
||||
return treeForeCast(tree['left'], inData, modelEval)
|
||||
else:
|
||||
return modelEval(tree['left'], inData)
|
||||
else:
|
||||
# 同上,可以把if-else去掉,只留if里面的分支
|
||||
if isTree(tree['right']):
|
||||
return treeForeCast(tree['right'], inData, modelEval)
|
||||
else:
|
||||
return modelEval(tree['right'], inData)
|
||||
|
||||
|
||||
# 预测结果
|
||||
def createForeCast(tree, testData, modelEval=regTreeEval):
|
||||
"""
|
||||
Desc:
|
||||
调用 treeForeCast ,对特定模型的树进行预测,可以是 回归树 也可以是 模型树
|
||||
Args:
|
||||
tree -- 已经训练好的树的模型
|
||||
testData -- 输入的测试数据
|
||||
modelEval -- 预测的树的模型类型,可选值为 regTreeEval(回归树) 或 modelTreeEval(模型树),默认为回归树
|
||||
Returns:
|
||||
返回预测值矩阵
|
||||
"""
|
||||
m = len(testData)
|
||||
yHat = mat(zeros((m, 1)))
|
||||
# print yHat
|
||||
for i in range(m):
|
||||
yHat[i, 0] = treeForeCast(tree, mat(testData[i]), modelEval)
|
||||
# print "yHat==>", yHat[i, 0]
|
||||
return yHat
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 测试数据集
|
||||
testMat = mat(eye(4))
|
||||
print(testMat)
|
||||
print(type(testMat))
|
||||
mat0, mat1 = binSplitDataSet(testMat, 1, 0.5)
|
||||
print(mat0, '\n-----------\n', mat1)
|
||||
|
||||
# # 回归树
|
||||
# myDat = loadDataSet('data/9.RegTrees/data1.txt')
|
||||
# # myDat = loadDataSet('data/9.RegTrees/data2.txt')
|
||||
# # print 'myDat=', myDat
|
||||
# myMat = mat(myDat)
|
||||
# # print 'myMat=', myMat
|
||||
# myTree = createTree(myMat)
|
||||
# print myTree
|
||||
|
||||
# # 1. 预剪枝就是:提起设置最大误差数和最少元素数
|
||||
# myDat = loadDataSet('data/9.RegTrees/data3.txt')
|
||||
# myMat = mat(myDat)
|
||||
# myTree = createTree(myMat, ops=(0, 1))
|
||||
# print myTree
|
||||
|
||||
# # 2. 后剪枝就是:通过测试数据,对预测模型进行合并判断
|
||||
# myDatTest = loadDataSet('data/9.RegTrees/data3test.txt')
|
||||
# myMat2Test = mat(myDatTest)
|
||||
# myFinalTree = prune(myTree, myMat2Test)
|
||||
# print '\n\n\n-------------------'
|
||||
# print myFinalTree
|
||||
|
||||
# # --------
|
||||
# # 模型树求解
|
||||
# myDat = loadDataSet('data/9.RegTrees/data4.txt')
|
||||
# myMat = mat(myDat)
|
||||
# myTree = createTree(myMat, modelLeaf, modelErr)
|
||||
# print myTree
|
||||
|
||||
# # # 回归树 VS 模型树 VS 线性回归
|
||||
# trainMat = mat(loadDataSet('data/9.RegTrees/bikeSpeedVsIq_train.txt'))
|
||||
# testMat = mat(loadDataSet('data/9.RegTrees/bikeSpeedVsIq_test.txt'))
|
||||
# # # 回归树
|
||||
# myTree1 = createTree(trainMat, ops=(1, 20))
|
||||
# print myTree1
|
||||
# yHat1 = createForeCast(myTree1, testMat[:, 0])
|
||||
# print "--------------\n"
|
||||
# # print yHat1
|
||||
# # print "ssss==>", testMat[:, 1]
|
||||
# # corrcoef 返回皮尔森乘积矩相关系数
|
||||
# print "regTree:", corrcoef(yHat1, testMat[:, 1],rowvar=0)[0, 1]
|
||||
|
||||
# # 模型树
|
||||
# myTree2 = createTree(trainMat, modelLeaf, modelErr, ops=(1, 20))
|
||||
# yHat2 = createForeCast(myTree2, testMat[:, 0], modelTreeEval)
|
||||
# print myTree2
|
||||
# print "modelTree:", corrcoef(yHat2, testMat[:, 1],rowvar=0)[0, 1]
|
||||
|
||||
# # 线性回归
|
||||
# ws, X, Y = linearSolve(trainMat)
|
||||
# print ws
|
||||
# m = len(testMat[:, 0])
|
||||
# yHat3 = mat(zeros((m, 1)))
|
||||
# for i in range(shape(testMat)[0]):
|
||||
# yHat3[i] = testMat[i, 0]*ws[1, 0] + ws[0, 0]
|
||||
# print "lr:", corrcoef(yHat3, testMat[:, 1],rowvar=0)[0, 1]
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
"""
|
||||
Created on 2017-07-13
|
||||
Updated on 2017-07-13
|
||||
RegressionTree:树回归
|
||||
Author: 小瑶
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
"""
|
||||
from __future__ import print_function
|
||||
|
||||
print(__doc__)
|
||||
|
||||
# 引入必要的模型和库
|
||||
import numpy as np
|
||||
from sklearn.tree import DecisionTreeRegressor
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# 创建一个随机的数据集
|
||||
# 参考 https://docs.scipy.org/doc/numpy-1.6.0/reference/generated/numpy.random.mtrand.RandomState.html
|
||||
rng = np.random.RandomState(1)
|
||||
# print 'lalalalala===', rng
|
||||
# rand() 是给定形状的随机值,rng.rand(80, 1)即矩阵的形状是 80行,1列
|
||||
# sort()
|
||||
X = np.sort(5 * rng.rand(80, 1), axis=0)
|
||||
# print 'X=', X
|
||||
y = np.sin(X).ravel()
|
||||
# print 'y=', y
|
||||
y[::5] += 3 * (0.5 - rng.rand(16))
|
||||
# print 'yyy=', y
|
||||
|
||||
# 拟合回归模型
|
||||
# regr_1 = DecisionTreeRegressor(max_depth=2)
|
||||
# 保持 max_depth=5 不变,增加 min_samples_leaf=6 的参数,效果进一步提升了
|
||||
regr_2 = DecisionTreeRegressor(max_depth=5)
|
||||
regr_2 = DecisionTreeRegressor(min_samples_leaf=6)
|
||||
# regr_3 = DecisionTreeRegressor(max_depth=4)
|
||||
# regr_1.fit(X, y)
|
||||
regr_2.fit(X, y)
|
||||
# regr_3.fit(X, y)
|
||||
|
||||
# 预测
|
||||
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
|
||||
# y_1 = regr_1.predict(X_test)
|
||||
y_2 = regr_2.predict(X_test)
|
||||
# y_3 = regr_3.predict(X_test)
|
||||
|
||||
# 绘制结果
|
||||
plt.figure()
|
||||
plt.scatter(X, y, c="darkorange", label="data")
|
||||
# plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
|
||||
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
|
||||
# plt.plot(X_test, y_3, color="red", label="max_depth=3", linewidth=2)
|
||||
plt.xlabel("data")
|
||||
plt.ylabel("target")
|
||||
plt.title("Decision Tree Regression")
|
||||
plt.legend()
|
||||
plt.show()
|
||||
|
|
@ -0,0 +1,124 @@
|
|||
#!/usr/bin/python
|
||||
# coding:utf8
|
||||
|
||||
'''
|
||||
Created on 2017-03-08
|
||||
Update on 2017-05-18
|
||||
Tree-Based Regression Methods Source Code for Machine Learning in Action Ch. 9
|
||||
Author: Peter/片刻
|
||||
GitHub: https://github.com/apachecn/AiLearning
|
||||
'''
|
||||
from __future__ import print_function
|
||||
import regTrees
|
||||
from Tkinter import *
|
||||
from numpy import *
|
||||
|
||||
import matplotlib
|
||||
from matplotlib.figure import Figure
|
||||
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
|
||||
matplotlib.use('TkAgg')
|
||||
|
||||
|
||||
def test_widget_text(root):
|
||||
mylabel = Label(root, text="helloworld")
|
||||
# 相当于告诉 布局管理器(Geometry Manager),如果不设定位置,默认在 0行0列的位置
|
||||
mylabel.grid()
|
||||
|
||||
|
||||
# 最大为误差, 最大子叶节点的数量
|
||||
def reDraw(tolS, tolN):
|
||||
# clear the figure
|
||||
reDraw.f.clf()
|
||||
reDraw.a = reDraw.f.add_subplot(111)
|
||||
|
||||
# 检查复选框是否选中
|
||||
if chkBtnVar.get():
|
||||
if tolN < 2:
|
||||
tolN = 2
|
||||
myTree = regTrees.createTree(reDraw.rawDat, regTrees.modelLeaf, regTrees.modelErr, (tolS, tolN))
|
||||
yHat = regTrees.createForeCast(myTree, reDraw.testDat, regTrees.modelTreeEval)
|
||||
else:
|
||||
myTree = regTrees.createTree(reDraw.rawDat, ops=(tolS, tolN))
|
||||
yHat = regTrees.createForeCast(myTree, reDraw.testDat)
|
||||
|
||||
# use scatter for data set
|
||||
reDraw.a.scatter(reDraw.rawDat[:, 0].A, reDraw.rawDat[:, 1].A, s=5)
|
||||
# use plot for yHat
|
||||
reDraw.a.plot(reDraw.testDat, yHat, linewidth=2.0, c='red')
|
||||
reDraw.canvas.show()
|
||||
|
||||
|
||||
def getInputs():
|
||||
try:
|
||||
tolN = int(tolNentry.get())
|
||||
except:
|
||||
tolN = 10
|
||||
print("enter Integer for tolN")
|
||||
tolNentry.delete(0, END)
|
||||
tolNentry.insert(0, '10')
|
||||
try:
|
||||
tolS = float(tolSentry.get())
|
||||
except:
|
||||
tolS = 1.0
|
||||
print("enter Float for tolS")
|
||||
tolSentry.delete(0, END)
|
||||
tolSentry.insert(0, '1.0')
|
||||
return tolN, tolS
|
||||
|
||||
|
||||
# 画新的tree
|
||||
def drawNewTree():
|
||||
# #get values from Entry boxes
|
||||
tolN, tolS = getInputs()
|
||||
reDraw(tolS, tolN)
|
||||
|
||||
|
||||
def main(root):
|
||||
# 标题
|
||||
Label(root, text="Plot Place Holder").grid(row=0, columnspan=3)
|
||||
# 输入栏1, 叶子的数量
|
||||
Label(root, text="tolN").grid(row=1, column=0)
|
||||
global tolNentry
|
||||
tolNentry = Entry(root)
|
||||
tolNentry.grid(row=1, column=1)
|
||||
tolNentry.insert(0, '10')
|
||||
# 输入栏2, 误差量
|
||||
Label(root, text="tolS").grid(row=2, column=0)
|
||||
global tolSentry
|
||||
tolSentry = Entry(root)
|
||||
tolSentry.grid(row=2, column=1)
|
||||
# 设置输出值
|
||||
tolSentry.insert(0,'1.0')
|
||||
|
||||
# 设置提交的按钮
|
||||
Button(root, text="确定", command=drawNewTree).grid(row=1, column=2, rowspan=3)
|
||||
|
||||
# 设置复选按钮
|
||||
global chkBtnVar
|
||||
chkBtnVar = IntVar()
|
||||
chkBtn = Checkbutton(root, text="Model Tree", variable = chkBtnVar)
|
||||
chkBtn.grid(row=3, column=0, columnspan=2)
|
||||
|
||||
# 退出按钮
|
||||
Button(root, text="退出", fg="black", command=quit).grid(row=1, column=2)
|
||||
|
||||
# 创建一个画板 canvas
|
||||
reDraw.f = Figure(figsize=(5, 4), dpi=100)
|
||||
reDraw.canvas = FigureCanvasTkAgg(reDraw.f, master=root)
|
||||
reDraw.canvas.show()
|
||||
reDraw.canvas.get_tk_widget().grid(row=0, columnspan=3)
|
||||
|
||||
reDraw.rawDat = mat(regTrees.loadDataSet('data/9.RegTrees/sine.txt'))
|
||||
reDraw.testDat = arange(min(reDraw.rawDat[:, 0]), max(reDraw.rawDat[:, 0]), 0.01)
|
||||
reDraw(1.0, 10)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# 创建一个事件
|
||||
root = Tk()
|
||||
# test_widget_text(root)
|
||||
main(root)
|
||||
|
||||
# 启动事件循环
|
||||
root.mainloop()
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- coding: UTF-8 -*-
|
||||
|
||||
|
||||
import numpy as np
|
||||
|
||||
|
||||
class ReluActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
#return weighted_input
|
||||
return max(0, weighted_input)
|
||||
|
||||
def backward(self, output):
|
||||
return 1 if output > 0 else 0
|
||||
|
||||
|
||||
class IdentityActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return weighted_input
|
||||
|
||||
def backward(self, output):
|
||||
return 1
|
||||
|
||||
|
||||
class SigmoidActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return np.longfloat(1.0 / (1.0 + np.exp(-weighted_input)))
|
||||
|
||||
def backward(self, output):
|
||||
return output * (1 - output)
|
||||
|
||||
|
||||
class TanhActivator(object):
|
||||
def forward(self, weighted_input):
|
||||
return 2.0 / (1.0 + np.exp(-2 * weighted_input)) - 1.0
|
||||
|
||||
def backward(self, output):
|
||||
return 1 - output * output
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue